테슬라 플릿 러닝 (Fleet Learning)
2021, Apr 01
- 출처 : https://www.youtube.com/watch?v=Ucp0TTmvqOE (1시간 52분 부터 Vision 관련 내용)
- 이번 글에서는 테슬라 오토노머스 데이에서 발표한 현재 테슬라에서 사용하고 있는 플릿 러닝이란 개념에 대하여 간략하게 요약하였습니다.
- 여기서
플릿(Fleet)이라 함은 전 세계에서 양산되어 돌아다니고 있는 테슬라 차량이라고 생각하면 됩니다. - 즉,
플릿 러닝이라 함은 전 세계의 고객 차량으로 부터 수집한 데이터를 이용하여 딥러닝 학습을 한다고 생각하시면 됩니다.
실제 도로 환경의 데이터의 필요성
- 테슬라에서는 최대한 실제 도로를 통해서 데이터를 얻으려고 하는 전략을 가집니다.

- 예를 들어 실제 도로에서 데이터를 얻되 왼쪽 그림과 같이 데이터 얻지 않고 오른쪽 그림과 같이 실제 도로 상황을 반영하여 데이터를 얻고자 합니다.

- 특히 낮 데이터 뿐 아니라 밤, 공사 현장 등과 같은 다양한 실제 도로의 데이터를 얻고자 합니다.
- 테슬라에서도 시뮬레이션을 통한 다양한 환경에서의 물체들간의 상호 작용들을 재현하여 데이터를 얻었지만 그럼에도 불구하고 가장 좋은 데이터는 실제 현실에서 취득한 데이터 라고 합니다.
- 따라서 테슬라는 자율주행 성능을 육성하기 위해
Large dataset,Varied dataset,Real dataset3가지 조건을 만족하는 데이터 셋이 구축되어야 뉴럴 네트워크의 성능을 끌어올릴 수 있다고 설명합니다. 그리고 이 3가지 조건을 만족하는 데이터셋을 구축하는 방법이 바로플릿입니다.
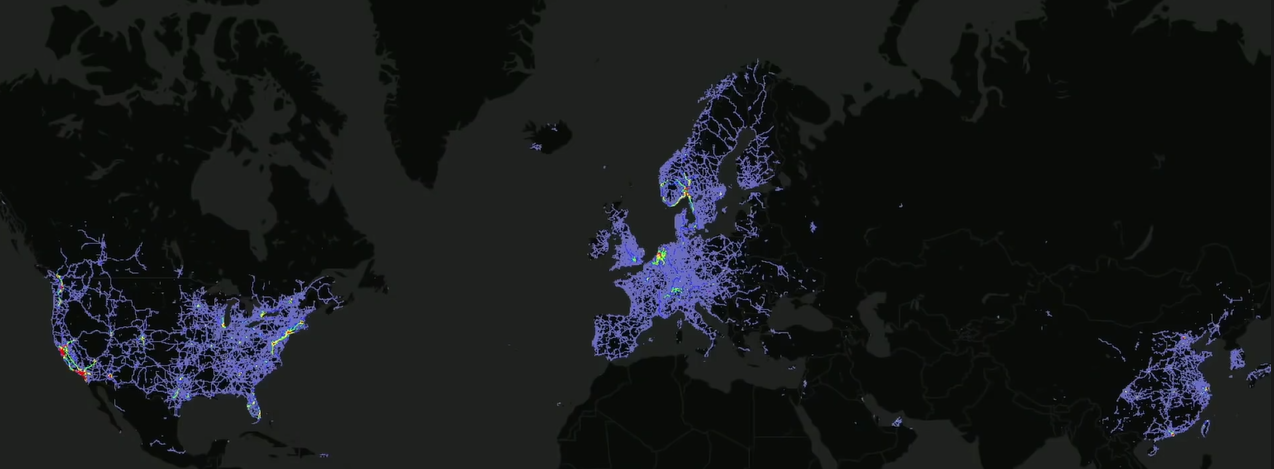
- 위 지도의 점들이 모두 테슬라 차량이라고 합니다. 저 다양한 환경의 플릿들로 부터 데이터를 수집하기 때문에
Large,Varied,Real3가지 조건을 만족할 수 있습니다.
플릿 러닝 프로세스

- 하나의 예시로 위 그림과 같은 경우 자전거는 인식을 하면 안되고 자동차 하나로 인식해야 합니다. 이러한 예외 케이스의 데이터들은 실도로 환경에서 밖에 구할 수 없습니다.
- 만약 위 그림과 같은 예외 상황이 발생하면 테슬라 내부적으로 그것을 인지하고 고객들로 부터 그러한 데이터를 전송하게 할 수 있도록 시스템을 마련하였다고 합니다.

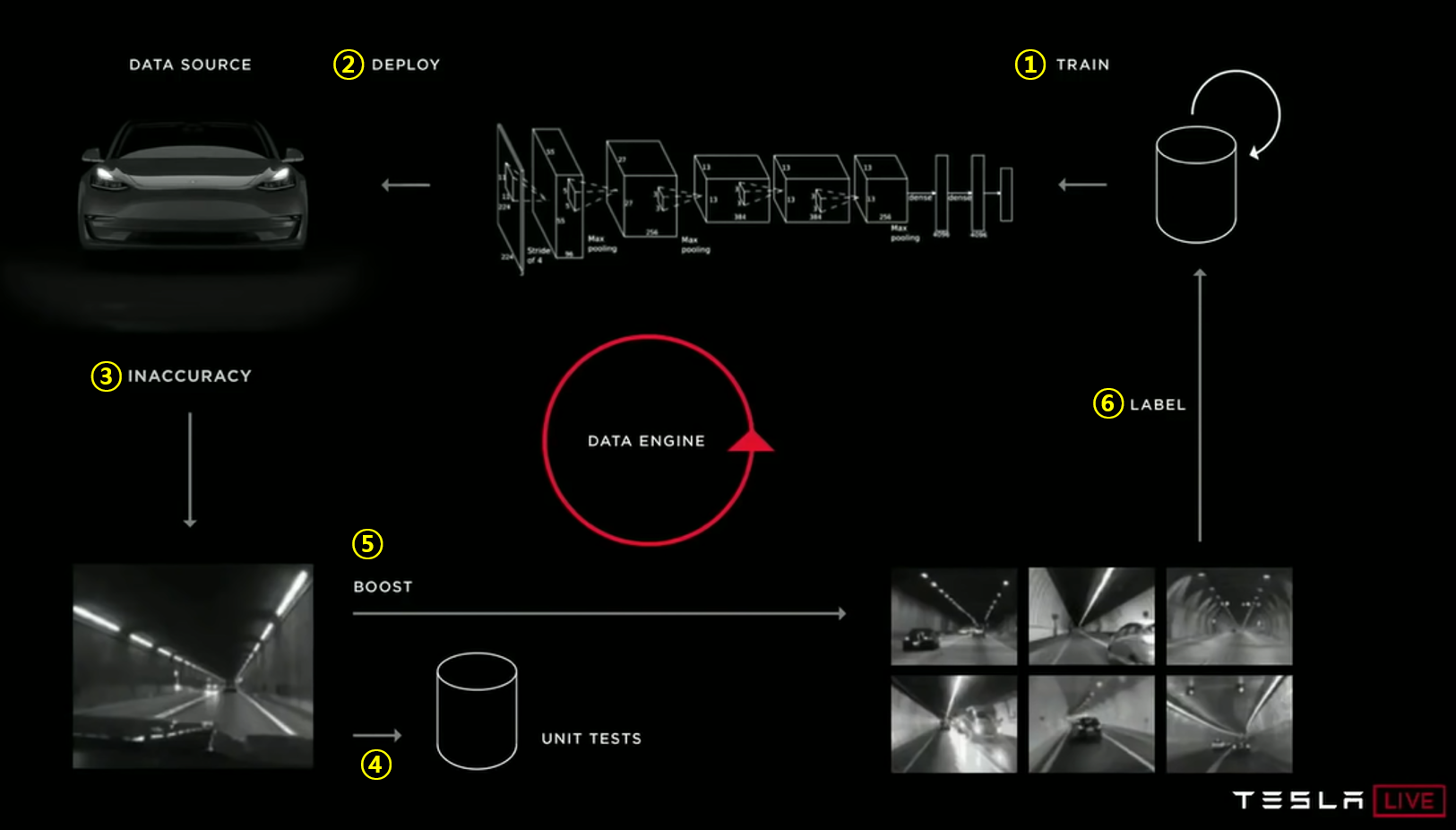
- 따라서 플릿 러닝을 위한 전체적인 프로세는 위 그림과 같습니다.
- ①
TRAIN: 기존에 보유중인 데이터 셋을 이용하여 딥 뉴럴 네트워크를 학습합니다. - ②
DEPLOY: 학습이 완료된 딥 뉴럴 네트워크를 OTA(Over The Air) 즉, 무선 네트워크를 통하여 자동으로 업데이트 합니다. - ③
INACCURACY: 오토파일럿, FSD와 같은 자율주행 기능을 사용 중에 내부 시스템적으로 인식이 잘 안된다고 판단되거나 고객이 시스템을 끄고 중간에 개입하는 것이 판단되면 그 상황의 이미지를UNIT TESTS로 전송합니다. 위 이미지의 예시는 터널에서 인식이 잘 되지 않았을 때의 상황을 Unit Test로 전송하는 것입니다. - ④
UNIT TESTS: UNIT TESTS로 전송된 데이터는 테슬라 내부적으로 확인하여 실제 인식이 잘 안된 데이터인지 확인을 하여 플릿들로 부터 확보해야 하는 데이터인 지 확인합니다. - ⑤
BOOST: UNIT TESTS를 통하여 플릿들로 부터 더 수집해야 하는 데이터로 판단이 되면 고객들로 부터 데이터를 수집합니다. 이 때, 고객들로부터 데이터 제공 동의를 받은 플릿에서 익명으로 데이터가 수집되도록 시스템을 구성하였습니다. 이 시스템을 통하여 예외 상황의 다양한 데이터를 수집할 수 있습니다. - ⑥
LABEL: BOOST 과정을 통해 플릿들로 부터 취득한 다양한 데이터를 다시 라벨링 하는 작업을 거쳐서 데이터셋에 추가합니다. - 이러한 6가지 과정을 계속 반복하여 학습 데이터를 계속 추가해 나아가고 성능을 육성합니다. 이것이 플릿 러닝의 기본적인 프로세스 입니다.
쉐도우(Shadow) 모드
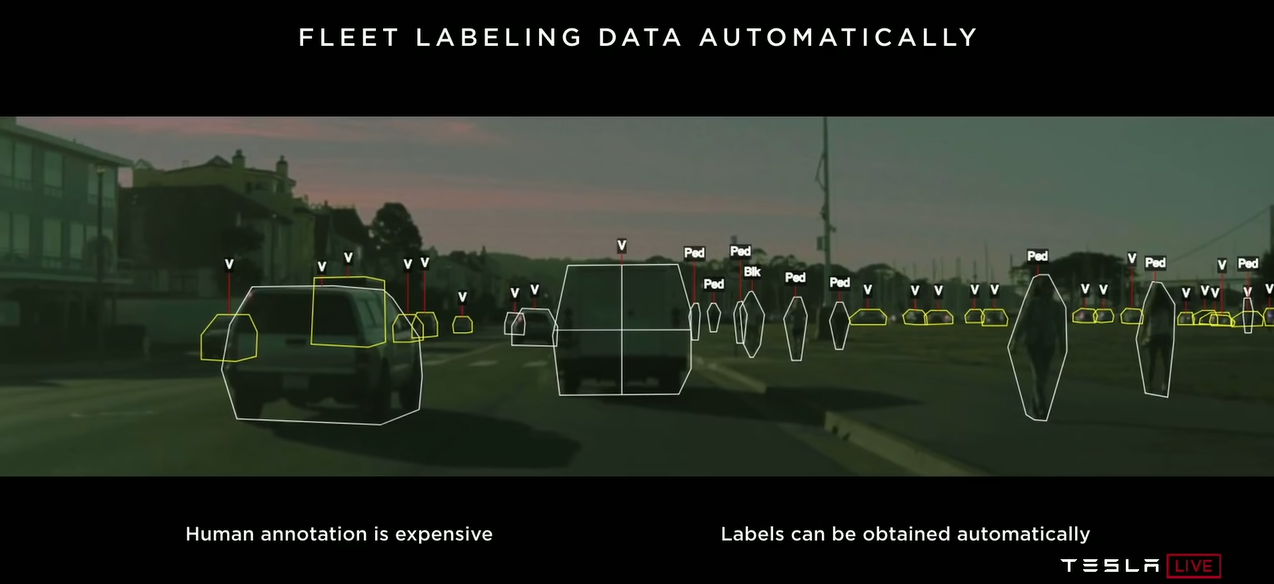
- 앞서 설명한 플릿 러닝 프로세스에서 빠진 점은 데이터 자동화 수집입니다. 자동화 없이 데이터를 수집하는 것은 아무래도 비용이 많이 들어가고 수집하는 데에도 한계가 있습니다. 따라서
쉐도우 모드라는 기능을 통하여 각 플릿에서 테스트 한 후 필요한 데이터를 테슬라 서버로 업로드 합니다.

- 위 예시는 데이터 추가 수집이 필요한 끼어들기 상황(CUT-IN) 예시입니다.
- 만약 추가 데이터로 끼어드는 상황의 데이터가 필요하다면 각 플릿 차량들이 내부적으로 주위 차량이 끼어들 차량인 지 아닌 지 예측하는 작업을 한다고 합니다.
- 만약 플릿 내부적으로 동작하는 로직이 끼어들기를 정확하게 예측하였다면 통과 되지만 예측과 틀린 경우 그 데이터를 테슬라 AI 팀으로 전달 하게 됩니다.
- 이 과정을 통하여 성능 육성이 필요한 상황들에 대하여 데이터를 수집할 수 있고 이 데이터를 이용하여 재학습 하는 플릿 러닝 프로세스를 계속 진행하게 됩니다.
- 이후 성능 육성이 완료되면 쉐도우 모드를 해제하거나 새로운 상황에 대한 쉐도우 모드를 진행하여 데이터 수집을 일부 자동화 할 수 있습니다.
- 이러한 자동화 수집 방법을 위하여 테슬라 내부 시스템으로 각 플릿 차량의 운전자가 정상 운전을 하는 사람인 지 난폭한 운전을 하는 사람인 지 판단하고 정상 운전자라고 판단되는 사람을 통해서 데이터를 수집합니다.