
2021 테슬라 AI 데이 (Day)
2021, Aug 28
- 21년 8월 20일에 개최한 테슬라 AI 데이에는 테슬라의 FSD 시스템을 구축하기 위한 일련의 과정을 잘 소개해 놓았습니다.
- 테슬라가 가지고 있는 기술 스택에는 어떤 것이 있는 지, 영상의 순서에 맞게 차례대로 알아보며 영상과 관련된 참조 될말한 상세 기술 내용은 별도 링크를 첨부하겠습니다.
목차
-
Tesla Vision
-
Planning and Control
-
Manual Labelling
-
Auto Labelling
-
Simulation
-
Hardware Integration
-
Dojo
Tesla Vision
- 테슬라의 현재 가장 중요한 인식 기술이 되는 비전 시스템입니다. 비전 시스템은 8대의 카메라로 부터 받은 영상을 이용하여 주위 환경을 인식을 하는데 사용됩니다.
- 지난 CVPR 2021에서도 안드레 카파시의 세미나를 통해 테슬라의 비전 시스템의 전체 구조를 이해할 수 있었습니다. 이번에는 전체 아키텍쳐를 더 자세하게 설명을 해주었는데, 실제 사용하는 딥러닝 네트워크의 종류도 설명한 점이 이례적입니다.
- 아래 별도 숫자로 표기된 내용은 발표에서 언급한 네트워크 아키텍쳐에 해당하며 각각의 링크에서 관련 내용을 살펴볼 수 있습니다.
- ①
RegNet: - ②
BiFPN (EfficientDet): - ③
Transformer: - ④
Spatial RNN:
- 테슬라는 차량 주위의 8대의 카메라로부터 데이터가 들어오면 이 이미지들을
vector space라는 곳으로 옮길 수 있도록 실시간으로 처리합니다. 이vector space는 운전하는데 필요한 정보 (도로의 커브, 신호동, 교통 표지판, 차량 및 차량의 방향, 위치, 속도 등)를 3차원으로 표현해줍니다.

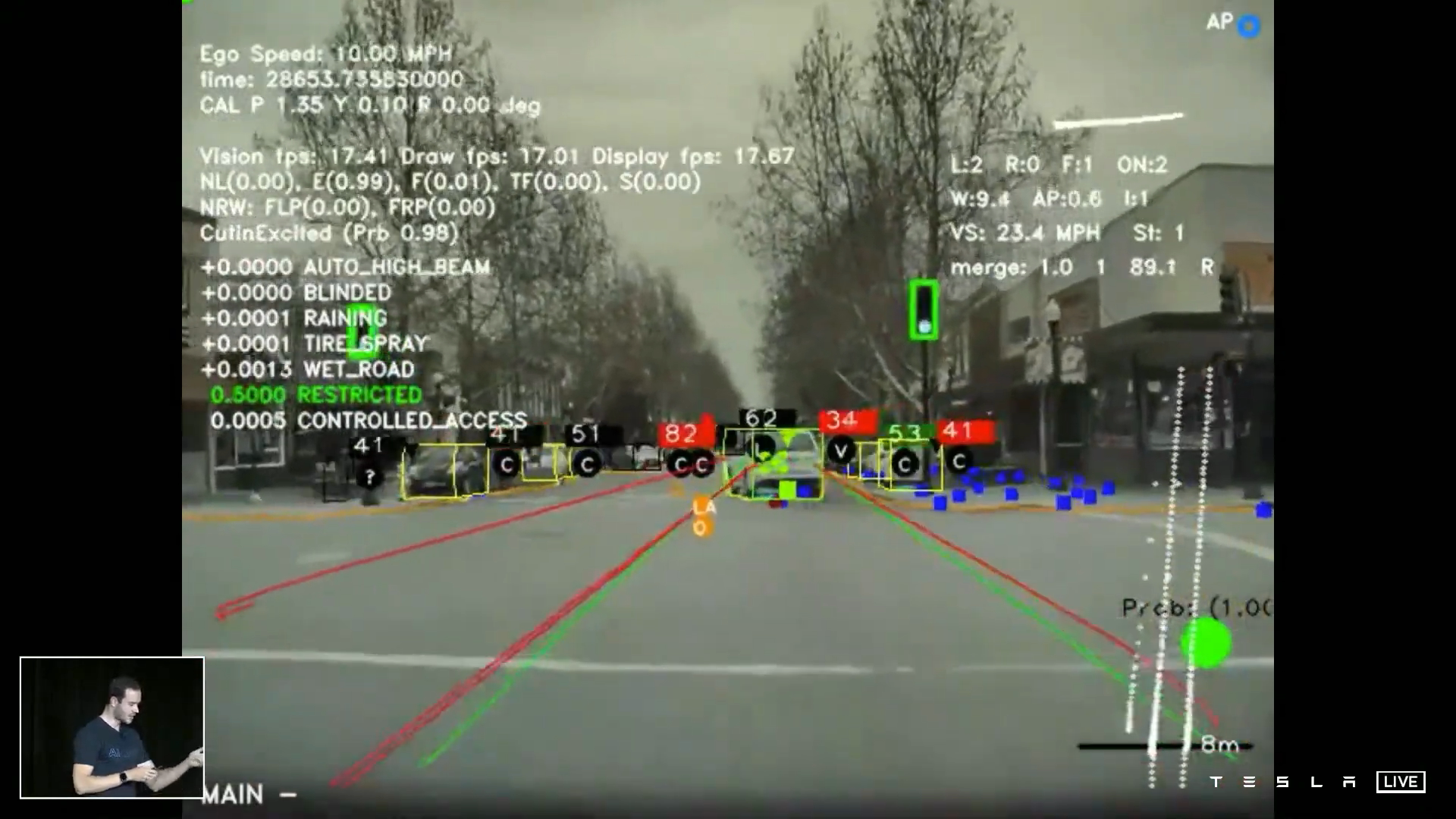
vector space의 결과를 보면 위 그림과 같이 8개의 카메라 영상을 입력으로 받고뉴럴 네트워크를 통하여 오른쪽 이미지의 디스플레이에 나오는 출력과 같이 벡터 공간의 정보를 렌더링하여 보여줍니다.
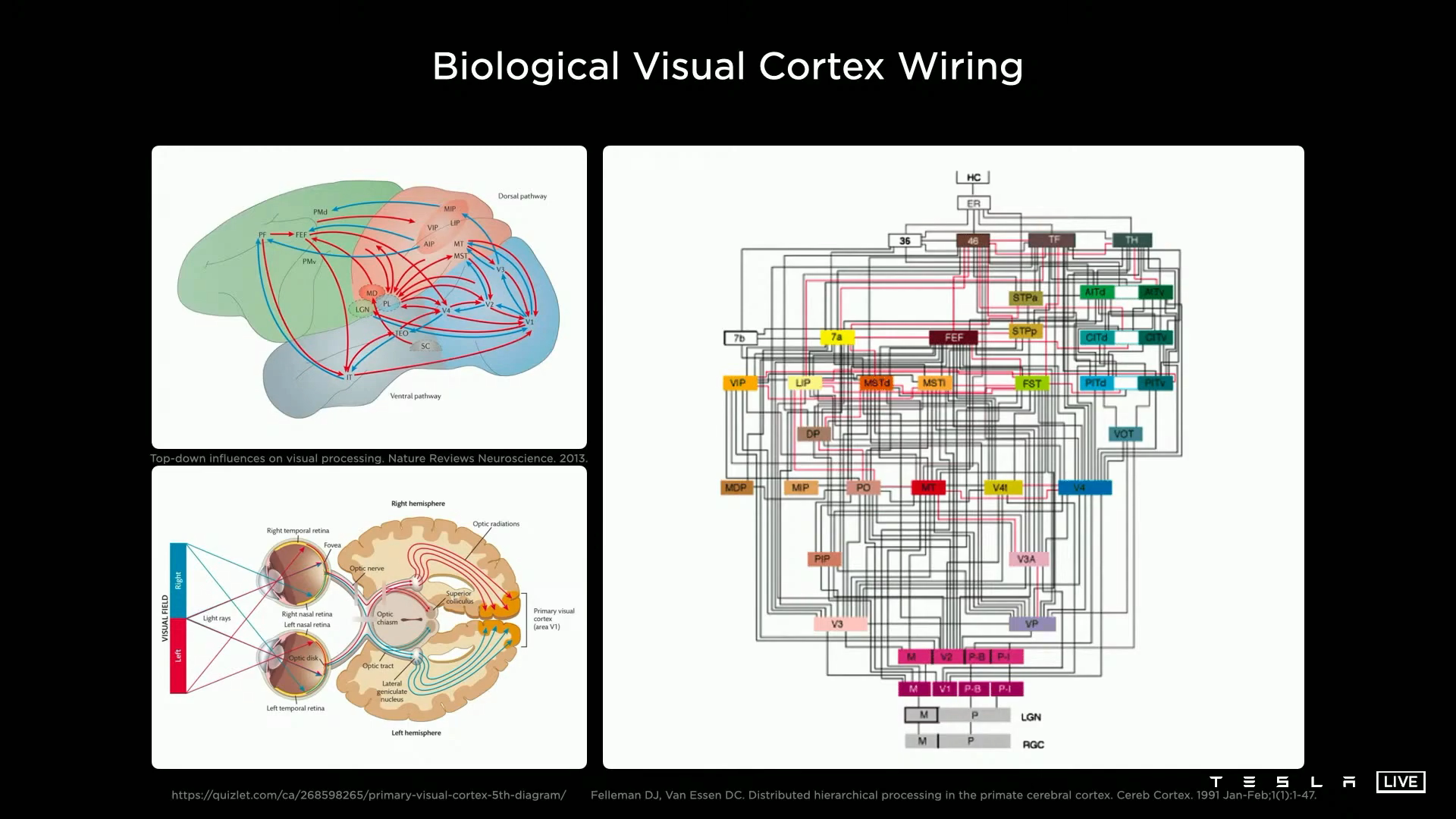
뉴럴 네트워크에서 하는 task는 인간의 시각을 통해 얻는 정보와 같이 카메라를 통해 얻은 정보를 처리하여 주변 환경을 인식하는 데 있습니다.

- 빛이 눈을 통해 들어와 망막에 물체의 상이 형성되는 것과 같이 빛이 카메라 렌즈를 통해 들어오게 되면 이미지 센서에 상이 형성되게 됩니다.
- 위 자료에서 살펴볼 수 있는 점은 테슬라에서 사용하는 카메라에 관한 정보입니다. 가로(1280 픽셀), 세로(960 픽셀) 크기의 이미지이며 HDR (High Dinamic Range)을 표현하기 위하여
12-bit 인코딩을 사용한 것을 알 수 있습니다. 그리고36 FPS로 영상이 입력되고 있는 것도 확인할 수 있습니다.
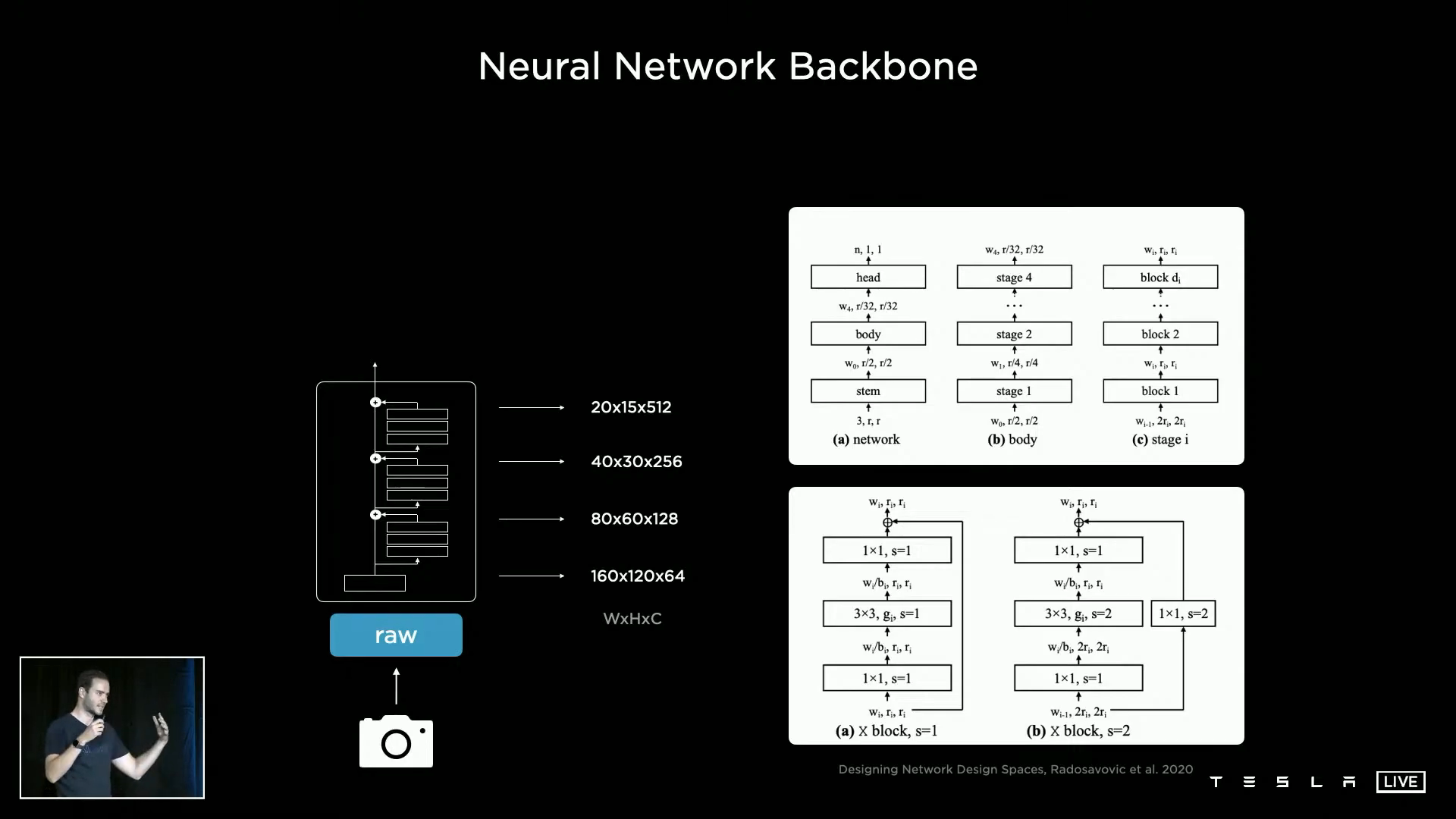
- 이와 같은 이미지 데이터가 입력이 되면 뉴럴 네트워크가 이 데이터를 처리하게 됩니다. 뉴럴 네트워크의
feature extractor는 그 이미지 데이터의 특징을 찾아내 의미있는 데이터를 구분하여 구체화합니다. - 이미지의 특징점들을 잘 찾아내는 것은 성능에 큰 영향을 미치게 되므로
backbone(척추)로 표현합니다. - 여기에는 수많은 Residual Block이 서로 연결되어 있고 이 연결성을 효과적으로 구현하기 위하여 현재 사용중인
backbone은RegNet을 사용하고 있습니다.RegNet관련 설명 링크 : https://gaussian37.github.io/dl-concept-regnet
RegNet은 뉴럴 네트워크를 위한 매우 좋은 디자인 공간을 만들어 주며latency와accuracy의 트레이드 오프를 할 수 있도록 지원합니다.RegNet은 아웃풋으로 서로 다른 해상도와 스케일의 feature를 추출합니다. 슬라이드 가운데를 보면W X H X C형태로 feature의 크기 정보가 나와있습니다.- 고해상도(W X H의 크기가 큼)는 적은 채널을 가지고 저해상도(W X H의 크기가 작음)는 많은 채널을 가지도록 설계되어 있으며
backbone의 깊이가 깊어질수록 고해상도 → 저해상도로 압축이 되는 것을 알 수 있습니다. 이 구조는 일반적으로 많이 사용되는backbone의 형태와 같습니다. 이와 같은 경우 입력과 가까운 layer일수록 물체의 디테일한 정보를 가지고 있고 입력과 먼 layer일 수록 전체적인 맥락을 살펴볼 수 있음이 알려져 있습니다.
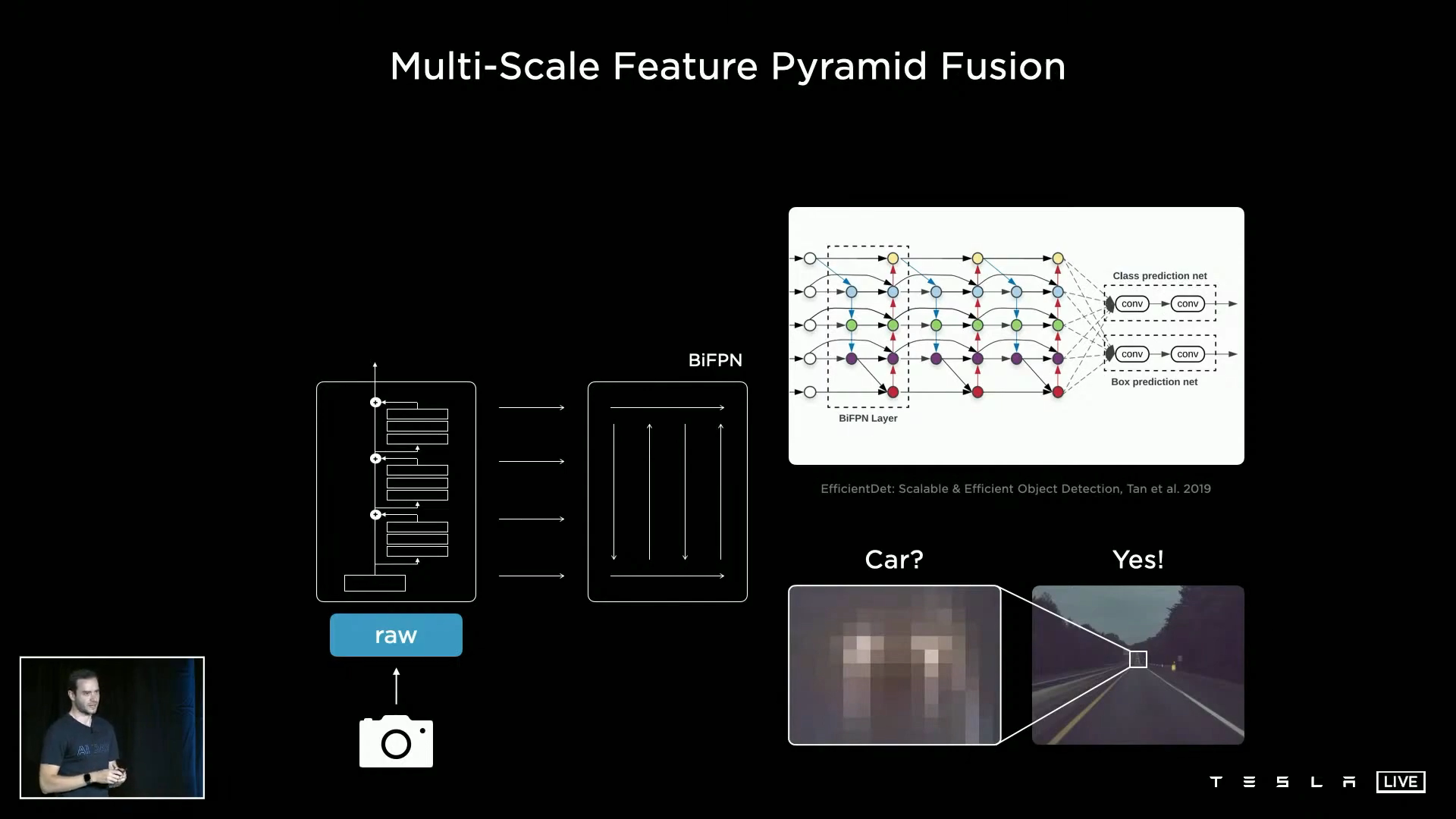
backbone의 layer에서 추출한 feature를BiFPN을 이용하여 처리합니다. 이 처리의 목적은Multi-Scale Feature Pyramid Fusion을 하기 위함이며 다양한 해상도를 이용한 이 방법을 통해 각 feature들이 서로 효과적으로 정보를 공유할 수 있습니다.- 예를 들어 디테일한 정보를 인식할 수 있는 layer의 뉴런이 전체 영역에서 인식할 수 있는 정보를 통해 인식한 물체가 차인지 아닌지 등을 확인하는 데 사용할 수 있다는 뜻입니다.
BiFPN은EfficientDet논문에서 소개되었으며 상세 내용은 아래 링크를 확인하시면 됩니다.EfficientDet관련 설명 링크 : https://gaussian37.github.io/vision-detection-efficientdet
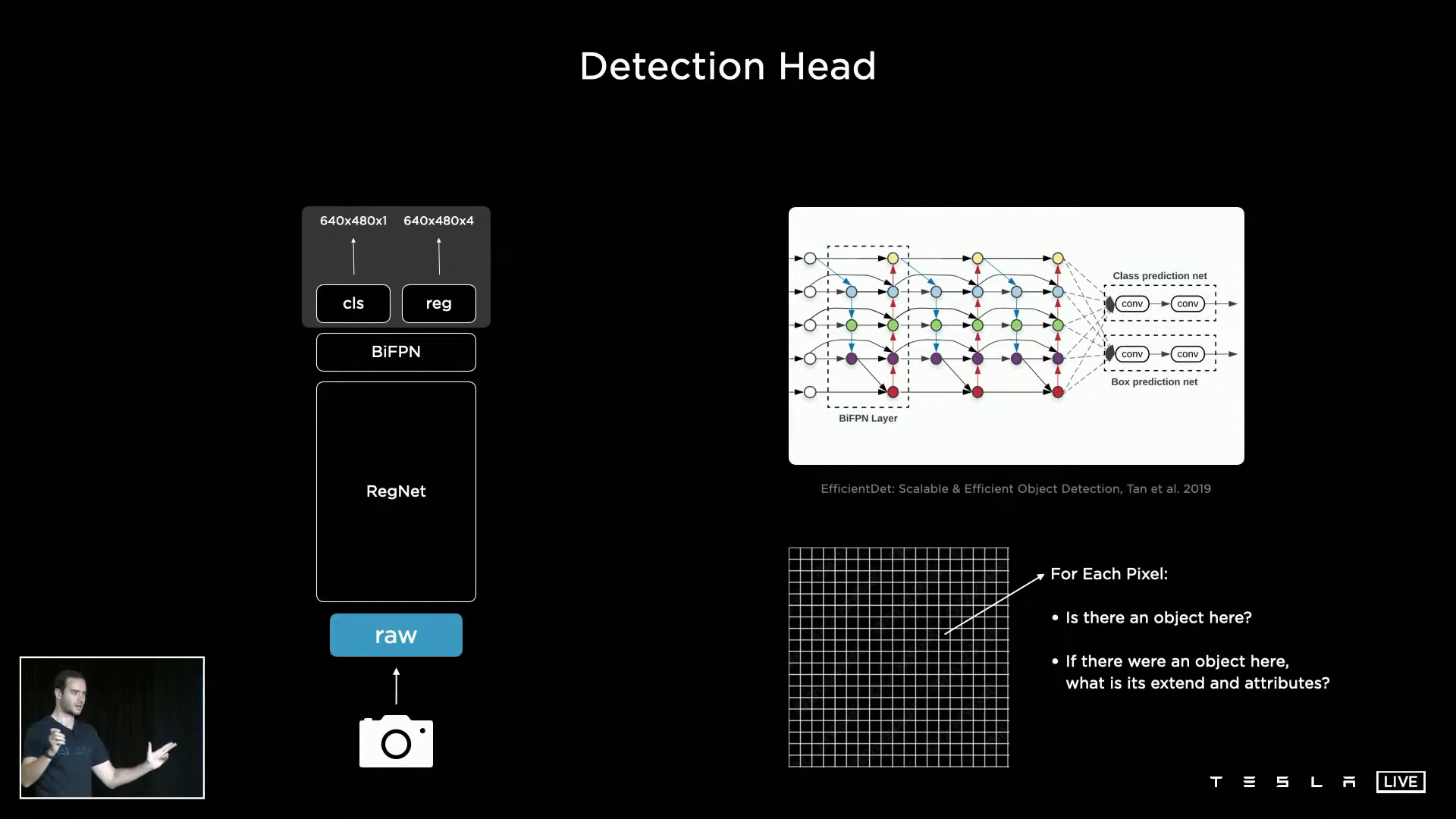
RegNet과BiFPN을 거친 Feature를 이용하여Detection Head를 거치게 됩니다.- 오른쪽 하단과 같은 비트맵 이미지 상에서
물체의 존재 여부와물체의 영역 및 속성등을 추정하는 것이Detection Head의 목적이 됩니다. - 2가지 역할을 하기 위하여
Detectino Head에는cls(classification)와reg(regression)2가지 헤더가 있습니다. 자료에 따르면 2가지 헤더 모두width = 640, height = 480의 해상도를 가지며cls의 채널 수는1,reg의 채널 수는 4를 가짐을 알 수 있습니다. cls는 binary 형태로 그 픽셀을 기준으로 물체가 있는 지, 없는 지를 나타냅니다. 따라서 1개의 채널에 그 값을 저장할 수 있습니다.reg는cls에 값이 있을 떄, 그 값을 기준으로 X, Y 축으로의 길이 및 그 물체에 대한 속성 값을 4개의 채널에 저장합니다.- 이러한 방법으로 특정 Task에 대한 Detection을 할 수 있습니다.
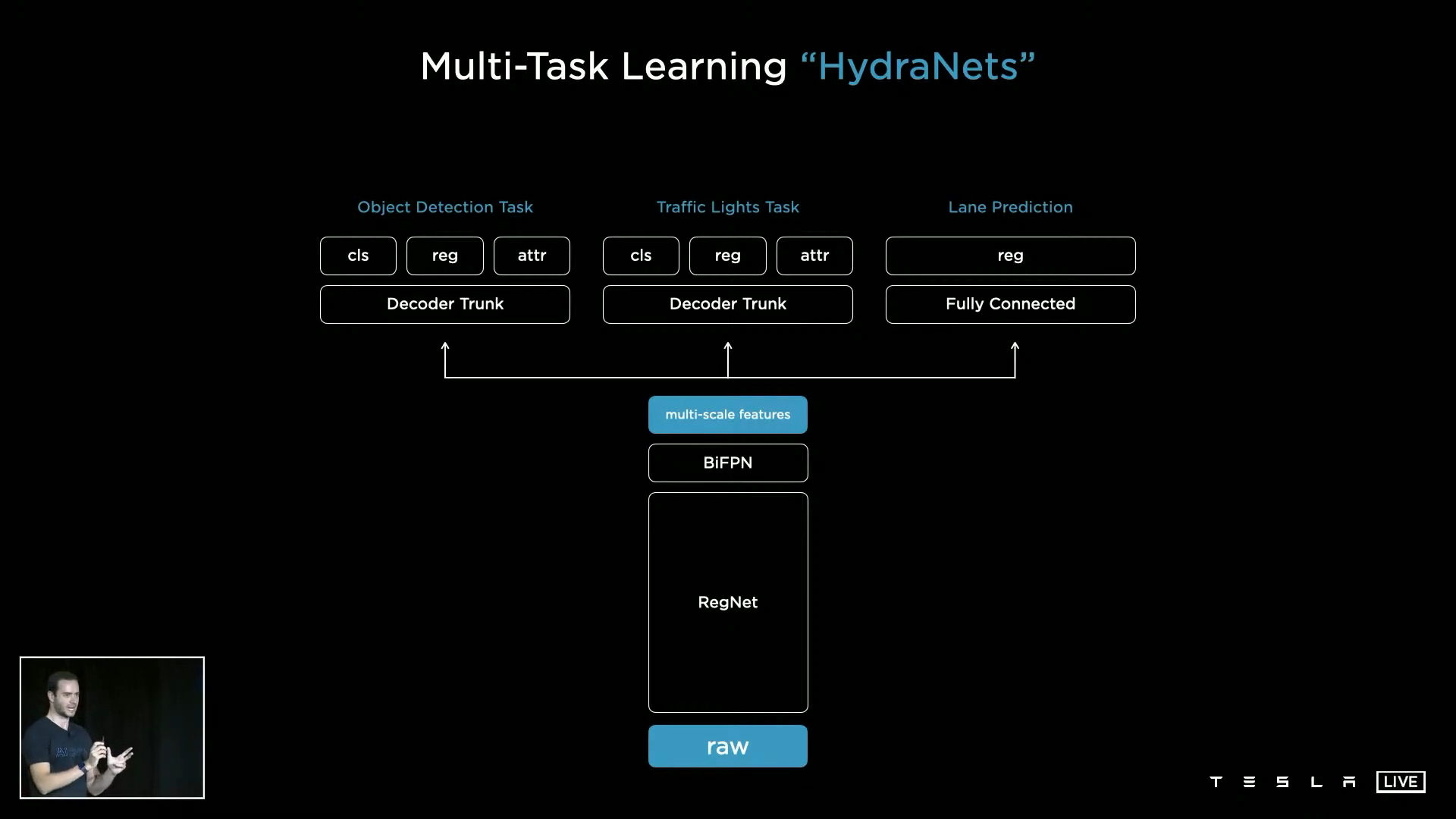
- 더 나아가서 뉴럴 네트워크가 여러가지 Task에 대하여 동작할 수 있도록 뉴럴 네트워크를 설계할 수 있습니다.
- 위 그림과 같이 1개의 backbone을 사용하고 backbone에서 나오는 출력을 이용하여 다양한 Task (Object Detection Task, Traffic Light Task, Lane Prediction) 등을 할 수 있습니다. 왜냐하면
multi-scale feature자체에는 영상의 중요한 정보를 모두 담고 있다고 가정하기 때문입니다. - 이러한 방식의 아키텍쳐 레이아웃을 사용하면 공통의 backbone에서 많은 헤드로 가지가 뻗어나도록 만들 수 있습니다. 생긴 것이 Hydra와 같다고 하여 이와 같은
Multi-Task Learning을 위한 네트워크를HydraNet으로 부릅니다. - 이와 같은 아키텍쳐에는 크게 3가지 이점이 있습니다.
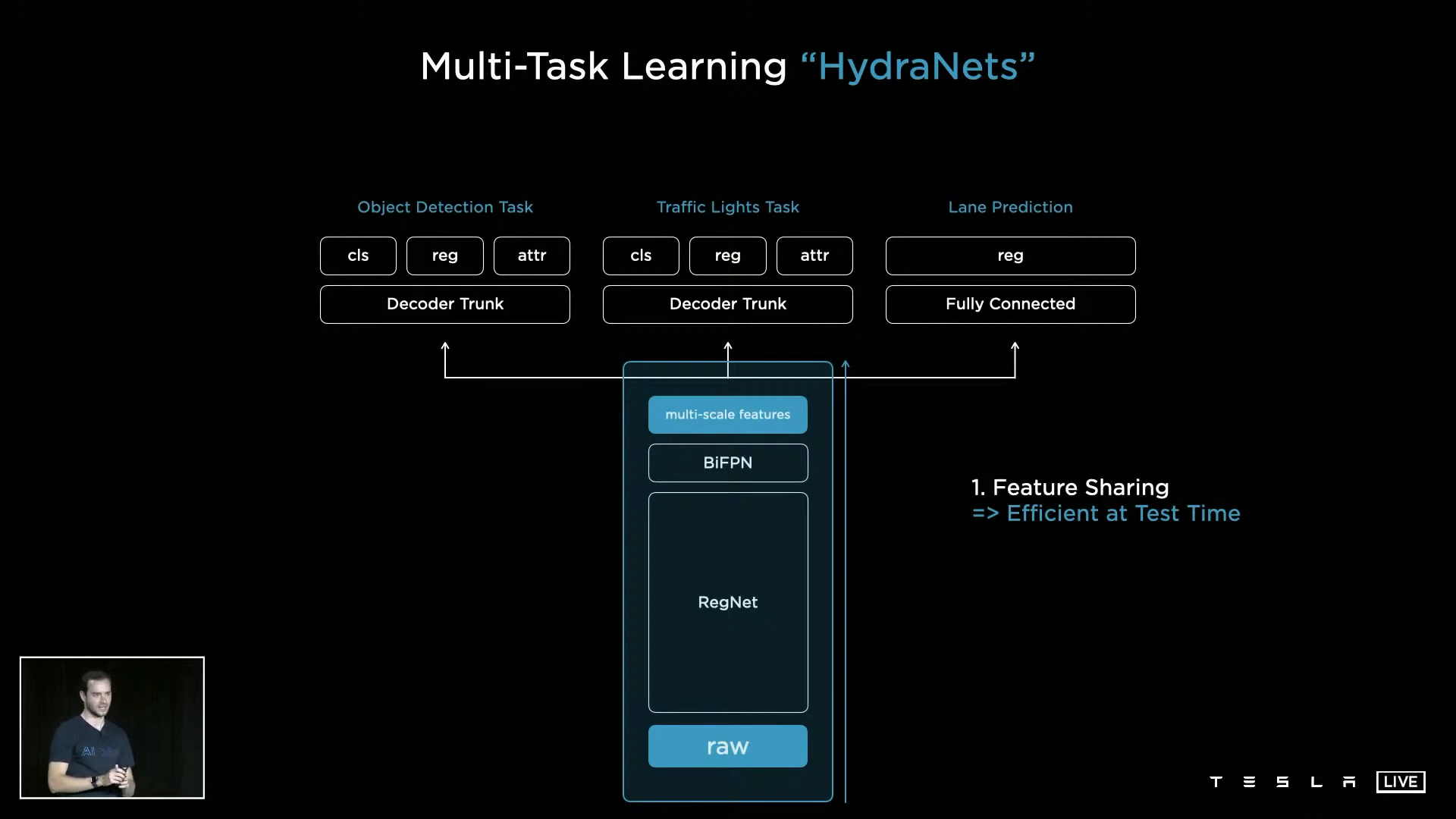
- ① feature를 서로 공유하기 때문에 테스트 차량에서의 inference에 사용되는 계산량이 줄어들게 되어 효율적입니다. 만약 모든 작업에 backbone이 따로 있어야만 한다면 차량 내부에 backbone이 너무 많아지는 문제가 발생하는데 그 문제를 개선할 수 있습니다.
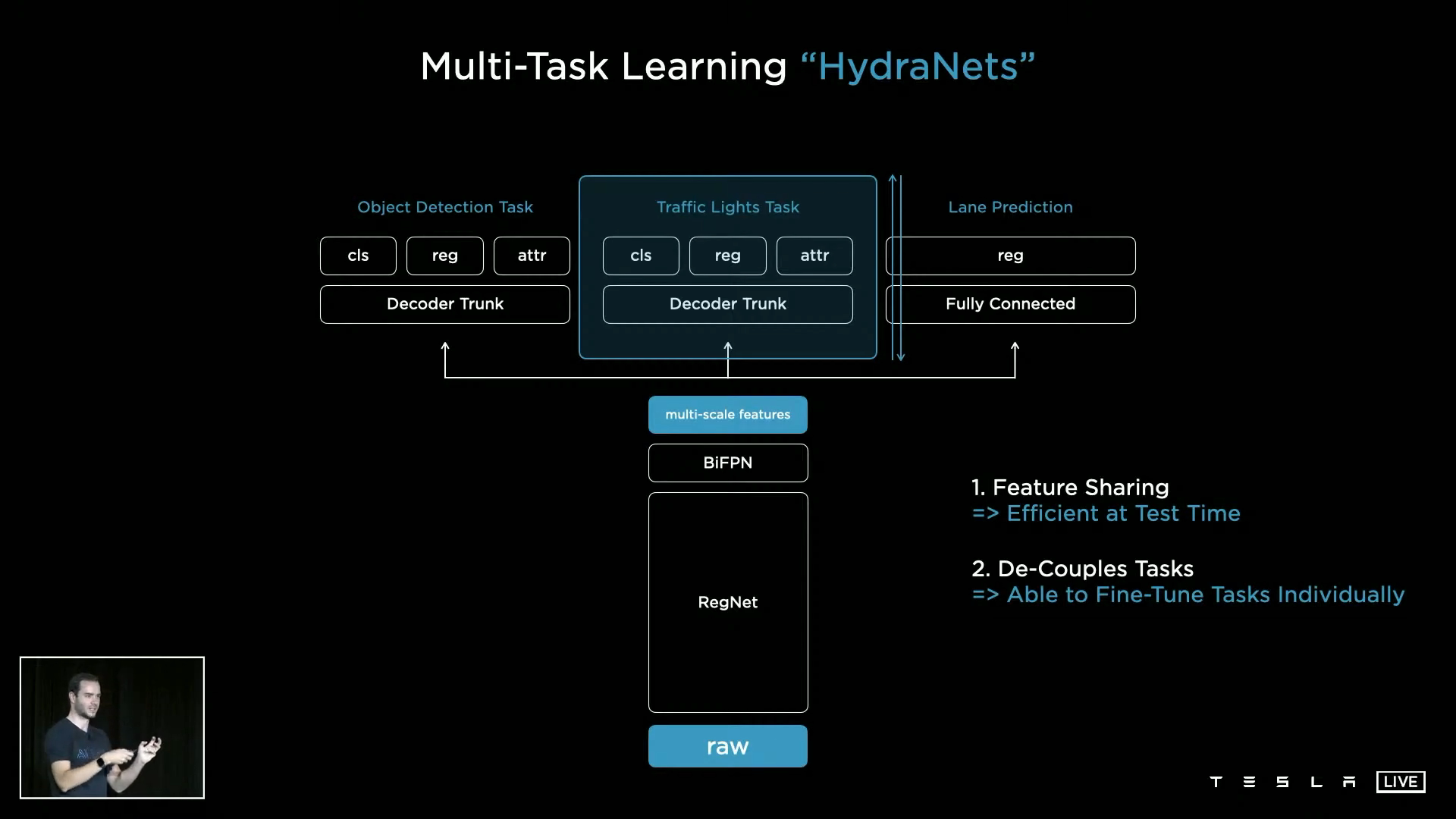
- ② backbone 이후의 각 Task 마다 분기가 발생하기 때문에 모든 작업의 연결 구조를 끊을 수 있어서 모든 작업을 독립적으로 수행할 수 있습니다. 특정 Head에 대해서만 추가 데이터셋을 사용하여
Fine Tuning을 할 수 있고 필요 시 헤드만 바꿀 수도 있습니다. 즉, backbone이 고정되어 있는 상태라면 head 끼리는 영향성이 전혀 없으므로 서로 다른 Task에 대해 검증에 드는 비용을 줄일 수 있습니다.
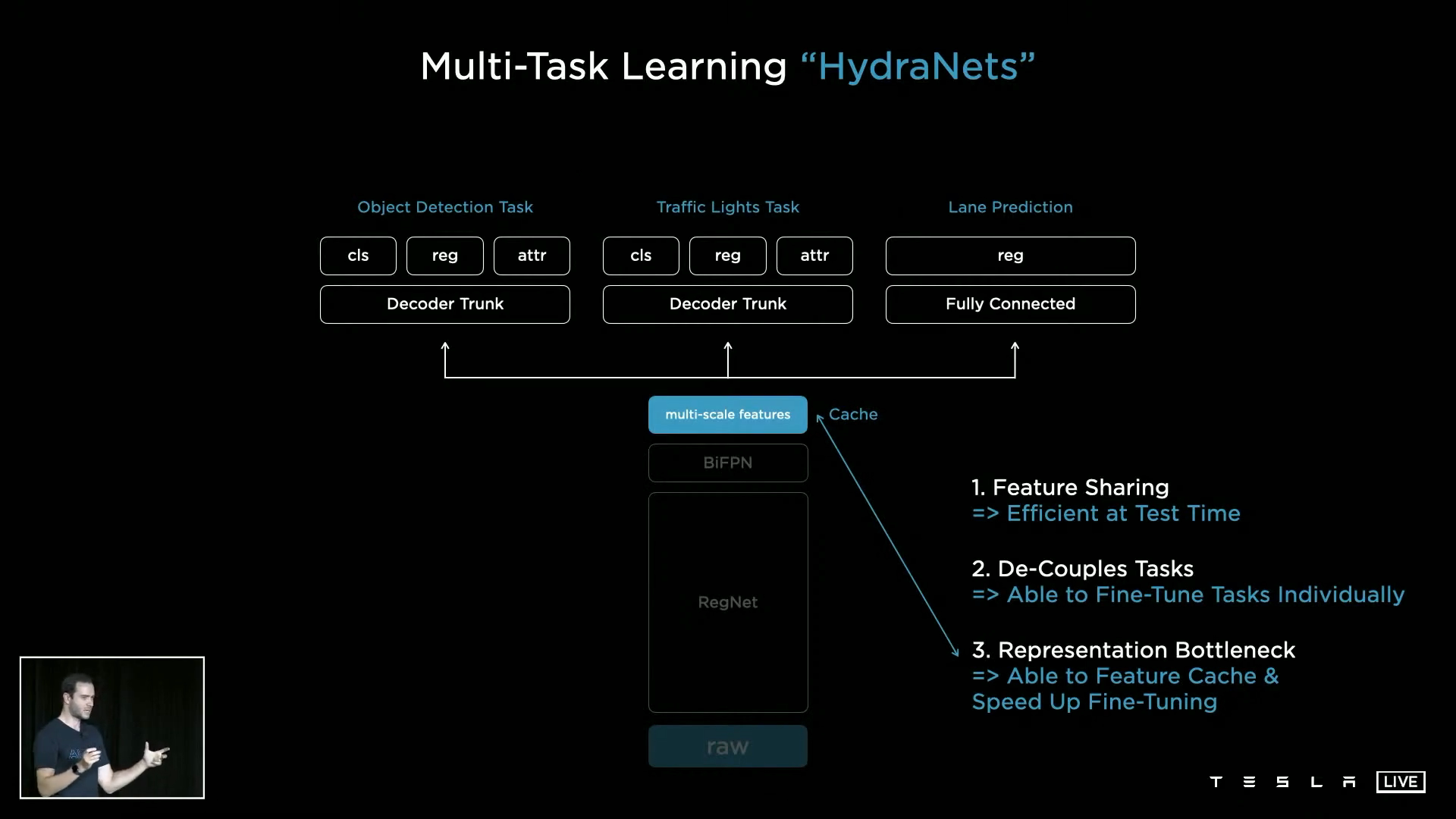
- ③ 전체 backbone을 매번 학습하지 않고 backbone의 출력부인
multi-scale feature을Fine Tuning할 때, 도움이 됩니다. Fine Tuning을 한 다음에, End-To-End로 전체적인 학습을 진행하곤 합니다.
- 앞에서 설명한 바와 같이 테슬라에서는 2016년도 경에는 각각의 역할을 하는 네트워크가 독립적으로 동작하도록 네트워크가 설계되었었습니다.
- 그 결과 위 그림과 같이 정지신호, 신호등, 차선, 도로경계, 다른 차들에 대한 각각의 예측을 볼 수 있습니다.
- 하지만
FSD를 위해서는 이와 같은 각각의 독립적인 네트워크를 별개로 사용하는 것에는 성능적인 한계가 있었습니다. 현재는 뉴럴 네트워크 측면에서는 앞에서 설명한HydraNet을 도입하였고 추가적으로vector space라는 최종 output 공간을 새로 정의하여 현재FSD수준을 구현할 수 있었습니다.

- 기존 문제를 개선하게된 시작점은 주차된 테슬라 차량을 호출하는
summon기능을 개선하기 위함이었습니다. - 위 그림과 같이 각 카메라에서 들어오는 영상을 이용하여 이미지에서 얻을 수 있는 정보를 얻은 후 그 정보들을 다시 모아서 전체 실시간으로 지도를 생성하였습니다.

- 각각의 이미지로부터 커브를 인식해내고 카메라 별 영역에 대한 장면들을 계속해서 스티칭 하게 하였습니다. 이 과정에서 크게 2가지 문제점이 있었습니다.
- ① 카메라 퓨전과 같은 물체가 여러 카메라에 걸쳐 있거나 이동 중일 때, tracking 하기가 까다롭다는 문제가 있습니다.
- ② 이미지 공간 (W X H X 3) 이 실제 3차원 공간과 차이가 있기 때문에 이미지 공간을 실제 3차원 공간의 좌표로 변환을 해줘야 한다는 문제가 있습니다.

- 위 슬라이드를 보면
① 카메라 퓨전,② 실제 3차원 공간 표시 문제2가지를 느낄 수 있습니다. 각각의 이미지에서는 잘 인식한 결과를 현실의 좌표계로 옮겼을 때에는 굉장히 성능이 나빠진 것을 알 수 있습니다. - 이와 가은 문제의 주요 원인은 픽셀 별로 정확한 깊이를 예측하기 어렵기 때문입니다. 또한 카메라에서 가려진 부분을 예측하는 것도 불가능합니다.

- 위 슬라이드는
카메라 퓨전이 얼마나 어려운 지 나타냅니다. 인식된 트레일러는 1대인데 카메라 퓨전을 통하여 이것을 1대의 차라고 인식하기는 상당히 까다롭습니다.
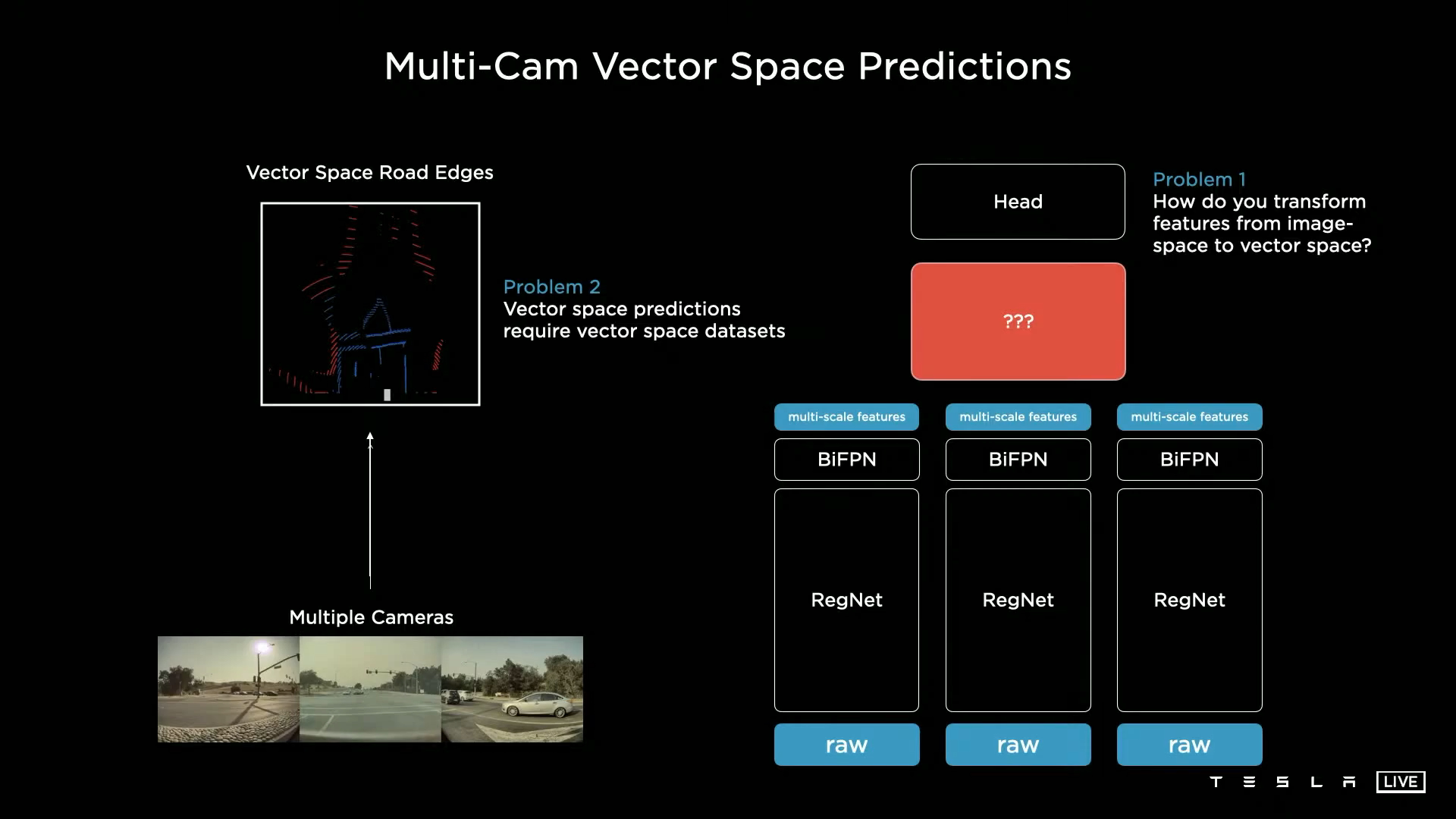
- 이 문제를 해결하기 위하여
Multi-Cam Vector Space를 구현하고자 하였습니다. 이미지 공간에서의 feature가vector space의 feature로 다시 표시되도록 만드는 것이 목적입니다. 이 때, 2가지 문제를 해결해야 합니다. - ① 각 카메라로 부터 들어온 영상을
image space→vector space로 어떻게 변환할 것인지 해결해야 합니다. - ②
vector space를 딥러닝으로 예측하기 위해서는vector space dataset이 필요합니다. 이 데이터셋이 있어야 End-to-End로 학습이 가능해지기 때문입니다.
- 먼저 Tesla Vision 챕터에서는 ① 문제인
vector space생성 방법에 대하여 다루고 그 이후 챕터인 Manual Labelling, Auto Labelling, Simulation에서 ② 문제인vector space dataset생성에 대하여 다루도록 하겠습니다.