
Andrej Karpathy (Tesla) CVPR 2021 Workshop on Autonomous Vehicles 정리
2021, Jun 30
- 출처 : https://www.youtube.com/watch?v=NSDTZQdo6H8
- 이번 글은 Andrej Karpathy가 CVPR 2021에서 발표한 Vision만을 이용하여 어떻게 테슬라에서 자율주행을 하는 지에 대한 간략한 설명을 정리하였습니다.
- 영상의 주요 내용은
Vision만으로도 자율주행을 위한 인식이 사용 가능하다는 것과 vision의 성능을 향상하기 위하여 어떻게 데이터를 구축하였는 지에 대한 내용입니다.

- 약간 표현이 어색하지만 사람을
Meat Computer라고 표현하였습니다. 사람은 80mph가 넘는 속도로 움직이는 1톤의 물체를 정교하게 제어해야 합니다. - 하지만 사람은 250ms의 latency를 가지고 주변 상황을 인식하기 위해서는 고개를 돌려서 상황을 직접 봐야 하는 한계가 있습니다. 심지어 인스타그램을 하는 딴 짓을 하기도 합니다. 이러한 단점들로 인하여 전세계적으로 약 3700명의 사람이 교통사고로 죽어가고 있고 있습니다.

- 반면 컴퓨터는 사람의 이러한 단점을 개선할 수 있습니다. (컴퓨터를
Silicon Computer로 표현하였습니다.) - 컴퓨터는 먼저 latency가 100ms 이하이고 360도 전방을 감지할 수 있습니다.
- 또한 사람처럼 딴 짓을 하지 않고 상시 전 집중을 하여 주변 상황을 인지합니다.
- 이러한 장점들로 인하여 교통 사고 문제를 개선할 수 있습니다.

- 현재 테슬라에서 제공하는 자율주행 시스템은
AEB (Autonomous Emergency Braking, 긴급 제동),Traffic Control Warning,PMM (Pedal Misapplication Mitigation, 운전자 페달 오조작 완화)와 같은 기능을 제공하고 있습니다.
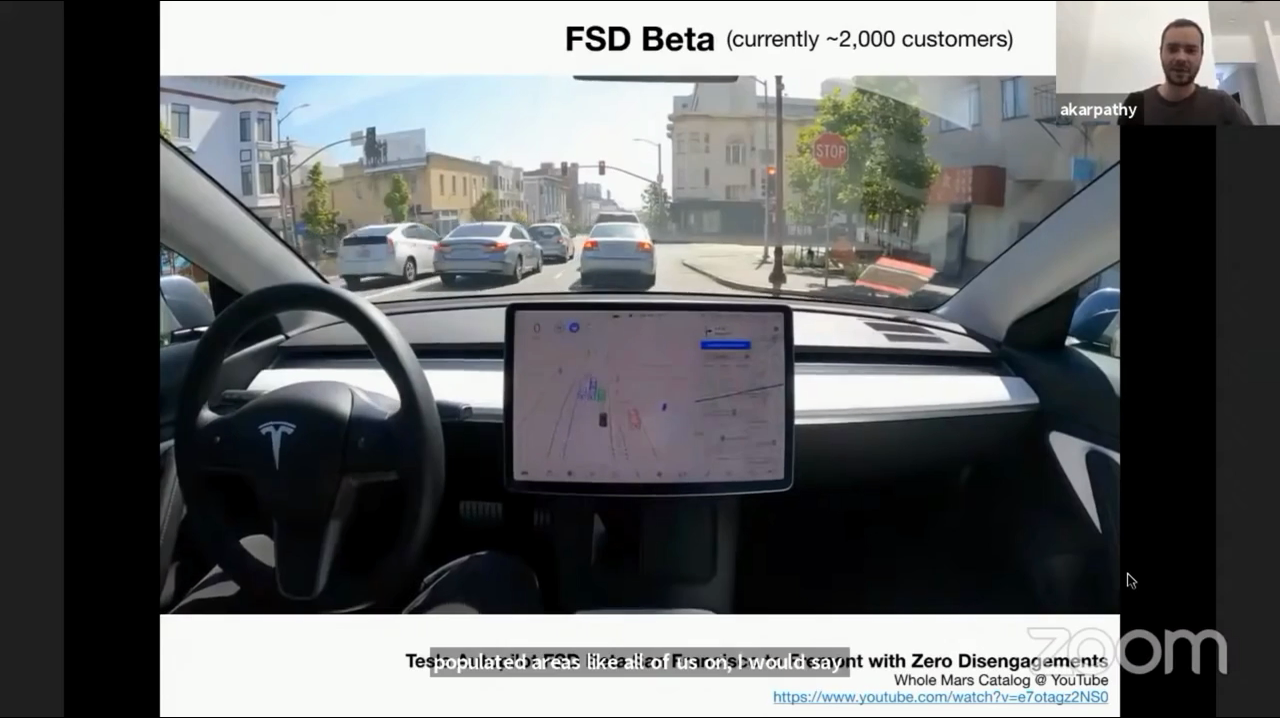
- 2021년 기준 현재 테슬라의 FSD Beta는 약 2,000명의 고객에게 임시로 Full Self-Driving 을 제공하고 있으며 인식 성능은 Display를 통하여 확인할 수 있습니다.
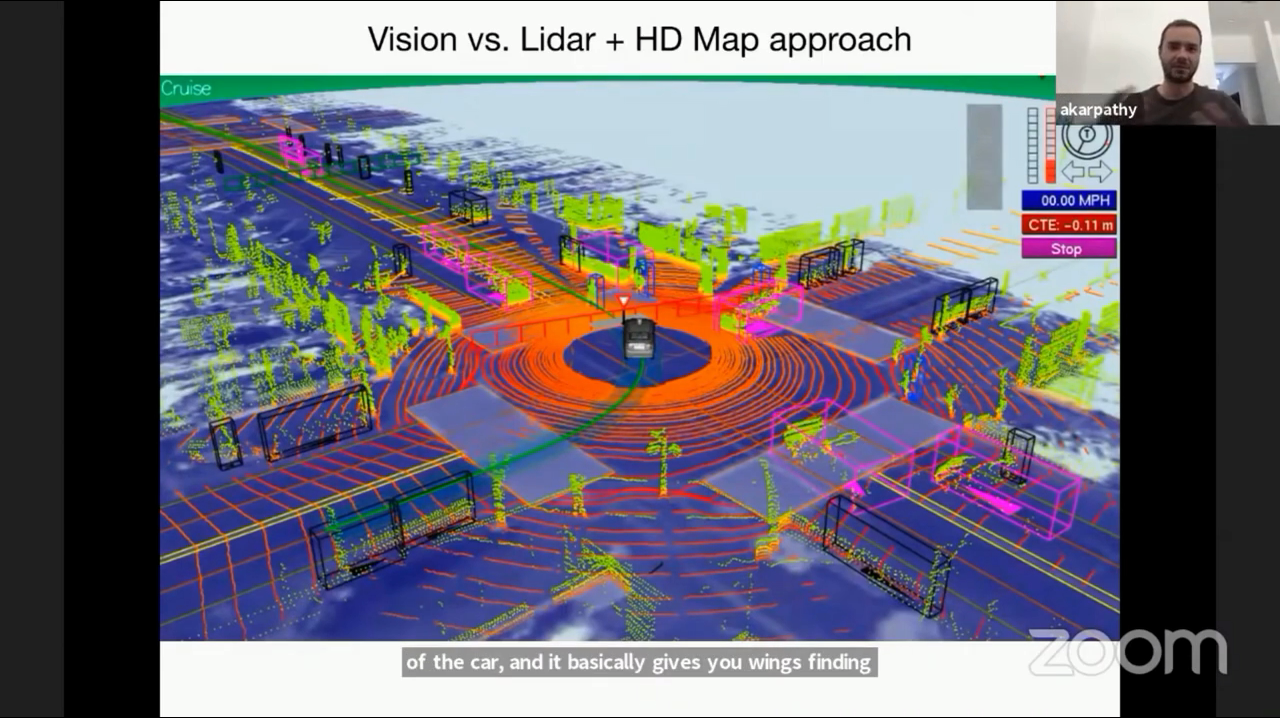
- 테슬라와 같은 기능은 테슬라 뿐 아니라 웨이모와 같은 다른 회사에서도 만들어 서비스를 하고 있지만 주변 상황을 인식하는 데 많은 차이점이 있습니다.
- 위 그림은 웨이모와 같은 회사에서 주변 상황을 인식하기 위한 센서를 종합한 것입니다. 즉, Vision 뿐 아니라 Lidar와 HD Map 까지 사용하고 있습니다.
- 라이다는 현재 상대적으로 가격이 비싸며 차량 360도 주변의 거리 검색을 하여 포인트 클라우드를 생성합니다. 이 때, 라이다 센서로 주의 환경을 미리 매핑을 해야 하는 전제 조건이 있습니다. 즉, 고해상도 지도(HD Map)를 만들어야 합니다. HD Map에서는 주변 인프라의 위치, 교통 신호, 차선 등도 포함하고 있습니다. 이렇게 고비용으로 만든 HD Map을 이용하여 자차의 위치를 추정하고 주행을 하는 것이 웨이모의 방식입니다.
- 하지만 테슬라는 라이다, HD Map 모두를 사용하지 않고 단순히 Vision만 사용합니다. 즉, 기존에 알고 있는 도로를 가는 것이 아니라 매번 새로운 도로를 가는 것으로 비유할 수 있습니다. (물론 학습 데이터에 사용된 도로에 갈 수도 있습니다. 하지만 HD Map 처럼 정보를 가지고 있지는 않습니다.)
- 테슬라에서 이와 같은 Vision 기반의 방식을 이용하려는 이유는 전 세계 곳곳에 서비스를 제공하기 위함입니다. 전 세계의 HD Map을 만들고 유지 보수하는 것은 굉장히 많은 비용이 발생하여 현실성이 없기 떄문입니다.
- 물론 딥러닝 기반의 Vision 시스템을 이용하여 HD Map 없이 이 문제를 해결하는 것은 굉장히 어렵습니다. 하지만 이 문제를 테슬라에서는 Vision 시스템으로 해결하고자 하였습니다. 만약 Vision 시스템으로 이 문제를 해결하면 어느 지역에서는 일반화 시킬 수 있기 때문입니다.
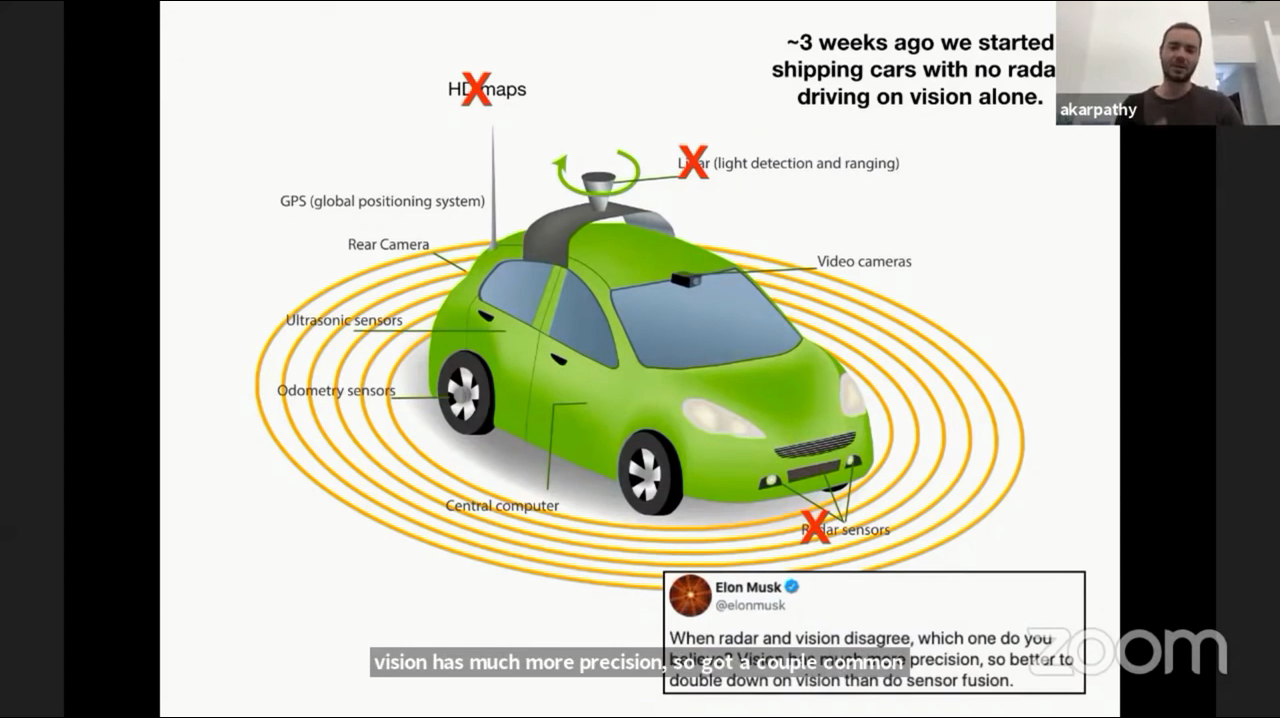
- 위 그림은 테슬라에서 사용하는 센서 현황입니다. 라이다, 레이더, HD Map은 없으며
카메라,초음파 센서,오도메터리 센서,GPS입니다. 주요 센서는카메라라고 말할 수 있습니다. - 기존에 사용하던 레이더도 이제 삭제되어 양산되고 있습니다. 테슬라 내부적으로 검토하였을 떄, 카메라의 인식이 오히려 레이더 보다 더 낫다고 판단하고 있으며 카메라와 레이더의 판단이 서로 다를 때, 카메라의 결과를 믿고 쓰고 있다고 합니다. 따라서 redundancy로 사용 하는 레이더를 삭제하고 그 리소스를 카메라를 이용한 Vision에 더 주는 것이 낫다고 판단하였습니다.

- 테슬라는 현재 8개의 카메라를 사용하고 있으며, 각각 전방 3개, 측방 2개, 후측방 2개, 후방 1개의 영역을 살피고 있고 각각의 카메라 영상을 뉴럴넷을 통하여 물체의 범위 및 깊이를 예측하고 있습니다.
- 사실 인간이 시각만을 이용하여 굉장히 정확하게 파악하지는 못하지만 주변 모든 물체의 깊이와 속도를 이해하면서 운전하고 있습니다. 뉴럴넷도 이와 비슷하게 동작할 수 있습니다. 심지어 사람의 느낌적으로 느끼는 거리보다는 더 정량적으로 우수하게 인식할 수 있습니다.
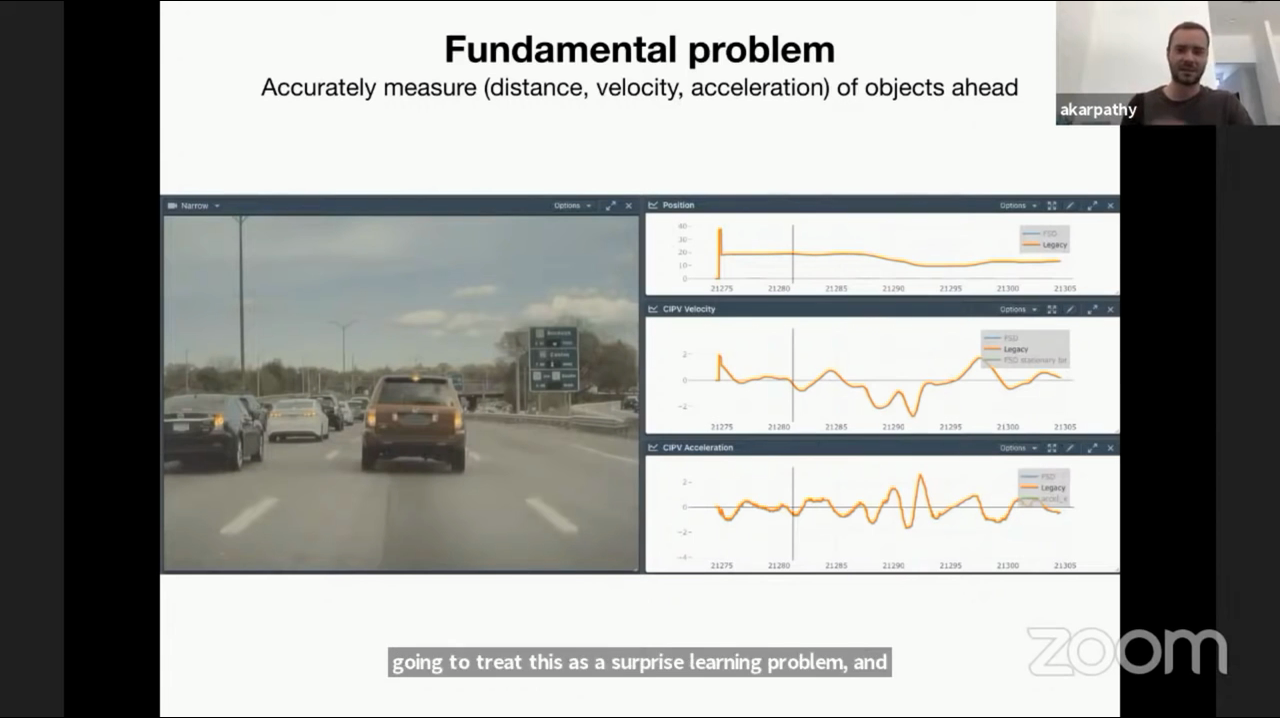
- 위 그림에서는
레이더가 인지한 앞의 차량의 거리, 속도, 가속도를 나타냅니다. 레이더는 위 그림과 같이 인식하고자 하는 물체의 거리, 속도, 가속도를 계산하는 데 좋은 성능을 가집니다. - 하지만 레이더는 때때로 오인식이나 노이즈를 발생시킵니다. 예를 들어 전방에 다리가 있는 상황에서 다리를 차로 인식하여 정차한 차로 오인식 하는 경우가 발생하곤 합니다.
- 이와 같은 상황에서 영상에서 인식한 거리, 속도 등의 정보와 레이더의 정보를 센서 퓨전하는 데 어려움이 있습니다.
- 다행이도 대량의 데이터로 학습한 영상 기반의 뉴럴넷에서 인식한 거리와 속도가 레이더에서 인식한 것과 유사한 수준에서 확인할 수 있었습니다. 따라서 레이더 없이 영상 기반으로 거리, 속도를 인식할 수 있었습니다. 여기서 핵심은
데이터 수집입니다.

- 뉴럴넷이 잘 동작하기 위해서는
Large,Clean,Diverse조건을 만족해야 합니다. - 먼저
Large즉, 수백만개의 데이터 비디오가 필요합니다. 일단 어느 정도 양을 충족해야 합니다. - 그 다음으로
Clean즉, 각 데이터는 질이 좋게 라벨링이 되어야 하며 물체를 인식할 때 필요한 depth, velocity, acceleration 등이 포함됭야 합니다. - 마지막으로
Diverse즉, 일반적인 상황의 데이터가 아니라 예외적인 상황까지 포함된 데이터이어야 합니다.
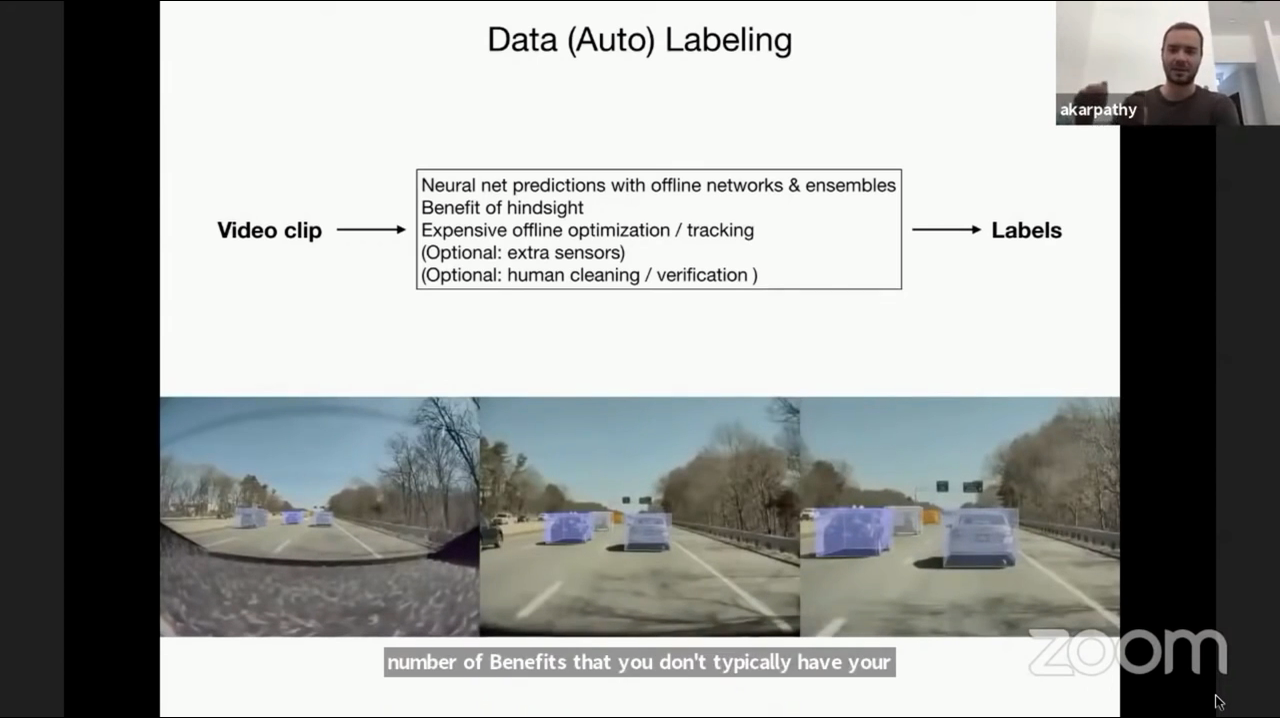
- 모든 데이터를 수작업으로 맡기면 이 작업 또한 굉장히 많은 비용일 발생합니다. 따라서 데이터 수집의 자동화를 위하여 Data Auto Labelling 즉, 데이터를 자동으로 라벨링 하는 작업을 진행하였습니다.
- 모든 Frame을 실시간으로 처리하는 방식과는 다르게 별도의 뉴럴넷이 동작하고 있으며 이 뉴럴넷의 예측을 통하여 데이터 라벨링을 부분적으로 자동화 할 수 있습니다. 이 때 사용되는 뉴럴넷은 실시간으로 동작할 필요가 없으므로 조금 더 신중하게 작업을 하도록 할 수 있도록 수행 속도는 느리지만 고성능의 뉴럴넷 모델을 사용할 수 있습니다. 이와 같이 실시간 인식 성능에 연관된 모델과 별도로 고객 차량에서 별도로 Data Auto Labelling을 위한 작업을 수행하는 데 이를
쉐도우 모드라고 합니다. - 물론 이 모든 작업이 완전 자동화는 아니며 작업자가 Auto Labelling된 데이터를 정리 및 검수를 해야합니다. 하지만 이 과정을 통하여 라벨링 작업을 자동화는 할 수 있습니다.

- 위 그림에서는 카메라에 물이 튀어서 뿌옇게 보이는 상황을 나타냅니다. 이런 다양한 데이터를 수집하는 데 Data Auto Labelling 시스템은 중요합니다.

- 위 그림에서는 눈이오는 환경에서의 주행 데이터 입니다. 이와 같은 데이터도 일반적이지 않은 데이터의 예시입니다.

- 모든 데이터를 다 수집하면 데이터의 양이 너무 방대해질 뿐 아니라 불필요한 데이터까지 수집될 수 있습니다.
- 따라서 테슬라는 221개의 트리거를 사용하여 위 예시에 해당하는 트리거에 만족할 때, Data Auto Labelling을 수행하고 있습니다.
- 221개의 트리거 중 일부 공개한 위 예시를 보면 어떤 전략을 통하여 데이터를 수집하는 지 알 수 있습니다.
- 좀 더 자세한 설명은 아래 링크를 참조해 주시기 바랍니다.
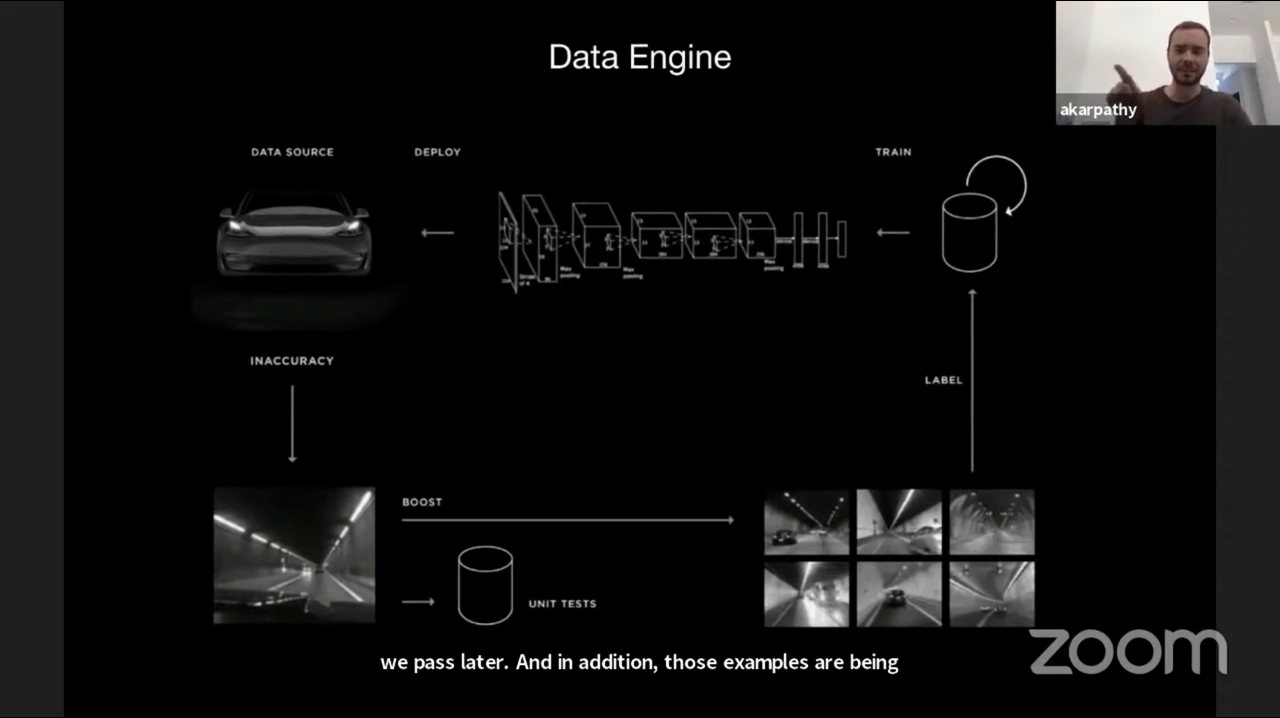
- 앞에서 사용하는 쉐도우 모두의 flow를 정리하면 위 그림과 같습니다. 시작은 오른쪽 상단의 Train 부터 시작합니다.
- ①
Train: 기본적인 기초 데이터로 뉴럴넷을 학습 시킵니다. - ②
Deploy: 고객 차량에서 쉐도우 모드로 사용할 뉴럴넷을 배포시킵니다. - ③ 그 다음 쉐도우 모드에서 뉴럴넷이 예측을 합니다.
- ④
Inaccuracy: 뉴럴넷의 부정확성을 찾아내는 도구가 필요하며 앞에서 설명한 221개의 트리거를 사용하면 네트워크가 잘못 동작하는 시나리오를 확인할 수 있습니다. - ⑤ 이런 시나리오를 자동 라벨링 하게 되고 학습 데이터에 다시 적용하도록 합니다. 그리고 비동기 프로세스로 항상 현재 학습 데이터를 정리하는 작업을 합니다.
- ⑥ 앞의 과정을 계속 반복하면서 뉴럴넷의 성능을 계속 향상시키며 이 과정을 반복합니다.

- 테슬라의 2021 CVPR 발표 이전에 뉴럴넷 배포에 사용한 방법 예시를 보면 다음과 같습니다.
- ① 총 7번의 쉐도우 모드를 실행하였습니다.
- ② 다양한 시나리오의 백만건의 8 카메라-36fps-10초 정도의 비디오를 로깅하였습니다.
- ③ 모든 데이터에 포함된 내용을 살펴보면 60억 건의 object label이 있습니다. (각 object label은 정확한 depth와 velocity 정보를 가집니다.)
- ④ 이 모든 데이터를 합하였을 때, 약 1.5 페타 바이트의 용량을 가집니다. (기존 데이터 + 쉐도우 모드로 자동 라벨링 한 데이터의 총 합이라고 생각됩니다.)
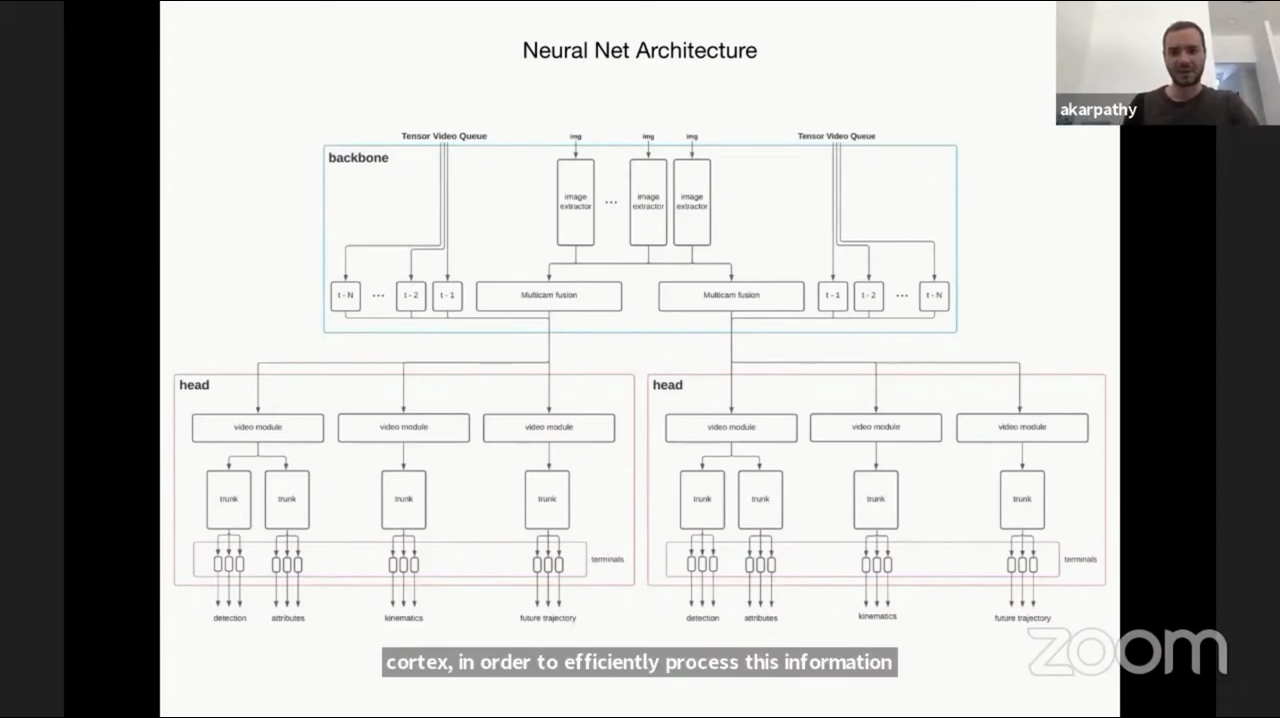
- 1.5 페타 바이트의 거대한 데이터를 위 그림과 같은 뉴럴넷 아키텍쳐에서 학습을 하게 됩니다. 이 때, 대용량의 데이터를 다소 복잡한 네트워크에 학습하려고 한다면 고성능 컴퓨팅 파워가 필요합니다.

- 현재 테슬라에는 슈퍼 컴퓨터를 보유하고 있으며 FLOP 측면에서 세계 5위의 슈퍼 컴퓨터라고 합니다.
- A100 GPU 8개를 가지는 컴퓨터 720개를 묶은 컴퓨터이므로 총 5760개의 GPU를 사용 중입니다. 상세한 하드웨어 스펙은 위 장표를 참조하시기 바랍니다. 이러한 슈퍼 컴퓨터의 지원으로 대용량 데이터로 학습이 가능해졌으며 컴퓨터 비전 기반의 자율 주행 시스템 구축을 하였습니다.
- 또한 학습 시 사용된 gradient를 잘 효율적으로 동기화가 잘 되도록 연구하여 적용하고 있습니다.
- 테슬라의 이러한 슈퍼 컴퓨터 프로젝트를
DOJO라고 하고 있으며 계속 발전되고 있다고 합니다.

- 실제 테슬라에서 사용하는 하드웨어 칩의 사양은 위와 같습니다. 12 CPU와 GPU 그리고 NPU 까지 사용되는 것을 알 수 있습니다.
- Graph Optimization과 Int8 Quantization Aware Training을 적용하여 최적화 하는 것도 확인할 수 있습니다.
- 테슬라는 소프트웨어 뿐 아니라 하드웨어 까지 자체 설계하는 것으로 알려져 있습니다. 즉, 소프트웨어에 적합한 하드웨어 또는 하드웨어에 적합한 소프트웨어를 동시에 고려하여 만들 수 있습니다.
- 그 다음으로 테슬라에서 레이더를 포함한 센서 퓨전의 결과가 비전만을 이용한 결과에 비하여 어떤 문제를 일으켰는 지 예시를 보여줍니다.
- 핵심 내용은 레이더를 사용하지 않게 된 이유라고 보시면 됩니다.
- 앞으로 3가지 예시에서 노란색이 레이더를 사용한 센서 퓨전의 결과이고 파란색이 현재 사용하는 비전만 사용한 결과입니다.

- 위 예시의 그래프는 위에서 부터 차례대로 상대 위치, 속도, 가속도를 뜻합니다.
- 노란색의 그래프는 레이더를 포함한 센서 퓨전한 결과이며 감속이 심하게 발생하며 물체를 추적하는 tracker가 끊김이 발생한 문제가 있었습니다. 위 예시의 센서 퓨전 결과에서는 같은 물체를 6번이 새로운 물체로 판단하게 되었다고 합니다. 반면 파란색 선의 비전에서는 그러한 문제가 발생하지 않았습니다. 파란색 선은 뉴럴넷의 출력 그대로를 표시한 것입니다.
- 물론 레이더의 파라미터를 바꾸어가면서 그 원인을 파악할 수 있지만 그 노력을 오히려 비전 시스템 개선에 두는 것이 더 낫다고 판단하여 레이더는 제거하기로 하였다고 합니다.
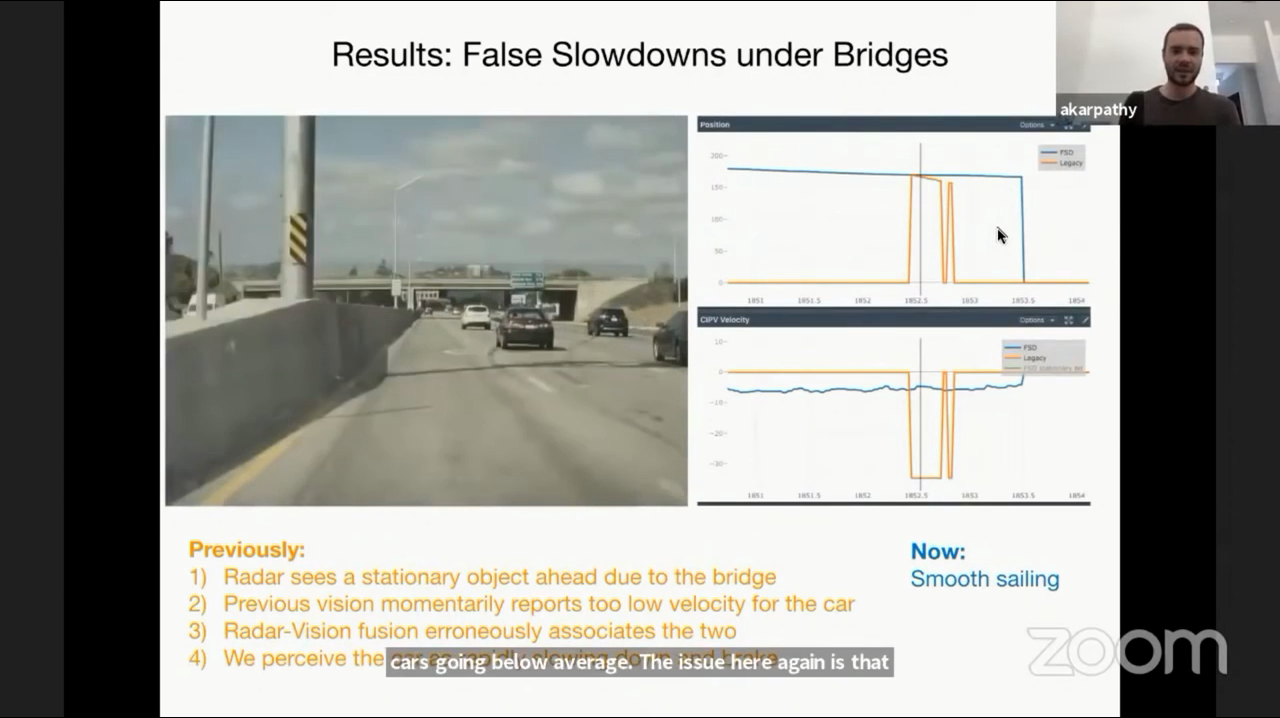
- 또다른 레이더의 문제를 살펴보겠습니다. 레이더는 수직 방향의 해상도가 좁습니다. 따라서 도로 위에 있는 다리를 정지되어 있는 물체로 오인식 하는 경우가 발생한다고 합니다.
- 노란색 선의 상대 속도를 보면 다리를 도로 위의 정지된 물체로 파악하고 급감속을 하는 것을 확인할 수 있습니다. 반면 파란색의 비전 시스템에서는 약간 감속하는 것을 확인할 수 있습니다.
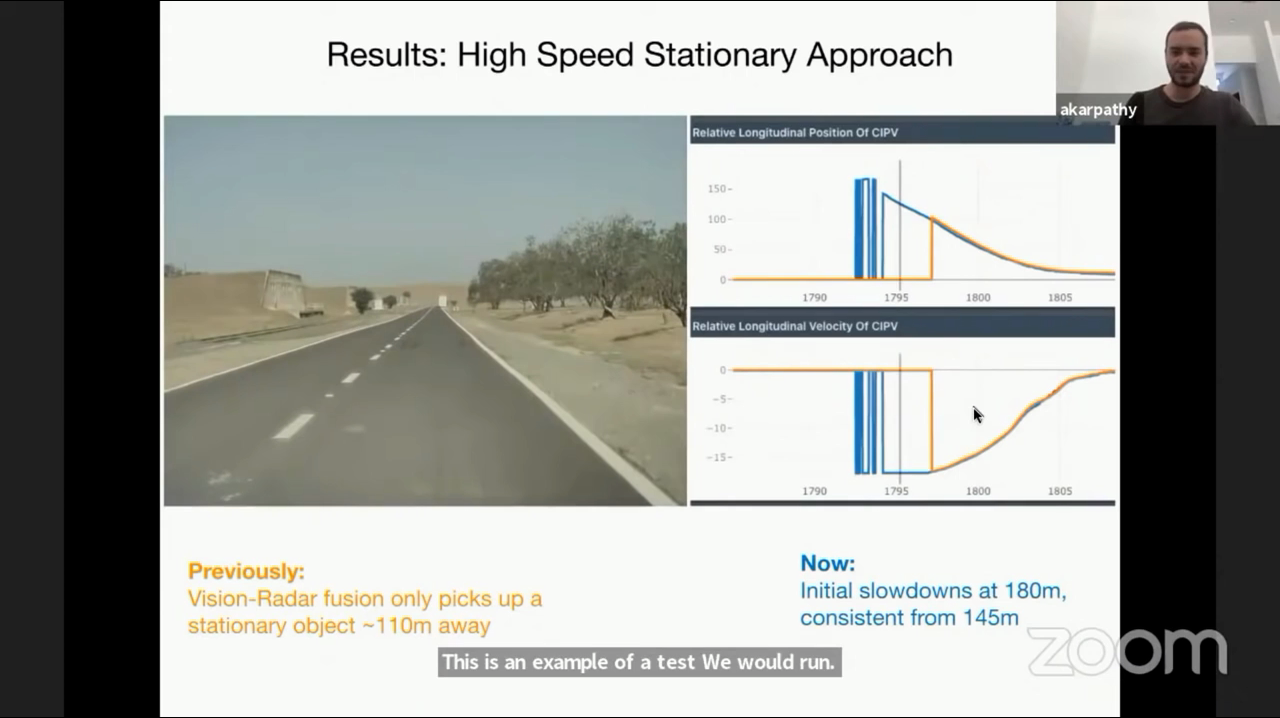
- 마지막 예시는 고속 상황에서의 실제 정차된 차량이 있는 경우입니다.
- 파란색 선의 비전 시스템의 경우 실제 정지된 차량을 일찍 인식하여 이른 시간에 감속해야 함을 확인하였지만 주황색 선의 센서 퓨전의 경우 오히려 늦은 시간에 감속해야 한다고 판단하였습니다. 오히려 비전 시스템을 방해한 경우라고 볼 수 있습니다.

- 현재 테슬라의 검증 및 배포 환경은 위와 같습니다.
- 설명 중 인상적이었던 내용은 레이더를 포함한 센서 퓨전 결과의 배포 시에는 500만 마일 당 사고가 발생한 반면 비전만 사용한 경우 1500만 마일의 주행 중에도 사고가 발생하지 않았다고 합니다.
- 테슬라에서의 발표를 정리하면 비전 시스템 만으로
뎁스 추정이 가능하다고 하며 (왜냐하면 비전은 정보의 대역폭이 넓은 좋은 센서이기 때문입니다.) 이를 위해서는 아래 4가지의 조건이 필요합니다. - ① 뉴럴넷을 학습할 슈퍼 컴퓨터
- ② 대용량의 학습 데이터를 수집할 Fleet 차량
- ③ 대용량의 학습 데이터를 관리한 시스템
- ④ 학습 데이터 수집, 학습 및 배포를 하기 위한 전체 Flow