
포인트 클라우드 처리를 위한 CloudCompare 사용법 정리
2021, Jun 30
- CloudCompare 매뉴얼 : http://www.cloudcompare.org/doc/qCC/CloudCompare%20v2.6.1%20-%20User%20manual.pdf
- 이번 글에서는 라이다 포인트를 읽고 처리하는 툴인
CloudCompare에 대하여 다루어 보도록 하겠습니다. CloudCompare는 코드를 다룰 필요가 없고 단순히 툴을 다루면 되기 때문에 필요한 기능들을 위주로 본 글에서 다루도록 하겠습니다.
목차
설치 방법
- CloudCompare는 아래 링크에서 운영 체제에 맞게 다운 받으면 됩니다.
- 링크 : http://www.danielgm.net/cc/release/
- 윈도우와 macOS의 경우 설치 파일을 받으면 되고 리눅스의 경우 간단하게 명령어로 설치 가능합니다.
snap install cloudcompare
- 오프라인 환경에서는 git에서 source를 받아서 사용하면 됩니다. 단, 아래 명령어를 통하여
recursive로 받아야 필요한 파일을 모두 받을 수 있습니다.- git source : https://github.com/CloudCompare/CloudCompare
git clone --recursive https://github.com/cloudcompare/CloudCompare.git
- git source를 이용하여 설치하는 방법은 repository의
BUILD.md파일에 자세하게 나와있습니다.- https://github.com/CloudCompare/CloudCompare/blob/master/BUILD.md
- git source를 받아서 설치하는 방법은 요약하면 다음과 같습니다. 리눅스 기준으로 설명 드리겠습니다.
- ① 리눅스 패키지 설치 :
sudo apt install libqt5svg5-dev libqt5opengl5-dev qt5-default qttools5-dev qttools5-dev-tools libqt5websockets5-dev - ② git source 다운로드 :
git clone --recursive https://github.com/cloudcompare/CloudCompare.git - ③ cmake configuration :
mkdir build && cd buildcmake ..
- ④ build :
cmake --build .(build 폴더에서 입력) - ⑤ install :
cmake --install .(build 폴더에서 입력)
- ① 리눅스 패키지 설치 :
- 여기까지 에러 없이 정상 동작 하였다면 설치가 완료되었습니다.
build내부의qCC폴더에CloudCompare라는 실행파일이 있습니다. 이 파일을 실행하면 CloudCompare가 실행 됩니다.
입력 파일 형식 및 예제 준비
- 참조 : https://www.cloudcompare.org/doc/wiki/index.php/FILE_I/O
- 위 링크를 보면 CloudCompare에서 사용하는 입력 포맷을 확인할 수 있습니다. 입력 가능한 포맷의 종류는 굉장히 많이 있으며 위 링크에서 포맷을 꼭 참조하시기 바랍니다.

- 링크의 내용을 참조하면 가장 마지막 열에
Features를 통해 필요로 하는 성분을 확인하고 사용하시면 됩니다. - 본 글에서는
ASCII타입을 사용하도록 하겠습니다.ASCII타입은 용량을 제외하면 큰 단점이 없고 좌표 정보 이외에Normals, colors (RGB), scalar fields (all)와 같은 다양한 정보를 사용할 수 있고 편집기로 바로 읽고 쓸 수 있어서 편리하다는 장점이 있습니다.scalar fiedls는Intensity, time, confidence, temperature, etc.와 같은 다양한 형태를 지원합니다. - 본 글에서는
X Y Z Red Green Blue에 대한 포인트 클라우드의 정보를 행 별로 저장한 것을 기준으로 글을 작성하겠습니다.ASCII양식은 다음과 같습니다.X Y Z R G B- Ex)
120.32 10.23 56.12 100 100 20 - 단위는 m 이며 소숫점 2자리 까지 반영하여 1cm로 구분가능하도록 정밀도를 구성하였습니다. RGB 각각의 값은 0 ~ 255의 범위를 가집니다. 이와 같이 구성하면 각 포인트에 대하여 위치 정보와 색 정보를 CloudCompare에서 표현할 수 있어서 보기 편합니다.
- 이번 글에서 다룰 ASCII 데이터는 semantic3d 데이터이며 여기 데이터 중 하나를 받아서 전처리를 한 다음에 사용 하도록 하겠습니다.
- semantic3d 사이트에서 받아도 되며 본 글에서 사용하는 샘플 데이터는 다음과 같습니다. 샘플 데이터는 원본 데이터를 아래 순서로 가공하여
X Y Z R G B(ex.120.32 10.23 56.12 100 100 20)- 원본 파일 : https://drive.google.com/file/d/1CGf0nXtjQMkpQx1gigTGMTRfkJhuUKc2/view?usp=sharing
- 가공한 csv 파일 : https://drive.google.com/file/d/19RUlPEMIk04ljTWxNordvvTBeCNGjRbg/view?usp=sharing
import pandas as pd
import numpy as np
def read_points(f):
# reads Semantic3D .txt file f into a pandas dataframe
col_names = ['x', 'y', 'z', 'i', 'r', 'g', 'b']
col_dtype = {'x': np.float32, 'y': np.float32, 'z': np.float32, 'i': np.int32,
'r': np.uint8, 'g': np.uint8, 'b': np.uint8}
return pd.read_csv(f, names=col_names, dtype=col_dtype, delim_whitespace=True)
def read_labels(f):
# reads Semantic3D .labels file f into a pandas dataframe
return pd.read_csv(f, header=None)[0].values
points = read_points('MarketplaceFeldkirch_Station4_rgb_intensity-reduced.txt')
points = points.drop['i']
points = points.round(2)
points.to_csv("cloudcompare_input.csv", index_col = False, sep=',')
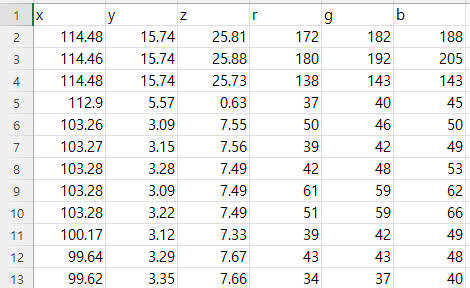
- 원본 파일을 읽어서 코드를 통해 csv 파일로 저장하면 위 형식과 같이 저장됨을 알 수 있습니다. X, Y, Z 값의 단위는 m로 소숫점 2자리 까지 저장되어서 1cm의 해상도를 가질 수 있고 각 포인트 별 RGB 값이 0 ~ 255의 범위로 저장되어 있습니다.
- 이 csv 파일을 CloudCompare에 드래그 & 드랍 또는 파일 열기로 읽어서 실행하면 다음과 같이 파일이 읽어집니다.

- 파일을 읽을 때, 각 값 열의 의미를 선택할 수도 있습니다.
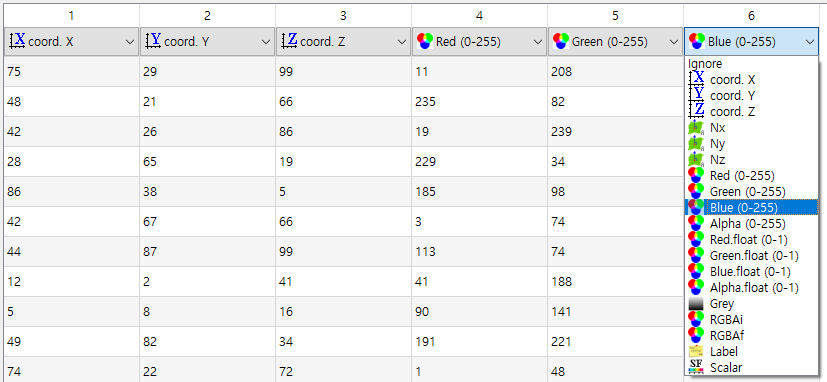
- ASCII 타입의 파일을 읽었을 때, 위 그림과 같이 X, Y, Z외 부가 정보가 있으면 값의 의미를 명시해 줄 수 있습니다.
- 위 예제에서는 RGB 값이기 때문에 차례대로 R, G, B를 선택한 예시입니다.
원점 좌표축 추가
- CloudCompare에서 (0, 0, 0)을 기준으로 좌표축을 그려주는 기능이 별도로 존재하지 않기 때문에, (0, 0, 0)에 임의의 점을 추가하여 좌표축을 이동하는 방법이 가장 쉽고 편리한 방법 중 하나입니다.
- 본 글에서 소개하는 방법은 x, y, z 좌표축을 포인트 클라우드로 만들고 이 포인트 클라우드를 기존 포인트 클라우드와 같이 보는 것입니다.
def get_origin_axis(max_range=1):
'''
- max_range 만큼의 거리 까지 좌표축을 생성하며 포인트의 간격은 cm 단위로 생성됩니다.
- max_range=1이라면 원점으로부터 1m 거리 까지 x, y, z 방향으로 좌표축이 생성됩니다.
'''
num_points = int(max_range * 100)
new_points = []
for i in range(1, num_points):
new_points.append((i/100, 0, 0, 255, 0, 0))
new_points.append((0, i/100, 0, 0, 255, 0))
new_points.append((0, 0, i/100, 0, 0, 255))
new_points.append((0, 0, 0, 255, 255, 255))
origin_axis_df = pd.DataFrame(new_points, columns = ['x', 'y', 'z', 'r', 'g', 'b'])
origin_axis_df.round(2)
return origin_axis_df
origin_axis_df = get_origin_axis(1)
origin_axis_df.to_csv("origin.csv", index=False, sep=',')
- 위 코드를 실행하면 원하는 크기의 좌표축을 생성할 수 있습니다. 생성된 좌표축을 별도로 불러와서 실행해 보겠습니다.
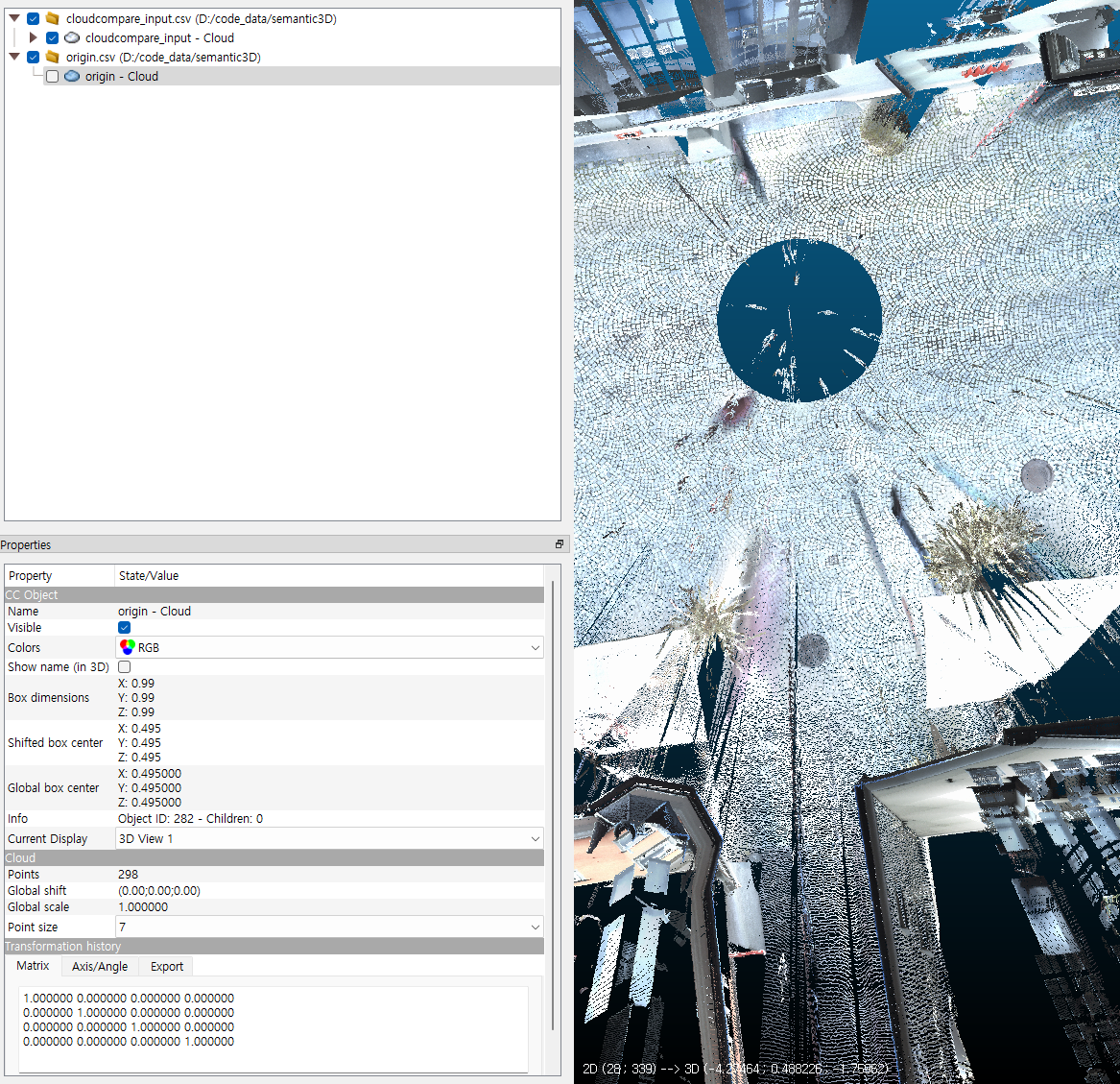
- 기존에 불러온 포인트 클라우드에서는 어디가 (0, 0, 0)인 지 확인하기 어렵습니다. CloudCompare 오른쪽 하단에 X, y, Z에 대한 방향은 표시되어 있지만 원점에 표시되어 있으면 더 보기 편합니다.
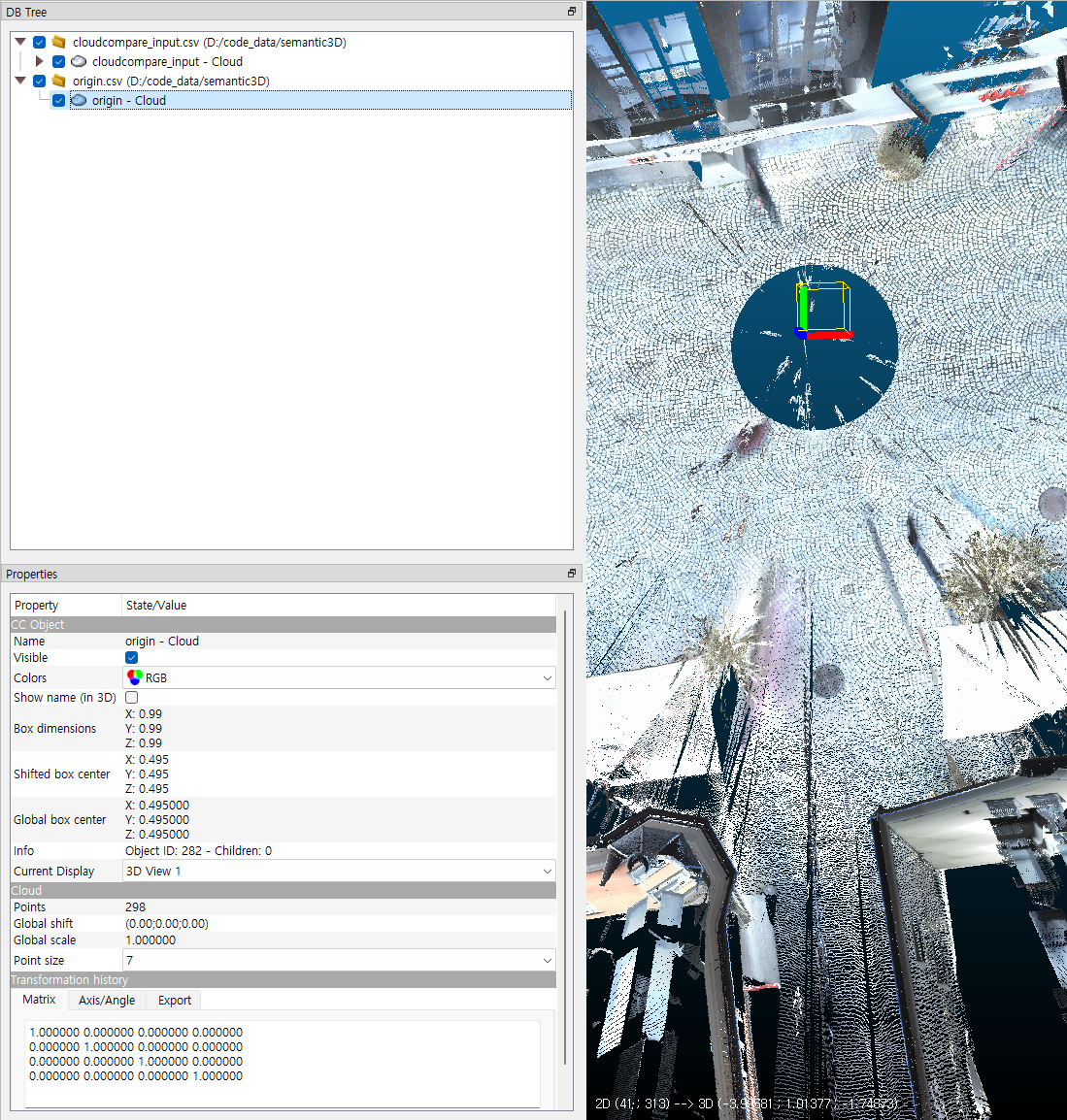
- 위 그림과 같이 원점 (origin.csv)를 불러온 뒤, 체크를 하면 위 그림과 같이 기존 포인트 클라우드와 좌표축 포인트 클라우드를 한번에 볼 수 있습니다.
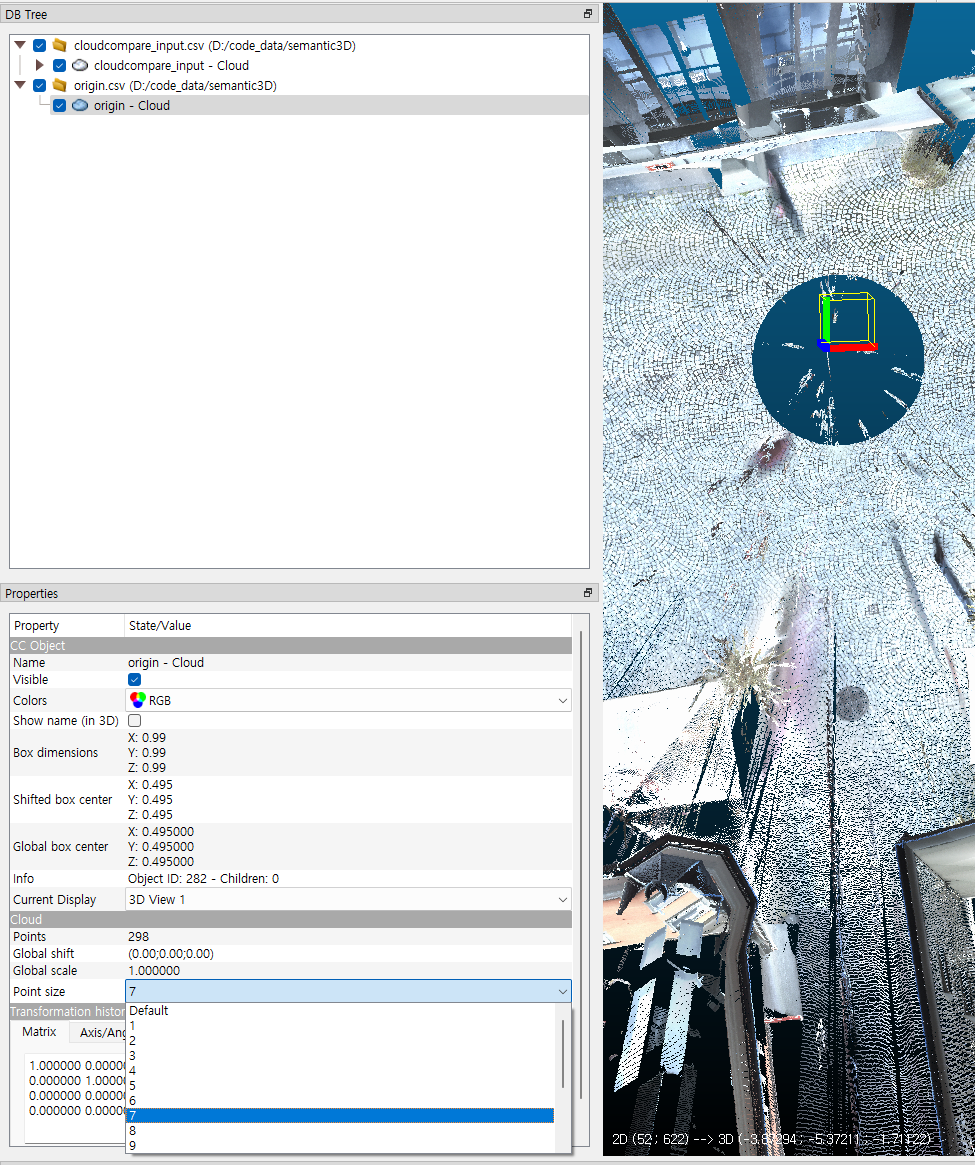
- 두 포인트 클라우드는 별 개 데이터이므로 좌표축 포인트 클라우드의 점 크기를 더 크게 할 수 있습니다. 점의 크기를 크게 하여 좀 더 쉽게 좌표축을 확인할 수 있습니다.