이미지 One Class Classification with Deep features
2019, Feb 11
- 종종 binary classification을 해야 하는 데, class 한개의 데이터만 있고 나머지 데이터는 없는 경우가 있습니다.
- 또는, 한개의 클래스와 그 이외의 클래스로 나뉘어야 하는 경우 그 이외의 클래스의 범주가 너무 많아서 명확하게 데이터를 모으기가 어려운 경우도 있습니다.
- 이런 경우 Class A와 outlier를 분류하는 케이스 입니다.
- 이러한 문제를 풀기 위하여 이번 글에서는
- One Class SVM
- Gaussian Mixture Model
- 두가지 방법에 대하여 알아보고 sklearn 코드에 대하여 살펴보도록 하겠습니다.
- one-class 학습에서는 오직 positive class 데이터 셋에서만 학습을 하고 예측을 합니다.
- 예측을 할 때에도 positive class에 대해서 수행하므로 positive class가 A라면 negative class는 ~A가 됩니다.
- 학습을 할 때 데이터의 차원이 점점 더 늘어날수록 문제의 난이도도 올라가게 됩니다.
- 특히 이미지와 같이 고차원 데이터의 경우 feature의 수가 급증하게 됩니다.
- 224 x 224 사이즈의 이미지에서는 50,176개의 feature가 있습니다.
- 학습을 하기 위해서는 효율적인 feature representation 방법이 필요하여
deep learning을 이용하도록 하겠습니다.
- 따라서 이번 글에서는 one-class learning using deep neural net features에 대하여 다루겠습니다.
- 그리고 deep neural net을 통하여 얻은 features를 이용하여 One class SVM, Isolation Forest, Gaussian Mixture에 적용해 보고 성능을 비교해 보겠습니다.
CNN을 이용한 Feature Extractors
- CNN을 이용하면 의미있는 feature extraction 이 가능하고 특히 Pre-trained ImageNet을 사용하면 충분히 성능이 좋은 feature를 얻을 수 있습니다.
- 저희가 사용해볼 모델은 ResNet-50입니다. ResNet 50은 다소 가볍지만(?) 성능이 좋은 모델입니다.
One Class SVM과 Isolation Forest 모델을 이용한 구현
- 먼저 Imagedata set을 이용하여 학습한 ResNet-50 feature를 계산합니다.
from keras.applications.resnet50 import ResNet50
def extract_resnet(X):
# X : images numpy array
resnet_model = ResNet50(input_shape=(image_h, image_w, 3),
weights='imagenet', include_top=False)
# Since top layer is the fc layer used for predictions
features_array = resnet_model.predict(X)
return features_array
- 모든 이미지 데이터 셋에서 ResNet feature를 계산할 수 있습니다.
- 그 다음 계산을 하여 얻은 feature에
standard scaler를 적용합니다. - PCA를 적용합니다. 이 때
n_components=512로 해보겠습니다. -
PCA 적용 한 후 남은 feature를
One Class SVM또는Isolation Forest에 전달합니다. - 아래 코드를 보면 X_train과 X_test는 train과 test 이미지의 ResNet feature 입니다.
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
from sklearn.ensemble import IsolationForest
from sklearn import svm
# Apply standard scaler to output from resnet50
ss = StandardScaler()
ss.fit(X_train)
X_train = ss.transform(X_train)
X_test = ss.transform(X_test)
# Take PCA to reduce feature space dimensionality
pca = PCA(n_components=512, whiten=True)
pca = pca.fit(X_train)
print('Explained variance percentage = %0.2f' % sum(pca.explained_variance_ratio_))
X_train = pca.transform(X_train)
X_test = pca.transform(X_test)
# Train classifier and obtain predictions for OC-SVM
oc_svm_clf = svm.OneClassSVM(gamma=0.001, kernel='rbf', nu=0.08) # Obtained using grid search
if_clf = IsolationForest(contamination=0.08, max_features=1.0, max_samples=1.0, n_estimators=40) # Obtained using grid search
oc_svm_clf.fit(X_train)
if_clf.fit(X_train)
oc_svm_preds = oc_svm_clf.predict(X_test)
if_preds = if_clf.predict(X_test)
# Further compute accuracy, precision and recall for the two predictions sets obtained
- One-Class SVM 또는 Isolation Forest 모두 -1 또는 1 값을 반환합니다.
- 1 인 경우는 One Class에 해당합니다. Positive
- -1인 경우는 One Class에 해당하지 않습니다. Negative
Gaussian Mixture와 Isotonoic Regression을 사용한 One Class Classification
- 음식 사진들이 주어졌을 때 음식 사진들은 다양한 음식의 cluster에 속할 수 있습니다.
- 어떤 음식 사진은 동시에 여러개의 cluster에 속할 수도 있습니다.
- 결과적으로 이런 경우에
Gaussian mixture를 Positive class data points(ResNet Feature)에 학습시킬 수 있습니다.Gaussian mixture는 확률 모델 종류 중의 하나로 전체 모수 내에서 normal distribution을 가지는 부분 모집단을 표현하는 모델입니다.Gaussian Mixture Model은 데이터에 의해 학습이 되면 새로운 데이터가 입력 되었을 때 이 데이터가 현재 학습된 데이터의 분포에서 부터 생성될 수 있는지의 확률을 만들어 냅니다.
- Gaussian mixture model은 주어진 sample의 log of probability density function 값을 반환합니다.
- 이 값은 실제 probability와는 다르므로
probability scores로 변경하는 작업이 필요합니다. probability score는 새로운 sample이 gaussian 분포와 얼만큼 가까운지에 대한 신뢰도 점수를 나타냅니다.
- 이 값은 실제 probability와는 다르므로
probability score를 얻기 위해서는isotonic regression방법을 사용하면 됩니다.
# The standard scaler and PCA part remain same. Just that we will also require a validation set to fit
# isotonic regressor on the probability density scores returned by GMM
# Also assuming that resnet feature generation is done
from sklearn.mixture import GaussianMixture
from sklearn.isotonic import IsotonicRegression
gmm_clf = GaussianMixture(covariance_type='spherical', n_components=18, max_iter=int(1e7)) # Obtained via grid search
gmm_clf.fit(X_train)
log_probs_val = gmm_clf.score_samples(X_val)
isotonic_regressor = IsotonicRegression(out_of_bounds='clip')
isotonic_regressor.fit(log_probs_val, y_val) # y_val is for labels 0 - not food 1 - food (validation set)
# Obtaining results on the test set
log_probs_test = gmm_clf.score_samples(X_test)
test_probabilities = isotonic_regressor.predict(log_probs_test)
test_predictions = [1 if prob >= 0.5 else 0 for prob in test_probabilities]
# Calculate accuracy metrics
평가 결과
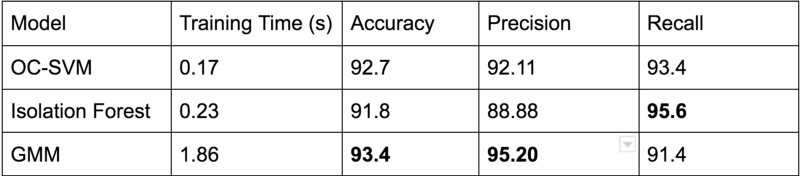
- food 이미지와 ~food image를 이용하여 평가해본 결과 성능 측면에서는 GMM이 가장 좋았습니다.
- one class 좋은 성능을 만들기 위해서는 positive / negative 샘플에 대하여 모두 학습하여 모델을 좀 더 강성하게 만들 수 있습니다.
- One class SVM의 경우 오직 Positive class에 대해서만 학습이 되어있습니다.
- GMM은 one-class SVM에 비하여 Negative 데이터 분포에 대하여 좀 더 명확하게 예측이 가능해 집니다.
- 즉, false positive 오류가 one-class SVM에 비하여 줄어듭니다.