Active Learning과 Learning Loss와 Bayesian Deep Learning을 이용한 Active Learning
2021, Jan 07
목차
-
Active Learning 이란
-
classification 문제를 통한 Active Learning의 Uncertainty
-
Learning Loss for Active Learning
-
Deep Bayesian Active Learning with Image Data
Active Learning 이란
Active Learning은 딥러닝의 한계 중 라벨링의 데이터 확보와 관련 있는 분야 입니다.- 딥러닝의 성능은 상당 부분 데이터의 질과 양에 달려 있습니다. 이러한 사실은 최근 연구 결과에서도 찾아볼 수 있으며,수십 억 개의 데이터를 활용해 학습된 신경망을
Transfer Learning형태로 재학습 시키는 경우 그 성능이 데이터에 비례하여 개선된다는 점이 밝혀지고 있습니다. - 특히, 일정 품질의 데이터양이 많으면 많을수록 성능이 개선될 여지가 있습니다. 따라서 데이터 기반의 딥러닝은 일정 수준의 데이터를 확보하는 것이 문제 해결과 직결됩니다.
- 하지만 데이터를 확보한다는 것은 결국 비용으로 이어집니다. 이미지에서 객체 인식하는 문제를 예로 들면 이를 위한 이미지 데이터 확보는 이미지에 있는 객체가 무엇인지 라벨링해야하는 것과 같습니다. 이미지에 라벨을 부여하는 작업은 기본적으로 사람이 정성적으로 처리해야 하는 문제이므로 비용과 직결됩니다.
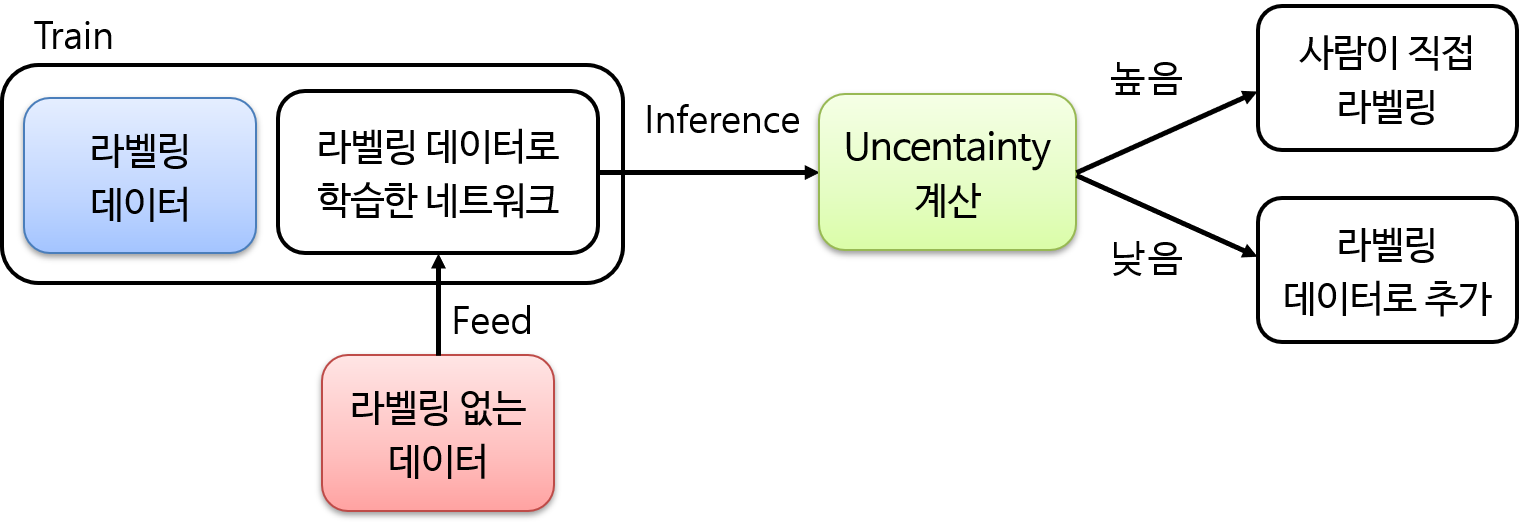
- 따라서 Active Learning은 이러한 문제를 해결하기 위해 라벨이 주어지지 않은 데이터를 이용하여 어떤 데이터는 자동으로 라벨을 붙일 수 있고 어떤 데이터는 사람이 꼭 라벨링을 해야 하는 지 필터를 해주는 방법이라고 말할 수 있습니다.
- 그러면
Semi-supervised learning과Active Learning에 대하여 헷갈릴 수 있습니다. - 역할은 비슷하나 관점이 다르다고 볼 수 있습니다.Semi-supervised learning은 라벨링 되지 않은 데이터를 기존의 라벨링된 데이터를 이용하여 어떻게 라벨링 할 수 있을까 라는 관점으로 문제를 바라보는 것입니다. 반면에 Active learning은 라벨링 되지 않은 데이터에서 사람이 반드시 라벨링 해야 하는 데이터는 무엇일까 라는 관점으로 문제를 바라봅니다.
- 결국 라벨링 되지 않은 데이터를 어떻게 처리해야 하는 같은 문제에서 그 방향이 다르다고 말할 수 있습니다.
classification 문제를 통한 Active Learning의 Uncertainty
- 특정 임무를 해결하기 위해 어느 정도 학습된 뉴럴 네트워크가 있다고 가정해 보겠습니다.
- 이 경우 많은 데이터가 라벨이 붙어져 있지 않은 상태라면 해당 데이터는 이미 학습된 네트워크를 통해 예측 값을 얻을 수 있습니다.
- 문제를 간단하게 정의하기 위해서 이미지 classification 문제를 가정해 보도록 하겠습니다.
- classification 문제에서 대부분의 예측 값은 0과 1사이의 확률값인데, 만약 올바른 예측을 했다면 특정 분류의 확률이 높을 것입니다.
- 이렇게 특정 class의 확률이 높은 데이터들은 대부분 예측 값과 실제 값이 동일할 가능성이 높습니다.
- Active Learning은 일정 기준 이상의 예측 확률값에 대해서는 라벨을 자동으로 붙입니다. 문제는 예측이 애매모호한 상태, 즉 불확실성(Uncertainty) 이 높은 데이터에서 발생합니다. 예를 들어 네 가지 과일 사진을 분류하는 문제가 주어질 경우 특정 과일 사진의 확률 값이 각각 0.25로 동일하다면 이는 학습된 인공신경망이 주어진 사진을 제대로 분류하지 못한다고 생각할 수 있습니다. 이런 문제를 불확실성이라고 볼 수 있는데 불확실성이 높은 데이터의 경우는 따로 걸러 내야 합니다. 즉. Active Learning은 불확실성이 높은 데이터를 어떻게 선별해 낼 것 인가에 달려있습니다.

- 위 그래프와 같이 uncertainty가 낮을 때, classification 문제에서는 그 inference 결과를 바로 라벨링으로 사용할 수도 있습니다. 왜냐하면 라벨링 결과가 그 이미지의 클래스만 정해주면 되기 때문입니다. 하지만 box 위치를 regression하는 object detection 같은 문제에서는 바로 접목하기는 어렵습니다. (이 문제는 뒤에서 더 다루어 보겠습니다.)
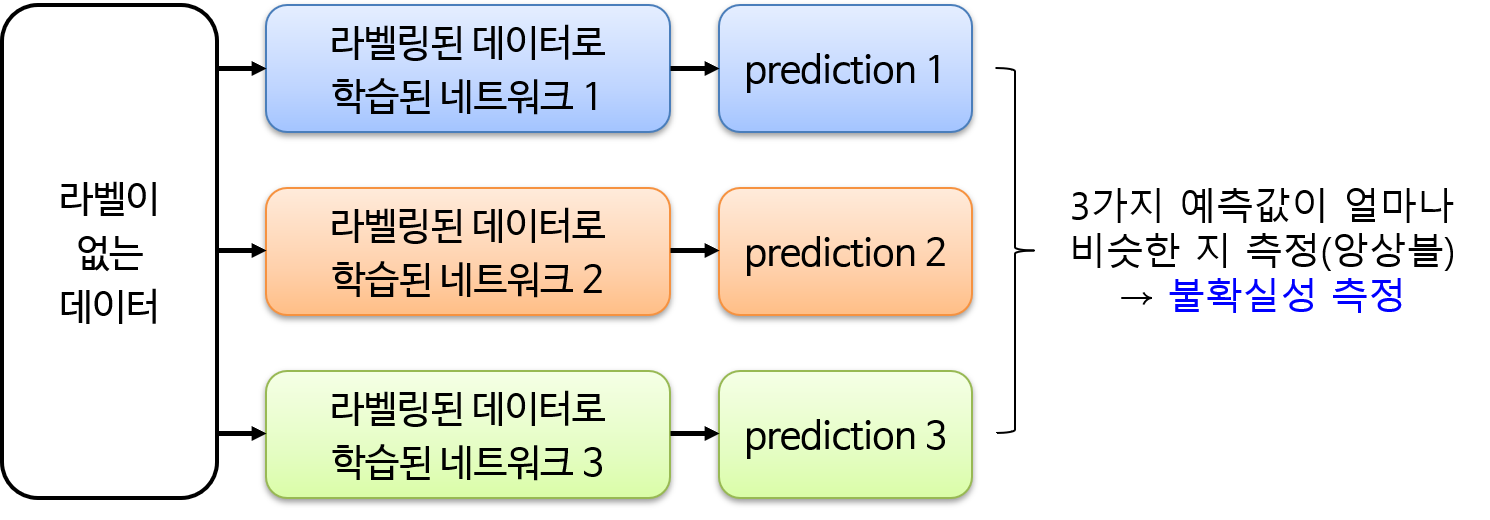
- uncertainty를 계산하기 위해 몇 가지 집근 방식을 취할 수 있는데 가장 먼저 다양한 네트워크를 활용하는 방법이 있습니다. 예를 들어 위 그림과 같이 같은 데이터에 대해서 서로 다른 네트워크의 예측이 동일 하다면 해당 데이터는 불확실성이 낮은 것이고. 그 반대의 경우는 불확실성이 높은 것으로 볼 수 있다.
- 이미지를 이용한 대표적인 딥러닝 Task에는 Classification, Object Detection, Segmentation, Depth regression 등이 있습니다.
- 이러한 각각의 Task에 맞춤형인 Active Learning 알고리즘도 있는 반면 Task에 무관하게 적용할 수 있는 Active Learning 방법들도 있습니다.
Learning Loss for Active Learning
- 작성 예정
Deep Bayesian Active Learning with Image Data
- 작성 예정