
Bag of Tricks for Image Classification with Convolutional Neural Networks
2020, Jan 01
- 논문 : https://arxiv.org/abs/1812.01187
- 참조 : https://www.youtube.com/watch?v=D-baIgejA4M&list=WL&index=34&t=0s
- 참조 : https://www.youtube.com/watch?v=2yxsg_aMxz0
- 참조 : https://hoya012.github.io/blog/Bag-of-Tricks-for-Image-Classification-with-Convolutional-Neural-Networks-Review/
목차
-
Base line
-
Linear scaling learning rate
-
Learning rate warm-up
-
Zero Gamma in BatchNorm
-
No bias decay
-
Low-precision training
-
Cosine Learning Rate Decay
- 19년도 CVPR에 발표된 Bag of Tricks 논문 입니다. 개인적으로 이런 논문은 너무 좋습니다. 블로그에서 핵심 내용만 뽑아준 것 같은 느낌이 들기 때문입니다.
- 이 논문은 네트워크 구조를 고치지 않고 ResNet-50을 기준으로 Trick 들만 적용하여 Accuracy와 학습속도를 높인 방법론을 정리한 내용을 다룹니다.
- 한번 쯤 들어본 내용들을 정리해서 다루었기 때문에 내용이 크게 어렵지 않을 것이라 생각 됩니다.
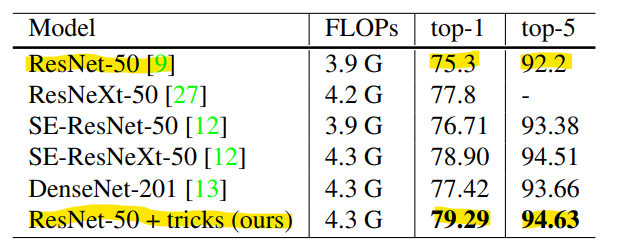
- Trick을 모두 적용하였을 때, 위 성능 지표와 같이 성능을 향상할 수 있었습니다.
- 먼저 논문에서 사용한 다양한 전처리 등은 생략하도록 하겠습니다. 자세한 내용은 논문 또는 위의 참조 링크를 참조하시기 바랍니다.
- 이 글에서 자세히 다루어 볼 것은 classification 문제 이외에도 충분히 사용할 만한
Trick내용만 작성하였습니다.
Base line
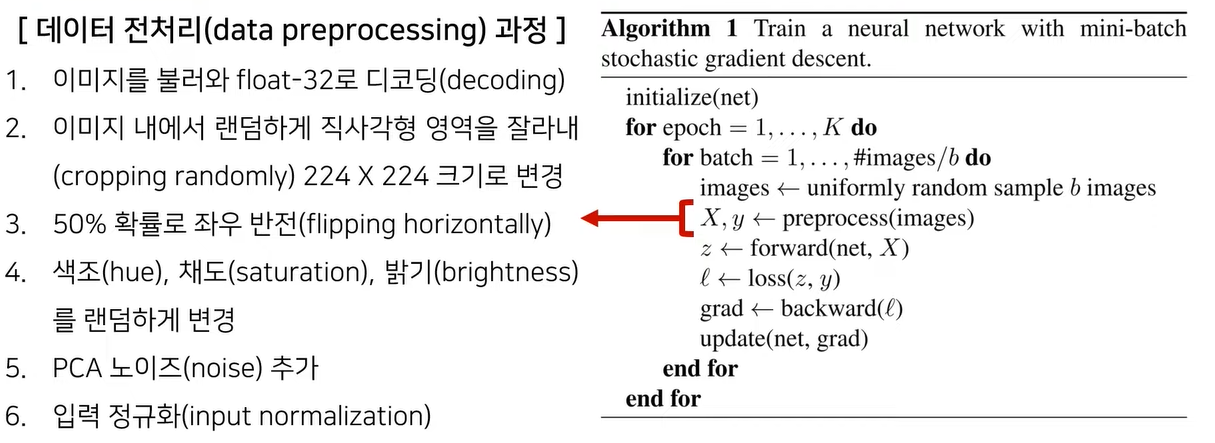
- 논문에서 사용된 기본적인 학습 절차 (base line)은 위 알고리즘을 따릅니다.
Linear scaling learning rate
- batch size가 증가하게 되면 병렬성이 좋아지고 인/아웃 횟수가 줄어 오버헤드가 줄어드는 장점이 있는 반면 학습이 수렴하는 시간이 느려지는 단점이 있습니다. 따라서 batch size가 작은 학습 방법과 batch size가 큰 학습 방법의 accuracy 결과를 비교하면 batch size를 작게하여 학습하는 경우 더 좋은 성능을 얻는 것을 확인할 수 있습니다.
- 하지만 batch size를 증가시키지 못하면 전체 학습 시간이 너무 오래 걸리므로 이 문제를 개선하기 위하여 연구가 진행되어 왔습니다.
- Accurate, large minibatch SGD: training imagenet in 1 hour 논문에서는 batch size가 증가하게 되면, 그 만큼 linear 하게 learning rate를 증가시켜주는 것이 학습하는 데 좋다는 내용을 소개합니다.
- 추천하는 방식으로는
initial learning rate' ← initial learning rate * batch size / 256입니다. 예를 들어 초기 learning rate가 0.1이고 batch size가 1024이면0.1 * 1024 / 256 = 0.4로 초기 learning rate를 적용해야 함을 의미합니다. 이 방식을 통해 batch size가 커져서 성능이 떨어지는 문제를 개선할 수 있다고 설명합니다.
Learning rate warm-up
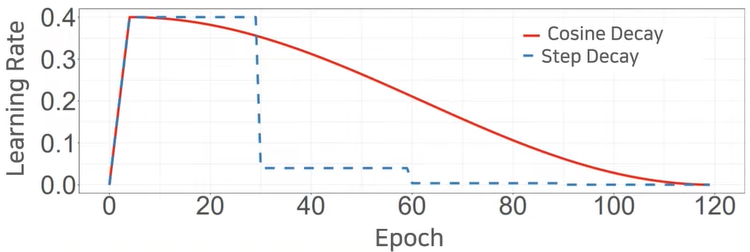
- 다음으로
Learning rate warm-up과 관련된 내용입니다. 보통 learning rate는 초기 설정한 값 (initial learning rate)을 기준으로 학습이 진행될수록 계속 줄여주는 방식을 많이 사용하고 있습니다. - 기존 방법과는 조금 다르게 초기에 learning rate를 0으로 설정하고 이를 일정 기간 동한 linear 하게 키워주는 방식을 learning rate warmup 방식으로 소개합니다.
- 이와 같이
warm-up과정을 거치는 이유는 학습을 처음에 시작할 때 random한 weight 값을 가지고 시작하게 되는데 이러한 random weight값을 이용하여 학습을 시작하면 학습이 안정화 되는데 불리하다는 점을 개선하기 위함입니다. - 위 그래프에서는 5 epoch 동안 조금씩 learning rate를 키워서 initial learning rate 값을 5 epoch에 0.4까지 도달하게 만든 후 점점 learning rate가 줄어들도록 변경하였습니다.
- 위 방법은 이 글의 뒷부분에 제시된
Cosine Learning Rate Decay부분과 혼합하여 사용할 수 있으며 그 코드는 다음 링크를 참조하시기 바랍니다.
Zero Gamma in BatchNorm
- 먼저 Batch Normalization에 대한 글을 읽고 오시길 추천 드립니다.
- Batch Normalization을 사용하면 대표적으로 다음과 같은 장점이 있습니다.
- ① 학습 속도를 빠르게 할 수 있습니다.
- ② weight initialization에 대한 민감도를 감소 시킬 수 있습니다.
- ③ regularization 효과가 있습니다.
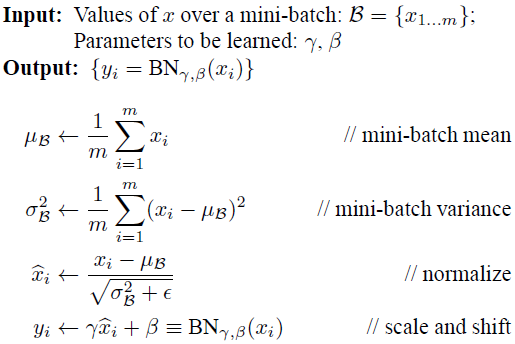
- Batch Normalization을 적용할 때, 위 식과 같이 \(\gamma, \beta\)가 사용되며 학습하면서 결정되는 파라미터입니다. 이 값은
scale과shift를 변경해주는 값으로 입력 차원이 \(k\)이면 두 파라미터의 차원도 \(k\)를 가집니다. - 두 파라미터를 사용하는 이유 중의 하나로 Batch Normalization로 인한 activation function의 non-linearity 영향력 감소 문제를 개선하기 위함이 있습니다.
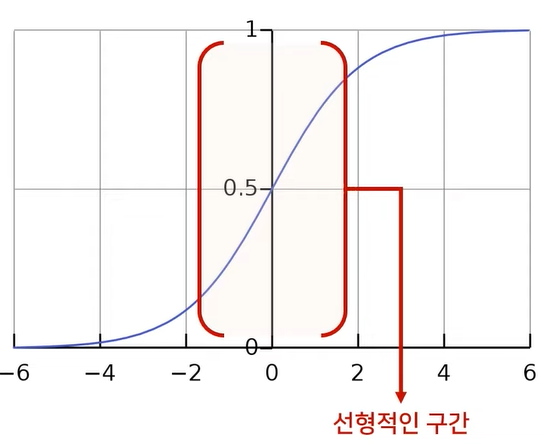
- 예를 들면 위 그림과 같은 시그모이드 함수를 activation function으로 사용하였을 때, Batch Normalization의 결과에 scale과 shift를 적용하지 않으면 위 그림의 빨간색 영역만 그대로 사용할 수 있습니다. 그러면 non-lineariry의 효과가 줄어들게 됩니다. 이 문제를 해결하는 역할로 \(\gamma, \beta\)가 사용됩니다.
- 이 값을 일반적으로 \(\gamma = 0, \beta = 1\)로 초기화 하고 학습을 하는데 이 논문에서는 \(\gamma = 0\)로 초기화 하는 것을 추천합니다.
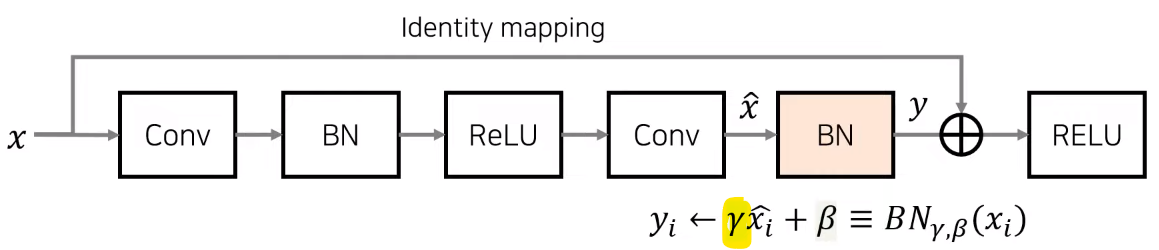
- 만약 \(\gamma = 0\)으로 두면 학습 시작할 때, 위 그림과 같은 ResNet 구조에서 Residual Block 내부의 weight에 0이 곱해지므로 무시하게 됩니다. 따라서
Identity mapping (Shortcut)으로만 weight가 전달되어Identity mapping만 사용하는 매우 간단한 네트워크를 일시적으로 사용할 수 있습니다. - 이와 같은 방법을 사용하면 학습 시작할 때 네트워크의 구조를 단순화 함으로써 네트워크의 복잡도를 일시적으로 낮출 수 있고, backpropagation을 통해 의미 있는 weight update가 발생하면 그 때 부터 Residual Block 내부가 사용됨과 동시에 원래 설계한 네트워크의 복잡도를 사용할 수 있습니다.
- Pytorch의
BatchNorm2d는 다음 링크에서 사용 방법을 알 수 있습니다. BatchNorm2d함수의 파라미터에 Gamma를 직접 제어하는 파라미터는 없으므로 Gamma에 직접 접근하여 값을 변경해주면 됩니다. 다음과 같습니다.
def SetZeroGammaInBatchNorm2d(bn):
bn.weight.data = torch.zeros(bn.weight.data.shape, requires_grad=True)
return bn
bn = nn.BatchNorm2d(3, affine=True)
print(bn.weight, bn.bias)
# Parameter containing:
# tensor([1., 1., 1.], requires_grad=True)
# tensor([0., 0., 0.], requires_grad=True)
bn = SetZeroGammaInBatchNorm2d(bn)
print(bn.weight, bn.bias)
# Parameter containing:
# tensor([0., 0., 0.], requires_grad=True) ← Changed
# tensor([0., 0., 0.], requires_grad=True)
No bias decay
- 학습을 할 때,
L2 Regularization방법을 통하여 weight의 크기를 줄이는 방법을 많이 사용 합니다. 이 때, weight는weight와bias를 모두 포함하지만 이 논문에서는 오직weight에만 decay를 주는 것을 권장합니다. (이 또한 휴리스틱한 방법으로 접근하였습니다.) bias의 경우 weight에 비해 파라미터 수가 매우 적으므로 Regularization을 해주지 않아도 overfitting에 대한 문제를 방지할 기여도가 적고 반대로 bias가 잘못 적용될 경우 underfitting이 날 가능성이 있으므로 사용하지 않도록 소개하니다.- 참조 논문은 Highly scalable deep learning training system with mixed-precision: Training imagenet in four minutes.입니다.
Low-precision training
- 참조 논문 : https://arxiv.org/abs/1710.03740
- NVIDIA의 GPU를 사용할 때, 기본적으로
FP32 (32-bit Floating Point)를 기본적인 데이터 타입으로 사용하고 있습니다. 하지만FP16을 기본 데이터 타입으로 사용하면 모델이 가벼워져서 학습 시간을 단축할 수 있습니다. V100GPU의 경우FP32를 사용할 때, 14 TFLOPS(Tera Floating Operations per Second)의 연산 속도를 가지는 반면FP16을 사용할 때, 100 TFLOPS의 연산속도를 가지는 것을 확인할 수 있었습니다. 실제 학습을 할 때에도 보통 2 ~ 3배 정도 연산 속도가 빨라지는 것을 경험할 수 있습니다.
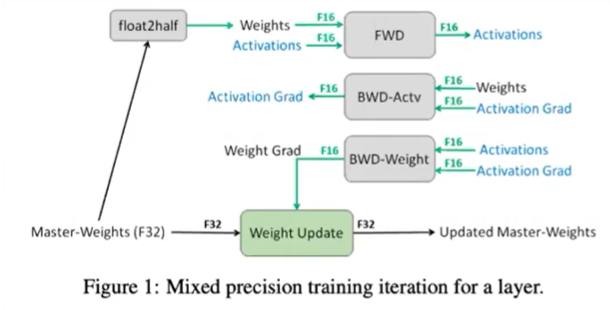
- 하지만 딥러닝에서 사용하는
weight의 경우 매우 작은 값을 가지므로 단순히FP16만을 사용하면 accuracy 성능에 문제가 발생할 수 있습니다. - 따라서 위 그림과 같이
Mixed Precision이라는 방법을 이용하여FP16과FP32를 섞어서 사용하며 이는Pytorch에서AMP(Automatic Mixed Precision)이라는 패키지로 지원합니다. - 위 그림을 보면 Forward, Backward, Activation 등 계산하여
gradient를 구할 때에는FP16을 사용하고optimizer.step()을 이용하여 실제 weight update가 발생할 때에는FP32를 사용하여 저장합니다. 이 때,FP32로 저장되는 weight를master weight라고 합니다. - 이 때,
FP16과FP32값의 범위 차이가 발생하기 때문에,FP16값이FP32값과 같은 precision 범위에서 계산이 될 수 있도록 별도 scaling factor를 따로 저장하고 weight update 시 이 값을 계산 결과인FP16에 곱해주어FP32와 값의 범위가 유사해지도록 만들어 주는 방법을 사용합니다.
Cosine Learning Rate Decay
Cosine Learning Rate Decay의 형태를 살펴보면 아래 그림과 같이 양의 값을 가지는 Cosine 함수 형태를 가집니다.
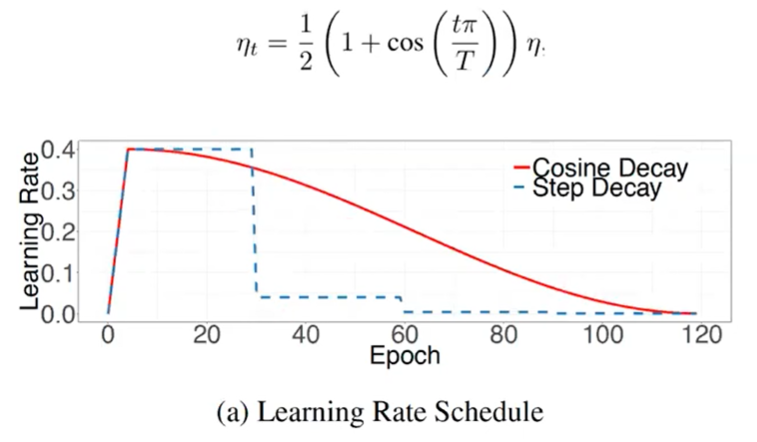
- Cosine값은 처음에 천천히 감소하다가 점점 감소량이 커지고 마지막에 로컬 미니멈에 빠지게 되었을 떄, 다시 천천히 감소하게 되는 형태를 나타냅니다.
- 위 방식을 제안한 논문은
SGDR : Stochastic Gradient Descent with Warm Restarts라는 논문으로 Cosine Learning Rate 스케줄러를 계속 반복시키면서 학습하여 로컬 미니멈에 빠졌을 때, 빠져나올 수 있도록 스케쥴러를 설계하였습니다. - 또한 앞에서 다룬
Learning rate warm-up과 함께Cosine형태의 Learning rate 스케쥴러를 사용하는 방법을 제시하였습니다.
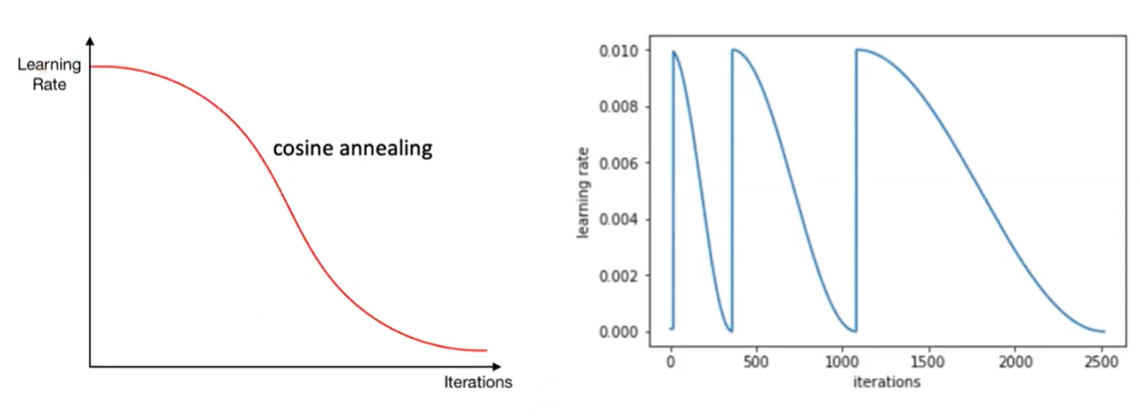
- 위 그림과 같이
SGDR또는 이 논문을 참조한 다른 논문에서는restart는 하지 않고warm-up+cosine scheduler만 사용하는 경우도 많이 있었습니다. Pytorch에서SGDR과 같이Warm-up+Cosine+Restart를 모두 사용한 코드를 확인하고 싶으시면 아래 링크를 참조해 주시기 바랍니다.
- 이 이외에도 ResNet-50의 최적화 방법, Knowledge distillation 및 Data Augmentation 방법이 있습니다. 다루지 않는 내용은 논문을 참조해 보시기 바랍니다.