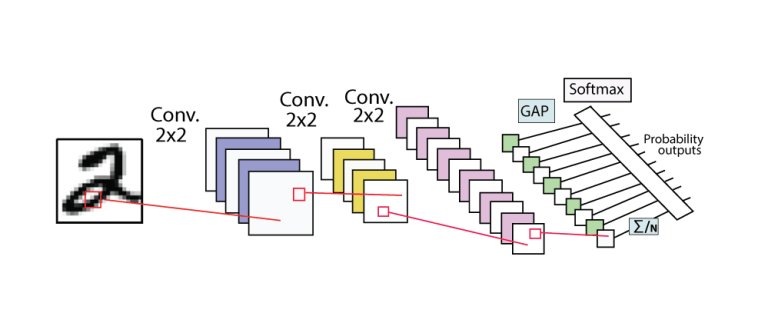
Global Average Pooling 이란
2019, Dec 01
- 참조 : https://kevinthegrey.tistory.com/142
- 참조 : https://blog.naver.com/nywoo19/221930484253
- 참조 : https://discuss.pytorch.org/t/global-average-pooling-in-pytorch/6721/11
- Covolution Neural Network를 만들 때, Convolution 레이어와 Pooling을 사용합니다.
- 이번 글에서는 Pooling 중의 Global Average Pooling에 대하여 다루어 보려고 합니다.
Pooling의 역할
- 먼저 Pooling이 무엇인지 알아보기 전에 Pooling의 필요성에 대하여 알아보도록 하겠습니다.
- CNN에는 많은 convolution layer를 쌓기 때문에 필터의 수가 많습니다. 필터가 많다는 것은 그만큼 feature map들이 쌓이게 된다는 뜻입니다. 즉, CNN의 차원이 매우 크다는 뜻입니다.
- 높은 차원을 다루려면 그 차원을 다룰 수 있는 많은수의 파라미터들을 필요로 합니다. 하지만 파라미터가 너무 많아지면 학습 시 over fitting이 발생할 수 있는 문제가 발생하곤 합니다. 따라서 필터에 사용된 파라미터 수를 줄여서 차원을 감소시킬 방법이 필요합니다.
- 이런 역할을 CNN에서 해 주는 레이어가
poolinglayer 입니다.
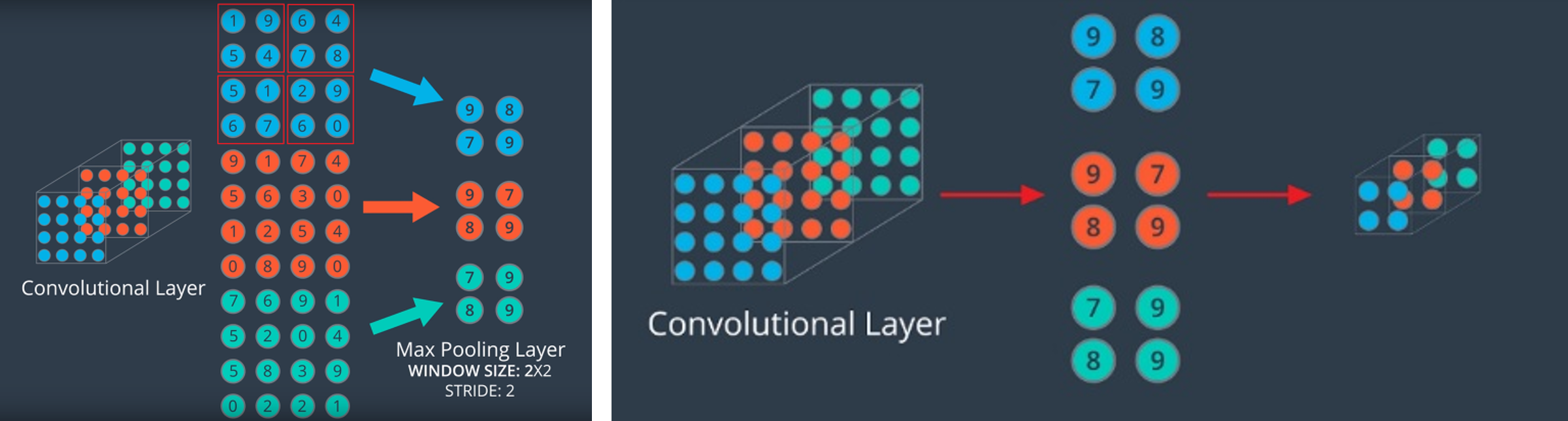
- 먼저 Pooling 중 가장 많이 사용되는 Max Pooling을 이용하여 Pooling을 방법에 대하여 설명해 보겠습니다.
- 위 그림의 왼쪽을 보면 Max Pooling의 경우 빨간색 박스 안에서 가장 큰 값이 선택 되어 새로운 feature를 형성합니다.
- 빨간색 박스가 Pooling을 하는 영역이 됩니다. 박스의 height, width 각각이 2이기 때문에 사이즈는 2이고 박스의 이동 거리가 2이기 때문에 stride 도 2입니다. (빨간색 박스의 꼭지점이 이동된 거리가 2인것을 참조하시면 됩니다.)
- Max pooling 처럼 가장 큰 값을 선택하는 이유는 ① 가장 큰 feature 값이 계산 시 가장 큰 영향을 주기 때문에 출력 값에 영향이 가장 크고 ② feature 즉, 특징을 가장 잘 나타내기 떄문입니다.
- 위 그림 예시와 같이 (2, 2) 영역을 보고 stride = 2의 Max Pooling을 한다면 feature의 크기는 반으로 줄어들면서 각 박스 영역의 최댓값만 선택되게 됩니다.
- 최댓값을 취하지 않고 평균 값을 취하는 방법도 있습니다. 이 경우를 Average Pooling 이라고 합니다. 이 방법은 feature의 모든 값들을 이용하면서 (평균) 하면서 feature의 크기를 줄여 차원을 감소시킵니다.
Global Average Pooling
- GAP(global average pooling)은 앞에서 설명한 Max(Average) Pooling 보다 더 급격하게 feature의 수를 줄입니다.
- 하지만 GAP의 목적은 앞에서 사용한 Pooling과 조금 다릅니다. GAP의 목적은 feature를 1차원 벡터로 만들기 위함입니다.
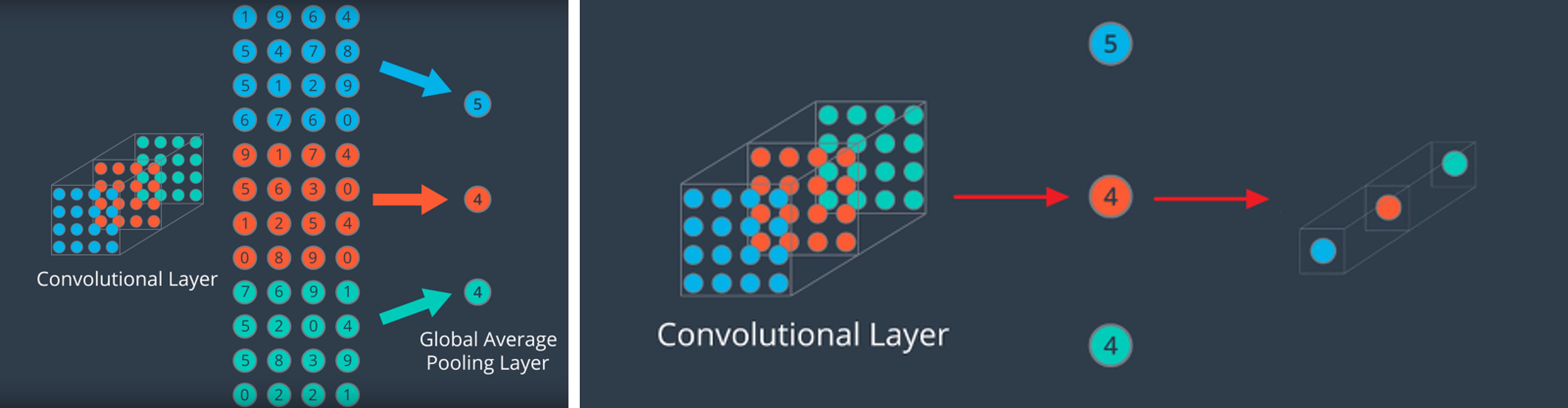
- 위 그림을 보면 같은 채널 (같은 색)의 feature들을 모두 평균을 낸 다음에 채널의 갯수(색의 갯수) 만큼의 원소를 가지는 벡터로 만듭니다.
- 이런 방식으로 GAP는 (height, width, channel) 형태의 feature를 (channel,) 형태로 간단하게 만들어 버립니다.
- 그러면 이렇게 극단적인 벡터 형태로 나타내는 GAP는 왜 고안되었을까요?
- GAP는 CNN + FC(Fully Connected) Layer에서 classifier인 FC Layer를 없애기 위한 방법으로 도입되었습니다.
- FC Layer는 마지막 feature와 matrix 곱을 하여 feature 전체를 연산의 대상으로 삼아서 결과를 출력합니다. 즉, feature가 이미지 전체를 함축하고 있다고 가정하면 이미지 전체를 보고 출력을 만들어 내는 것입니다.
- 하지만 FC layer를 classifier로 사용하는 경우 파라미터의 수가 많이 증가하는 단점이 있으며 feature 전체를 matrix 연산하기 때문에 위치에 대한 정보도 사라지게 됩니다. 더구나 FC Layer 사용 시 반드시 지정해 주어야 하는 FC layer의 사이즈로 인해 입력 이미지 사이즈 또한 그에 맞춰서 고정되어야 하는 단점이 있습니다.
- 반면 GAP는 어떤 크기의 feature 라도 같은 채널의 값들을 하나의 평균 값으로 대체하기 때문에 벡터가 됩니다. 따라서 어떤 사이즈의 입력이 들어와도 상관이 없습니다. 또한 단순히 (H, W, C) → (1, 1, C) 크기로 줄어드는 연산이므로 파라미터가 추가되지 않으므로 학습 측면에서도 유리합니다. 또한 파라미터의 갯수가 FC Layer 만큼 폭발적으로 증가하지 않아서 over fitting 측면에서도 유리합니다.
- 따라서 GAP 연산 결과 1차원 벡터가 되기 때문에 최종 출력에 FC Layer 대신 사용할 수 있습니다.
- 경우에 따라서 FC layer와 같이 사용 되기도 합니다. FC layer에 전달하기 전에 GAP를 이용하여 차원을 줄여서 벡터로 만든 다음에 FC layer로 전달 하면 FC Layer에서 쉽게 사이즈를 맞출 수 있기 때문입니다.
Pytorch 구현 방법
- pytorch를 이용하여 Global Average Pooling을 구현하는 방법은 크게 3가지가 있으며 아래 코드를 참조하시면 됩니다.
- average pooling 관련 함수를 사용하여도 되고 단순히 feature를 reshape한 다음에
torch.mean함수를 이용하여도 됩니다.
import torch
import torch.nn.functional as F
x = torch.randn((256, 96, 128, 128)).cuda()
F.avg_pool2d(x, x.size()[2:])
F.adaptive_avg_pool2d(x, (1, 1))
torch.mean(x.view(x.size(0), x.size(1), -1), dim=2)