경량 딥러닝 기술 동향(ETRI)
2020, Jan 03
- 출처 : https://ettrends.etri.re.kr
- 이 글을 경량 딥러닝 기술 동향에 대한 ETRI의 글 중에 필요한 내용만 발췌한 글입니다. 내용이 참 좋으니 전문을 읽어보시는 것 또한 추천드립니다.
경량 딥러닝의 필요성
- 경량 디바이스, 모바일 디바이스 및 다양한 센서와 같은 디바이스에서 직접 학습과 추론을 하려면 기존의 PC 레벨의 성능과 GPU를 사용하기에는 무리가 있습니다.
- 따라서 기존의 학습된 모델의 정확도를 유지하면서 보다 크기가 작고, 연산을 간소화하는 경량 딥러닝이 필수적입니다.
- 경량 딥러닝 기술은 크게 적은 연산과 효율적인 구조로 설계하여 효율을 극대화 시키는 방법과 모델의 파라미터를 줄이는 방법을 적용한 모델 압축 방법등으로 나눌 수 있습니다.
경량 딥러닝 관련
- CNN계열의 모델에서 주로 학습 시 가장 큰 연상량을 필요로 하는 합성곱 연산을 줄이기 위하여 효율적인 합성곱 필터 방법들이 연구가 되고 일반화 되었습니다.
- 주로 다루어졌던 것이 기본 단일 층 별 연산에 그치지 않고 연산량과 파라미터의 수를 줄이기 위한
Residual Block또는Bottleneck Block과 같은 형태를 반복적으로 쌓아 신경망을 구성하는 방법입니다. - 또는 기존 신경망의 모델 구조를 인간이 찾지 않고 모델 구조를 자동 탐색하여 모델을 자동화하거나 연산량 대비 모델 압축 비율을 조정하는 등 자동 탐색 기술등도 연구되었습니다.
- 이는 모바일 딥러닝과 같은 다양한 기기의 성능 대비 추론 속도가 중요한 어플리케이션을 위해 정확도, 지연시간, 전력량 등을 고려하여 강화 학습을 사용하여 경량 모델을 탐색하는 방법입니다.
- 또한 모델이 가지는 파라미터의 크기를 줄이는 방법도 다양하게 연구되어 왔습니다.
- 일반적으로 크기가 큰 딥러닝 모델은 파라미터가 과하게 많습니다. 어떤 파라미터의 값의 크기가 작을 경우 모델의 정확도에 큰 영향을 미치지 못하므로 무시하는 방법을 취하기도 하는 데 이것을
pruning이라고 합니다. - 즉 파라미터의 값에 0을 대입하여 모델이 작은 가중치에 대하여 내성이 생기도록 하는데 파라미터 (weight)에 가지치기를 하므로
weight pruning이라고도 합니다. - 또한 일반적인 모델의 가중치는 부동 소수점을 가지지만 이를 특정 비트수로 줄이는
Quantization을 통해 기존 딥러닝의 표현력은 유지하면서 실제 모델의 저장 크기는 줄이는 방법이 있습니다.Quantization: 부동 소수점을 특정 비트(e.g. 8bit)로 구간을 나누어서 표현하는 방법으로 부동 소수점 대비 그 크기를 줄일 수 있습니다.
- 더 나아가 0과 1로 파라미터 값을 표현하여 표현력은 많이 줄지만 정확도와 손실을 어느 정도 유지하면서 모델 저장 크기를 확연히 줄이는
Binarization에 대한 기법도 연구되었습니다. - 따라서 경량 딥러닝은 딥러닝 모델의 구조적 한계를 극복하고자 하는 경량 딥러닝 알고리즘과 기존 모델의 효율적인 사용을 위한 알고리즘 경량화 두 축으로 연구가 진행중입니다.
모델 구조 변경 기술
- CNN 알고리즘 초기에는 convolution 연산 이후 다운 샘플링을 통해 통과하는 격자의 크기를 줄여 연산량과 변수가 많아 학습되지 않는 문제를 해결하고자 하였습니다.
- 점차적으로 필터의 크기가 줄어들면서 1x1 필터의 사용이 중요해지게 되었고 더 나아가 필터 축소 이외에 서로 다른 필터를
병렬로 연결하는 인셉션 모듈을 통하여 다양한 형태로 발전하게 되었습니다. - 필터를 병렬로 연결하는 것이 더 발전하여
ResNet과 같이 두 개의 연속적인 합성곱 층에 단위행렬의 추가를 위한 지름길을 더해 줌으로써 가중치들이 더 쉽게 최적화될 수 있는Residual Block형태로 개선되었으며, 이것을 기반으로Bottleneck Architecture또는Dense Block형태로 발전되었습니다.
ResNet
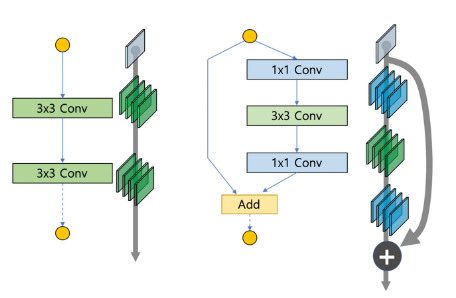
- 위 그림과 같이 레어의 수가 늘어날수록 점차 정확도가 저하되는 문제가 발생하는데 shortcut을 통해 파라미터 없이 바로 연결되는 구조로 바꾸고, 연산량 관점에서 덧셈이 추가되는 형태로 문제를 단순화 할 수 있었습니다.
- 이 시점 이후에 Residual Block을 사용하는 다양한 네트워크가 생기게 되었고 깊은 신경망에서도 최적화가 가능해졌고 정확도의 개선 효과도 있었습니다.
DenseNet
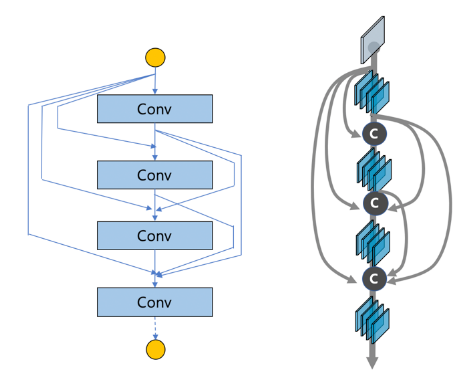
- 기존 신경망 모델 구조의 여러 장점을 모아서 DenseNet이 소개 되었습니다. DenseNet에서는 기존 Feature map에 덧셈 연산을 통해 합치는 것이 아니라 concat 해서 쌓아가는 과정을 통해 성능을 높이고자 하였습니다.
- 또한 이전에는 가장 마지막 레이어에서 추출한 정보를 이용하여 문제를 해결하였는데 (e.g. classification) DenseNet에서는 이전의 모든 층에서의 정보를 취득하는 형태가 가능하게 되었습니다. 이를 통해, 기존의 다른 네트워크보다 좁게 설계가 가능해 지고 파라미터의 수를 줄일 수 있게 되었습니다.
- 위 그림을 보면 기존에는 전 후 레이어 간의 연결 또는 Skip Connection 에 의한 연결만 존재하였지만 DenseNet에서는 다양한 연결이 접목되어 있음을 알 수 있습니다.
SqueezeNet
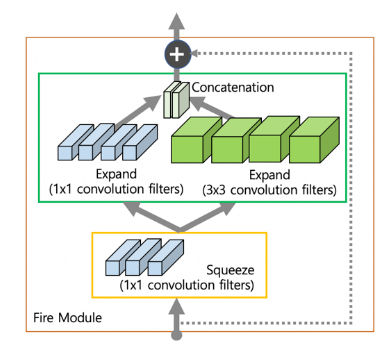
- 스퀴즈넷은 기본적으로 사용하는 3 x 3 convolution 필터를 1 x 1 필터로 대체하여 9배 적은 파라미터를 가지고 1 x 1 convolution 연산을 통하여 채널 수를 줄였다가 다시 늘리는
Fire Module기법을 제안하였습니다. - 또한 다운 샘플링 하는 시점을 레이어 뒤에서 (늦게) 적용하여 한번에 필터가 볼 수 있는 영역을 좁히면서 해당 이미지의 정보를 압축시키는 효과를 볼 수 있게 하였습니다.
- 위에서 모델 구조 변경 기술의 방법을 이용하여 성능을 개선한
ResNet,DenseNet,SqueezeNet을 살펴보았습니다. - 그러면 다음으로 효율적인 합성곱 필터 기술에 대하여 살펴보도록 하겠습니다.
효율적인 합성곱 필터 기술
- 모델 구조를 변경하는 다양한 경량 딥러닝 기법은 점차 채널을 분리하여 학습시키면서 연산량과 변수의 갯수를 줄일 수 있는 연구로 확장되었습니다.
- 일반적인 합성곱은 채널 방향으로 모두 연산을 수행하여 하나의 feature를 추출하는 반면, 채널 별로 (Depthwise)로 합성곱을 수행하고, 다시 점 별(Pointwise)로 연산을 나누어 전체 파라미터를 줄이는 것과 같이 다양한 합성곱 필터를 설계하기 시작하였습니다.
- 이후에는 점 별 그룹 형태로 섞는 셔플 방법 또한 고안 되었습니다.
MobileNet
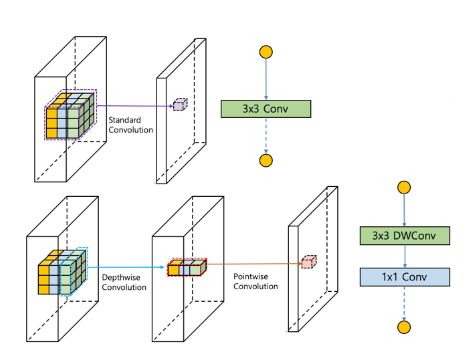
- 기존의 합성곱 필터를 채널 단위로 먼저 convolution 연산을 하고, 그 결과를 하나의 픽셀에 대하여 합성곱 연산하는 것으로 나눔으로써 3 x 3 필터 기준으로 약 8 ~ 9배의 연산량 감소 효과를 얻을 수 있었습니다.
ShuffleNet
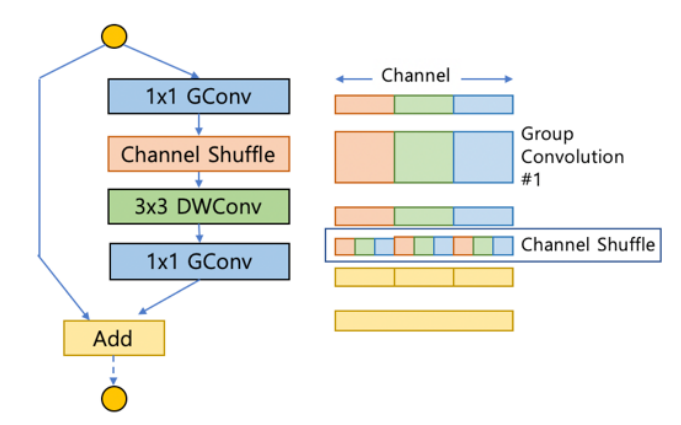
ShuffleNet에서는 바로 앞의 MobilenNet에서 사용된 Depthwise Convolution과 Pointwise Convolution이 그대로 사용됩니다.- 단 추가적으로 사용되는 것은, Pointwise Convolution 연산 시, 특정 영역의 채널에 대해서만 연산을 취하는 형태로 설계하면 연산량을 줄일 수 있을것으로 판단하여 인풋의 각 그룹이 잘 섞일 수 있도록 개선한 것입니다.
경량 모델 자동 탐색 기술
- 강화 학습 기법이 적용된 다양한 응용이 활발히 연구되고 있는데, 모델 설계과 Convolution 필터 설계 시에 강화 학습 기법을 적용하여 적합한 딥 러닝 네트워크를 자동 탐색하는 기법들이 소개되고 있습니다.
- 기존의 뉴럴 네트워크 최적화는
MACs(Multiplier - Accumulators)또는FLOPs(Floating Operations Per Seconds)에 의존하였으나, 실용적인 방식인Latency또는Energy Consumption문제로 기준이 바뀌고 있습니다. - Inference에 최적화된 신경망을 자동 생성 하거나 연산량 대비 모델의 압축비를 조정하는 데 사용하여 신경망을 생성, 훈련, 배포하는 과정을 크게 단축시키는 역할을 하였습니다.
알고리즘 경량화
- 알고리즘 경량화는 기존 알고리즘의 불필요한 파라미터를 제거하거나, 파라미터의 공통된 값을 가지고 공유하거나 파라미터의 representation 능력을 잃지 않으면서 기존 모델의 크기를 줄이는 방법입니다.
- 대표적으로 Model Compression이나 Knowledge Distillation의 방법등이 있습니다.
Model Compression
- Model Compression의 첫번째 방법으로
weight pruning방법이 있습니다.
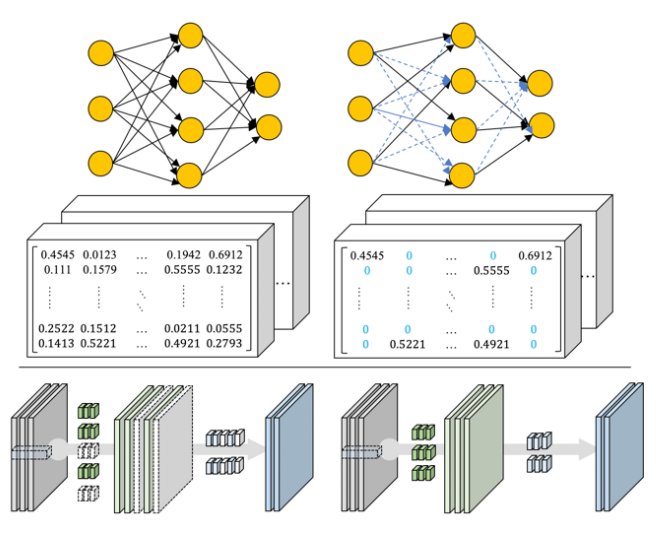
- 기존 신경망이 가지고 있는 weight 중에 inference를 위해서 필요한 값은 비교적 작은 값들에 대한 내성을 가지므로, 작은 가중치값을 모두 0으로 하여 네트워크의 모델 크기를 줄이는 기술입니다.
weight pruning이후에는 training을 다시 하여 성능을 높일 수 있는 방향으로 뉴럴 네트워크를 튜닝하는 방식으로 진행됩니다.- 위 그림을 참조하시면
weight pruning에 대하여 직관적으로 확인하실 수 있습니다.
- 다음으로
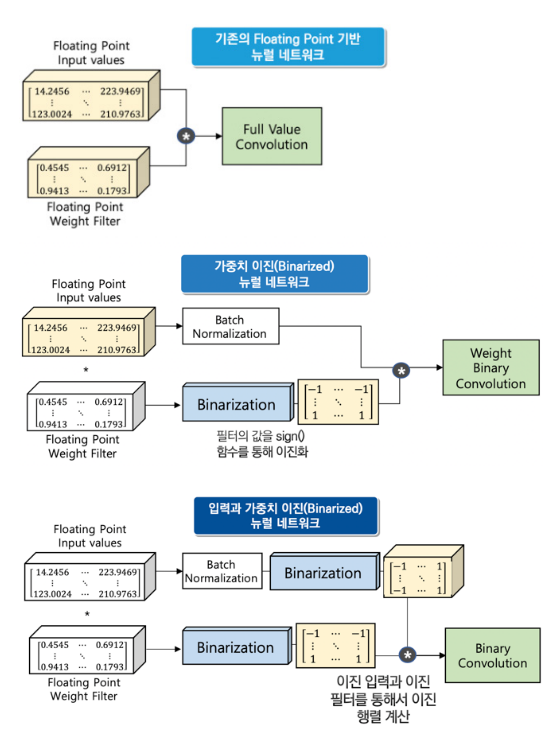
quantization과binarization에 대하여 알아보겠습니다. - 이 두 기법 모두 기존의 신경망의 부동 소수점을 줄이는 데 그 목적이 있습니다.
quantization의 경우 특정 비트 수 만큼 줄여서 계산하는 방법입니다. 예를 들어 32비트 소수점을 8비트로 줄여서 연산을 수행합니다.binarization은 신경망이 가지고 있는 가중치와 층 사이의 입력을 부호에 따라 -1 또는 1의 이진 형태의 값으로 변환하여 기존의 부동 소숫점을 사용하는 신경망들에 비해 용량과 연산량을 대폭 압축시키는 기술입니다.
Knowledge Distillation
Knowledge Distillation은 앙상블 기법을 통해 학습된 다수의 큰 네트워크들로부터 작은 하나의 네트워크에 지식을 전달하는 기법입니다.- 다수의 큰 네트워크들인
Teacher모델에서 출력은 일반적으로 특정 레이블에 대한 하나의 확률값만을 나타내지만,Student모델 학습 시에 모델의 Loss와Teacher모델의 Loss를 동시에 반영하는 형태로Student모델을 학습에 활용합니다.
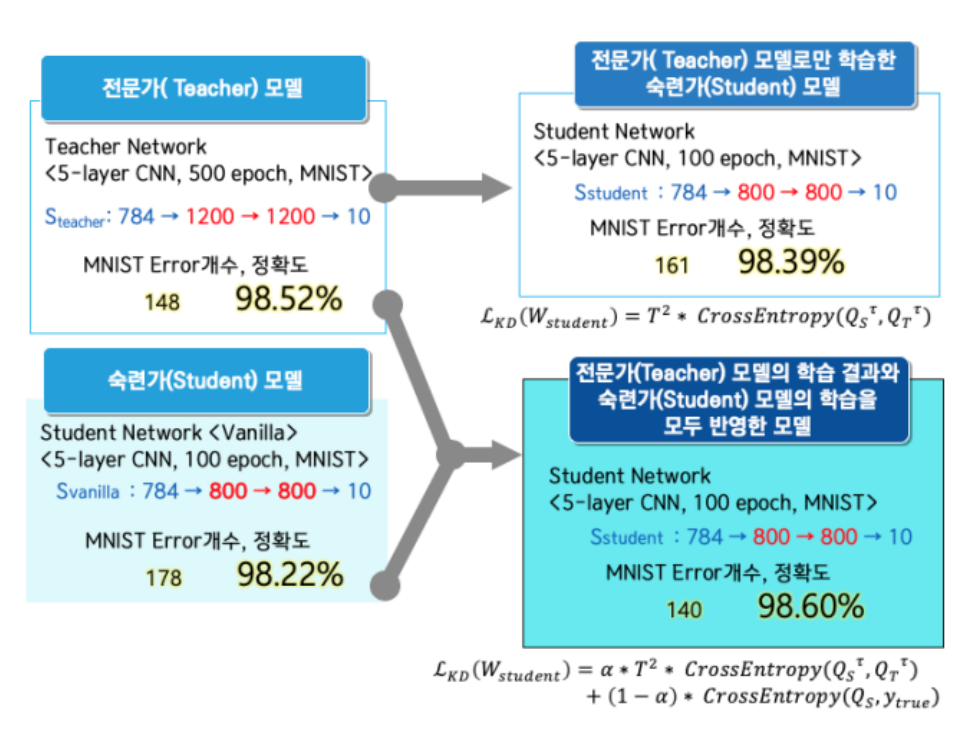
- 위 이미지에서의
Loss식을 살펴보면Knowlege Distillation을 위하여 어떻게 Loss를 설계해야 하는 지 알 수 있습니다.