MobileNetV2(모바일넷 v2), Inverted Residuals and Linear Bottlenecks
2019, Jan 01
- 출처 :
- https://arxiv.org/abs/1801.04381
- https://www.youtube.com/watch?v=mT5Y-Zumbbw&t=1397s
- 이번 글에서는 mobilenet v2에 대하여 알아보도록 하겠습니다.
- 이 글을 읽기 전에
mobilenet과depth-wise separable연산에 대해서는 반드시 알아야 하기 때문에 모르신다면 아래 글을 읽으시길 추천드립니다. mobilenet: https://gaussian37.github.io/dl-concept-mobilenet/depth-wise separable 연산: https://gaussian37.github.io/dl-concept-dwsconv/
- Mobilenet v2의 제목은 Inverted Residuals and Linear Bottlenecks입니다.
- 즉, 핵심적인 내용 2가지인
Inverted Residuals와Linear Bottlenecks가 어떻게 사용되었는 지 이해하는 것이 중요하겠습니다.
목차
-
Mobilenet v2 전체 리뷰(#mobilenect-v2-전체-리뷰)
-
Linear Bottlenecks(#linear-bottlenecks-1)
-
Inverted Residuals(#inverted-residuals-1)
-
Pytorch 코드 리뷰(#pytorch-코드-리뷰-1)
Mobilenect v2 전체 리뷰
- 먼저 mobilenet v2 전체를 간략하게 리뷰해 보도록 하겠습니다.
- 앞선 mobilenet v1에서는 Depthwise Separable Convolution 개념을 도입하여 연산량과 모델 사이즈를 줄일 수 있었고 그 결과 모바일 디바이스와 같은 제한된 환경에서도 사용하기에 적합한 뉴럴 네트워크를 제시한 것에 의의가 있었습니다.
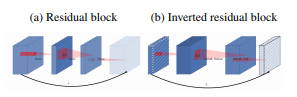
- mobilenet v2에서의 핵심 개념은 Inverted Residual 구조입니다.
- 논문에서는 이 구조를 이용한 네트워크를 backbone으로 하였을 때, object detection과 segmentation에서의 성능이 이 시점 (CVPR 2018)의 다른 backbone 네트워크 보다 더 낫다고 설명하였습니다.
Linear Bottleneck과Inverted Residual에 대한 자세한 내용은 전체 리뷰가 끝난 다음에 자세히 알아보고 먼저 큰 숲을 살펴보도록 하겠습니다.
Mobilenet_v1 Vs. Mobilenet_v2
- 먼저
mobilenet v2의 전체적인 구조를 mobilenet v1에 비교해 보겠습니다.
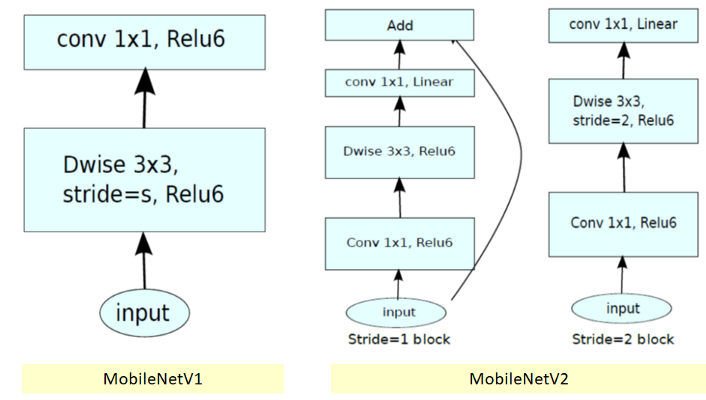
- 먼저
mobilenet v1입니다. - mobilenet v1에서의 block은 2개의 layer로 구성되어 있습니다.
- 첫번째 layer가 depthwise convolution이고 두번째 layer가 pointwise convolution 입니다.
- 첫번째 layer인 depthwise convolution은 각 인풋 채널에 single convolution filter를 적용하여 네트워크 경량화를 하는 작업이었습니다.
- 두번째 layer인 pointwise convolution 또는 1x1 convolution에서는 depthwise convolution의 결과를 pointwise convolution을 통하여 다음 layer의 인풋으로 합쳐주는 역할을 하였습니다.
- 그리고 activation function으로 ReLU6를 사용하여 block을 구성하였습니다.
- 참고로 ReLU6는
min(max(x, 0), 6)식을 따르고 음수는 0으로 6이상의 값은 6으로 수렴시킵니다.
- 참고로 ReLU6는
ReLU6를 사용하는 이유는 다음 링크를 참조 하시기 바랍니다.- 링크 : https://gaussian37.github.io/dl-concept-relu6/
- 다음으로
mobilenet v2입니다. - mobilenet v2에는 2가지 종류의 block이 있습니다. 첫번째는 stride가 1인 residual block이고 두번째는 downsizing을 위한 stride가 2인 block입니다. 이 각각의 block은 3개의 layer를 가지고 있습니다.
- 두 block 모두 첫 번째 layer는 pointwise(1x1) convolution + ReLU6 입니다.
- 두번째 layer는 depthwise convolution 입니다. 첫번째 block은 여기서 stride가 1로 적용되고 두번째 block은 stride가 2가 적용되어 downsizing됩니다.
- 세번째 layer에서는 다시 pointwise(1x1) convolution이 적용됩니다. 단, 여기서는 activation function이 없습니다. 즉, non-linearity를 적용하지 않은 셈입니다.
- stride가 2가 적용된 block에는 skip connection이 없습니다. stride 2를 적용하면 feature의 크기가 반으로 줄어들게 되므로 skip connection 또한 줄어든 크기에 맞게 맞춰져야 하는 문제가 있어서 skip connection은 적용하지 않은것으로 추정됩니다.

- 입출력의 크기를 보면 상수
t가 추가되어 있습니다. 이 값은expansion factor란 이름으로 도입하였고 논문의 실험에서는 모두 6으로 정하여 사용하였습니다. - 예를 들어 입력의 채널이 64이고 t = 6이라면 출력의 채널은 384가 됩니다.
Architecture
mobilenet v2의 전체적인 아키텍쳐에 대하여 살펴보도록 하겠습니다.
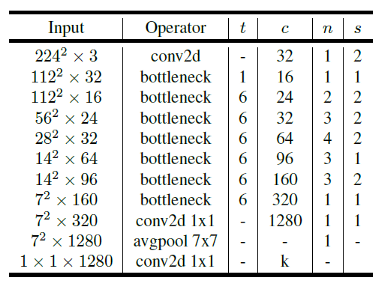
- 위 표에서 사용된 상수들의 의미를 먼저 살펴보겠습니다.
t: expansion factorc: output channel의 수n: 반복 횟수s: stride- 위와 같은 입력 resolution을 기준으로 multiply-add에 대한 연산 비용은 약 300M 이고 3.4M개의 파라미터를 사용하였습니다.
- 참고로 width multiplier는 layer의 채널수를 일정 비율로 줄이는 역할을 합니다. 기본이 1이고 0.5이면 반으로 줄이는 것입니다.
- 그리고 resuolution multiplier는 입력 이미지의 resolution을 일정한 비율로 줄이는 것입니다.
- mobilenet v1에서 도입된 width multiplier는 1로 설정하였습니다.
- performance와 파라미터등의 trade off는 입력 resolution과 width multiplier 조정등으로 가능합니다.
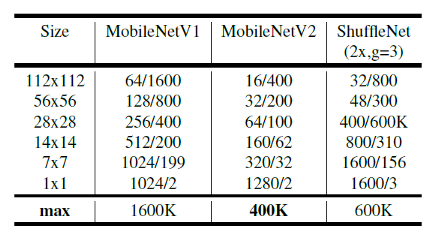
- 위 테이블에서는 각 인풋 사이즈에 따른
mobilenet,mobilenet v2,shufflenet에 대한 채널의 수/메모리(Kb 단위)의 최대 크기를 기록하였습니다. - 논문에서는 mobilenet v2의 크기가 가장 작다고 설명하고 있습니다.
Linear Bottlenecks
- 그러면
Linear Bottleneck에 대한 내용을 알아보도록 하겠습니다. - 먼저
manifold라는 개념을 알아야 하는데, 간략히 말하면 뉴럴 네트워크들은 일반적으로 고차원 → 저차원으로 압축하는Encoder역할의 네트워크 부분이 발생하게 됩니다. 이 과정에서 feature extraction을 수행하게 됩니다.
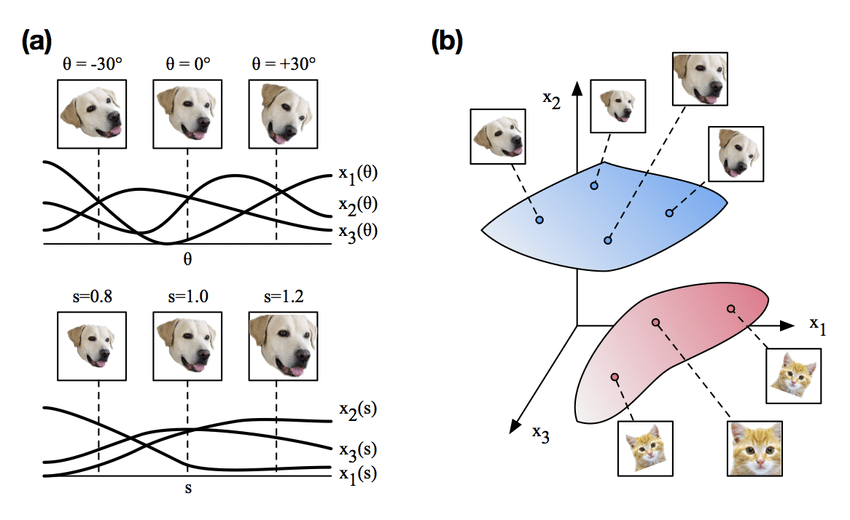
- 위 그림처럼 고차원의 데이터가 저차원으로 압축되면서 특정 정보들이 저차원의 어떤 영역으로 매핑이 되게 되는데, 이것을
manifold라고 이해하고 아래 글을 이해하시면 되겠습니다. - 따라서 뉴럴 네트워크의 manifold는 저차원의 subspace로 매핑이 가능하다고 가정해 보겠습니다.
- 이런 관점에서 보면 어떤 데이터에 관련된 manifold가
ReLU를 통과하고 나서도 입력값이 음수가 아니라서 0이 되지 않은 상태라면,ReLU는linear transformation연산을 거친 것이라고 말할 수 있습니다. 즉, ReLU 식을 보면 알 수 있는것 처럼, identity matrix를 곱한것과 같아서 단순한 linear transformation과 같다고 봐집니다. - 그리고 네트워크를 거치면서 저차원으로 매핑이 되는 연산이 계속 되는데, 이 때, (인풋의 manifold가 인풋 space의 저차원 subspace에 있다는 가정 하에서) ReLU는 양수의 값은 단순히 그대로 전파하므로 즉, linear transformation이므로, manifold 상의 정보를 그대로 유지 한다고 볼 수 있습니다.
- 즉, 저차원으로 매핑하는 bottleneck architecture를 만들 때, linear transformation 역할을 하는 linear bottleneck layer를 만들어서 차원은 줄이되 manifold 상의 중요한 정보들은 그대로 유지해보자는 것이 컨셉입니다.
- 여기 까지는 일단 가설이고, 실제로 실험을 하였는데 bottleneck layer를 사용하였을 때,
ReLU를 사용하면 오히려 성능이 떨어진다는 것을 확인하였습니다.
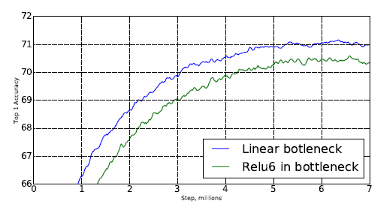
-
Inverted Residuals
- 그 다음으로 제안된 개념인
inverted residuals에 대하여 다루어 보도록 하겠습니다.
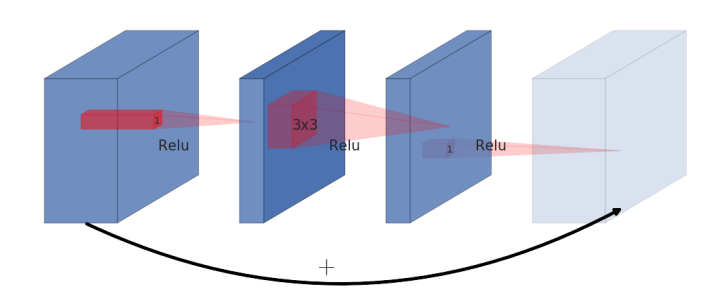
- 일반적인
residual block의 형태는 위와 유사합니다. - 즉, wide → narrow → wide 형태가 되어 가운데
narrow형태가bottleneck구조를 만들어줍니다. - 처음에 들어오는 입력은 채널이 많은 wide한 형태이고 1x1 convolution을 이용하여 채널을 줄여 다음 layer에서 bottleneck을 만듭니다.
- bottleneck에서는 3x3 convolution을 이용하여 convolution 연산을 하게 되고 다시 skip connection과 합쳐지기 위하여 원래의 사이즈로 복원하게 됩니다.
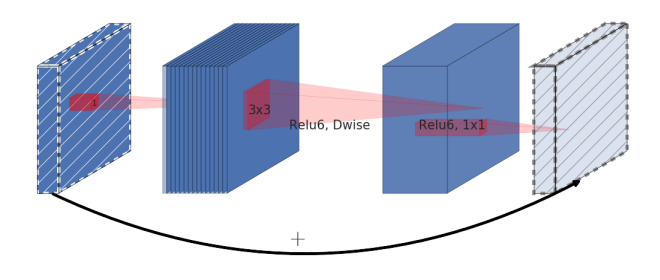
- 하지만 이 논문에서 제안된
inverted residual은 일반적은 residual block과 정반대로 움직입니다. - 위 그림의 처음 입력으로 그려진 점선 형태의 feature는 앞에서 다룬
linear bottleneck입니다. ReLU를 거치지 않았다고 이해하시면 됩니다. - 즉 narrow → wide → narrow 구조로 skip connection을 합치게 됩니다.
- 이렇게 시도한 이유는 narrow에 해당하는 저차원의 layer에는 필요한 정보만 압축되어서 저장되어 있다라는 가정을 가지고 있기 때문입니다.
- 따라서 필요한 정보는 narrow에 있기 때문에, skip connection으로 사용해도 필요한 정보를 더 깊은 layer까지 잘 전달할 것이라는 기대를 할 수 있습니다.
- 물론 이렇게 하는 이유의 목적은 압축된 narrow layer를 skip connection으로 사용함으로써 메모리 사용량을 줄이기 위함입니다.
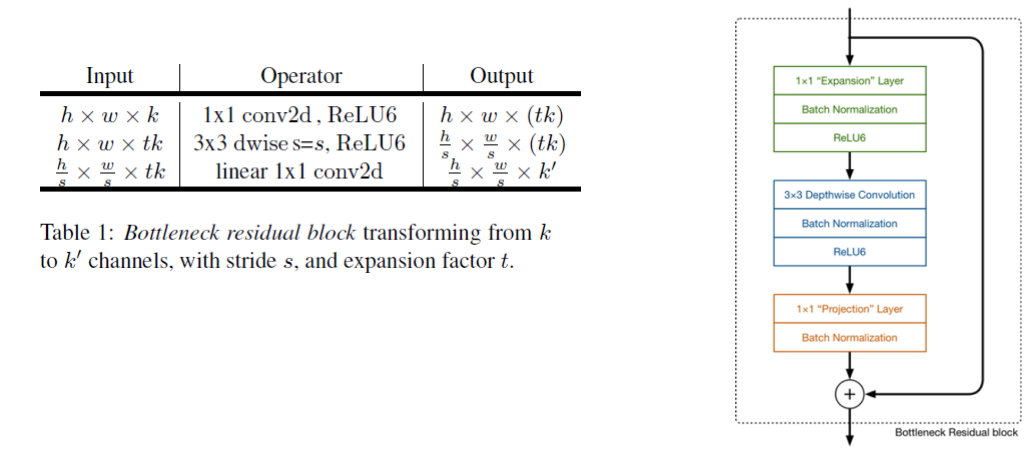
- 앞에서 설명한 inverted residual block을 표현하면 위 그림과 같이 나타낼 수 있습니다. 또는 이것을
Bottleneck Residual Block이라고 합니다. - 처음에 전체 구조를 알아볼 때 소개한 expansion factor
t가 여기서 사용됩니다. block 중간의 layer에서 expansion factor 만큼 채널이 확장 되는 것을 알 수 있습니다.- 이 논문에서는
t를 6으로 사용하고 있습니다. 논문을 따르면 5 ~ 10 정도를 사용하는 것을 추천합니다.
- 이 논문에서는
- block에서 채널을 늘리기 위해서는 pointwise(1x1) convolution이 사용되었고 경량화된 convolution 연산을 위해 depthwise separable convolution을 사용한 것을 확인하면 기존의 mobilenet과 유사한 것을 알 수 있습니다.
- 이 때, 연산량을 한번 살펴보겠습니다.
- 인풋의 크기를
h x w라고 하고, expansion factor를t, 커널의 사이즈를k, 인풋의 채널 수를d', 아웃풋의 채널 수를d''라고 하겠습니다. - 이 때 multiply-add 연산의 총 수는 다음과 같습니다.
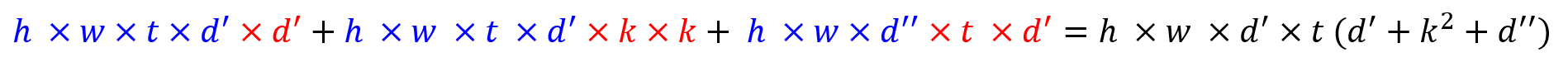
- 위 식에서 파란색에 해당하는 식이 아웃풋에 관련된 식이고 빨간색은 아웃풋을 계산하기 위한 convolution filter의 사이즈를 나타냅니다.
- 첫번째 식은 1x1 convolution을 곱하기 때문에
1 x 1 x d'가 아웃풋에 곱해집니다. - 두번째 식은 3x3 convolution을 depthwise convolution 하는 연산입니다. 따라서 곱해지는 채널의 수가 1이므로 생략되었습니다.
- 세번째 식은 마지막 출력이므로 아웃풋 채널인
d''가 도입되었습니다.
Pytorch 코드 리뷰
from torch import nn
from torch import Tensor
from typing import Callable, Any, Optional, List
__all__ = ['MobileNetV2', 'mobilenet_v2']
model_urls = {
'mobilenet_v2': 'https://download.pytorch.org/models/mobilenet_v2-b0353104.pth',
}
def _make_divisible(v: float, divisor: int, min_value: Optional[int] = None) -> int:
"""
This function is taken from the original tf repo.
It ensures that all layers have a channel number that is divisible by 8
It can be seen here:
https://github.com/tensorflow/models/blob/master/research/slim/nets/mobilenet/mobilenet.py
:param v:
:param divisor:
:param min_value:
:return:
"""
if min_value is None:
min_value = divisor
new_v = max(min_value, int(v + divisor / 2) // divisor * divisor)
# Make sure that round down does not go down by more than 10%.
if new_v < 0.9 * v:
new_v += divisor
return new_v
class ConvBNReLU(nn.Sequential):
def __init__(
self,
in_planes: int,
out_planes: int,
kernel_size: int = 3,
stride: int = 1,
groups: int = 1,
norm_layer: Optional[Callable[..., nn.Module]] = None
) -> None:
padding = (kernel_size - 1) // 2
if norm_layer is None:
norm_layer = nn.BatchNorm2d
super(ConvBNReLU, self).__init__(
nn.Conv2d(in_planes, out_planes, kernel_size, stride, padding, groups=groups, bias=False),
norm_layer(out_planes),
nn.ReLU6(inplace=True)
)
class InvertedResidual(nn.Module):
def __init__(
self,
inp: int,
oup: int,
stride: int,
expand_ratio: int,
norm_layer: Optional[Callable[..., nn.Module]] = None
) -> None:
super(InvertedResidual, self).__init__()
self.stride = stride
# stride는 반드시 1 또는 2이어야 하므로 조건을 걸어 둡니다.
assert stride in [1, 2]
if norm_layer is None:
norm_layer = nn.BatchNorm2d
# expansion factor를 이용하여 channel을 확장합니다.
hidden_dim = int(round(inp * expand_ratio))
# stride가 1인 경우에만 residual block을 사용합니다.
# skip connection을 사용하는 경우 input과 output의 크기가 같아야 합니다.
self.use_res_connect = (self.stride == 1) and (inp == oup)
# Inverted Residual 연산
layers: List[nn.Module] = []
if expand_ratio != 1:
# point-wise convolution
layers.append(ConvBNReLU(inp, hidden_dim, kernel_size=1, norm_layer=norm_layer))
layers.extend([
# depth-wise convolution
ConvBNReLU(hidden_dim, hidden_dim, stride=stride, groups=hidden_dim, norm_layer=norm_layer),
# point-wise linear convolution
nn.Conv2d(hidden_dim, oup, 1, 1, 0, bias=False),
norm_layer(oup),
])
self.conv = nn.Sequential(*layers)
def forward(self, x: Tensor) -> Tensor:
# use_res_connect인 경우만 connection을 연결합니다.
# use_res_connect : stride가 1이고 input과 output의 채널 수가 같은 경우 True
if self.use_res_connect:
return x + self.conv(x)
else:
return self.conv(x)
class MobileNetV2(nn.Module):
def __init__(
self,
num_classes: int = 1000,
width_mult: float = 1.0,
inverted_residual_setting: Optional[List[List[int]]] = None,
round_nearest: int = 8,
block: Optional[Callable[..., nn.Module]] = None,
norm_layer: Optional[Callable[..., nn.Module]] = None
) -> None:
"""
MobileNet V2 main class
Args:
num_classes (int): Number of classes
width_mult (float): Width multiplier - adjusts number of channels in each layer by this amount
inverted_residual_setting: Network structure
round_nearest (int): Round the number of channels in each layer to be a multiple of this number
Set to 1 to turn off rounding
block: Module specifying inverted residual building block for mobilenet
norm_layer: Module specifying the normalization layer to use
"""
super(MobileNetV2, self).__init__()
if block is None:
block = InvertedResidual
if norm_layer is None:
norm_layer = nn.BatchNorm2d
input_channel = 32
last_channel = 1280
# t : expansion factor
# c : output channel의 수
# n : 반복 횟수
# s : stride
if inverted_residual_setting is None:
inverted_residual_setting = [
# t, c, n, s
[1, 16, 1, 1],
[6, 24, 2, 2],
[6, 32, 3, 2],
[6, 64, 4, 2],
[6, 96, 3, 1],
[6, 160, 3, 2],
[6, 320, 1, 1],
]
# only check the first element, assuming user knows t,c,n,s are required
if len(inverted_residual_setting) == 0 or len(inverted_residual_setting[0]) != 4:
raise ValueError("inverted_residual_setting should be non-empty "
"or a 4-element list, got {}".format(inverted_residual_setting))
# building first layer
input_channel = _make_divisible(input_channel * width_mult, round_nearest)
self.last_channel = _make_divisible(last_channel * max(1.0, width_mult), round_nearest)
features: List[nn.Module] = [ConvBNReLU(3, input_channel, stride=2, norm_layer=norm_layer)]
# Inverted Residual Block을 생성합니다.
# features에 feature들의 정보를 차례대로 저장합니다.
for t, c, n, s in inverted_residual_setting:
# width multiplier는 layer의 채널 수를 일정 비율로 줄이는 역할을 합니다.
output_channel = _make_divisible(c * width_mult, round_nearest)
for i in range(n):
stride = s if i == 0 else 1
features.append(block(input_channel, output_channel, stride, expand_ratio=t, norm_layer=norm_layer))
input_channel = output_channel
# building last several layers
features.append(ConvBNReLU(input_channel, self.last_channel, kernel_size=1, norm_layer=norm_layer))
# make it nn.Sequential
self.features = nn.Sequential(*features)
# building classifier
self.classifier = nn.Sequential(
nn.Dropout(0.2),
nn.Linear(self.last_channel, num_classes),
)
# weight initialization
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out')
if m.bias is not None:
nn.init.zeros_(m.bias)
elif isinstance(m, (nn.BatchNorm2d, nn.GroupNorm)):
nn.init.ones_(m.weight)
nn.init.zeros_(m.bias)
elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight, 0, 0.01)
nn.init.zeros_(m.bias)
def _forward_impl(self, x: Tensor) -> Tensor:
# This exists since TorchScript doesn't support inheritance, so the superclass method
# (this one) needs to have a name other than `forward` that can be accessed in a subclass
x = self.features(x)
# Cannot use "squeeze" as batch-size can be 1 => must use reshape with x.shape[0]
x = nn.functional.adaptive_avg_pool2d(x, (1, 1)).reshape(x.shape[0], -1)
x = self.classifier(x)
return x
def forward(self, x: Tensor) -> Tensor:
return self._forward_impl(x)
def mobilenet_v2(pretrained: bool = False, progress: bool = True, **kwargs: Any) -> MobileNetV2:
"""
Constructs a MobileNetV2 architecture from
`"MobileNetV2: Inverted Residuals and Linear Bottlenecks" <https://arxiv.org/abs/1801.04381>`_.
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
progress (bool): If True, displays a progress bar of the download to stderr
"""
model = MobileNetV2(**kwargs)
if pretrained:
try:
from torch.hub import load_state_dict_from_url
except ImportError:
from torch.utils.model_zoo import load_url as load_state_dict_from_url
state_dict = load_state_dict_from_url(
'https://download.pytorch.org/models/mobilenet_v2-b0353104.pth', progress=True)
model.load_state_dict(state_dict)
return model
if __name__ == '__main__':
net = mobilenet_v2(True)