Multi Task Deep Learning (멀티 태스크 러닝) 개념 및 컴퓨터 비전 태스크 적용
2022, Mar 03
- 이번 글에서는 딥러닝을 이용한 멀티 태스트 러닝 내용과 컴퓨터 비전의 대표적인 태스크인 sementic segmentation과 depth estimation을 멀티 태스크 러닝으로 풀어보는 과정을 설명해 보도록 하겠습니다.
- 본 글에서 다룰 sementic segmentation과 depth estimation의 멀티 태스크 논문은 Real-Time Joint Semantic Segmentation and Depth Estimation Using Asymmetric Annotations 입니다.
- 물론 가장 대표적인 컴퓨터 비전의 멀티 태스크인 object detection은 bounding box의 클래스를 classification 함과 동시에 box의 위치를 regression 합니다. 따라서 object detection을 이해하시면 멀티 태스킹의 원리에 도움이 될 것입니다.
목차
멀티 태스크 러닝의 소개
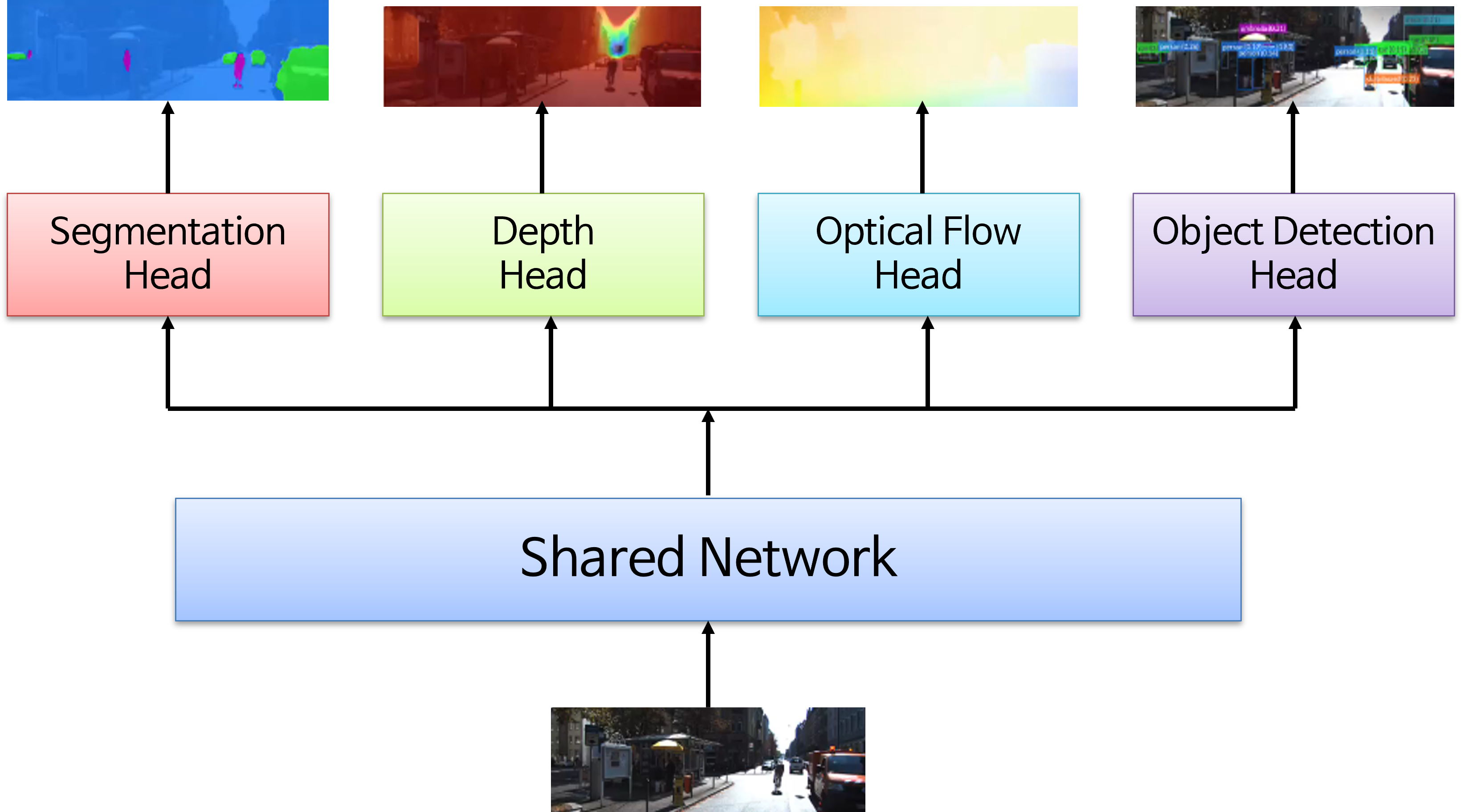
- 멀티 태스크 러닝은 하나의 모델을 이용하여 다양한 태스크를 처리하기 위해 사용합니다. 컴퓨터 비전에서 다루는 대표적인 태스크는 object detection, sementic segmentation, depth estimation. optical flow 등이 있습니다.
- 이와 같은 태스크를 모두 개별적으로 동작하기 보다 한 개의 모델을 이용하여 멀티 태스크를 처리하면 ①
one forward propagation, ②one backpropagation, ③lower parameter와 같은 장점을 얻을 수 있습니다. - 뿐만 아니라 여러 모델을 사용할 때 보다 한 개의 모델을 이용하여 멀티 태스크를 하는 경우 메모리 사용량도 더 적어서 실시간으로 동작할 때 효율적일 수 있습니다.
- 또한 멀티 태스크를 하는 태스크가 서로 연관되어 있으면 태스크를 같이 학습하는 데 전체적인 성능을 향상할 수도 있습니다. 이와 관련된 논문도 있으며 이는 태스크를 잘 조합해야 의미가 있습니다.
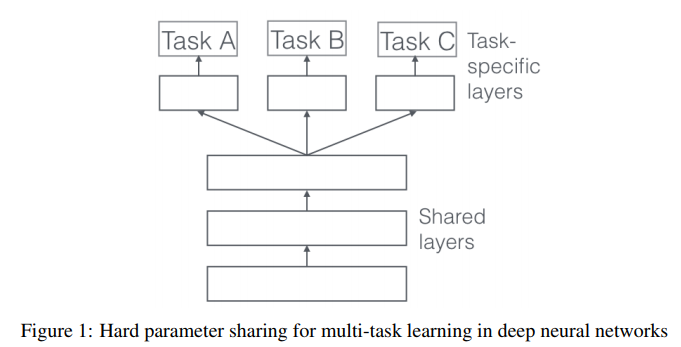
- 멀티 태스크 러닝은 일반적으로 위 구조와 같이
shared network를 통하여 공통의 feature를 추출하고 그 이후에 분기별로 나뉘어져 각 태스크를 해결할 수 있도록 추가 학습되는 구조를 가집니다. - 앞에서 설명한 다양한 장점이 있는 반면에 멀티 태스크는 상대적으로 잘 학습하기가 어려울 수 있습니다.
- 먼저 ① 태스크 별 데이터셋의 크기가 다릅니다. 따라서 데이터 불균형이 발생할 수 있기 때문에 학습하는 데 문제가 발생할 수 있습니다.
- ② 태스크 별 학습 난이도가 다를 수 있습니다. 따라서 태스크 별 다른 Learning Rate를 사용하거나 필요한 Epoch 수가 다를 수 있는데 학습할 때 이 점들을 모두 고려하여 반영하기가 까다롭습니다.
- ③ Loss function을 설계 시, 각 태스크가 잘 학습될 수 있도록 Loss function을 설계해야 합니다. 간단하게 \(L = \alpha_{1} L_{1} + \alpha_{2} L_{2} + \alpha_{3} L_{3}\) 과 같이 스케일만 조절하더라도 그 스케일 값을 결정해야 합니다.
- ④ Fine Tuning을 할 경우에 어떻게 멀티 태스크를 반영해야 할 지 검토해야 합니다.
멀티 태스크 러닝 구현 및 실습
- 기본적인 컴퓨터 비전 태스크를 기반으로 멀티 태스크 러닝 예제를 다루어 보도록 하겠습니다. 실습 코드는 아래 링크를 참조해 주시기 발바니다.
- colab 링크 : https://colab.research.google.com/drive/1_hEKSoi9_UMZ5el-7PbjwwRedLYgS1w3?usp=sharing
- 멀티 태스크 러닝의 핵심은 앞의 그림과 같이
shared backbone이 있고 그 backbone에서 출력되는 ① 각 태스크 별로 추가적인 layer 구조와 ② 학습을 하기 위한 데이터셋 그리고 ③ Loss function이 필요합니다.
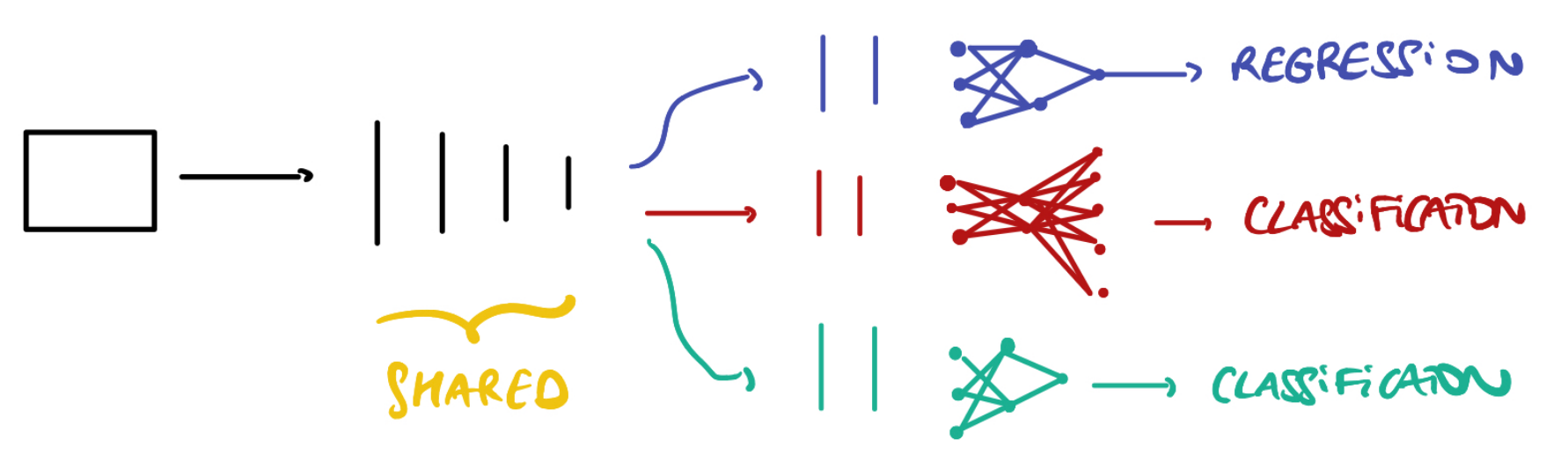
- 멀티 태스크 러닝을 다루기 위한 이번 예제는 위 그림과 같이 적용합니다.
- ①
shared backbone으로 pretrained 된resnet50을 사용하고 resnet의 마지막 feature에서 3가지 출력 (regression, classification, classification)을 적용합니다. - ② 데이터셋은
UTKFace셋으로 얼굴 이미지를 통하여 나이, 성별, 인종을 예측합니다. 나이는 regression 문제가 되고 성별 (0: male, 1: female)과 인종(0:White, 1:Black, 2:Asian, 3:Indian, 4:Other)은 classification 문제가 됩니다. 데이터셋은 다음 링크를 참조하시면 됩니다. (https://susanqq.github.io/UTKFace/) - ③ Loss의 경우 나이는 regression 문제이기 때문에
L1loss를 사용하였고, 성별은 binary classification이기 때문에Binary Cross Entropy Loss를 사용하였고 인종은 Multi Classification이기 때문에Cross Entropy Loss를 사용하였습니다.
class MultiTaskNet(nn.Module):
def __init__(self, net):
super(MultiTaskNet, self).__init__()
self.net = net
self.n_features = self.net.fc.in_features
self.net.fc = nn.Identity()
self.net.fc1 = nn.Sequential(OrderedDict([('linear', nn.Linear(self.n_features,self.n_features)),('relu1', nn.ReLU()),('final', nn.Linear(self.n_features, 1))]))
self.net.fc2 = nn.Sequential(OrderedDict([('linear', nn.Linear(self.n_features,self.n_features)),('relu1', nn.ReLU()),('final', nn.Linear(self.n_features, 1))]))
self.net.fc3 = nn.Sequential(OrderedDict([('linear', nn.Linear(self.n_features,self.n_features)),('relu1', nn.ReLU()),('final', nn.Linear(self.n_features, 5))]))
def forward(self, x):
age_head = self.net.fc1(self.net(x))
gender_head = self.net.fc2(self.net(x))
race_head = self.net.fc3(self.net(x))
return age_head, gender_head, race_head
net = resnet50(pretrained=True)
model = MultiTaskNet(net)
model.to(device=device)
race_loss = nn.CrossEntropyLoss()
gender_loss = nn.BCELoss()
age_loss = nn.L1Loss()
- 위 코드는 멀티 태스크 러닝을 위한 네트워크의 구조와 Loss 함수에 대한 내용입니다.
멀티 태스크 러닝 최적화 방법론
- 다음은 멀티 태스크 러닝의 학습을 잘 하기 위한 대표적인 학습 방법론입니다. 멀티 태스크 학습을 최적화 할 때 사용하면 도움이 되며 각 내용은 본 글에서 자세히 살펴보도록 하겠습니다.
- Multi-Task Learning Using Uncertainty to Weigh Losses for Scene Geometry and Semantics
- GradNorm: Gradient Normalization for Adaptive Loss Balancing in Deep Multitask Networks
- Gradient Surgery for Multi-Task Learning
멀티 태스크 러닝 조합 방법론
- 아래 내용은 컴퓨터 비전의 멀티 태스크 러닝 사용 시 어떤 조합으로 멀티 태스크 러닝을 해야 효과가 있는 지 조사한 내용입니다.
- Which Tasks Should be Learned Together in Multi-Task Learning
A Survey on Multi-Task Learning
- 아래 내용은 A Survey on Multi-Task Learning을 정리한 내용입니다.