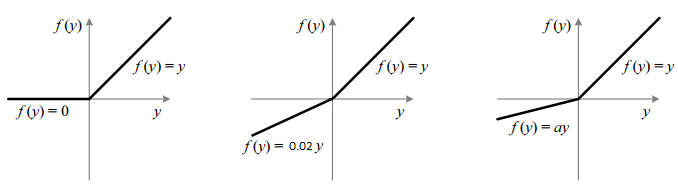
PReLU (Parametric ReLU)
2019, Dec 01
- 이번 글에서는 PReLU (Parametric ReLU)에 대하여 간략하게 알아보겠습니다.
- ReLU는 최근 딥러닝 네트워크의 activation function으로 필수적으로 사용되어 지고 있습니다.
- ReLU로 인한 딥러닝의 성능 향상이후 ReLU를 좀 더 개선한 것들이 나오고 있는데 대표적으로 LeakyReLU가 있고 이 글에서 다룰 Parametric ReLU가 있습니다.
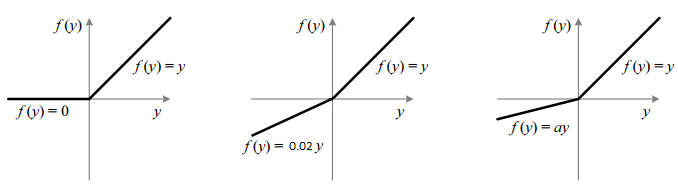
- 먼저 ReLU에서는 음수의 값을 모두 0으로 만듭니다. 즉, 양수에서는 gradient가 1, 음수에서는 0이 되도록합니다.
- 반면 LeakyReLU는 음수에서도 작은 값의 gradient를 가집니다. 위 그림에서는 0.02를 가지게 됩니다.
- 즉, 단순 ReLU 보다 음의 값에 대하여 gradient가 발생할 수 있도록 열어둔 것입니다.
- 여기서 중요한 것은 ReLU에서 음수의 gradient는 0이라는 상수값, LeakyReLU 에서 음수의 gradient는 어떤 상수 값입니다. 즉 둘다
상수값을 가집니다. - PReLU에서는 음수에 대한 gradient를 변수로 두고 학습을 통하여 업데이트 시키자는 컨셉입니다.
- \[f(y_{i}) = \left\{ \begin{array}{c} y_{i}, \ \ \ if \ \ y_{i} \gt 0 \\ a_{i}y_{i} \ \ if \ \ y_{i} \le0 \\ \end{array} \right.\]
- \[f(y_{i}) = \text{max}(0, y_{i}) + a_{i} \text{min}(0, y_{i})\]
- 정리하면 \(a_{i}\) 값에 따라서 ReLU, LeakyReLU, PReLU를 구분할 수 있습니다.
- 만약 \(a_{i} = 0\)이면
ReLU - 만약 \(a_{i} > 0\)이면
LeakyReLU - 만약 \(a_{i}\)가 학습 가능하면
PReLU
- 만약 \(a_{i} = 0\)이면
- Feedforward 네트워크에서 각 계층은 단일 기울기 매개변수를 학습할 수 있고 CNN에서는 각 계층별로 학습하거나 각 계층별 또는 채널별로 학습할 수 있습니다.
pytorch 코드 예시
- 아래 코드의
nn.PReLU()를 이용하면 쉽게 적용할 수 있습니다.
def __init__(self):
super(Net, self).__init__()
self.conv1_1 = nn.Conv2d(1, 32, kernel_size=5, padding=2)
self.prelu1_1 = nn.PReLU()
self.conv1_2 = nn.Conv2d(32, 32, kernel_size=5, padding=2)
self.prelu1_2 = nn.PReLU()
self.conv2_1 = nn.Conv2d(32, 64, kernel_size=5, padding=2)
self.prelu2_1 = nn.PReLU()
self.conv2_2 = nn.Conv2d(64, 64, kernel_size=5, padding=2)
self.prelu2_2 = nn.PReLU()
self.conv3_1 = nn.Conv2d(64, 128, kernel_size=5, padding=2)
self.prelu3_1 = nn.PReLU()
self.conv3_2 = nn.Conv2d(128, 128, kernel_size=5, padding=2)
self.prelu3_2 = nn.PReLU()
self.preluip1 = nn.PReLU()
self.ip1 = nn.Linear(128*3*3, 2)
self.ip2 = nn.Linear(2, 10)