
L1,L2 Regularization
2018, Jun 06
- 참조 : https://youtu.be/kuJROoa4kh8
Normalization과 Regularization
- 이 글에서 설명할 Regularization은 정규화 라고 불립니다. 반면 Normalization의 경우에도 정규화라고 불립니다. 따라서 같은 정규화 라는 단어로 사용되기 때문에 종종 헷갈릴 수 있습니다. 따라서 차이점을 정확하게 확인하고 넘어가시길 바랍니다.
Normalization: 데이터에 scale을 조정하는 작업Regularization: predict function에 복잡도를 조정하는 작업
- 예를 들어 데이터가 매우 다른 scale(하한값과 상한값의 범위가 매우 큰 경우)에있는 경우 데이터를
Normalization할 수 있습니다. 이 때, 대표적으로 평균 및 표준 편차와 같은(또는 호환 가능한) 기본 통계를 이용하여 데이터를 변경합니다. 이는 학습된 모델의 정확도를 손상시키지 않으면서 데이터의 Scale을 조정하여 데이터의 분포 범위를 조절할 수 있습니다.
- 모델 학습의 한 가지 목표는 중요한 feature를 식별하고 noise(모델의 최종 목적과 실제로 관련이 없는 random variation)를 무시하는 것입니다. 주어진 데이터에 대한 오류를 최소화하기 위해 모델을 자유롭게 조정하는 경우 과적합이 될 수 있습니다. 모델은 이러한 임의의 변형을 포함하여 데이터 세트를 정확하게 예측해야합니다.
Regularization은 복잡한 함수보다 더 간단한 피팅 함수에 보상(reward)을 합니다. 예를 들어, RMS 에러가 x 인 단순 로그 함수가 오류가 x / 2 인 15 차 다항식보다 낫다고 말할 수 있습니다. 이러한 모델 단순화의 정도와 에러에 대한 트레이드 오프 조정은 모델 개발자에게 달려 있습니다.
- 이번 글에서는 딥러닝에서 많이 사용되는 L1, L2 Regularization에 대하여 간략하게 알아보도록 하겠습니다.

- 파란 점과 빨간 점을 나누는 line을 구할 때 Solution1,2 중 어떤 모델의 Error가 작을까요? 일단 Solution 1,2의 line은 둘다 같은 line을 가집니다.
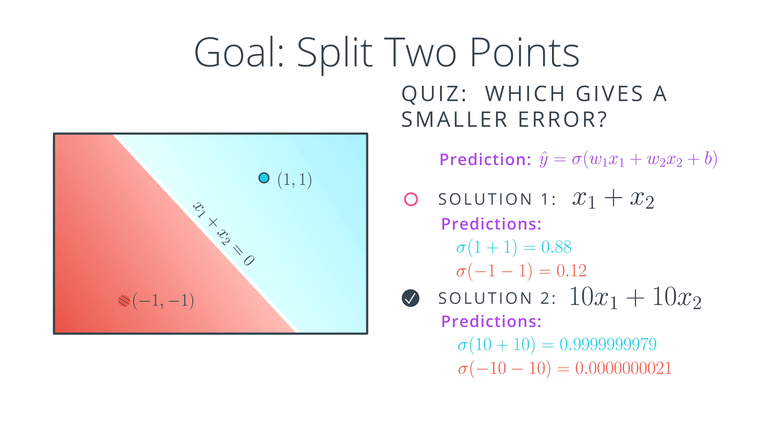
- 하지만 Prediction을 구해보면 상황은 다릅니다. Solution1 모델에 파란점 (1, 1)과 빨간점 (-1, -1)을 sigmoid에 대입한 결과와 동일 방법으로 Solution2 모델에 대입한 결과 값은 차이가 많이 납니다.
최적해를 구하기 위해 Error를 최소화 해야하고 Error를 최소화 하기 위해서는 M.L(Maximum likelihood)에 따라서 모든 이벤트의 발생 확률이 높도록 모델을 설정해 주어야 합니다. 위에서 Solution1과 Solution2의 모델을 각각 적용하여 CE(Cross Entropy)를 구하면 Solution2의 CE값이 좀 더 M.L에 가까우므로 Solution2의 Error가 더 작다고 할 수 있습니다. (즉, label = 1인 blue 포인트의 확률은 좀 더 1에 가깝고, label = 0인 red 포인트의 확률은 좀 더 0에 가깝습니다.)- 그러면 Solution2가 항상 Solution1보다 좋다고 할 수 있을까요? 즉, 최적화 되었다고 할 수 있을까요? 정답은 아닙니다. 사실 여기에는 다른 문제가 남아있습니다.
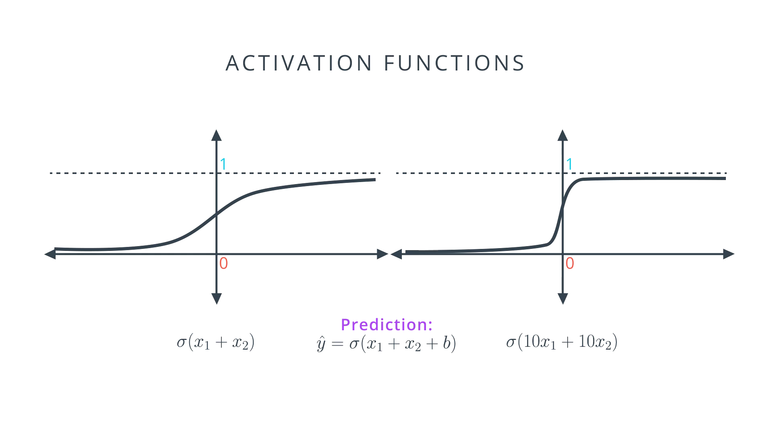
- Solution2 = 10 x Solution1 입니다. weight의 차이로 인하여 Solution2의 sigmoid 출력값(예측값)은 Solution1에 비하여 정답(blue)이라고 생각하는 점은 1에 가깝고, 오답(red)라고 생각하는 점은 0에 가깝습니다. 하지만 Solution2의 예측 방법이 경우에 따라서 더 나쁠 수 있습니다.
- 왜 Solution1이 Solution2에 비하여 ML이 좋지 않음에도 좋은 모델이 될 수 있는지 설명드리겠습니다. 왼쪽의 Solution1 모델과 오른쪽의 Solution2 모델에 sigmoid를 적용한 그래프를 보면 기울기가 다릅니다.
- 왼쪽 그래프에 비하여 오른쪽 그래프는 x = 0 주위로 급격한 기울기를 가집니다. 그리고 x의 값이 점점 커지거나 작아질수록 기울기가 0에 급격히 가까워 집니다.
- 학습을 하기 위해서는 gradient 값이 중요한데 오른쪽 모델 같은 경우에는 gradient가 급격하게 0에 수렴하게 되어 학습이 제대로 이루어 지지 않습니다. 만약 오른쪽 모델을 선택 하였을 때, 점들이 오 분류되어있다면 학습을 통하여 모델을 수정하기가 어려워져 Error가 줄어들지 않게 됩니다.

- 이 문제를 간단히 정리하면
large coefficient로 인하여overfitting이 발생한 것이라고 할 수 있습니다.coefficient가 크면 클수록 기존 데이터에 최적화 되고 학습이 잘 되지 않기 때문입니다. 그러면 이 문제를 어떻게 해결해야 할까요?
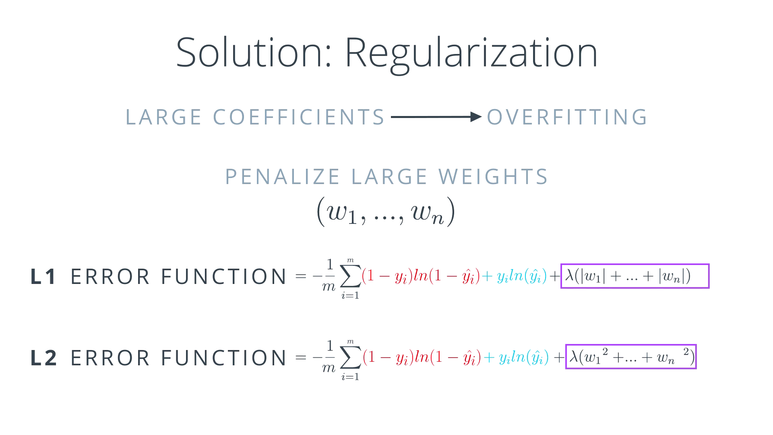
- 기본적인 컨셉은 큰 coefficient 즉, weight에 페널티를 주는 것 입니다. 페널티를 주는 방법은 위와 같이 Error에 coefficient에 해당하는 weight들을 더해주는 것입니다. 이 때 \(\lambda\)는 얼마나 페널티를 줄 지 정하게 됩니다.
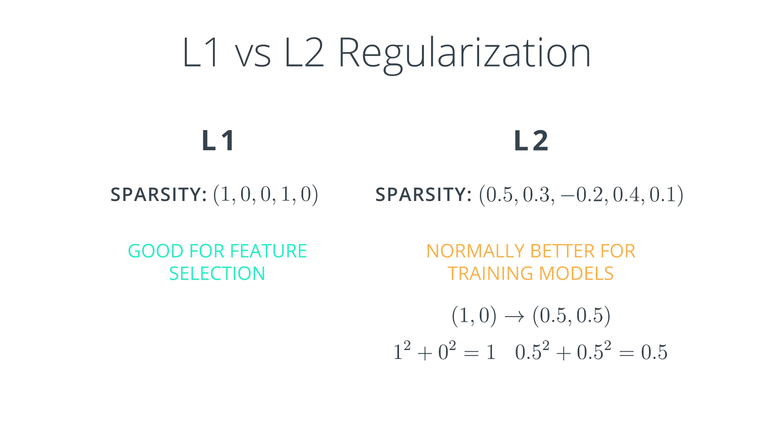
- L1과 L2 regularization을 선택하는 기준을 무엇일까요?
- L1을 적용 하면, vector들이 sparse vector가 되는 경향이 있습니다. 즉 작은 weight 값은 0이 되어버리는 것입니다. 따라서 weight의 수를 줄이고 small set을 만들고 싶으면, L1을 사용하면 됩니다. 따라서 L1을 이용하면 Feature(특정 weight)를 선택하여 사용할 수 있습니다. weight가 너무 많을 때 좀 더 중요한 weight만 선택하게 되고 나머지 weight는 0으로 되는 효과를 얻을 수 있습니다.
- L2는 sparse vector를 만드는 것은 아닙니다. 대신 모든 가중치를 균등하게 작게 유지하려고 합니다. 이 모델은 일반적으로 학습시 더 좋은 결과를 만듭니다. 따라서 학습할 때에는 대부분 L2 모델을 사용할 것입니다.
- 왜 L1은 sparse vector를 만들고 L2는 균등하게 작은 weight들을 만들까요?
- 만약 \((1, 0)\) vector가 있을 때, L1으로 계산하면 \(\vert 1 \vert + \vert 0 \vert = 1\)이 되고 L2로 계산하여도 \(1 + 0 = 1\)이 됩니다. 반면 \((0.5, 0.5)\) vector가 있을 때, L1으로 계산하면 \(\vert 0.5 \vert + \vert 0.5 \vert = 1\)이 되지만 L2로 계산하면 \(0.5^{2} + 0.5^{2} = 0.25 + 0.25 = 0.5\)가 됩니다. 값이 균등하게 작을 때에는 L2의 값이 더 작아지게 됩니다. 따라서 Error에 더 작은 penalty를 주게 됩니다.
- L1, L2 연산한 값을 Error에 더하므로 연산 결과가 작아지는 값을 선호합니다. 이 값이 너무 커져 버리면 오히려 학습하는 데 방해가 될 수 있기 때문입니다. 따라서 L1 보다 L2를 많이 사용하는 이유이기도 합니다.
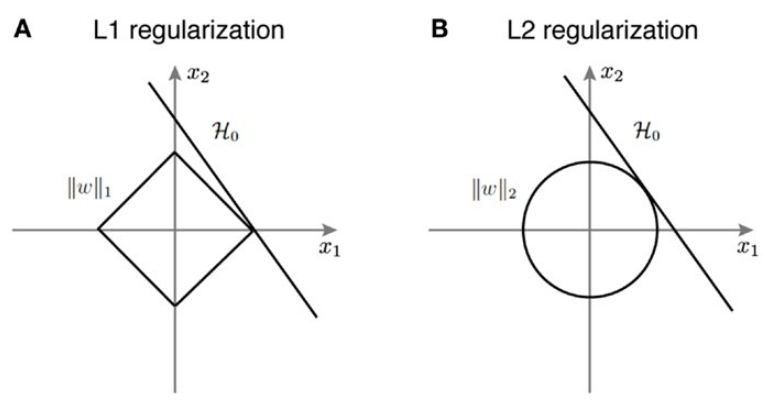
- 이번에는 L1과 L2를 그래프 관점에서 바라보겠습니다. 앞에서 설명한 바와 같이 L1, L2 Regularization은 Error 값을 증가시켜서 최적화 하는데 제약을 주게 됩니다.
- 파라미터가 x1, x2로 2개일 때, 왼쪽 곡선은 L1 Regularization의 분포를 나타내고 오른쪽 곡선은 L2 Regularization의 분포를 나타냅니다.
- 위 그래프에서 H0를 Error 값을 최적화 시키는 solution이라고 가정합시다. 이 때, L1 또는 L2 Regularization의 분포와 H0가 한점에서 접하는 지점이 최적화 하는 해가 됩니다.
- L1 Regularization을 좌표평면에 나타내면 왼쪽 마름모 형태의 분포와 같고 H0와 한점에서 만나는 지점은 끝 모서리가 됩니다. 끝 모서리에서 solution을 찾았다는 것은 solution의 값 중 하나는 0이 되었다는 것입니다. 즉, 절대값 함수의 형태로 인하여 sparse vector가 생성되게 됩니다.
- L2 Regularization을 좌표평면에 나타내면 오른쪽 원의 형태와 같고 H0와 한점에서 만나는 지점은 원에 접하는 모든 부분이 됩니다.
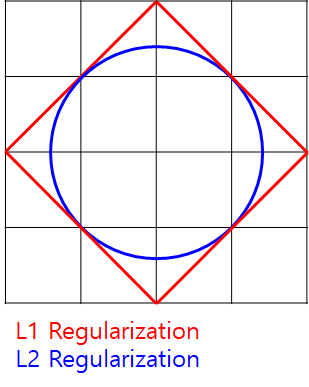
- 다시 정리하면 L1 Regularization을 이용하면 weight가 sparse해지고 L2 Regularization을 이용하면 균등하게 작은 값들로 weight로 업데이트가 됩니다. 그 이유는 L1의 경우 해가 모서리 부분에서 발생할 수 있어 일부 값들이 0이 되기 때문이고 L2의 경우 L1 분포에 내접하는 원의 형태로 weight가 분포하므로 L1보다 작은 값들로 구성되게 됩니다.

- 다른 관점으로 다시 한번 Regularization을 살펴보겠습니다. 위 식을 다시 살펴보면
Regularization식은 Loss에 더해집니다. - 중요한 것은 일반적으로 사용하는 Loss의 공통점은 Backpropagation이 가능한 미분 가능한 형태이며
convex하다는 것입니다. - Loss와 동일하게 Regularization 또한
convex합니다. L1의 경우 V형태를 띄고 L2의 경우 U 형태를 띄기 때문입니다. 즉, Loss와 Regulaization 모두 convex 하다는 공통점이 있습니다. 최적화 이론에서 convex + convex = convex가 성립하기 때문에 Loss(convex) + Regularization(convex) = Loss(convex)가 성립하게 됩니다. - 앞에서 설명하였듯이 Regularization은 Loss라는 convex 함수가 최소값에 다가가지 못하도록 하는 역할을 합니다. 최적화의 목적이 convex의 최소점에 다가가도록 하는 것인데 그 궁극적인 목적을 방해하는 것입니다. 왜냐하면 최적화가 학습 데이터를 이용하여 이루어지는데 너무 학습 데이터에 편중되어서 학습되는 것을 막게 하기 위해서 입니다. 즉 과적합을 막기 위해 강제로 최적화가 되지 않도록 막는 것입니다.
- 정리하면 Loss + Regularization은 제약 조건이 있는 상태의 최적화 문제라고 말할 수 있습니다.
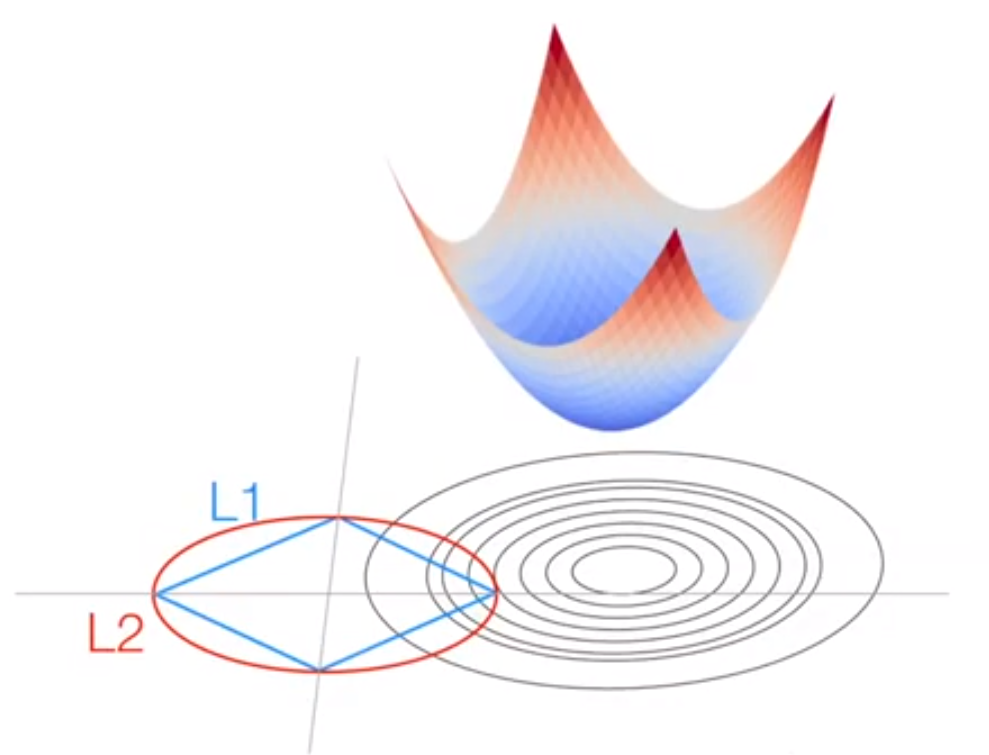
- 이것을 시각화 해서 보면 등고선 형태의 Loss가 있을 때, 최적화가 될 수록 등고선의 Loss가 줄어야 합니다.
- 하지만 L1 또는 L2 Regularization이 더해지므로 위 그림에서 L1 또는 L2의 범위 내에서 최소값이 수렴하게 됩니다. 이런 방법을 통하여 완전한 global minimum에 수렴하지 못하도록 하여 overfitting 문제를 개선해 줍니다. (위 그림에서 L1과 L2의 범위가 일치하는 것처럼 보이지만 실제로는 다양한 크기의 형태를 가질 수 있습니다.)
- L1, L2 Regulaization을 설명하는 다른 좋은 자료를 찾아서 추가적으로 설명을 붙이도록 하겠습니다.
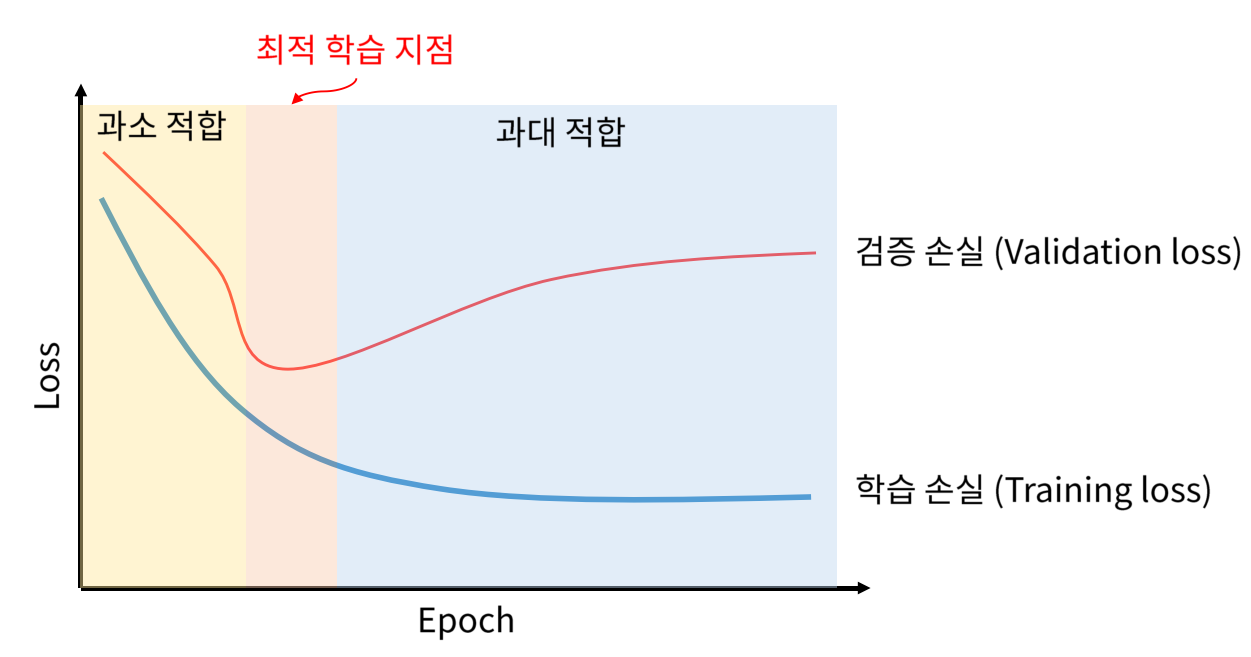
- Train / Validation 셋을 이용하여 학습을 진행하다 보면 Train 데이터에 과적합 (Overfitting)되는 현상이 발생합니다.
- \[\text{Cost} = \text{Loss}(\color{red}{\text{Data}} \vert \text{Model}) + \lambda \text{Complexity}(\color{red}{\text{Model}})\]
- 위 식을 보면
Loss이외에 추가적인Complexity항이 추가 됩니다. 이 항이 Regularization에 해당합니다. Loss하나를 가지고 학습을 한다면 Loss는 Cost와 동일합니다. 반면 Regularization을 추가한다면Cost는Loss+Regularization이 됩니다.Cost를 구할 때,Loss에 집중을 하게 되면, Train 데이터에 대한 신뢰도가 높아지게 됩니다. 따라서 Train 데이터에 속하지 않는 입력에 대해서는 취약해 집니다.Complexity는 모델의 복잡도를 나타냅니다. 모델의 복잡도가 지나치게 높아지게 되면 Train 데이터에 비하여 Validation 데이터와 Test 데이터의 성능이 너무 낮아지게 됩니다. 이를 개선 하기 위하여 모델이 너무 복잡해지지 않게 일반적인 feature만 학습을 하도록 Train 데이터 학습보다 모델의 일반화에 집중함으로써 Complexity를 낮출 수 있습니다.- 이 때, \(\lambda\)를 통하여 얼만큼 Complexity를 낮출 지를 결정할 수 있습니다. 예를 들어 \(\lambda = 0\)으로 두면
Loss에만 온전히 집중을 하겠다는 뜻이고 \(\lambda\)의 값에 큰 값을 넣으면 Complexity를 낮추겠다는 의미를 가집니다.
- Complexity를 주기 위한 방법으로
L2 Regularization (Ridge)을 많이 사용하곤 합니다. L2 regularization은 weight의 L2 Norm을 구해서 아래와 같이 Loss에 페널티를 부과하여 Cost를 구성합니다.
- \[\text{Cost} = \text{Loss}(\text{Data} \vert \text{Model}) + \lambda \text{Complexity}(\text{Model})\]
- \[\text{Complexity}(\text{Model}) = \frac{1}{N} \sum_{i} \frac{1}{2} w_{i}^{2} = \color{red}{\frac{1}{2} \Vert w \Vert^{2}}\]
- L2에서 사용되는 제곱함수 큰 값에 대하여 크기가 급격하게 커지게 됩니다. 따라서 weight의 값이 커지게 되면 점점 더 페널티가 커지게 되어 complexity를 낮출 수 있습니다. 그 결과 모델을 좀 더 단순화 하도록 할 수 있습니다.
- 뿐만 아니라 L2 Regularization을 사용하면 베이지안 사전 확률 분포 (정규 분포)를 사용하는 것과 동일하며 가중치가 정규 분포의 형태를 이루도록 합니다. (이 글 주제와는 좀 다른 내용이라 따로 식을 유도하지는 않겠습니다.)
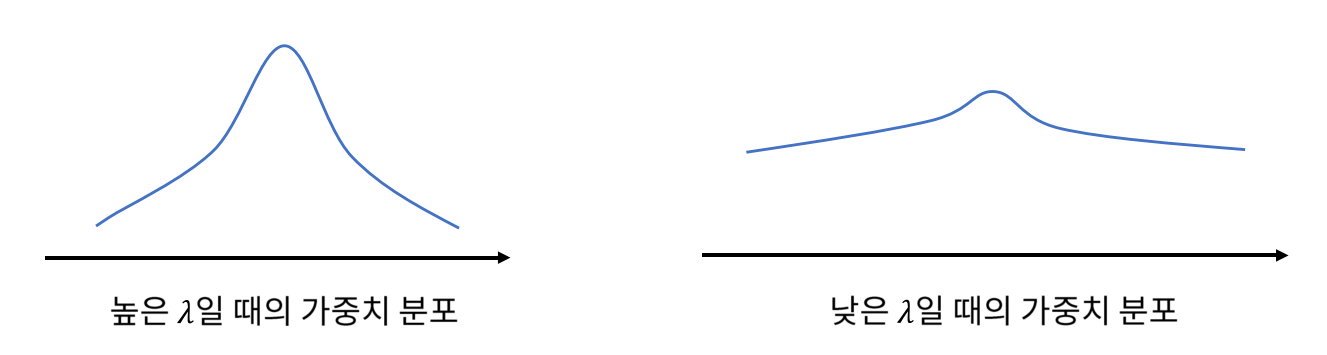
- 따라서 Cost의 분포는 \(\lambda\) 값의 크기에 따라 위 그림과 같이 다르게 나타납니다. \(\lambda\)의 값이 클수록
정규 분포에 가깝게 Cost가 분포하는 것을 확인할 수 있습니다. - 반면 \(\lambda\) 값이 0에 가까울수록 weight의 분포 정규화가 일어나지 않으며 weight의 분포는 아주 작은 음수 부터 아주 큰 양수 까지 넓게 분포하게 됩니다.
- 이번에는
L1 Regularization (Lasso)에 대하여 알아보도록 하겠습니다. L1 Regularization은 가중치의 절대값에 페널티를 주는 방법을 뜻합니다. - L1 Regularization은 weight 값이 양수 또는 음수로 존재하기만 하면 weight를 줄이고자 합니다. 왜냐하면 0이 아닌 모든 weight는 Cost에 더해지기 때문에 gradient descent를 할 때, gradient에 비례하여 weight가 감소되기 때문입니다. L1 Regularization은 절대값을 가지기 때문에 항상 기울기(gradient)가 1 또는 -1입니다. 이 값이 weight 감소에 사용됩니다.
-
따라서 0이 아닌 weight 값이 존재하면 0으로 만들려고 하기 때문에 weight 값이
Sparse해 지는 특징이 있습니다. - \[\text{Cost} = \text{Loss}(\text{Data} \vert \text{Model}) + \lambda \text{Complexity}(\text{Model})\]
- \[\text{Complexity}(\text{Model}) = \frac{1}{N} \sum_{i} \frac{1}{2} w_{i}^{2} = \color{red}{\Vert w \Vert_{1}}\]
- L1 Regularization 또한 베이지안 사전 확률 분포 (라플라스 분포)를 따르게 됩니다.
- 라플라스 분포의 특징 답게 0에 많은 값이 분포할 뿐 아니라 양 극단에 많은 값이 분포하게 됩니다. 이러한 성질을 Sparse 하다고 말할 수 있습니다.
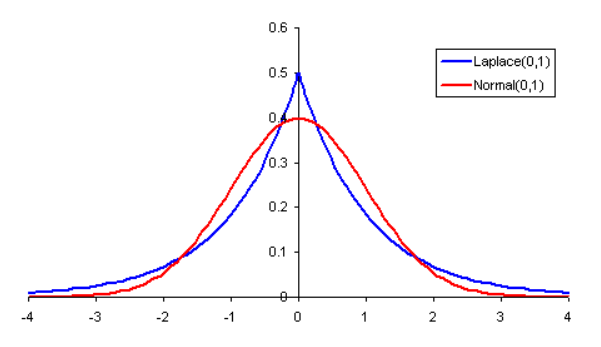
- 정리해 보겠습니다. 이 글에서 L1, L2 Regularization을 사용하였을 때, Weight가 어떤 분포를 이루게 될 지에 대하여 정확하게 수식으로 유도하지는 않았지만 그 결과를 살펴보았을 때, 위 그림과 같은 분포가 나타남을 알 수 있습니다.
- 앞에서 설명하였듯이, L1 Regularization을 적용하였을 때, weight는 라플라스 분포를 가지게 되고 이는 파란색 그래프와 같은 형태를 가집니다.
- 반면 L2 Regularization을 적용하였을 때, weight는 정규 분포를 가지게 되고 이는 빨간색 그래프와 같은 형태를 가지게 됩니다.
- 따라서 L1 Regularization은 L2에 비하여 0인 경우에 많이 분포하고 뿐만 아니라 절대값이 큰 양 극단에도 상대적으로 많이 분포하게 되어 Sparse한 형태를 가집니다.
- L2 Regularization은 상대적으로 0 근처에 대부분 분포하게 되면서 고르게 분포하도록 만들어 줍니다.
- 이 점이 L1, L2 Regularization의 특징 및 차이점이라 말할 수 있습니다.
- 추가적으로 Loss function으로써의 L1, L2 norm이 어떻게 사용되는 지 알아보도록 하겠습니다.
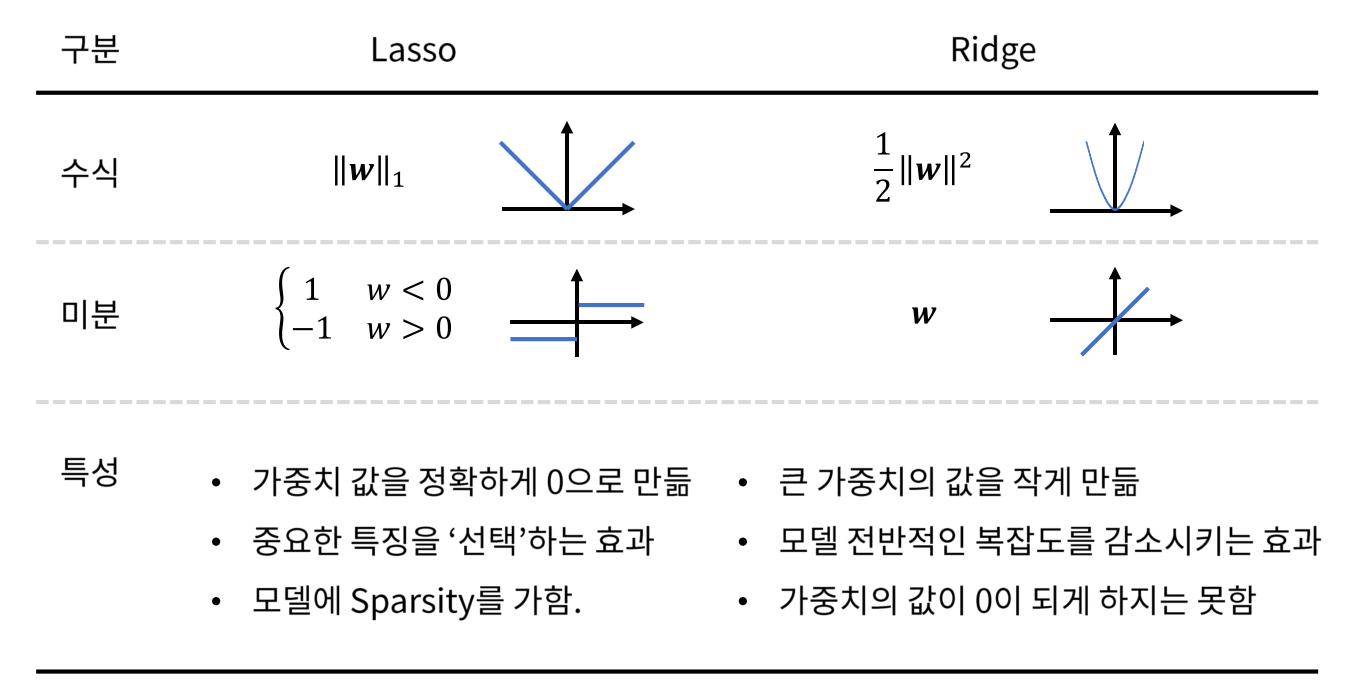
- 앞에서 다루었던 L1 (Lasso)와 L2 (Ridge)에 대하여 도표로 정리하면 위 그림과 같습니다.
Lasso의 경우 절대값의 형태를 가지므로 값이 선형적으로 증가합니다. 따라서 미분을 하였을 때, 값의 크기와 무관하게 양수인 경우 1, 음수인 경우 -1의 값을 가집니다. 따라서 weight의 값이 0이 아닌 경우는 일정한 크기로 계속 0을 만들기 위해 업데이트 하게 됩니다. 따라서 가중치의 값을 정확하게 0으로 만들도록 업데이트 합니다. 이 메커니즘은 중요한 feature를 선택 하도록 하는 효과 (feature selection)가 있습니다. 중요하지 않은 값은 0으로 만들어 버리기 때문에 모델의 Sparsity를 만들어 줍니다.Ridge의 경우 이차 함수로 값이 점점 더 크게 증가하는 형태를 가집니다. 미분을 하였을 때, 미분값이 선형적으로 증가합니다. 0 보다 더 커지면 커질수록 미분값이 더 크게 나타나기 때문에 weight의 값이 큰 경우 더 큰 폭으로 감소 시키고 상대적으로 weight 값이 작은 경우 작은 폭으로 감소하게 됩니다. 따라서 큰 weight의 값을 작게 만드는 효과와 더불어 모델 전반적인 복잡도를 감소시키는 효과가 있습니다. 하지만 가중치의 값이 0이 되게 하지는 못합니다. 왜냐하면 weight가 0에 가까울수록 미분값도 0에 아주 가까워지기 때문에 weight 업데이트가 잘 되지 않기 때문입니다.
- 지금부터 설명하는 바는
Regularization과 상관없으나 L1, L2를 이용하여Loss를 적용해 보려고 합니다. 즉 아래 빨간색 부분입니다. 이를 linear regression을 통해서 살펴보겠습니다.
- \[\text{Cost} = \color{red}{\text{Loss}(\text{Data} \vert \text{Model})} + \lambda \text{Complexity}(\text{Model})\]
- \[y = wx\]
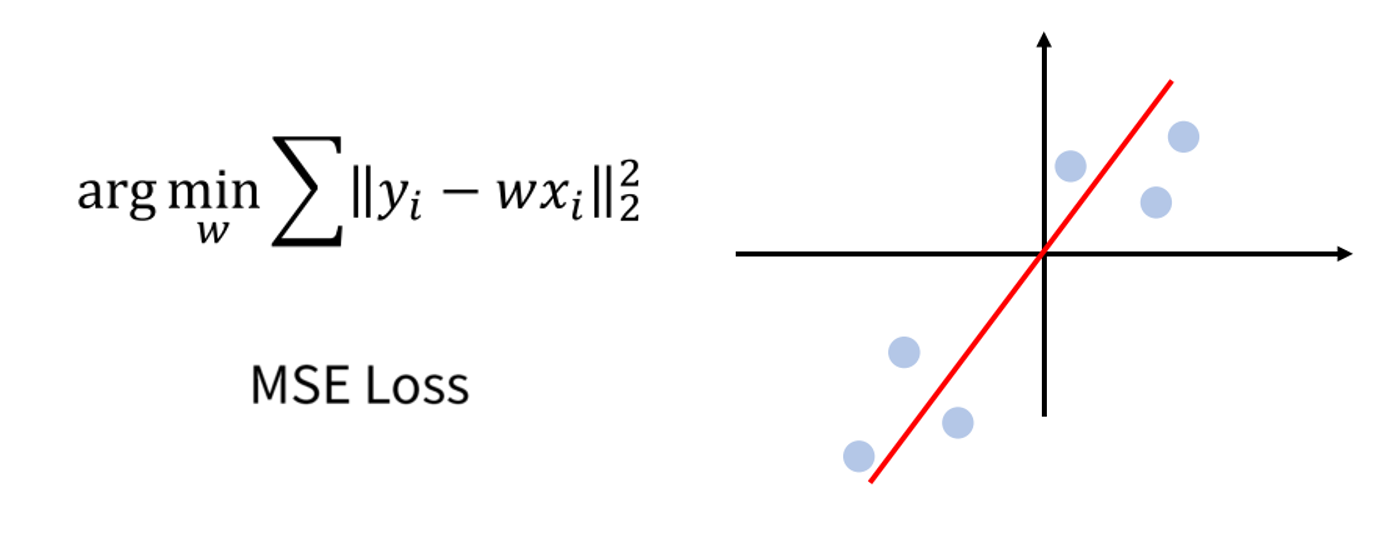
MSE (Mean Squared Error) Loss는 L2 (Ridge)와 관련되어 있습니다.- 이 경우 에러가 클수록 더 큰 페널티를 가집니다.
- 그리고 데이터의
평균을 내는 효과를 가집니다. 평균값이기 때문에 MSE의 추세선을 살펴보면 실제 존재하지 않는 값을 나타냅니다. - 또한 데이터를 smoothing 하는 효과를 가집니다.
- 하지만 outlier가 있을 때, outlier의 loss를 줄이기 위하여 MSE의 추세선이 다르게 변형될 수 있으므로 전체 Loss를 잘못 구할 수 있습니다. 따라서 outlier에 취약한 단점이 있습니다. 이는 MSE가
평균을 나타내는 특성으로 인하여 평균의 취약점인 outlier에 의한 평균의 왜곡 문제와 일맥상통합니다.
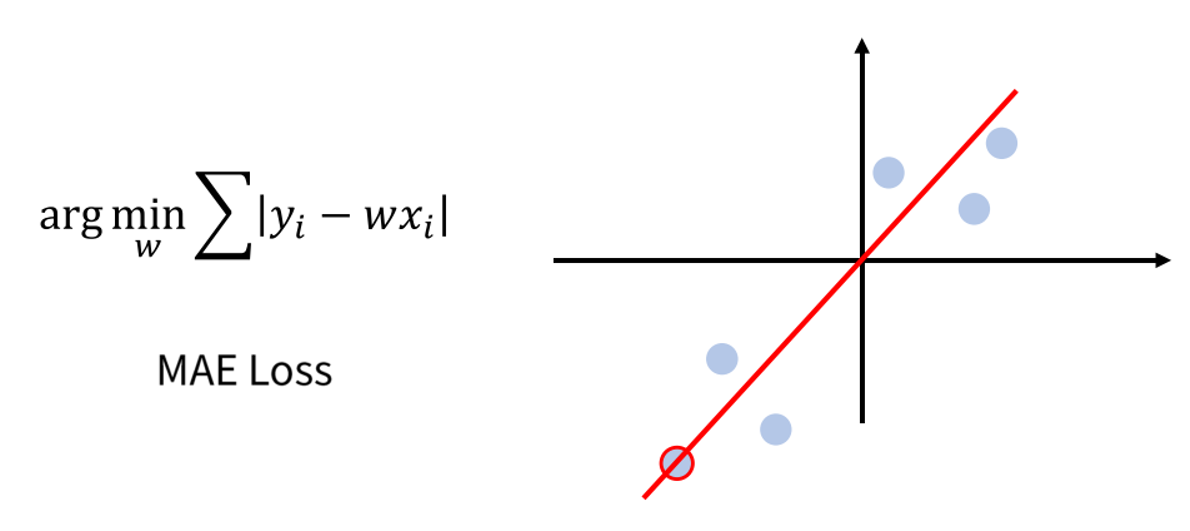
- 반면
MAE (Mean Absolue Error) Loss는 중앙값 (median)을 나타냅니다. 이는 outlier에 의한 평균의 오차를 개선하기 위하여 중앙값을 종종 쓰는데 이 때, 사용하는 중앙값과 뜻이 같습니다. - MAE에서는 에러가 커져도 동일한 페널티를 가집니다. 즉 outlier의 loss를 줄이는 것과 outlier가 아닌 것의 loss를 줄이는게 동일한 효과를 가지기 때문에 MSE처럼 outlier에 크게 반응하지 않습니다.
- 또한 데이터의 중앙값을 가지기 때문에 MAE에서는 추세선이 존재하는 정확한 값을 가집니다.
- 정리하면
MAE는 중앙값을 가지므로 Outlier에 강건한 특성이 있습니다.