ReLU6와 ReLU6를 사용하는 이유
2020, Jan 01
- 이번 글에서는 뉴럴 네트워크에서 사용되는 activation function 중에서
ReLU6에 대하여 다루어 보려고 합니다. - ReLU6는 기존의 ReLU에서 상한 값을 6으로 두는 것을 말합니다.
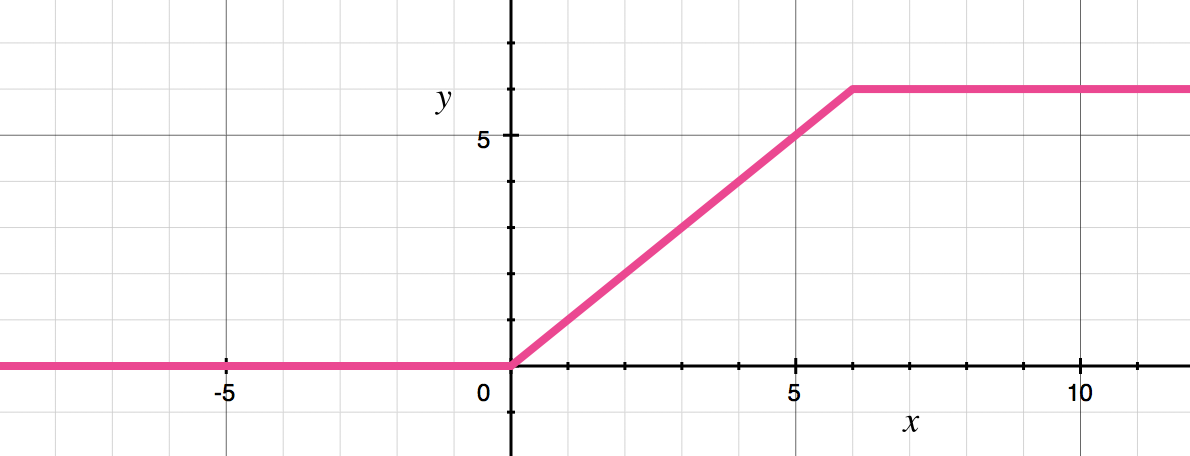
- 그래프로 나타내면 다음과 같습니다.

- 식으로 나타내면
min(max(0, x), 6)이 됩니다. 반면ReLU는max(0, x)가 됩니다. - 그러면 왜 upper bound를 주었는지와 왜 6을 주었는지에 대하여 궁금증이 발생할 수 있는데, 그 점에 대하여 이 글에서 간략하게 다루어 보겠습니다.
- 결론적으로 말하면 테스트 경과 학습 관점에서 성능이 더 좋았고 최적화 관점(fixed-point)에서도 더 좋았기 때문입니다.
- 먼저
fixed-point관점 입니다. - 딥러닝 모델 성능 최적화를 할 때 fixed-point로 변환해야 하는 경우가 있습니다. 특히 embedded 에서는 중요한 문제입니다.
- 만약 upper bound가 없으면 point를 표현하는 데 수많은 bit를 사용해야 하지만 6으로 상한선을 두게 된다면 최대 3 bit만 있으면 되기 때문에 상한선을 두는 것은 최적화 관점에서 꽤나 도움이 됩니다.
- 다음으로 AlexNet의 Alex Krizhevsky의 논문에 따라 설명해 보겠습니다. 딥러닝 프레임워크들에서도 공식적으로 이 논문의 논리에 따라서
ReLU6를 적용하였습니다. 즉, 상한선이 6인 ReLU만 따로 존재하는 이유입니다.- http://www.cs.utoronto.ca/~kriz/conv-cifar10-aug2010.pdf
- 이 논문에 따르면
ReLU에 상한선을 두게 되면 딥러닝 모델이 학습 할 때, sparse한 feature를 더 일찍 학습할 수 있게 된다는 이유로 상한선을 두었고 여러가지 테스트를 통해 확인해 보았을 때,6을 상한선으로 둔 것이 성능에 좋았기 때문에ReLU6를 사용했다는 것입니다. - 관련 내용은 논문을 통해 정확히 파악하길 권장드립니다.