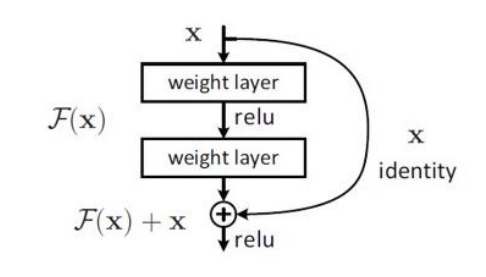
ResNet (Residual Network)
2017, May 03
- 이번 글에서는
Residual Network에 대하여 알아보겠습니다. 현재는 가장 기본이 되는 네트워크 중 하나인데, 처음에 나왔을 때에는 상당히 큰 성능 개선의 역할을 이루어 낸 중요한 뉴럴 네트워크입니다. 그러면resnet에 대하여 알아보도록 하겠습니다.
목차
-
ResNet 관련 배경
-
ResNet의 구조
-
Skip Connection
-
Bottleneck Architecture
-
Identity Mapping
-
pytorch 코드
ResNet 관련 배경
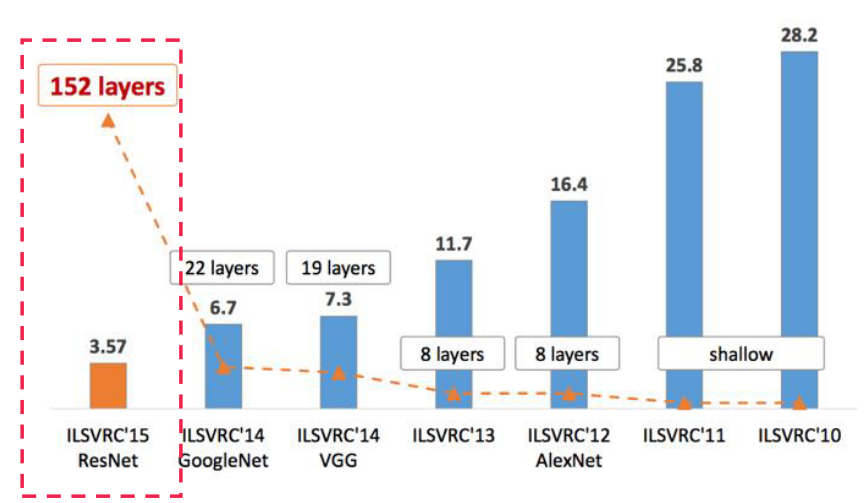
ResNet은 Kaimimg He의 논문에서 소개 되었는데 classification 대회에서 기존의 20계층 정도의 네트워크 수준을 152 계층 까지 늘이는 성과를 거두었고 위의 그래프와 같이 에러율 또한 3.57%로 인간의 에러율 수준 (약 5%)을 넘어서게 된 시점이 되겠습니다.- 여기서 2014년도의 VGG, GoogLeNet 같은 경우에는 레이어의 수가 20 내외 였는데, ResNet의 경우에는 152개로 7배 이상 레이어를 쌓는 결과를 보였습니다. 즉, ResNet 이전에는 레이어를 계속 쌓는 데 문제가 있었기 때문에 무한정 레이어를 쌓기 어려웠습니다. 하지만 ResNet에서 그 문제를 개선하였기 때문에 더 깊은 레이어로 성능을 낼 수 있었습니다.
ResNet의 구조
- 전체적인 ResNet의 구조를 먼저 살펴보겠습니다.
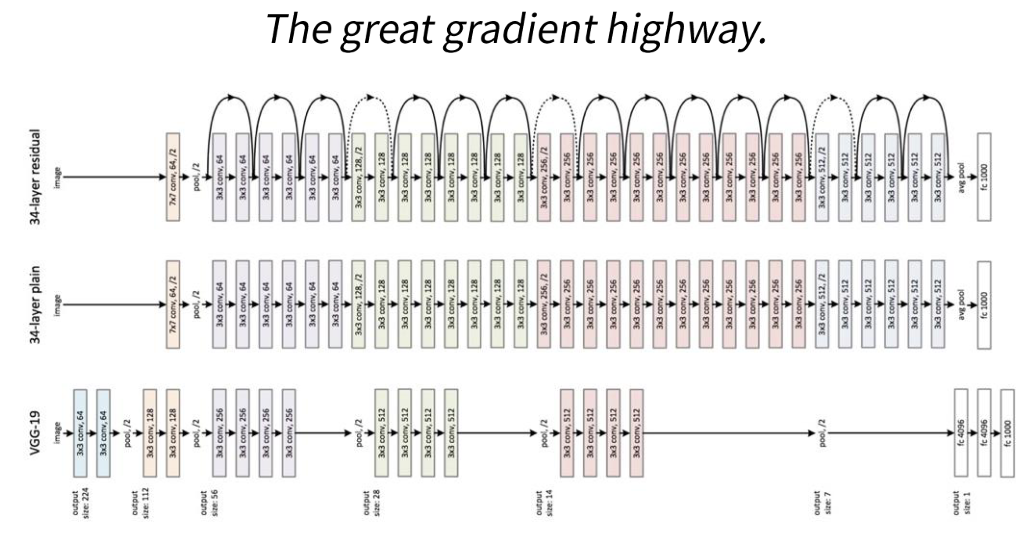
- 위 그림과 같이 ResNet은 레이어 사이 사이에 연결된 구조가 보이는 데 이것을
skip connection이라고 합니다. - 이것이 아주 중요한 역할을 하는데, 위 그림과 같이 great gradient highway 즉, gradient를 전달하기 위한 좋은 통로가 됩니다.
Skip Connection
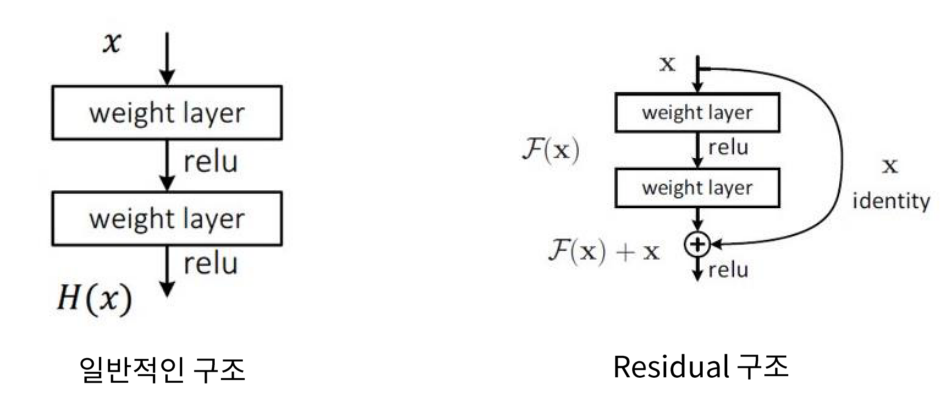
- 왼쪽이 일반적인 구조의 (convolutional) neural network 입니다. 입력이 들어오면 layer를 거쳐서 (e.g. convolution filter 와의 연산) activation이 적용되고 이러한 작업이 연속적으로 이루어 지는 것입니다.
- 반면 오른쪽의 Residual 구조에서는 입력을 출력과 더해주는 형태를 가지게 됩니다.
- 이 때, 입력에서 출력으로 그대로 더해지는 값을
identity라고 부릅니다.
- 이 때, 입력에서 출력으로 그대로 더해지는 값을
- 즉, 위의 형태는 처음 제안되었던 skip connection의 구조로 feature를 추출하기 전 후를 더하는 특징을 가지고 있습니다.
- 논문을 살펴보면 왼쪽의 일반적인 네트워크 구조에서 표현할 수 있는 것은 오른쪽의 Residual 구조에서 똑같이 표현할 수 있다고 잘 설명이 되어있으니 논문을 참조하시면 도움이 됩니다.
- 정리하면 Residual 구조에서는 인풋 \(x\)의 값 또한 그대로 전달 받기 때문에 입력의 더 작은 fluctuation 검출을 더 깊은 레이어에서도 가능하게 합니다. 즉, 작은 변화가 발생하여도 더 민감하게 반응해서 학습할 수 있다고 생각하셔도 됩니다.
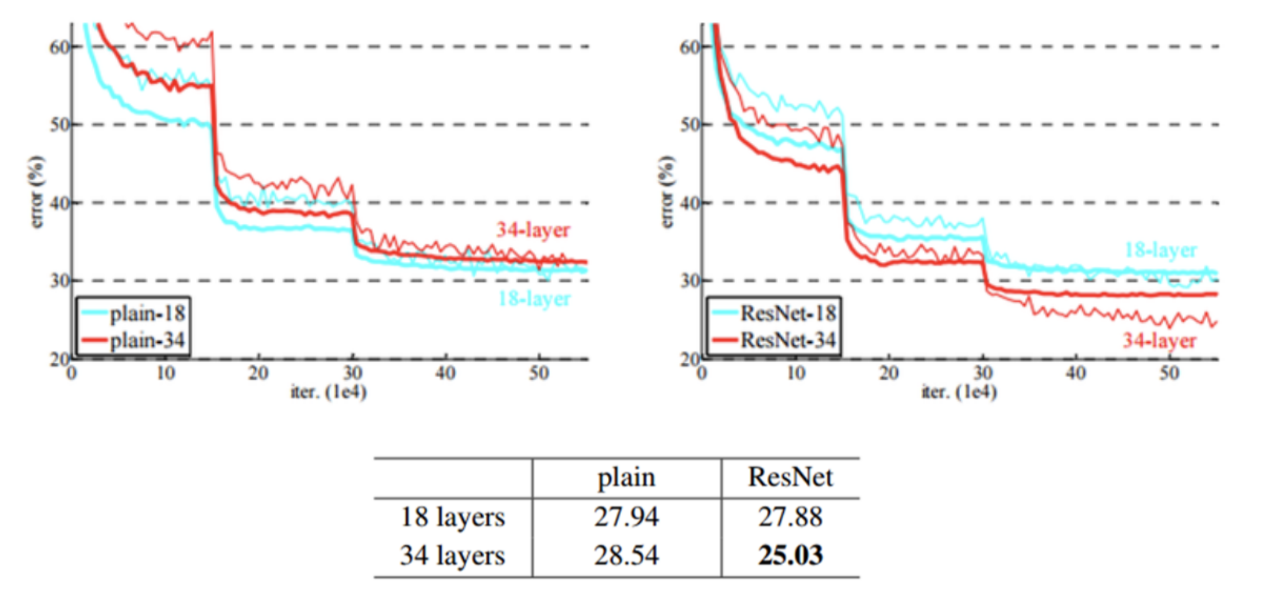
- 컨셉은 기존의 레이어가 깊어질수록 발생하는 Vanishing gradient 문제를 개선할 수 있는 path가 생겼고 따라서 입력의 작은 변화도 깊은 레이어에서 알아챌 수 있도록 한다는 것이었고 실제 실험의 결과에서 그것을 보여줍니다.
- 이론적으로는 레이어가 깊어질수록 고차원의 feature 들을 학습해 낼 수 있어서 classification 성능이 높아진다는 것이 알려져 있지만 일정 레이어 이상으로 깊이가 깊어지면 성능이 나빠지게 되어(Vanishing gradient 나 overfitting 문제) 레이어의 수를 제한적으로 사용해 왔습니다.
- 그것의 예로 위 왼쪽 그래프를 보면 34 레이어가 오히려 18 레이어 보다 성능이 나빠진 실험 결과를 볼 수 있지요.
- 하지만 Residual 구조로 인하여 위 실험과 같이 레이어의 깊이가 깊어짐에 따라서 모델의 성능이 더 좋아진 것을 확인할 수 있습니다.
- 즉 plain 한 모델의 경우에는 레이어가 일정 깊이 이상으로 깊어지면 학습이 안되었지만 Residual 구조에서는 레이어가 깊어져도 학습이 잘 되는 것을 확인할 수 있습니다.
Bottleneck Architecture
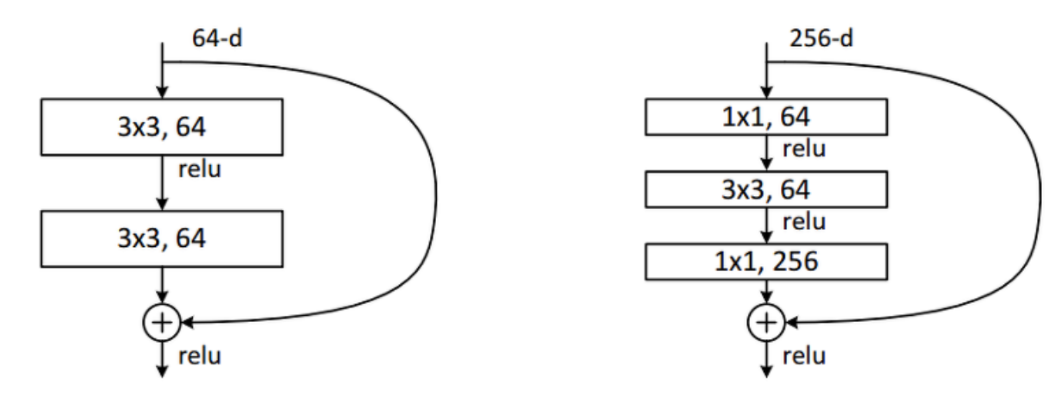
- 가장 기본적인 Residual 구조에서 조금 변형한 형태의
Bottleneck구조입니다. - Residual 구조에서
1x1 → 3x3 → 1x1구조를 이용하여 Bottleneck 구조를 만들어 내었고 Dimension의 Reduction과 Expansion 효과를 주어 연산 시간 감소 성능을 얻을 수 있습니다.
Identity Mapping
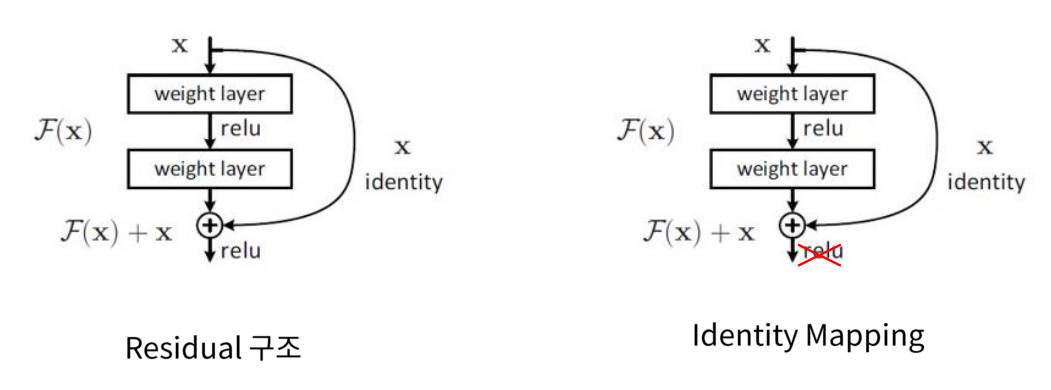
- 초기의 ResNet 논문이 나오고 나서 얼마 뒤 약간의 개선된 논문이 바로 나왔는데 Residual 구조가 조금 수정된 Identity Mapping 입니다.
- 기존에는 한 단위의 feature map을 추출하고 난 후에 activation function을 적용하는 것이 상식이었습니다.
- 하지만 개선된 구조에서는 네트워크 출력값과 identity를 더할 때 activation function을 적용하지 않고 그냥 더하는 구조를 가지게 됩니다.
- 대신에 identity는 변경사항은 없지만 네트워크에 변경을 주게 됩니다. 변경 사항은 다음과 같습니다.
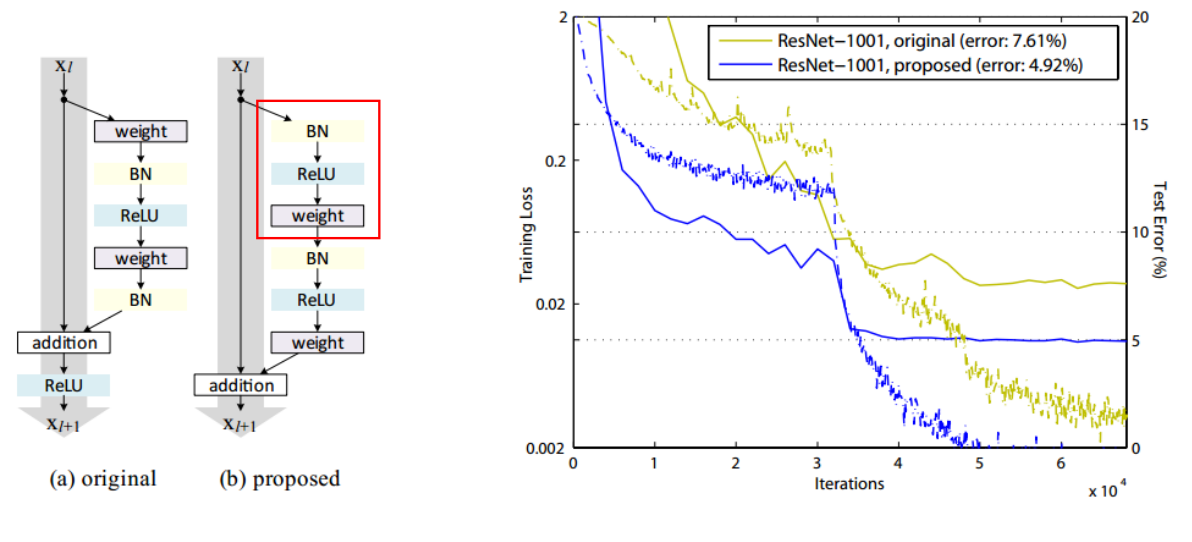
- 위 네트워크 구조에서
proposed라고 되어 있는 네트워크 구조가 개선된 구조이고 이것은Pre-Activation이라고 부르고 있습니다. - 즉, 개선된 구조에서는 네트워크의 처리 순서를
BN → ReLU → weight → BN → ReLU → weight로 변경하였습니다. - 실험 결과 기존의 ResNet보다 에러율도 더 낮아지고 학습도 더 잘되는 것으로 논문에서 나타납니다.
- 정리하면
Conv - BN - ReLU에서BN - ReLU - Conv구조로 변경한 것 만으로 성능이 개선되었고 후자에서는skip connection에 어떤 추가 연산도 없이 말 그대로Gradient Highway가 형성되어 극적인 효과를 얻게 되었습니다. - 그런데 이 구조는 사실 일반적인 통념과는 조금 다른 구조 입니다. 보통 Convolution 연산을 먼저 한 다음에 Batch Normalization과 Activation function을 적용하는데
Pre-Activation에서는 그 순서를 바꾸었습니다.
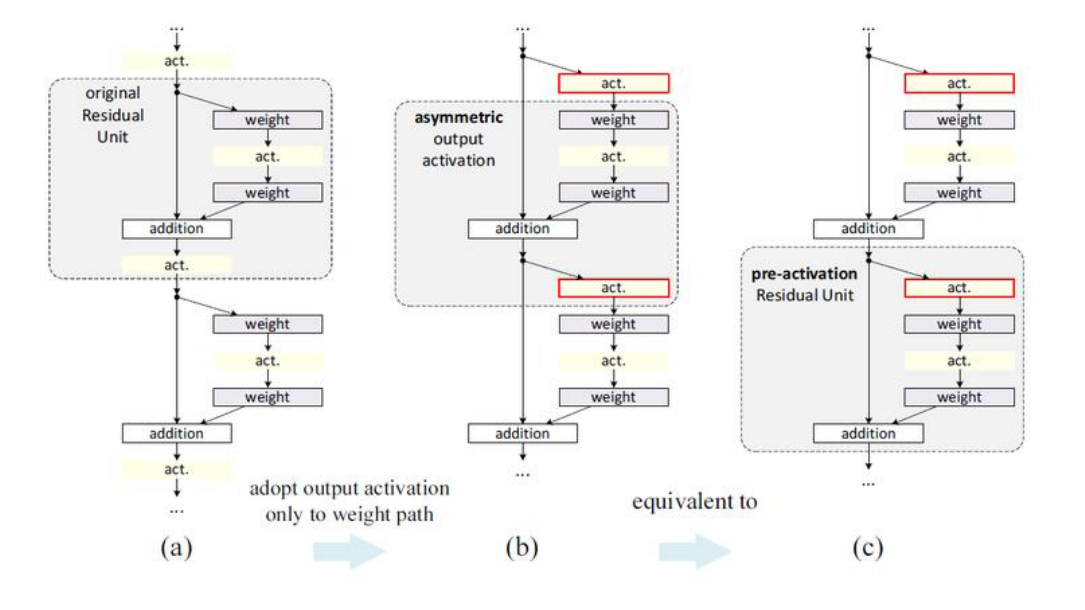
- 논문에서 설명하기로는 이러한 구조를 적용한 것이 asymmetric과 pre-activation 효과를 주기 위해서라고 설명하였습니다.
- 위 그림의 가장 왼쪽의 기존 Residual 구조이고 가운데 또는 오른쪽 그림 (두 개는 같지만 시점을 다르게 하였습니다.)은
Pre-Activation구조입니다. - 먼저 가운데 그림 시점에서
Pre-Activation을 보면 기존의 Residual 구조에 비해 비대칭적인 구조를 적용할 수 있어 네트워크에 다양성을 부과할 수 있고 - 오른쪽 그림 시점에서 보면 Activation function을 먼저 적용해 봄으로써 새로운 효과를 주어봤고 실제 성능이 좋았다 라고 설명합니다.
pytorch 코드
- 마지막으로 위에서 배운 내용을 다시 한번 정리하면서 pytorch 코드를 통하여 구현해 보도록 하겠습니다.
- 앞에서 배운 Residual 구조는 이전 단계에서 뽑았던 특성을 변형시키지 않고 그대로 뒤 레이어로 전달하기 때문에 입력단에서 뽑은 단순한 특성과 뒷부분에서 뽑은 복잡한 특성을 모둥 사용한다는 장점이 있습니다.
- 또한 더하기 연산은 역전파 계산을 할 때, 기울기가 1이기 때문에 손실이 줄어들거나 하지 않고 모델의 앞부분 까지 잘 전파하기 때문에, 학습 면에서도 GoogLeNet 처럼 보조 레이어가 필요하지 않습니다.
- 모델의 깊이는 VGG 네트워크보다 훨씬 더 깊어졌고 논문에서는 레이어를 152개 까지 사용하기도 하였습니다.
- 모델의 크기도 커짐에 따라 GoogLeNet의
1x1 convolution을 활용하였고 위에서 다룬 바와 같이 bottleneck이라고 이름을 붙였습니다. - 이번 코드에서는 완전히 vanilla 형태의 ResNet 보다는 좀 개선된 bottleneck이 적용된 ResNet을 구현해 보겠습니다.
- bottleneck은 먼저
1x1 convolution으로 채널 방향을 압축합니다. 그리고 이 압축된 상태에서3x3 convolution으로 추가 feature를 뽑아내고 다시1x1 convolution을 사용하여 채널의 수를 늘려줍니다.- 이렇게 함으로써 변수의 수를 줄이면서도 원하는 개수의 feature를 뽑을 수 있도록 합니다.
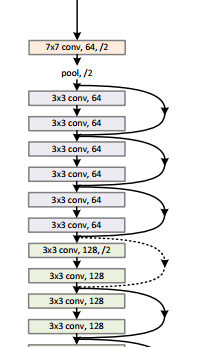
- 그리고 ResNet을 자세히 살펴보면 위와 네트워크와 같이 실선은 feature map의 가로 세로 해상도가 바뀌지 않는 경우이고 점선은 다운 샘플링으로 인하여 해상도가 바뀌는 경우입니다.
- 이 경우 이전 단계의 feature map이 가로 세로 방향으로 반 씩 줄어들게 됩니다.
- 먼저 기본적인 합성곱 블록을 구현해 보도록 하겠습니다.
- nn.Conv2d는 다음 링크를 참조하시기 바랍니다.
def conv_block_1(in_dim, out_dim, act_fn, stride = 1):
""" bottleneck 구조를 만들기 위한 1x1 convolution """
model = nn.Sequential(
nn.Conv2d(in_dim, out_dim, kernel_size = 1, stride = stride),
act_fn
)
return model
def conv_block_3(in_dim, out_dim, act_fn):
""" bottleneck 구조를 만들기 위한 3x3 convolution """
model = nn.Sequential(
nn.Conv2d(in_dim, out_dim, kernel_size = 3, stride = 1, padding = 1),
act_fn
)
class BottleNeck(nn.Module):
"""
Residual Network의 bottleneck 구조
- down 파라미터는 down 블록을 통과하였을 때, feature map의 크기가 줄어드는 지의 여부의 불리언 값 입니다.
- True인 경우 stride = 2가 되어 크기가 반으로 줄어듭니다.
- 경우에 따라서 채널의 갯수가 달라 더해지지 않는 경우가 있는데, 이럴 때는 차원을 맞춰 주는 1x1 conv를 추가하여
입력의 채널을 출력의 채널과 같게 만들어 줍니다.
"""
def __init__(self, in_dim, mid_dim, out_dim, act_fn, down=False):
super(BottleNeck, self).__init__()
self.act_fn = act_fn
self.down = down
if self.down:
self.layer == nn.Sequential(
conv_block_1(in_dim, mid_dim, act_fn, 2),
conv_block_3(mid_dim, mid_dim, act_fn),
conv_block_1(mid_dim, out_dim, act_fn)
)
self.downsample = nn.Conv2d(in_dim, out_dim, 1, 2)
else:
self.layer = nn.Sequential(
conv_block_1(in_dim, mid_dim, act_fn),
conv_block_3(mid_dim, mid_dim, act_fn),
conv_block_1(mid_dim, out_dim, act_fn)
)
# shape을 맞추기 위한 1x1 conv
self.dim_equalizer = nn.Conv2d(in_dim, out_dim, kernel_size = 1)
def forward(self, x):
if self.down:
downsample = self.downsample(x)
out = self.layer(x)
out = out + downsample
else:
out = self.layer(x)
if x.size() is not out.size():
x = self.dim_equalizer(x)
out = out + x
return out
class ResNet(nn.Module):
""" ResNet 50 layer """
def __init__(self, base_dim, num_classes = 2):
super(ResNet, self).__init__()
self.act_fn = nn.ReLU()
self.layer_1 = nn.Sequential(
nn.Conv2d(3, base_dim, 7, 2, 3),
nn.ReLU(),
# nn.MaxPool2d(kernel_size, stride, padding)
nn.MaxPool2d(3, 2, 1),
)
self.layer_2 = nn.Sequential(
# BottleNeck(in_dim, mid_dim, out_dim, act_fn, down)
BottleNeck(base_dim, base_dim, base_dim * 4, self.act_fn),
BottleNeck(base_dim * 4, base_dim, base_dim * 4, self.act_fn),
BottleNeck(base_dim * 4, base_dim, base_dim * 4, self.act_fn, down = True),
)
self.layer_3 = nn.Sequential(
BottleNeck(base_dim * 4, base_dim * 2, base_dim * 8, self.act_fn),
BottleNeck(base_dim * 8, base_dim * 2, base_dim * 8, self.act_fn),
BottleNeck(base_dim * 8, base_dim * 2, base_dim * 8, self.act_fn),
BottleNeck(base_dim * 8, base_dim * 2, base_dim * 8, self.act_fn, down = True),
)
self.layer_4 = nn.Sequential(
BottleNeck(base_dim * 8, base_dim * 4, base_dim * 16, self.act_fn),
BottleNeck(base_dim * 16, base_dim * 4, base_dim * 16, self.act_fn),
BottleNeck(base_dim * 16, base_dim * 4, base_dim * 16, self.act_fn),
BottleNeck(base_dim * 16, base_dim * 4, base_dim * 16, self.act_fn),
BottleNeck(base_dim * 16, base_dim * 4, base_dim * 16, self.act_fn),
BottleNeck(base_dim * 16, base_dim * 4, base_dim * 16, self.act_fn, act_fn = True),
)
self.layer_5 = nn.Sequential(
BottleNeck(base_dim * 16, base_dim * 8, base_dim * 32, self.act_fn),
BottleNeck(base_dim * 32, base_dim * 8, base_dim * 32, self.act_fn),
BottleNeck(base_dim * 32, base_dim * 8, base_dim * 32, self.act_fn),
)
self.avgpool = nn.AvgPool2d(7, 1)
self.fc_layer = nn.Linear(base_dim * 32, num_classes)
def forward(self, x):
out = self.layer_1(x)
out = self.layer_2(out)
out = self.layer_3(out)
out = self.layer_4(out)
out = self.layer_5(out)
out = self.avgpool(out)
out = out.view(out.size(0), -1)
out = self.fc_layer(out)
return out