In Defense of the Unitary Scalarization for Deep Multi-Task Learning 리뷰
2022, Dec 20
- 논문 : https://arxiv.org/pdf/2201.04122.pdf
- NIPS 2022에서 발표한
MTL (Multi-Task Learning)관련 논문이며 분석의 방법이 꽤 재미있어서 글을 작성하였습니다. - 논문에서 말하고자 하는 목적은
MTL에서 각 Task의 Loss를 단순히 더하는 방법인Unitary Scalarization방식이 꽤 좋은 방법임을 실험적으로 주장합니다.
- 본 실험의 용어 및 조건을 설명하면 다음과 같습니다.
MTL은 m 개의 Task를 한번에 학습하는 방식을 의미합니다.
- \[\{ \mathcal L_{i}(\theta) \vert \forall i \in \{1, ... , m \} \}\]
MTL을 적용하는 방식은 간단한hard parameter sharing방식을 사용합니다. 이 방식은 각 Task 모두가 공유하는MTL의head를 공유하는 방식이며head이외의 부분은 독립적으로 사용하는 방식을 의미합니다.- 완전히 독립적으로 구분된다는 의미에서
hard parameter라는 용어를 사용합니다. - 이 때, 풀고자 하는 문제는 각 Task의 성능이 잘 나올 수 있도록 하는 것입니다.
- 본 논문에서 기준으로 삼는
Unitary Scalarization은 방식을 식으로 나타내면 다음과 같으며 간단히 모든 Task의 Loss를 더한다는 뜻입니다.
- \[\underset{\theta}{\text{min}} [\mathcal L^{\text{MT}}(\theta) := \sum_{i \in \tau}\mathcal L_{i}(f(\theta, X, i), Y) ]\]
- \[\mathcal L_{\text{MTL}} = \sum_{i=1}^{N} \mathcal L_{\text{task}_i}\]
- 이 방식은 구현하기가 매우 쉽고 단순히
gradient를 합하는 방식이기 때문에 연산 과정도 단순합니다. - 이 방식이 쉬운 반면
MTL학습에 불리하다는 의견이 있어 더 나은 방식이 연구되었으나 본 논문에서는 학습에 불리하지 않다고 설명합니다.
- 기존에
Unitary Scalarization이MTL학습에 불리함을 개선하기 위하여 다양한 학습 방식이 연구되어 왔고 대표적으로 다음과 같은 방식이 있습니다.GradNorm: https://arxiv.org/abs/1711.02257Multi-Task Learning Using Uncertainty to Weigh Losses for Scene Geometry and Semantics: https://arxiv.org/abs/1705.07115Gradient Surgery for Multi-Task Learning: https://arxiv.org/abs/2001.06782
- 본 논문에서는
Unitary Scalarization와 비교를 위하여IMTL,MGDA,GradDrop,PCGrad,RLW Diri,RLW Norm이 사용됩니다. - 본 글에서 각 방식을 설명하지는 않겠습니다만 각 방식은
Unitary Scalarization에 비하여 구현이 복잡하며 방법에 따라서 각 Task 별 Gradient를 모두 구해야 해서 학습 시간도 오래 걸리는 경우도 흔합니다.
- 먼저
CelebA데이터셋에 대한 평가 결과 입니다.
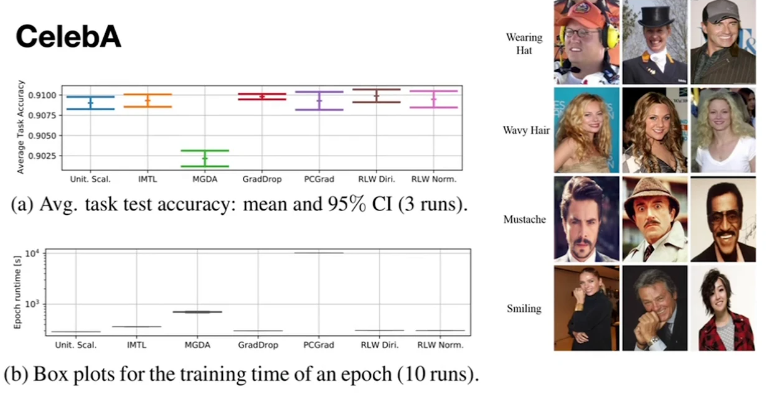
CelebA는 유명인사의 이미지 데이터셋이 있으며 40 종류의binary classification문제가 존재합니다. 이 각각의 binary classification 문제를 모두 풀고 평균을 낸 수치가 위 그래프와 같습니다.- 수치 결과를 살펴보면
Unitary Scalarization을 성능과 학습 시간면에서 압도하는 학습 방식은 없는 것을 실험적으로 확인하였습니다.
- 다음은
cityscapes데이터셋으로semantic segmentation과depth estimation의MTL성능 비교 입니다.

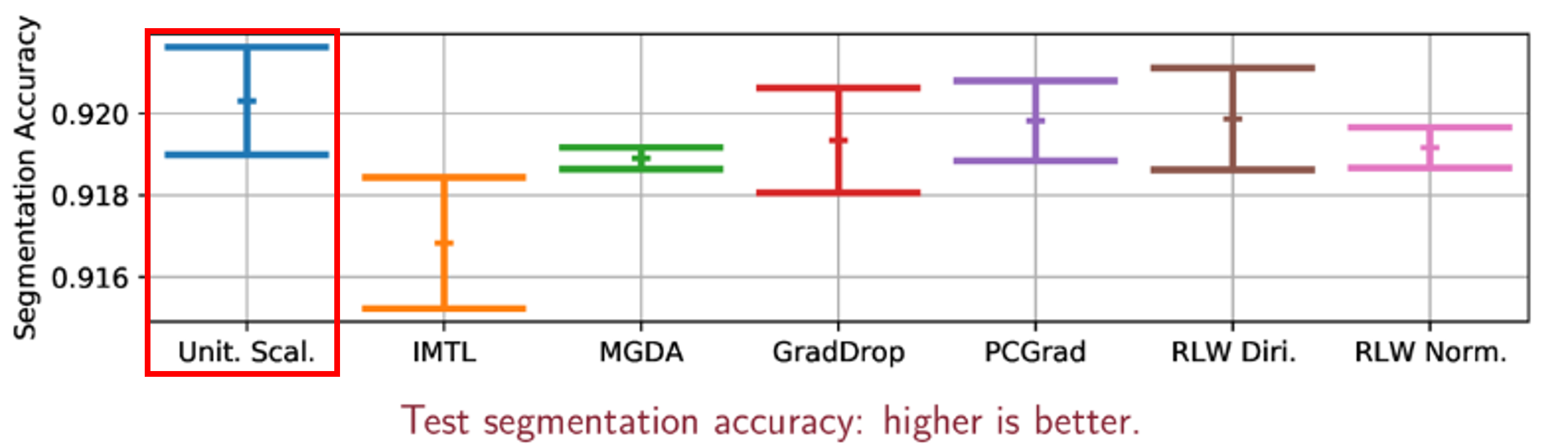
Absolute Depth Error와Relative Depth Error는 작은 값이 좋으며 실험한 학습 방식 중 중간 보다 좋은 방식으로 판단됩니다.Segmentation mIOU와Segmentation Accuracy는 큰 값이 좋으며 실험한 학습 방식 중 중간 보다 좋은 방식으로 봐집니다.- 따라서
Unitary Scalarization방식을 압도하는 학습 방식은 없었음을 확인하였습니다. - 반면 학습 시간 관점에서는 추가적인 계산이 필요없기 때문에 효율적인 것을 확인하였습니다.
- 지금까지 Supervised Learning 기반의 MTL 예시를 살펴보았습니다. 추가적으로 Reinforcement Learning 에서의 MTL 예시를 살펴보겠습니다.
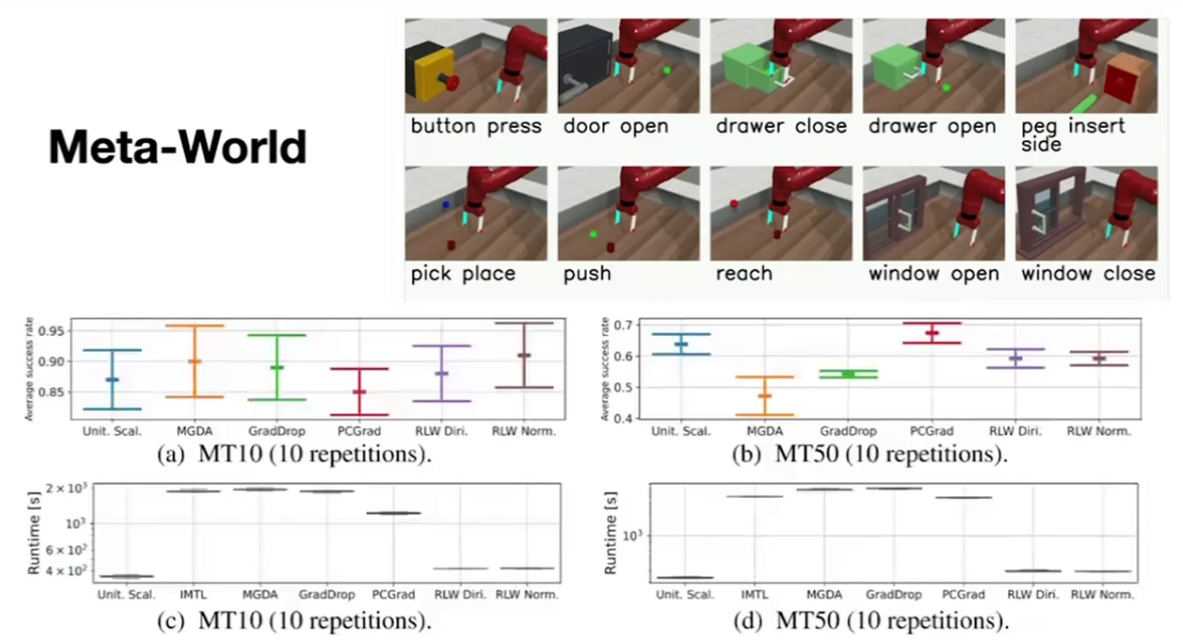
- 위 실험에서
MT10은 10 개의 Task를 사용한 케이스이고MT50은 50 개의 Task를 사용한 케이스 입니다.MT10에서Unitary Scalarization은 중간 정도의 성능이고MT50은 2번쨰로 높은 성능을 가집니다. - 반면
Runtime에서Unitary Scalarization은 가장 효율적이므로 Reinforement Learning 에서도Unitary Scalarization를 압도하는 학습 방법은 없는 것을 확인할 수 있었습니다.