
(Pytorch) MLP로 Image Recognition 하기
2019, May 19
- 이번 글에서는 Image Recognition을 위한 기본 내용 부터 필요한 내용까지 전체를 다루어 볼 예정입니다.
MNIST데이터셋 이미지 인식을 먼저 실습해 보겠습니다.- 다음 글에서는 좀 더 이미지를 잘 분석하기 위하여 Convolutional Neural Network 구조를 사용해 보겠습니다.
- 그 다음 글에서는 좀 더 다양한 이미지를 분석 하기 위하여
CIFAR10이미지를 분석해 보겠습니다. - 마지막으로
Transfer learning을 이용하여 성능을 더 향상시켜보도록 하겠습니다.
- 전체 코드
Fashion MNIST 데이터를 Naive 하게 학습하기
- 먼저 다음과 같이 필요한 라이브러리를 import합니다.
import torch
from torch import nn, optim
import torch.nn.functional as F
import matplotlib.pyplot as plt
import numpy as np
from torchvision import datasets, transforms
from tqdm import tqdm
- 다음으로 데이터 셋을 받기 위한 설정을 한 뒤 데이터를 로컬에 받습니다.
# 데이터 셋을 받을 때 transform할 조건을 설정합니다.
mean = 0.5
sigma = 0.5
transform = transforms.Compose([transforms.ToTensor(), # 데이터를 불러 올 때 Tensor 타입으로 불러옵니다.
transforms.Normalize([mean], [sigma]) # 앞의 괄호는 평균, 뒤의 괄호는 표준편차이며 세 차원 모두 적용
])
# root경로에 train 데이터를 다운 받습니다. 이 때 조건은 transform 조건에 따라 Tensor 타입과 Normalize가 된 상태로 받습니다.
training_dataset = datasets.FashionMNIST(root="./data", train=True, download=True, transform=transform)
# Dataloader를 정의합니다. Dataloader에서는 batch size와 shuffle을 세팅해줍니다.
training_loader = torch.utils.data.DataLoader(dataset=training_dataset, batch_size=100, shuffle=True)
- 위 옵션으로 데이터를 받으면 학습에 편리하도록 값을 변형해서 받는 것이지 시각화 하기에는 적합하지 않습니다.
- 아래 코드는 시각화 하기 좋도록 image를 복사한 뒤 차원을 (H, W, C)순서로 변형하고 Normalize 하기 전 값으로 복원합니다.
- 시각화 할 때 사용하면 되고 학습에는 전혀 상관없으므로 무시하셔도 되는 코드입니다.
# Tensor 형태의 이미지 데이터를 원래 데이터로 바꿉니다.
def imgConvert(tensor, mean, sigma):
# tensor를 복사하고 그래프와 독립적으로 분리한 다음 numpy로 변형합니다.
image = tensor.clone().detach().numpy()
# Pytorch에서 제공하는 (H, W, C) 순서의 차원을 (H, W, C)로 변경합니다.
image = image.transpose(1, 2, 0)
# Normalize한 이미지 데이터를 원상 복귀 합니다.
image = image * sigma + mean
# 이미지의 범위를 0과 1 사이로 고정시킵니다.
image = image.clip(0, 1)
return image
- 앞의 코드를 보면
training_loader를 선언할 때 batch_size = 100 으로 설정하였습니다. - 다음 코드를 보면 batch의 크기만큼 generator가 이미지를 불러오는 것을 확인할 수 있습니다.
dataiter = iter(training_loader)
images, labels = dataiter.next()
>> print(images.shape)
torch.Size([100, 1, 28, 28]) # (배치사이즈, 채널수, 높이, 너비)
- 다음 코드는 Neural Network를 만드는 클래스 입니다.
- 아래 코드는 간단한 Neural Network로 hidden layer가 1개인 간단한 구조 입니다.
# Neural Network Class
class Classifier(nn.Module):
def __init__(self, D_in, H1, H2, D_out):
super().__init__()
self.linear1 = nn.Linear(D_in, H1)
self.linear2 = nn.Linear(H1, H2)
self.linear3 = nn.Linear(H2, D_out)
def forward(self, x):
x = F.relu(self.linear1(x))
x = F.relu(self.linear2(x))
x = self.linear3(x)
return x
- 위에서 선언한 클래스로 Neural Network 객체를 생성합니다.
model = Classifier(784, 125, 65, 10)
- 학습에 사용할 loss function을 만듭니다.
- 대표적으로 많이 사용하는 Cross Entropy를 사용하겠습니다.
loss_func = nn.CrossEntropyLoss()
- optimizer 또한 학습이 잘 되는 Adam을 사용하도록 하겠습니다.
- learning rate는 0.001로 잡았습니다.
optimizer = optim.Adam(model.parameters(), lr=0.001)
- 이제 본격적으로 학습하기 위하여 아래와 같이 training과 validation의 loss와 accuracy를 저장할 리스트를 생성합니다.
epochs = 12
# 학습 데이터의 loss를 저장
running_loss_history = []
# 학습 데이터의 accuracy를 저장
running_corrects_history = []
# 평가 데이터의 loss를 저장
val_running_loss_history = []
# 평가 데이터의 accuracy를 저장
val_running_corrects_history = []
- 아래 코드와 같이 학습을 진행합니다. 코드 상세 내용은 주석을 읽어보시면 이해가 될것입니다.
for epoch in tqdm(range(epochs)):
running_loss, val_running_loss = 0.0, 0.0
running_corrects, val_running_corrects = 0.0, 0.0
# 학습 데이터를 batch 단위로 가져와서 학습시킵니다.
for inputs, labels in training_loader:
# (배치사이즈, 1*28*28)로 reshape 합니다.
inputs = inputs.view(inputs.shape[0], -1)
# feedforward
outputs = model(inputs)
# loss를 계산합니다.
loss = loss_func(outputs, labels)
# gradient 초기화
optimizer.zero_grad()
# backpropagation
loss.backward()
# weight update
optimizer.step()
# output의 각 이미지 별로 class가 가장 큰 값을 가져옵니다.
_, preds = torch.max(outputs, 1)
# loss를 더해줍니다.
running_loss += loss.item()
# 분류가 잘 된 갯수를 더해줍니다.
running_corrects += torch.sum(preds == labels.data)
# epoch의 loss를 계산합니다.
epoch_loss = running_loss/len(training_loader)
running_loss_history.append(epoch_loss)
# epoch의 accuracy를 계산합니다.
epoch_acc = running_corrects/len(training_loader)
running_corrects_history.append(epoch_acc)
# 평가 데이터를 feedforward할 때에는 gradient가 필요없습니다.
with torch.no_grad():
for val_inputs, val_labels in validation_loader:
# training 과정과 유사하나 학습이 필요없으므로 backprob하고 weight 업데이트 하는 과정이 없습니다.
val_inputs = val_inputs.view(val_inputs.shape[0], -1)
val_outputs = model(val_inputs)
val_loss = loss_func(val_outputs, val_labels)
_, val_preds = torch.max(val_outputs, 1)
val_running_loss += val_loss.item()
val_running_corrects += torch.sum(val_preds==val_labels.data)
# 평가 데이터의 loss와 accuracy를 저장해줍니다.
val_epoch_loss = val_running_loss / len(validation_loader)
val_running_loss_history.append(val_epoch_loss)
val_epoch_acc = val_running_corrects / len(validation_loader)
val_running_corrects_history.append(val_epoch_acc)
# 매 epoch의 학습과 평가가 끝났으면 결과를 출력해줍니다.
print('training loss : {:4f}, acc : {:4f}, validation loss : {:4f}, acc : {:4f}'.format(
epoch_loss, epoch_acc, val_epoch_loss, val_epoch_acc))
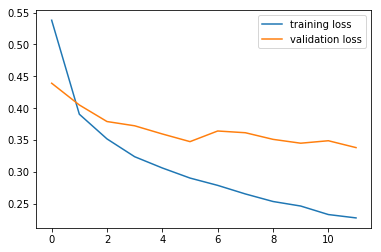
- 학습이 완료되면 training과 validation의 loss와 accuracy를 보고 학습이 잘 되었는지, 오버피팅은 이루어지지 않았는지 확인해 봅니다.
plt.plot(running_loss_history, label='training loss')
plt.plot(val_running_loss_history, label='validation loss')
plt.legend()
- loss를 보면 epoch의 수가 작아서 그런지 오버핏이 조금 발생한 것을 볼 수 있습니다.
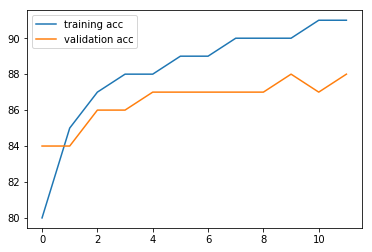
- 이번에는 accuracy를 한번 보겠습니다.
plt.plot(running_corrects_history, label='training acc')
plt.plot(val_running_corrects_history, label='validation acc')
plt.legend()
- 마지막으로 학습을 완료한 파일은 다음과 같이 저장 및 로드 할 수 있습니다.
# 마지막으로 학습을 완료한 모델을 저장합니다.
torch.save(model, 'mlp.pt')
# 저장한 모델은 다음과 같이 load 할 수 있습니다.
model = torch.load('mlp.pt')
>> model.eval()
Classifier(
(linear1): Linear(in_features=784, out_features=125, bias=True)
(linear2): Linear(in_features=125, out_features=65, bias=True)
(linear3): Linear(in_features=65, out_features=10, bias=True)
)