
albumentation을 이용한 이미지 augmentation
2021, Apr 30
- 참조 : https://youtu.be/c3h7kNHpXw4
- 참조 : https://youtu.be/rAdLwKJBvPM?list=PLhhyoLH6IjfxeoooqP9rhU3HJIAVAJ3Vz
- 참조 : https://github.com/albumentations-team/albumentations
- 참조 : https://albumentations.ai/docs/
- 참조 : https://hoya012.github.io/blog/albumentation_tutorial/
목차
-
albumentation 설치
-
albumentation 이란
-
albumentation의 기본적인 사용 방법
-
albumentation의 pytorch에서의 사용 방법
-
albumentation 사용 시 tip
-
멀티 데이터 셋의 albumentation 적용
-
자주 사용하는 이미지 segmentation augmentation 리스트
albumentation 설치
- albumentation은 python 3.6 버전 이상을 사용하여야 하며
pip를 통하여 다음과 같이 설치 하기를 권장합니다.-U는 최신 버전을 받기 위하여 지정하였습니다.- 명령어 :
pip install -U albumentations
- 명령어 :
- albumentation을 위한 전체 document는 아래 링크를 참조하시면 됩니다.
- albumentation은 pytorch의
DataSet과DataLoader의 역할을 합니다. 따라서 이 2가지 기능에 대해서는 반드시 숙지하시길 바랍니다.
albumentation 이란
albumentation은 이미지 augmentation을 쉽고 효율적으로 할 수 있도록 만든 라이브러리 입니다.- 딥러닝 기반의 이미지 어플리케이션을 개발할 때에는 제한된 학습 이미지로 인하여 augmentation은 필수적으로 사용하고 있습니다. Pytorch를 기준으로 예시를 들면 torchvision이라는 패키지를 이용하여 다양한 transform을 할 수 있도록 지원하고 있습니다.
- 이번 글에서 설명할
albumentation은 torchvision에서 지원하는 transform 보다 더 효율적이면서도 다양한 augmentation 기법을 지원합니다.
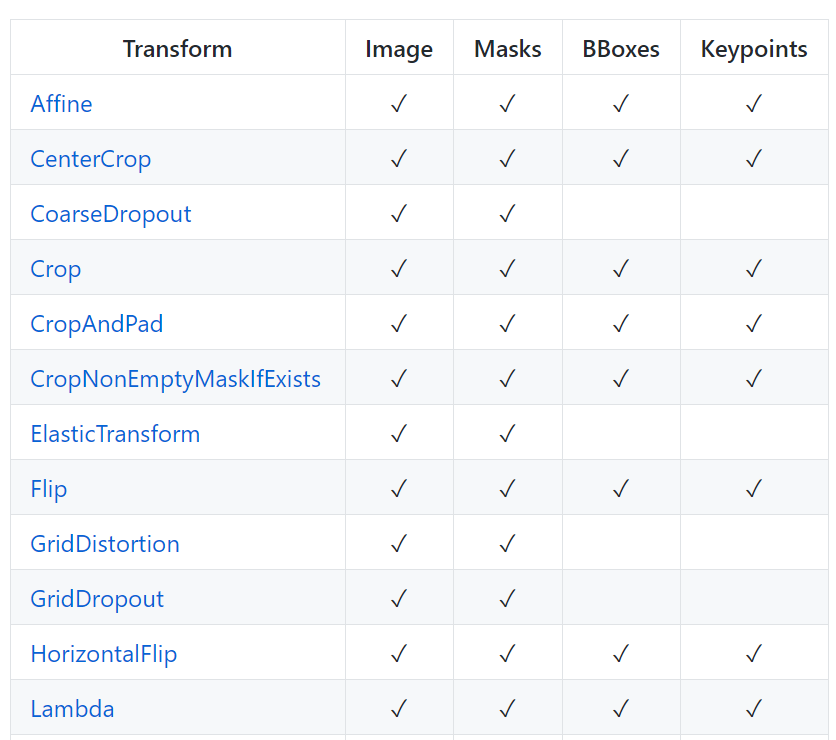
- 뿐만 아니라 이미지 기반 딥러닝 어플리케이션 중 대표적인 세그멘테이션(Masks), 2D object detection(BBoxes) 그리고 Keypoints를 자동으로 augmentation에 적용시켜 줍니다.
- 예를 들어 위 예제와 같이 Crop을 하면 Mask 또한 Crop이되고 BBox와 Keypoint 또한 Crop을 반영한 좌표가 적용됩니다. 이 점을 잘 이용하면 굉장히 쉽게 augmentation을 적용할 수 있습니다.
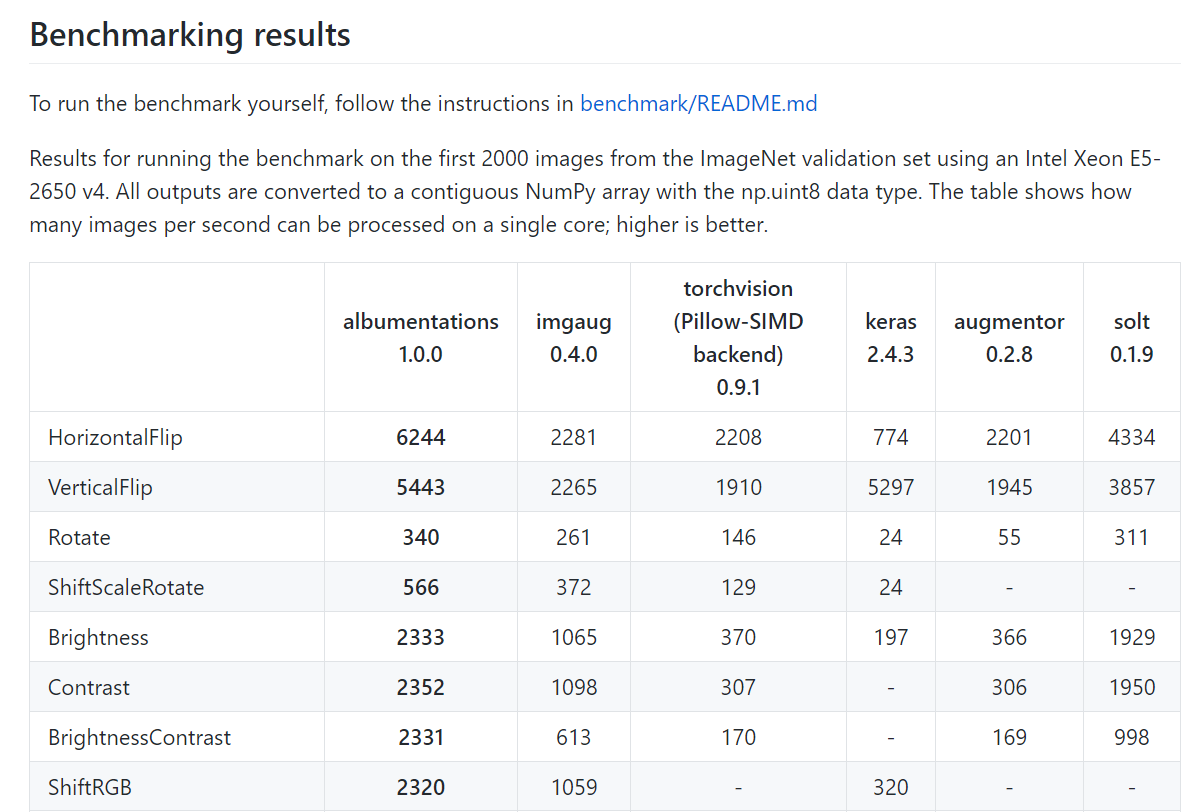
- 위 수치는 벤치마크를 이용하여 Intel Xeon E5-2650 v4 CPU에서 초당 얼만큼의 이미지를 처리할 수 있는 지 나타냅니다. 초당 처리할 수 있는 이미지의 양이기 때문에 숫자가 클 수록 성능이 더 좋다고 말할 수 있습니다.
- albumentation은 다른 패키지에서 제공하지 않는 augmentation 방법을 지원할 뿐 아니라 같은 방법이라도 초당 더 많은 augmentation 성능을 확보하였습니다.
albumentation의 기본적인 사용 방법
-
이번 글에서는 albumentation을 사용하는 방법과 pytorch에서는 어떻게 사용하는 지 알아보고 자주 사용하는 이미지 augmentation에 대하여 하나씩 살펴보겠습니다. 특히
semantic segmentation task를 기준으로 글을 작성할 예정임 처리 순서는 다음과 같습니다. - ①
opencv를 이용하여 이미지와 라벨을 불러 옵니다. (필요 시, BGR → RGB로 변환합니다.) - ②
transform = A.Compose([])을 이용하여 이미지와 라벨 각각에 Augmentation을 적용하기 위한 객체를 생성합니다. - ③
augmentations = transform(image=image, mask=mask)를 이용하여 실제 Augmentation을 적용합니다. - ④
augmentation_img = augmentations["image"]를 이용하여 Augmentation된 이미지를 얻을 수 있습니다. - ⑤
augmentation_mask = augmentations["mask"]를 이용하여 Augmentation된 마스크를 얻을 수 있습니다.
- 아래 코드에서 사용된 샘플 이미지는 다음 링크에서 받을 수 있습니다.
{kind=link}
{kind=link}
import albumentations as A
import cv2
image = cv2.imread("city_image.png")
mask = cv2.imread("city_mask.png")
height = 150
width = 300
# Declare an augmentation pipeline
transform = A.Compose([
A.Resize(height=height, width=width),
A.RandomResizedCrop(height=height, width=width, scale=(0.3, 1.0)),
])
augmentations = transform(image=image, mask=mask)
augmentation_img = augmentations["image"]
augmentation_mask = augmentations["mask"]
cv2.imwrite("city_image_augmented.png", augmentation_img)
cv2.imwrite("city_mask_augmented.png", augmentation_mask)

- 위 코드에서 사용된
RandomResizedCrop을 통하여 원본 영상이 resize 된 것을 알 수 있습니다. - segmentation에서 사용되는
mask는 각 픽셀 별 클래스 정보를 나타내므로 1 채널 8bit 이미지이지만 시각화를 위하여 컬러 이미지를 사용하였습니다. - 여기서 핵심은
augmentations = transform(image=image, mask=mask)입니다.image와mask에 해당하는 데이터를 단순히transform의image와mask라는 파라미터로 넘겨주기만 하면 segmentation 목적에 맞게 data가 변형됩니다. 이 점이 바로albumentation의 핵심이라고 말할 수 있습니다. - 기본적으로
image는bilinear interpolation이 적용되어 이미지의 사이즈가 변형이 되고mask는nearest가 적용이 되어 이미지의 사이즈가 변형이 됩니다.
albumentation에서 다루고 있는 대표적인 Task는segmentation,2d detection,keypoints estimation이며 PyConBy 20에서 설명한 슬라이드를 통해 간단히 사용법을 살펴보면 아래와 같습니다.
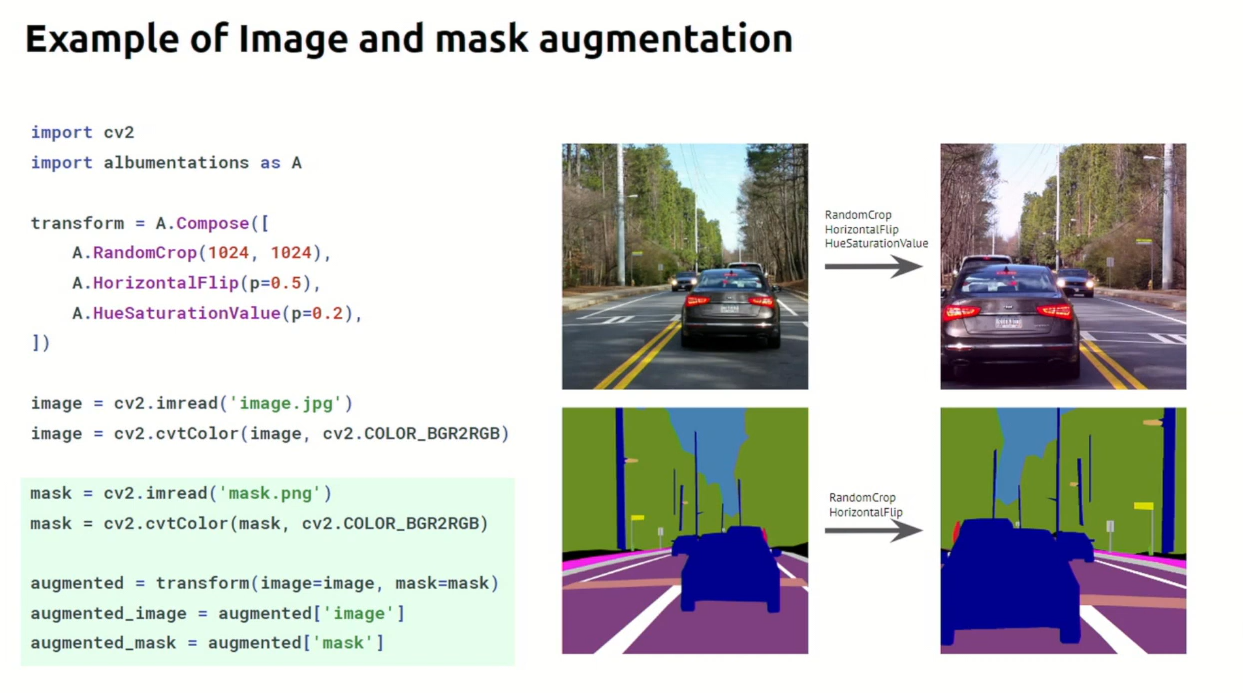
- 먼저
segmentation의 경우 앞에서 설명한 것과 같으며 아래 코드에서의 핵심은transform(image=image, mask=mask)부분이 됩니다.
- 다음으로
2d detection의 경우 먼저transform을 선언할 때, 어떤 형식으로 좌표값을 입력하였는 지 정해주어야 합니다. 따라서 아래 코드와 같이transform선언 시bbox_params={'format', : 'coco'}와 같은 형태로 어떤 오픈 데이터셋의 포맷을 따랐는 지 정해줍니다. 2d detection의 경우transform(image=image, bboxes=bboxes)과 같이bboxes라는 옵션을 사용하면 augmentation 방법에 따라 자동적으로 bbox의 값이 변경됩니다.

keypoints estimation의 경우2d detection사례와 사용 방법이 유사합니다.transform선언 시keypoint_params={'format' : 'xy'}과 같이 데이터셋의 포맷을 입력하고transform(image=image, keypoints=keypoints)와 같이keypoints라는 옵션을 사용하여 augmentation 방법에 따라 자동적으로 keypoint값이 변경되도록 설정해줍니다.

albumentation의 다양한 augmentation 기법은 공식 문서를 통해 확인이 가능하며 대략적으로 아래와 같은 범주로 augmentation을 지원합니다.

- 다양한 augmentation 방법을
A.Compose()로 묶어서transform을 생성합니다. 여러가지 방법을 조합하는 방법은 다음과 같습니다.

- 위 예시에서 다양한 augmentation 방법이 List 형식으로 차례대로 이어져 있습니다.
- 여기서
A.OneOf라는 방법을 살펴보면A.OneOf([...])의 List에 있는 방법 중 하나가 적용된다는 의미입니다. 이 때, 각 augmentation의 발생 확률을 상세하게 정할 수 있어 어떤 augmentation이 좀 더 잘 선택 될수 있도록 할 수도 있습니다. 만약A.OneOf([...], p)와 같이A.OneOf자체에p값을 입력하면A.OneOf자체가 적용될 확률 또한 적용할 수 있습니다.
albumentation의 pytorch에서의 사용 방법
albumentation을 pytorch에서 사용하려면 augmentation이 적용된 데이터 타입을torch로 변환을 해야 합니다.from albumentations.pytorch import ToTensorV2를 import 한 다음에ToTensorV2를A.Compose마지막에 추가하면 augmentation이 적용된 데이터를torch타입으로 변환할 수 있습니다.- 아래 2가지 예시를 통하여
ToTensorV2를 적용한 것과 아닌 것의 차이점을 살펴보겠습니다.
import albumentations as A
from albumentations.pytorch import ToTensorV2
import cv2
import numpy as np
image = cv2.imread("city_image.png")
mask = cv2.imread("city_mask.png")
height = 150
width = 300
# Declare an augmentation pipeline
transform = A.Compose([
A.Normalize(),
A.Resize(height=height, width=width),
A.RandomResizedCrop(height=height, width=width, scale=(0.3, 1.0)),
# ToTensorV2()
])
augmentations = transform(image=image, mask=mask)
augmentation_img = augmentations["image"]
augmentation_mask = augmentations["mask"]
print(augmentation_img.shape)
# (150, 300, 3)
print(type(augmentation_img))
# <class 'numpy.ndarray'>
- 위 예시에서
image는 opencv를 통하여 입력되었으므로 numpy 형태이고 이 값을 augmentation 하더라도 그대로 numpy 값을 가집니다. - opencv로 이미지를 읽었을 때, (H, W, C) 순서의 shape을 가지는 것 또한 확인할 수 있습니다.
import albumentations as A
from albumentations.pytorch import ToTensorV2
import cv2
import numpy as np
image = cv2.imread("city_image.png")
mask = cv2.imread("city_mask.png")
height = 150
width = 300
# Declare an augmentation pipeline
transform = A.Compose([
A.Normalize(),
A.Resize(height=height, width=width),
A.RandomResizedCrop(height=height, width=width, scale=(0.3, 1.0)),
ToTensorV2()
])
augmentations = transform(image=image, mask=mask)
augmentation_img = augmentations["image"]
augmentation_mask = augmentations["mask"]
print(augmentation_img.shape)
# torch.Size([3, 150, 300])
print(type(augmentation_img))
# <class 'torch.Tensor'>
A.Compose의 마지막에ToTensorV2()를 추가하였을 때, shape과 class가 모두torch타입으로 바뀌어져 있는 것을 알 수 있습니다. shape의 순서가 (H, W, C) → (C, H, W) 가 되고 class도torch.Tensor가 되었습니다.
albumentation 사용 시 tip
- ① 멀티 GPU를 사용한다면 다음 2가지의
opencv설정을 해주면 효과적입니다.cv2.setNumThreads(0)cv2.ocl.setUseOpenCL(False)- 이유는 다음과 같습니다. In some systems, in the multiple GPU regime, PyTorch may deadlock the DataLoader if OpenCV was compiled with OpenCL optimizations. Adding the following two lines before the library import may help. For more details https://github.com/pytorch/pytorch/issues/1355
- ② transform을 한 이후에
image,label의 값이 유효한 지 한번 더 체크하는 것이 좋습니다. 저의 경우 transform 이후 label이 이상한 값을 가지게 되어 Loss 에서 에러가 발생하는 경우가 있었습니다. 아래와 같이 해결하였습니다.
augmentations = transform(image=image, mask=mask)
image = augmentations['image']
mask = augmentations['mask']
no_use_class = 99
mask[mask >= num_class] = no_use_class
mask[mask < 0] = no_use_class
멀티 데이터 셋의 albumentation 적용
- 참조 : https://albumentations.ai/docs/examples/example_multi_target/
- Augmentation을 적용 시, 동일한 기준으로 여러개의 데이터 셋에 동시에 적용하고자 하는 경우가 있습니다.
- 이 때,
additional_targets옵션을 이용하여additional data : base data로 같은 기준으로 augmentation 하는 짝을 맞추어 주면 됩니다. 다음 코드를 참조하시면 됩니다.
import albumentations as A
transform = A.Compose(
[HorizontalFlip(p=0.5), ...],
additional_targets={
'image1': 'image',
'image2': 'image',
...
'imageN': 'image',
'bboxes1': 'bboxes',
'bboxes1': 'bboxes',
...
'bboxesM': 'bboxes',
'keypoints1': 'keypoints',
'keypoints2': 'keypoints',
...
'keypointsK': 'keypoints',
'mask1': 'mask',
'mask2': 'mask',
...
'maskL': 'mask'
})
- 위 코드에서
image1,image2, … ,imageN는image와 동일한 Augmentation이 적용됩니다. 즉, 어떤 랜덤값에 의하여 Augmentation이 될 때, 동일한 값으로 적용되는 것입니다. - image 뿐만 아니라
bboxes,keypoints,mask등도 동일하게 적용됩니다. - 실제 Pytorch에서 사용 시 아래 코드를 따르면 됩니다.
import random
import cv2
from matplotlib import pyplot as plt
import albumentations as A
image = cv2.imread('images/multi_target_1.jpg')
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
image0 = cv2.imread('images/multi_target_2.jpg')
image0 = cv2.cvtColor(image0, cv2.COLOR_BGR2RGB)
image1 = cv2.imread('images/multi_target_3.jpg')
image1 = cv2.cvtColor(image1, cv2.COLOR_BGR2RGB)
transform = A.Compose(
[A.VerticalFlip(p=1)],
additional_targets={'image0': 'image', 'image1': 'image'}
)
transformed = transform(image=image, image0=image0, image1=image1)
자주 사용하는 이미지 augmentation 리스트
Normalize
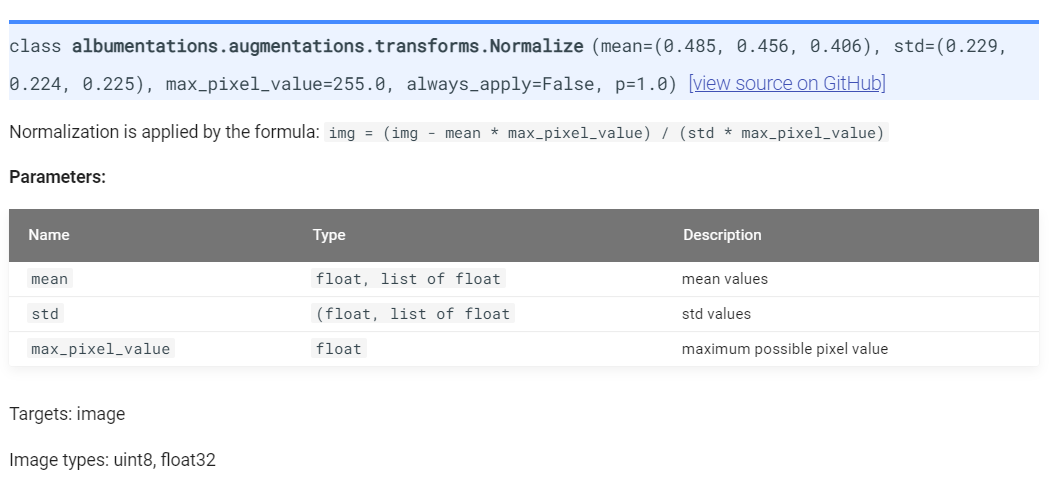
Normalize는 입력 받은 이미지 값의 범위를 (0, 255) → (-1, 1) 범위로 줄여주는 역할을 합니다. 이와 같이 하는 이유는 입력 값의 범위를 줄여줌으로써 학습이 빨리 수렴되게 하고 특정 입력값이 커짐으로써 특정 weight값이 커지는 문제를 개선할 수 있기 때문입니다.Normalize를 할 때,mean,std값이 필요하며 albumentation에서는 추가적으로max_pixel_value라는 값을 필요로 합니다. 그 이유는Normalize하는 식이 다음과 같기 때문입니다.
img = (img - mean * max_pixel_value) / (std * max_pixel_value)
- 보통
mean,std값을 (0, 255) 사이의 값으로 저장하거나 (-1, 1) 사이의 값으로 저장합니다. 이 때,max_pixel_value값은 다음과 같이 설정합니다. 참고로mean,std는 리스트, 튜플 또는 넘파이 배열로 입력하면 됩니다.
- ①
mean,std값의 범위 (0, 255) :max_pixel_value = 1.0으로 설정 합니다.
mean1 = [90, 100, 100]
std1 = [30, 32, 28]
transform = A.Compose([
A.Normalize(mean=mean1, std=std1, max_pixel_value=1.0),
])
- ②
mean,std값의 범위 (-1, 1) :max_pixel_value = 255으로 설정
mean2 = [mean1[0]/255, mean1[1]/255, mean1[2]/255]
std2 = [std1[0]/255, std1[1]/255, std1[2]/255]
transform = A.Compose([
A.Normalize(mean=mean2, std=std2, max_pixel_value=255),
])
- 위와 같이
max_pixel_value를 설정해야 정확한 Normalization 수식(변량 - 평균) / 표준편차를 적용할 수 있습니다.
ColorJitter
ColorJitter는 대표적인 Augmentation 방법 중 하나입니다. 픽셀의 값을brightness,contrast,saturation,hue값으로 분할하고 각 성분에 대한 random 값을 적용하여 다양한 이미지를 생성합니다.- 물론
ColorJitter를 Augmentation으로 사용하려면 색이 바뀌어도 풀고자 하는 문제에 영향이 없어야 합니다. - 상세 내용은 아래 albumentation의 내용을 따릅니다.

transform = A.Compose([
A.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2, hue=0.2),
])
