
pytorch 모델 저장과 ONNX 사용
2019, May 18
- 참조 : https://www.learnopencv.com/how-to-run-inference-using-tensorrt-c-api/?ck_subscriber_id=272174900
- 참조 : https://opencv.org/how-to-speed-up-deep-learning-inference-using-openvino-toolkit-2/
- 이 글에서는 pytorch를 이용하여 학습한 결과를 저장하거나 다른 프레임워크에서 사용하는 방법에 대하여 다루어 보겠습니다.
목차
-
모델 저장과 불러오기
-
ONNX를 사용한 다른 프레임워크와의 연계
-
pytorch에서 학습 완료된 모델 불러오기
-
ONNX로 export
-
ONNX에 shape 정보 저장
-
onnx 파일 확인
-
pytorch와 onnx 비교
-
onnx 모델에 pytorch weight 할당
-
onnx 모델 export 코드 종합
-
netron을 이용한 ONNX 시각화
-
onnx 그래프 수정
-
onnx 모델의 shape 확인
-
ONNX 모델을 caffe2 모델로 저장
-
onnxruntime을 이용한 모델 사용
모델 저장과 불러오기
- 먼저 모델의 저장과 불러오는 방법에 대하여 다루어 보도록 하겠습니다.
- 딥러닝이나 머신러닝에서 학습한 모델을 저장해 두었다가 나중에 재사용하는 것은 필수적입니다.
- 이 때,
모델 저장하는 것은모델 구조 자체 + 학습한 파라미터두가지를 함께 저장하는 것을 뜻합니다. - 모델 구조는 코드를 그대로 사용하면 되지만 학습한 파라미터는 대량의 수치 데이터이므로 파일로 저장할 필요가 있습니다.
- 먼저 파이토치에서는
state_dict메서드를 사용하여 파라미터의 텐서를 사전 형식으로 추출할 수 있고,torch.save라는pickle의 wrapper 함수를 사용하여 파일로 저장할 수 있습니다. - 참고로
pickle_protocol = 4옵션은 pickle 형식으로 큰 객체를 효율적으로 저장할 수 있습니다.
# 학습이 끝난 신경망 모델
params = net.state_dict()
# net.prm라는 파일로 저장
torch.save(params, "net.prm", pickle_protocol = 4)
- 저장한 파라미터 파일을 불러올 때에는
torch.load함수를 사용하고nn.Module의load_state_dict함수에 전달하면 딥러닝 모델에 파라미터를 설정할 수 있습니다.
# net.prm 불러오기
params = torch.load("net.prm", map_location = "cpu")
net.load_state_dict(params)
- 여기서 map_location은 읽은 파라미터를 어디에 저장할 것인지를 나타냅니다.
- 예를 들어 GPU로 학습한 모델의 파라미터를 그대로 저장하면
torch.load로 읽는 경우 우선 CPU로 불러온 후에 GPU로 전송합니다. - 이 경우에 GPU가 없는 서버에서 사용할 때에는 오류가 발생해 버립니다.
- 이런 오류를 방지하기 위하여 map_location 인수를 사용하여 읽은 후의 동작을 지정합니다.
- 파라미터를 저장할 때에는 어떻게 사용할 지를 고려해서 GPU 또는 CPU 버전으로 저장해 두어야 합니다. 만약 CPU에서 사용한다면 다음 예와 같이 일단 모델을 CPU로 전송해 두는 것도 좋은 방법입니다.
# 일단 CPU로 모델 이동
net.cpu()
# 파라미터 저장
params = net.state_dict()
torch.save(params, "net.prm", pickle_protocol=4)
ONNX를 사용한 다른 프레임워크와의 연계
ONNX란Open Neural Network eXchange의 줄임말입니다.- 이 글에서는 ONNX라는 신경망 모델의 표준 포맷에 대하여 설명하고,
pytorch로 학습한 모델을 ONNX를 경유해서Caffe2로 실행해 보겠습니다. (pytorch와 caffe2 모두 페이스북에서 개발한 것으로 비교적 안정적으로 동작합니다.) - 먼저 ONNX에 대하여 간단하게 살펴보면 Facebook과 MS가 개발한 신경망 모델의 호환 포맷입니다.
- 특정 프레임워크에서 작성한 모델을 다른 프레임워크에서 사용할 수 있게 하는 도구로
pytorch, caffe, CNTK, MXNet등을 지원하고 caffe나 MXNet 같은 C++ 기반의 프레임워크를 지원하기 때문에 모바일 기기에 배포할 수 있어서 응용 범위가 넓어집니다. - 예를 들면 Pytorch 작성 → ONNX 변환 → Caffe에서 임포트 하는 순서로 사용 가능합니다.
pytorch에서 학습 완료된 모델 불러오기
- 먼저 학습이 완료된 모델을 불러오겠습니다. 아래 코드는 예제로 참고만 하시기 바랍니다.
- 물론 모델을 저장할 때에는
평가모드로 저장해야 합니다.
from torchvision import models
# resnet18의 binary classification 예제
def CreateNetwork():
net = models.resnet18()
return net
# 모델 생성
net = CreateNetwork()
# 파라미터 읽기 및 모델에 설정
prm = torch.load("net.prm", map_location="cpu")
net.load_state_dict(prm)
# 평가 모드로 설정
net.eval()
ONNX로 export
- 다음은 ONNX로 export를 해보겠습니다.
- pytorch는 동적인 계산 그래프를 이용해야 하므로 export할 때에는 네트워크 계산을 직접 한번 해야 합니다.
- 이를 위해서는 실제 이미지를 사용할 필요는 없고 입력 데이터와 크기가 같은 더미용 데이터를 사용해도 됩니다.
- 예를 들어 입력 데이터의 크기가 (3, 224, 224)의 이미지라고 가정해보고 배치 차원도 포함해서 (1, 3, 224, 224)라고 하면 더미 데이터도 이 크기로 만들면 됩니다.
import torch.onnx
dummy_data = torch.empty(1, 3, 224, 224, dtype = torch.float32)
torch.onnx.export(net, dummy_data, "output.onnx")
- 위와 같이 코드를 입력하면 export가 완료됩니다. ONNX의 제약 중 하나는 pytorch 등의 동적 계산 프레임워크로부터 export할 경우에 1회 계산을 해야하므로 네트워크 내에서 if문 등으로 분기가 이루어지지 않는 경우에는 제대로 export가 되지 않을 수 있습니다.
- ONNX로 변환시 입력부와 출력부의 이름은 임의의 이름으로 지정되어 있습니다. ONNX를 사용하는 입장에서
입력부와출력부의 이름을 특정 이름으로 지정하고 싶으면 export 할 때 옵션을 다음과 같이 지정할 수 있습니다.
# 입출력이 각각 1개인 경우
torch.onnx.export(net, dummy_data, input_names = ['input'], output_names = ['output'], "output.onnx")
# 입력이 1개 출력이 2개인 경우
torch.onnx.export(net, dummy_data, input_names = ['input'], output_names = ['cls_score','bbox_pred'], "output.onnx")
ONNX에 shape 정보 저장
- 단순히
torch.onnx.export를 하였을 때에는, layer 간 입출력 크기를 확인할 수 없습니다. 단순히 모델 전체의 입출력만 표시되어 있습니다. - 모델 아키텍쳐 전체를 이해하기 위해서는 layer 간 입출력의 크기를 알아야 하기 때문에 다음과 같이
torch.onnx.export로 저장된output.onnx를 다시 불러와서shape정보를 다시 입력한 다음 저장해 주면 이 문제를 해결할 수 있습니다.
import onnx
from onnx import shape_inference
path = ".../path/to/the/output.onnx"
onnx.save(onnx.shape_inference.infer_shapes(onnx.load(path)), path)
- 위 코드를 실행하면 기존의 onnx 파일에 shape 정보를 추가한 뒤 다시 덮어 쓰게 됩니다.
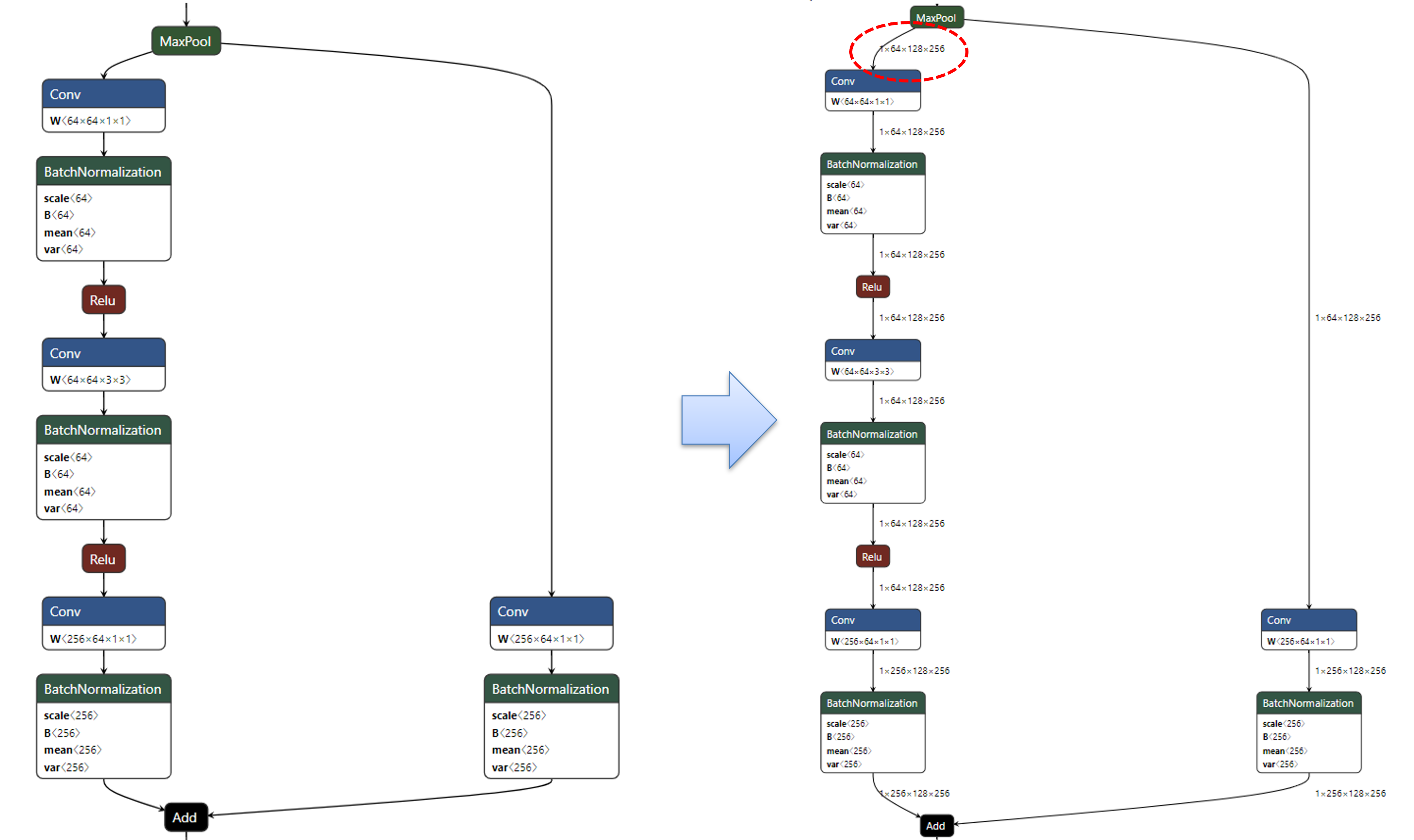
- 이렇게 shape을 저장하면 onnx에 별도로 shape에 대한 정보를 알 수 있게 됩니다.
- 위 그림은 이 글 뒷부분에서 다루는
netron을 이용하여 시각화한 정보입니다. 각 layer의 입출력 크기를 시각화 해서 알 수 있기 때문에 모델 아키텍쳐 분석이 쉬워집니다.
onnx 파일 확인
- 변환된 onnx를 확인하기 위해서는
onnx패키지가 필요합니다. 다음 명령어를 통하여 onnx 패키지를 설치할 수 있습니다.- 명령어 :
pip install onnx
- 명령어 :
- 그 다음
onnx.load()함수를 통하여 onnx를 불러올 수 있습니다.
onnx_path = "./path/to/the/onnx/something.onnx"
onnx_model = onnx.load(onnx_path)
graph = onnx_model.graph
initializers = dict()
for init in graph.initializer:
initializers[init.name] = numpy_helper.to_array(init)
- 위 코드를 이용하여
onnx를 불러오고numpy_helper를 이용하여 각 layer의 값을numpy의 자료형으로 변환시키면 각 layer 별로 어떤 값을 가지는 지 알 수 있습니다.
pytorch와 onnx 비교
- 지금까지 pytorch를 이용하여 onnx 파일을 만드는 방법에 대하여 알아보았습니다. 이 때, 정확히 pytorch → onnx로 변환이 되었는 지 확인하기 위하여 각 layer 별 weight 변환을 확인해 볼 필요가 있습니다.
- 아래 코드에서는 기존의 pytorch 모델과 onnx의 layer 별 weight 비교 하는 방법을 보여줍니다.
- 특히 두 numpy array를 비교하는
compare_two_array의 numpy 함수는 https://gaussian37.github.io/python-basic-numpy-snippets/ 에서 내용을 살펴보시기 바랍니다. - 전체적인 흐름은 다음과 같습니다.
- ① 입력 받은 onnx 파일 경로를 통해 onnx 모델을 불러옵니다.
- ② onnx 모델의 정보를 layer 이름 : layer값 기준으로 저장합니다.
- ③ torch 모델의 정보를 layer 이름 : layer값 기준으로 저장합니다.
- ④ onnx와 torch 모델의 성분은 1:1 대응이 되지만 저장하는 기준이 다르므로 onnx와 torch의 각 weight가 1:1 대응이 되는 성분만 필터합니다. 아래 왼쪽은 onnx 모델의 layer 정보이고 오른쪽은 torch 모델의 layer 정보입니다. 아래 정보와 같이 onnx 모델은 weight 이외의 layer를 별도로 가지는 반면 torch 모델은 weight가 suffix로 있는 layer만 존재합니다. 정확히는 torch 모델의 bn과 같은 일부 layer의 정보가 onnx 모델에서는 weight, bias, running_mean, running_var과 같이 여러 개로 풀어졌기 때문에 onnx 모델의 layer가 더 많은 것처럼 보입니다.
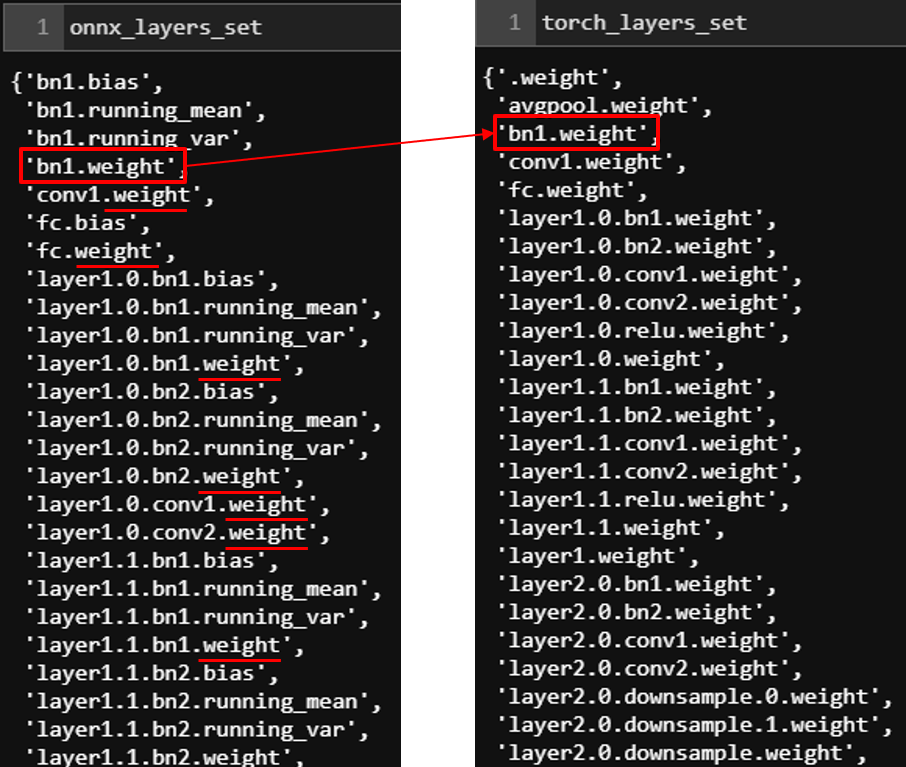
- ⑤ compare_two_array 함수를 통하여 onnx와 torch의 각 대응되는 layer의 값을 비교합니다.
def compare_two_array(actual, desired, layer_name, rtol=1e-7, atol=0):
# Reference : https://gaussian37.github.io/python-basic-numpy-snippets/
flag = False
try :
np.testing.assert_allclose(actual, desired, rtol=rtol, atol=atol)
print(layer_name + ": no difference.")
except AssertionError as msg:
print(layer_name + ": Error.")
print(msg)
flag = True
return flag
# ① 입력 받은 onnx 파일 경로를 통해 onnx 모델을 불러옵니다.
onnx_path = "output.onnx"
onnx_model = onnx.load(onnx_path)
# ② onnx 모델의 정보를 layer 이름 : layer값 기준으로 저장합니다.
onnx_layers = dict()
for layer in onnx_model.graph.initializer:
onnx_layers[layer.name] = numpy_helper.to_array(layer)
# ③ torch 모델의 정보를 layer 이름 : layer값 기준으로 저장합니다.
torch_layers = {}
for layer_name, layer_value in net.named_modules():
torch_layers[layer_name] = layer_value
# ④ onnx와 torch 모델의 성분은 1:1 대응이 되지만 저장하는 기준이 다르므로
# onnx와 torch의 각 weight가 1:1 대응이 되는 성분만 필터합니다.
onnx_layers_set = set(onnx_layers.keys())
# onnx 모델의 각 layer에는 .weight가 suffix로 추가되어 있어서 문자열 비교 시 추가함
torch_layers_set = set([layer_name + ".weight" for layer_name in list(torch_layers.keys())])
filtered_onnx_layers = list(onnx_layers_set.intersection(torch_layers_set))
# ⑤ compare_two_array 함수를 통하여 onnx와 torch의 각 대응되는 layer의 값을 비교합니다.
for layer_name in filtered_onnx_layers:
onnx_layer_name = layer_name
torch_layer_name = layer_name.replace(".weight", "")
onnx_weight = onnx_layers[onnx_layer_name]
torch_weight = torch_layers[torch_layer_name].weight.detach().numpy()
compare_two_array(onnx_weight, torch_weight, onnx_layer_name)
onnx 모델에 pytorch weight 할당
- 바로 직전 예제에서 onnx 모델의 weight와 pytorch 모델의 weight를 비교하여 차이가 있는 지 확인하였습니다.
- 간혹 weight의 차이가 있는 경우가 발생하는데, 이 때 가장 직관적이며 빠른 해결 방법은 pytorch의 weight를 onnx 모델의 weight에 저장하는 것입니다.
- 앞에 두 모델의 비교 예제에서 살펴보았듯이 두 모델의 각 weight를 가지는 layer는 1:1 대응이 되므로 쉽게 구현할 수 있습니다. 다른 weight를 복사하여 onnx 모델의 layer를 업데이트 할 때,
onnx_model.graph.initializer[index].CopyFrom(tensor)를 이용할 수 있습니다. (onnx_model은 onnx.onnx_ml_pb2.ModelProto 타입입니다.) - onnx의 weight를 변경할 때, 주의할 점은 weight 뿐만 아니라 layer 이름도 같이 업데이트 해주어야 한다는 점입니다. 아래 코드를 살펴보겠습니다.
- ① onnx 모델의 layer가 torch 모델의 layer에 속하는 지 확인
- ② torch 모델의 weight를 onnx 모델의 weight로 복사하고 이 때, layer name의 정보도 같이 복사함
- ③ onnx 재저장
graph = onnx_model.graph
for index, layer in enumerate(graph.initializer):
layer_name = layer.name
# ① onnx 모델의 layer가 torch 모델의 layer에 속하는 지 확인
if layer_name in filtered_onnx_layers:
onnx_layer_name = layer_name
torch_layer_name = layer_name.replace(".weight", "")
onnx_weight = onnx_layers[onnx_layer_name]
torch_weight = torch_layers[torch_layer_name].weight.detach().numpy()
# ② torch 모델의 weight를 onnx 모델의 weight로 복사하고 이 때, layer name의 정보도 같이 복사함
copy_tensor = numpy_helper.from_array(torch_weight, onnx_layer_name)
onnx_model.graph.initializer[index].CopyFrom(copy_tensor)
onnx_new_path = os.path.dirname(os.path.abspath(onnx_path)) + os.sep + "updated_" + os.path.basename(onnx_path)
onnx.save(onnx_model, onnx_new_path)
onnx 모델 export 코드 종합
- 참조 : https://github.com/gaussian37/pytorch_onnx_exporter
- 앞에서 살펴본 모든 코드를 하나로 종합하였습니다. 코드가 실행되는 전체적인 flow는 다음과 같습니다.
- ① 사용할 딥러닝 네트워크를 불러온 뒤 평가 모드로 설정합니다.
- ② torch 모델을 이용하여 onnx 모델을 생성합니다.
- ③ 생성한 onnx 모델을 다시 불러와서 torch 모델과 onnx 모델의 weight를 비교합니다.
- ④ onnx 모델에 기존 torch 모델과 다른 weight가 있으면 전체 update를 한 후 새로 저장합니다.
- ⑤ 최종적으로 저장된 onnx 모델을 불러와서 shape 정보를 추가한 뒤 다시 저장합니다.
import numpy as np
import torch.nn as nn
import torch.onnx
from torchvision import models
import onnx
from onnx import shape_inference
import onnx.numpy_helper as numpy_helper
# CreateNetwork should be modified by custom deep-learning model
def CreateNetwork():
net = models.resnet18()
return net
def compare_two_array(actual, desired, layer_name, rtol=1e-7, atol=0):
# Reference : https://gaussian37.github.io/python-basic-numpy-snippets/
flag = False
try :
np.testing.assert_allclose(actual, desired, rtol=rtol, atol=atol)
print(layer_name + ": no difference.")
except AssertionError as msg:
print(layer_name + ": Error.")
print(msg)
flag = True
return flag
# parameters
channel = 3
height = 224
width = 224
onnx_path = "output.onnx"
# ① 사용할 딥러닝 네트워크를 불러온 뒤 평가 모드로 설정합니다.
net = CreateNetwork()
net.eval()
# ② torch 모델을 이용하여 onnx 모델을 생성합니다.
# (B, C, H, W) 의 dimension을 가지는 것으로 가정함
dummy_data = torch.empty(1, channel, height, width, dtype = torch.float32)
torch.onnx.export(net, dummy_data, onnx_path, input_names = ['input'], output_names = ['output'])
# ③ 생성한 onnx 모델을 다시 블루어와서 torch 모델과 onnx 모델의 weight를 비교합니다.
# 입력 받은 onnx 파일 경로를 통해 onnx 모델을 불러옵니다.
onnx_model = onnx.load(onnx_path)
# onnx 모델의 정보를 layer 이름 : layer값 기준으로 저장합니다.
onnx_layers = dict()
for layer in onnx_model.graph.initializer:
onnx_layers[layer.name] = numpy_helper.to_array(layer)
# torch 모델의 정보를 layer 이름 : layer값 기준으로 저장합니다.
torch_layers = {}
for layer_name, layer_value in net.named_modules():
torch_layers[layer_name] = layer_value
# onnx와 torch 모델의 성분은 1:1 대응이 되지만 저장하는 기준이 다릅니다.
# onnx와 torch의 각 weight가 1:1 대응이 되는 성분만 필터합니다.
onnx_layers_set = set(onnx_layers.keys())
# onnx 모델의 각 layer에는 .weight가 suffix로 추가되어 있어서 문자열 비교 시 추가함
torch_layers_set = set([layer_name + ".weight" for layer_name in list(torch_layers.keys())])
filtered_onnx_layers = list(onnx_layers_set.intersection(torch_layers_set))
difference_flag = False
for layer_name in filtered_onnx_layers:
onnx_layer_name = layer_name
torch_layer_name = layer_name.replace(".weight", "")
onnx_weight = onnx_layers[onnx_layer_name]
torch_weight = torch_layers[torch_layer_name].weight.detach().numpy()
flag = compare_two_array(onnx_weight, torch_weight, onnx_layer_name)
difference_flag = True if flag == True else False
# ④ onnx 모델에 기존 torch 모델과 다른 weight가 있으면 전체 update를 한 후 새로 저장합니다.
if difference_flag:
print("update onnx weight from torch model.")
for index, layer in enumerate(onnx_model.graph.initializer):
layer_name = layer.name
if layer_name in filtered_onnx_layers:
onnx_layer_name = layer_name
torch_layer_name = layer_name.replace(".weight", "")
onnx_weight = onnx_layers[onnx_layer_name]
torch_weight = torch_layers[torch_layer_name].weight.detach().numpy()
copy_tensor = numpy_helper.from_array(torch_weight, onnx_layer_name)
onnx_model.graph.initializer[index].CopyFrom(copy_tensor)
print("save updated onnx model.")
onnx_new_path = os.path.dirname(os.path.abspath(onnx_path)) + os.sep + "updated_" + os.path.basename(onnx_path)
onnx.save(onnx_model, onnx_new_path)
# ⑤ 최종적으로 저장된 onnx 모델을 불러와서 shape 정보를 추가한 뒤 다시 저장합니다.
if difference_flag:
onnx.save(onnx.shape_inference.infer_shapes(onnx.load(onnx_new_path)), onnx_new_path)
else:
onnx.save(onnx.shape_inference.infer_shapes(onnx.load(onnx_path)), onnx_path)
netron을 이용한 ONNX 시각화
netron을 이용하면 onnx로 변환된 model의 그래프를 시각적으로 확인할 수 있습니다.- 위 링크에서 매뉴얼을 읽은 후 각 OS에 맞는 파일을 설치를 하면 onnx 파일을 실행할 수 있는 어플리케이션이 설치 됩니다. 이 어플리케이션을 이용하여 onnx 파일을 실행 시키면 아래 그림과 같이 입력 ~ 출력 까지 그래프 형태로 모델의 구조를 살펴볼 수 있습니다.

- 이와 같은 시각화를 통하여 모델의 전체적인 구조 및 파라미터 등을 알 수 있고 특히 onnx에서 사용하는 입출력의 이름과 shape을 확인할 수 있습니다.
- 이 과정을 통하여 글의 뒷부분에 작성한
onnxruntime을 이용한 모델 사용에서 사용하는 입출력의 이름과 입력의 shape 정보를 쉽게 확인할 수 있습니다.
onnx 그래프 수정
- 깃헙 : https://github.com/ZhangGe6/onnx-modifier
- 생성이 완료된 onnx 모델을 수정하고 싶은 경우
onnx-modifer를 통해 수정이 가능합니다.onnx-modifier가 지원하는 연산은 노드의 삭제, 추가, 속성 변경 및 입/출력 추가 등이 있습니다. - 실제 학습이 완료된 모델을 onnx로 변환하기 때문에 노드의 추가나 속성 값의 변경은 많이 발생하지 않습니다. 다만 특정 layer 이후의 모든 layer (childeren)은 삭제를 하는 기능은 종종 사용합니다. 예를 들어 모든 기능을 다 지원하는 onnx 파일을 만든 이후에 사용 목적에 따라 필요 없는 layer를 삭제하여 경량화 하는 것입니다.
- 이번 글에서는 layer를 삭제하는 기능을 살펴볼 것이며 전체 내용은 위의 깃헙 링크를 참조하시기 바랍니다.
- 설치 방법 :
pip install onnx flask - 사용 방법 :
git clone git@github.com:ZhangGe6/onnx-modifier.git또는 위 링크에서 git 다운로드cd onnx-modifierpython app.py- 서버가 켜지면 웹 브라우저에서
http://127.0.0.1:5000/접속하면 netron과 유사한 형태의 UI가 켜지는 것을 확인할 수 있습니다.
- 아래 모델은 MobileNet 모델로 깃헙에서 기본으로 제공하는 모델이며 마지막 출력부의 형태 입니다.
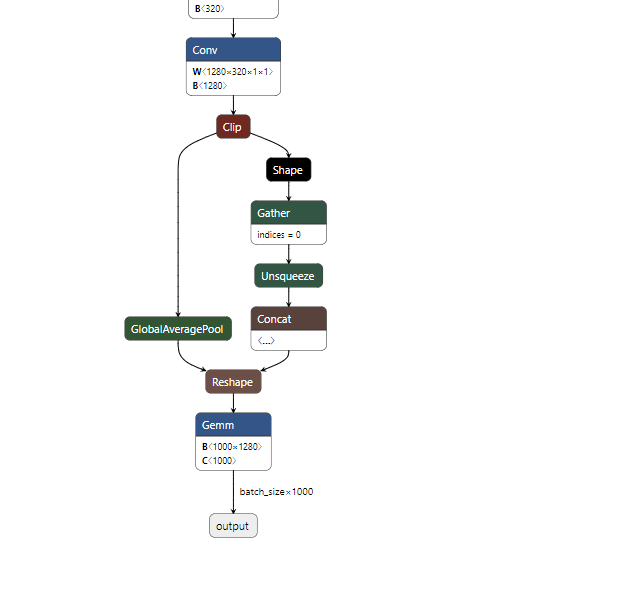
- 특정 layer를 기준으로 그 layer 하부의 연관된 모든 layer를 삭제하는 기능입니다. 먼저 기준이 되 layer를 선택합니다.
- 그 다음으로
Delete With Children을 선택 후 Enter를 누르면 선택된 layer를 기준으로 하부 layer는 삭제된 것을 확인할 수 있습니다.
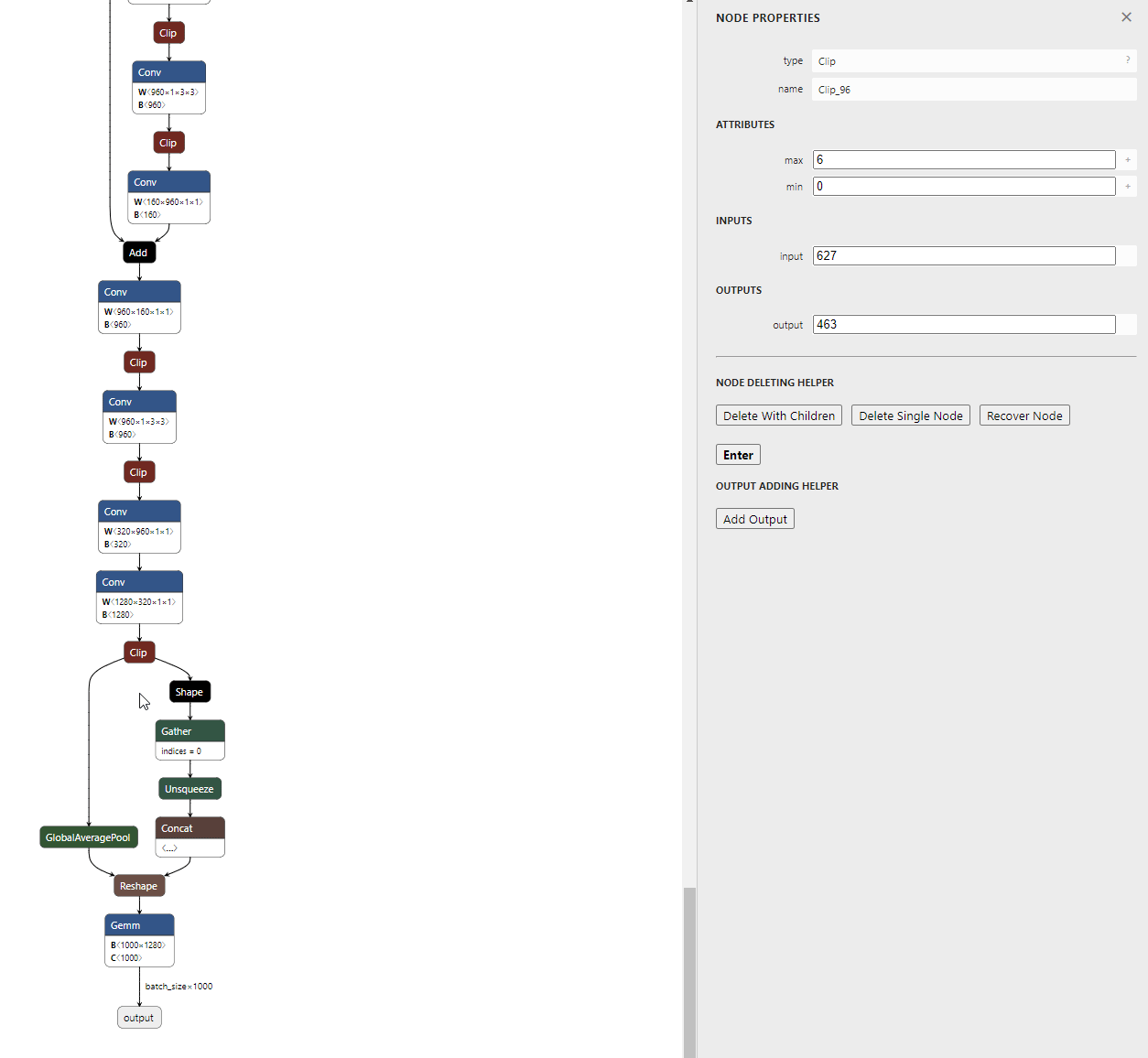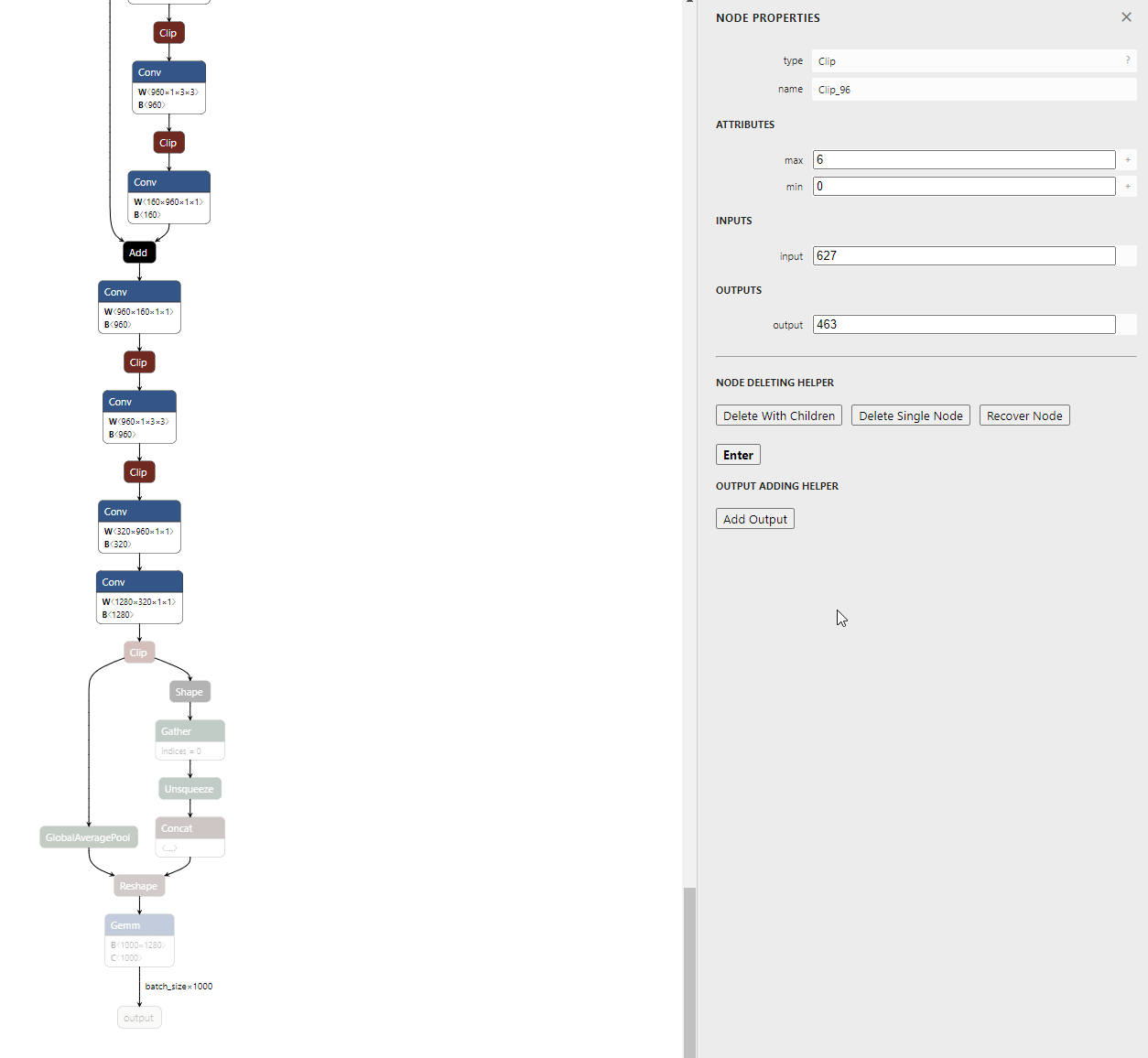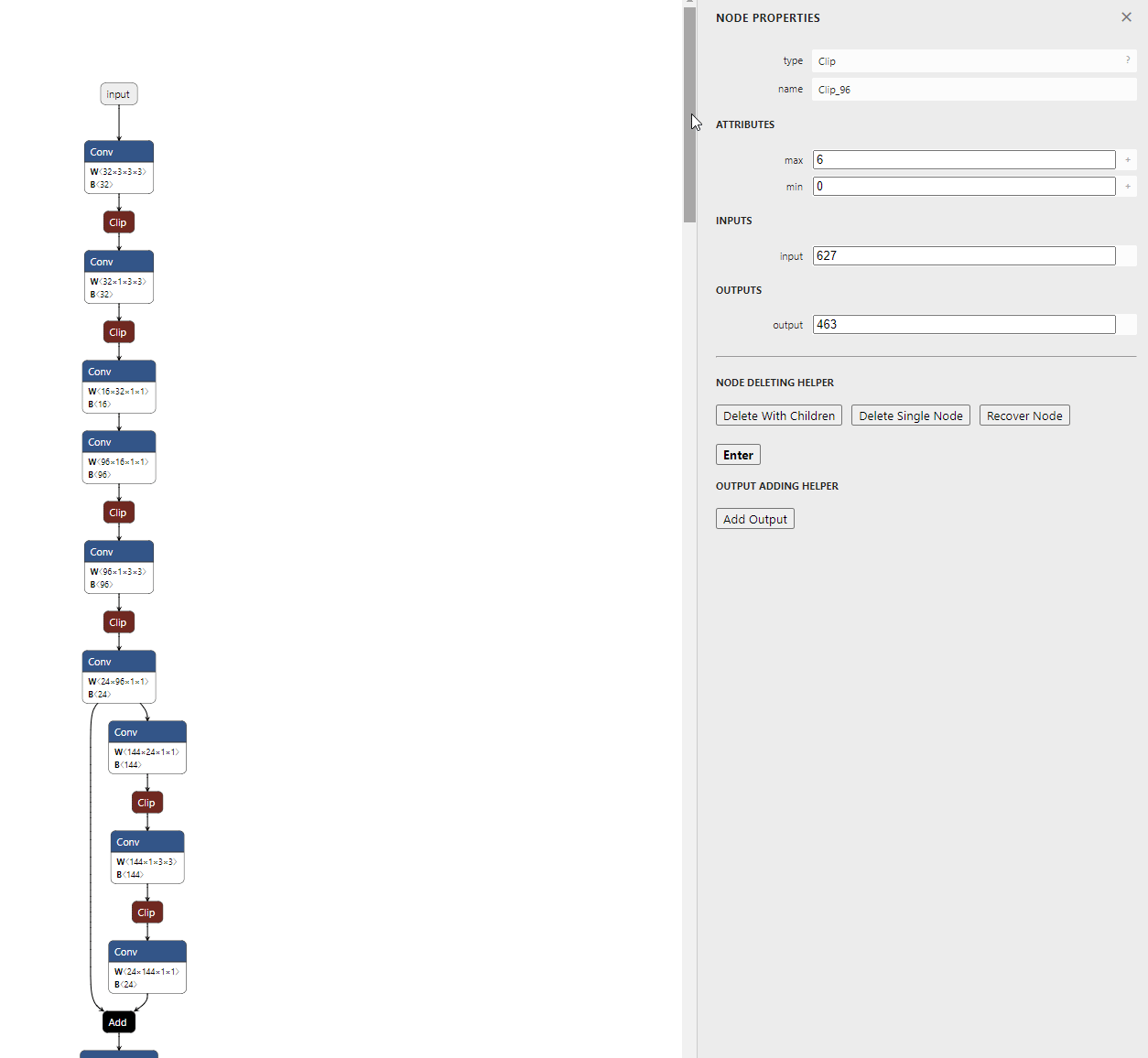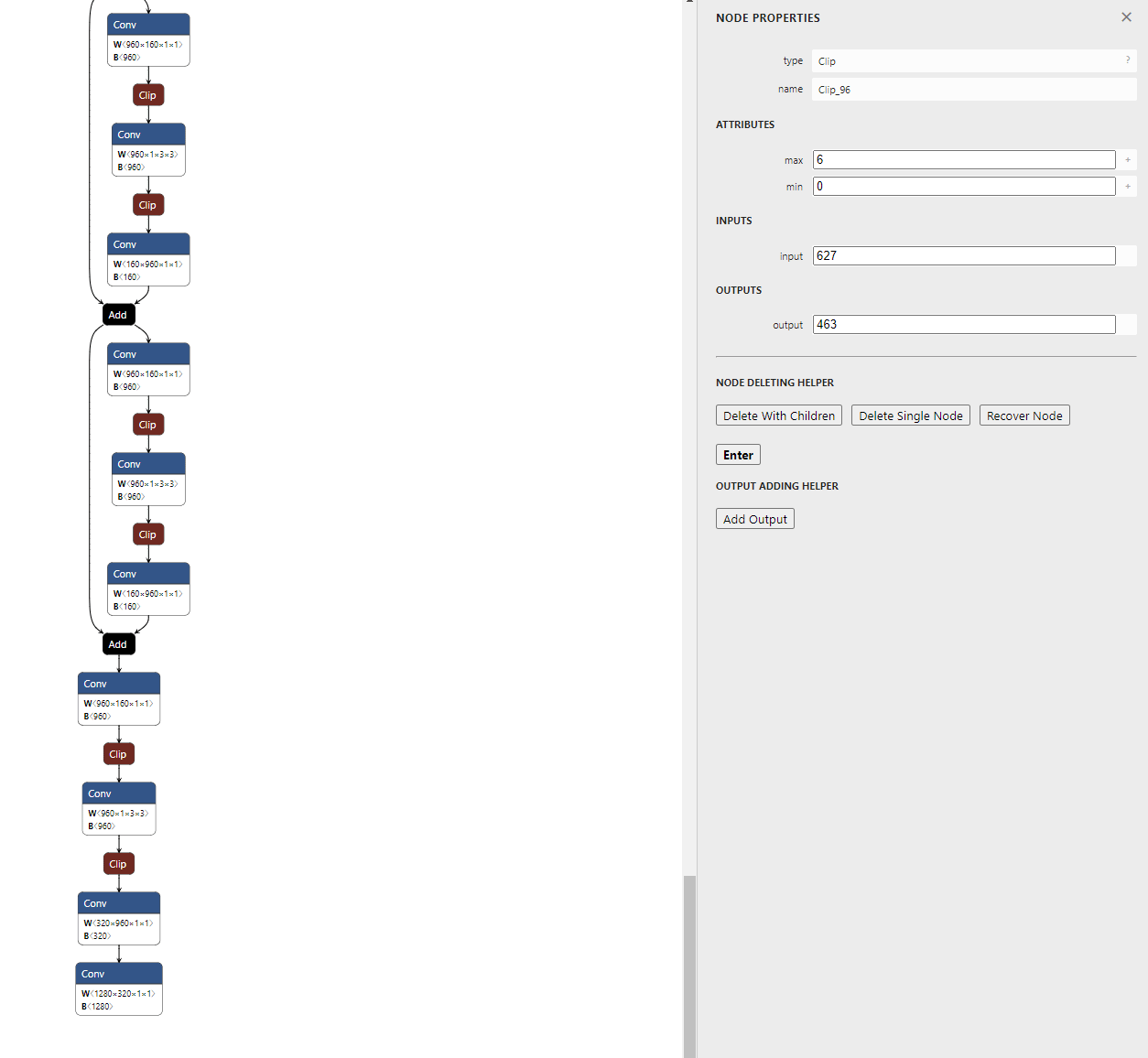
- 삭제가 완료된 모델은 왼쪽 상단의
Download버튼을 통해 다운 받을 수 있습니다.
onnx 모델의 shape 확인
- 위에서 살펴본
netron에서 확인하기 어려운 점이 하나 있는데, 각 layer의 shape입니다. 이 정보는shape_inference라는 onnx의 기능을 통해서 확인할 수 있습니다. - 확인 방법은 아래 코드를 참조하시기 바랍니다.
import onnx
from onnx import helper, shape_inference
onnx_model = onnx.load(onnx_path)
inferred_model = shape_inference.infer_shapes(onnx_model)
inferred_model.graph.value_info[0]
# name: "123"
# type {
# tensor_type {
# elem_type: 1
# shape {
# dim {
# dim_value: 1
# }
# dim {
# dim_value: 64
# }
# dim {
# dim_value: 112
# }
# dim {
# dim_value: 112
# }
# }
# }
# }
- 위 출력에서
dim을 살펴볼 수 있습니다. dim을 차례대로 보면 shape을 알 수 있습니다. 위 예시에서는 (1, 64, 112, 112)로 된 것을 통하여 이 layer의 shape을 확인할 수 있습니다.
Caffe2에서 ONNX 모델 사용
- ONNX 모델을 불러오면 onnx 패키지가 필요하며, caffe2에서 ONNX 모델을 사용하려면 caffe2에 포함되어 있는 caffe2.python.onnx라는 패키지를 사용하여 변환해야 합니다.
- 다음은 caffe2에서 ONNX를 이용하여 임포트 하는 코드 입니다.
import onnx
from caffe2.python.onnx import backend as caffe2_backend
# ONNX 모델 불러오기
onnx_model = onnx.load("output.onnx")
# ONNX 모델을 caffe2 모델로 변환하기
backend = caffe2_backend.prepare(onnx_model)
- 그리고 난 후
backend.run에 이미지 데이터를 numpy의 ndarray 형태로 넣으면 계산할 수 있습니다. - 원래 pytorch 모델과 ONNX 경유로 caffe2에서 사용한 모델이 동일한 결과를 보여주는 것을 확인할 수 있습니다.
- 다음은 pytorch 모델과 ONNX 경유 caffe2 모델을 비교하는 코드입니다.
from PIL import Image
from torchvision import transforms
# 이미지를 잘라서 텐서로 변환하는 함수
transform = transforms.Compose([
transforms.CenterCrop(224),
transforms.ToTensor()
])
# 이미지 불러오기
img = Image.open("test.jpg")
# 텐서로 변환해서 배치 차원을 더함
img_tensor = transform(img).unsqueeze(0)
# ndarray로 변환
img_ndarray = img_tensor.numpy()
# 파이토치로 실행할 때에는 tensor를 입력
net(img_tensor)
: tensor([[ 1.1262, -1.8448]])
# ONNX와 caffe2로 실행할 때에는 numpy를 입력
output = backend.run(img_ndarray)
output[0]
: array([[ 1.126245 , -1.8447802]], dtype=float32)
- 내부 처리가 다르므로 세세한 오차는 있지만, 동일 계산 결과가 반환됩니다.
- pytorch로 작성한 신경망이 ONNX를 경유하여 caffe2에서 제대로 실행되는 것을 확인하실 수 있을 것입니다.
ONNX 모델을 caffe2 모델로 저장
- 다음 예에선 ONNX 모델을 실행하기 위하여 caffe2를 백엔드로 사용하고, 딥러닝 계산 자체는 caffe2의 API를 사용하는 예제입니다.
- 먼저 ONNX에 의존하지 않고 단순한 caffe2 모델로 변환하는 예제를 살펴보겠습니다.
from caffe2.python.onnx.backend import Caffe2Backend
init_net, predict_net = Caffe2Backend.onnx_graph_to_caffe2_net(onnx_model)
onnx_graph_to_caffe2_net은 caffe2의 뉴럴넷과 파라미터를 생성합니다. 이 두가지 결과물을 다음과 같이 파일로 저장해보겠습니다.- 따로 파일을 저장한다면 ONNX를 더 이상 사용하지 않고 caffe2만으로도 inference를 할 수 있습니다.
- 즉, 학습은 pytorch로 시작하고 그 결과를 ONNX 형태로 저장한 다음에 caffe2에서 사용할 수 있도록 하였고 더 나아가 caffe2만으로 사용할 수 있도록 caffe2 형태로 다 변환할 수 있음을 보여줍니다.
with open('init_net.pb', "wb") as fopen:
fopen.write(init_net.SerializeToString())
with open('predict_net.pb', "wb") as fopen:
fopen.write(predict_net.SerializeToString())
onnxruntime을 이용한 모델 사용
- 참조 : https://pytorch.org/tutorials/advanced/super_resolution_with_onnxruntime.html
- 앞선 과정을 통하여 onnx 파일을 생성하면 그 onnx 파일의 입력의 형태와 출력의 형태가 결정됩니다. onnx의 입력 형태에 맞게 입력을 넣어주면 정해진 형식대로 출력을 생성할 수 있습니다.
- 이 과정은
onnxruntime이라는 패키지를 이용하여 사용할 수 있습니다.
import onnxruntime
session = onnxruntime.InferenceSession("path/.../to/model.onnx")
input_name = session.get_inputs()[0].name
output_name = session.get_outputs()[0].name
out = session.run([output_name], {input_name : data})[0]
- 먼저 위 코드를 한 줄 씩 살펴보도록 하곘습니다.
- 첫번째 코드인
session = onnxruntime.InferenceSession("path/.../to/model.onnx")을 이용하여onnxruntim패키지를 이용해 inference에 사용 할onnx파일을 불러옵니다. 일반적으로session이란 변수명으로 저장합니다. - 위 코드에서
input_name,output_name은 글의 초반부에onnx파일을 저장할 때 지정한 input의 이름과 output의 이름입니다.torch.onnx.export함수 부분을 살펴 보시면 export 할 때, input_name과 output_name을 지정하였었습니다. 이 값을 지정하는 이유는 onnx를 inference할 때, 모델에서 원하는 위치에서 부터 입력을 넣고 원하는 위치에서 출력을 만들어 내기 위함입니다. 일반적으로 end-to-end 방식으로 입출력을 구성하기 때문에 모델의 시작점인 input_name을 입력부로 설정하고 모델의 끝부분인 output_name을 출력부로 설정합니다. - 마지막으로 inference 하는 부분인
out = session.run([output_name], {input_name : data})[0]을 살펴보겠습니다. 먼저 출력부인 output_name을 설정하고 그 다음으로 입력부인input_name과 입력할 데이터를 key, value 형태로 입력해 줍니다. 마지막에[0]을 붙인 이유는session.run()의 결과가 리스트 형태이기 때문에 inference 결과에 해당하는 인덱스 0번째 값을 가져오기 위함입니다. - onnxruntime에서 사용되는
data는numpy데이터가 사용됩니다.
- 위와 같은 방법을 이용하여
out에 원하는 inference 결과를 저장할 수 있습니다. - 만약 이미지 데이터를
pytorch를 이용하여 딥러닝 모델을 학습하고 그 결과를onnx로 사용한다면[batch, channel, height, width]의 순서로 입력을 받는 것이 일반적입니다. - 아래는
opencv를 이용하여 1개의 이미지를 입력으로 받고[batch, channel, height, width]로 입력의 크기를 변경해주는 코드입니다.
img = cv2.imread(image_name).astype(np.float32)
# image resize가 필요한 경우 아래와 같이 적용
img = cv2.resize(img, (width, height), interpolation=cv2.INTER_LINEAR)
# image 스케일을 [0, 255] → [0, 1]로 변경 이 필요하면 변경한다.
# image의 normalization이 필요하면 적용한다.
# [height, width, channel] → [channel, height, width]
img = img.transpose((2, 0, 1))
# [channel, height, width] → [1, channel, height, width] (1은 batch를 의미함)
img = np.expand_dims(img, axis=0)
# out : [1, 출력 shape] (1은 batch를 의미함)
out = session.run([output_name], {input_name : src_image})[0]
# out : 출력 shape (batch dimension 제거)
out = out.squeeze(0)
- 마지막으로
onnxruntime에는 이슈가 있음을 언급하면서 글을 마치겠습니다. - pytorch 모델의 inference 결과와 onnxruntime을 이용한 onnx 모델의 inference 결과에는 차이점이 있으며 일반적으로 onnx 모델의 결과가 더 성능이 좋지 않습니다.
- stackoverflow를 보면 이러한 inference 성능 차이 문제는 각 과제 별 풀어야 할 숙제로 남아져 있습니다. 사용하시는 분들은 별다른 문제가 없길 바랍니다.