
Dropout과 BatchNormalization
2019, Jun 06
- 신경망 모델은 표현력이 매우 높은 모델이지만, 훈련된 데이터에만 과적합되는 문제가 생깁니다.
- ML, DL 모두 겪는 문제입니다.
- 과적합을 방지하는 방법을 regularization이라고 하는데 신경망 구축시 사용하는 대표적인 방법으로 dropout과 batchnormalization이 있습니다.
데이터 준비
import torch
from torch import nn, optim
from torch.utils.data import TensorDataset, DataLoader
# 데이터를 훈련용과 테스트용으로 분리
from sklearn.datasets import load_digits
from sklearn.model_selection import train_test_split
from tqdm import tqdm
from torchsummary import summary
import matplotlib.pyplot as plt
# 전체의 20%는 검증용
digits = load_digits()
X = digits.data
Y = digits.target
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size = 0.2)
X_train = torch.tensor(X_train, dtype=torch.float32).to("cuda:0")
Y_train = torch.tensor(Y_train, dtype=torch.int64).to("cuda:0")
X_test = torch.tensor(X_test, dtype=torch.float32).to("cuda:0")
Y_test = torch.tensor(Y_test, dtype=torch.int64).to("cuda:0")
Dropout
- Dropout 기법은 몇 개의 노드를 랜덤으로 선택하여 의도적으로 사용하지 않는 방법입니다.
- Dropout은 신경망 훈련 시에만 사용하고, 예측 시에는 사용하지 않는 것이 일반적입니다.
- 파이토치에서는 모델의
train과eval메서드로 dropout을 적용 또는 미적용 할 수 있습니다.
# 0.5 확률로 랜덤으로 변수의 차원을 감소시킵니다.
model = nn.Sequential(
nn.Linear(64, 100),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(100, 100),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(100, 100),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(100, 100),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(100, 10),
).to("cuda:0")
>> summary(model.to("cuda:0"), (64,))
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Linear-1 [-1, 100] 6,500
ReLU-2 [-1, 100] 0
Dropout-3 [-1, 100] 0
Linear-4 [-1, 100] 10,100
ReLU-5 [-1, 100] 0
Dropout-6 [-1, 100] 0
Linear-7 [-1, 100] 10,100
ReLU-8 [-1, 100] 0
Dropout-9 [-1, 100] 0
Linear-10 [-1, 100] 10,100
ReLU-11 [-1, 100] 0
Dropout-12 [-1, 100] 0
Linear-13 [-1, 10] 1,010
================================================================
Total params: 37,810
Trainable params: 37,810
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.00
Forward/backward pass size (MB): 0.01
Params size (MB): 0.14
Estimated Total Size (MB): 0.15
----------------------------------------------------------------
lossFunc = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters())
ds = TensorDataset(X_train, Y_train)
loader = DataLoader(ds, batch_size=32, shuffle=True)
trainLosses = []
testLosses = []
for epoch in tqdm(range(100)):
runningLoss = 0.0
# 신경망을 train 모드로 설정
model.train()
for i, (batchX, batchY) in enumerate(loader):
optimizer.zero_grad()
yPred = model(batchX)
loss = lossFunc(yPred, batchY)
loss.backward()
optimizer.step()
runningLoss += loss.item()
trainLosses.append(runningLoss/i)
# 신경망을 test 모드로 설정
model.eval()
yPred = model(X_test)
testLoss = lossFunc(yPred, Y_test)
testLosses.append(testLoss.item())
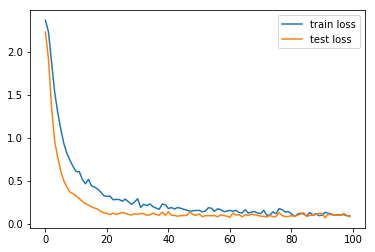
plt.plot(range(100), trainLosses, label = "train loss")
plt.plot(range(100), testLosses, label = "test loss")
plt.legend()
BatchNormalization
- 신경망 학습에서는 각 변수의 차원이 동일한 범위의 값을 가지는 것이 중요합니다.
- 한 층으로 된 선형 모델에서는 사전에 데이터를 정규화해 두면 되지만, 깊은 신경망에서는 층이 늘어날수록 데이터 분포가 바뀝니다.
- 따라서 입력 데이터의 정규화만으로는 부족합니다. 앞의 층의 파라미터가 변화하므로 뒤에 있는 층의 학습이 불안정해집니다.
- 이런 문제를 해결하고 학습을 안정화 및 가속화 하는 방법으로 Batch Normalization이 있습니다.
- Batch Normalization 또한 훈련 시에만 사용되고 평가시에는 사용되지 않습니다.
- Batchnorm은 아래와 같이 사용될 수 있습니다. 파라미터는 feature의 갯수입니다.
model = nn.Sequential(
nn.Linear(64, 100),
nn.ReLU(),
nn.BatchNorm1d(100),
nn.Dropout(0.5),
nn.Linear(100, 100),
nn.ReLU(),
nn.BatchNorm1d(100),
nn.Dropout(0.5),
nn.Linear(100, 100),
nn.ReLU(),
nn.BatchNorm1d(100),
nn.Dropout(0.5),
nn.Linear(100, 100),
nn.ReLU(),
nn.BatchNorm1d(100),
nn.Dropout(0.5),
nn.Linear(100, 10),
).to("cuda:0")