
Pytorch Learning Rate Scheduler (러닝 레이트 스케쥴러) 정리
2020, Nov 15
- 참조 : How to adjust learning rate (https://pytorch.org/docs/stable/optim.html)
- 참조 : https://katsura-jp.hatenablog.com/entry/2019/07/24/143104
- 이번 글에서는 기본적인 Learning Rate Scheduler와 Pytorch에서의 사용 방법에 대하여 정리해 보도록 하겠습니다.
- 개인적으로 자주 사용하는 스케쥴러는
Custom CosineAnnealingWarmUpRestarts입니다.
목차
-
learning rate 임의 변경
-
LambdaLR
-
StepLR
-
MultiStepLR
-
ExponentialLR
-
CosineAnnealingLR
-
CyclicLR
-
CosineAnnealingWarmRestarts
-
Custom CosineAnnealingWarmRestarts
learning rate 임의 변경
- 학습에 사용되는 learning rate를 임의로 변경하기 위해서는 SGD, Adam과 같은 optimizer로 선언한 optimizer 객체를 직접 접근하여 수정할 수 있습니다.
- 일반적인 환경인 1개의 optimizer를 사용한다면
optimizer.param_groups[0]을 통하여 현재 dictionary 형태의 optimizer 정보를 접근할 수 있습니다. 그 중lr이라는 key를 이용하여 learning rate의 value값을 접근할 수 있습니다. - 다음은 learning rate를 반으로 줄이는 작업을 나타내는 예시입니다.
optimizer.param_groups[0]['lr'] /= 2
LambdaLR
- pytorch 코드 : https://github.com/pytorch/pytorch/blob/v1.1.0/torch/optim/lr_scheduler.py#L56
- 먼저 pytorch에서 제공하는
LambdaLR에 대하여 알아보도록 하겠습니다. - LambdaLR은 가장 유연한 learning rate scheduler입니다. 어떻게 scheduling을 할 지 lambda 함수 또는 함수를 이용하여 정하기 때문입니다.
- LmabdaLR을 사용할 때 필요한 파라미터는
optimizer,lr_lambda입니다. 다음 예제를 살펴보도록 하겠습니다.
scheduler = LambdaLR(optimizer, lr_lambda = lambda epoch: 0.95 ** epoch)
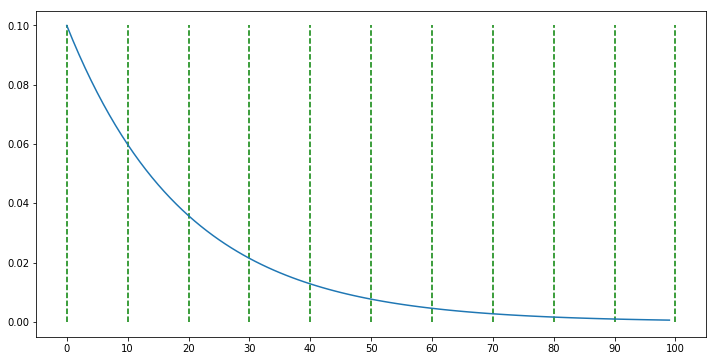
- 먼저 위 그래프에서는
lambda함수를 이용하여 \(0.95^{\text{epoch}}\) 형태로 나타내었습니다. - 위 예제와 같이
LambdaLR()내에서 lambda 형식으로 바로 람다 함수를 작성해도 되지만 좀 더 복잡한 조건을 주기 위하여 일반적인 함수를 작성해도 상관없습니다.
def func(epoch):
if epoch < 40:
return 0.5
elif epoch < 70:
return 0.5 ** 2
elif epoch < 90:
return 0.5 ** 3
else:
return 0.5 ** 4
scheduler = LambdaLR(optimizer, lr_lambda = func)
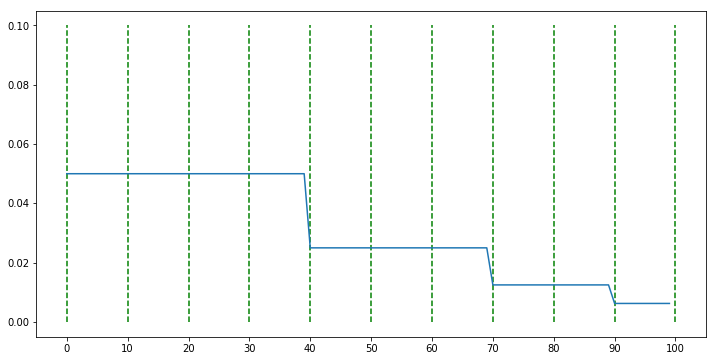
- 위 그래프에서 연두색 점선은 10 epoch을 나타냅니다. 앞에서 선언한 function이 epoch 40, 70, 90에서 식이 바뀌기 때, 그 시점에 맞춰서 learning rate가 변화하는 것을 볼 수 있습니다.
- 이번에는
torch.optim.lr_scheduler.LambdaLR을 상속받아서 클래스를 생성하는 방법을 알아보도록 하겠습니다.
class WarmupConstantSchedule(torch.optim.lr_scheduler.LambdaLR):
""" Linear warmup and then constant.
Linearly increases learning rate schedule from 0 to 1 over `warmup_steps` training steps.
Keeps learning rate schedule equal to 1. after warmup_steps.
"""
def __init__(self, optimizer, warmup_steps, last_epoch=-1):
def lr_lambda(step):
if step < warmup_steps:
return float(step) / float(max(1.0, warmup_steps))
return 1.
super(WarmupConstantSchedule, self).__init__(optimizer, lr_lambda, last_epoch=last_epoch)
optimizer = torch.optim.SGD(model.parameters(), lr=0.05, momentum=0.9, weight_decay=1e-5)
scheduler = WarmupConstantSchedule(optimizer, warmup_steps=10)
for step in range(100):
scheduler.step()
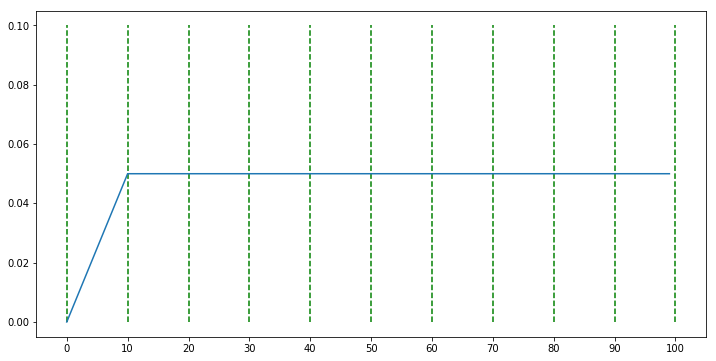
- 위 코드에서 선언한
WarmupConstantSchedule는 처음에 learning rate를 warm up 하면서 증가시키다가 1에 고정시키는 스케쥴러입니다. WarmupConstantSchedule클래스에서 상속되는 부모 클래스를 살펴보면torch.optim.lr_scheduler.LambdaLR를 확인할 수 있습니다.- 위와 같이
LambdaLR을 활용하면 lambda / function을 이용하여 scheduler를 정할 수 있고 또는 클래스 형태로도 custom 하게 만들 수 있습니다.
StepLR
- pytorch 코드 : https://github.com/pytorch/pytorch/blob/v1.0.1/torch/optim/lr_scheduler.py#L126
- StepLR도 가장 흔히 사용되는 learning rate scheduler 중 하나입니다. 일정한 Step 마다 learning rate에 gamma를 곱해주는 방식입니다.
- StepLR에서 필요한 파라미터는
optimizer,step_size,gamma입니다. 아래 예제를 살펴보시기 바랍니다.
scheduler = StepLR(optimizer, step_size=200, gamma=0.5)
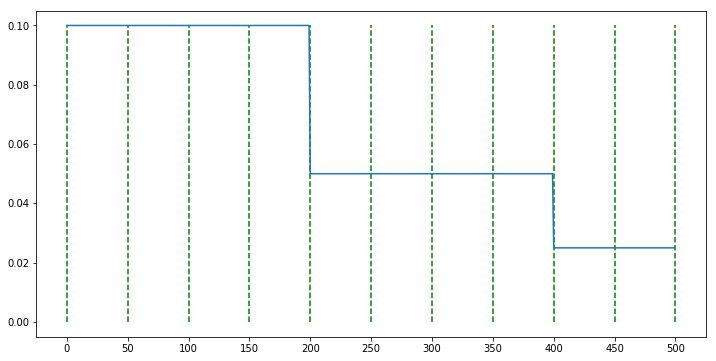
- 위 그래프에서 연두색 선은 50 epoch을 나타냅니다. step_size가 200이므로 50번 씩 4번 step이 0.5배가 되는 것을 확인할 수 있습니다.
MultiStepLR
- pytorch 코드 : https://github.com/pytorch/pytorch/blob/v1.0.1/torch/optim/lr_scheduler.py#L161
StepLR이 균일한 step size를 사용한다면 이번에 소개할MultiStepLR은 step size를 여러 기준으로 적용할 수 있는 StepLR의 확장 버전입니다.- StepLR과 사용방법은 비슷하며 StepLR에서 사용한 step_size 대신,
milestones에 리스트 형태로 step 기준을 받습니다. 다음 예제를 살펴보겠습니다.
scheduler = MultiStepLR(optimizer, milestones=[200, 350], gamma=0.5)
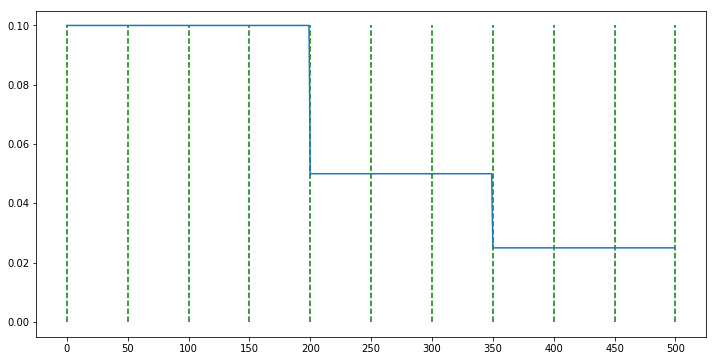
- 위 그래프에서 연두색 선은 50 epoch을 나타냅니다. 200 epoch과 350 epoch 선에서 learning rate가 0.5배가 된 것을 확인할 수 있습니다.
ExponentialLR
- pytorch : https://github.com/pytorch/pytorch/blob/v1.1.0/torch/optim/lr_scheduler.py#L201
- 지수적으로 learning rate가 감소하는 방법도 많이 사용합니다. 이번에 다룰 내용은 지수적으로 learning rate가 감소하는 ExponentialLR입니다.
- 지수적으로 감소하기 때문에 하이퍼 파라미터는 감소율
gamma하나 입니다. 따라서 다음과 같이 간단하게 사용할 수 있습니다.
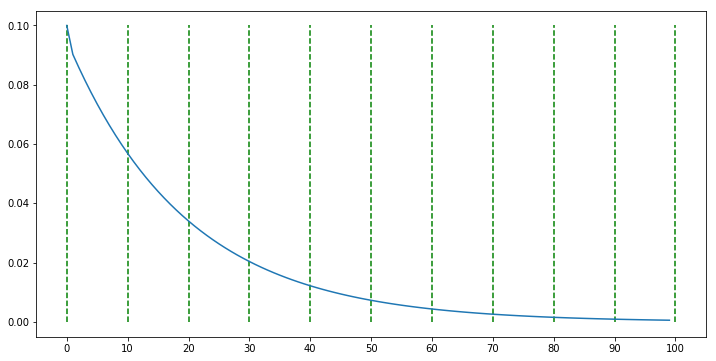
scheduler = ExponentialLR(optimizer, gamma=0.95)
CosineAnnealingLR
- pytorch 코드 : https://github.com/pytorch/pytorch/blob/v1.1.0/torch/optim/lr_scheduler.py#L222
CosineAnnealingLR은 cosine 그래프를 그리면서 learning rate가 진동하는 방식입니다. 최근에는 learning rate가 단순히 감소하기 보다는 진동하면서 최적점을 찾아가는 방식을 많이 사용하고 있습니다. 이러한 방법 중 가장 간단하면서도 많이 사용되는 방법이CosineAnnealingLR방식입니다.CosineAnnealingLR에 사용되는 파라미터는T_max라는 반주기의 단계 크기값과eta_min이라는 최소값입니다.
scheduler = CosineAnnealingLR(optimizer, T_max=100, eta_min=0.001)
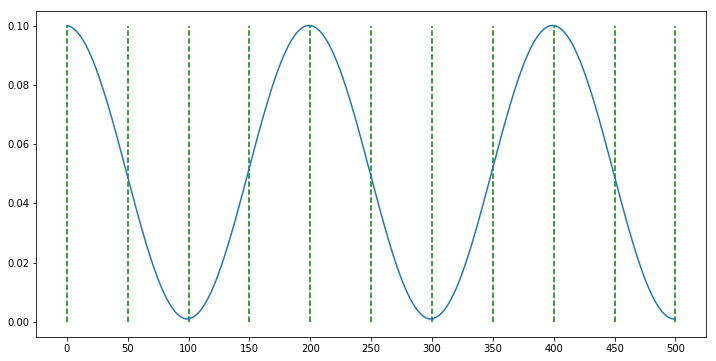
- 위 그래프에서 연두색 선은 50 epoch을 나타냅니다.
T_max = 100이기 때문에 cosine 그래프의 half cycle은 100이되므로 연두색 선 2칸을 차지합니다. - 이 때, 가장 최저점의 learning rate는
eta_min = 0.001이 됩니다. 이와 같은 방식으로 learning rate는 진동하게 됩니다.
CyclicLR
- 논문 : Cyclical Learning Rates for Training Neural Networks (https://arxiv.org/abs/1506.01186)
- pytorch 코드 : https://github.com/pytorch/pytorch/blob/v1.1.0/torch/optim/lr_scheduler.py#L442
CyclicLR방법 또한 많이 사용하는 방법입니다. 앞에서 설명한 CosineAnnealingLR은 단순한 cosine 곡선인 반면에 CyclicLR은 3가지 모드를 지원하면서 변화된 형태로 주기적인 learning rate 증감을 지원합니다.- 이 때 사용하는 파라미터로
base_lr,max_lr,step_size_up,step_size_down,mode가 있습니다.base_lr은 learning rate의 가장 작은 점인 lower bound가 되고max_lr은 반대로 learning rate의 가장 큰 점인 upper bound가 됩니다.step_size_up은 base_lr → max_lr로 증가하는 epoch 수가 되고step_size_down은 반대로 max_lr → base_lr로 감소하는 epoch 수가 됩니다. - 아래 코드를 보면서 사용된 파라미터와
mode에 대하여 다루어 보겠습니다.
scheduler = CyclicLR(optimizer, base_lr=0.001, max_lr=0.1, step_size_up=50, step_size_down=100, mode='triangular')
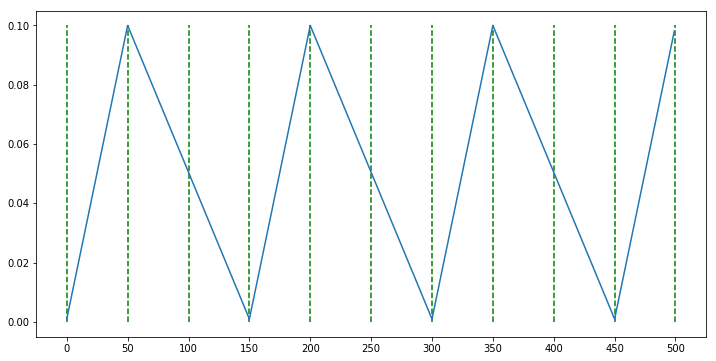
- 먼저 위 그래프를 살펴보겠습니다. 위 그래프틑
triangular모드에 해당합니다. learning rate는base_lr=0.001부터 시작해서step_size_up=50 epoch동안 증가하여max_lr=0.1까지 도달합니다. 그 이후step_size_down=100 epoch동안 감소하여 다시base_lr까지 줄어듭니다. 이 작업을 계속 반복하게 됩니다.
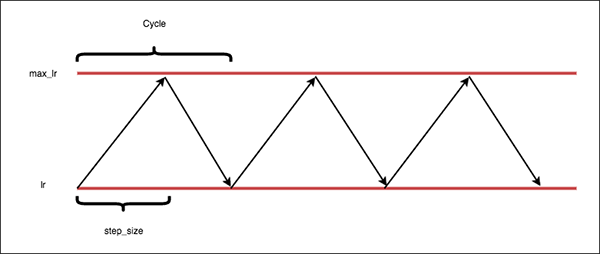
- 논문의 그림을 빌리면
triangular모드는 위 그림과 같습니다.
scheduler = CyclicLR(optimizer, base_lr=0.001, max_lr=0.1, step_size_up=50, step_size_down=None, mode='triangular2')
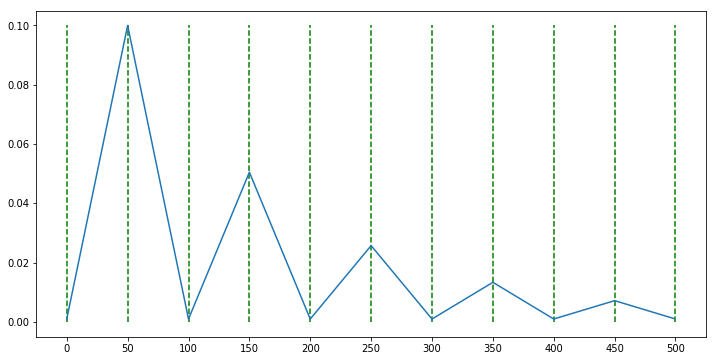
- 이번에는
triangular2모드에 대하여 다루어 보겠습니다. 이 모드에서는 주기가 반복되면서max_lr의 값이 반 씩 줄어드는 것을 볼 수 있습니다. - 위 코드에서는
step_size_down=None을 입력하였는데 이 경우step_size_up과 같은 주기를 같습니다. 따라서 상승 하강 주기가 모두 50 epoch이 됩니다. - 이 모드의 경우 max_lr이 반씩 줄어들기 때문에 마지막에는 수렴하게 됩니다.
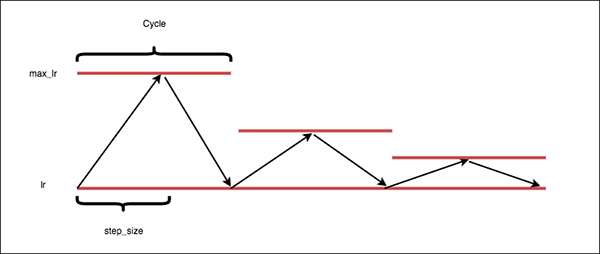
- 논문의 그림을 빌리면
triangular2모드는 위 그림과 같습니다.
scheduler = CyclicLR(optimizer, base_lr=0.001, max_lr=0.1, step_size_up=50, step_size_down=None, mode='exp_range', gamma=0.995)
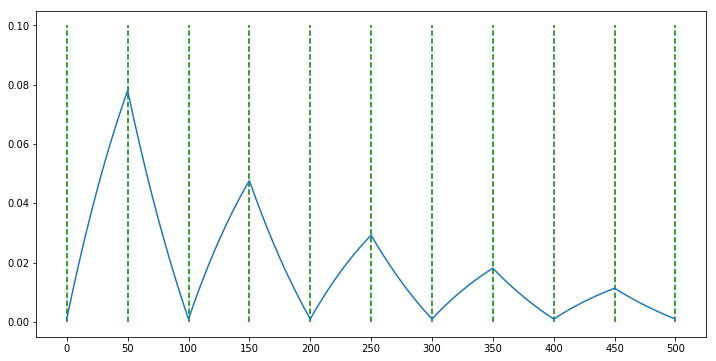
exp_range모드는triangular2와 유사합니다. 대신 선형 증감이 아니라 지수적 증감 방식을 사용합니다. 따라서 지수식의 밑에 해당하는gamma값을 따로 사용합니다.
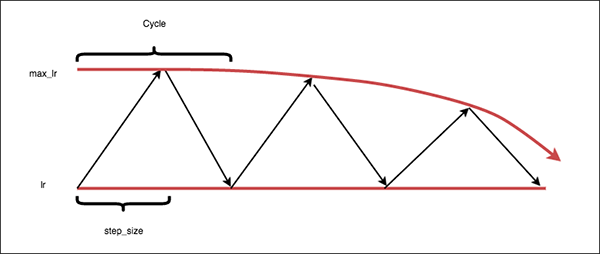
- 논문의 그림을 빌리면
exp_range모드는 위 그림과 같습니다.
CosineAnnealingWarmRestarts
- pytorch 코드 : https://github.com/pytorch/pytorch/blob/v1.1.0/torch/optim/lr_scheduler.py#L655
- 그 다음으로
CosineAnnealingWarmRestarts에 대하여 다루어 보겠습니다. - 개인적으로 이 스케쥴러는 아쉽게 구현이 되어있습니다. 왜냐하면 warmup start가 구현되어 있지 않고 learning rate 최댓값이 감소하는 방법이 구현되어 있지 않기 때문입니다.
- 따라서 아래 따로 구현한
Custom CosineAnnealingWarmRestarts을 사용하길 바랍니다. 대신에 pytorch에서 제공하는 기능은 간단하게 살펴만 보겠습니다. - 사용할 파라미터는 optimizer 외에
T_0,T_mult그리고eta_min이 있습니다.T_0는 최초 주기값 입니다.T_mult는 주기가 반복되면서 최초 주기값에 비해 얼만큼 주기를 늘려나갈 것인지 스케일 값에 해당합니다.eta_min은 learning rate의 최소값에 해당합니다.
scheduler = CosineAnnealingWarmRestarts(optimizer, T_0=50, T_mult=2, eta_min=0.001)
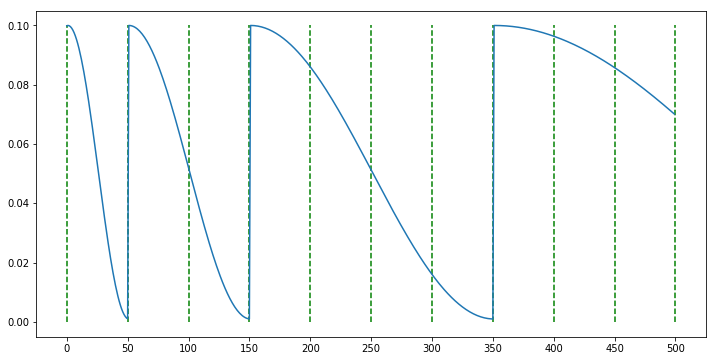
- 위 코드 예제는 50 epoch 주기를 초깃값으로 가지되 반복될수록 주기를 2배씩 늘리는 방법입니다.
- 앞에서 언급하였듯이 warmup start나 max값이 감소되는 기능은 없습니다.
Custom CosineAnnealingWarmRestarts
- pytorch 코드 : https://github.com/gaussian37/pytorch_deep_learning_models/blob/master/cosine_annealing_with_warmup/cosine_annealing_with_warmup.py
- 논문 : SGDR, Stochastic Gradient Descent with Warm Restarts (https://arxiv.org/abs/1608.03983)
- 논문 : bag of tricks for image classification (https://arxiv.org/abs/1812.01187)
- 이번에 다룰 스케쥴러는 많은 논문에서 사용 중이고 SGDR로 알려져 있으며 특히 bag of tricks for image classification에서 사용한 최적화 방법으로 좋은 성능을 보입니다.
- 간단하게 설명드리면 앞에서 다룬
CosineAnnealingWarmRestarts에 warm up start와 max 값의 감소 기능이 추가된 형태입니다. - 아래 코드는 Pytorch의 기존 CosineAnnealingWarmRestarts를 변경하여 사용되었습니다.
import math
from torch.optim.lr_scheduler import _LRScheduler
class CosineAnnealingWarmUpRestarts(_LRScheduler):
def __init__(self, optimizer, T_0, T_mult=1, eta_max=0.1, T_up=0, gamma=1., last_epoch=-1):
if T_0 <= 0 or not isinstance(T_0, int):
raise ValueError("Expected positive integer T_0, but got {}".format(T_0))
if T_mult < 1 or not isinstance(T_mult, int):
raise ValueError("Expected integer T_mult >= 1, but got {}".format(T_mult))
if T_up < 0 or not isinstance(T_up, int):
raise ValueError("Expected positive integer T_up, but got {}".format(T_up))
self.T_0 = T_0
self.T_mult = T_mult
self.base_eta_max = eta_max
self.eta_max = eta_max
self.T_up = T_up
self.T_i = T_0
self.gamma = gamma
self.cycle = 0
self.T_cur = last_epoch
super(CosineAnnealingWarmUpRestarts, self).__init__(optimizer, last_epoch)
def get_lr(self):
if self.T_cur == -1:
return self.base_lrs
elif self.T_cur < self.T_up:
return [(self.eta_max - base_lr)*self.T_cur / self.T_up + base_lr for base_lr in self.base_lrs]
else:
return [base_lr + (self.eta_max - base_lr) * (1 + math.cos(math.pi * (self.T_cur-self.T_up) / (self.T_i - self.T_up))) / 2
for base_lr in self.base_lrs]
def step(self, epoch=None):
if epoch is None:
epoch = self.last_epoch + 1
self.T_cur = self.T_cur + 1
if self.T_cur >= self.T_i:
self.cycle += 1
self.T_cur = self.T_cur - self.T_i
self.T_i = (self.T_i - self.T_up) * self.T_mult + self.T_up
else:
if epoch >= self.T_0:
if self.T_mult == 1:
self.T_cur = epoch % self.T_0
self.cycle = epoch // self.T_0
else:
n = int(math.log((epoch / self.T_0 * (self.T_mult - 1) + 1), self.T_mult))
self.cycle = n
self.T_cur = epoch - self.T_0 * (self.T_mult ** n - 1) / (self.T_mult - 1)
self.T_i = self.T_0 * self.T_mult ** (n)
else:
self.T_i = self.T_0
self.T_cur = epoch
self.eta_max = self.base_eta_max * (self.gamma**self.cycle)
self.last_epoch = math.floor(epoch)
for param_group, lr in zip(self.optimizer.param_groups, self.get_lr()):
param_group['lr'] = lr
- 먼저 warm up을 위하여 optimizer에 입력되는 learning rate = 0 또는 0에 가까운 아주 작은 값을 입력합니다.
- 위 코드의 스케쥴러에서는
T_0,T_mult,eta_max외에T_up,gamma값을 가집니다. T_0,T_mult의 사용법은 pytorch 공식 CosineAnnealingWarmUpRestarts와 동일합니다.eta_max는 learning rate의 최댓값을 뜻합니다.T_up은 Warm up 시 필요한 epoch 수를 지정하며 일반적으로 짧은 epoch 수를 지정합니다.gamma는 주기가 반복될수록eta_max곱해지는 스케일값 입니다.
optimizer = optim.Adam(model.parameters(), lr = 0)
scheduler = CosineAnnealingWarmUpRestarts(optimizer, T_0=150, T_mult=1, eta_max=0.1, T_up=10, gamma=0.5)
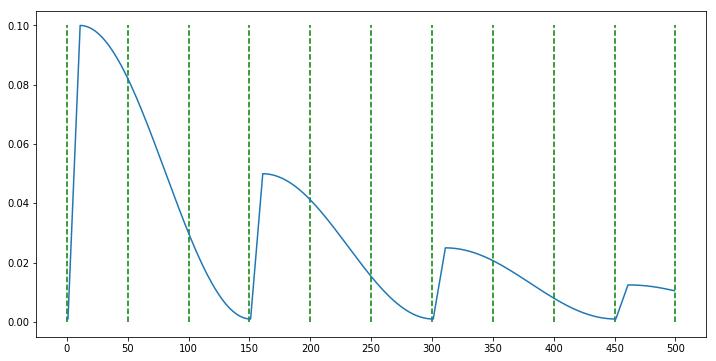
- 먼저 위 그래프의 연두색 선은 50 epoch을 나타냅니다. 따라서
T_0=150 epoch의 초기 주기값 후에 다시 0으로 줄어들게 됩니다. 이 때,T_up=10 epoch만에 learning rate는 0 →eta_max까지 증가하게 되고 다음 주기에는gamma=0.5만큼 곱해진eta_max * gamma만큼 warm up start 하여 learning rate가 증가하게 됩니다. - 앞에서도 언급하였지만 주의할 점은 optimizer에서 시작할 learning rate를 일반적으로 사용하는 learning rate가 아닌 0에 가까운 아주 작은 값을 입력해야 합니다.
scheduler = CosineAnnealingWarmUpRestarts(optimizer, T_0=50, T_mult=2, eta_max=0.1, T_up=10, gamma=0.5)
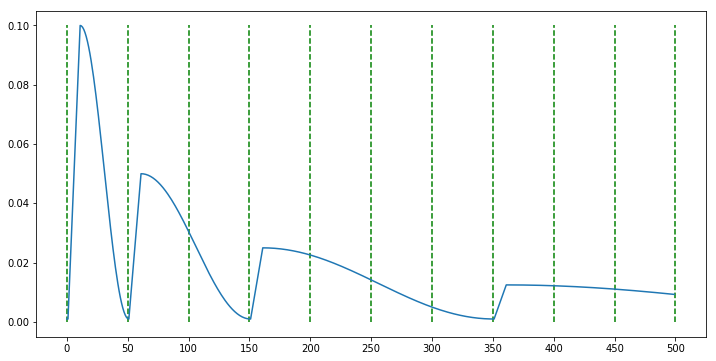
- 이번 예제에는
T_mult=2가 적용되었습니다. 따라서 주기가 반복될수록T_0 * T_mult만큼 주기가 늘어나게 됩니다. 따라서 위 예제와 같이 주기가 반복할수록 주기가 2배씩 늘어나는 것을 볼 수 있습니다.
scheduler = CosineAnnealingWarmUpRestarts(optimizer, T_0=100, T_mult=1, eta_max=0.1, T_up=10, gamma=0.5)
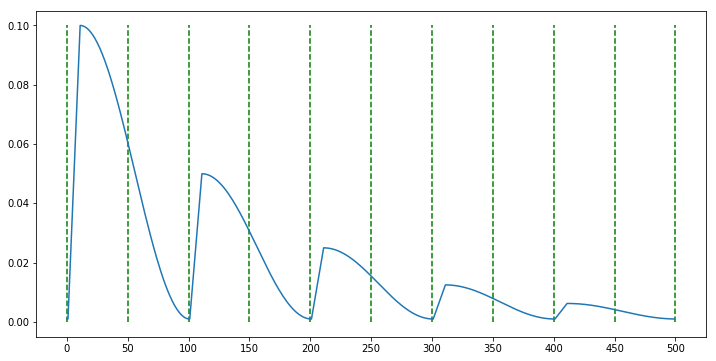
- 지금 까지 많이 사용하는 대표적인 learning rate scheduler에 대하여 다루어 보았습니다.
- 만약 어떤 것을 사용해야 할 지 모르겠다면 마지막
Custom CosineAnnealingWarmUpRestarts을 선언 후 사용해 보시길 추천드립니다.