
Pytorch의 시각화 및 학습 현황 확인
2020, Jan 03
- 참조 : https://medium.com/@avkashchauhan/deep-learning-and-machine-learning-models-visualization-43ca99aa7931
- 이 글에서는 Pytorch에서 학습 현황이나 모델 현황들을 정리해 보겠습니다.
목차
-
torchsummary를 통한 모델 정보 요약
-
torchinfo를 통한 모델 정보 요약
-
visdom을 통한 학습 상태 모니터링
-
graphviz를 통한 모델 시각화
-
netron을 통한 모델 시각화
-
tensorboard를 통한 학습 현황 확인
torchsummary를 통한 모델 정보 요약
- 참조 : https://deepbaksuvision.github.io/Modu_ObjectDetection/posts/03_04_torchsummary.html
-
참조 : https://medium.com/@umerfarooq_26378/model-summary-in-pytorch-b5a1e4b64d25
- 먼저 네트워크의 현황을 쉽게 알아보기 위한 방법으로
torchsummary기능을 사용하는 것입니다. 사용 방법은 다음과 같습니다.
from torchsummary import summary
summary(your_model, input_size=(channels, H, W))
- 즉, 위 사용법에서 볼 수 있듯이
input_size가 반드시 필요하며 이 shape 만큼 forward pass를 만들어 줍니다. - 따라서 딥러닝
model만 만들고 그 model의 input_size = (channels, height, width)을 안다면 model의 모양과 파라미터 등을 정리해서 볼 수 있습니다.
from torchvision import models
from torchsummary import summary
vgg = models.vgg16()
summary(vgg, (3, 224, 224)
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [-1, 64, 224, 224] 1,792
ReLU-2 [-1, 64, 224, 224] 0
Conv2d-3 [-1, 64, 224, 224] 36,928
ReLU-4 [-1, 64, 224, 224] 0
MaxPool2d-5 [-1, 64, 112, 112] 0
Conv2d-6 [-1, 128, 112, 112] 73,856
ReLU-7 [-1, 128, 112, 112] 0
Conv2d-8 [-1, 128, 112, 112] 147,584
ReLU-9 [-1, 128, 112, 112] 0
MaxPool2d-10 [-1, 128, 56, 56] 0
Conv2d-11 [-1, 256, 56, 56] 295,168
ReLU-12 [-1, 256, 56, 56] 0
Conv2d-13 [-1, 256, 56, 56] 590,080
ReLU-14 [-1, 256, 56, 56] 0
Conv2d-15 [-1, 256, 56, 56] 590,080
ReLU-16 [-1, 256, 56, 56] 0
MaxPool2d-17 [-1, 256, 28, 28] 0
Conv2d-18 [-1, 512, 28, 28] 1,180,160
ReLU-19 [-1, 512, 28, 28] 0
Conv2d-20 [-1, 512, 28, 28] 2,359,808
ReLU-21 [-1, 512, 28, 28] 0
Conv2d-22 [-1, 512, 28, 28] 2,359,808
ReLU-23 [-1, 512, 28, 28] 0
MaxPool2d-24 [-1, 512, 14, 14] 0
Conv2d-25 [-1, 512, 14, 14] 2,359,808
ReLU-26 [-1, 512, 14, 14] 0
Conv2d-27 [-1, 512, 14, 14] 2,359,808
ReLU-28 [-1, 512, 14, 14] 0
Conv2d-29 [-1, 512, 14, 14] 2,359,808
ReLU-30 [-1, 512, 14, 14] 0
MaxPool2d-31 [-1, 512, 7, 7] 0
Linear-32 [-1, 4096] 102,764,544
ReLU-33 [-1, 4096] 0
Dropout-34 [-1, 4096] 0
Linear-35 [-1, 4096] 16,781,312
ReLU-36 [-1, 4096] 0
Dropout-37 [-1, 4096] 0
Linear-38 [-1, 1000] 4,097,000
================================================================
Total params: 138,357,544
Trainable params: 138,357,544
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.57
Forward/backward pass size (MB): 218.59
Params size (MB): 527.79
Estimated Total Size (MB): 746.96
----------------------------------------------------------------
- 위 예제는 pytorch에서 기본적으로 제공하는 이미 선언된 모델을 이용한 것입니다.
- 이번에는 임의의 다음 코드와 같은 custom 모델을 이용하여 summary를 해보겠습니다.
torchinfo를 통한 모델 정보 요약
- 설치 :
pip install torchinfo - 안타깝게도 앞에서 설명한 torchsummary의 업데이트가 되지 않는 반면 새로운 모델 정보 요약 라이브러리인
torchinfo가 많이 사용되고 있습니다. -torchinfo는 기존의 torchsummary와 사용 방법은 거의 같습니다. 더구나 기존의 torchsummary에서 LSTM과 같은 RNN 계열의 Summary 시 일부 오류가 났던 문제와 layer 분류를 좀 더 계층적으로 상세히 해준다는 점 등의 개선이 있어서 torchsummary 대신torchinfo를 사용하는 것을 추천 드립니다. - 사용 방법의 일부 차이점은
torchinfo에서는 (batch, channel, height, width)와 같은 형태로 데이터를 입력 받습니다. 이는 torchsummary 에서 batch를 사용하지 않고 (channel, height, width)를 사용하는 것과 차이점입니다. 실제 사용하는 입장에서는 batch를 고려하여 모델을 설계하는 것이 더 현실적이기 때문에torchinfo를 사용하는 것이 더 좋다고 생각이 듭니다. - 아래는 VGG16에 (3, 224, 224) 크기의 이미지를 250개의 batch를 통하여 feedforward 하였을 때의 상태를 요약해 주는 예제 코드 입니다.
from torchvision import models
from torchinfo import summary
vgg = models.vgg16()
summary(vgg, (250, 3, 224, 224))
==========================================================================================
Layer (type:depth-idx) Output Shape Param #
==========================================================================================
├─Sequential: 1-1 [250, 512, 7, 7] --
| └─Conv2d: 2-1 [250, 64, 224, 224] 1,792
| └─ReLU: 2-2 [250, 64, 224, 224] --
| └─Conv2d: 2-3 [250, 64, 224, 224] 36,928
| └─ReLU: 2-4 [250, 64, 224, 224] --
| └─MaxPool2d: 2-5 [250, 64, 112, 112] --
| └─Conv2d: 2-6 [250, 128, 112, 112] 73,856
| └─ReLU: 2-7 [250, 128, 112, 112] --
| └─Conv2d: 2-8 [250, 128, 112, 112] 147,584
| └─ReLU: 2-9 [250, 128, 112, 112] --
| └─MaxPool2d: 2-10 [250, 128, 56, 56] --
| └─Conv2d: 2-11 [250, 256, 56, 56] 295,168
| └─ReLU: 2-12 [250, 256, 56, 56] --
| └─Conv2d: 2-13 [250, 256, 56, 56] 590,080
| └─ReLU: 2-14 [250, 256, 56, 56] --
| └─Conv2d: 2-15 [250, 256, 56, 56] 590,080
| └─ReLU: 2-16 [250, 256, 56, 56] --
| └─MaxPool2d: 2-17 [250, 256, 28, 28] --
| └─Conv2d: 2-18 [250, 512, 28, 28] 1,180,160
| └─ReLU: 2-19 [250, 512, 28, 28] --
| └─Conv2d: 2-20 [250, 512, 28, 28] 2,359,808
| └─ReLU: 2-21 [250, 512, 28, 28] --
| └─Conv2d: 2-22 [250, 512, 28, 28] 2,359,808
| └─ReLU: 2-23 [250, 512, 28, 28] --
| └─MaxPool2d: 2-24 [250, 512, 14, 14] --
| └─Conv2d: 2-25 [250, 512, 14, 14] 2,359,808
| └─ReLU: 2-26 [250, 512, 14, 14] --
| └─Conv2d: 2-27 [250, 512, 14, 14] 2,359,808
| └─ReLU: 2-28 [250, 512, 14, 14] --
| └─Conv2d: 2-29 [250, 512, 14, 14] 2,359,808
| └─ReLU: 2-30 [250, 512, 14, 14] --
| └─MaxPool2d: 2-31 [250, 512, 7, 7] --
├─AdaptiveAvgPool2d: 1-2 [250, 512, 7, 7] --
├─Sequential: 1-3 [250, 1000] --
| └─Linear: 2-32 [250, 4096] 102,764,544
| └─ReLU: 2-33 [250, 4096] --
| └─Dropout: 2-34 [250, 4096] --
| └─Linear: 2-35 [250, 4096] 16,781,312
| └─ReLU: 2-36 [250, 4096] --
| └─Dropout: 2-37 [250, 4096] --
| └─Linear: 2-38 [250, 1000] 4,097,000
==========================================================================================
Total params: 138,357,544
Trainable params: 138,357,544
Non-trainable params: 0
Total mult-adds (G): 15.61
==========================================================================================
Input size (MB): 143.55
Forward/backward pass size (MB): 25857.38
Params size (MB): 527.79
Estimated Total Size (MB): 26528.72
==========================================================================================
- 마지막의
Estimated Total Size를 참조하면 실제 학습할 때 사용할 GPU 양을 계산할 수 있습니다. 이를 통해 현재 GPU 자원을 기준으로 적당한 batch 크기를 계산할 수 있습니다.
visdom을 통한 학습 상태 모니터링
- 참조 : https://github.com/GunhoChoi/PyTorch-FastCampus/blob/master/02_Regression%26NN/Visdom_Tutorial.ipynb
visdom은 딥러닝 학습할 때, 학습 상황을 모니터링 하기 위한 기능 중에 하나입니다. 유사한 기능으로는tensorboard가 있습니다.- 이번 글에서는
visdom을 사용하여 학습 상황을 모니터링하는 방법에 대하여 간략하게 알아보도록 하겠습니다. - 먼저 visdom을 실행하려면 커맨드 창에서 서버를 하나 띄워야 합니다. 서버를 띄우기 위해 다음 명령어를 실행합니다.
python -m visdom.server
- 그러면 커맨드 창에
You can navigate to http://localhost:8097와 같은 형태의 로그가 남게 됩니다. - 위 주소를 브라우저에 입력하면 아래와 같은
visdom환경을 사용할 수 있습니다.
from visdom import Visdom
viz = Visdom()
textwindow = viz.text("Hello")
- 코드를 입력 가능한 환경에서 위와 같이 코드를 입력 한다면 브라우저에서 “Hello”라는 문자열이 출력된 것을 볼 수 있습니다.
image_window = viz.image(
np.random.rand(3,256,256),
opts=dict(
title = "random",
caption = "random noise"
)
)

- 위 코드를 입력하면 이미지 형태로 보여줄 수 있습니다.
images_window = viz.images(
np.random.rand(10,3,64,64),
opts=dict(
title = "random",
caption = "random noise"
)
)

- 여기서 3채널 이상의 채널을 입력하였을 때에는 위와 같이 펼쳐 10개의 RGB 이미지를 펼쳐주는 것을 볼 수 있습니다.
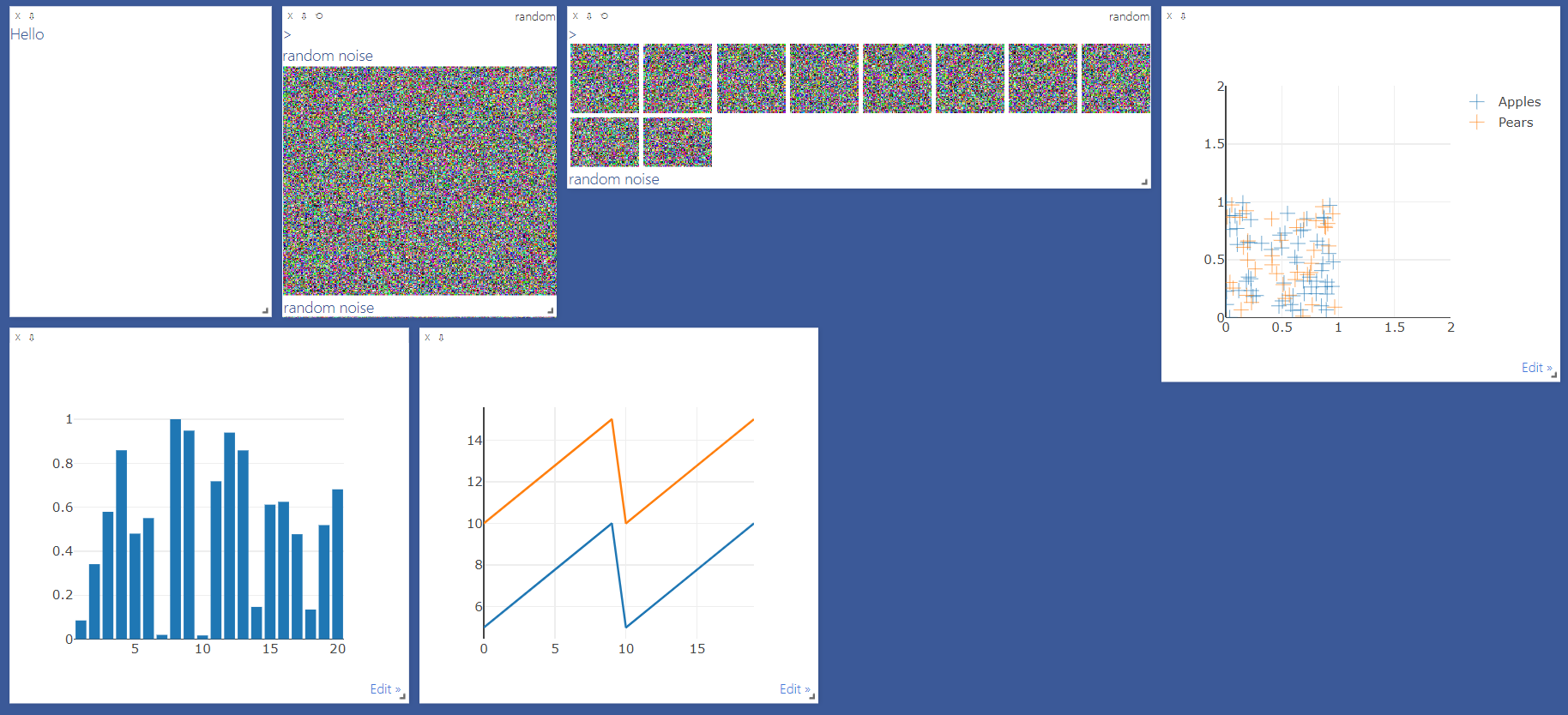
- 다양한 그래프를 깔끔하게 그려줄 수도 있습니다. 이 기능들은
plot.ly를 이용한 것입니다.
- 딥러닝 학습을 할 때, 학습의 변화를 관측하기 위하여 tensorboard나 visdom을 사용합니다.
- 그러면 주 목적인 측정 지표를 어떻게 실시간으로 업데이트 할 지 살펴보겠습니다.
- 먼저 측정한 지표는
line형태로 주로 나타내기 때문에 아래와 같이 사용할 수 있습니다.
plot = viz.line(
X = np.array([0, 1, 2, 3, 4]),
Y = torch.randn(5),
)
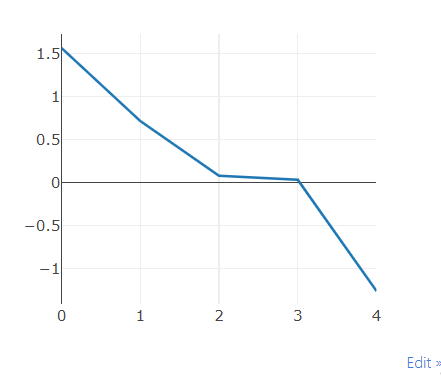
- 위와 같이 코드를 입력하면
visdom에 line이 그려집니다. - 코드를 해석하면 X축의 값과 Y축의 값이 대입되어 있는 것을 볼 수 있습니다.
- 여기서 중요한 것은
viz.line()을 plot으로 받았다는 것입니다.
viz.line(X = np.array([5]), Y = torch.randn(1), win = plot, update = 'append')
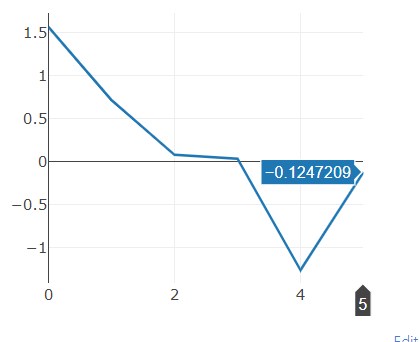
- 위 코드를 보면
plot에append방식으로 (X, Y)를 업데이틑 하는 것을 뜻합니다. - 위 코드를 응용하면 **매 번의 epoch 마다 Accuracy, Precision, Recall 등의 지표가 어떻게 변하는 지 실시간으로 관찰할 수 있습니다.
- 다음은 실제로 사용할 수 있는 예제를 살펴보겠습니다.
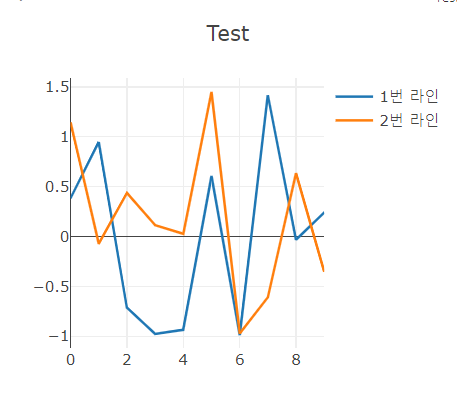
viz.line(
X = np.column_stack((np.arange(0, 10), np.arange(0, 10))),
Y = torch.randn(10, 2),
opts = dict(
title = "Test",
legend = ["1번 라인", "2번 라인"],
showlegend = True
)
)
graphviz를 통한 모델 시각화
- pytorch에서
graphviz를 통하여 모델을 시각화 할 때, 다음 2가지를 설치해야 합니다.graphviztorchviz
- 먼저
graphviz설치 방법입니다. - windows 사용 시 아래 링크에서
*.msi파일을 받은 후 설치합니다.- windows의 graphviz 설치 파일 : https://graphviz.gitlab.io/_pages/Download/Download_windows.html
- windows 이외의 환경에서는 아래 링크에 접속 하여 설치합니다.
- graphviz 설치 파일 링크 : https://graphviz.gitlab.io/download/
- wondows 기준으로 기본 경로로 설정하면 다음 경로에 graphviz가 설치됩니다.
- 설치된 경로 : C:\Program Files (x86)\Graphviz2.38\bin
- 계속하여 windows 기준으로 설명하면 설치를 하였을 때의 경로(C:\Program Files (x86)\Graphviz2.38\bin)를 (고급 시스템 설정 보기 - 환경 변수 - path)에 등록 후 재부팅 합니다.
- 그 다음으로
torchviz설치 방법입니다. 저는pip환경을 주로 사용하므로pip를 이용한 설치 방법은 다음과 같습니다.- 설치 1 :
pip install torchviz - 설치 2 :
pip install graphviz
- 설치 1 :
- 설치가 완료되면 다음과 같은 방법으로 graph를 그릴 수 있습니다. 아래 코드를 이용하여 간단한 네트워크 구조를 만들어 본 뒤 graph를 생성해 보겠습니다.
from torchviz import make_dot
from torch.autograd import Variable
model = nn.Sequential()
model.add_module('W0', nn.Linear(8, 16))
model.add_module('tanh', nn.Tanh())
# Variable을 통하여 Input 생성
x = Variable(torch.randn(1, 8))
# 앞에서 생성한 model에 Input을 x로 입력한 뒤 (model(x)) graph.png 로 이미지를 출력합니다.
make_dot(model(x), params=dict(model.named_parameters())).render("graph", format="png")
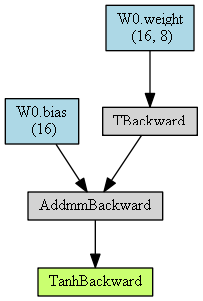
make_dot함수의 2번째 파라미터인params는 dictionary로 출력 시 아래와 같은 값을 가지며 graph의 노드에 내용을 기록합니다.- 아래 dictionary 에서 key 값을 이용하여 노드의 description으로 사용됩니다.
{'W0.weight': Parameter containing:
tensor([[ 0.0185, 0.2153, -0.1656, -0.0408, -0.2663, 0.0856, 0.1391, -0.1638],
[-0.3323, -0.0382, 0.3480, 0.1085, -0.0556, 0.0960, 0.0335, -0.1688],
[ 0.0233, -0.1096, -0.0951, -0.1614, -0.3147, 0.0567, 0.0194, 0.0006],
[-0.0470, -0.0736, 0.0893, 0.2884, -0.0908, -0.1680, -0.1470, 0.2240],
[ 0.2011, 0.0820, -0.2302, 0.0455, 0.0299, -0.2891, 0.1577, 0.1492],
[ 0.2150, -0.2890, 0.3529, 0.0599, 0.0362, -0.1695, -0.3131, -0.0038],
[-0.2578, -0.1018, -0.1806, -0.1187, 0.3324, -0.2751, -0.0826, 0.2949],
[-0.0076, 0.3321, -0.2230, -0.2180, 0.2186, -0.3149, -0.0771, -0.2608],
[-0.0456, -0.0793, 0.1187, -0.0683, -0.0952, 0.3463, -0.2887, 0.2991],
[ 0.2906, 0.1747, -0.1580, -0.2925, -0.3426, 0.1422, -0.1813, -0.0478],
[ 0.2726, 0.2489, 0.2315, -0.1059, -0.2196, -0.0942, 0.0975, 0.0384],
[-0.0050, 0.0482, -0.0005, -0.3295, -0.0809, 0.2922, 0.0284, -0.3526],
[-0.3084, 0.1586, 0.1185, -0.0663, -0.0610, -0.0461, 0.2608, -0.3014],
[ 0.3216, 0.0423, 0.1459, 0.1183, -0.2403, 0.1154, -0.3481, -0.2284],
[ 0.3139, 0.0864, -0.1457, -0.2685, 0.2632, 0.1253, -0.0926, 0.2467],
[ 0.0160, 0.1017, -0.2498, -0.2490, -0.0378, 0.1362, 0.2760, -0.1610]],
requires_grad=True),
'W0.bias': Parameter containing:
tensor([-0.0809, 0.2801, 0.0043, 0.2818, -0.1833, -0.0775, 0.2175, 0.3165,
0.2796, -0.0485, -0.1416, 0.2230, 0.0059, 0.3444, 0.2317, -0.3440],
requires_grad=True)}
netron을 통한 모델 시각화
- 앞에서 다룬
torchsummary와graphviz모두 model의 현황을 확인 하기 위한 좋은 방법이지만, 좀 더 세련되고 정보를 가득히 저장할 수 있는 방법이 있습니다. 바로netron을 통한 시각화 방법입니다. - 현재 까지 제가 아는 방법 중 가장 세련된 방법이니 이 방법은 꼭 배워두면 좋을 것 같습니다.
netron은 앞에서 다룬 torchsummary나 graphviz와 같이 현재 메모리에 올라가 있는model을 이용하여 시각화 하는 것이 아니라 파일 형태로 저장한 모델을 이용하여 시각화합니다. 저장한 model 파일을 이용하므로 다양한 framework에서 여러 가지 방식으로 저장한 파일들이 호환이 되도록 만들어졌습니다.- 이 글에서 다룰 내용은
pytorch에서 만든model을onnx형태로 저장하고 이 저장한 파일을 시각화 해보겠습니다. 보통 pytorch에서는*.pth형태로 model을 저장하는데,*.pth파일은 전체 그래프를 저장하지 않지만 나머지는 Python 모듈로 인코딩되므로 최상위 노드 만 저장합니다. 따라서 전체 그래프를 저장하는onnx파일을 이용해야 합니다.- 참조 : https://github.com/lutzroeder/netron/issues/236
- 먼저
netron을 이용하기 위하여 아래 링크에서 각 OS 환경에 맞게 설치 파일을 받아 설치해 줍니다.- netron 설치 링크 : https://github.com/gaussian37/netron
- 그 다음 pytorch로 만든 model을
onnx파일 형태로 저장합니다. 관련 내용은 아래 링크를 통해 참조하실 수 있습니다.- pytorch onnx 링크 : https://gaussian37.github.io/dl-pytorch-deploy/
- 퀵 하게 내용을 살펴 보려면 다음과 같은 과정을 이용하여
onnx파일을 저장하면 됩니다. 주석에 유념해서 의미를 해석해 보시기 바랍니다.
import torch
import torchvision # model을 불러오기 위해 import 하였습니다.
import torch.onnx
# 1. 임의의 model을 사용해도 되며, 실제 사용하는 custom model을 불러와서 저장해 보시기 바랍니다.
model = torchvision.models.vgg16(pretrained=False)
# 2. model의 파라미터를 OrderedDict 형태로 저장합니다.
params = model.state_dict()
# 3. 동적 그래프 형태의 pytorch model을 위하여 data를 model로 흘려주기 위한 더미 데이터 입니다.
dummy_data = torch.empty(1, 3, 224, 224, dtype = torch.float32)
# 4. onnx 파일을 export 해줍니다. 함수에는 차례대로 model, data, 저장할 파일명 순서대로 들어가면 됩니다.
torch.onnx.export(model, dummy_data, "output.onnx")
- 앞에서
netron을 설치하였기 때문에onnx파일의 아이콘이netron형태가 되어있을 것입니다. 즉,onnx가 더블 클릭을 통해 실행이 가능해 졌습니다. - 위 예제에서 다룬
vgg16모델을 한번 불러와 보겠습니다.
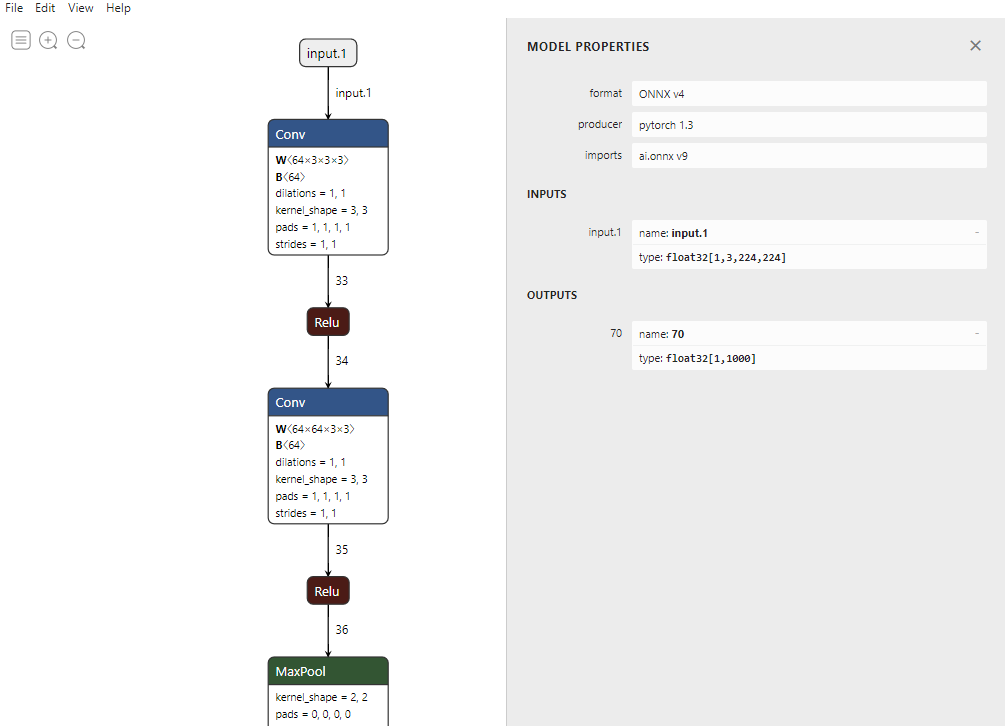
- 위 그림을 보면 modelpropeties 부터 각 layer의 상세한 정보까지 볼 수 있습니다.
- 이 결과를 저장할 때에는 메뉴의 File → Export 를 한 후
SVG형태로 저장하길 추천드립니다. 웹 브라우저에서 열리며 확대해도 해상도가 깨지지 않습니다. png로 저장하면 나중에 확대해서 보는 데 불편함이 있습니다.
tensorboard를 통한 학습 현황 확인
- 참조 : https://tensorboardx.readthedocs.io/en/latest/tensorboard.html
- 참조 : https://pytorch.org/docs/stable/tensorboard
- 이 글에서는 pytorch에서
tensorboard를 사용하는 방법에 대하여 다루어 보도록 하겠습니다. tensorflow에서 사용하는 tensorboard와 완전히 동일한 그 tensorboard 입니다. - 먼저 tensorboard를 설치하기 위하여 다음 명령어를 사용합니다.
- 명령어 :
pip install tensorboard
- 명령어 :
- 그 다음 tensorboard를 사용하기 위해서는 아래과 같이
SummaryWriter를 import하고 객체를 할당합니다. - pytorch에 tensorboard가 직접적으로 도입되기 이전에는 pytorch를 이용하여 쉽게 사용하기 위하여
tensorboardX라는 것을 사용하였습니다. 이것 또한 동일하게SummaryWriter를 사용합니다.
from torch.utils.tensorboard import SummaryWriter
# from tensorboardX import SummaryWriter
writer = SummaryWriter()
- 위 코드에서는 SummaryWriter 객체를 선언할 때, 어떤 옵션도 사용하지 않은 기본적인 형태입니다. 상세한 옵션은 위 참조 링크인 pytorch 문서를 확인하시기 바랍니다.
- 위와 같이 사용하여도 충분히 잘 사용할 수 있으니 이 글에서는 기본값을 사용하도록 하겠습니다. 기본적으로
run폴더에 날짜와 시간 별로 log를 생성합니다. - 다음 코드를 참조하여 어떻게 Tensorboard를 사용하는 지 살펴보겠습니다.
from torch.utils.tensorboard import SummaryWriter
import numpy as np
writer = SummaryWriter()
for n_iter in range(100):
writer.add_scalar('Loss/train', np.random.random(), n_iter)
writer.add_scalar('Loss/test', np.random.random(), n_iter)
writer.add_scalar('Accuracy/train', np.random.random(), n_iter)
writer.add_scalar('Accuracy/test', np.random.random(), n_iter)
- 위 코드는 random 값을 이용하여 tensorboard의 scalar 기능을 사용해 볼 수 있는 코드입니다.
- 일반적으로 가장 많이 사용하는 기능이 다음 그림과 같은 그래프를 실시간으로 보기 위한 기능입니다.
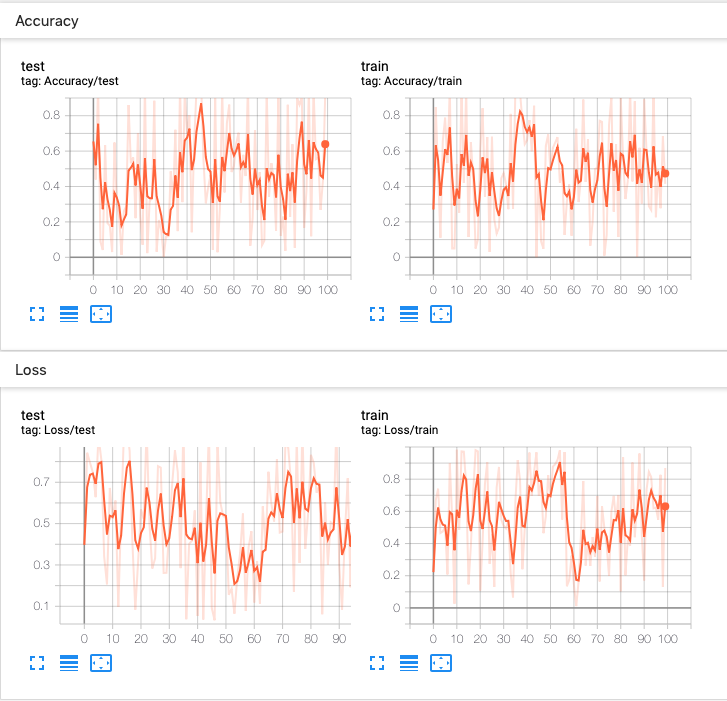
- 위 코드와 같이
writer.add_scalar('title', y_value, x_value)순서로 입력하면 위 그래프를 생성할 수 있습니다. .add_scalar에서 첫번째 인자는 그래프의 제목입니다. 두번째 인자는 세로축인 y값이고 세번째 인자는 가로축인 x값입니다.- 즉, 위 그래프는 iteration이 증가할수록 loss 및 accuracy가 어떻게 변화하는 지 확인하기 위한 그래프입니다.
- 정리하면 같은
title을 기준으로 x, y 값을 계속 저장하면 차례대로 누적되어서 원하는 그래프를 그릴 수 있습니다.
from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter()
x = range(100)
for i in x:
writer.add_scalar('y=2x', i * 2, i)
writer.close()
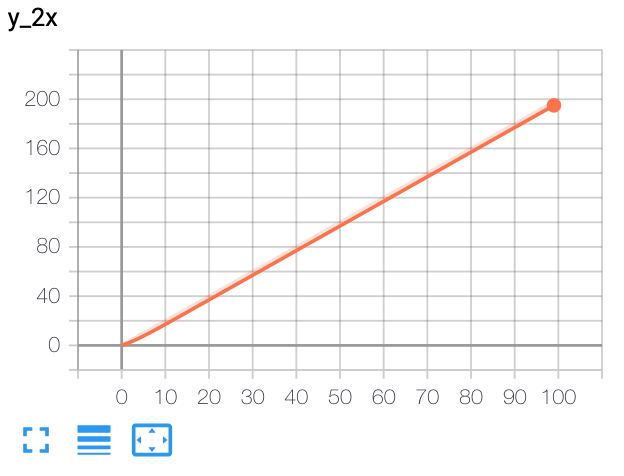
- 위 그림을 보면 x축이 0 ~ 99 까지 증가할 때, y 축은 2배씩 증가하는 \(y = 2x\) 그래프가 그려지는 것을 확인할 수 있습니다.
- 만약 한 개의 좌표평면에 여러 개의 그래프를 그리고 싶으면 어떻게 그릴 수 있을까요?
- 중괄호 (
{ })를 이용하여 여러개의 식을 묶으면 됩니다. 물론 x축의 값은 하나가 입력됩니다. 보통 epoch에 따른 train, validation의 성능을 한번에 비교할 때 많이 사용됩니다. - 다음 예제를 참조 하시기 바랍니다.
from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter()
r = 5
for i in range(100):
writer.add_scalars('run_14h', {'xsinx':i*np.sin(i/r),
'xcosx':i*np.cos(i/r),
'tanx': np.tan(i/r)}, i)
writer.close()
# This call adds three values to the same scalar plot with the tag
# 'run_14h' in TensorBoard's scalar section.
- 만약 저장 위치를 변경 및 코멘트 추가를 하고 싶다면 다음 코드를 응용하여 사용할 수 있습니다.
- 기본 저장 위치는 runs 폴더가 생성되고 그 아래에 날짜와 현재 컴퓨터의 이름을 기반으로 만들어 집니다.
from torch.utils.tensorboard import SummaryWriter
# create a summary writer with automatically generated folder name.
writer = SummaryWriter()
# folder location: runs/May04_22-14-54_s-MacBook-Pro.local/
# create a summary writer using the specified folder name.
writer = SummaryWriter("my_experiment")
# folder location: my_experiment
# create a summary writer with comment appended.
writer = SummaryWriter(comment="LR_0.1_BATCH_16")
# folder location: runs/May04_22-14-54_s-MacBook-Pro.localLR_0.1_BATCH_16/
- 지금 까지 내용을 통하여
writer.add_scalar()의 사용법을 정리하면 다음과 같습니다. writer.add_scalar('title', y축 값, x축 값)으로 사용하며title을 고정하여 계속 값을 추가하면 그래프가 그려집니다. 일반적으로x축 값에는epoch을 사용하고y축 값에는 성능 지표 또는 loss 등을 사용하여 표현합니다. 예를 들면writer.add_scalar('loss', loss, epoch)과 같은 형태로 사용할 수 있습니다.
- 영상 데이터를 처리할 때에는 학습 단계에서 이미지의 학습 과정을 출력해야 하는 단계가 필요합니다.
- tensorboard에서 이미지를 출력하기 위해서는
writer.add_image('이미지 출력 라벨', x, iteration)형식으로 사용합니다. - 첫번째 인자인 이미지 출력 라벨은 tensorboard에서 어떤 라벨로 표시되어 결과가 출력되는 지 이미지의 제목을 나타냅니다.
- 두번째 인자인
x는 출력되는 텐서를 의미합니다. 텐서의 shape은[3, H, W]가 되어야 하며 batch 단위로 표현하려면 별도의 make_grid 함수를 사용해야 합니다. 우선 단일 이미지 기준으로 처리한다면 3차원의[3, H, W]shape의 텐서를 넣으면 됩니다. - 마지막 인자인
iteration은 몇번째 iteration의 이미지인 지 표시합니다.이미지 출력 라벨이 동일한 이미지는 아래 그림과 같이 횡방향 스크롤바를 통하여 연속적으로 보여주기 때문입니다.
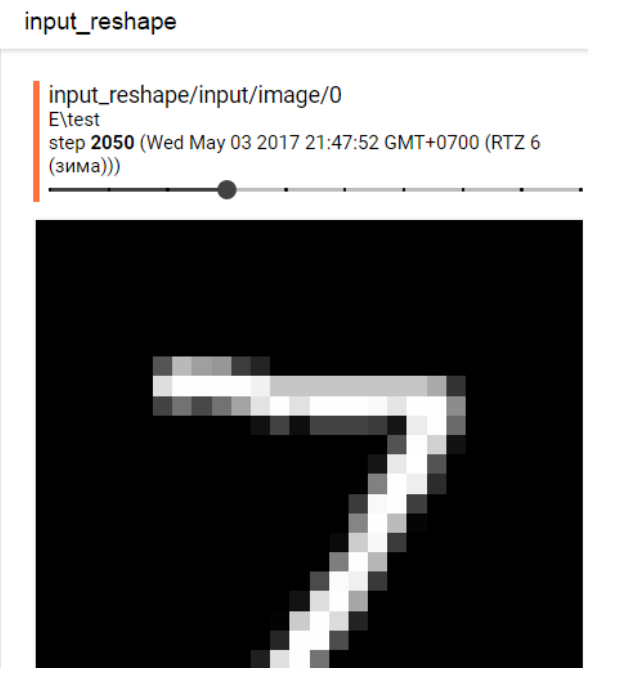
- 이 때 고려할 점은 크게 2가지 입니다. 먼저 uint8 형태의 RGB (또는 BGR) 이미지를 사용하였을 때, 일반적으로 이 값을 그대로 사용하지 않고 normalize 해서 사용합니다. 따라서 컬러 형태로 tensorboard에서 출력하기 위해서는 normalize 한 역 방향으로 uint8 타입으로 변환을 해서 사용해야 합니다.
- 예를 들어 red 값의 mean = 100, std = 25라고 하고
red_norm = (red - mean) / std와 같은 형태로 normalize 하였다면 그 역방향인red_norm * std + mean = red와 같이 처리를 해주어야 정확한 컬러값을 출력할 수 있습니다. 방법은 아래와 같습니다.
def rgb_inverse_normalize(x, mean, std):
rgb = x.clone()
for i in range(3):
rgb[i] *= std[i]
for i in range(3):
rgb[i] += mean[i]
rgb.type(torch.uint8)
return rgb
- 만약 grayscale 이미지를 출력할 때, grayscale 이미지 또한 컬러값처럼 변경하여 출력합니다. 따라서 1 channel의 grayscale 값을 복사하여 3 channel의 grayscale 값으로 만들어준 다음 출력하면 됩니다.
def grayscale_3ch(x):
x = x.unsqueeze(0).expand(3, -1, -1)
return x
- 따라서 실제 torch 코드에서 사용 중인
tensor는 위 함수를 사용하여 다음과 같이 시각화 할 수 있습니다.
from torch.utils.tensorboard import SummaryWriter
# from tensorboardX import SummaryWriter
writer = SummaryWriter()
for i in range(100):
# rgb_tensors : (3, H, W) 100 tensors, normalized with torch transform.
rgb_tensor_visualize = rgb_inverse_normalize(rgb_tensors[i], mean, std)
# grayscale_tensors : (H, W) 100 tensors, normalized with torch transform.
grayscale_tensor_visualize = grayscale_3ch(grayscale_tensors[i])
writer.add_image("visualize image", rgb_tensor_visualize, i)
writer.add_image("grayscale image", grayscale_tensor_visualize, i)