
Transport Layer
2020, Oct 03
- 이번 글에서는 OSI 7 계층 중 Transport Layer에 대하여 다루어 보겠습니다.
목차
-
transport-layer services
-
multiplexing and demultiplexing
-
connectionless transport : UDP
-
principles of reliable data transfer
-
connection-oriented transport : TCP
-
principles of congestion control
-
TCP congestion control
transport-layer services
multiplexing and demultiplexing

- 앞에서 설명한 바와 같이 편지를 모아서 우체통에 넣어주는 것이 multiplexing이고 편지를 받아서 집에 사는 다른 사람에게 나누어 주는 것을 demultiplexing이라고 하였습니다. 그리고 각각의 집에 사는 사람들이 process 라고 설명하였습니다.
- 그러면 multiplexing과 demultiplex을 비유가 아닌 process를 기준으로 설명해 보도록 하겠습니다.
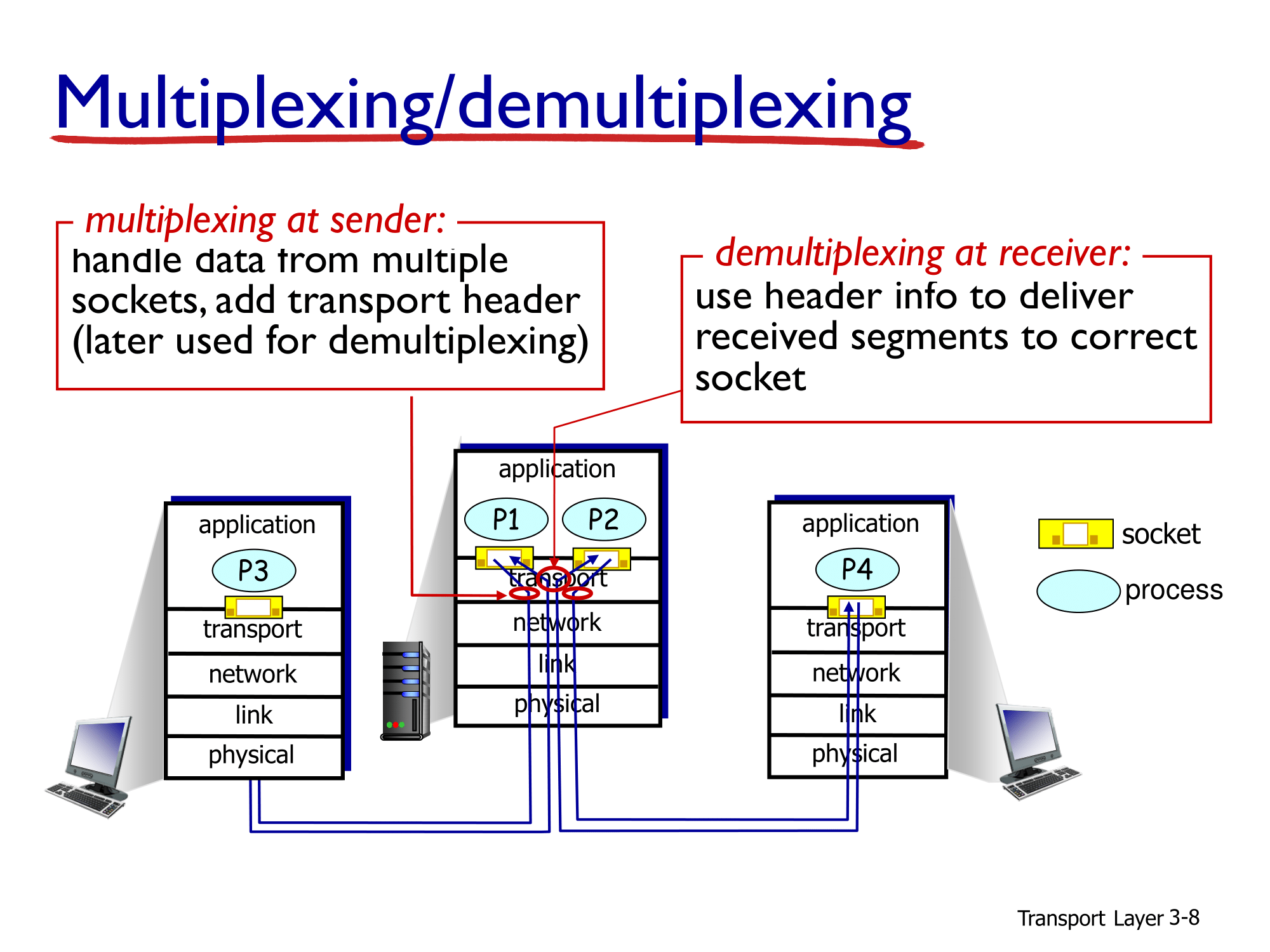
- multiplexing에 대하여 설명드리겠습니다. 먼저 여러개의 message는 application layer로 부터 socket을 통해 transport layer로 전달됩니다.
- 여기서 process를 접근하기 위해서는 socket을 이용해야 하고 process를 구별하기 위해서는 PORT 넘버를 이용해야 합니다. host 자체는 IP 주소를 이용하여 구분하지만 process는 PORT 넘버를 이용하여 구분한다는 것을 기억하시기 바랍니다.
- socket을 통하여 데이터가 전달 될 때, 데이터에 transport header를 붙입니다. 이 header는 나중에 demultiplexing에 사용되고 이 header를 통하여 어느 process에 데이터를 보내는 지 알 수 있어야 합니다.
- 반면 demultiplexing에서는 받은 세그먼트들을 맞는 socket에 보내기 위해서 PORT 넘버를 보게 됩니다.
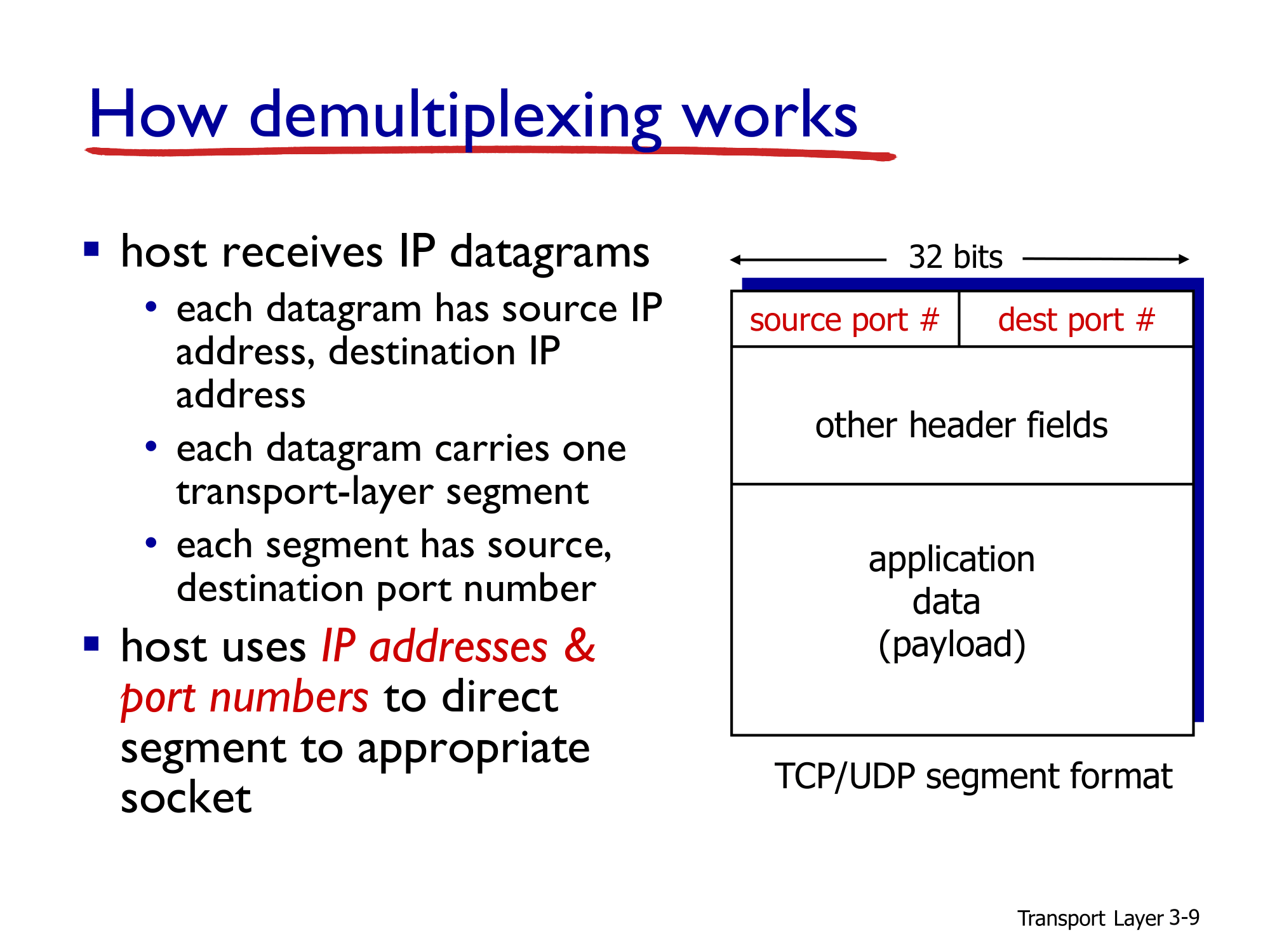
- demultiplexing에서 PORT 넘버를 참조할 때, 위와 같은 구조의 header에서 확인할 수 있습니다.
- TCP/UDP의 segment format에는 차이가 있지만 공통적으로 가지고 있는 포맷은 위 슬라이드와 같습니다. 기본적으로 source port와 dest port는 header에 있어야 합니다.
- 먼저 host의 transport layer에서는 IP datagram을 받습니다. 각각의 datagram에는 source와 destination의 IP 주소를 가지고 있습니다. 그리고 이 IP datagram에 앞에서 설명한 PORT 넘버를 붙이게 됩니다.
- 위 슬라이드의 TCP/UDP segment format을 보면 application data가 전달할 데이터가 되고 거기에 IP 주소와 PORT 넘버가 추가적으로 붙으면서 포맷이 완성이 된다.
- 정리하면 IP 주소와 PORT 넘버를 가지고 어떠한 host에 어떠한 socket으로 segment를 보내야 하는 지를 결정할 수 있습니다.

- 위 슬라이드 제목의 Connectionless는 UDP를 의미합니다. UDP는 시작할 때, 상대측에 request를 보내지 않습니다. 단순히 상대 측의 IP 주소와 PORT 넘버를 가지고 데이터를 그냥 보내는 역할을 합니다.
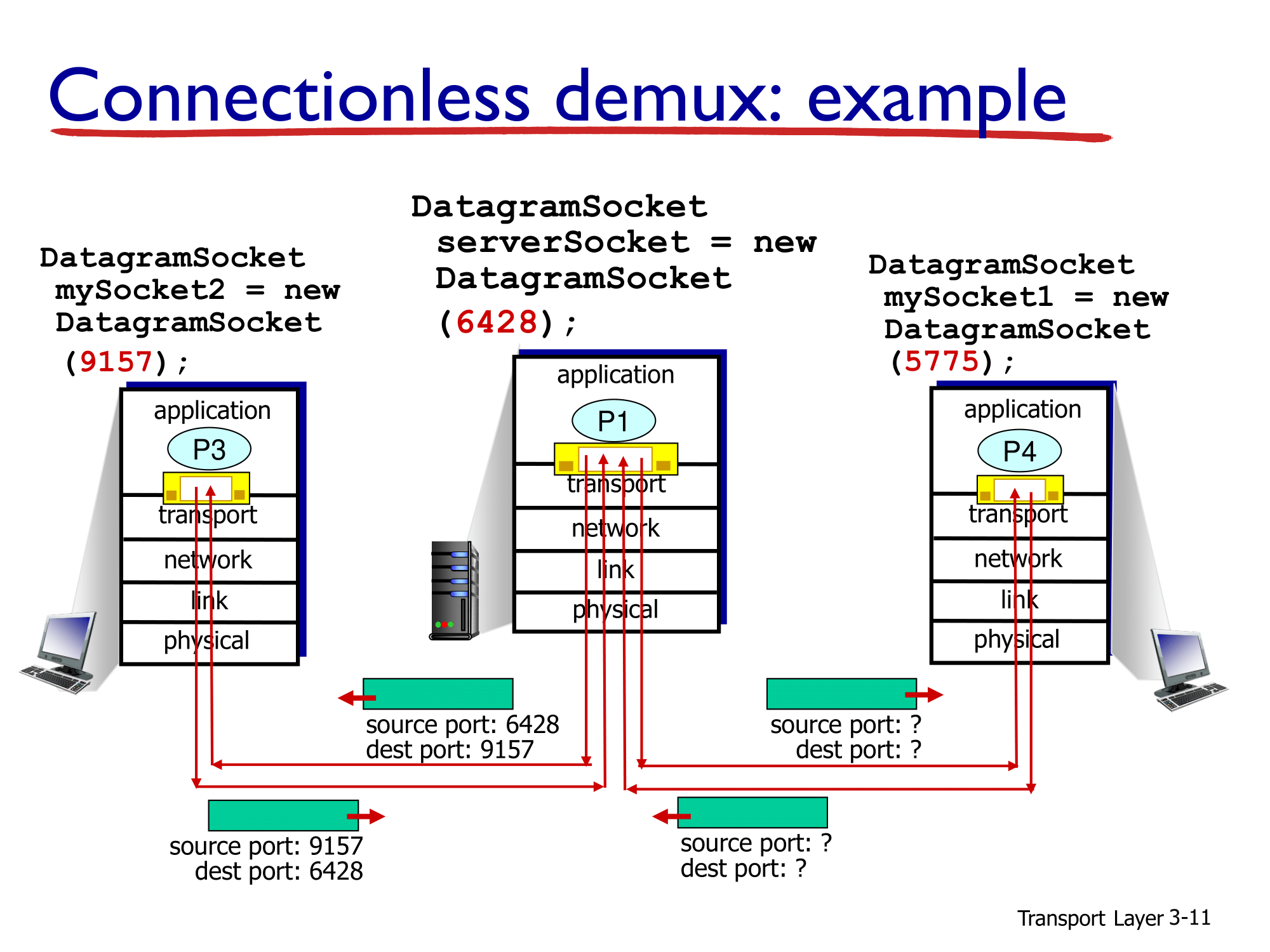
- 위 슬라이드를 보면 header에 추가된 port 정보를 통하여 source와 destination을 구분할 수 있음을 보여줍니다.
- 사실 UDP에서는 source port 넘버가 필요하진 않습니다. 말 그대로 connectionless 이기 때문입니다. 하지만 간혹 에러가 발생하였을 때, source 쪽으로 데이터를 전달하기 위하여 사용하기는 하지만 원칙적으론 필요는 없습니다.

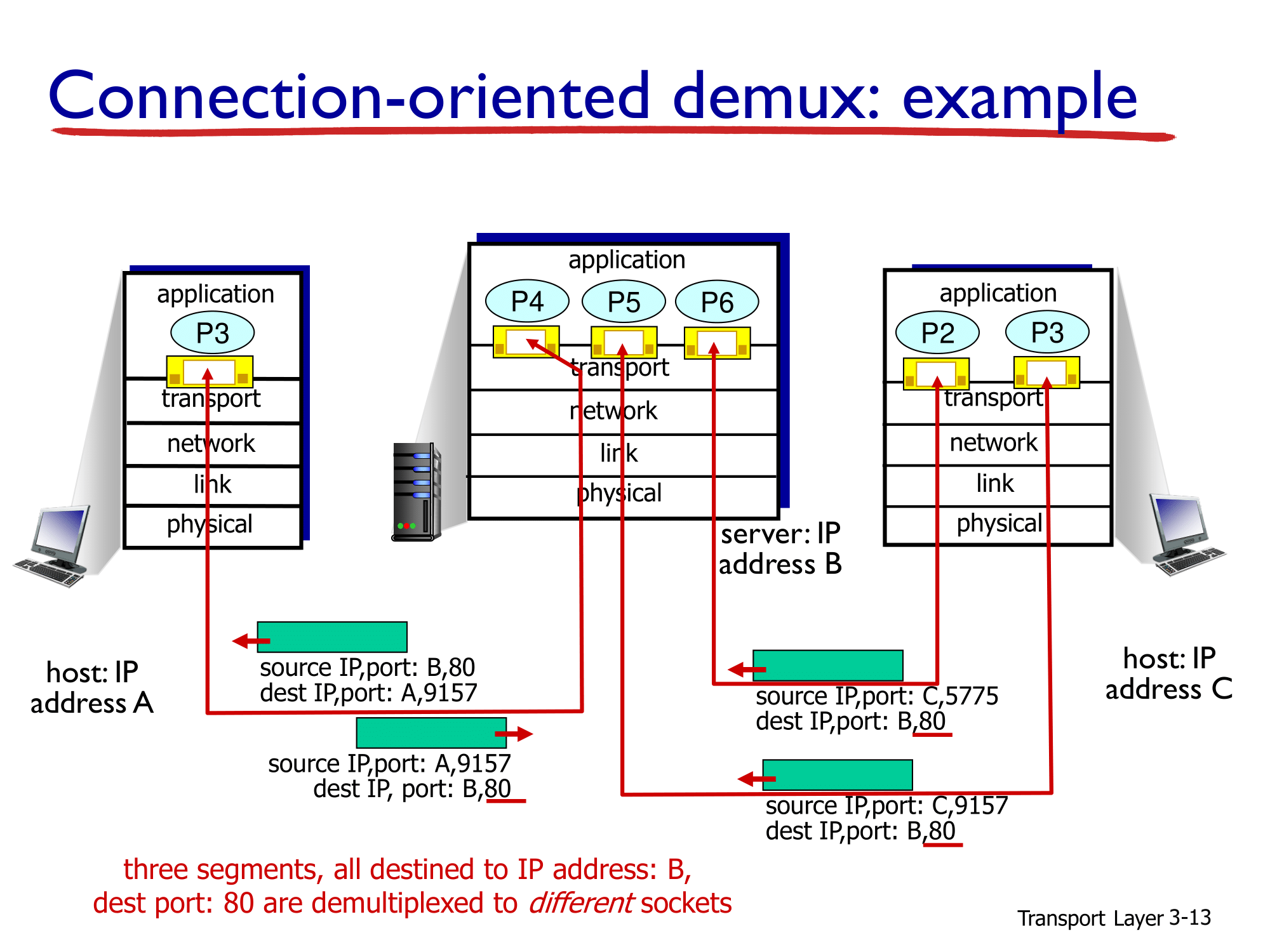
connectionless transport : UDP
principles of reliable data transfer

- stop-and-wait 방식의 비효율적인 패킷 전송 방식을 개선하기 위하여
pipelining방식을 도입한다. - 이 방식은 stop-and-wait 프로토콜에서 단순히 하나의 데이터 패킷을 전송하는 것과는 달리 여러개의 데이터 패킷을 보내는 것을 허용 하는 방식입니다.
- 따라서 기존의 stop-and-wait 방식에서는 데이터 패킷을 하나 보내고 그 보낸 것에 대한 ACK를 기다리는데 pipelining 방식에서는 여러개의 데이터 패킷을 pipeline에 채워서 보냅니다. 이 방법은 ACK를 받지 않은 상태에서도 데이터 패킷을 보내는 것을 허용합니다.
- 이 방법을 구현하기 위해서는 sender 쪽에 buffer가 있어야 합니다. 왜냐하면 retransmission 때문입니다. stop-and-wait 프로토콜에서는 데이터 패킷이 1개이기 때문에 buffer를 1개만 가지고 있으면 되지만 pipelining 프로토콜에서는 ACK를 받지 못한 데이터들을 retransmission 해야 하므로 buffering을 해야합니다. 따라서 pipeling에서는 메모리가 좀 더 필요해집니다.
- pipelining 프로토콜의 대표적인 방식이
GBN(go-Back-N)과SR(selective repeat)방식 입니다.
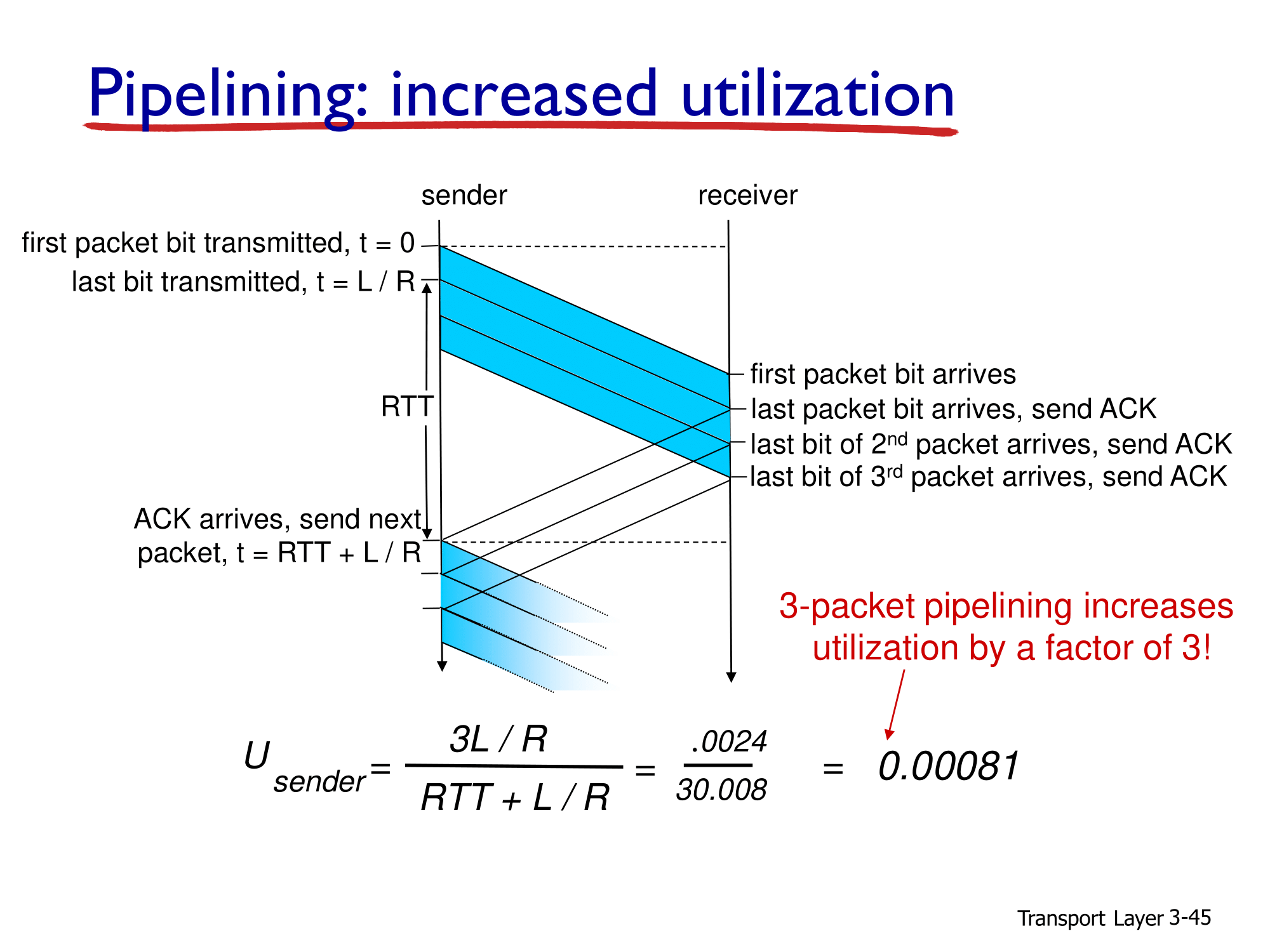
- 먼저 pipelining 프로로토콜을 사용함으로써 stop-and-wait 방식에 비해 utilization을 상승하는 것을 확인할 수 있습니다.
- 기존의 stop-and-wait 프로토콜에서는 1개의 데이터 패킷을 보내고 ACK를 받았지만 pipelining 프로토콜에서는 N개의 데이터 패킷을 보내기 때문에 utilization이 기존 stop-and-wait에 비하여 N배가 됩니다.
connection-oriented transport : TCP
- TCP에서는 round trip time을 어떻게 설정해야 하는 지 고려해야 합니다. 데이터 패킷 loss가 발생하였는 지 알 수 있는 방법이 timeout을 설정하는 방법이기 때문입니다.
- timeout 시간을 설정하고 round trip 하는 데 드는 시간이 timeout 시간보다 길어지면 데이터가 없어졌다고 간주합니다.
- 이 때, timeout 시간을 어떻게 설정하느냐에 따라서 데이터 loss를 잘 확인할 수 있는 반면 문제가 발생할 수도 있습니다. 예를 들어 timtout value를 너무 작은 값을 설정하거나 너무 큰 값을 설정한 경우입니다.
- 일반적으로 Round Trip Time 보다는 Timeout value를 더 크게 만들어야 합니다. 따라서 Round Trip Time을 여러번 측정하고 그 측정값 보다는 크게 Timeout value를 설정합니다.
- 만약 Round Trip Time보다 더 짧은 시간의 값을 Timeout Value로 설정하면 영구적인 timeout이 발생합니다. receiver 쪽으로 패킷이 전달 되었다가 ACK가 다시 sender 쪽으로 전달되는 시간이 필요한데 이 시간 보다 작게 설정하면 영구적인 timeout이 발생하고 불필요한 retransmission을 계속 하게 됩니다.
- 반면 Timeout Value를 너무 크게 설정하면 실제로 데이터 패킷 loss가 발생하여 retransmission을 해주어야 하는데 retransmission을 하기 까지 너무 오래 걸리는 문제가 발생합니다.
- 따라서 적당한 Timeout value 값을 설정하기 위해 Round Trip Time의 평균값을 잘 구해야 합니다.
principles of congestion control
TCP congestion control
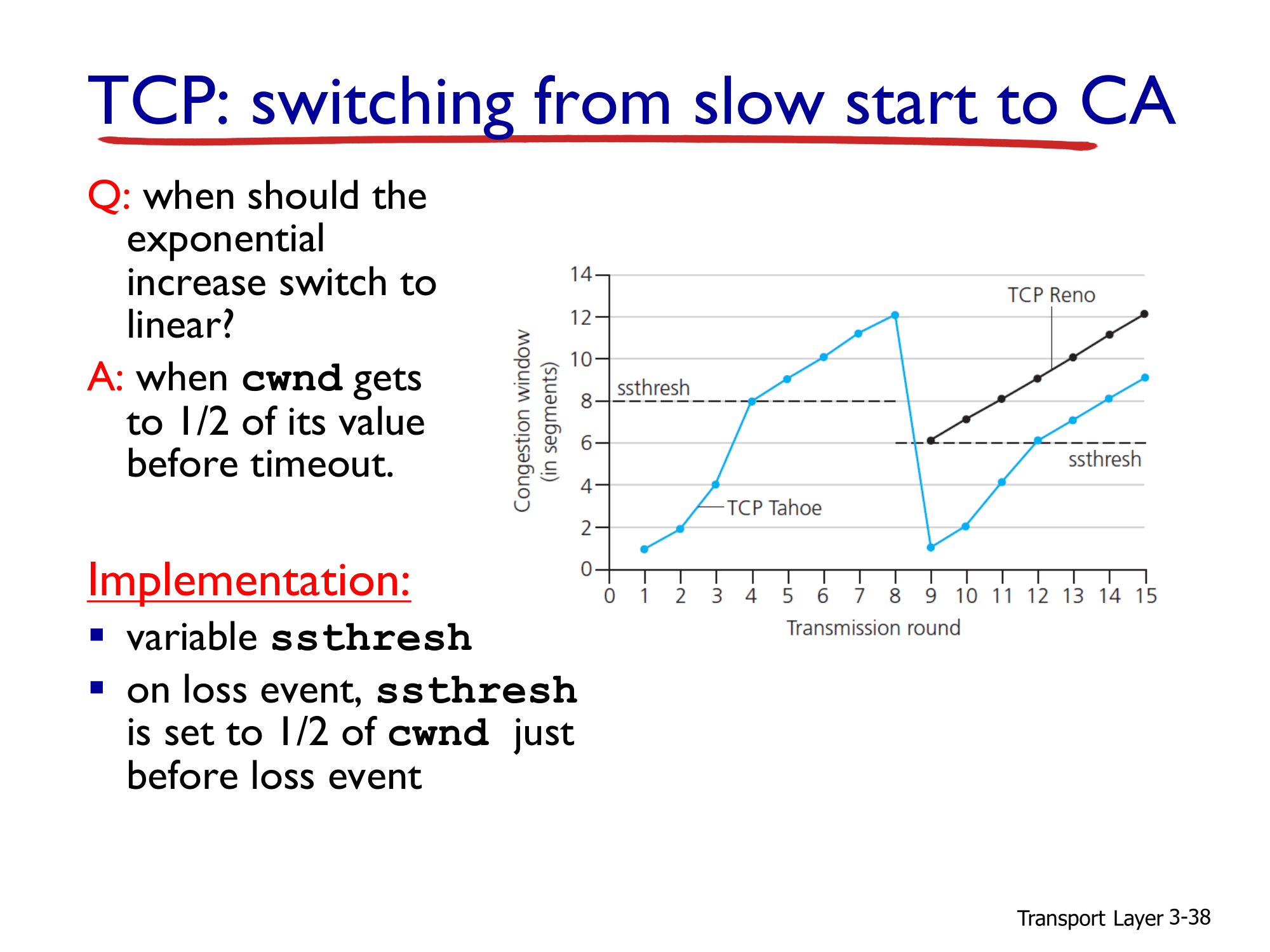
- 위 슬라이드의 예시에 대하여 한번 살펴보도록 하겠습니다.
- 그래프의 X축은 시간값인 Transmission round 이고 Y축은 세그먼트 단위의 Congestion window 입니다.
- 처음 시작할 때에는 Congestion window가 1에서 시작하여 지수적으로 증가하다가 ssthresh가 8로 설정되어 있기 때문에 Congestion window가 8로 설정되어 있는 Transmission round = 4인 지점에서 부터 선형적으로 Congestion window가 증가하게 됩니다.
- 이후 Transmission round = 8인 지점에서 loss가 발생하게 됩니다.
- 일단 loss가 발생하면 TCP Tahoe는 Congestion Window를 1로 줄이게 되어 있으므로 Transmission round = 9인 지점에서 Congestion Window가 1이 됩니다.
- 반면 TCP Reno는 Transmission round = 9인 지점에서 Congestion window의 반으로 줄어들었습니다. (12 → 6) 이를 통하여 Transmission round = 8에서 3 duplicate ACK가 발생한 것을 확인할 수 있습니다.
- ssthresh 또한 Transmission round = 9인 지점에서 Congestion window의 반으로 줄어들어 6이 되었습니다.
- 따라서 TCP Reno는 Transmission round = 9에서 부터 Congestion window가 ssthresh를 넘었기 때문에 선형적으로 Congestion window가 증가하게 되는 것을 확인할 수 있고 TCP Tahoe는 ssthresh = 6인 지점까지 Congestion window가 지수적으로 증가하다가 Transmission round = 12 지점부터 다시 선형적으로 증가하는 것을 확인할 수 있습니다.