
머신러닝에서의 Bias와 Variance
2019, Apr 13
- 출처 : Machine Learning (Andrew Ng)
- 출처 : https://opentutorials.org/module/3653/22071
Bias와 Variance의 정의
- 이번 글에서는 머신 러닝에서의
bias와variance의 정의와 Bias와 Variance에 따라 나타나는 문제에 대하여 다루어 보도록 하겠습니다. - 먼저
bias와variance의 뜻에 대하여 알아보기 전에 \(f(x), \hat{f}(x), E[ \hat{f}(x) ]\)의 뜻에 대하여 알아보도록 하곘습니다.
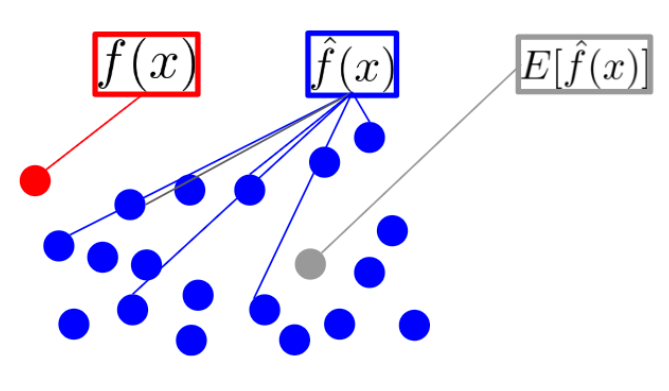
- 먼저 \(f(x)\)는 입력 데이터 \(x\)에 대하여 실제 정답에 해당하는 값입니다. 정답은 하나이기 때문에 빨간색 점에 해당하는 정담 \(f(x)\)는 하나 존재합니다.
- 반면 \(\hat{f}(x)\)는 머신 러닝 모델에 입력 데이터 \(x\)가 입력되었을 때, 모델이 출력하는 예측값입니다. 이 값은 모델의 상태(ex. 파라미터 값)에 따라 다양한 값들을 출력할 수 있습니다. 따라서 여러가지의 파란색 예측값들을 만들어 낼 수 있습니다.
- 이 때, \(E[ \hat{f}(x) ]\)는 \(\hat{f}(x)\)들의 평균(기댓값)에 해당합니다. 즉, 대표 예측값이라고 생각할 수 있습니다.

- 먼저
bias는 모델을 통해 얻은 예측값과 실제 정답과의 차이의 평균을 나타냅니다. 즉, 예측값이 실제 정답값과 얼만큼 떨어져 있는 지 나타냅니다. 만약bias가 높다고 하면 그만큼 예측값과 정답값 간의 차이가 크다고 말할 수 있습니다.
- \[\text{Bias}[ \hat{f}(x) ] = E[ \hat{f}(x) - f(x) ]\]
- 예측값과 실제 정답값과의 차이의 평균을 수식으로 나타내면 위와 같습니다.

- 반면
variance는 다양한 데이터 셋에 대하여 예측값이 얼만큼 변화할 수 있는 지에 대한 양(Quantity)의 개념입니다. 이는 모델이 얼만큼flexibilty를 가지는 지에 대한 의미로도 사용되며 분산의 본래 의미와 같이 얼만큼 예측값이 퍼져서 다양하게 출력될 수 있는 정도로 해석할 수 있습니다.
- \[\text{Var}[ \hat{f}(x) ] = E[ (\hat{f}(x) - E[ \hat{f}(x)])^{2} ] = E[ \hat{f}(x)^{2} ] - E[ \hat{f}(x) ]^{2}\]
variance를 수식으로 나타내면 다음과 같습니다. 말 그대로 평균과 변량의 편차를 제곱하여 나타낸 것입니다.
머신 러닝 모델과 Bias 및 Variance의 관계
bias와variance는 머신 러닝의 모델이 학습 상태를 나타낼 수 있는 좋은 척도입니다.
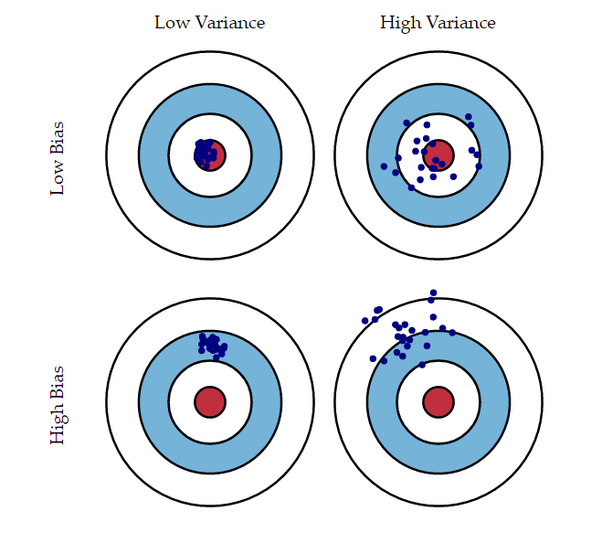
bias와variance의 크고 작음에 따라서 4가지 경우로 분류하고 그 경우에 따라서 머신 러닝 모델이 예측한 값들의 분포와 정답간의 관계를 한번 살펴보도록 하겠습니다. 각 그림의 원의 중심인 빨간색이 정답 데이터의 위치라고 생각하시면 됩니다.- ①
Low Bias & Low Variance: 예측값들이 정답 근방에 분포되어 있고(bias가 낮음) 예측값들이 서로 몰려 있습니다. (variance가 낮음) - ②
Low Bias & High Variance: 예측값들이 정답 근방에 분포되어 있으나 (bias가 낮음) 예측값들이 서로 흩어져 있습니다. (variance가 높음) - ③
High Bias & Low Variance: 예측값들이 정답에서 떨어져 있고 (bias가 높음) 예측값들이 서로 몰려 있습니다. (variance가 낮음) - ④
High Bias & High Variance: 예측값들이 정답에서 떨어져 있고 (bias가 높음) 예측값들이 서로 흩어져 있습니다. (variance가 높음)
- 머신 러닝 모델과
bias,variance의 관계를 4가지 분류로 살펴보았습니다. 위 그림을 통하여 알 수 있듯이, 가장 적합한 구간은 ①에 해당하는Low Bias & Low Variance입니다.

- 이 상태를
Error를 이용한 수식으로 나타내면 위 식과 같습니다. - 첫번째 항은
bias에 해당합니다. 정답과 예측값이 얼만큼 다른지를 에러로 나타내기 위하여 그 차이에 제곱을 하여 양의 값으로 나타내었습니다. - 두전째 항은
variance에 해당합니다. 예측값의 평균과 각 예측값들의 차이가 클 수록 에러가 높도록 설정하였습니다. - 마지막 항은
irreducible error라고 하며 근본적으로 줄일 수 없는 에러를 뜻합니다. 이 에러가 존재하는 이유는bias와variace를 0으로 만들다고 하더라도 그 모델이 항상 완벽할 수는 없기 때문에 추가된 항입니다.
- 지금 까지 확인한 개념을 이용하여
bias와variance가 실제 모델의 예측값과 어떤 관계를 가지는 지 그래프를 통하여 확인해 보겠습니다. 먼저regression예제입니다.
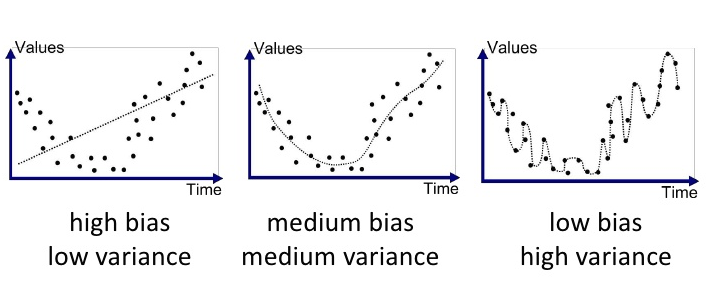
- 위 그래프에서 점선은
예측값의 regression이고 점은 각 Time 값에 해당하는 정답입니다. - 첫번째 그래프는
high bias & low variance하다고 말할 수 있습니다.high bias인 이유는 예측값이 실제 정답값과 많이 다르기 때문이고low variance한 이유는 예측값들의 편차가 작기 때문입니다. - 두번째 그래프는
medium bias & medium variance하다고 말할 수 있습니다. 첫번째 그래프에 비해 예측값과 정답값이 상대적으로 유사하지만 세번째 그래프에 비해 오차가 크기 때문입니다.variance측면에서는 첫번째 그래프에 비해서 예측값들의 편차가 상대적으로 커졌지만 세번째 그래프에 비해서는 편차가 작습니다. 따라서 mideum 하다고 말할 수 있습니다. - 세번재 그래프에서는 예측값과 정답이 굉장히 유사합니다. 따라서
bias는 작다고 말할 수 있습니다. 반면 모델의 예측값이 구불구불해져서 예측값들의 편차가 커졌습니다.
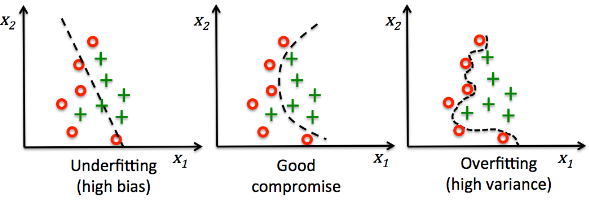
- 이번에는
classification예제를 다루어 보겠습니다. - regression 문제와 동일한 성격의 예제입니다. 첫번째 그래프에서는
high bias & low variance입니다. 지금 까지 패턴으로 보았을 때,high bias인 경우는 모델의 성능이 정답을 잘 예측하지 못하는 경우로underfitting이 발생한 경우라고 볼 수 있습니다. - 반면, 세번재 그래프에서는
high variance가 발생하였는데, 이는 모델이 필요 이상으로 복잡하여 예측값 간의 편차가 크게 발생하는 경우입니다. 이와 같은 경우를overfitting이 발생하였다고 볼 수 있습니다. - 이와 같이
bias와variacne는 모델의 복잡도와 관련이 있습니다. 또한 관계를 잘 살펴보면bias와variance는 서로 영향을 끼치고 있습니다. bias를 낮추기 위해서 (underfitting을 개선하기 위해서) 모델의 복잡도를 높이게 되면variance가 높아지게 되고 (overfitting이 발생) 반대로variance를 낮추기 위해서 (overfitting을 낮추기 위해서) 모델의 복잡도를 낮추게 되면bias가 증가 (underfitting이 발생)하게 됩니다.- 따라서 적당한 수준의 bias와 variance를 만들기 위하여 적정한 수준에서 모델의 학습을 종료 시켜야 합니다.
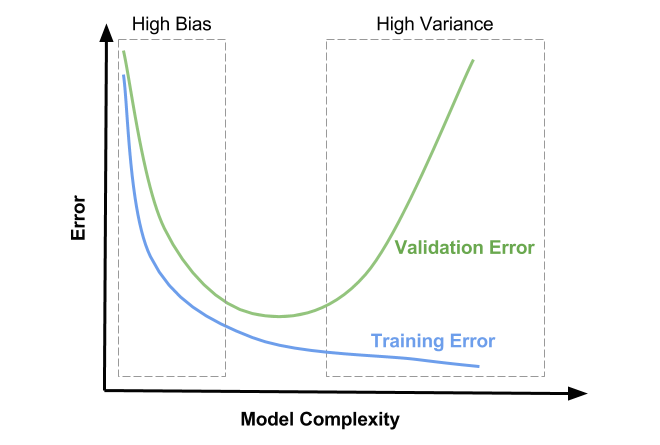
- 대표적인 방법으로 위 그림과 같이
train데이터 셋과validation데이터 셋을 이용하는 방법이 있습니다. - train 데이터를 통해 학습을 하면서 train error를 줄여나가면
bias는 점점 줄어들고variance는 점점 증가하게 됩니다. - 이 때, validation 데이터도 동시에 error를 계산하여 validation error도 감소하는 것을 관측하다가 다시 증가하는 지점을 확인하여
low(medium) bias & low(medium) variance를 찾습니다.
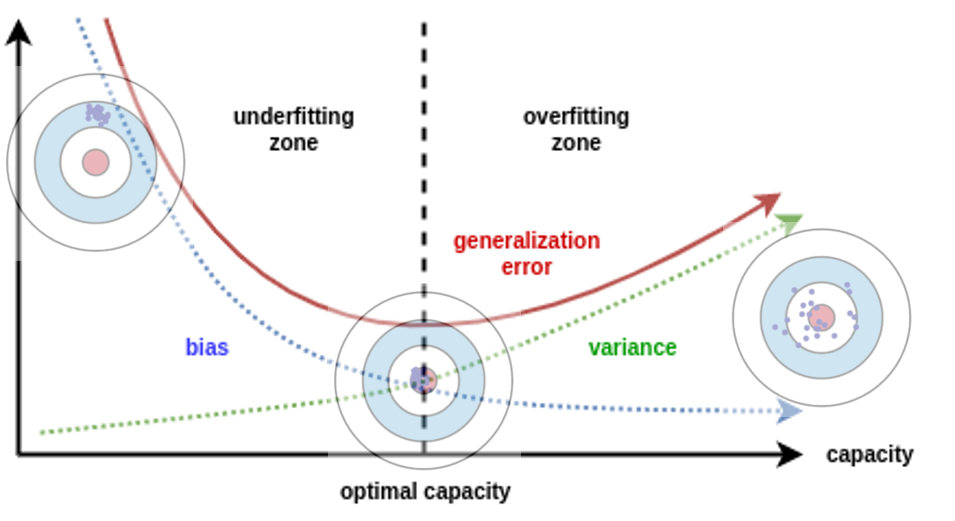
- 앞에서 배운 내용을 모두 종합하여 다시 살펴보겠습니다.
- 그래프를 보면 전형적인 학습 진행 현황을 underfitting, overfitting 구간으로 나누어서 볼 수 있습니다. 학습을 진행할 수록 generalization error에 대한 곡선이 점점 줄어들다가 다시 증가하는 지점이 발생합니다. 이 지점에서 모델은
low(medium) bias & low(medium) variance를 만족하게 됩니다.
- 아래는 Andrew Ng의 Machine Learning 강의에서 발췌한
Bias와Variance에 대한 내용입니다.
Bias Vs. Variance
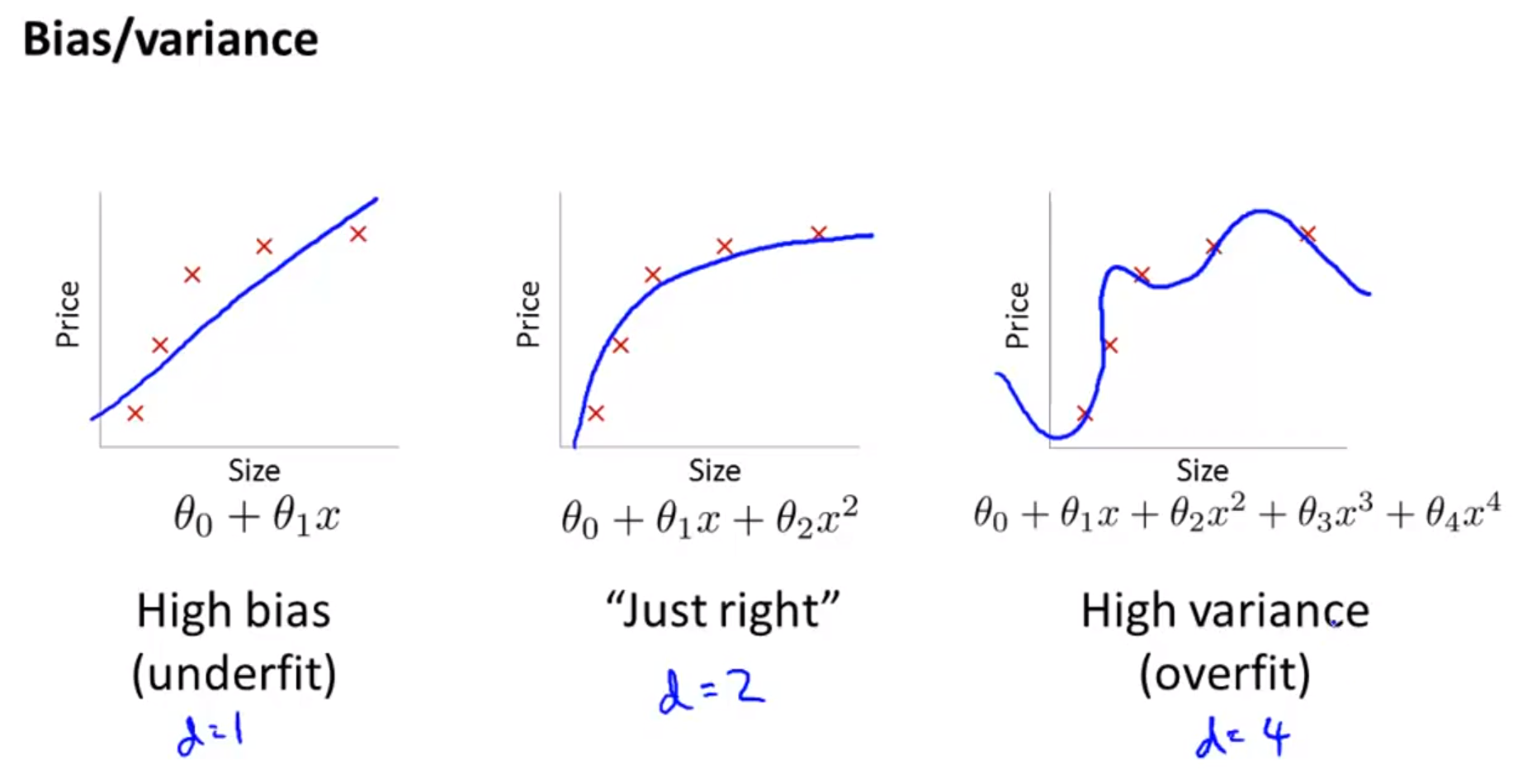
- Bias와 Variance 문제의 정의를 살펴보면 bias 문제는 데이터의 분포에 비하여 모델이 너무 간단한 경우 underfit이 발생한 경우에 발생합니다.
- Variance 문제는 모델의 복잡도가 데이터 분포보다 커서 데이터를 overfitting 시키는 문제를 말합니다.
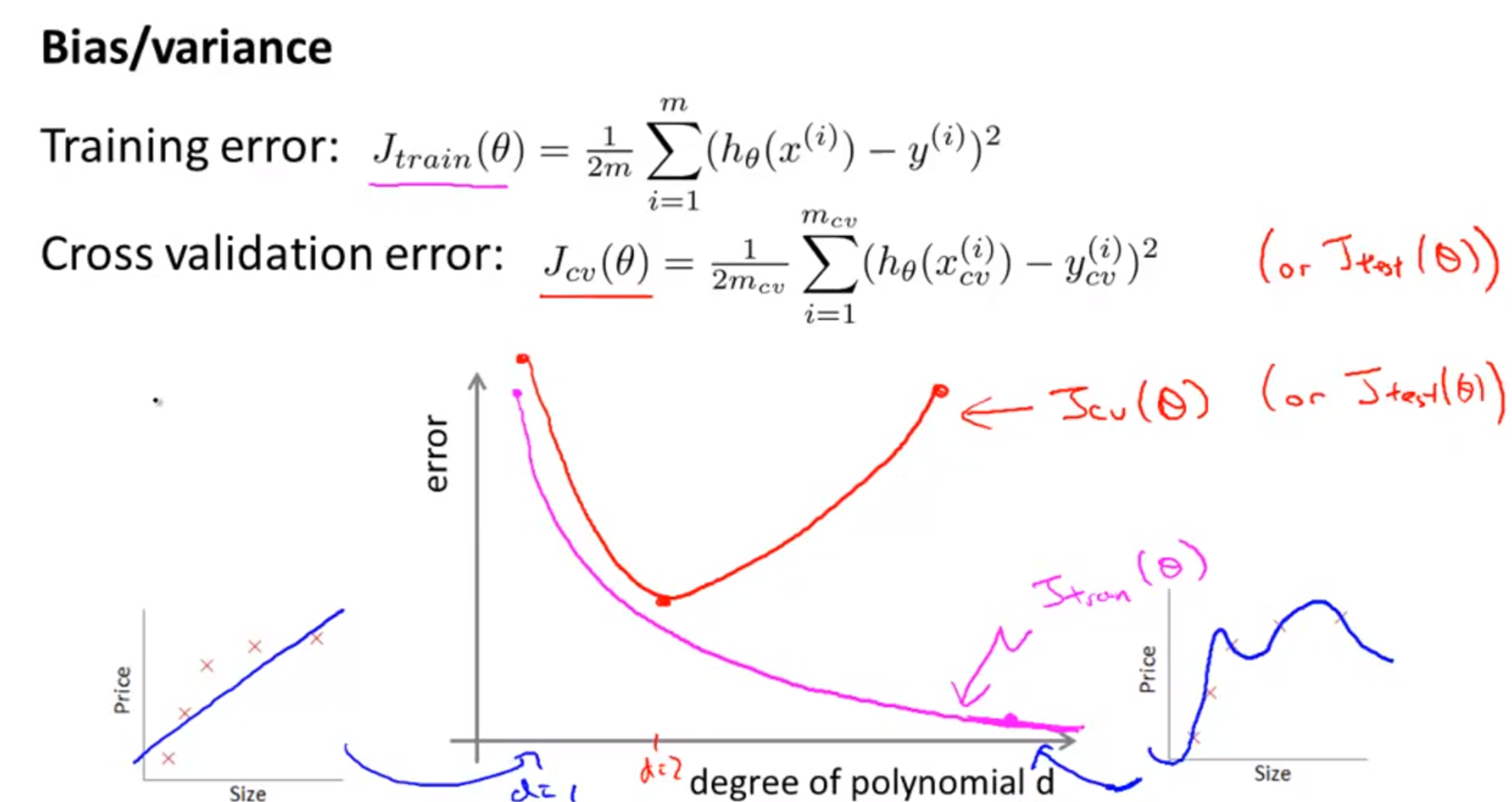
- 모델의 degree를 높이면 식의 표현력이 더 증가해서 성능이 증가하지만 데이터 분포에 비하여 너무 표현력이 증가하면 overfitting이 발생할 수 있음을 확인하였습니다.
- 위 슬라이드의 그래프는 degree의 증가에 따라서 error가 어떻게 바뀌는 지 보여줍니다.
- 예를 들어 \(d = 1\) 일 때, 식이 너무 단순해서 데이터를 잘 표현하지 못하는 underfitting 문제가 발생합니다.
- 이 때에는 training error와 validation error 가 둘 다 높습니다.
- 앞에서 설명한 바와 같이 이 문제가
bias problem입니다.
- degree를 높이다 보면 training error와 validation error가 둘 다 감소하는 구간이 있습니다.
- error가 감소하는 마지막 구간이 가장 적합한 degree 입니다.
- degree를 계속 증가시키다 보면 training error는 감소하지만 validation error는 다시 증가하는 현상이 발생하는데 이 때가 overfitting이 발생한 구간 입니다.
- 이 문제가
variation problem입니다.
- 이 문제가
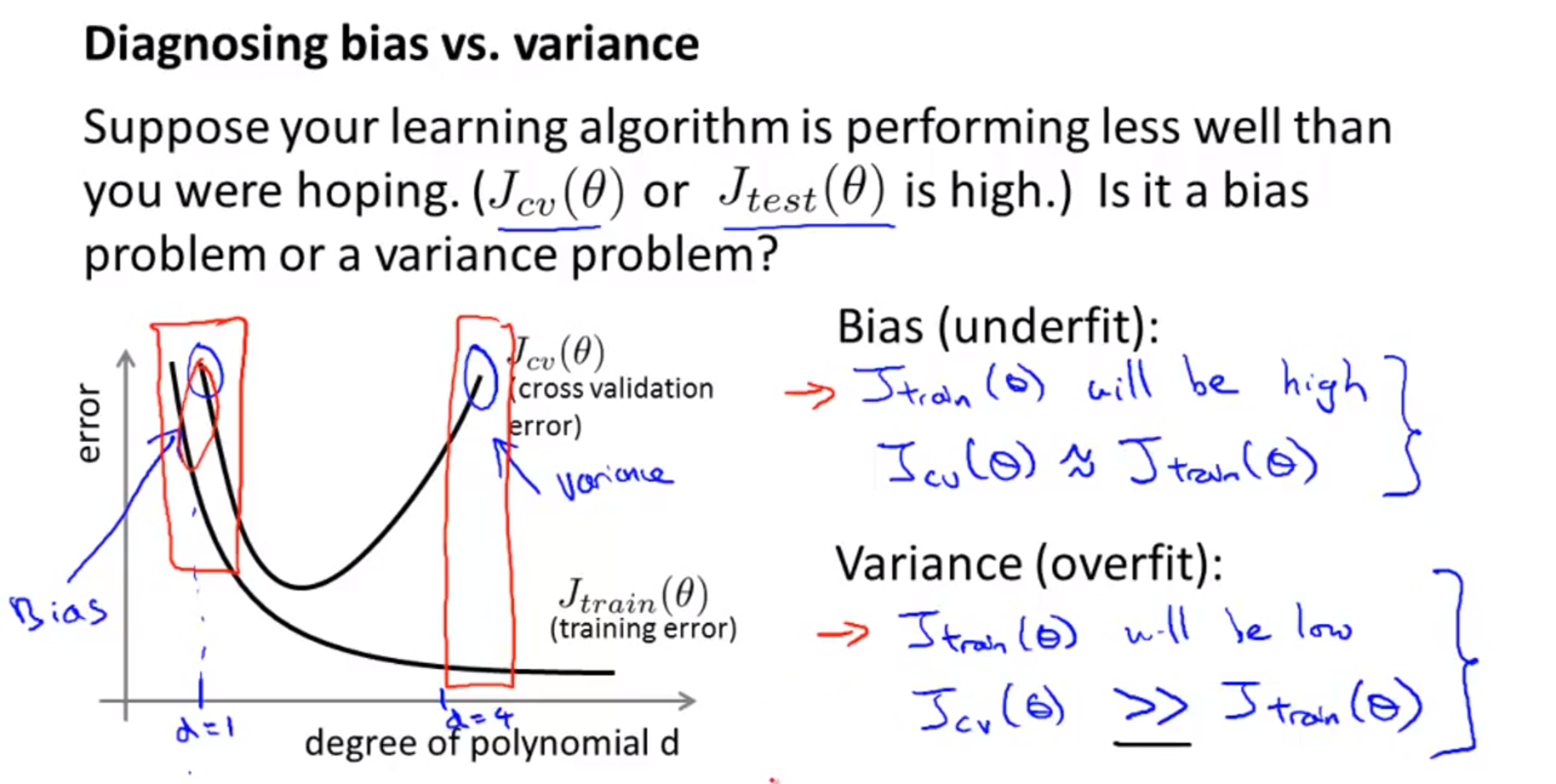
- 앞에서 설명한 내용을 다시 정리하면 위와 같습니다.
- 다시 한번 확인해볼 점은 Bias와 Variance 문제가 언제 발생하고 이 때의 train error와 validation error의 관계를 파악하는 것입니다.
Regularization and Bias/Variance
- 이번에는 앞에서 알아본
bias와variance를regularization과 연관하여 알아보도록 하겠습니다.
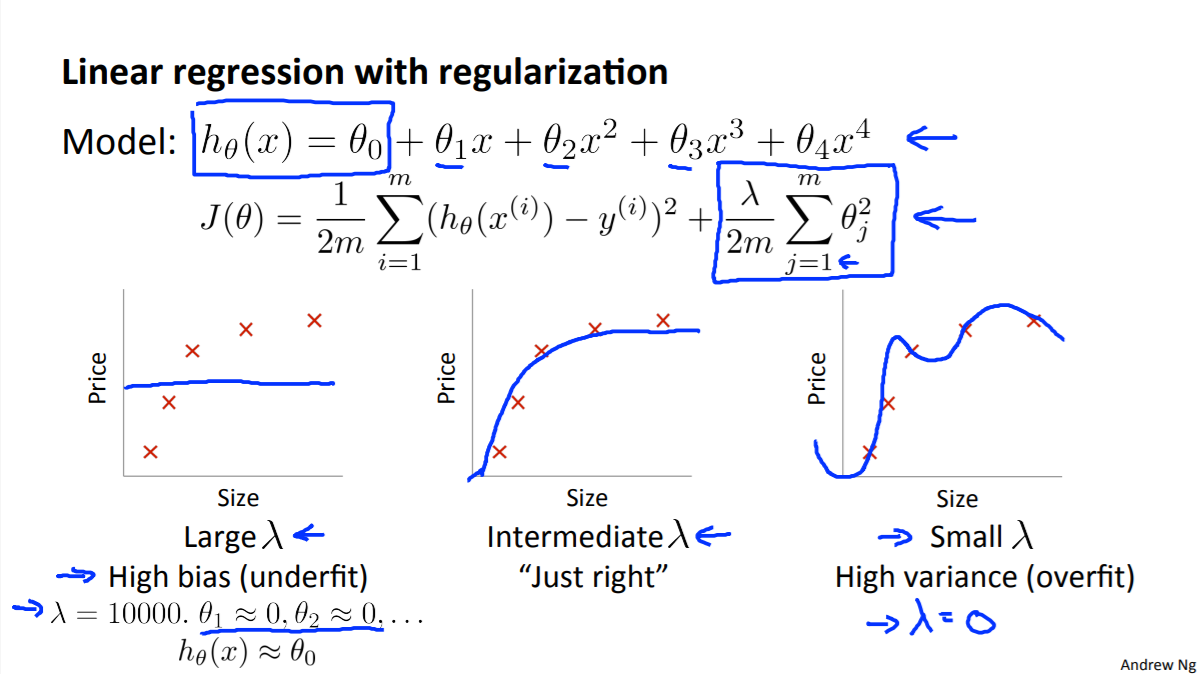
- 만약 위 슬라이드와 같이
polynomial모델이 있고regularization을 적용했다고 가정해 보겠습니다. - 이 때, \(\lambda\) 값에 따라서 bias/variance 문제는 어떻게 되는지 살펴보겠습니다.
- 먼저
regularization텀을 보면 \(j = 1, ..., m\)의 범위를 가집니다. - 즉, \(\lambda\) 가 아주 큰 값을 가지게 되면 \(\theta_{1}, ..., \theta_{m}\)에 대해서는 학습이 안되게 됩니다.
- 반면 \(\theta_{0}\)의 값만 남게 되어
High bias의 그래프 처럼 수평선 그래프가 그려지게 됩니다.
- 반면 \(\theta_{0}\)의 값만 남게 되어
- 반대로 High variance의 상황을 보면 \(\lambda = 0\) 으로 극단적으로 생각할 수 있습니다.
- 이 상황은 regularization을 사용하지 않은 것으로 overfitting의 문제가 나타날 수 있습니다.
- 따라서 우리의 목적은 적당한 bias와 variance를 가지도록 \(\lambda\) 값을 설정할 필요가 있습니다.

- 따라서 위 슬라이드와 같이 \(\lambda\)를 정할 때, 0부터 시작해서 점점 더 크기를 올리면서 적용하는 것이 좋습니다.
- 위 슬라이드에서 보면 각각의 \(\lambda\) 후보값들을 이용하여 validation error를 구하고 그 error가 최소인 것을 선택하는 방법을 사용하였습니다.
- 예를 들면 위 슬라이드에서는 \(\lambda =0.08\)에서 validation error가 최소가 되므로 선택되었습니다.
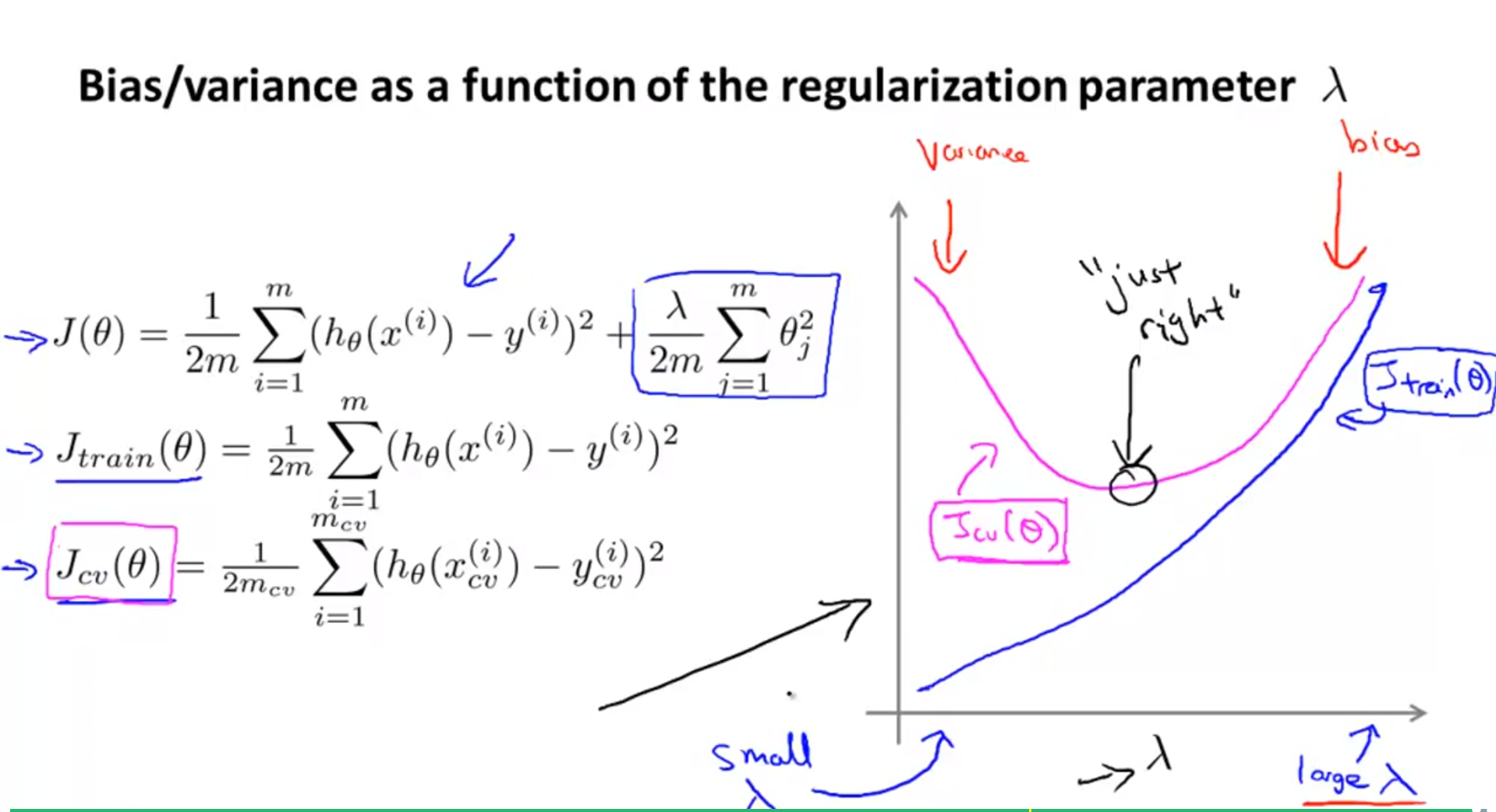
- regularization parameter의 변화에 따라서 train error와 validation error에 대하여 확인해 보면 위 슬라이드의 그래프와 같습니다.
- train error의 경우 regularization의 크기가 커질수록 error의 크기가 더 커지게 됩니다.
- cost function을 보면 알 수 있듯이 regularization term은 항상 양수 값이 더해지기 때문입니다.
- 반면 validation error의 경우 regularization이 점점 커질수록 error가 줄다가 다시 커지게 됨을 알 수 있습니다.
- regularization이 매우 작은 값에서 적당한 값으로 커지게 되면 overfitting 문제가 조금씩 해결되면서 validation error가 줄어들게 됩니다.
- 하지만 적정 크기의 regularization parameter 보다 값이 커지게 되면 cost function 의 형태와 같이 항상 error에 양의 값이 더해지게 되므로 error 값이 증가하게 됩니다.
- 즉, regularization parameter가 적당한 값까지 증가할 때에는 variance 문제가 해결되는 것이 error에 값이 더해지는 것 보다 효과가 있어서 error가 줄어듭니다.
- 반면 최적점을 지날 만큼 parameter 값이 커지게 되면 bias 문제에 빠지게 되고 error값에 더해지는 regularization값도 커지게 되어 error가 증가하게 됩니다.
Learning Curves
- 이번에는
training set의 크기에 따른 bias와 variance의 변화를 살펴보도록 하겠습니다.

- 먼저 위 슬라이드를 보면
training set의 크기에 따라서 모델의generalization성능이 상승되는 것을 알 수 있습니다. - 슬라이드의 오른쪽을 보면 데이터가 1개 있을 때부터 점점 증가하여 데이터가 6개 있을 때 까지 그래프의 모양이 변형되는 것을 볼 수 있습니다.
- 즉, 데이터가 많아질수록 파라미터가 데이터에 맞춰 학습이 되기 때문에 점점 더 데이터의 데이터 모집단의 분포에 가까워 지게 됩니다.
- 슬라이드 왼쪽 하단의 training set과 error의 그래프를 보면 학습 데이터 셋의 크기가 매우 작은 경우는 error가 상당히 작은 것을 알 수 있습니다.
- 왜냐하면 데이터가 너무 작기 때문에 error가 발생할 데이터의 수가 작기 때문입니다.
- 데이터가 점점 증가할수록 training error는 점점 증가하다가 정체됩니다. 이 경향이 일반적인 training error의 변화 과정입니다.
- 반면 validation error는 학습 데이터가 매우 작을 때에는 상당히 큽니다. 왜냐하면 아주 조금의 데이터로 모델을 학습하였기 때문에
generalization성능이 매우 떨어지기 때문입니다. - 그러다가 학습 데이터의 갯수가 늘어날수록
generalization성능이 커지게 되어 training error보단 크지만 유사한 수준으로 validation error가 감소하는 것을 볼 수 있습니다.
- 그러면 이러한 training set의 크기와 bias/variance 의 관계에 대해서 알아보도록 하겠습니다.
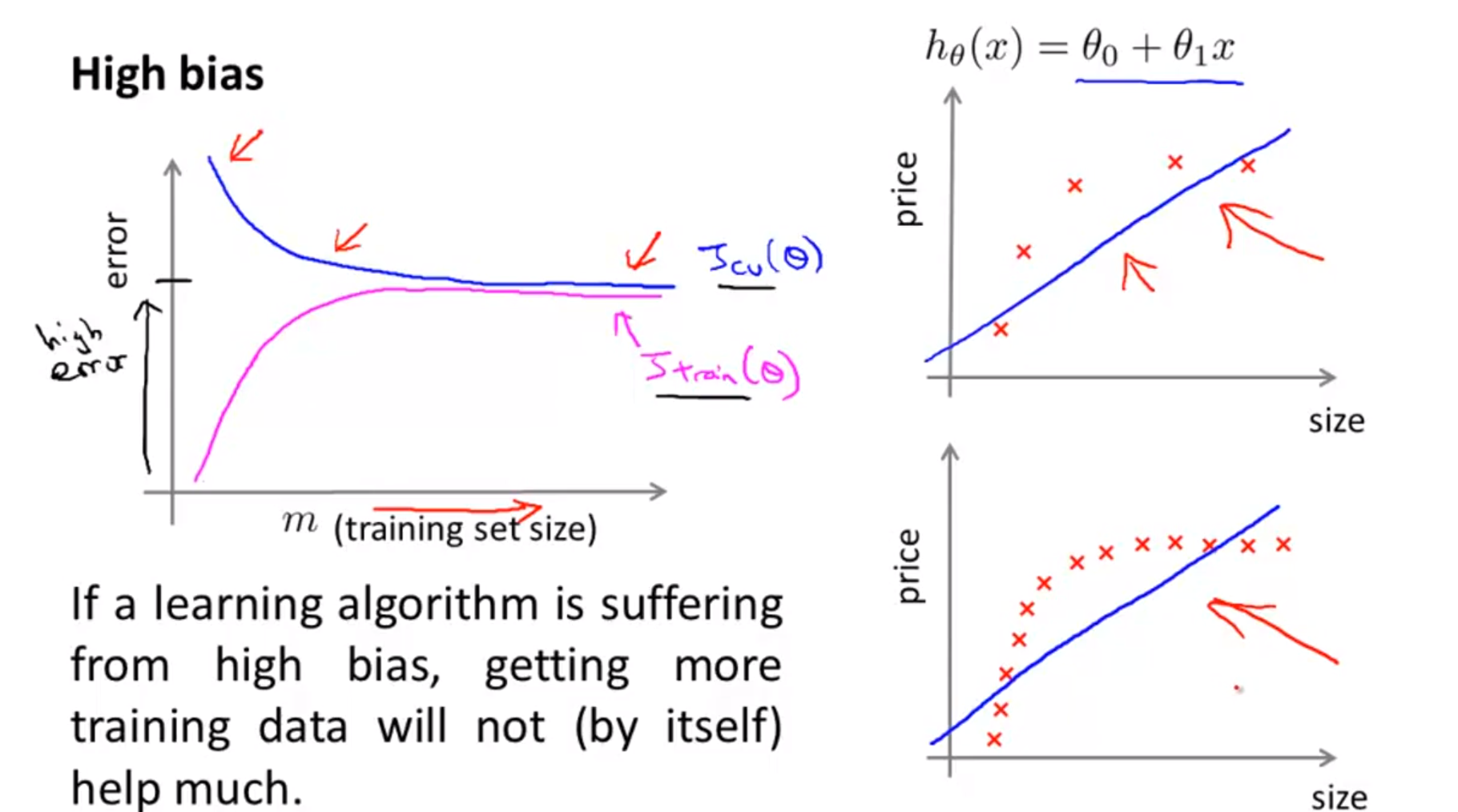
- 먼저
bias문제에 대하여 살펴보겠습니다.bias문제는 기본적으로 모델의 복잡도가 낮아서 표현력이 안좋기 때문에 발생합니다. - 위 슬라이드처럼 모델이 단순 선형이라고 가정하면 데이터 분포를 적합하게 표현할 수가 없습니다.
- 이런 경우에 training data 크기를 늘리더라도 bias 문제를 해결하기는 어렵습니다.
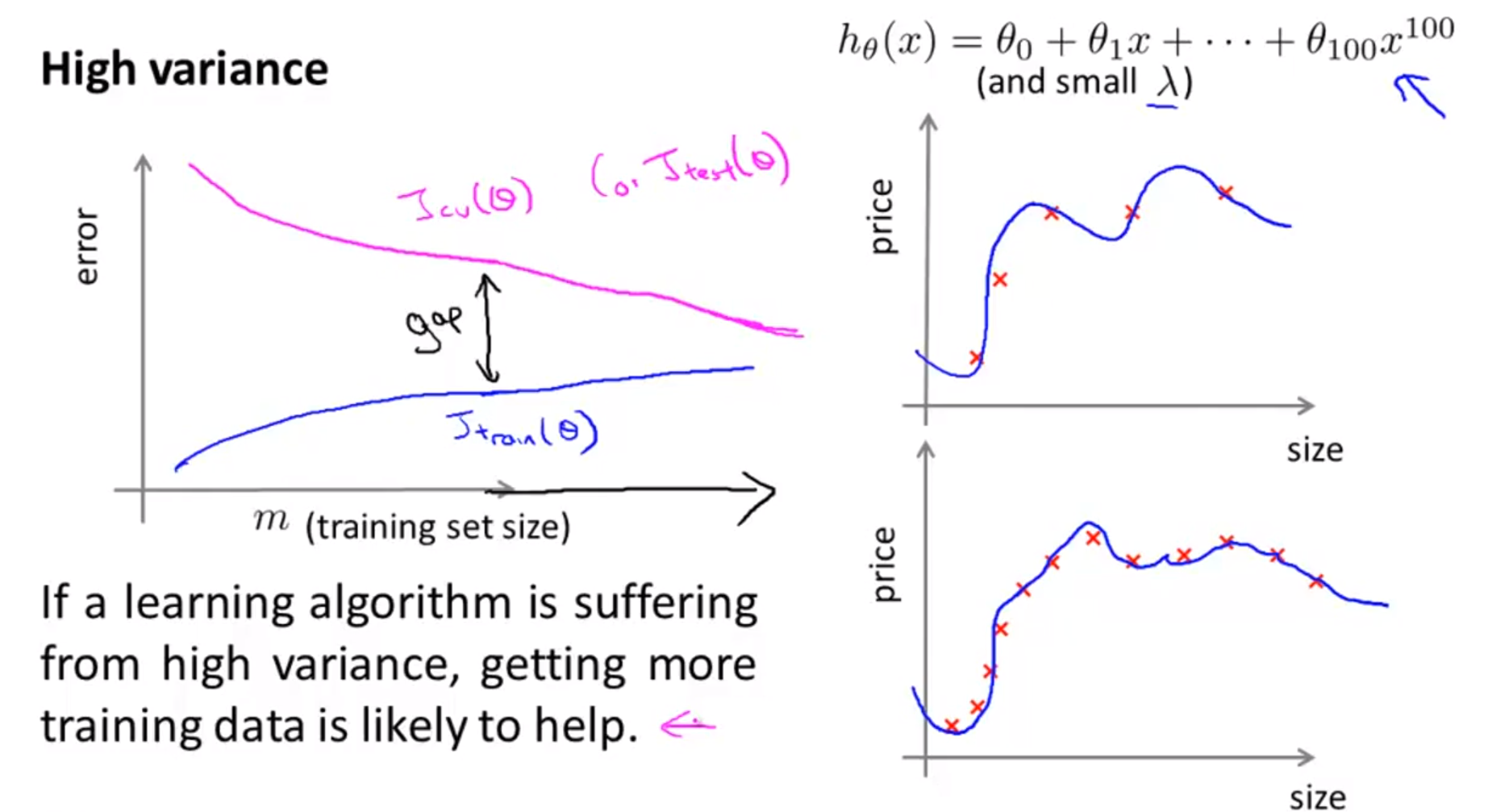
- 반면,
variance문제는 기본적으로 학습 데이터에 비하여 너무 모델의 복잡도가 높아서 모델이 너무 과하게 학습한 문제로 인해 발생합니다. - 즉, 학습 데이터의 크기를 늘려서 validation/test error를 줄인다는 것은
variance문제에 상당히 적합합니다. - 표현력이 너무 좋아서 문제가 된 모델이 더 많은 학습데이터를 통하여 데이터 분포를 정확하게 표현하게 되므로
generalization성능도 올라가게 됩니다.- 즉 validation/test error가 줄어들게 됩니다.
bias/variance 문제 정리
- 앞에서 배운
bias와variance관련 내용을 정리해 보겠습니다.

- 위 슬라이드 내용을 정리하면
high variance문제를 해결하기 위해서- training data의 갯수를 늘린다.
- feature의 갯수를 줄인다.
- regularization parameter \(\lambda\)의 크기를 증가시킨다.
high bias문제를 해결하기 위해서- feature의 갯수를 늘인다.
- polynomial feature를 추가해 본다. 좀 더 복잡한 모델을 사용해 본다.
- regularization parameter \(\lambda\)의 크기를 줄여본다.
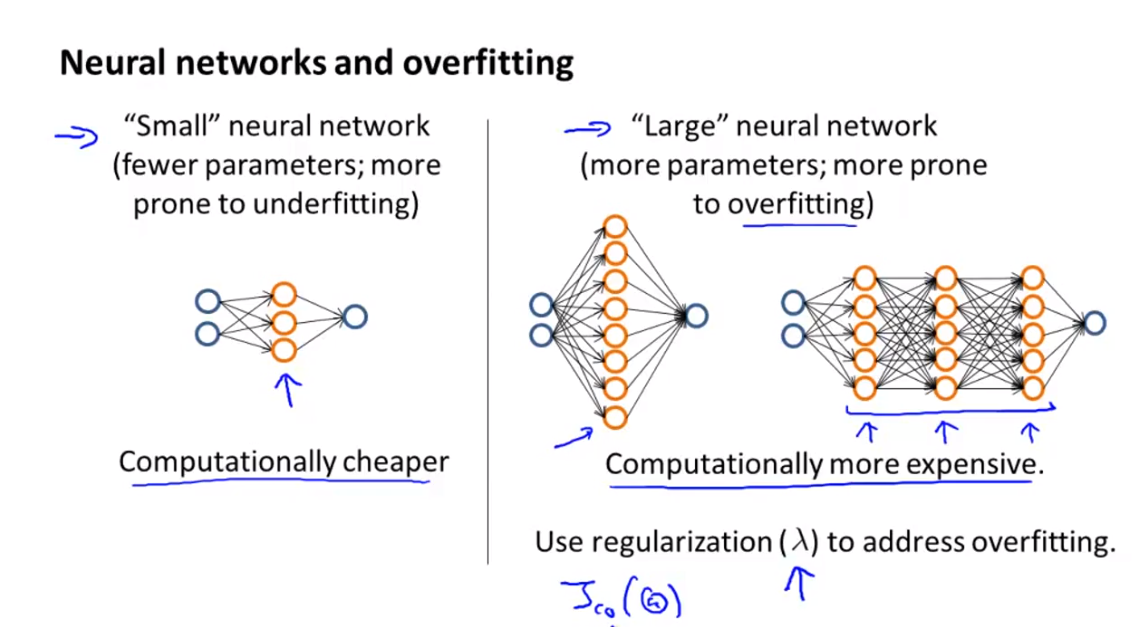
- Neural Network에서 layer의 갯수와 parameter의 갯수는 비례합니다.
- layer의 갯수가 작으면 계산 비용은 작지만
high bias 문제에 빠질 가능성이 있습니다.- 이 떄에는 layer를 추가하는 것이 좋습니다.
- 반면 layer의 갯수가 너무 많으면 계산 비용도 많이 들고
high variance 문제에 빠질 가능성이 있습니다.- 이 때에는 데이터의 갯수를 늘리거나 regularization을 추가하거나 layer의 갯수를 줄여보면 좋습니다.