
(베이즈 통계학 기초) 베이즈 추정에서는 정보를 순차적으로 사용할 수 있다.
2019, Mar 03
베이즈 추정에서는 이전 정보를 잊어도 앞뒤가 맞습니다.
- 이전 글에서 스팸메일 필터의 예를 들어 두 가지 정보를 바탕으로 사후 확률을 계산하는 방법을 배웠습니다.
- 그 구조는 다음과 같습니다.

- 위와 같이 연속해서 들어오는 정보에 대한 연속적인 추정에는 다음과 같은 성질이 적용 됩니다.
- 이전 정보에서 타입에 대한 확률을 개정하면 이후 정보를 사용할 때, 앞의 정보는 잊어도 됩니다.
- 예를 들어 정보1 에서 타입에 대한 확률을 개정하면 정보 2를 사용할 때, 앞의 정보 1은 잊어도 됩니다.
- 이를
축차합리성이라고 합니다. - 이 내용을 이전 글의 스팸메일 내용을 통해서 설명드리겠습니다.
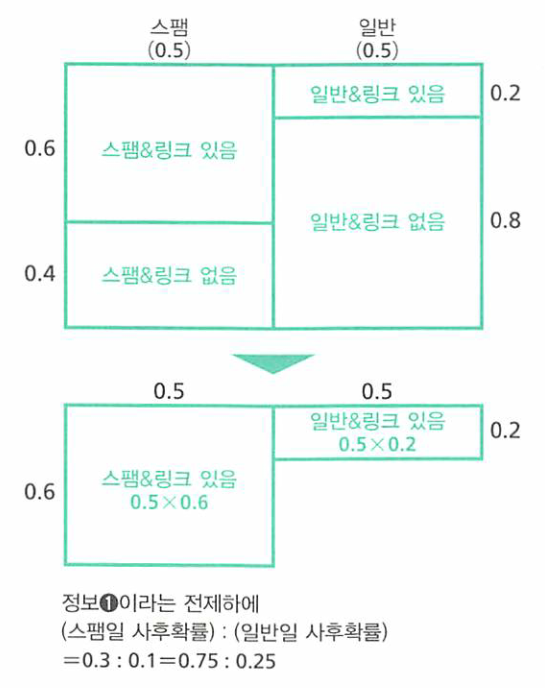
- 위 표는 정보1 단계의 정보에 따른 베이즈 추정입니다.
정보1로부터 얻은 사후확률은 사전확률로 설정합니다.
- 먼저 이전글에서 처음에 한 추정인 URL 포함에 관한 내용부터 다시 확인해 보겠습니다.
- 먼저 처음에 시작할 때, 이유 불충분의 원리를 이용하여 스팸메일과 일반메일의 사전확률으르 0.5 씩 배정하였습니다.
- 그리고 URL 포함유무를 이용하여 사후확률을 추정하였을 때, URL 포함인 경우에 스팸메일은 0.75의 확률이었고 일반메일은 0.25의 확률이었습니다.
- 여기서 중요한 발상은 지금 구한 사후확률을 다음 정보에 적용할 때 사전확률로 삼는 것입니다.
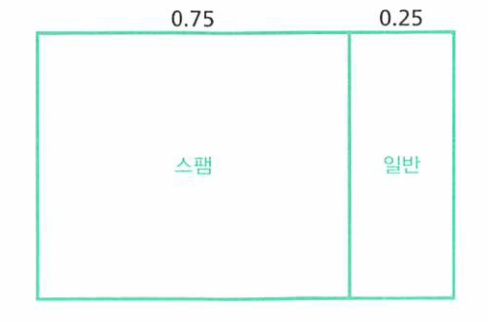
- 위와 같이 사전확률을 0.5 : 0.5 → 0.75 : 0.25 로 업데이트 하였습니다.
- 이유야 어찌되었든간에, 지금 조사하고 있는 메일의 스팸메일이 애초에 사전확률이 0.75 : 0.25 라고 생각하는 것과 같습니다.
- 즉, 이유 불충분의 원리로 0.5 : 0.5 이었던 것을 정확한 사유는 모르지만 누군가가 작성해 놓은 데이터를 기반으로 0.75 : 0.25로 변경한것과 동일합니다.
정보2를 사용하여 베이즈 갱신을 합니다.
- URL 링크 있음, 없음에 대한 사후확률을 다시 사전확률로 잡으면
만남이라는 단어에 의한 스팸메일 검출은 단순히 하나의 정보를 이용한 베이즈 추정이 됩니다.
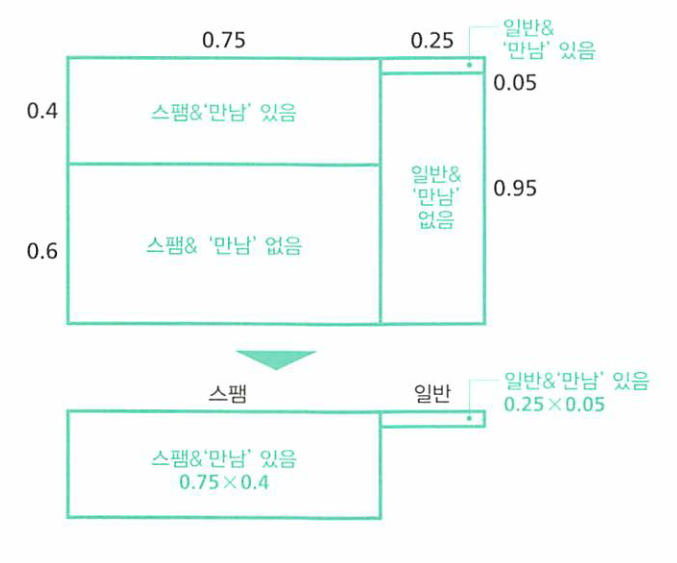
- 그러면 위와 같이 만남이라는 단어가 있는 영역만 남기고 정규화를 시키면 (스펨메일일 사후확률) : (일반메일일 사후확률) = 24/25 : 1/25 가 됩니다.
- 이 결과를 보면 한 번에 2가지 정보(A, B)를 모두 이용하여 사후확률을 추정하는 것과 1개의 정보(A)를 이용하여 사후확률을 추정하고 그것을 사전확률로 취한다음 다시 1개의 정보(B)를 더 이용하여 사후확률을 취하는 것은 결과적으로 완전히 일치합니다.
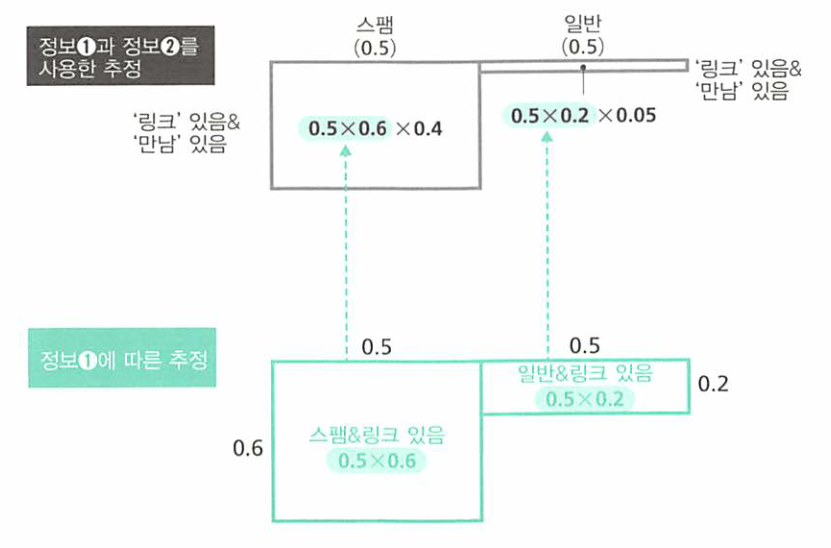
- 위 그림의 상단 그림을 보면 두 개의 정보(정보1, 정보2)를 이용해 사후확률을 한 번에 구할 때의 그림입니다.
- 여기서 직사각형 속 확률의 비를 정규화하면 사후확률을 구할 수 있습니다.
- 아래 그림은 정보1로 부터 각 타입의 확률을 개정하여 얻은 사후확률입니다.
- 아래 그림의 직사각형 속의 곱셈이 위 그림의 직사각형 속 ‘세 수의 곱셈 중’ 앞 두 수의 곱셈과 일치함을 확인하시길 바랍니다.
- 위 그림을 통해 이해하면 정보1로부터 수정한 사후확률을 사전확률로 사용하고 여기에 정보2를 결합하여 구한 사후확률과 정보1, 정보2를 한 번에 사용해서 구한 사후확률이
일치한다는 것을 확인할 수 있습니다.
베이즈 추정은 인간다운 추정입니다.
- 이때까지 설명한 두 가지 정보를 한꺼번에 사용하여 추정한 결과와 첫 번째 정보를 사용하여 추정하고, 그 추정 결과를 사전확률로 두고 두번째 정보를 사용하여 추정한 결과가 완전히 일치하는 것을
축차합리성이라고 합니다.
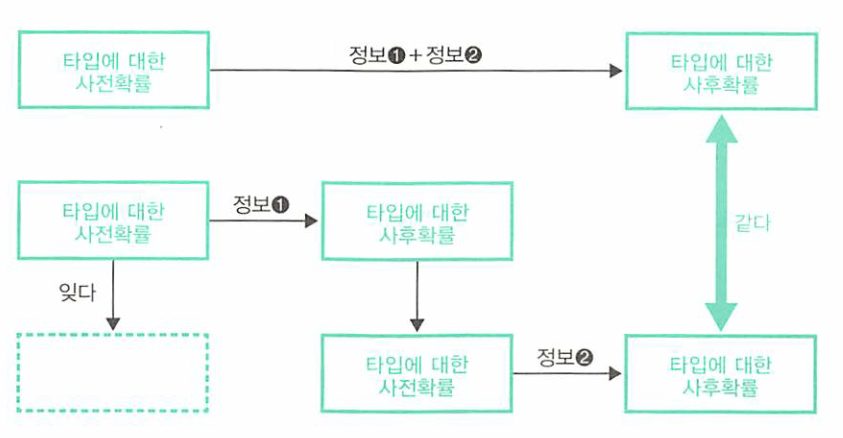
- 축차합리성이 성립한다는 것은 정보를 한 번에 이용하지 않고 축차적으로 이용해 나가도 같은 결과를 얻을 수 있음을 뜻합니다.
- 바꾸어 말하면 이전에 사용한 정보는 잊어도 관계없다라는 뜻입니다. 왜냐하면 앞의 정보는 사후확률에 온전히 반영되어 있기 때문입니다.
- 이는
베이즈 추정의 유용성에 대한 설명이기도 합니다. 요즘 같은 대용량 시대에 확률적 추론을 할 때마다 모든 데이터를 불러와서 추론을 해야 한다면 상당히 큰 계산 비용과 데이터 저장 비용이 발생하기 떄문입니다. - 하지만 이때까지 설명한 축차합리성을 기반으로 생각한다면 한번 사용한 정보는 버려도 현재의 추정에 완전히 반영되어 활용될 수 있다는 뜻을 내포하고 있습니다.
- 이것은 마치
학습기능과 유사합니다. - 즉, 정보로부터 학습이 이루어진 결과라고 볼 수 있으며 베이즈 추정은 정보를 입수하면 자동적으로 똑똑해지는 기능을 가졌다고 볼 수 있습니다.
- 이것은 마치
- 이것은 마치 인간이
정보를 습득 → 생각을 개정 → 정보를 망각하는 것과 유사합니다. 중요한 것은 생각을 개정하는 것은 이후에 발생할 추론의 사전 확률이 바뀐다는 것과 같습니다.