
Machine Learning Yearning (Andrew Ng)과 AI 관련 글
2020, Nov 08
- 원문 링크 : https://gallery.mailchimp.com/dc3a7ef4d750c0abfc19202a3/files/5dd91615-3b3f-4f5d-bbfb-4ebd8608d330/Ng_MLY01_13.pdf
- 참조 : https://github.com/hoya012/Machine-Learning-Yearning-Korean-Translation
- 참조 : AI 프로젝트 실패의 5가지 원인, 송호연
- 이 글은 Andrew Ng의 Machine Learning Yearing을 제가 필요한 내용에 맞게 재해석하여 요약한 글과 AI 사업 관련 좋은 글들을 모아서 작성하였습니다
목차
-
1. 왜 머신러닝에 대한 전략을 알아야 하는가?
-
2. 이 책을 사용 하는 방법 (Skip)
-
3. 이 책을 읽기전 미리 알아야 하는 것과 사용되는 표기법(Skip)
-
4. 규모가 머신러닝의 진보를 이끈다.
개발용 데이터셋과 테스트용 데이터셋을 설정하는 것에 대하여
-
5. 개발 데이터셋과 테스트 데이터셋
-
6. 개발/테스트 데이터셋은 같은 분포의 데이터로 구성되어야 한다
-
7. 개발/테스트 데이터셋이 얼마나 커야 하는가?
-
8. 알고리즘 최적화를 위해서 단일-숫자 평가지표를 설정하는것
-
9. 최적화와 만족화라는 평가 지표에 대해서
-
10. 개발 데이터셋과 평가지표로 개발 사이클 순환 속도를 빠르게
-
11. 개발/테스트 데이터셋과 평가지표를 언제 바꿔야 하는가?
-
12. 요약: 개발 데이터셋과 테스트 데이터셋을 설정하는 것에 관하여
기본적인 에러 분석에 대하여
-
13. 빨리 시스템을 만들어 보고, 개발 사이클의 순환을 빠르게 하자
-
14. 에러 분석: 아이디어에 대한 평가를 위해 개발 데이터셋을 살펴보는 것
-
15. 에러 분석 중간에 여러가지 아이디어를 동시에 판단해 보는 것
-
16. 개발/테스트 데이터셋의 잘못 레이블링된 데이터를 정리하는 것
-
17. 큰 사이즈의 개발 데이터셋이 있는 경우, 두개의 부분집합으로 이를 나누고, 그 중 하나만 관찰하는 것
-
18. “눈알”과 “블랙박스” 개발데이터셋은 얼마나 커야 할까?
-
19. 요약: 기본적인 에러 분석에 관하여
편향과 분산에 대하여
-
20. 편향과 분산: 에러를 일으키는 두 가지 큰 원인
-
21. 편향과 분산의 예
-
22. 최적의 에러율과 비교하는 것
-
23. 편향과 분산 문제 해결방법에 대한 고심
-
24. 편향 vs. 분산의 균형 대립
-
25. 피할 수 있는 편향을 줄이기 위한 기법들
-
26. 학습 데이터셋에 대한 에러 분석
-
27. 분산치를 줄이기 위한 기법들
학습 곡선(Learning Curve)에 대하여
-
28. 편향과 분산을 진단하는 것: 학습 곡선
-
29. 학습 데이터셋에 대한 에러의 곡선을 그리는 것
-
30. 학습 곡선을 해석하는 것: 높은 편향치
-
31. 학습 곡선을 해석하는 것: 그 외의 상황
-
32. 학습 곡선들을 그리는 것
-
인간 수준의 성능과 비교하는 것에 대하여
-
33. 왜 사람-수준의 성능과 비교해야 하는가?
-
34. 어떻게 사람-수준의 성능을 정의할 것인가?
-
35. 사람-수준의 성능을 넘어서는 것
다른 데이터 분포에 대하여 트레이닝과 테스트하는 것에 대하여
-
36. 다른 분포로 부터 구성되는 학습, 테스트 데이터셋을 언제 사용해야 하는가?
-
37. 모든 데이터를 사용해야하는지 어떻게 결정을 내려야 하는가?
-
38. 일관적이지 못한 데이터를 포함시키기 위한 결정을 어떻게 내려야 하는가?
-
39. 데이터에 가중치를 주는 것
-
40. 학습 데이터셋에서 개발 데이터셋으로 일반화 하는 것
-
41. 편향과 분산을 표현/해결하는 것
-
42. 데이터 미스매치를 표현/해결하는 것
-
43. 인공적인 데이터 합성에 대하여
추론 알고리즘을 디버깅 하는 것에 대하여
-
44. 최적화 검증 테스트(The Optimization Verification test)
-
45. 최적화 검증 테스트의 일반적인 형태
-
46. 강화학습의 예
End-to-End 딥러닝에 대하여
-
47. End-to-End 학습의 등장
-
48. End-to-End 학습의 다른 예
-
49. End-to-End 학습의 장단점
-
50. 파이프라인의 컴포넌트를 선택하는 것: 데이터 수집의 가능성
-
51. 파이프라인의 컴포넌트를 선택하는 것: 작업의 간결성
-
52. 직접적으로 부유한(rich) 출력값을 학습하는 것
부분별로 수행하는 에러 분석
-
53. 부분/컴포넌트별로 수행하는 에러 분석
-
54. 에러를 특정 컴포넌트의 잘못으로 분류하는것
-
55. 에러를 특정 컴포넌트의 잘못으로 분류하는 일반적인 방법
-
56. 사람-수준의 성능과 각 컴포넌트를 비교하여 에러분석을 수행하는 것
-
57. ML 파이프라인의 결함을 발견하는 것
-
결말
-
58. super hero 팀을 결성하고 이 문서를 공유할 것
-
AI 프로젝트 실패의 5가지 원인
1. 왜 머신러닝에 대한 전략을 알아야 하는가?
- 머신러닝 알고리즘을 이용하여 컴퓨터 비전 시스템을 구축할 때, 다양한 아이디어를 가질 수 있습니다. 예를 들어 다음과 같습니다.
- ① 더 많은 데이터의 수집. 즉, 더 많은 사진을 확보합니다.
- ② 더 다양한 트레이닝 셋을 수집합니다.
- ③ 더 긴 시간동안 더 많은 횟수의 Grandient Descent를 반복(iteration) 하여 학습시킵니다.
- ④ 더 많은 레이어, 히든 유닛, 또는 파라메터로 구성된 더 큰 뉴럴 네트워크 모델을 사용해 봅니다.
- ⑤ 반대로 작은 뉴럴 네트워크 를 시도해 보는 방법도 있습니다.
- ⑥ L2 regularization와 같은 학습에 도움이 되는 테크닉들을 시도해 볼 수 있습니다.
- ⑦ 활성 함수 또는 히든 유닛의 개수등에 변화 를 주어 뉴럴 네트워크의 설계를 변경하는 방법도 있을 수 있습니다.
- …
- 위와 같은 아이디어가 적중할 때에는 성능 개선될 수 있지만 반대로 잘못 접근하면 시간낭비만 할 수 있습니다.
- 이
글의 목적은 위와 같은 아이디어를 적중하는 데 도움이 되기 위함입니다.
- 아래 두 내용은 Skip하였습니다.
- 2) 이 책을 사용 하는 방법
- 3) 이 책을 읽기전 미리 알아야 하는 것과 사용되는 표기법
4. 규모가 머신러닝의 진보를 이끈다.
- 딥러닝의 발전에는 다음 2가지 요소가 있었습니다.
데이터의 입수 가능성: 사람들이 디지털 장비에 갈수록 더 많은 시간을 소비하고 있습니다. 이러한 디지털 장비 사용은 많은 양의 데이터를 생성하게 되고, 이 데이터는 학습 알고리즘에 인풋 데이터로서 활용될 수 있게 됩니다.계산 규모: 최근에야 비로소 거대한 데이터로 부터 이득을 취할 수 있는 큰 사이즈의 인공신경망을 학습 시킬 수 있게 되었다.- 더 많은 데이터를 축적 하더라도, 예전의 학습 알고리즘 (logistic regression과 같은) 에 대한 성능은 보통 일직선으로 수렴 하게 됩니다. (특정 시점 이후 더 이상 개선이 안되는 현상). 러닝 커브가 평평해 지고 더 많은 데이터를 입력하더라도 성능은 개선되지 못하였습니다.

- 마치 예전의 알고리즘들은 수집된 거대한 데이터를 어떻게 사용해야 하는지 모르는 것 같아 보였습니다. 하지만 만약 작은 인공신경망을 동일한 지도학습 문제에 적용한다면, 약간은 더 나은 결과 를 얻을 수도 있습니다.
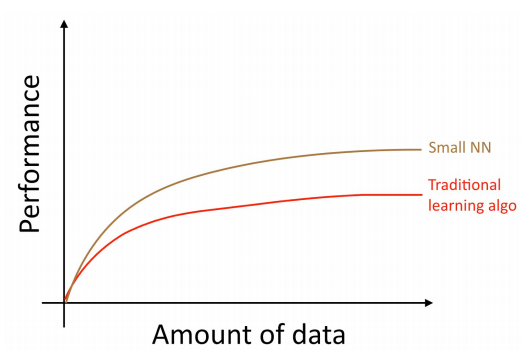
- 여기서
작은 인공신경망은 작은 수의 “히든 유닛”, “레이어”, “파라메터”로 구성된 인공신경망을 의미합니다. 계속해서 더 큰 인공신경망을 이용하여 학습을 시도하는 경우에 더 나은 결과 를 얻을 수 있습니다. - 또한 위 그래프를 통해 작은 양의 데이터에서도 인공신경망이 더 나은 성능을 가진다는 것을 알 수 있습니다.
- 이 현상은 거대한 데이터에 대하여 인공신경망이 꽤 나은 결과를 보여주는 현상과는 약간 다른 양상을 보여줍니다. 작은 양의 데이터 에 대하여, 얼마나 features들이 수작업으로 잘 엔지니어링 되었는지 에 따라서, 전통적인 알고리즘이 더 좋은 결과를 보일 수도 있고 그렇지 않을 수도 있습니다.
- 예를 들어서, 20개의 학습 데이터가 있는 경우, logistic regression을 사용하는 것과 인공 신경망을 사용하는 것 사이에 큰 차이가 없을 수 있습니다. 이 때는 학습 데이터의 feature에 대한 엔지니어링된 정도가 알고리즘을 선택하는것 보다 큰 효과가 있을 수 있습니다.
- 하지만 만약 100만개의 학습 데이터가 있는 경우 거의 항상 인공신경망 을 사용하는게 좋다고 볼 수 있습니다.
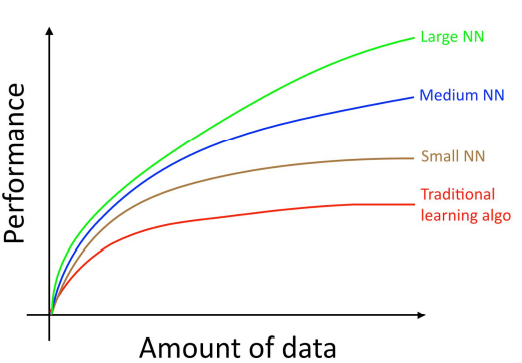
- 위 그래프를 보면 매우 큰 인공신경망에 학습을 시도할 때에 최고의 성능을 얻을 수 있습니다. 위 그림의 녹색 곡선 처럼 큰 인공 신경망에는 거대한 양의 데이터가 필요합니다. 물론 인공 신경망의 구조를 설계하는 다른 많은 부분이 중요하고 이에 대한 많은 발전이 이루어 지고 있습니다.하지만 알고리즘의 성능을 향상 시키기 위한 가장 안정적인 방법 중 하나는 여전히 ① 더 큰 네트워크 의 사용과 ② 더 많은 데이터 를 모으는 것에 있습니다.
- ①, ②를 성취하기 위한 과정은 매우 복잡하다. 앞으로 다룰 글에서는 이 방법에 대해서 자세하게 다룰 예정이다. 우선 전통적인 알고리즘과 인공신경망 모두에게 유용한 일반적인 전략에 대해 설명하고, 그리고 나서 딥러닝 시스템을 구축하기 위한 가장 현대적인 방법에 대하여 다루겠습니다.
개발용 데이터셋과 테스트용 데이터셋을 설정하는 것에 대하여
5. 개발 데이터셋과 테스트 데이터셋
- 사용자들은 모바일 앱을 실행하고 수많은 사진들을 그 앱을 통해 업로드 합니다. 만약 앱의 알고리즘이 그 사진들 중 고양이 사진을 자동으로 찾아내길 원한다고 가정하겠습니다.
- 그러면 고양이 사진(positive)과 고양이가 아닌 사진(negative)을 다운로드 해서 거대한 데이터를 구축해야 합니다. 그 후 총 데이터의 70%를 학습용 으로 30%를 테스트용 데이터셋으로 분리하여, 각각의 데이터셋에서 잘 동작하는 고양이 분류 프로그램을 만들수 있습니다.
- 그런데, 이 분류 프로그램을 실제 배포할때, 성능이 상당히 나쁘다는 것을 알게 될 수도 있습니다.
- 사용자들이 업로드한 사진과 이전에 웹에서 다운로드하여 학습용으로 구축한 데이터의 이미지가 다르다는 것을 뒤늦게 발견할 수 있기 때문입니다.
- 예를 들어서 사용자들은 모바일 기기로 사진을 업로드 하기 때문에 낮은 해상도, 흐린 픽셀 집합, 밝기 문제등을 가지고 있을 수 있습니다.
- 학습용/테스트용 데이터셋은 웹에서 다운로드 되었기 때문에, 배포된 알고리즘은 실제로 신경써야 하는 모바일 기기로 부터의 사진 데이터 분포에 대하여 일반화 되어 있지 못할 수 있습니다.
- 현대 빅 데이터의 시대가 오기 전에, 전체 데이터 중 무작위로 70%를 학습용 데이터로, 30%를 테스트용 데이터 로 분리하여 사용하는 것이 머신러닝에서는 꽤나 일반적인 규칙이었습니다. 이러한 관행은 잘 동작할 수도 있지만, 때로는 좋은 방법이 아닐 수 있다. 학습용 데이터의 분포가 실제로 예측을 하고자 하는 데이터의 분포와 다른 경우가 있기 때문입니다.
- 먼저 다음과 같이 용어를 정의해 보겠습니다.
학습(Training) 데이터셋: 학습 알고리즘을 수행 하기 위해 사용됩니다.개발(Development) 데이터셋: 파라매터의 튜닝, Feature의 선택등 학습 알고리즘에 관련된 어떤 결정을 내리기 위해 사용됩니다. hold-out cross validation set 이라고 불리기도 한다.테스트(Test) 데이터셋: 알고리즘의 성능을 측정 하기 위해 사용됩니다. 하지만 알고리즘의 튜닝과 같은 것에 대하여 어떤 결정을 내리는데 사용되어선 안됩니다.
- 개발 데이터셋과 테스트 데이터셋을 정의하고 나면 이에 대하여 수많은 아이디어를 시도해 볼 수 있습니다. 예를 들어 학습 알고리즘에 들어가는 다른 파라미터값을 대입하여 어떤 것이 최고의 성능을 보여주는가를 관찰해볼 수 있습니다. 개발 데이터셋과 테스트 데이터셋은 알고리즘이 얼마나 잘 동작하는지 빠르게 확인하는데 도움을 줄 수 있습니다.
- 간단히 말하면, 개발/데스트 데이터 셋을 선택할 때, 두 개의 데이터셋은 미래에 기대되는 결과를 도출하는 데이터를 잘 반영하고 있어야 합니다.
-
즉, 테스트 데이터셋은 단순하게 전체 데이터의 30%를 추출한 것이 아니어야 합니다. 특히, 만약 미래에 사용될 데이터(모바일 기기의 이미지)가 학습용 데이터(웹 다운로드 이미지)와는 다른 경우에 조심해야 합니다.
- 어떤식으로든 이러한 데이터의 확보가 어렵다면, 웹에서 다운로드된 이미지를 사용하여 일단 시작할 수도 있습니다. 하지만 해당 이미지로는 일반화된 알고리즘을 만드는데 한계가 있다는 리스크를 항상 인지하고 있어야 한다.
- 훌륭한 개발/테스트 데이터셋을 구축하는데 얼마나 많은 비용을 사용해야 하는지에 대한 결정도 이루어 져야 합니다. 그러나 학습 데이터셋이 테스트 데이터셋과 동일한 분포를 형성할 것이라고 추측하지는 말아야 합니다. 가능한한 최종적으로 사용될 데이터와 근사하도록 테스트 데이터셋을 구성하려고 노력해야합니다.
6. 개발/테스트 데이터셋은 같은 분포의 데이터로 구성되어야 한다
- 앞에서 설명하였듯이, 단순히 개발 데이터와 테스트 데이터는 랜덤으로 나누어서는 안됩니다.
- 일단 개발/테스트 데이터셋의 정의가 되고 나면, 개발 데이터셋에 대하여 알고리즘 성능을 향상 시키는데 집중하게 될 것입니다. 따라서 개발 데이터셋은 가장 성능 향상을 원하는 부분을 반영 해야만 합니다.
- 두 번째 고려 사항은 개발 데이터셋과 테스트 데이터셋이 서로 다른 데이터 분포를 가질 수 있다는 것입니다. 한쪽의 데이터셋에서 잘 작동하는 알고리즘이, 다른 한쪽의 데이터셋에 대하여 만족할 만한 성능 결과를 보여주지 못할 수 있습니다. 이는 노력의 낭비를 가져오기 떄문에 이런 일이 생기는 것을 피해야 합니다.
- 예를 들어 개발한 시스템이 개발 데이터셋에 잘 동작하지만 테스트 데이터셋에는 잘 동작하지 않는다고 가정해 보겠습니다. 개발 데이터셋과 테스트 데이터셋이 동일한 데이터 분포 를 가진다면, 과적합과 같은 문제가 발생 했을 때 뭐가 잘못 됐는지에 대하여 매우 명확한 진단을 내릴 수 있습니다. 이 경우의 과적합 문제가 발생 했을때, 분명한 해결책은 더 많은 개발 데이터셋을 확보하는 것입니다.
- 하지만 개발 / 테스트 데이터셋이 서로 다른 데이터 분포를 가진다면, 문제가 발생 했을때 무엇을 해야 하는지에 대한 해결책을 세우기가 불명확해집니다. 이 때, 다음과 같은 것들을 생각해 볼 수는 있습니다.
- ① 개발 데이터셋에 대하여 과적합이 발생
- ② 테스트 데이터셋이 개발 데이터셋보다 학습되기 어려운 케이스가 있습니다. 이 경우 알고리즘이 기대한 만큼의 성능을 보여주기는 하지만, 그 이상의 성능 향상은 어렵습니다.
- ③ 테스트 데이터셋이 딱히 더 학습되기 어려운 것은 아니지만, 개발 데이터셋과는 다른 경우가 있습니다. 개발 데이터셋에 잘 동작하던 알고리즘이 테스트 데이터셋에서는 잘 동작하지 않는다면 개발 데이터셋에 대한 성능을 향상 시키기 위한 많은 노력이 의미없는 시간이 될 수도 있습니다.
- 동일한 데이터분포를 가지지 않는 개발/테스트 데이터셋을 이용하는 것은 “개발 데이터셋에 대하여 성능을 향상시키는 일이 테스트 데이터셋에 대한 성능을 향상 시킬 수 있는가?”에 대한 문제를 가집니다. 이러한 데이터셋은 뭐가 알고리즘을 잘 동작하게 만드는지, 그렇지 않게 만드는지 알아내기 어렵게 합니다. 그래서 무엇에 우선순위를 두고 일을 해야하는 지 정하기 어려워집니다.
- 만약 제3의 단체(회사)에 대한 벤치마킹을 수행 하는 경우, 그 곳에는 정해진 개발/테스트 데이터셋이 존재할수 있고, 마찬가지로 서로 다른 데이터 분포를 가질 수 있습니다. 이런 경우에는 기술적인 측면 보다는, 운이 성능을 뽑아내는데 더 큰 영향을 끼칠 수 있습니다.
- 한가지 데이터 분포에 대하여 학습된 알고리즘이 다른 데이터 분포에도 잘 동작하도록 일반화 하는 것은 아주 중요한 연구 주제 중 하나입니다. (그 만큼 어렵습니다.) 하지만, 당신의 목표가 연구적인 중요한 발견이 아니라 특정 머신 러닝 어플리케이션에 대해서 잘 동작하는 결과를 얻는 것 이라면, 개발/테스트 데이터셋이 동일한 이미지 분포를 가지도록 구성하는 것을 추천 합니다.
7. 개발/테스트 데이터셋이 얼마나 커야 하는가?
- 개발 데이터셋은 여러개의 알고리즘의 다른점을 구분짓기에 충분할 만큼 커야 합니다. 예를 들어서, A라는 분류 알고리즘이 90.0% 만큼의 정확도를 보이고, B라는 분류 알고리즘이 90.1% 만큼의 정확도를 보여줄 때, 100개의 개발 데이터셋은 이 0.1%라는 차이를 감지하지 못할 수도 있습니다.
- 개발 데이터셋은 일반적으로 적어도 1,000 ~ 10,000 개의 데이터로 구성되어야합니다. 10,000개의 데이터로는 0.1%의 성능 향상을 감지할 수 있을 것입니다.
- 광고, 웹 검색, 제품 추천과 같이 이미 성숙된, 아주 중요한 어플리케이션은 0.01% 만큼의 작은 성능 향상이라도 얻어 내는 것이 중요할 수 있습니다. 이 정도의 성능 향상도 그 회사의 이익 창출에 직접적으로 큰 영향을 미치기 때문이다. 이 경우에, 더욱 더 작은 수준의 향상을 감지하기 위해서 개발 데이터셋의 크기는 10,000개보다 훨씬 커져야 합니다.
- 그렇다면, 테스트 데이터셋의 크기는 얼만큼 구축해야 할까요? 간단히 말하면 구축하는 시스템의 전체적인 성능에 대하여 높은 신뢰를 보여줄 수 있을 정도면 됩니다. 과거에 인기 있는 방법으로는 전체 데이터의 30%를 사용 하는 방법이 있었습니다. 이 30%를 사용하는 방법은 100 ~ 10,000개 수준의 데이터가 있을때는 잘 동작할 수 있습니다.
- 하지만 백만개의 데이터가 넘는 데이터를 다루는 빅 데이터의 시대에서 테스트 데이터셋에 할당된 데이터의 지분(율) 은 점점 작아지고 있습니다. (하지만 절대적인 데이터의 수는 증가하므로 비율은 낮아어도 데이터 수는 증가하게 됩니다.) 그러나 알고리즘의 성능을 평가하는데 개발/테스트 데이터셋을 구성하기 위해서, 터무니 없이 거대한양의 데이터 까지는 필요 없을 것으로 판단됩니다.
8. 알고리즘 최적화를 위해서 단일-숫자 평가지표를 설정하는것
- 분류 알고리즘의
accuracy는 단일숫자(single-number) 평가 지표의 한 예 입니다. - 개발 데이터셋에 대해서 분류 알고리즘을 수행하고, 얼마 만큼의 부분 데이터가 올바르게 분류 되었는지에 대하여 단일 숫자의 지표를 얻게 됩니다. 이 단일 숫자로 표현되는 평가 지표에 따르면, 만약 분류 알고리즘 A가 97%의 정확도를 보이고, B가 90%의 정확도를 보여주는 경우, A가 B보다 더 나은 알고리즘이라고 판단할 수 있습니다.
- 반면
Recall과Precision은 단일 지표라고 할 수 없습니다. 여러개의 평가지표를 가지는 것은 알고리즘의 비교를 더 어렵게 만들 수 있기 때문에 단일 지표를 사용하는 것을 추천드립니다. 아래 표를 보시겠습니다.
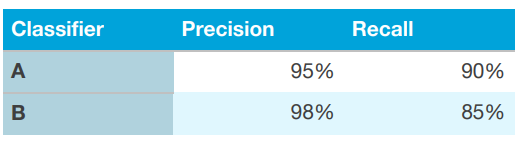
- 위의 경우, 두개의 분류 알고리즘 모두 명확하게 누가 더 좋다라고 말할 수 없습니다. 따라서 어떤 알고리즘을 선택해야 하는 지 즉각적인 판단이 어렵습니다.

- 개발 과정에서 모델 파라미터, feature 선택 방법, 알고리즘의 설계 등에 대하여 수 많은 아이디어를 시도 할 수 있습니다. accuracy와 같은 단일 숫자 평가 지표는 모든 모델을 손쉽게 더 나은 순으로 정렬 할 수 있게 해주고, 가장 좋은 알고리즘을 빠르게 선택하는데 도움을 줍니다.
- 만약 Precision과 Recall을 정말 고려해야 한다면, 이 두개를 단일 숫자로 결합하는 표준적인 방법을 사용하는 것을 추천합니다. 예를 들어서, 이 두가지 지표의 평균으로 단일숫자를 만들어낼 수 있습니다. 또한, 다른 대안으로 평균을 구하는 약간 변형된 방법인
F1 스코어라는 값을 계산할 수도 있습니다.(F1 스코어는 단순 평균보다 더 좋다고 알려져 있습니다. 이유는 아래 링크를 참조하시기 바랍니다.0 - 링크 : https://gaussian37.github.io/math-pb-averages/
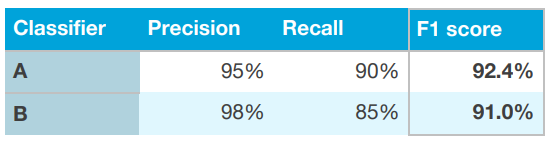
- 단일 숫자 평가지표는 많은 분류 알고리즘 중 하나를 선택해야 하는 경우, 의사결정의 시간을 많이 단축 시켜줍니다. 각 알고리즘의 선호도에 따른 순위를 매기고, 이후 진행되어야 하는 방향에 대하여 깔끔한 가이드를 할 수 있습니다.
- 마지막 예제로, 어떤 그림 분류 알고리즘의 정확도를 4개의 시장(미국, 중국, 인도, 그외)에 대해 별도로 추적한다고 가정해 보겠습니다. 이때, 결과로는 4가지 평가 지표를 얻게 됩니다. 4가지 숫자의 평균값 또는 가중된 평균값을 계산하여, 단일숫자 평가지표를 얻을 수 있습니다. 가중된 평균값을 계산하는 것은 이러한 환경에서 가장 보편화된 방법으로 알려져 있습니다.
9. 최적화와 만족화라는 평가 지표에 대해서
- 여러개의 평가지표를 결합하는 또 다른 방법 을 소개해 보겠습니다.
- 학습 알고리즘의 수행 시간과 정확도, 두 개를 모두 고려해야 하는 상황을 가정해 보도록 하겠습니다. 그리고 다음과 같은 3가지 분류 알고리즘에 대하여 그 결과를 조사하였다고 가정해 보겠습니다.
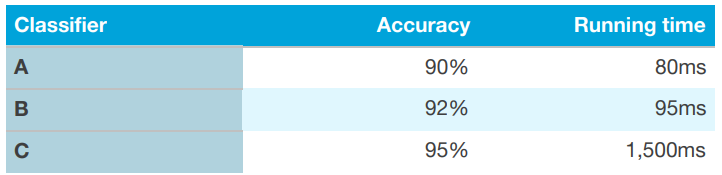
- 예를 들어 Accuracy - 0.5 * Running time 와 같은 방법으로 Accuracy와 Running time을 결합하여 단일 숫자 평가 지표를 계산하는것은 꽤나 부자연스럽게 느껴질 수 있습니다.
- 대신 다음과 같은 방법을 사용할 수 있습니다. 우선 최소한의 납득 가능한 수행시간을 정의하도록 하겠습니다. 예를 들어서, 100ms가 최소한으로 납득 가능하다고 설정해 볼 수 있습니다. 그리고 나서 이 수행 시간에 기반하여 정확도를 최대화 해볼 수 있습니다. 여기서 Running time은
만족화 지표(satisficing metric)로 수행하는 알고리즘은 이 지표에 대해서 만족만 하면 됩니다. 즉, 지나치게 좋을 필요도 없고 딱 그정도만 만족하면 됩니다. 그러면, Accuracy는최적화 지표(optimizing metric)라고 정의하면 됩니다.
- 만약 모델의 크기, Running time, Accuracy등의 N가지 다른 기준에 의한 트레이드-오프 상황이 발생한다면, N-1개의 기준을 만족화 지표로 설정하는 것을 고려해 볼 수 있습니다. 예를 들어서 N-1개는 단순히 특정 기준만 만족하면 되도록 하고 마지막 하나를
최적화 지표로서 정의할 수 있습니다. - 예를 들어 마이크를 통해 특정 소리를 들으면 절전상태가 해제되는 하드웨어를 만든다고 가정해 보겠습니다. 예를 들어 안드로이드 스마트폰의 Okay Google과 같은 기능입니다. 이 기능의 지표로 False Positive는 실제 기계가 절전을 해제하였지만 Okay google을 말하지 않은 상태입니다. 반면 False Negative는 실제 사람이 Okay google을 말하였지만 실제 기계가 절전을 하지 않은 상태입니다.
- 보통 제품의 Recall 성능은 낮으면 안되기 때문에 False Negative를 줄여야 합니다. 따라서 False Positive는
만족화 지표로 24시간 동안 1번 이하가 발생하도록 조건을 정한 다음 False Negative 비율을 최소화 하는최적화 지표를 만족하도록 할 수 있습니다.
10. 개발 데이터셋과 평가 지표로 개발 사이클 순환 속도를 빠르게
- 새로운 문제에 직면하였을 때, 어떤 접근 방법이 가장 좋은지 미리 아는 것은 매우 어려운 일입니다. 경험이 있는 머신러닝 연구자 또한 일반적으로 어떤 만족 할 만한 결과를 발견하기 까지 수많은 아이디어를 시도해야합니다. 머신러닝 시스템을 만들때, 보통 다음과 같은 프로세스를 수행합니다.
- ① 어떻게 시스템을 만들것인지에 대한 몇가지 아이디어로 시작한다.
- ② 그 아이디어를 코드로 구현한다.
- ③ 얼마나 그 아이디어가 잘 동작하는지 확인 가능한 수준으로 실험을 한다.
- 일반적으로 첫번째 몇가지 아이디어는 잘 동작하지 않습니다. 이 실험으로 부터 단서를 발견하게되고 추가적인 아이디어를 더 만들어보는 과정을 반복하게 됩니다.
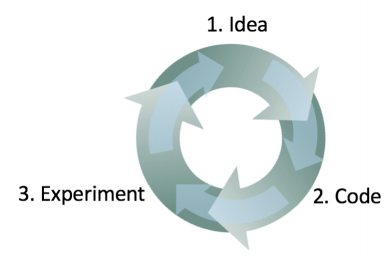
- 즉, 위의 프로세스는 반복하게 됩니다. 이 반복의 고리를 빠르게 돌수록, 더 빠른 결과를 얻을 수 있습니다. 여기서 개발/테스트 데이터셋, 그리고 평가지표가 왜 중요한지를 알 수 있습니다.
- 각 반복의 프로세스 단계에서 새로운 아이디어를 시험하게 됩니다. 개발 데이터셋은 그 아이디어의 성능을 측정 하여 올바른 방향으로 나아가고 있는지 아닌지 결정을 빠르게 내리는데 도움을 줄 수 있습니다.
- 이와는 대조적으로, 정해진 개발 데이터셋과 평가지표가 아직 없다고 가정해 보겠습니다. 각각의 반복 프로세스 단계에서 새로운 분류 알고리즘이 개발 될 수 있습니다. 개발된 분류 알고리즘은 개발중인 어플리케이션과 함께 연동하여 동작해 봐야 할 것이고, 새로운 알고리즘의 성능이 향상 되었는지 알아보기 위해서 해당 어플리케이션을 몇 시간 정도 테스트 해 봐야 할 것입니다.
- 만약에 알고리즘의 정확도를 95.0%에서 95.1%로 향상시키고 싶다면, 0.1%의 향상을 어플을 테스트 하는동안 알아채기는 것은 사실상 불가능합니다. 개발 데이터셋과 평가 지표는 어떤 아이디어가 가장 성공적인지 빠르게 알 수 있도록 도와줍니다. 그렇기 때문에, 어떤 아이디어를 더 정제 해야하고 어떤 아이디어를 버려야 하는지 빠르게 결정 할 수 있습니다.
11. 개발/테스트 데이터셋과 평가지표를 언제 바꿔야 하는가?
- 새로운 프로젝트를 시작할 때, 최대한 빨리 개발 / 테스트 데이터셋을 선택하려고 합니다. 왜냐하면 이 데이터셋들에 대한 빠른 선택은 잘 정의된 목적(타겟)이나 방향성을 제시 해 주기 때문입니다.
- 나(Andrew ng)는 보통 첫번째로 선택 될 개발/테스트 데이터셋과 측정지표(metric)을 1주 이내로 생각해달라고 팀에게 요청합니다. 완전하지 않는 것을 생각해낸 후 다음 수순으로 빠르게 움직이는 것이 필요 이상으로 과하게 생각하는 것 보다 더 낫기 때문입니다.
- 하지만, 그 한 주 동안의 시간을 보내는 것은 이미 성숙된 어플리케이션에 대한 개발에는 적용되지 않습니다. 예를 들어서, 스팸 차단기는 이미 꽤나 성숙된 딥러닝 어플리케이션입니다. 이와 같은 성숙한 시스템에 대해서 일을 하는 팀들을 많이 봐 왔고, 그들이 더 나은 개발/테스트 데이터셋을 구하기 위해서 수개월의 시간을 보내곤 합니다.
- 따라서 신규 문제가 아닌 널리 알려진 문제와 같은 경우에는 시행착오를 통해 빠르게 수정하는 것 보다 좀 더 많은 고민 시간을 가지고 데이터셋과 측정 지표를 고민하는 것이 낫습니다.
- 만약에 첫번째로 선택한 개발/테스트 데이터셋과 평가 지표가 뭔가 잘못되었음을 알게 된다면, 이는 단순히 그 데이터셋들과 평가지표를 빨리 바꿔야 함을 의미합니다. 예를 들어서, 만약 개발 데이터셋과 평가지표가 A 라는 분류 알고리즘이 B 라는 분류 알고리즘보다 더 좋다고 순위를 매겼지만, 팀은 분류 알고리즘 B가 사실상 개발 대상이 되는 상품에서는 더 나은 성능을 보여준다고 생각하는 경우가 있을 수 있습니다. 이러한 현상은 개발/테스트 데이터셋 또는 평가 지표를 변경해야 한다는 시그널이라고 판단할 수 있습니다.
- 분류 알고리즘 A가 더 낫다는 잘못된 판단을 하는데에는 개발 데이터셋과 평가지표에 관한 기본적인 세 가지 발생 가능한 원인이 있을 수 있습니다.
- ① 실제로 좋은 성능을 보여주길 원하는 데이터의 분포가 개발/테스트 데이터셋과 다른 경우
- 처음으로 선택한 개발/테스트 데이터셋이 성인 고양이의 사진들로 주로 이루어져 있다고 가정해 보겠습니다. 그리고 이것이 적용된 어플리케이션을 배포하였는데, 많은 사용자들이 예상한 것 보다 새끼 고양이 사진을 훨씬 더 많이 업로드 한다고 가정해 보겠습니다. 그렇다면, 개발/테스트 데이터셋의 분포는 실제 개발된 어플이 잘 동작해야 하는 데이터의 분포와는 달라집니다. 이 경우, 선택된 개발/테스트 데이터셋을 더 실제 환경과 비슷한 것들로 교체할 필요가 있습니다.
- ② 개발 데이터셋에 과적합 되는 경우
- 지속적으로 떠오르는 아이디어를 동일한 개발 데이터셋에 대하여 평가하는 과정이, 알고리즘으로 하여금 점차적으로 그 개발 데이터셋에 과적합 되도록 만들 수 있습니다. 개발을 끝내고 나서 개발된 시스템을 테스트 데이터셋을 통하여 평가하게 되는데, 이때 알고리즘의 개발 데이터셋에 대한 성능이 테스트 데이터셋에 대한 성능보다 월등히 뛰어나다면, 이는 개발 데이터셋에 과적합 되었다는 신호로 볼 수 있습니다.
- 이 경우에는, 기존에 사용된 데이터 말고 새로운 데이터로 개발 데이터셋을 구성하면 됩니다. 팀의 개발 진척도를 추적 하고자 하는 경우, 개발중인 시스템을 테스트 데이터셋에 대해서 정기적(주단위나 월단위)으로 평가 할 수 있습니다. 그러나, 알고리즘에 대한 어떠한 결정 (지난 주의 시스템으로 롤백해야 하는지에 대한 결정도 포함)이 사용된 테스트 데이터셋을 통해서는 평가를 하면 안됩니다. 만약에 어떤 결정을 내리게 된다면, 그 테스트 데이터셋에 대해서도 과적합 될 것 이고, 개발중인 시스템의 성능을 완전히 공정하게 측정하는것이 어려워질 것입니다.
- ③ 측정 지표가 프로젝트가 최적화 해야하는 것 이외의 것을 측정 하는 경우
- 고양이 분류 어플리케이션 에서 당신이 측정 지표로서 “분류의 정확도”를 설정 했다고 가정해 보겠습니다. 이 측정 지표는 현재 A라는 분류기가 B라는 분류기보다 더 낫다는 판단을 내리게 해주고 있습니다.
- 하지만 두 개의 알고리즘을 모두 시도해 봤을 때, A라는 분류기가 때때로 부적절한 사진이 노출되는 것을 허용함을 발견하게 되었다고 생각해 보겠습니다. A의 정확도가 더 높았지만, 이러한 나쁜 결과는 A의 성능을 받아들여지기 어렵다는 것을 의미 합니다. 이 때 어떻게 해야 할까요?
- 평가 지표 만으로는 알고리즘 B가 사실상 알고리즘 A보다 더 낫다는 것을 보여주는데에는 실패 하였습니다. 그러면, 최고의 알고리즘을 선별하기 위해서 이 평가 지표를 더이상 믿을 수 없게 됩니다.
- 즉, 이 경우에는 평가 지표를 바꿔야 합니다. 예를 들어서, 부적절한 사진을 필터링 하는데 촛점을 맞춘 평가 지표를 고를 수도 있습니다. 신뢰할 수 없는 평가지표를 사용하여 분류 알고리즘을 선택하는 반복을 하면서 많은 시간을 낭비 하는 것보다는, 명쾌하게 새로운 목표를 정의할 수 있는 새로운 평가 지표를 고를 것 을 강력히 추천 하는 바입니다.
- 개발/테스트 데이터셋 또는 평가 지표를 프로젝트 진행 도중에 변경하는 것을 꽤나 흔한 일입니다.
- 만약 개발/테스트 데이터셋 또는 평가 지표가 더이상 당신의 팀이 향해야 하는 방향을 가이드 하지 못한다는 것을 발견한다면, 그렇게 심각하게 고민할 필요 없습니다. 그냥 새로운 방향을 제시할 수 있는 데이터셋과 평가 지표로 바꿔서 당신의 팀원들에게 명쾌한 방향을 제시하면 됩니다.
12. 요약 : 개발 데이터셋과 테스트 데이터셋을 설정하는 것에 관하여
- 개발/테스트 데이터셋을 고를때, 실제 사용되는 상황에서 잘 동작하길 원하는 데이터를 반영 하도록 해야합니다. 데이터셋을 잘못 선정하면 개발용으로 선정된 데이터와 테스트 데이터셋이 다를 수 있습니다.
- 개발/테스트 데이터셋이 가능한한 동일한 데이터 분포로 부터 구성되어야 합니다.
- 단일 숫자의 평가 지표를 선택해서 팀이 이를 최적화 하도록 해야합니다. 만약 고려해야 하는 여러 개의 목표가 있는 경우, 여러개의 목표를 결합하여
하나의 수식(ex. 평균, F1 스코어)으로 표현하거나 만족화 평가지표 와 최적화 평가지표 등을 설정해야 합니다. - 머신러닝은 개발 사이클을 상당히 자주 돌려야 하는 작업입니다. 이에 대해서 스스로 만족하기 까지 수 많은 아이디어를 시도 해 봐야 합니다. 이 때,
개발/테스트 데이터셋과단일 숫자 평가지표가 현재 알고리즘을 빠르게 평가하는데 도움을 줄 것이고, 개발 사이클을 더 빠르게 돌 수 있도록 도와줄 것입니다. - 완전히 새로운 어플리케이션 개발 프로젝트를 시작할때, 개발/테스트 데이터셋과 평가 지표를 1주 이내로 최대한 빠르게 설정 하도록 합니다. 하지만 이미 성숙한 어플리케이션이 대상인 경우에는, 그 이상의 시간이 걸려도 괜찮으며 좀 더 깊게 생각할 수 있는 시간을 가지는 것이 좋습니다.
- 전체 데이터를 학습/테스트 데이터셋으로 70%/30% 비율 로 나누는 오래된 방식은 엄청나게 많은 데이터가 있는 경우에는 고려될 필요 없는 방식입니다. 개발/테스트 데이터셋은 전체 데이터의 30%보다 훨씬 적은 양으로 설정 되어도 괜찮다.
- 개발 데이터셋은 알고리즘의 정확도와 같은 부분에서 의미있는 변화를 체감할 수 있기 충분할 정도로 커야 합니다. 하지만 그 이상으로 엄청나게 클 필요는 없습니다. 테스트 데이터셋은 시스템의 최종 성능을 측정할때, 만족할만한 신뢰를 줄 수 있는 정도의 크기면 됩니다.
- 만약 개발 데이터셋과 평가지표가 더 이상 팀을 올바른 방향으로 이끌지 못한다면, 빨리 이를 바꿀 필요가 있습니다. 대표적으로 다음 기준을 따릅니다.
- ① 만약 개발 데이터셋에 대해서 과적합 된 경우, 더 많은 개발 데이터 셋을 구해야합니다.
- ② 만약 실제 환경의 데이터 분포가 개발/테스트 데이터셋의 분포와 다른 경우, 새로운 개발/테스트 데이터셋을 구해야합니다.
- ③ 만약 평가지표가 더 이상 당신이 중요 하게 생각하는 것을 측정하지 못한다면, 평가지표를 변경해 보도록 합니다.
13. 빨리 시스템을 만들어 보고, 개발 사이클의 순환을 빠르게 하자
- 새로운 머신 러닝 시스템을 구축하고 싶을 때, 다양한 아이디어가 떠오를 수 있습니다.
- 예를 들어 메일의 스팸 필터링 시스템을 구축한다고 가정해 보겠습니다. 스팸 필터링 시스템 구축을 위해 오랫동안 일해 왔다고 할지라도, 어떤 주제로 방향을 정할지를 선택하는 것은 어려움이 따릅니다. 만약에 이 특정 어플리케이션의 생태 환경을 이해하지 못하는 비전문가라면, 더욱 더 어려운 일이 될 것이다.
- 따라서 완벽한 시스템을 디자인하고 개발하는 것에 목적을 두고 시작하지 말아야 합니다. 대신에, 아주 간단한 시스템을 몇 일 안에 빨리 개발하고 학습시켜 보는 것이 중요합니다. 아주 간단한 시스템이 당신이 최선을 다해 개발할 수 있는 최고의 시스템과 많이 거리가 멀더라도, 그 간단한 시스템이 어떻게 동작하는지 관찰하는 것은 여전히 의미 있는 일이 될 것입니다. 이를 통하여 어디에 시간을 더 투자하고, 더 유망한 방향이 무엇인지에 대한 단서를 더 빠르게 찾을 수 있을 것입니다.
14. 에러 분석: 아이디어에 대한 평가를 위해 개발 데이터셋을 살펴보는 것
- 예를 들어 고양이 분류 어플을 사용할 때, 강아지를 고양이로 잘못 분류하는 경우가 있다는 것을 발견할 수 있습니다.
- 한달 이라는 시간을 이 작업에 투자하기 전에 먼저 그 작업으로 인해서 시스템의 정확도가 얼마나 향상될지를 예측해 보는 작업을 추천합니다. 그러고 나면, 이 작업이 한달이나 개발 시간을 쓰는 것에 의미가 있는지 좀 더 합리적으로 판단할 수 있다. 그렇지 않다면, 그 시간을 다른 곳이 투자하는 것이 더 좋기 때문입니다.
- 예를 들어 다음과 같은 상황을 생각해 보도록 하겠습니다.
- ① 현재 시스템이 잘못 분류하는(에러가 발생된) 100개의 예제 개발 데이터셋를 구해본다.
- ② 이 데이터셋을 일일이 수작업으로 한번 들여다 본다. 100개 중 몇 퍼센트나 강아지 이미지가 있는지 세어본다.
- 잘못 분류된 예제 데이터를 들여다 보는 작업을
에러 분석이라고 합니다. 이 예제에서, 단지 잘못 분류된 전체 이미지의 5%만이 강아지 이미지라는 것을 발견 했다면, 강아지 이미지에 대해서 알고리즘의 성능을 향상시켜 봤자 그 5% 에러를 해결하는 것은 어려울 것이다. 다시 말해서, 5%는 마지노선 (최대로 가능한 수준) 이라고 볼 수 있습니다. - 따라서, 만약 전체 시스템이 현재 90%의 정확도 (10%의 에러)를 가지고 있는 경우, 이 강아지 이미지에 대한 개선작업은 (최초 10%의 에러율보다 5% 줄어든 9.5%의 에러로 인하여) 정확도 향상에 고작 90.5% 까지밖에 기여하지 못합니다.
- 이와 대조적으로, 만약 50%의 실수가 강아지 이미지였다면, 에러 분석을 통하여 현재의 90% 정확도를 95%까지 끌어올릴 수 있을 것입니다. (에러를 50% 감소하여, 이는 최초 10%에러를 5%까지 줄이는 것을 의미)
에러 분석은 다른 문제 해결의 방향들이 얼마나 유망한지 알아내는데 도움을 주기도 합니다.에러 분석을 시행하는것을 꺼려하는 수 많은 엔지니어가 있습니다. 아마도, 몇몇 아이디어를 생각해 내고 이를 구현하는데 직접 뛰어드는 것이, 그 아이디어가 얼마나 가치 있는지에 대하여 질문을 던지는데 시간을 사용하는 것보다 흥미롭기 때문일 것입니다. 그러나 이건 아주 일반적인 실수입니다.- 수작업으로 100개의 예제를 관찰해 보는 것은 그다지 시간이 걸리지 않습니다. 하나의 이미지당 1분을 소요한다고 가정해도 2시간 이내에 작업을 완료할 수 있습니다. 이 2시간은 쓸데 없는 노력으로 허비되는 1달을 절약하는데 도움을 줄 수 있습니다.
에러 분석은 작성된 알고리즘이 잘못 분류한 개발 데이터셋의 일부 예제를 관찰해 보는 과정으로 에러를 유발하는 기본적인 원인을 이해하는데 도움을 줍니다.- 특히 프로젝트를 이끌어 나가는 여러가지 제안된 방향들 중 우선순위를 매길 수 있게 도와줍니다. 다음 몇몇 챕터들은 에러 분석을 수행하기 위한 최고의 실전 방법을 소개합니다.
15. 에러 분석 중간에 여러가지 아이디어를 동시에 판단해 보는 것
- 고양이 분류 알고리즘을 향상하기 위해, 다음과 같은 몇가지 아이디어를 떠올릴 수 있습니다.
- 강아지를 고양이로 인식하는 알고리즘의 문제점을 고치는 것, 거대한 고양이 (사자, 팬서, 등등..)을 애왕용 집고양이로 인식하는 알고리즘의 문제점을 고치는 것, 흐릿한 이미지에 대하여 시스템 성능을 향상 시키는 것 등등.
- 나열된 모든 아이디어를 동시에 효율적으로 평가해 볼 수 있습니다. 보통 100개 까지의 잘못 분류된 개발 데이터셋을 보면서, 그 예제 데이터를 스프레드 시트에 기록하곤 합니다.
- 그리고 특정 중요한 예제에 대해서 몇가지 코멘트를 남기기도 합니다. 이 과정을 설명하기 위해서, 4개의 예제 데이터로 구성된 작은 개발 데이터셋에 대한 스프레드 시트를 한번 살펴 보도록 하겠습니다.
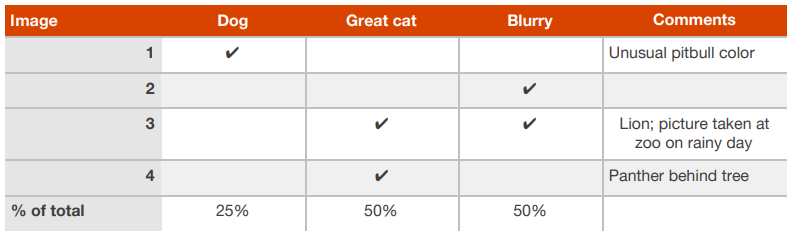
- 위 테이블과 같이 강아지, 큰 고양이, 흐릿함이라는 카테고리를 먼저 구성 한 후에, 예제 이미지들을 손으로 분류해 볼 수 있습니다.
- 일단 그 예제 이미지를 보기 시작하면 아마도 새로운 에러 종류의 카테고리를 추가적으로 제안하게 될 가능성이 큽니다. 예를 들어서 12장의 이미지를 관찰하다가 새로운 필터가 적용된 사진들에 대해서 많은 실수가 발생했다는 것을 알게 될 수 있습니다.
- 이러한 경우, 다시 처음으로 돌아가서, 새로운 그 필터에 대한 새로운 컬럼을 스프레드 시트에 추가할 수 있습니다. 알고리즘이 잘못 분류한 예제 이미지를 일일이 수동으로 관찰하고 사람이라면 그 사진을 어떻게 제대로 레이블링 할 수 있는지 질문해 보는 것이 새로운 종류의 카테고리를 생각해 낼 수 있게 하고 그에 대한 해결책도 찾을 수 있게 해줄 수 있습니다.
- 가장 도움이 되는 에러 카테고리는 성능을 향상 시킬 수 있는 어떤 아이디어가 있을 경우 그 아이디어를 사용하는 것입니다.
- 예를 들어서 어떤 필터에 대한 카테고리는 그 필터가 적용된 사진을 원본으로 되돌릴 수 있는 방법을 알고 있는 경우 이 케이스를 추가하면 큰 도움이 되는 카테고리라고 볼 수 있습니다.
- 하지만 어떻게 성능을 향상 시킬 수 있는지 아는 것만 에러 카테고리로서 추가해야 한다고 스스로를 제한할 필요는 없습니다. 이 과정의 목표는 내가 지금 가지고 있는 포커스를 맞춰야 하는 가장 유망한 부분에 대한 직관력을 키우는 것입니다.
- 에러 분석은 반복적인 작업입니다. 어떤 카테고리를 사용해야 하는지 생각나는 것이 없더라도 걱정할 필요는 없습니다.
- 몇몇 예제 이미지를 관찰 하고 나면 에러 카테고리에 대한 몇가지 아이디어를 얻게 될 것입니다. 몇몇 예제 이미지를 수작업으로 각 카테고리에 맞게 분류한 후, 새로운 카테고리를 설정하고 그 예제 이미지들을 새로운 카테고리의 기준에 맞추어 다시 생각해 볼 수도 있습니다. 이런 식으로 카테고리에 대한 아이디어를 얻어 나갈 수 있습니다.
- 예를 들어 100개의 잘못 분류된 개발 데이터셋의 예제 이미지에 대한 에러 분석을 끝냈고, 다음과 같은 결과를 얻었다고 가정해 보겠습니다.

- 이런 결과를 얻고 나면, 강아지 이미지로 인해 실수가 발생한 것을 개선하기 위하여 프로젝트를 진행 했을 때, 최대 8%의 에러를 개선할 수 있다는 것을 알 수 있습니다.
- 반면 거대한 고양이 또는 흐릿한 이미지 에러에 대한 개선은 강아지 이미지로 인한 에러의 개선보다 더 많은 에러의 개선에 도움을 줄 수 있습니다. 따라서 후자로 언급된 두 가지의 카테고리에 좀 더 포커스를 맞추어 프로젝트를 진행하자는 결정을 내릴 수 있습니다.
- 만약 당신의 팀이 많은 사람으로 구성되어, 동시에 여러가지 방향을 시도해볼 수 있다면, 몇몇 엔지니어에게는 거대한 고양이에 관련된 에러를, 그리고 또 몇몇 엔지니어에게는 흐릿한 이미지에 관련된 에러를 개선하도록 요청할 수도 있습니다.
- 에러 분석에서 가장 높은 우선순위가 무엇인지 바로 알 수 있는 어떤 엄격한 수학적인 공식이 존재하여 것은 아닙니다. 각각 서로 다른 카테고리에 대해서 얼마나 많은 진척을 이루어 낼 수 있는지, 그리고 얼마나 많은 시간이 각각에 대하여 필요한지를 생각하는 것이 중요합니다.
16. 개발/테스트 데이터셋의 잘못 레이블링된 데이터를 정리하는 것
- 에러 분석 도중에 개발 데이터셋에 있는 몇몇 예제 데이터들이 잘못 레이블링 된 것을 발견하는 경우가 있습니다.
잘못 레이블링된이라는 이야기는 알고리즘이 이 문제에 직면하기도 전에 이미 사람이 잘못된 레이블을 기입한 경우를 말합니다. - 예를 들어서, (x, y) 라는 예제 데이터에서 y 값이 잘못 기입된 것입니다. 또 다른 예로 몇몇 고양이가 아닌 사진들이 고양이다 라고 잘못 레이블링된 경우나, 그 반대의 경우를 생각해 볼 수 있습니다. 잘못 레이블링된 이미지들의 부분 집합이 매우 중요하다고 생각된다면, 다음과 같이 그 잘못 레이블링된 예제 데이터를 추적하기 위한 카테고리를 추가해 보는 것이 좋습니다.
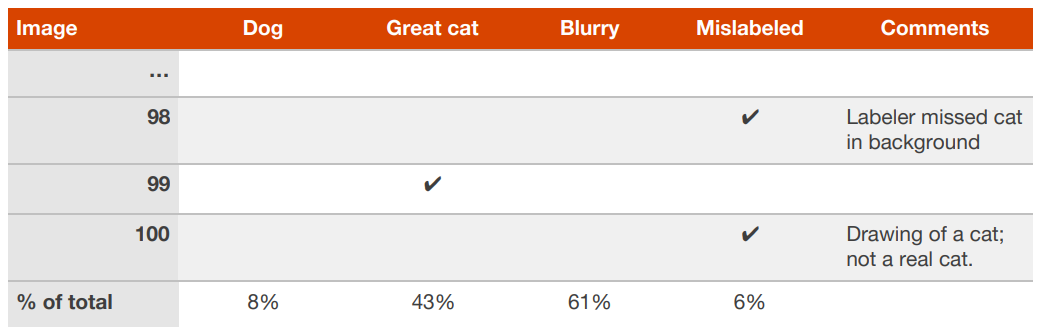
- 그런데 개발 데이터셋에 있는 레이블들을 올바르게 수정해야만 할까요? 개발 데이터셋의 목표점은 알고리즘 A가 B보다 더 낫다고 빠르게 판단을 내릴 수 있는데 도움을 주는 것임을 생각해야 합니다. 잘못 레이블링된 개발 데이터셋의 일부분이 이런 판단을 내리는 것을 지연시키고 있다면, 이 잘못 레이블링된 값을 올바르게 수정하는데 드는 시간은 의미가 있습니다.
- 예를 들어 분류기의 성능이 다음과 같다고 가정해 보겠습니다.
- 개발 데이터셋에 대한 종합적인 정확도 : 90% (10%의 종합적인 에러율)
- 잘못 레이블링된 데이터로 인한 에러율 : 0.6% (개발 데이터셋에서의 6%의 에러율)
- 그 외의 원인으로 인한 에러율 : 9.4% (개발 데이터셋에서의 94%의 에러율)
- 잘못 레이블링된 데이터로 인한 0.6% 라는 부정확성은 비교적 그다지 중요하지 않을 수 있습니다. 왜냐하면 상대적으로 그 외의 원인을 조사하여 9.4%라는 에러율을 개선 할 수 있을지도 모르기 때문입니다. 이 말이 개발 데이터셋에서 잘못 레이블링된 데이터를 수작업으로 올바른 값으로 수정할 필요가 없다는 것은 아닙니다. 그러나 그 작업이 크게 중요하지도 않을 수 있다는 것을 염두해 두셔야 합니다. 전체 시스템의 에러율이 10%이고 그 중 9.4%가 그 외의 원인에 해당하는 경우 잘못 레이블링된 데이터를 수정하는 것에 너무 치중하는 것은 효과적이지 않을 수 있다는 뜻입니다.
- 분류 알고리즘을 계속 개선하여, 다음과 같은 성능을 얻었다고 가정해 보겠습니다.
- 개발 데이터셋에 대한 종합적인 정확도 …….. 98.0% (2.0%의 종합적인 에러율)
- 잘못 레이블링된 데이터로 야기된 에러율 …… 0.6% (개발 데이터셋에서의 30%의 에러율)
- 그 외의 원인으로 야기된 에러율 …………. 1.4% (개발 데이터셋에서의 70%의 에러율)
- 종합적인 에러율 2%의 30%에 해당하는 0.6 % 에러율이 개발 데이터셋에 있는 잘못 레이블링된 이미지로 인하여 발생하였습니다.
- 이는 정확도 측정에 대한 중대한 에러율이라고 볼 수 있습니다. 이 경우에는 개발 데이터셋에 있는 레이블들의 퀄리티를 향상시키는 것이 의미 있는 일이 될 수 있습니다.
- 잘못 레이블링된 개발/테스트 데이터셋을 인지하면서 개발을 시작하는것은 매우 일반적이다. 하지만 시스템의 성능이 향상됨에 따라서, 잘못 레이블링된 데이터로 인한 에러율이 차지하는 비율이 커질 수 있는 것 또한 인지해야 합니다. 그러므로 시스템이 성장함에 따라 이를 염두해 두는 것이 좋습니다.
- 또한 개발 데이터셋의 레이블을 고치기 위한 과정은 테스트 데이터셋에도 동일하게 적용해야 함을 기억해 두어야합니다. 그래야 개발/테스트 데이터셋이 동일한 데이터 분포를 가지게 됩니다. 개발/테스트 데이터셋을 함께 수정하는 것이 6번에서 논의된 문제를 방지할 수 있을 것입니다.
- 레이블의 퀄리티를 향상 하고자 마음 먹었다면, 시스템이 잘못 분류한 예제 데이터와 잘 분류한 예제 데이터의 레이블을 함께 체크해 보기를 권장합니다. 수정 전의 레이블과 알고리즘이 모두 그 특정 예제 데이터에 대해서 잘못되어 있을 가능성이 있기 때문입니다.
- 만약 시스템이 잘못 분류한 데이터의 레이블만을 수정한다면, 이후 평가 단계에서 편향된 결과를 얻을 수도 있다. 1,000개로 이루어진 개발 데이터셋을 가지고 있을때, 그리고 작성된 알고리즘이 98.0%의 정확도를 보일때, 20개의 잘못 분류된 데이터를 분석해 보는 것이 나머지 잘 분류된 980개의 데이터를 분석하는 것 보다 쉽습니다. 왜냐하면 현실적으로 잘못 분류된 데이터를 체크해 보는 것이 더 쉽기 때문입니다. 이 경우에, 편향된 결과가 몇몇 개발 데이터셋에 발생하게 됩니다. 이 편향된 결과는 어플리케이션을 개발하는 것에만 관심이 있는 경우 어느 정도 허용될 수 있습니다. 하지만, 아카데믹한 연구 논문에 사용되거나 올바른 테스트 데이터셋의 정확도를 측정 하고 싶을때는 문제가 될 수 있습니다.
17. 큰 사이즈의 개발 데이터셋이 있는 경우, 두개의 부분집합으로 이를 나누고, 그 중 하나만 관찰하는 것
- 개발 데이터셋으로 20%의 에러율을 보이는 5,000개의 예제 데이터가 있다고 가정해 보겠습니다. 그러면 개발된 알고리즘은 약 1,000개의 이미지를 잘못 분류하게 됩니다. 1000개의 이미지를 수작업으로 일일이 확인하는데는 시간이 오래 걸리므로 에러 분석에 1000개 모두를 사용하지 않는다는 결정을 내려버릴 수도 있습니다.
- 이 경우에 개발 데이터 셋을 명시적으로 두 개의 부분 집합으로 분리한 뒤 한 집합은 면밀히 분석하고 나머지 하나는 분석하지 않습니다.
- 이 때, 수작업으로 관찰한 특정 집합(전자)에 대하여 모델을 빠르게 과적합하게 하고 나머지 관찰하지 않는 집합(후자)으로는 하이퍼파라미터 튜닝을 합니다.
- 앞서 사용한 (5,000개의 개발 데이터셋 중 1,000개를 잘못 분류하는 알고리즘) 예를 계속 살펴보겠습니다.
- 여기서, 에러 분석을 위해서 이미 에러로 확인한 1,000개의 에러 데이터 중에서 50%에 해당하는 500개의 에러 케이스를 수작업으로 일일이 관찰하길 원한다고 가정해 보겠습니다. 이때, 개발 데이터셋의 50%는 반드시 무작위로 선정 되어야 하고, 선택된 데이터는
Eyeball 개발 데이터셋이라고 부르는 집합에 넣겠습니다. Eyeball 개발 데이터셋이라고 부르는 이유는 실제로 우리의 눈을 가지고 관찰되어야 하는 데이터임을 우리 스스로에게 상기시키기 위함이다. - 이렇게 해서 Eyeball 개발 데이터셋은 500개의 데이터를 가지게 되고, 우리가 개발한 알고리즘은 이 500개의 데이터에 대해서는 항상 잘못 분류한다고 말할 수 있습니다.
- 개발 데이터셋에서 분리되어 나온 두번째 부분 집합은
Blackbox 개발 데이터셋이라고도 불리는데, 이 데이터셋은 나머지 4,500개의 데이터를 가지게 됩니다. - 이 Blackbox 개발 데이터셋을 사용해서 분류 알고리즘들의 에러율을 측정하여, 자동으로 각 알고리즘들을 평가하는데 사용할 수 있습니다. 또한, 여러개의 알고리즘들 중에서 하나를 선택하거나, 하이퍼파라메터의 값을 튜닝하기 위한 용도로도 사용될 수 있습니다.
- 하지만, 실제로 이 데이터를 직접 들여다 보는 것은 피해야 합니다.
Blackbox라는 용어를 사용한 이유는 Blackbox를 통해서 알고리즘들의 평가를 얻기 위한 데이터로 사용되기 때문입니다.
- 왜 명시적으로 전체 개발 데이터셋을
Eyeball과Blackbox개발 데이터셋으로 분리해야만 할까요? - 작업자가
Eyeball 개발 데이터를 직접 확인할 때, 그 속의 예제 데이터에 대한 어떤 직감적인 무언가를 느낄 수 있기 때문입니다. - Eyeball 개발 데이터를 보고 Blackbox 개발 데이터셋으로 학습하면서 하이퍼파라미터를 튜닝하기 때문에 Eyeball 개발 데이터셋에 대하여 더 빠르게 과적합이 시작될 수 있습니다.
- 만약 Eyeball 개발 데이터셋에 대한 성능 향상이 Blackbox 개발 데이터셋에 대한 성능 향상보다 빠르게 일어나는 것을 눈치 챈다면, Eyeball 개발 데이터셋에 대하여 과적합 되었음을 의미합니다. 이 경우에는, 기존의 Eyeball 개발 데이터셋을 버리고, Blackbox 개발 데이터셋으로부터 더 많은 데이터를 가져와서 새로운 Eyeball 개발 데이터셋을 구성할 필요가 있tmqslek. (또는 완전히 새로운 데이터를 얻어 보는 방법도 있습니다.)
- 정리하면 전체 개발 데이터셋을
Eyeball과Blackbox개발 데이터셋으로 분리하는 것을 통하여 수작업으로 진행되는 에러 분석 과정을 Eyeball 데이터셋에 대하여 진행하고 Blackbox 데이터셋을 통하여 학습을 하면서 하이퍼파라미터를 튜닝하여 Eyeball 데이터셋에 대한 오류를 줄여나아갑니다. 이 때, Eyeball 데이터셋에 대하여 과적합이 발생하는 지 확인을 하고 과적합 발생 시, Eyeball 데이터셋을 수정해 나아갑니다.
18. Eyeball과 Blackbox 개발데이터셋은 얼마나 커야 할까?
- 구성된
Eyeball과 개발 데이터셋은 개발 중인 알고리즘이 만들어내는 중대한 에러 종류(카테고리)를 확인할 수 있을만큼 충분한 크기여야 합니다. - 개발 중인 분류 알고리즘이 5%의 에러율을 보인다고 가정해 보겠습니다.
Eyeball개발 데이터셋에 있는 100개의 잘못 분류된 데이터를 가지고 있음을 확신하기 위해서,Eyeball개발 데이터셋은 2,000개의 데이터를 가져야 할 수 있습니다. (왜냐하면 0.05 * 2,000 = 100, 5%의 양) 이와 같은 이유로 분류 알고리즘의 에러율이 낮으면 낮을 수록, 더 큰Eyeball개발 데이터셋이 필요해집니다.
- 그렇다면
Blackbox개발 데이터셋은 어떨까요? 앞에서 1,000 ~ 10,000개로 구성되는 개발 데이터셋이 일반적임을 이야기 한 적이 있습니다. 이 말을 좀 더 다듬어 보면, 1,000 ~ 10,000개의Blackbox개발 데이터셋은 여러개의 모델 중 하나를 선택하거나, 하이퍼-파라메터를 튜닝하기 충분한 양이라는 말이 됩니다.
- 작은 크기의 개발 데이터셋을 가지고 있다면, 그 데이터들을
Eyeball과Blackbox개발 데이터셋으로 나누기에 충분하지 않을 수 있습니다. 이 때는 대신에, 전체 개발 데이터셋이Eyeball개발 데이터셋으로 사용될 수 있습니다. 이 경우 모든 개발 데이터셋이 수작업으로 관찰되어야 하는 대상이 되어야 합니다.
Eyeball과Blackbox개발 데이터셋 중에서,Eyeball개발 데이터셋이 더 중요한 것이라고 생각합니다. 만약Eyeball개발 데이터셋 만을 가지고 있는 경우, 에러 분석을 수행할 수 있고, 이 데이터셋으로 모델 선택 및 하이퍼-파라메터 튜닝을 수행할 수 있기 때문입니다.Eyeball개발 데이터셋 만을 가지게 되는 것의 단점은 개발 데이터셋에 대하여 과적합될 위험성이 매우 커진다는 것이 있을 수 있습니다.- 만약 충분한 양의 데이터가 있다면,
Eyeball개발 데이터셋의 크기는 수작업으로 분석하는데 쏟을 수 있는 시간이 얼마나 있는지로 정해질 수 있습니다. 따라서 비용을 고려하여 충분히 큰Eyeball개발 데이터셋을 구축하면 됩니다.
19. 요약: 기본적인 에러 분석에 관하여
20. 편향과 분산: 에러를 일으키는 두 가지 큰 원인
21. 편향과 분산의 예
22. 최적의 에러율과 비교하는 것
23. 편향과 분산 문제 해결방법에 대한 고심
24. 편향 vs. 분산의 균형 대립
25. 피할 수 있는 편향을 줄이기 위한 기법들
26. 학습 데이터셋에 대한 에러 분석
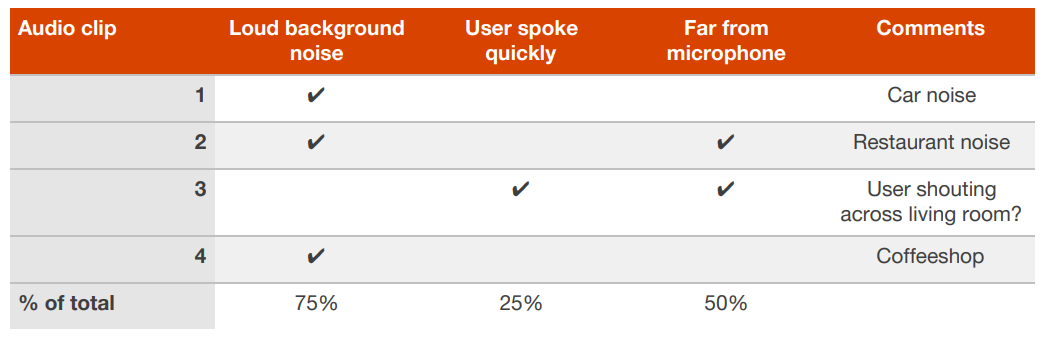
27. 분산치를 줄이기 위한 기법들
28. 편향과 분산을 진단하는 것: 학습 곡선
29. 학습 데이터셋에 대한 에러의 곡선을 그리는 것
30. 학습 곡선을 해석하는 것: 높은 편향치
31. 학습 곡선을 해석하는 것: 그 외의 상황
32. 학습 곡선들을 그리는 것
인간 수준의 성능과 비교하는 것에 대하여
33. 왜 사람-수준의 성능과 비교해야 하는가?
34. 어떻게 사람-수준의 성능을 정의할 것인가?
35. 사람-수준의 성능을 넘어서는 것
36. 다른 분포로 부터 구성되는 학습, 테스트 데이터셋을 언제 사용해야 하는가?
37. 모든 데이터를 사용해야하는지 어떻게 결정을 내려야 하는가?
38. 일관적이지 못한 데이터를 포함시키기 위한 결정을 어떻게 내려야 하는가?
39. 데이터에 가중치를 주는 것
40. 학습 데이터셋에서 개발 데이터셋으로 일반화 하는 것
41. 편향과 분산을 표현/해결하는 것
42. 데이터 미스매치를 표현/해결하는 것
43. 인공적인 데이터 합성에 대하여
44. 최적화 검증 테스트(The Optimization Verification test)
45. 최적화 검증 테스트의 일반적인 형태
46. 강화학습의 예
47. End-to-End 학습의 등장
48. End-to-End 학습의 다른 예
49. End-to-End 학습의 장단점
50. 파이프라인의 컴포넌트를 선택하는 것: 데이터 수집의 가능성
51. 파이프라인의 컴포넌트를 선택하는 것: 작업의 간결성
52. 직접적으로 부유한(rich) 출력값을 학습하는 것
53. 부분/컴포넌트별로 수행하는 에러 분석
54. 에러를 특정 컴포넌트의 잘못으로 분류하는것
55. 에러를 특정 컴포넌트의 잘못으로 분류하는 일반적인 방법
56. 사람-수준의 성능과 각 컴포넌트를 비교하여 에러분석을 수행하는 것
57. ML 파이프라인의 결함을 발견하는 것
58. super hero 팀을 결성하고 이 문서를 공유할 것
AI 프로젝트 실패의 5가지 원인
- 이 글은 Riiid Techblog의 송호연님의 글을 요약하여 작성하였습니다. 생각해 볼 내용인 것 같습니다.
린 사고방식: 성공하기 위해 빠르게 실패하라 (Fail Fast). 빠르게 실패하여 낭비를 줄여야 합니다. 그리고 프로젝트를 실패하게 만들 위험 요인을 식별해야 합니다.- AI 프로젝트가 실패할 수 밖에 없는 5가지 이유
- ① Value: 가치가 없는 프로젝트를 추진한다.
- AI 프로젝트는 정말 비용이 많이 듬에도 불구하고 추진할만한 가치가 없는 프로젝트를 진행합니다.
- ② Data: 데이터 전략이 없다.
- 경쟁력의 원천은 데이터이고 새로운 데이터를 더 넣어주는 방식으로 성능을 개선할 수 있습니다.
- ex1) 콜드 스타드 문제(Cold-start problem) : 프로젝트 시작 전 데이터가 없으므로 다음 과정을 거쳐 데이터를 생성합니다.
- 라벨링 작업자의 인건비를 고려하여 라벨링 예산을 수립합니다.
- 시간 당 얼마의 데이터가 확보 가능한 지 계산합니다.
- 라벨링 작업자를 모집할 수단을 계획합니다.
- 직접 라벨링 시스템 구축 or 아웃소싱 여부를 결정합니다.
- ex2) 외부에 공개된 데이터 셋은 실제 사용할 데이터셋의 분포와 다름
- 학습하는 모델의 테스트 데이터 셋(test dataset)으로 오픈 데이터셋을 사용하면 안됨
- 학습하는 모델의 테스트 데이터 셋(test dataset)은 실제 유저를 통해 사용될 데이터와 최대한 유사해야 함
- ex3)
액티브 러닝: 모델의 취약한 데이터 위주로 데이터를 확보하는 방법- 예를 들어 어떤 클래스에 대한 성능이 낮다면, 이 클래스에 해당하는 데이터를 데이터 셋에 추가하는 방식으로 데이터를 똑똑하게 수집하는 전략입니다. 중요한 점은 어떻게 취약한 데이터를 구분하는 지에 대한 전략입니다.
- ③ Metric: 성공의 기준이 명확하지 않다.
- 구체적인 목표 설정을 위해 가능하면 목표를 수치화해야 합니다. 즉, 성능 지표를 정확하게 정해야 합니다.
- ④ Team: 인공지능 엔지니어링 팀을 구성하지 못한다.
- ⑤ Result: 빠르게 결과를 얻지 못한다.
- 앞에서 언급한 바와 같이 Fast Fail 전략을 취해야 합니다. 빠르게 움직여서 빠르게 결과를 확인하는 방향이 성공의 지름길입니다.