
sklearn의 Toy Data 불러오기
2018, Dec 23
사이킷 런을 사용하여 예제를 풀 때 많이 사용하는 데이터로는
- Boston housing price
- Digits
- Iris
이렇게 3가지가 있습니다. 거의 수학의 정석에서 집합이라고 할 수 있을까요?
- 먼저 라이브러리를 불러 오겠습니다.
from sklearn import datasets
import matplotlib.pyplot as plt
Boston Housing Price 데이터 불러오기
# 보스턴 집값 데이터를 불러옵니다.
boston = datasets.load_boston()
# feature matrix를 만듭니다.
X = boston.data
# target vector를 만듭니다.
y = boston.target
# feature의 첫번째 값을 확인해 봅니다.
X[0]
>> array([ 6.32000000e-03, 1.80000000e+01, 2.31000000e+00,
0.00000000e+00, 5.38000000e-01, 6.57500000e+00,
6.52000000e+01, 4.09000000e+00, 1.00000000e+00,
2.96000000e+02, 1.53000000e+01, 3.96900000e+02,
4.98000000e+00])
값을 출력해 봅니다.
[ "{:.2f}".format(x) for x in X[0]]
>>> ['0.006320',
'18.000000',
'2.310000',
'0.000000',
'0.538000',
'6.575000',
'65.200000',
'4.090000',
'1.000000',
'296.000000',
'15.300000',
'396.900000',
'4.980000']
숫자 데이터 불러오기
# 숫자 데이터 불러오기
digits = datasets.load_digits()
# feature matrix
X = digits.data
# target vector
y = digits.target
# 첫 번째 값 확인
X[0]
>> array([ 0., 0., 5., 13., 9., 1., 0., 0., 0., 0., 13.,
15., 10., 15., 5., 0., 0., 3., 15., 2., 0., 11.,
8., 0., 0., 4., 12., 0., 0., 8., 8., 0., 0.,
5., 8., 0., 0., 9., 8., 0., 0., 4., 11., 0.,
1., 12., 7., 0., 0., 2., 14., 5., 10., 12., 0.,
0., 0., 0., 6., 13., 10., 0., 0., 0.])
- 첫 번째 이미지를 matplotlib을 이용하여 확인해 보겠습니다.
plt.gray()
plt.matshow(digits.images[0])
plt.show()
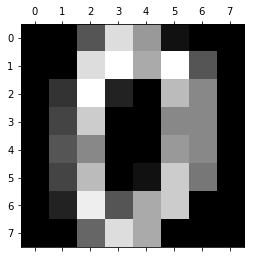
Iris 데이터 불러오기
앞에서 한 방법과 동일하게 데이터를 불러오면 됩니다.
# iris 데이터 불러오기
iris = datasets.load_iris()
# feature matrix
X = iris.data
# target vector
y = iris.target
# 첫 번째 값 확인
X[0]
>> array([ 5.1, 3.5, 1.4, 0.2])
도움이 되셨으면 광고 한번 클릭 부탁드립니다. 꾸벅