
파이썬 crawling snippets
2020, Sep 01
- 이 글에서는 파이썬의 크롤링 방법들에 대하여 다루겠습니다. 크롤링을 하기 위해 필요한
requests,beautifulsoup,selenium등을 포함합니다.
목차
-
requests, selenium, beautifulsoup을 이용한 기본적인 크롤링
requests, selenium, beautifulsoup을 이용한 기본적인 크롤링
- 먼저 크롤링을 위한 절차는 다음과 같습니다.
- ① 크롤링 하고 싶은 페이지를 requests 또는 selenium을 통하여 source를 가져옵니다.
- ② 가져온 source를 beautifulsoup을 이용하여 parsing 합니다.
- 즉, 크롤링을 할 때 항상 언급되는 requests, selenium은 웹페이지의 정보를 읽어올 때 사용하고 beautifulsoup은 읽어온 웹페이지의 정보를 분석할 때 사용하는 것으로 이해하면 됩니다.
- 먼저 requests를 이용하여 정보를 읽어오는 방법에 대하여 설명드리겠습니다.
import requests
url = "https://naver.com"
r = requests.get(url)
html = r.text
- 위 코드와 같이 최종적으로
html변수에 url에 해당하는 웹 페이지의 source를 가져올 수 있습니다. - requests는 다양한 기능을 가지고 있고 get 뿐 아니라 post 하는 기능이 있으므로 다양한 역할을 할 수 있습니다.
- 하지만 requests는 동적으로 움직이는 웹페이지를 유연하게 대응하여 크롤링 하는 데에는 불편함이 있습니다.
- 예를 들어 웹 페이지의 어떤 버튼을 눌렀을 때에만 그 페이지의 어떤 영역의 정보를 읽어오는 경우가 많이 있습니다. 댓글 같이 페이지네이션이 되어 더 보기와 같은 버튼 눌러야 정보를 더 읽어올 수 있는 경우가 대표적인 케이스입니다.
- 이런 경우 requests 만으로는 유연하게 크롤링 하기가 어렵습니다. 이 때, 사용해야 하는 패키지가
selenium입니다.
- 다음 명령어를 이용하여 selenium을 설치할 수 있습니다.
pip install selenium- selenium의 주 목적은 웹 페이지를 동적으로 다루기 위함입니다. 따라서 selenium을 이용하여 웹 페이지를 다루기 위해 사용할 브라우저의 웹 드라이버를 다운 받아야 합니다.
- 예를 들어 크롬의 웹 드라이버는 다음 링크에서 다운 가능합니다.
- 다운로드 : https://chromedriver.chromium.org/downloads
- 현재 사용하고 있는 크롬 브라우저의 버전에 맞는 웹 드라이버를 받고 사용하고 있는 PC 어느 곳에 그 파일을 위치 시킵니다.
- 저 같은 경우에는
C:\chromedriver_win32\chromedriver.exe에 위치시켰습니다. - 그러면 다음 코드를 이용하여 웹 드라이버를 실행시키고 웹 페이지의 html을 가져올 수 있습니다.
from selenium import webdriver
url = "https://naver.com"
driver = webdriver.Chrome(executable_path=r'C:\chromedriver_win32\chromedriver.exe')
driver.get(url)
html = driver.page_source
- requests와 selenium의 webdriver를 이용하여 같은 페이지를 읽어와도 webdriver를 통해 정보가 더 많은 것을 비교하면 확인하실 수 있습니다.
- requests는 서버에 read 요청을 하였을 때, 서버를 통해 받는 정보인 반면 webdriver는 실제 웹 페이지에 있는 정보를 모두 가져오기 때문입니다.
- 따라서 selenium의 webdriver를 이용하여 크롤링 하는 것을 추천드립니다.
- 추가적으로 많이 사용하는 기능 중의 하나가
xpath를 이용하여 원하는 버튼을 클릭하는 것입니다.
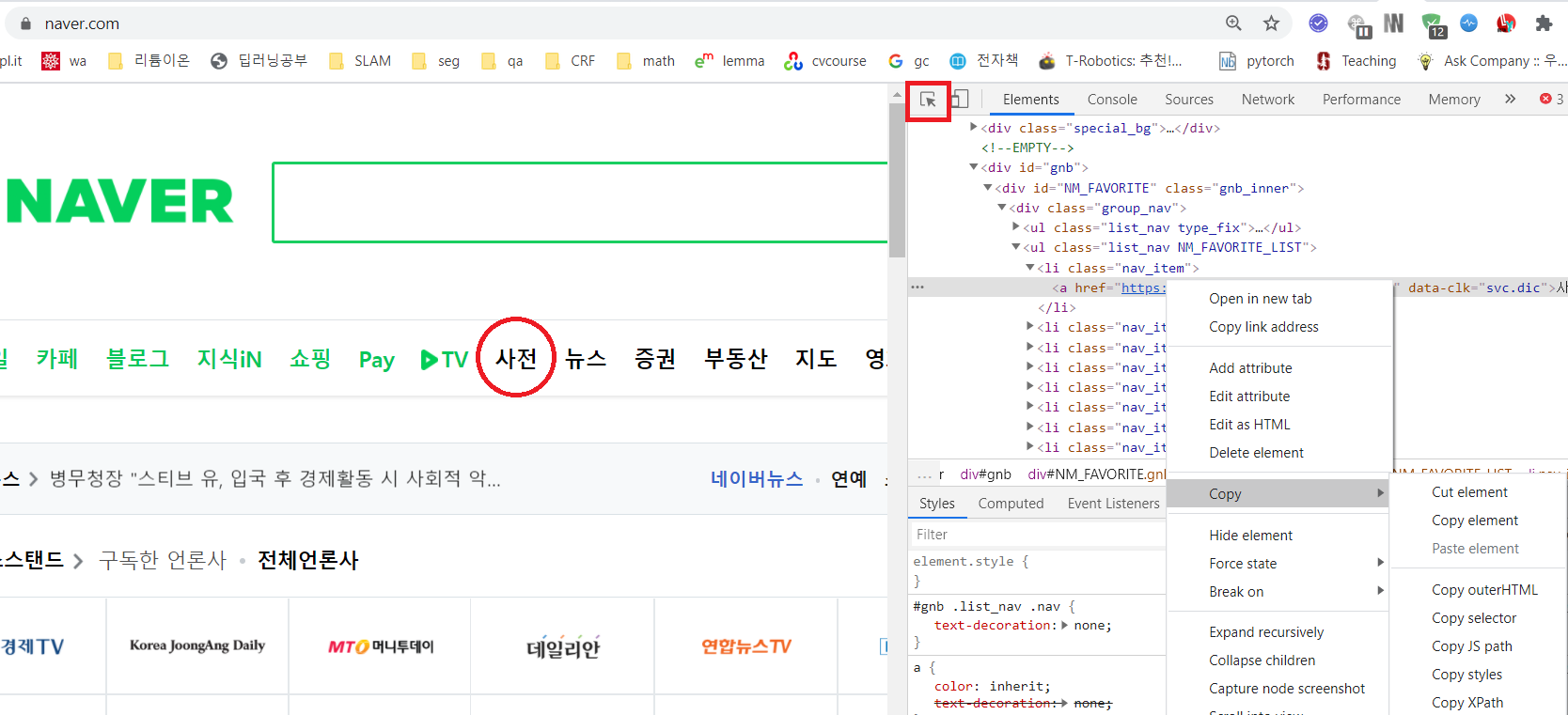
- 위 그림과 같이 오른쪽에 검사 화면을 띄우려면 브라우저에서
F12를 누르면 됩니다. - 오른쪽 상단의 빨간색 박스에 해당하는 키를 누른 다음에 클릭하고 싶은 버튼을 누릅니다.
- 그러면 그 버튼에 해당하는 html 코드에 음영으로 색칠해 집니다.
- 코드에 마우스 오른쪽 클릭을 하여 Copy → Copy XPath를 클릭하면 다음과 같은 코드가 복사 됩니다.
//*[@id="NM_FAVORITE"]/div[1]/ul[2]/li[1]/a
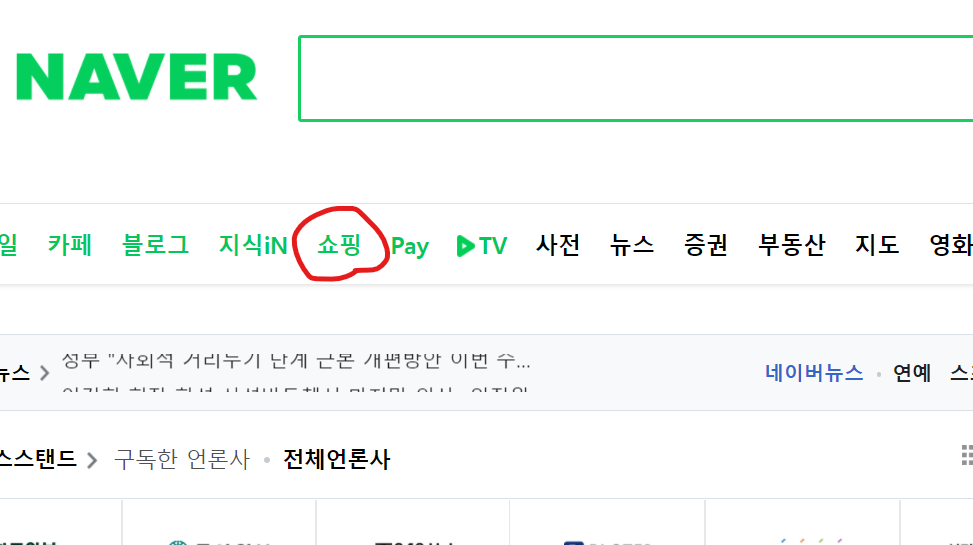
- 이 XPath 코드를 이용하여 원하는 위치를 클릭할 수 있습니다.
- 아래 xpath는 naver의 상단 탭의 쇼핑 버튼에 해당합니다.
from selenium import webdriver
url = "https://naver.com"
driver = webdriver.Chrome(executable_path=r'C:\chromedriver_win32\chromedriver.exe')
driver.get(url)
xpath = '`//*[@id="NM_FAVORITE"]/div[1]/ul[2]/li[1]/a`
driver.find_element_by_xpath(xpath).click()
- xpath는 해당 url에서만 유효하므로 driver.get(url)을 이용하여 그 위치로 이동한 다음에 위 코드와 같이 클릭을 해야 정상적으로 동작합니다.
- selenium 또는 requests로 읽어온 html을 분석할 때에는 beautifulsoup을 사용합니다.
- beautifulsoup을 이용하면 사용자가 읽을 수 있도록 쉽게 parsing을 해줍니다. 다음 코드와 같습니다.
import bs4
from bs4 import BeautifulSoup
from selenium import webdriver
url = "https://naver.com"
driver = webdriver.Chrome(executable_path=r'C:\chromedriver_win32\chromedriver.exe')
driver.get(url)
html = driver.page_source
soup = BeautifulSoup(html, 'lxml')
- 이 때, soup 변수에 저장된 결과는 현재 웹 드라이버에서 보이는 페이지의 html을 파싱한 결과입니다.
- 이 데이터에서 원하는 정보만을 가져 오기 위해서는
태그와속성을 이용하여 필요한 정보를 접근해야 합니다.
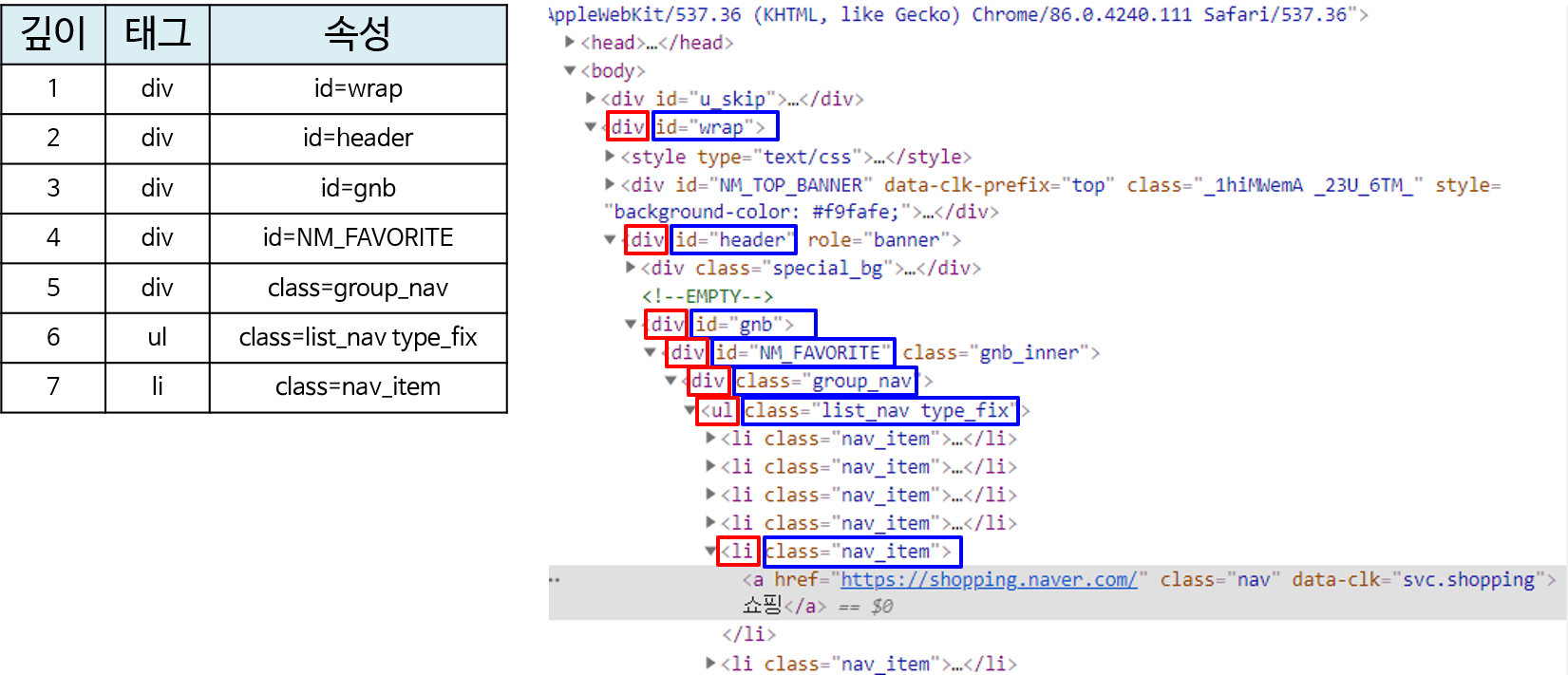
- 위 그림에서 보면 빨간색 글씨가
태그이고 파란색 글씨가속성입니다. - soup을 이용하여 어떤 태그와 속성에 대한 정보를 찾으려면
.find또는.find_all함수를 사용하여 찾을 수 있습니다. - 예를 들어
soup.find('div', {'id':'wrap'})과 같이 함수를 사용하면 전체 html에서 가장 첫번째 태그, 속성 쌍의 내부의 html만 가져오게 됩니다. - 이와 같은 원리로 필요한 영역의 태그, 속성 값을 이용하여 계속 하위 영역으로 접근할 수 있습니다.
soup.find('div', {'id':'wrap'}).find('div', {'id':'header'}).find('div', {'id':'gnb'}).find
('div', {'id':'NM_FAVORITE'}).find('div', {'class':'group_nav'}).find('ul', {'class':'list_nav type_fix'}).find_all('li', {'class':'nav_item'})
# [<li class="nav_item">
# <a class="nav" data-clk="svc.mail" href="https://mail.naver.com/"><i class="ico_mail"></i>메일</a>
# </li>,
# <li class="nav_item"><a class="nav" data-clk="svc.cafe" href="https://section.cafe.naver.com/">카페<
# /a></li>,
# <li class="nav_item"><a class="nav" data-clk="svc.blog" href="https://section.blog.naver.com/">블로
# 그</a></li>,
# <li class="nav_item"><a class="nav" data-clk="svc.kin" href="https://kin.naver.com/">지식iN</a></li>
# ,
# <li class="nav_item"><a class="nav" data-clk="svc.shopping" href="https://shopping.naver.com/">쇼핑<
# /a></li>,
# <li class="nav_item"><a class="nav" data-clk="svc.pay" href="https://order.pay.naver.com/home">Pay</
# a></li>,
# <li class="nav_item">
# <a class="nav" data-clk="svc.tvcast" href="https://tv.naver.com/"><i class="ico_tv"></i>TV</a>
# </li>]
- 위 코드와 같이
.find함수를 이용하여 태그와 속성값을 접근하여 계속 하위 영역으로 접근할 수 있습니다. - 경우에 따라서 모든 위치의 태그와 속성값을 다 사용할 필요는 없으나 안전하게 접근하기 위해서 차례 차례 접근하는 것을 추천드립니다.
- 위 코드에서 주목할 점은 마지막에 사용한
.find_all함수입니다.
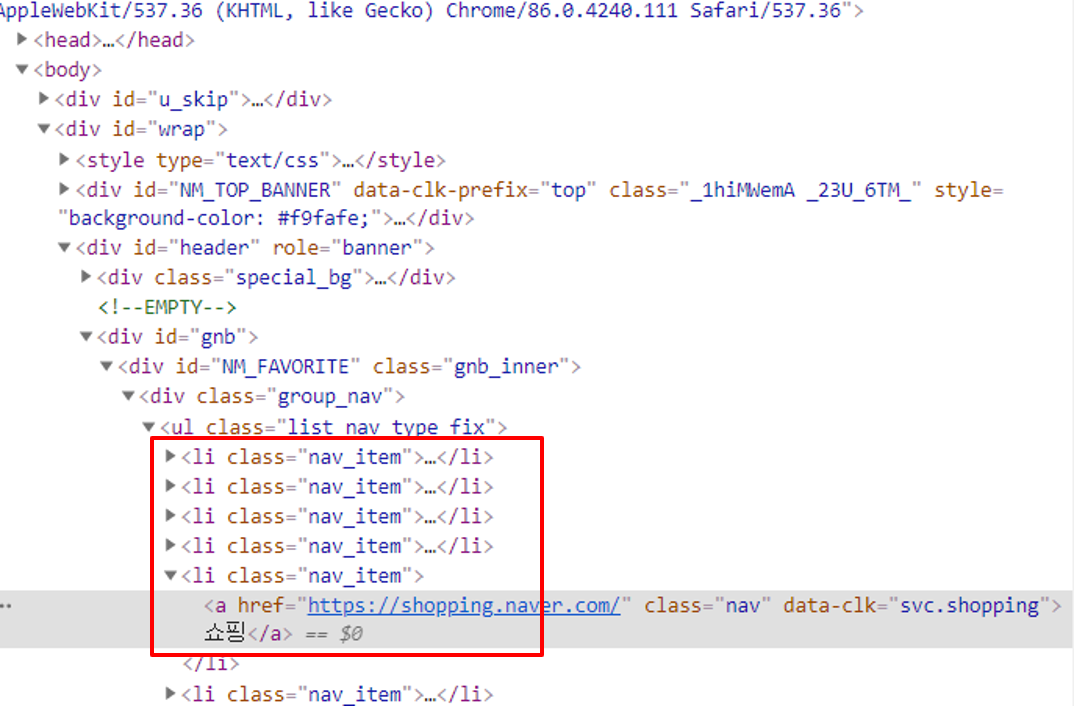
- 빨간색 박스 영역을 보면 같은 태그와 속성값이 나열되어 있습니다. 이 경우
.find함수를 사용하면 가장 첫번째 태그와 속성값만 접근하게 됩니다. - 따라서
.find_all함수를 통하여 원하는 태그, 속성값을 전체 조회하고 필요한 영역을 접근해야 합니다. 다음 코드를 참조하시기 바랍니다.
soup.find('div', {'id':'wrap'}).find('div', {'id':'header'}).find('div', {'id':'gnb'}).find
('div', {'id':'NM_FAVORITE'}).find('div', {'class':'group_nav'}).find('ul', {'class':'list_nav type_fix'}).find_all('li', {'class':'nav_item'})[4].text
# '쇼핑'
- 마지막으로
a태그와href속성값이 있는 영역 까지 접근하였을 때,.text값을 읽어오면 원하는 텍스트를 가져올 수 있습니다.
- 여기까지가 requests, selenium, beautifulsoup을 이용한 가장 기본적인 텍스트 크롤링 방법이었습니다.
- 더 나아가 어떤 기능들이 있는 지 추가적으로 알아보도록 하겠습니다.