
Pandas 기본 문법 및 코드 snippets
2019, Jan 06
- 이 글에서는
Pandas를 사용하면서 필요하다고 느끼는Pandas 기본 문법 및 코드들을 정리해 보겠습니다.
목차
-
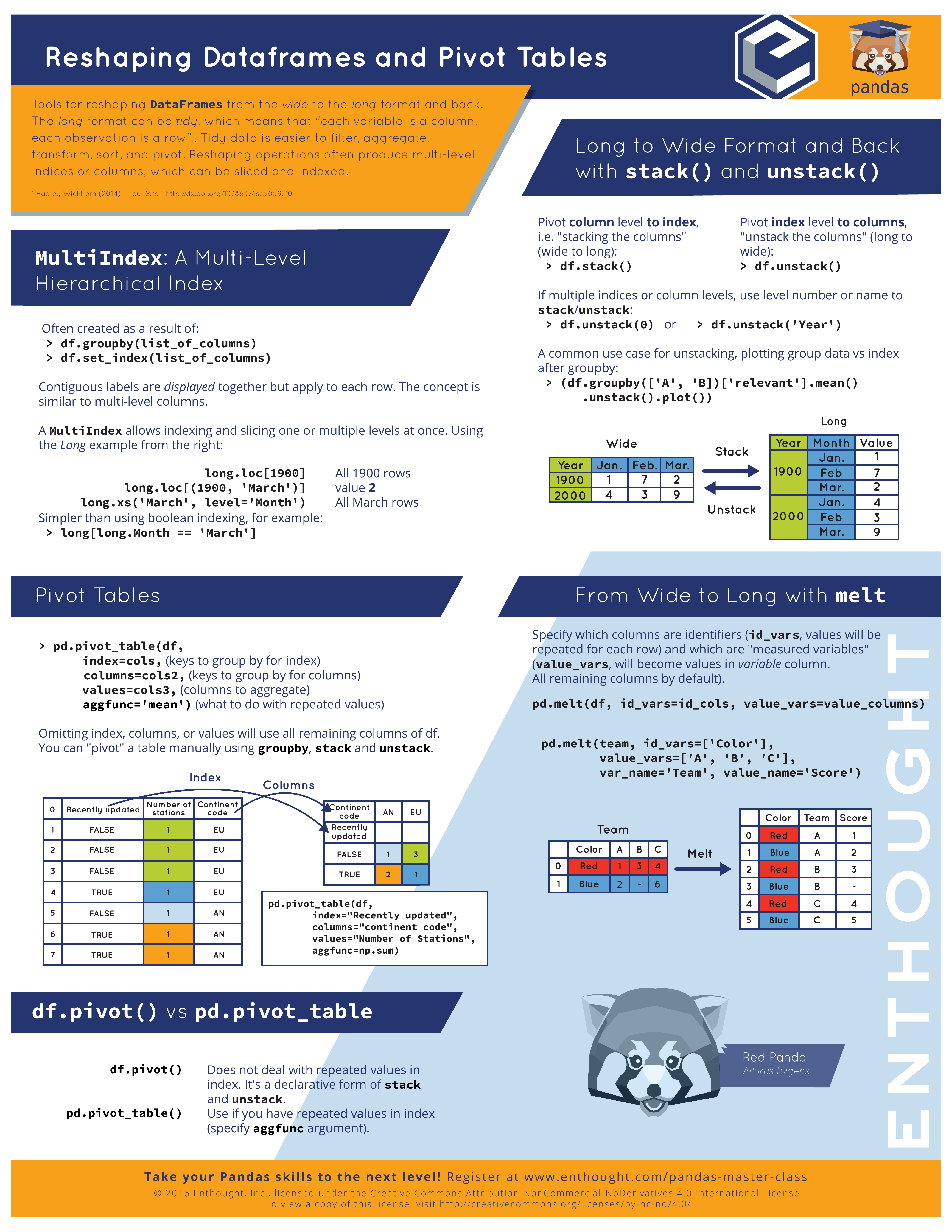
Pandas Cheatsheet 모음
-
Pandas GUI 사용 방법
-
DataFrame에 column 추가
-
DataFrame에 행 단위로 데이터 추가하기
-
pd.read_csv(excel) 함수를 통하여 파일 읽을 때
-
df.to_csv(excel) 함수를 통하여 파일 쓸 때
-
column 명 확인
-
category 데이터 → Ordinal 데이터로 변경
-
category 데이터 → one hot 데이터로 변경
-
Pandas에서 결측값 제거하기
-
column의 인덱스 번호를 이용하여 열 선택
-
concat 함수를 이용한 DataFrame 합치기
Pandas Cheatsheet 모음
- https://blog.finxter.com/pandas-cheat-sheets/#3_The_Excel_Users_Cheat_Sheet
- https://pandas.pydata.org/Pandas_Cheat_Sheet.pdf
- https://www.dataquest.io/blog/pandas-cheat-sheet/
- The Most Beautiful Cheat Sheet
- The Most Compact Cheat Sheet
- The Best Machine Learning Cheat Sheet
- The Best Statistics Cheat Sheet










Pandas GUI 사용 방법
- 관련 페이지 : https://pypi.org/project/pandasgui/
- 설치 방법 :
pip install pandasgui - 사용 방법 : pandas gui로 타이타닉 데이터 분석
- 동영상 설명 : https://youtu.be/F8mSlETrcl8
- pandas gui를 사용하는 방법은 아래와 같습니다.
# 1개의 DataFrame을 pandas gui로 열기
import pandas as pd
from pandasgui import show
df = pd.DataFrame(([[1, 2, 3], [4, 5, 6], [7, 8, 9]]), columns=['a', 'b', 'c'])
show(df)
# n개의 DataFrame을 pandas gui로 열기
from pandasgui import show
from pandasgui.datasets import pokemon, titanic, all_datasets
show(**all_datasets)
- pandas를 이용하여 데이터 분석을 할 때, 커스텀한 목적이 있지 않고 기본적인 데이터의 분포를 살펴보려고 한다면
pandas gui를 통하여 시각적으로 분석하는 것이 굉장히 효율적입니다. - ①
DataFrame 탭: 가장 기본적인 기능으로DataFrame을 엑셀 화면과 같이 볼 수 있고, 편집까지 할 수 있는 기능을 제공합니다. - ②
Filters 탭:DataFrame에Filter를 적용할 수 있는 기능이 제공됩니다. Filter는 숫자의 경우 부등호를 이용하여 필터를 할 수 있고 문자열의 경우==,!=등과 같이 문자열을 비교하는 기호를 통하여 비교할 수 있습니다. 이 때, 비교를 해야하는 기준은column 이름입니다. 예를 들어 column 이름이age라면age >= 20과 같이 사용할 수 있습니다. 또는sex == 'mail'과 같이 문자열 비교도 할 수 있습니다. - ③
Statistics 탭: 각 column을 기준으로Type,Count,N Unique,Mean,StdDev,Min,Max값에 대한 정리를 합니다. - ④
Grapher 탭: 파이썬에서 사용하는 보편적인 그래프를 쉽게 사용할 수 있도록 기능을 제공합니다. - ⑤
Reshaper 탭: 테이블에서 주로 사용하는Pivot과Melt기능을 제공합니다.
DataFrame에 column 추가
- DataFrame을 생성할 때, column을 추가하려면 다음과 같이 DataFrame 생성 시 옵션을 넣을 수 있습니다.
columns = ['name', 'age', 'address', 'phone']
data_frame = pd.DataFrame(columns = columns)
DataFrame에 행 단위로 데이터 추가하기
- DataFrame에 한 행씩 데이터를 차곡 차곡 쌓아가고 싶으면 아래 코드와 같이
.loc[i]를 이용하여 한 행씩 접근하고 column의 갯수 만큼의 값을 가지는 리스트를df.loc[i]에 입력해 주면 됩니다.
import pandas as pd
from numpy.random import randint
df = pd.DataFrame(columns=['lib', 'qty1', 'qty2'])
for i in range(5):
df.loc[i] = ['name' + str(i)] + list(randint(10, size=2))
pd.read_csv(excel) 함수를 통하여 파일 읽을 때
- ① 파일을 읽을 때, 첫 열의 인덱스(0, 1, 2, …)를 만들고 싶지 않다면 다음 옵션을 준다.
index_col = False
- ② 파일을 읽을 때, 첫 행에 헤더를 만들고 싶지 않다면 다음 옵션을 줍니다.
header = None
- ③ 파일을 읽을 때, 구분자의 기준을 주고 싶다면 다음 옵션을 줍니다.
sep = ',', 특정 문자를 입력하면 됩니다.
df.to_csv(excel) 함수를 통하여 파일 쓸 때
df.to_csv("파일명", option)형태로 정하며 많이 사용하는 option은 아래와 같습니다.- ① 파일을 쓸 때, 첫 열의 인덱스(0, 1, 2, …)를 만들고 싶지 않다면 다음 옵션을 준다.
index = False
- ② 파일을 쓸 때, 첫 행에 헤더를 만들고 싶지 않다면 다음 옵션을 줍니다.
header = None
- ③ 파일을 쓸 때, 구분자의 기준을 주고 싶다면 다음 옵션을 줍니다.
sep = ',', 특정 문자를 입력하면 됩니다.
column 명 확인
- DataFrame에서 column의 이름을 확인할 때, 다음과 같습니다.
df = pd.read_csv("file.csv")
column_list = list(df.columns)
column_list = df.columns.to_list()
column_list = df.columns.values.tolist()
category 데이터 → Ordinal 데이터로 변경
- 이번 글에서는 category 형태의 데이터들을 숫자 형태로 바꾸는 간단한 방법에 대하여 알아보도록 하겠습니다.
- 이 작업은 데이터 분석을 할 때 상당히 중요하기 때문에 자주 사용됩니다. 왜냐하면 데이터 분석 시 카테고리 형태의 데이터는 수치화 할 수 없기 때문입니다. 다음 예제를 살펴보도록 하겠습니다.
import pandas as pd
df = pd.DataFrame({'Score': [
'Low', 'Low', 'Medium', 'Medium', 'High'
]})
print(df)
# Score
# 0 Low
# 1 Low
# 2 Medium
# 3 Medium
# 4 High
- 위 예제에서 Low, Medium, High과 같은 문자열을 그대로 데이터 분석을 하기는 어렵습니다. 따라서 다음과 같이 Low = 1, Medium = 2, High = 3으로 매핑시켜 보겠습니다.
scale_mapper = {'Low':1, 'Medium':2, 'High':3}
df['Scale'] = df['Score'].replace(scale_mapper)
print(df)
# Score Scale
# 0 Low 1
# 1 Low 1
# 2 Medium 2
# 3 Medium 2
# 4 High 3
- 위 코드와 같이 새로운 축에 Scale이 생긴것을 확인할 수 있습니다. 물론 Low, Medium, High이 필요없기 때문에 Score에 그대로 대입할 수 있습니다.
scale_mapper = {'Low':1, 'Medium':2, 'High':3}
df['Score'] = df['Score'].replace(scale_mapper)
print(df)
# Score
# 0 1
# 1 1
# 2 2
# 3 2
# 4 3
- 하지만 위와 같은 방법에서는 mapping 값을 직접 입력해주어야 하는 불편함이 있습니다. 따라서 category 별로 자동적으로 값이 부여되도록 하는 방법을 알아보겠습니다.
- 아래 코드와 같이
pd.factorize를 이용하면 자동으로 카테고리 별로 번호가 부여됩니다.
df['Score'] = pd.factorize(df['Score'])[0]
print(df)
# Score
# 0 0
# 1 0
# 2 1
# 3 1
# 4 2
category 데이터 → one hot 데이터로 변경
- 데이터 중 category 형태의 데이터는 (ex. 국가, 성별) 대소 관계가 있지 않으므로 데이터 전처리 할 때 0, 1, 2, …형태로 숫자로 매핑하지 않고 one-hot 형태로 매핑해야 합니다.
- 특정 column을 one-hot 형태로 만들어 줄 때,
pd.get_dummies()함수를 사용합니다. 사용 방법은pd.get_dummies(df, columns=[컬럼명1, 컬럼명2, ...])형태로 사용하면 됩니다.
import pandas as pd
df = pd.DataFrame(columns=['name', 'nation', 'age', 'sex'])
df.loc[0] = ["A", "Korea", 10, "male"]
df.loc[1] = ["B", "Japan", 20, "female"]
df.loc[2] = ["C", "China", 10, "male"]
print(df)
# name nation age sex
# 0 A Korea 10 male
# 1 B Japan 20 female
# 2 C China 10 male
df_one_hot = pd.get_dummies(df, columns=['nation', 'sex'])
print(df_one_hot)
# name age nation_China nation_Japan nation_Korea sex_female sex_male
# 0 A 10 0 0 1 0 1
# 1 B 20 0 1 0 1 0
# 2 C 10 1 0 0 0 1
- 위 코드를 보면 one-hot으로 변경된 column은 기존의 column 이름을 접두사로 가지고 각 값을 접미사로 가지는 형태의 열을 가지게 됩니다.
- 따라서 데이터 전처리를 직접하면서 필요한 column만 입력하여 위 예제와 같이 one-hot 형태로 만들 수 있습니다.
- 일반적으로 어떤 값이 str 타입이면 category 데이터일 가능성이 매우 높습니다. 따라서 1행의 값을 조사하여 1행의 각 열의 값이 str 타입이면 그 열만 one-hot으로 바꾸는 방법을 사용하면 자동화 할 수 있습니다. 코드는 다음과 같습니다.
# get candidate of one-hot columns to be applied. except_columns will be excluded from candidates.
of one-hot columns to be applied. except_columns will be excluded from candidates.
def GetOneHotColumns(df, except_columns=[]):
column_names = df.columns.to_list()
str_columns = []
for value, column_name in zip(df.loc[0], column_names):
if isinstance(value, str):
str_columns.append(column_name)
set_str_columns = set(str_columns)
set_except_columns = set(except_columns)
one_hot_columns = list(set_str_columns.difference(set_except_columns))
return one_hot_columns
ont_hot_columns = GetOneHotColumns(df, except_columns=['name'])
print(ont_hot_column)
# ['sex', 'nation']
df_one_hot = pd.get_dummies(df, columns=ont_hot_columns)
print(df_one_hot)
# name age sex_female sex_male nation_China nation_Japan nation_Korea
# 0 A 10 0 1 0 0 1
# 1 B 20 1 0 0 1 0
# 2 C 10 0 1 1 0 0
Pandas에서 결측값 제거하기
- 먼저 아래와 같이 행렬을 만들어 줍니다.
X = np.array([[1, 2],
[6, 3],
[8, 4],
[9, 5],
[np.nan, 4]])
- Numpy로 만든 행렬을 Pandas 타입으로 바꿔 줍니다.
df.dropna()를 통하여 결측값을 제거합니다.
df = pd.DataFrame(X, columns=['feature_1', 'feature_2'])
# 결측값을 제거해 줍니다.
df.dropna()
- 임의의 DataFrame을
NaN값을 포함하여 만든 후 NaN의 값이 있는 좌표만 따로 반환 받을 수 있습니다.
X = np.array([[1, 2],
[6, 3],
[8, 4],
[9, 5],
[np.nan, 4]])
df = pd.DataFrame(X)
print(np.asarray(df.isnull()).nonzero() )
# (array([4], dtype=int64), array([0], dtype=int64))
- 이 성질을 이용하여 결측값에 특정값, 예를 들어 0을 입력할 수 있습니다.
X = np.array([[1, 2],
[6, 3],
[8, 4],
[9, 5],
[np.nan, 4]])
df = pd.DataFrame(X)
df[df.isnull()] = 0
column의 인덱스 번호를 이용하여 열 선택
- 참조 : https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html
- 참조 : https://stackoverflow.com/questions/17193850/how-to-get-column-by-number-in-pandas
- DataFrame에서 특정 열의 인덱스를 기준으로 열을 선택하는 방법은 다음과 같습니다. (물론 인덱스는 0부터 시작합니다.)
selected_columns = [1, 3, 5]
df.iloc[:, selected_columns]
- 위 코드를 통하여 선택된 열인 1, 3, 5 열만 DataFrame에서 선택되는 것을 확인할 수 있습니다.
concat 함수를 이용한 DataFrame 합치기
- 참조 : https://pandas.pydata.org/pandas-docs/stable/user_guide/merging.html
- DataFrame을 합칠 때, 행 방향과 열 방향으로 합칠 수 있습니다. 다른 NumPy와 같은 라이브러리와 같이
concat함수가 존재하며 행 방향과 열 방향으로 합칠 수 있습니다.
# 행 방향 (아래로) DataFrame 합치기
df3 = pd.concat([df1, df2], axis = 0)
# 열 방향 (옆으로) DataFrame 합치기
df3 = pd.concat([df1, df2], axis = 1)