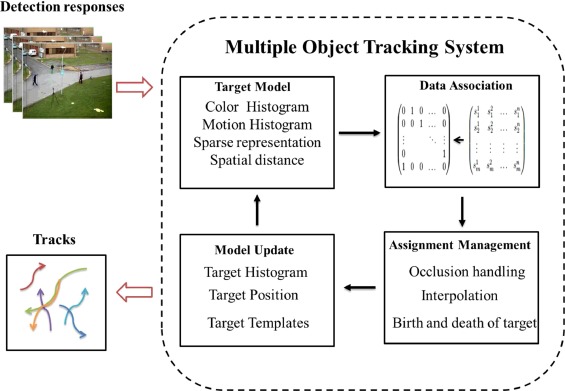
VOT(Visual Object Tracking)와 MOT(Multiple Object Tracking)
2019, Dec 30
- 이번 글에서는 Tracking의 종류에 대하여 간략하게 다루어 볼 예정입니다.
- 특히 Tracking의 두 종류인 Visual Object Tracking과 Multiple Object Tracking이 무엇인지 다루어 보겠습니다.
- 엄청 자세한 Tracking의 방법론 제 블로그의 다른 글들을 살펴보시면 감사하겠습니다. (Detection + 칼만 필터를 사용해 보시면 됩니다.)
목차
-
VOT(Visual Object Tracking) 이란
-
VOT의 예
-
MOT(Multiple Object Tracking) 이란
-
MOT의 예
Visual Object Tracking 이란
- 이번 글의 첫번째 주제인 VOT(Visual Object Tracking)에 대하여 알아보도록 하겠습니다.

- Object Tracking이라는 것은 비디오 영상에서 시간에 따라 움직이는 어떤 물체 또는 여러개의 물체의 위치를 찾는 과정을 말합니다.
- Object Tracking에서의 출력은 Tracker가 되는데 Tracker는 각 비디오 frame에서의 객체 정보를 가지고 있습니다.
- 그러면
VOT가 다루는 문제는 단일 객체(Single Object)를 다루는 문제에 대해서 설명드리겠습니다. VOT는 먼저 단일 객체 (Single Object)를 대상으로 이루어지는 Tracking 문제 입니다.- 여기서 중요한 것은
VOT에서 주어지는 정보는 첫 번째 프레임에서의 객체의 위치 입니다. 이 정보 이외에는 다른 정보가 없습니다. - 즉, 객체에 대한 자세한 정보는 모르지만 첫 프레임에서 객체가 어디에 있는지 알면 비디오에서 계속 그 객체를 추적해 나아가야 하는 문제입니다.
- 그리고 오직 사용 할 수 있는 정보는 현재 프레임과 이전 프레임 2가지 입니다.

- VOT 문제를 풀 때 고려해야 할 것들을 보면 먼저 가장 중요한 것 중에 하나인 계산 속도가 있습니다.
- 그리고 객체의 형상이나 비디오의 방향, 빛 등이 변할 수 있기 때문에 그런 것들에 영향을 받지 않고 성능이 나올 수 있도록 해야 합니다.
- 또한 객체와 유사한 것들이 다수 출현하였을 때, 예를 들어 객체가 사람인데 사람들 사이에 그 객체가 들어가게 된다면, Occlusion 문제 등이 발생할 수 있고 또는 다른 유사한 객체(사람)를 Tracking 하는 문제가 발생할 수 있습니다.
- VOT 문제를 푸는 대회도 있습니다. (http://votchallenge.net) 여기에 다양한 데이터 셋과 정보들이 있으니 참조하시면 도움이 됩니다.
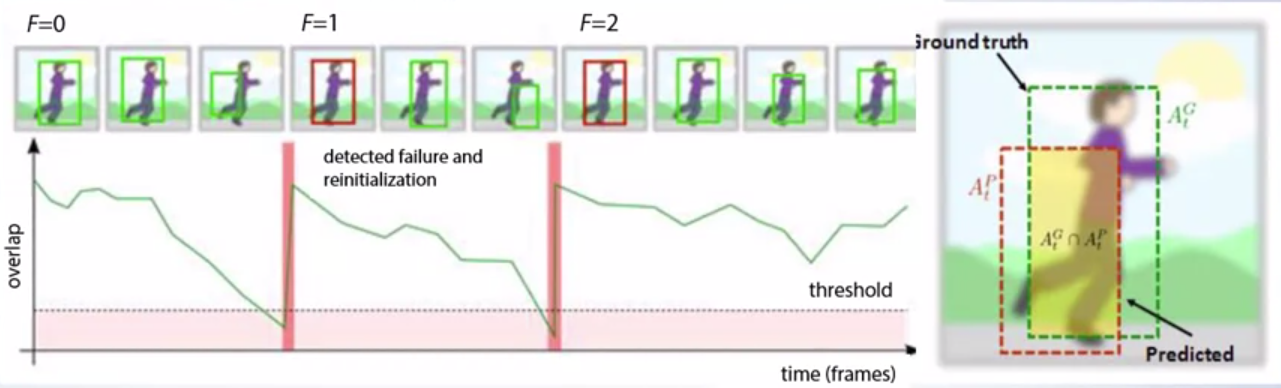
- VOT의 성능을 평가하는 방법은
Accuracy,Robustness가 있습니다. - 이 측정 방법의 기본이 되는 것은 위 그림에서 보여주는
IoU입니다. GT 대비해서 얼만큼 Ttacking이 겹치는 지가 기준이 됩니다. Accuracy는 비디오 전체에서 얼만큼IoU가 threshold(얼마나 정확하게 tracking 했는지 나타내는 값 ex. 0.8) 보다 높은지를 나타냅니다.Robustness는 비디오 전체에서IoU가 threshold(얼마나 부정확하게 tracking 했는지 나타내는 값 ex. 0.2) 보다 낮게 계산되어 위치값을 다시 주어야 하는 경우를 카운트한 값을 나타냅니다. 위 그림에서는 2번 발생하였습니다.
Visual Object Tracking의 예
MOT(Multiple Object Tracking) 이란

- 이번에는 MOT(Multiple Object Tracking)에 대하여 알아보도록 하겠습니다.

- 앞에서 다룬 VOT와 비교하여 MOT는 어떻게 다른지 알아보겠습니다.
- MOT는 말 그대로 여러개의 객체를 트래킹 하는 것을 말합니다.
- MOT의 목적은 크게 2가지가 있습니다. 첫번째로
여러 객체를 동시에 처리할 수 있어야 한다는 것과 두번째로 단기간의 시간이 아닌장기간(long-term) 트래킹이 가능해야 한다는 것입니다. - 물론 트래킹을 하기 위해서는 센서값인 디텍션 좌표가 필요합니다.
- 디텍션을 이용한 트래킹에는 크게 2가지 방법이 있습니다. 첫번째가 DBT(Detection Based Tracking)이고 두번째는 DFT(Detection Free Tracking) 입니다.
- DBT는 일반적으로 감지해야할 객체가 정의가 되어 있고 그 객체에 대한 좌표 값을 매 프레임 마다 얻는 것을 말합니다.
- 반면 DFT는 시작 프레임의 좌표 또는 바운딩 박스의 좌표를 가지고 객체를 트래킹 하는 방법을 말합니다. 즉, 시작 프레임에서 특정 객체에 바운딩 박스를 주고 그 객체만을 계속 트래킹 하는 것으로 이해할 수 있습니다.
- 이번 글에서는
DBT를 기준으로 설명해 보겠습니다. - 즉, 트래킹 해야 할 대상은 영상 속에서 디텍션 알고리즘에 의해 검출된 좌표 또는 바운딩 박스들이 됩니다.
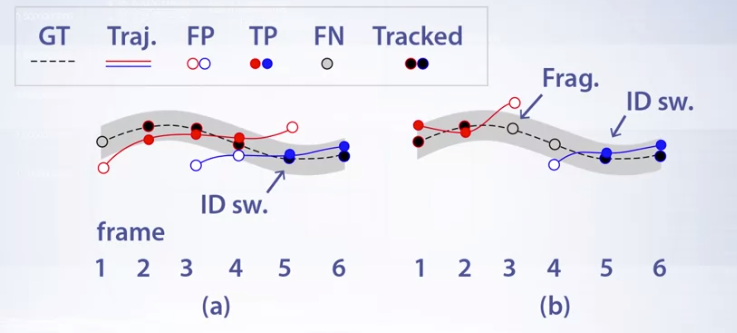
- 트래킹에서 발생하는 에러에는 대표적으로 2가지가 있습니다. 첫번째로
ID Switch문제가 있고 두번째로Fragmentation문제가 있습니다. ID Switch문제는 위 그림과 같이 Ground Truth 하나에 2개의 trajectory(자취)가 생기는 것을 말합니다.- 여기서 Ground Truth는 검은색 점들의 trajectory로 정답에 해당합니다.
- 처음에 빨간색 trajectory가 GT에 근사하게 표시되다가 파란색 trajectory로 바뀌는 오류를 범하였습니다.
- 이것은 트래킹 알고리즘에 새로운 객체로 인식해서 새로운 trajectory로 형성한 것입니다. 그래서 객체의 ID가 변화는
ID Switch문제가 발생한 것입니다.
- 두번째는
Fragmentation문제입니다.- 이 오류는 센서값인 디텍션 정보가 중간에 끊어졌기 때문에 발생하는 것입니다. 즉, 실제는 있어야 할 trajectory가 일정 시간 형성되지 않아 False Negative 가 발생한 것입니다.
- 트래킹 알고리즘이 fragmentation 보완을 잘 해줘서 trajectory가 Ground Truth를 잘 쫓아가도록 해주어야 합니다. 그렇지 않으면 위의 오른쪽 그림과 같이 trajectory가 끊겼다가 새로 시작하는 지점에서 새로운 객체로 인지하여 또다시
ID Switch가 발생하게 됩니다.
Multiple Object Tracking의 예
- 그러면 MOT를 어떻게 접근하면 될 지 간략하게 다루어 보도록 하겠습니다.
- 먼저 Tracking은 2가지 단계를 거쳐야 합니다. 첫번째는 각 프레임 별로 Object Detection을 하는 것이고 두번째는 Object Detection 결과를 Tracking과 연관시키는 작업입니다.

- 위 그림처럼 성능이 낮은 Detector는 실제 객체인 사람이 있음에도 불구하고 Detection을 하지 못했으므로 False Negative 가 증가하게 되어 Recall 성능이 낮아지게 됩니다.
- 좋은 Tracker는 프레임 간의 정보를 이용하여 Detector의 부족한 점들을 보완해주어야 하고 결과적으로 False Negative 또는 False Positive에 대하여 원하는 방법으로 성능을 높여주어야 합니다.
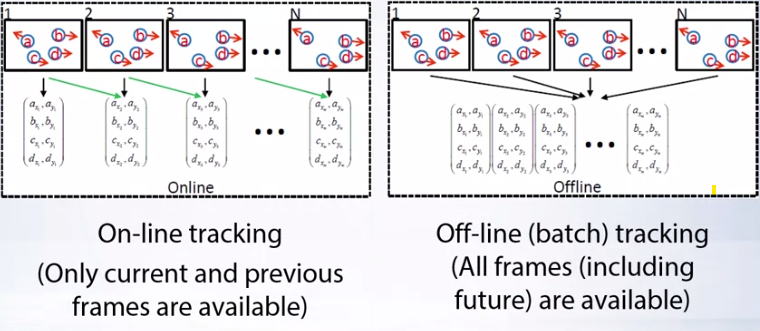
- Detector의 성능이 확보 된다면 이제 Tracking 처리를 할 Tracker를 만들어야 합니다.
- Tracking을 하는 방법에는 위와 같이
online방법과offline방법이 있습니다. onlinetracking은 현재 프레임과 바로 직전의 프레임을 이용하여 tracking을 하는 것이고offlinetracking은 실시간이 아닌 전체 비디오를 입력 받고 모든 프레임을 사용하여 tracking 하는 것입니다. 즉, 과거 frame 또는 미래 frame 모두를 이용하는 것입니다.- 실용적으로 필요한 것은
onlinetracking이 대부분 입니다. 그 많은 비디오를 저장하는데에도 한계가 있고 tracking은 실시간으로 처리하는 데 목적이 있기 때문입니다. 그래서 이 글에서는onlinetracking을 위주로 다루어 보겠습니다.
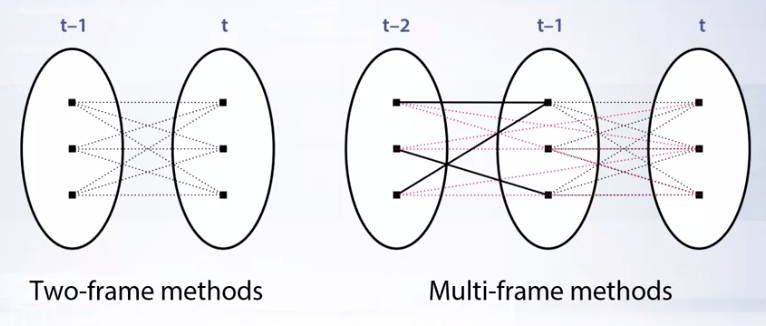
- tracking의 핵심은 현재 프레임에서 detection한 좌표들이 있을 때, 이 좌표들과 직전 프레임에서 detection한 좌표들을 연결하는 것에 있습니다.
- 위 그림과 같이 프레임 간에 좌표들을 연결할 때, 몇 개의 프레임을 사용할 지는 알고리즘 설계 단계에서 선택해야 합니다.
- 이 과정은 바로 앞에서 다룬
online과offlinetracking을 고려하는것과 유사합니다. 이 글에서 다루어 볼 것은onlinetracking 조건에서two-frame method입니다. 왜냐하면 가장 간단한 방법이면서 메모리 및 계산량에 효율적이고 무엇보다onlinetracking에 가장 적합하기 때문입니다.
- 프레임 간의 detection 정보들을 연결시키려면 detection 정보 사이의 유사성등을 파악해야 합니다.
- 시각적인 유사성이나 동작 유사성 등을 이용할 수 있으며 위와 같은 예들을 결합해서 사용할 수도 있습니다.
- 간단한 방법 몇가지를 소개해 보겠습니다.
- 첫번째로 아주 간단한 방법 중 하나인
IoU, Intersection over Union을 이용하여 tracking 하는 방법입니다.- 소위
IoU Tracker라고 불리는 방법이지요.
- 소위
- 이전 프레임과 현재 프레임의 detection의 영역(예를 들어 bounding box)들을 비교합니다. 이 때 비교하는 방법으로
IoU를 사용하여 영역이 가장 많이 겹치는 쌍이 결합될 수 있습니다.- 예를 들어, t-1 프레임의 b1 bounding box와 t 프레임의 b2 bounding box의
IoU가 0.9이고 이것은 b1 bounding box와 t 프레임의 다른 bounding box와IoU를 비교하였을 때 보다 큰 값이라고 하면 b1과 b2가 결합이 되어야 한다는 뜻입니다.
- 예를 들어, t-1 프레임의 b1 bounding box와 t 프레임의 b2 bounding box의
- 먼저 이 tracking 방법의 장점은 연산량이 작아서 빠르게 수행할 수 있다는 점입니다. 아주 간단하기 때문이지요.
- 특히, 객체의 이동속도가 엄청나게 빠르지 않다면 꽤나 성능이 좋습니다. MOT challenge 2017에서 좋은 성적을 거두었습니다.
- 알고리즘을 정리하면 다음과 같습니다.

- 각 track에 대하여 가장 높은
IoU를 가지는 detection을 선택합니다. 이 IoU가 임계값보다 크면 트랙에 추가하고 연결되지 않은 detection 목록에서 제거합니다. - IoU가 임계값 보다 낮은 track은 track을 끝냅니다. 만약 이 track의 길이가 너무 짧다면 False Positive로 간주할 수 있으므로 제거해도 된다고 판단합니다.
- 이 알고리즘에 대하여 다 자세히 알고 싶으면 다음 링크를 참조하시기 바랍니다.
- 링크 : https://motchallenge.net/tracker/IOU17
- 논문 : http://elvera.nue.tu-berlin.de/files/1517Bochinski2017.pdf
- 좀 더 정교한 알고리즘에 대하여 알아보도록 하겠습니다.
SORT라고 불리는 이 tracking 알고리즘의 이름은 Simple Online and Realtime Tracking입니다.- 제 개인적으로도 많이 사용하는 알고리즘 입니다. 왜냐하면 성능이 꽤 괜찮고 빠르기 때문이지요.
- SORT는 칼만 필터와 헝가리안 알고리즘을 이용합니다.
- 1) 칼만 필터를 이용하여 이전 프레임 까지의 tracking 정보를 칼말 prediction을 합니다.
- 2) 현재 프레임의 객체들의 정보를 detection합니다.
- 3) 칼만 prediction한 값들과 detection 값들을 헝가리안 알고리즘을 이용하여 매칭합니다.
- 거리 값들을 이용하여 헝가리안 알고리즘을 사용하면 매칭된 prediction과 detection 사이의 거리의 총합이 최소가 되는 매칭 쌍들을 찾을 수 있습니다.
- 즉, 각 점들 하나 하나가 가장 가까운 점을 찾는다기 보다는 전체적으로 봤을 때 가장 거리가 가깝도록 최적해를 찾는 것이라고 봐야 합니다.
SORT에 대한 방법론은 다른 글에서 좀 더 자세하게 다루어 보도록 하겠습니다.

- 앞에서 다룬
IoU Tracker와SORT모두 간단하지만 생각보다 성능이 괜찮아서onlinetracking에서 사용할 수 있습니다. - False Positive 이외에는
SORT가 성능이 우세하고 FP에만IoU Tracker가 성능이 우세합니다. - 특히, 가장 민간한 오류인 False Negative에서
SORT가 더 우세한 이유로 인하여 저는SORT를 사용하는 것을 추천드립니다.
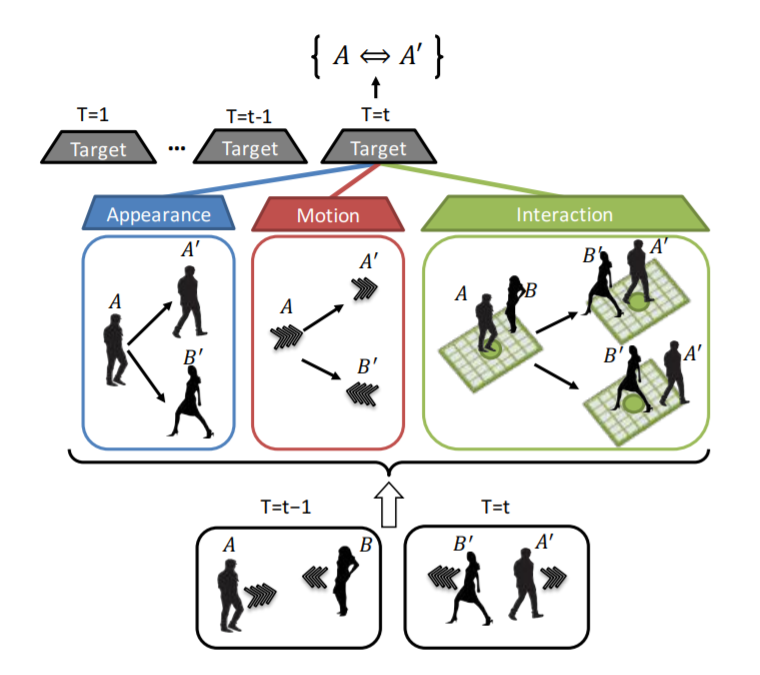
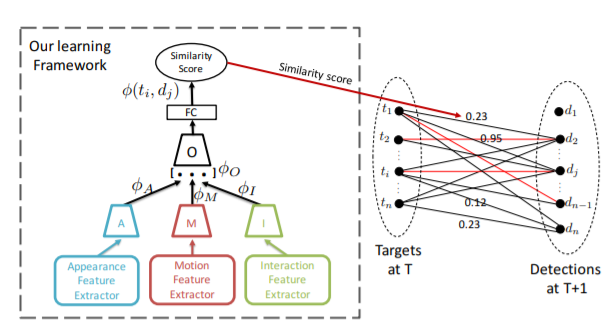
- 최근에는 딥러닝의
RNN계열을 이용하여 이 문제를 해결하는 방법도 제안되고 있습니다. - RNN 계열을 쓴다는 것은 detection을 위한 뉴럴 네트워크 한개와 별도로 track과 detection을 매칭(association)하기 위한 용도의 뉴럴 네트워크를 추가적으로 사용하는 것입니다. 관련 내용은 아래 논문을 참조 바랍니다.
- 참조 :https://arxiv.org/abs/1701.01909