
2. Image Classification
2018, Jan 11
목차
-
Summary
Summary
- 먼저 Summary를 통하여 Image Classification 강의를 간략하게 정리하겠습니다.
이미지 분류 (Image classification)
- ① 이미지 입력 값 : 0-255 값을 갖는 픽셀들로 이루어진 행렬 (높이 x 너비 x 채널 수)
- ② 이미지 분류를 어렵게 하는 요소들 : 다양한 조도, 형태 변형, 가려짐, 배경과의 식별이 어려울 때, 같은 분류 집합 내에서의 다양성 등
자료 기반 접근법 (Data-driven approach)
- 정답 (label)이 있는 이미지들의 많은 예제를 보고 분류기(classifier) 학습
최근접 이웃 분류기 (Nearest Neighbor classifier)
- ① k-최근접 이웃 분류기 (k-Nearest Neighbors; k = 클래스 개수)

- ② 거리 계산법 (학습용 이미지와 테스트용 이미지 사이 간 거리)
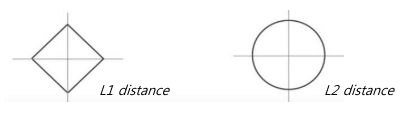
L1 distance(맨하탄 거리; 각 픽셀 별 오차의 절대값들의 합)
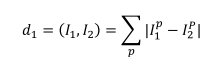
L2 거리(유클리디안 거리; 각 픽셀 별 오차의 제곱평균제곱근(root mean square))
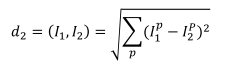
하이퍼파라미터(Hyperparameter)
- 학습 전 단계에서 미리 결정해 줘야 하는 모수 (학습되지 않음)
- k-최근접 이웃 분류기 알고리즘의 k와 거리 계산 법이 하이퍼파라미터에 해당됨.
- 적절한 초모수 값은 풀고자 하는 문제 및 데이터 셋에 따라 달라짐.

- 전체 데이터를 학습용(train), 검증용(validation), 테스트용(test)로 나눔. 검증용 데이터에서 초모수를 선택하고, 테스트용 데이터에서 평가함.
- 교차 검증 (cross-validation) : 학습용 데이터를 여러 겹(folds)으로 나누고, 하나의 겹을 검증용 데이터로 이용하고 나머지는 학습용 데이터로 이용함. 각 겹을 돌아가면서 한번씩 검증용 데이터로 사용. 적은 데이터 셋에 적합.
- k-최근접 이웃 분류기는 이미지 데이터 셋에 사용되지 않음 (연산 속도가 느리고 이미지의 정보를 추출하기에 적합하지 않음).
선형 분류 (Linear Classification)
- ① 모수적 접근 (Parametric approach) : \(f x, W = Wx + b\)
- \(x\)는 입력 이미지, \(W\)는 가중치 \(b\)는 편향
- \(x\) : \color{blue}{픽셀 개수× 이미지 채널 개수}
- \(W\) : \color{red}{클래스 개수} × \color{blue}{(픽셀 개수× 이미지 채널 개수)}
- \(b\) : \color{red}{클래스 개수} × 1
- ② 선형 분류가 어려운 상황들
- 배타적 논리합(XOR)문제
- 비선형
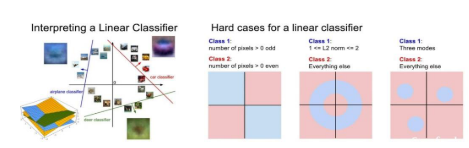
퀴즈
- 최근접 이웃 분류기는 선형분류기의 일종이다. (X)
- 교차 검증법은 딥러닝에 필수적이다. (X)
- 검증용(validation data) 데이터는 모수(parameter)를 학습하기 위해 사용된다. (O)
- 파라미터(parameter)와 하이퍼파라미터(hyperparameter)의 차이점
- 파라미터: 학습 단계 중에 모델에 의해서 학습됨
- 하이퍼파라미터 : 학습 전에 사람에 의해서 결정
- L1 거리와 L2 거리가 이미지 분류에 적합하지 않은 이유는?
- 이미지의 배경과 의미론적인 부분을 구별할 수 없기 때문에 사용하는 데 한계가 있다.