CompletionFormer, Depth Completion with Convolutions and Vision Transformers
2023, Apr 25
- 논문 : https://arxiv.org/abs/2304.13030
- 사전 지식 : NLSPN
- 이번 글에서 다룰 논문은 CVPR 2023 Paper로 등재된 논문이며
Transformer를 이용하여Depth Completion을 적용한 뒤NLSPN을 이용하여refinement를 적용한 논문으로 요약할 수 있습니다. NLSPN논문만 이해하면 본 논문에서는 이해하기 어려운 부분은 없으니 쉽게 읽을 수 있을 것으로 생각됩니다. 본 글을 읽기 전에 사전 지식으로NLSPN을 꼭 읽기를 추천드립니다.
목차
-
Abstract
-
1. Introduction
-
2. Related Work
-
3. Method
-
4. Experiments
-
5. Conclusion and Limitations
-
Pytorch 코드
Abstract

sparse depthmap과RGB image가 주어졌을 때,sparse depthmap의 값을 전체 이미지의 픽셀로 확장하는 것이depth completion의 역할입니다.- 지금까지 많이 시도되어 왔던 CNN 기반의
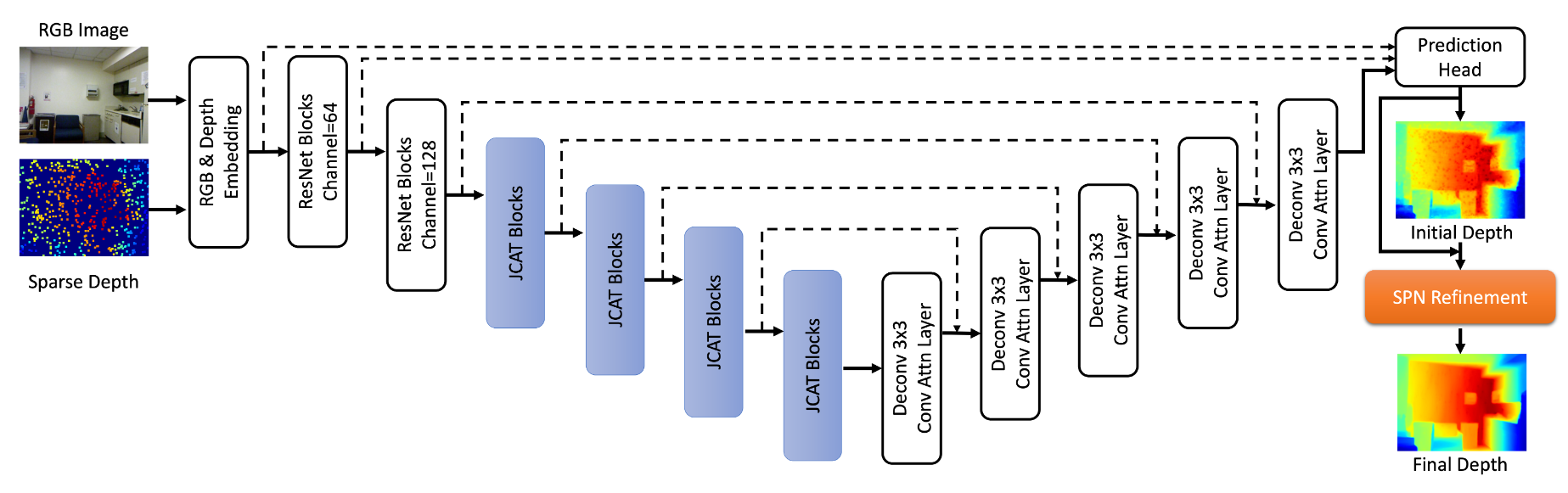
depth completion은locality에 집중하는 Convlution Layer의 특성 상 픽셀 간의 거리가 멀었을 때,depth completion이 정확하게 되지 않는 문제가 발생하였습니다. 최근에 급속도로 발전 중이며 많이 사용되는transformer구조에서는global receptive field를 가지기 때문에 이러한 문제를 개선할 수 있음을 논문에서 보여줍니다. - 본 논문에서는 단순히
CNN이나Transformer만을 사용하지 않고CNN의 성질을 통해locality의depth completion성능을 확보하고Transformer의 성질을 통해globality의depth completion의 성능을 확보하고자JCAT,Joint Convolutional Attention and Transformer block구조를 제안합니다.