Semantic Segmentation과 Depth Estimation의 Multi Task Learning
2021, Dec 25
- 이번 글에서는 Semantic Segmentation과 Depth Estimation을 멀티 태스크 러닝을 통하여 한번에 학습하고 출력하는 전체 과정에 대하여 다루어 보도록 하겠습니다.
- 이와 관련된 내용으로 ICRA 2019에 발표된 Real-Time Joint Semantic Segmentation and Depth Estimation Using Asymmetric Annotations 논문을 기준으로 설명해 보도록 하겠습니다.
- 이 논문의 아이디어나 학습 방법 등에 초점을 두지 않고 Hard Parameter 방식의 멀티 태스크 러닝이 어떤 메카니즘으로 동작하는 지 살펴보면 되겠습니다.
- 이 논문에서 다루는 멀티 태스크 러닝 모델을
HydraNet이라고 부르도록 하겠습니다.

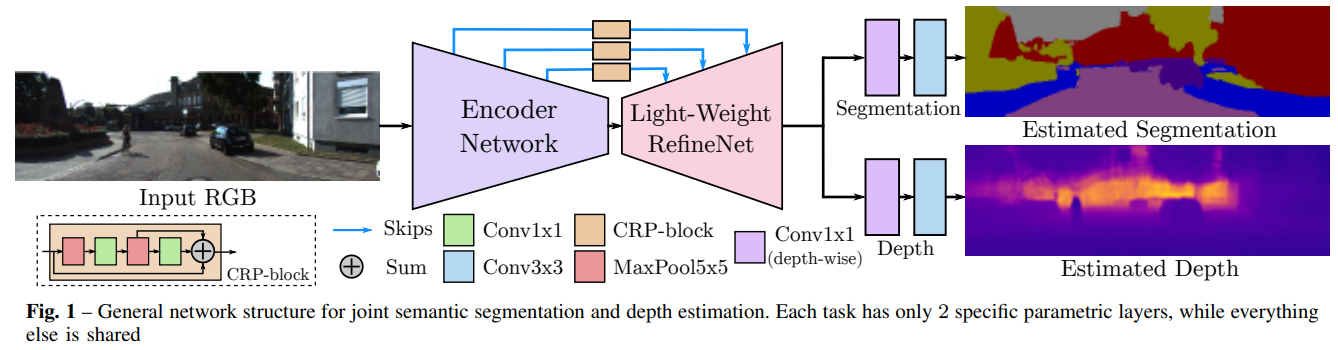
- HydraNet의 구조는 위와 같습니다. 입력은 1개의 RGB 이미지가 입력되는 반면에 출력은 segmentation과 depth가 출력이 되며 출력의 해상도는 입력 해상도와 같습니다.
- 모델의 중간 구조는 학습이 잘 되기위한 skip connection이 인코더와 디코더 부분을 연결하고 있고 디코더 부분의 출력에서부터 두 부분으로 나뉘어져서 segmentation과 depth가 출력되는 구조입니다.
- backbone이라고 말할 수 있는 Encoder, Decoder가 모델의 핵심이며 segmentation과 depth estimation을 동시에 잘 수행할 수 있는 backbone이 되도록 학습시키는 것이 중요합니다.
- 위 그림은 KITTI 데이터 셋을 이용하여 segmentation과 depth estimation을 학습 후 open3d로 3차원으로 나타내어 시각화한 것입니다. KITTI에는 segmentation 라벨링 수가 1,000 개 미만의 소량 데이터이므로 그 수준에 맞는 성능을 냅니다.
- 출력 결과를 RGBD 형식으로 재정리하면 위 그림과 같이 결과를 정리할 수 있습니다.