Lift, Splat, Shoot (Encoding Images from Arbitrary Camera Rigs by Implicitly Unprojecting to 3D)
2022, Jan 05
- 논문 : https://arxiv.org/abs/2008.05711
- 논문 : https://nv-tlabs.github.io/lift-splat-shoot/
- 참조 : https://towardsdatascience.com/monocular-birds-eye-view-semantic-segmentation-for-autonomous-driving-ee2f771afb59
- 참조 : https://patrick-llgc.github.io/Learning-Deep-Learning/paper_notes/lift_splat_shoot.html
- 이번 글에서는 NVIDIA의 멀티 카메라 기반의 BEV (Bird Eye View) 세그멘테이션 논문인
Lift, Splat, Shoot을 자세하게 다루어 보도록 하겠습니다.
목차
-
전체 내용 요약
-
0. Abstract
-
1. Introduction
-
2. Related Work
-
3. Method
-
4. Implementation
-
5. Experiments and Results
-
Pytorch 코드 분석
전체 내용 요약
Lift, Splat, Shoot논문은 각 픽셀을 학습 가능한 BEV map에 생성하여 거리 분포를 예측하는 모델입니다.- 이 논문은 OFT(Orthographic Feature Transform for Monocular 3D Object Detection), PyrOccNet, MonoLayout, Pseudo-lidar 논문 등의 시도들을 기반으로 만들어 졌습니다.
- 이 논문에서는 RGB 영상의 픽셀에 대하여 뎁스 (depth) 분포 예측을 통하여 RGB 영상의 픽셀에 대한 깊이 분포 예측을 통한 확률적
3D lifting을 제안하여 격자 형태의 픽셀에 사영(projection) 시킵니다. 이 사영된 결과는 학습 가능한 (미분가능한)semantic BEV map이 됩니다. semantic BEV map예측을 하기 위하여 모든 카메를 통해 얻은 예측값을 결합된 (chohesive) 하나의 representation으로 퓨전해야 합니다. 이것은 카메라 입력에 따라 자차의 주변의 360도 전체 scene에 대한 학습이고 궁극적으로 BEV map 예측을 통하여 motion planning을 위한dense representation을 학습합니다.- 본 논문이 다른 논문에 비하여 아쉬운 점은 픽셀 간의 간격이 0.5m 정도로 꽤 픽셀 간격이 넓습니다. 다른 논문인 FishingNet은 픽셀 간의 간격이 0.1m, 0.2m 인것에 비교하면 resolution이 낮습니다. (동등 비교는 아니지만 HDMap을 사용한 모델과도 resolution의 차이가 납니다.)
핵심 아이디어는 다음과 같습니다.View transformation: Probabilistic pixel-wise depth predictionLift: probabilistic (and differentiable) 3D liftingSplat: point pillar generationShoot: motion planning + \(K\) template에 대한 분포를 예측합니다.
Resolution관련 내용은 다음과 같습니다.카메라 이미지: \(H \times W = 128 \times 512\)BEV grid: \(X \times Y = 200 \times 200\), 각 픽셀 당 0.5m의 간격을 가지므로 \(100m \times 100m\)의 전체 영역을 가집니다.Depth resolution: \([4, 45]\) m 범위를 1m 간격으로 구분합니다.
학습 관련 내용은 다음과 같습니다.cumsum trick을 이용한sum pooling을 통해 이미지를 통합하여 BEV로 나타나는 데 효율적으로 연산할 수 있었습니다.- 학습 과정 중에
camera dropout(input dropout)을 이용하고noisy extrinsic을 이용한 학습을 통하여 카메라 입력과calibration noise에 좀 더 강건해 질 수 있도록 학습하였습니다.
0. Abstract

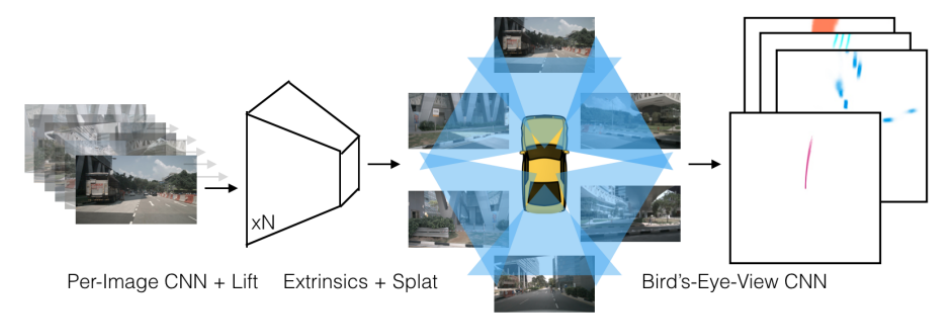
- 이 논문의 목적은 위 그림의 왼쪽과 같이 멀티 뷰 카메라 데이터를 입력 받아서 위 그림의 오른쪽과 같이 BEV(Bird Eye View) 좌표계에 직접적으로 인퍼런스 출력하는 것입니다.
- 출력을 살펴보면 파란색은 차, 주황색은 주행 가능 영역 그리고 초록색은 차선을 의미합니다.
- 위 그림의 왼쪽에서 각 카메라 뷰 별 파란색, 주황색, 초록색의 점들이 찍혀 있습니다. 이 점들은 BEV의 출력에 해당하는 결과를 다시 입력 이미지로 가져와서 projection 한 것입니다.

- Abstract에 나온 바와 같이 자율주행 자동차의 인식 관련 주요 기능은 멀티 센서의 정보를 퓨전하여 얻은 representation으로 부터 semantic representation을 추출하고 단일 BEV 좌표계에 정보를 표현하여 motion planning 까지 하는 것입니다.
- 이러한 기능을 구현하기 위하여 본 논문에서는 BEV 좌표계에 직접 인식 결과를 출력하는 end-to-end 구조를 소개하였습니다. 이 구조의 입력은 임의의 갯수의 카메라 영상을 입력받습니다.
- 이 논문의 제목과 같이
lift,splat,shoot은 각 단계별 task를 의미합니다. - 먼저
lift는 각 카메라의 이미지를 각frustum으로 변경하는 역할을 하는 단계를 의미합니다.frustum은 피라미드 모양의 위면이 잘린 입체형태를 의미하며lift를 구현하기 위한 feature의 구조가 이와 같이 생겨서 frustum으로 표현하였습니다. - 그 다음으로
splat은 모든frustumfeature를 rasterized BEV grid로 표현하는 것을 의미합니다. rasterized란 뜻은 discrete pixel 형태의 이미지를 나타내었다는 뜻으로 흔히 알고 있는 픽셀 형태로 BEV grid를 표현했다고 이해하시면 됩니다. - 차량에 장착된 카메라의 영상 전체를 한번에 학습함으로써 본 논문의 모델은 이미지를 어떻게 represent 하는 지 학습하고 모든 카메라 이미지를 통해 얻은 출력을 퓨전하여 결합된 단일 BEV scene에 표현하는 방법을 학습합니다. 이 과정 속에서 차량에 장착된 카메라에서 발생하는 캘리브레이션 에러에 강건해지는 장점을 얻을 수 있었습니다. 이러한 학습 방법을 통하여 기존의 object segmentation 이나 map segmentation 보다 좋은 성능을 얻을 수 있었습니다.
- 그리고 BEV 에 representation 하는 방식을 통하여 end-to-end 방식의 motion planning을 할 수 있으며 이 방식을
shooting이라고 표현합니다. shooting은 template trajectory를 BEV cost map output에 적용하는 과정을 의미하며 자세한 내용은 본문 내용에서 살펴보겠습니다.- 최종적으로 성능 검증은 lidar 데이터를 통하여 확인하였습니다.
1. Introduction
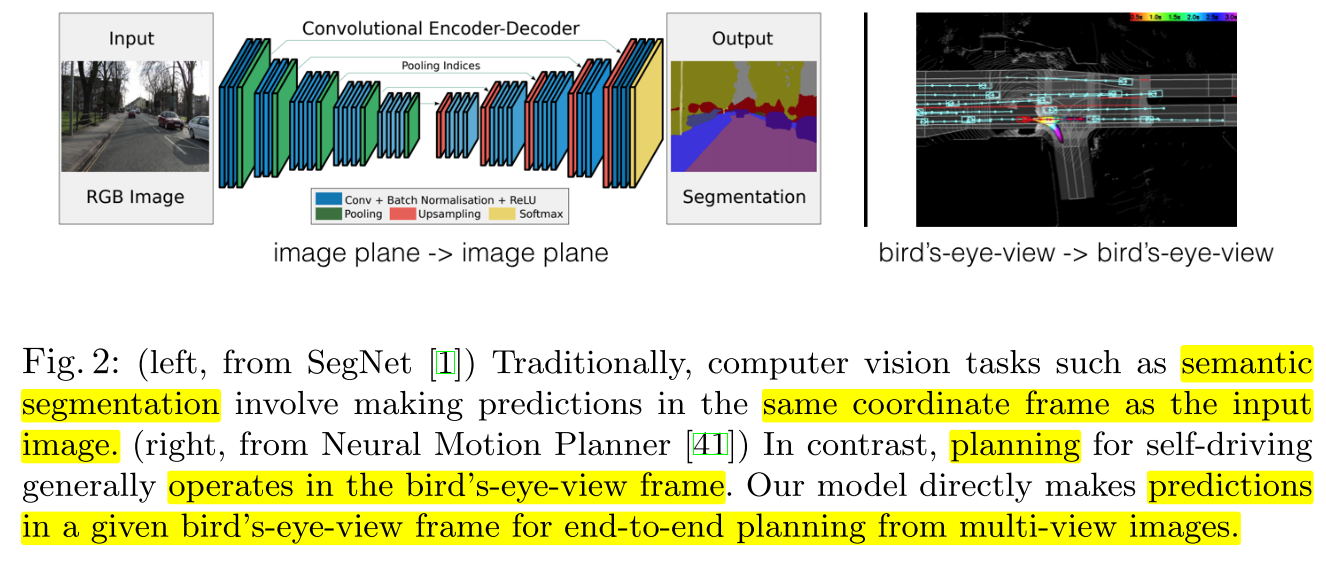

- 컴퓨터 비전 알고리즘은 좌표계가 무관한 classification과 같은 task가 있고 detection, semantic segmentation과 같이 입력 좌표계와 동일한 좌표계에서 문제를 해결하는 task도 있습니다.
- 자율주행 관련된 task 에서는 여러 개의 센서로부터 입력을 받아서 자차 (ego car)를 중심으로 만든 새로운 좌표계를 기준으로 예측값을 출력합니다.
- 위 Fig. 2. 와 같이 기존의 semantic segmentation에서는 입력 이미지와 동일한 해상도의 출력 이미지를 만들어내는 FIg. 2. 의 오른쪽 이미지는 planning을 할 때 BEV 환경에서 동작하는 예시를 나타냅니다.
- 본 논문은 멀티 뷰 이미지를 입력으로 받아서 각 frame 별 출력으로 만든 BEV에서 인식을 하고 end-to-end 방식으로 planning 까지 다룹니다.

- 한 개의 이미지에서 멀티 뷰 이미지로 확장하기 위해서 여러 개의 카메라들을 각 카메라의 intrinsic과 extrinsic 정보를 이용하여 각 카메라의 좌표계 기준을 기준 좌표계 기준으로 변환해야 합니다. 이 때, 카메라의 intrinsic과 extrinsic을 이용합니다.
- 이와 같은 멀티 뷰 이미지로의 개념 확장은 아래 3가지 특성을 만족을 기대합니다.
- ①
Translation equivariance: 각 이미지 내의 픽셀 좌표계에서 물체가 이동하면, 동일한 크기만큼 출력 좌표계에서도 물체가 이동되어야 합니다. - ②
Permutation invariance: 최종 출력은 카메라 입력의 순서에 의존적이지 않아야 합니다. - ③
Ego-frame isometry equivariance: 멀티 뷰 이미지에서 동일한 물체를 인식하면 자차 기준의 ego-frame에서 같은 물체로 인식되어야 합니다. 즉, 차량에 장착된 카메라가 회전 및 이동이 발생하면 그 변경양에 맞춰서 보정이 되어서 같은 물체를 다른 물체 또는 다른 위치에서 인식하지 않도록 해야 합니다. (멀티 뷰 전체를 고려한 Frame을 ego-frame 이라는 용어로 사용하였습니다.)

- 가장 간단한 방법은 post process 방식을 이용하여 인식 결과를 처리하는 것입니다. 하지만 이러한 접근 방식은 ego-frame 에서 서로 다른 센서를 통해 얻은 예측을 구분하는 데 방해가 될 수 있습니다.
- 그리고 post process 방식을 시용하면 모델이 data-driven 방식으로 학습을 할 수 없습니다. 가장 좋은 방식은 멀티 뷰 카메라 간 정보를 퓨전하는 것인데 data-driven 방식으로 학습하면서 자동적으로 개선되는 방식이 좋습니다.

- 따라서 본 논문에서는
Lift-Splat이라는 모델의 학습을 통하여 앞에서 언급한 멀티 뷰 이미지의 3가지 요소인Translation equivariance,Permutation invariance,Ego-frame isometry equivariance를 만족하도록 하려고 합니다.
- 이후에 다룰 내용 중
3.Method에서는lift-splat모델의 내용을 다룰 예정입니다. - 먼저
lifts에서는 2D 이미지에서 얻은 정보를 frustum 모양의 contextual feature 포인트 클라우드로 생성하여 3D로 나타내는데 이 과정을lift라고 합니다. 즉, 2D 이미지를 3D feature로 lift (들어 올린다) 한다고 생각하시면 됩니다. - 그 다음
splat에서는 모든 frustum feature들을reference plane (BEV)에 펼칩니다. 말 그대로splat하는 것입니다. 이 과정을 통해 그 이후에 진행되는 motion planning에 도움이 됩니다. - 마지막으로
shooting이라는 과정은 reference plnae 상에서 trajectory를 제안하는 방법입니다. 이 방법을 통하여 해석 가능한 end-to-end 방식의 motion planning을 접근합니다.
4. Implementation에서는 멀티 뷰 카메라에서 어떻게lift-splat모델이 학습하는 지 상세히 다루어 보겠습니다.5. Experiments and Results에서는 실험적 증거를 통하여lift-splat모델이 여러 카메라의 정보를 효과적으로 퓨전한 지를 소개하겠습니다.
2. Related Work

- 멀티 카메라로 부터 얻은 이미지 데이터로 부터 얻은 결합된 표현 방식 (cohesive representation)에 대한 학습은 센서 퓨전과 단안 카메라 이미지에서의 객체 인식에 관한 최근 연구들이 많이 진행 되어 왔습니다.
- 다양한 multi-model 데이터셋이 공개되어 있어서 데이터셋들로 부터 많이 연구가 되고 있고 본 논문의 Lift-Splat 아키텍쳐 또한 이러한 데이터 셋들을 이용하여 연구되었습니다.
Monocular Object Detection

- 단안 카메라 이미지에서 객체를 인식 할 때에는 2D image plane에서 3D reference frame으로 어떻게 모델을 이용하여 변환하는 지가 학샘입니다.
- nuScences 데이터가 대표적으로 많이 사용되고 있으며 기존 2D detector에 depth를 추정하는 loss를 추가하여 3D detector 형태로 사용하고 있습니다. 이러한 접근 방식이 좋은 성능을 보이곤 하는데 단안 카메라의 depth 추정의 모호함을 제거해주는 역할을 하기 때문입니다.
- 이 방식은 결국 2D 이미지에서 3D 물체의 위치를 추정하는 것으로 정리할 수 있습니다.

- 반면 다른 방식으로 한 개의 네트워크는 단안 카메라 영상에서 depth를 추정하고 또 다른 네트워크에서는 BEV 좌표계에서 객체 인식을 하는 것입니다.
- 이러한 depth prediction을 이용하는 접근 방식을
pseudo lidar라고 하며 BEV 좌표계에서 객체를 인식하기 때문에 최종적으로 어플리케이션에서 사용되는 좌표 형태에서 바로 객체의 위치를 나타낼 수 있다는 의의가 있습니다.
Inference in the Bird’s-Eye-View Frame

- extrinsic과 intrinsic을 사용하여 BEV frame에 직접 인식 결과를 출력하는 모델에 대한 연구가 여러 방면으로 진행되고 있습니다.
MonoLayout은 단안 카메라를 통하여 BEV 출력을 하였으며 BEV 출력에서 adversarial loss를 통하여 가려진 물체에 대해서도 출력할 수 있도록 연구하였습니다.Pyramid Occupancy Network는 transformer 구조(Attention 구조는 아니며, view를 변환한다는 의미의 transform)를 사용하여 image representation을 BEV representation으로 변경하여 segmentation 하는 연구를 하였습니다.FISHING Net은 멀티 뷰 환경에서 다양한 센서를 입력 받아 하나의 BEV 환경에 표현하고자 하였으며 현재 Frame과 향후 Frame에 대하여 세그멘테이션을 하고자 하였습니다.- 본 논문에서는 이전 다른 연구보다 높은 성능을 얻을 수 있었으며 관련 내용은 다음 챕터에서부터 설명하도록 하겠습니다.
3. Method

- 이번 섹션에서는 임의의 카메라로 부터 얻은 이미지를 통해 얻은 BEV representation을 학습하는 방법을 알아보도록 하겠습니다.
extrinsic\(E_{k} \in \mathbb{R}^{3 \times 4}\) 와intrinsic\(I_{k} \in \mathbb{R}^{3 \times 3}\) 의 정보를 가진 각 이미지 \(X_{k} \in \mathbb{R}^{3 \times H \times W}\) 가 주어질 때, BEV 좌표계의rasterized representation형태로 나타내고자 합니다. BEV 좌표계는 \(y \in \mathbb{R}^{C \times X \times Y}\) 로 나타냅니다.- n개의 카메라 각각에 대하여
extrinsic과intrinsic행렬을 사용하기 때문에 3차원 world coordinate인reference coordinate\((x, y, z)\) 와local pixel coordinate인 \((h, w, d)\) 간 매핑이 가능해집니다.refernece coodrinate는 모든 카메라를 다 고려하였을 때, 실제 3차원의 좌표라고 생각할 수 있는 반면local p;ixel coordinate는 각 카메라의 이미지 좌표계 기준으로 거리 개념이 추가된 것으로 볼 수 있습니다. - 이와 같은 방법을 이용 시 학습 또는 테스트 시 뎁스와 관련된 센서는 필요 없어집니다.
3.1 Lift: Latent Depth Distribution
lift과정의 전체적인 구조는 다음OFT논문을 베이스로 발전되었습니다. 따라서 아래 논문을 먼저 참조하는 것이 아키텍쳐 이해에 도움이 됩니다.

- 본 논문의 첫번째 단계인
lift는 각 카메라로 부터 얻은 이미지를 2D 이미지 좌표계에서 모든 카메라의 정보가 공유된 3D 좌표계로 변환 (여기서는lift라는 용어를 사용) 하는 작업을 의미합니다. lift에서는 기존의 단안 카메라 퓨전 시 뎁스가 모호한 점을 개선하기 위하여 뎁스를 추정할 수 있는 모든 픽셀에 대하여 새로운 방식의 representation을 만듭니다.

- 먼저
lift에 사용된 개념을 알아보기 위해 관련 용어를 정리해보도록 하겠습니다. - \(X \in \mathbb{R}^{3 \times H \times W}\) : \(X\) 는 각 카메라를 통해 얻은 이미지를 나타냅니다.
- \(E, I\) : \(X\) 이미지에 사용되는 카메라의 Extrinsic, Intrinsic 파라미터를 의미합니다.
- \(p, h, w\) : \(p\) 는 \(X\) 이미지의 픽셀을 의미하고 \(h, w\) 는 각 픽셀의 위치를 의미합니다.
- \(D\) : \(D\)
discrete depth의 집합을 의미합니다. 픽셀 \(p\) 의 각 위치인 \((h, w)\) 에discrete depth형식으로 총 \(\vert D \vert\) 개 단계로 depth를 나누었을 때, \(\{d_{0} + \Delta, ... , d_{0} + \vert D \vert \Delta \}\) 와 같은 집합으로 각 단계별 \(d\) 를 표현할 수 있습니다. 이 때, \(\{(h, w, d) \in \mathbb{R}^{3} \vert d \in D \}\) 와 같이 각 픽셀 별로discrete depth\(D\) 를 가집니다. 이와 같은 방식으로 뎁스 \(D\) 를 나타내어 \(D \cdot H \cdot W\) 크기의 포인트 클라우드를 만들어냅니다. - 뎁스와는 별도로 이미지를 통해 얻은 feature를 나타내는 정보가 있으며 이 feature는 각 픽셀 \(p\) 별로 벡터 형태로 있어서
context vector라고 합니다. 각 픽셀 \(p\) 에 대하여 네트워크는context인 \(c \in \mathbb{R}^{C}\) 와depth\(\alpha \in \Delta ^{\vert D \vert - 1}\) 에 대한 분포를 예측합니다. - \(\alpha_{d}\) : 먼저 \(d\) 인덱스는 \(D\) 집합에서 카메라로 부터 가장 가까운 뎁스를 \(d = 0\), 가장 먼 뎁스를 \(d = \vert D \vert -1\) 라고 하였을 때 선택되는 인덱스를 의미합니다. \(\alpha\) 는 뎁스를 의미하므로 \(\alpha_{d}\) 는 뎁스에 대한 분포에서 \(d\) 번째 뎁스를 의미합니다.
- \(c_{d}\) : 각 픽셀 \(p\) 별로
context vector인 \(c\) 가 존재하는데, \(c_{d} = \alpha_{d}c\) 로 정의됩니다. 즉,context vector에 뎁스를 곱한 것이 \(c_{d}\) 가 됩니다.
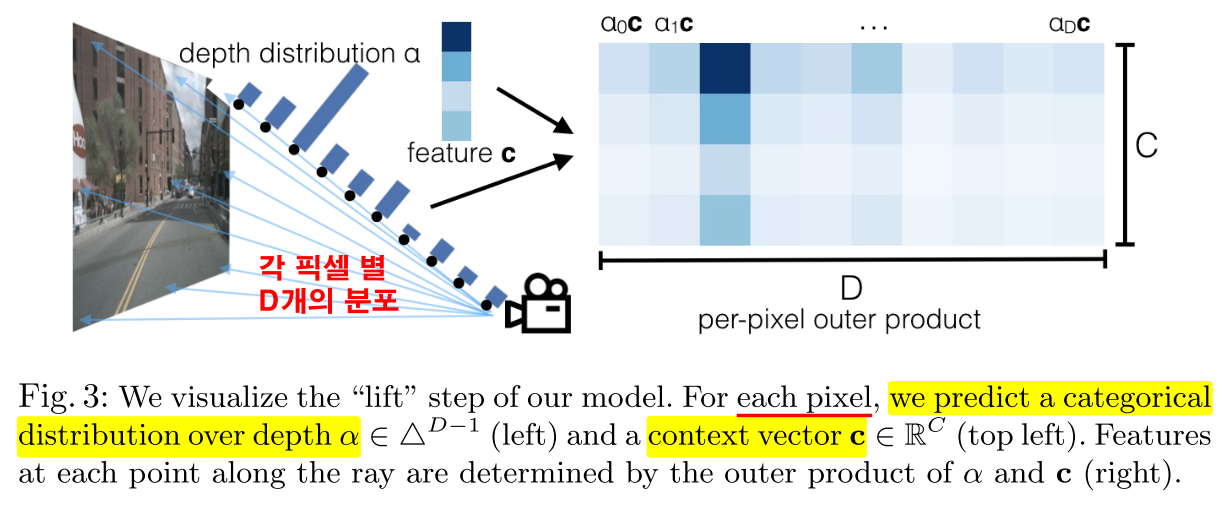
- 위 그림을 살펴보면 각 픽셀 별로 \(\vert D \vert\) 개의 뎁스 단계가 있고 어떤 단계에 그 픽셀의 뎁스가 해당하는지
depth distribution\(\alpha\) 를 통해 표시됩니다. - 이 때, \(\alpha\) 와 feature \(c\) 의 곱을 통해 나타내는 결과를
per-pixel outer product로 표시하며 각 열은 \(c_{0}, c_{1}, ...\) 와 같이 표시할 수 있습니다.

- 네트워크가 \(\alpha\) 에 대한 원-핫 벡터를 예측하는 경우 \(p_{d}\) 지점의 context는
pseudo-lidar에서와 같이 단일 깊이 \(d^{*}\) 에 대해 0이 아니며 만일 네트워크가 뎁스에 대하여 uniform distribution으로 예측하였다면 각 픽셀 별로 뎁스와 독립적으로 같은 representation을 예측할 것입니다. - 따라서 우리 네트워크는 뎁스가 모호한 경우 BEV representation의 특정 위치에 이미지의 context를 배치하는 것과 전체 ray (빛) 공간에 context를 분산시키는 방법등을 선택할 수 있습니다.
- (이 부분의 문장의 뜻은 정확히 이해 못함) 최종적으로
lift는 각 이미지에 대하여 \(g_{c} : (x, y, z) \in \mathbb{R}^{3} \to c \in \mathbb{C}\) 로 생성하는 함수를 뜻하며 이 함수는 이미지의 어떤 spatial location에 대한 query에context vector로 return해 주는 역할을 합니다.
3.2 Splat: Pillar Pooling
splat과정의 전체적인 구조는 다음PointPillars논문을 베이스로 발전되었습니다. 따라서 아래 논문을 먼저 참조하는 것이 아키텍쳐 이해에 도움이 됩니다.

lift에 의한 포인트 클라우드 출력을 변환하기 위하여 앞서 설명한PointPillars아키텍쳐를 따릅니다.Pillars는 높이가 무한한 voxel을 의미합니다.- 포인트 클라우드의 모든 Point는 가장 가까운 pillar로 할당되고 \(C \times H \times W\) 의 텐서를 만들기 위하여
sum pooling연산을 수행합니다. pooling 연산 속도를 향상하기 위하여 베이스 논문이 되는OFT와 유사하게 sum pooling을 사용하며 padding 방법을 고려하여 좀 더 효율적으로 연산하기 위하여cumsum trick을 사용합니다. 이와 관련 내용은 Chapter 4에서 다루도록 하곘습니다. - sum pooling을 이용하여 이와 같은 형태(\(C \times H \times W\))의 텐서를 만드는 이유는 일반적인
2D CNN사용하기 위함입니다. CNN 연산을 이용하여 BEV 상에서 inference를 하며 전체적인lift-splat아래 그림을 참조하시면 됩니다.
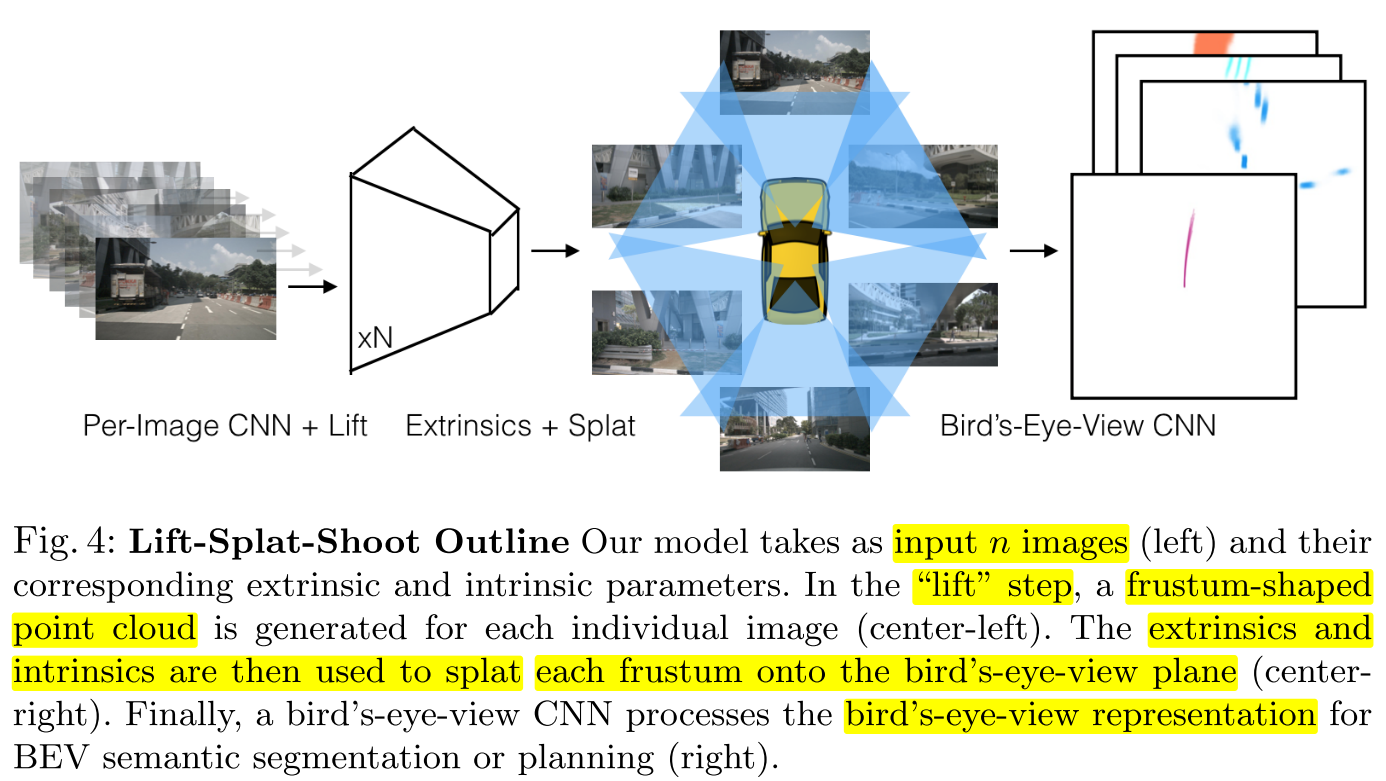
- 위 아키텍쳐는
lift-splat전체 아키텍쳐를 나타내며 크게 3가지 부분으로 나뉘어져 있는 것을 알 수 있습니다. - ①
Per-Image CNN + Lift: n개의 이미지와 그 이미지의 카메라 extrinsic, intrinsic 파라미터를 입력으로 받습니다.lift단계에서는 frustum 모양의 포인트 클라우드 feature가 각 이미지에 대하여 생성됩니다. - ②
Extrinsic + Splat: 카메라의 extrinsic과 intrinsic 파라미터를 사용하여 ① 단계에서 생성한 frustum 모양의 feature를 BEV plane으로 펼칩니다. 이 과정을Splat이라고 합니다. - ③
Bird's-Eye-View CNN: 마지막으로 BEV 상에서 semantic segmentation과 planning을 하기 위하여 BEV representation을 CNN으로 처리합니다.
3.3 Shoot: Motion Planning
4. Implementation
4.1 Architecture Details

- 본 논문의 모델은 2개의 큰 backbone 네트워크를 가집니다. 첫번째 backbone은 각 이미지로부터 생성된 point cloud feature를 만들기 위한 모델입니다. 첫번째 backbone은
EfficientNet을 사용하여 feature를 생성하였습니다. - 두번째 backbone은 point cloud가 reference frame의 pillar로 펼쳐 (splat) 지도록 하는 역할을 하며 최종적으로 BEV를 만들어 냅니다. 이 backbone은 ResNet block의 조합을 사용하여 만들어지며 block의 상세 내용은 논문을 참조하시면 됩니다.
- 이러한 2종류의 네트워크가 결합이 되어
lift-splat이되며 약 14.3M개의 학습 파라미터를 가지는 모델을 구성합니다.

- 모델의 전체 아키텍쳐를 설계하기 위하여 중요한
하이퍼파라미터들이 존재합니다. - 첫번째 하이퍼파라미터는 입력 이미지의 해상도 \(H \times W\) 를 정하는 것입니다. 본 논문의 모델은 원본 이미지를 resize와 crop을 하여 \(128 \times 352\) 크기를 만들고 그 크기에 맞추어서 카메라 파라미터를 수정하였습니다.
- 두번째 하이퍼파라미터는 BEV grid의 해상도 \(X \times Y\) 입니다. 본 논문에서는 \(x, y\)의 범위를 -50m ~ 50m 까지 범위로 정하였고 grid의 각셀은 \(0.5 \text{m} \times 0.5 \text{m}\) 의 크기를 가집니다. 따라서 총 \(200 \times 200\) 개의 셀을 가지는 BEV grid를 만들도록 하이퍼파라미터를 정합니다.
- 세번째 하이퍼파라미터는
lift단계에서 사용하는 depth의 해상도인 \(D\) 입니다. 본 논문에서는 \(D\) 를 4.0m ~ 45.0 m 까지 1.0m로 구분하여 나뉘었고 40개의 단위로 구분하여 확률 분포를 구하였습니다. - 이 하이퍼파라미터는 모델 전체의 사이즈를 결정하는데 중요한 역할을 하며 위와 같이 하이퍼파라미터를 사용 시 forward pass에 35 Hz (약 28 ms) 정도의 수행시간을 가지게 됩니다.
4.2 Frustum Pooling Cumulative Sum Trick

5. Experiments and Results

5.1 Description of Baselines

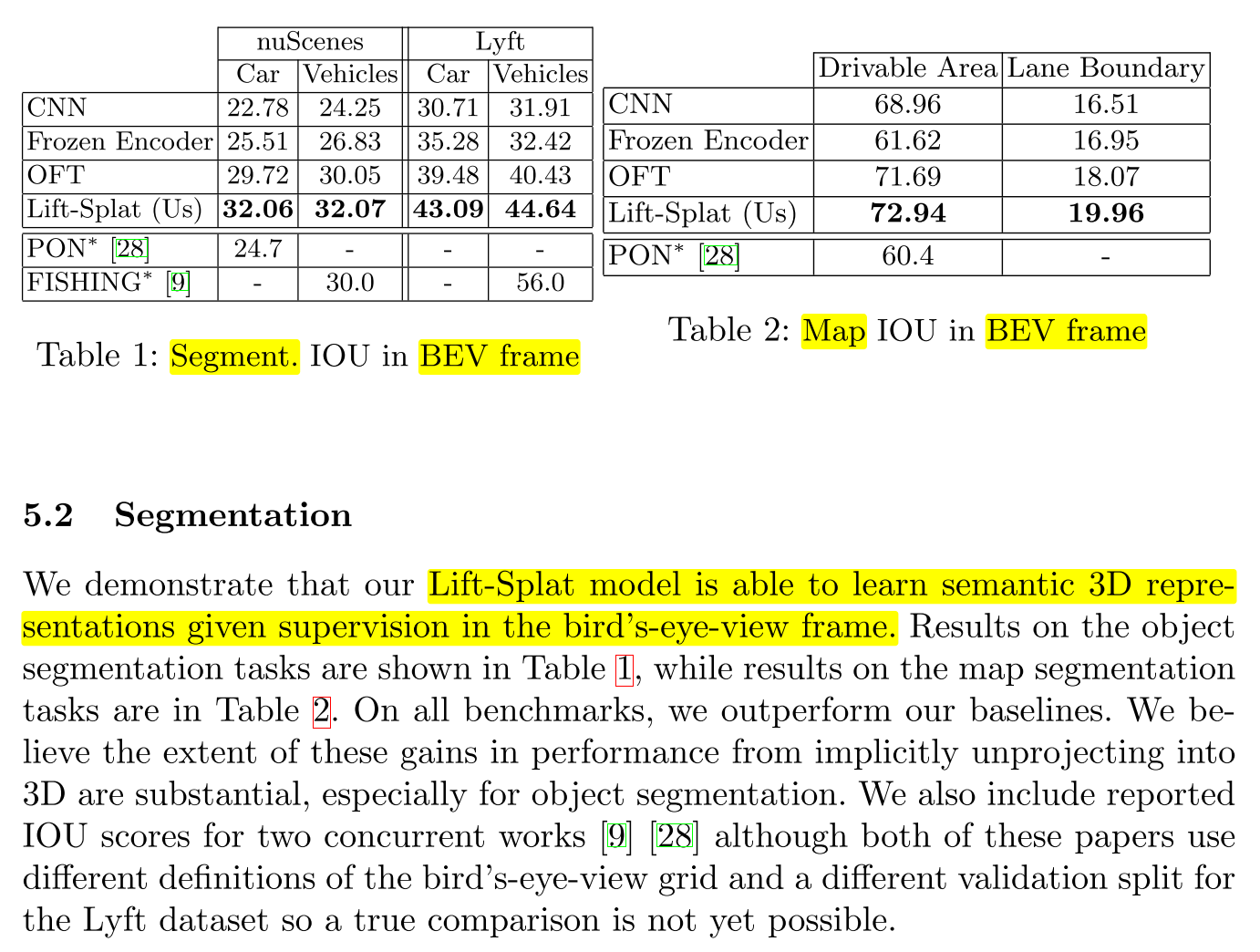
5.2 Segmentation
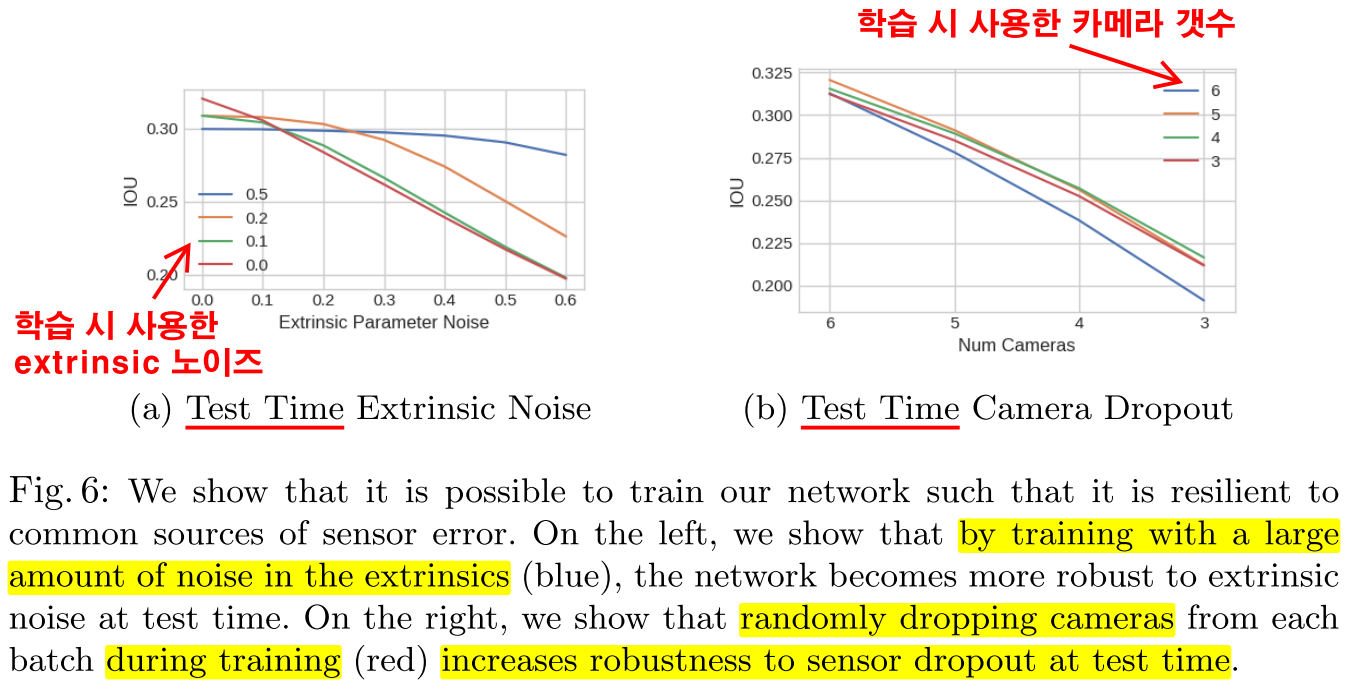
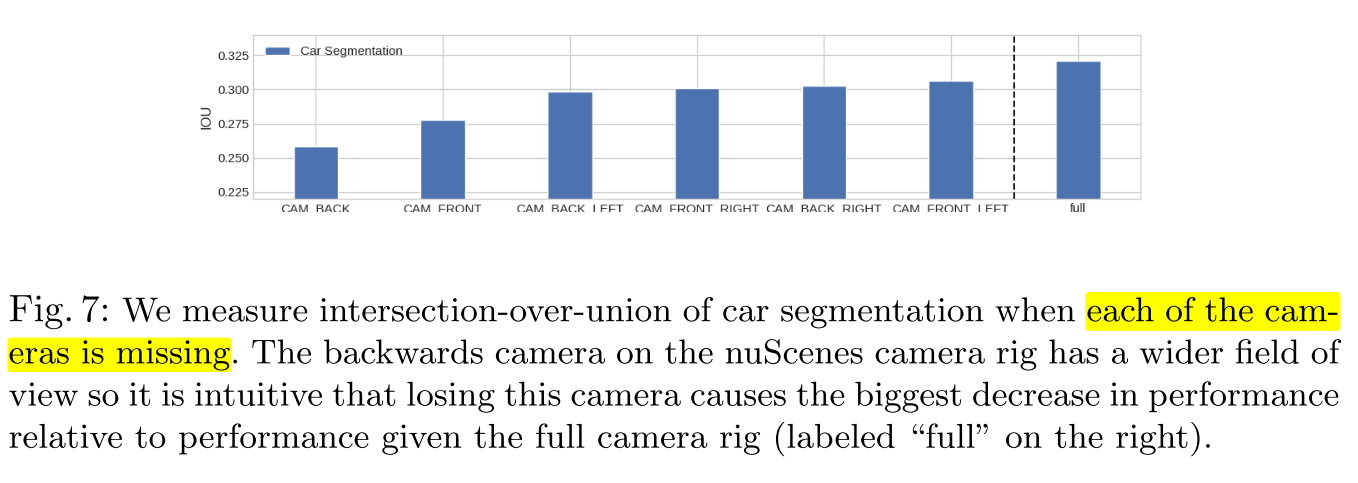
5.3 Robustness

5.4 Zero-Shot Camera Rig Transfer



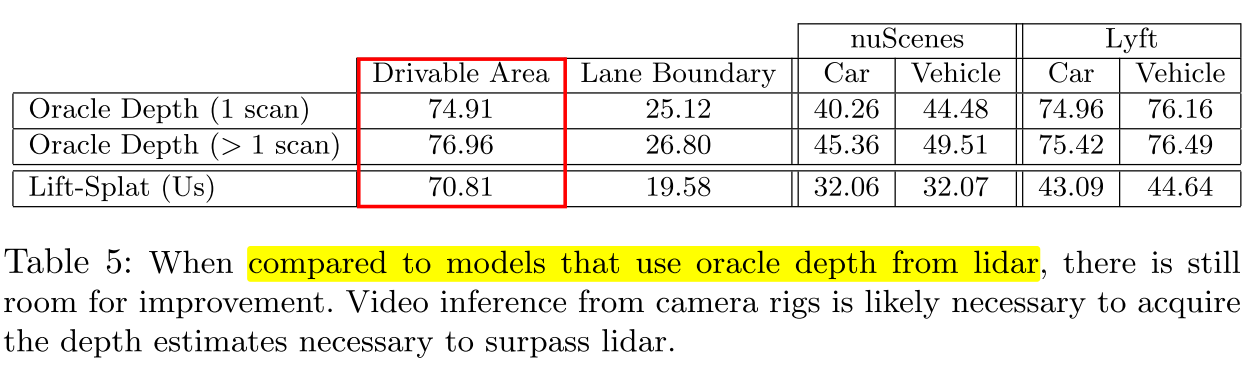
5.5 Benchmarking Against Oracle Depth