NVAutoNet, FAST AND ACCURATE 360◦ 3D VISUAL PERCEPTION FOR SELF DRIVING
2023, May 15
- 논문 : https://arxiv.org/abs/2303.12976
- NVIDIA DRIVE Perception : https://developer.nvidia.com/drive/perception
- 이번 글에서는
NVIDIA에서 arxiv에 등재한NVAutoNet이라는 논문을 살펴보도록 하겠습니다.

- 논문의 핵심 내용은 부제인
Fast and Accurate 360° 3D Visual Perception For Self Driving에서 알 수 있듯이 ①Fast, ②Accurate, ③360°, ④Visual Perception4가지 요소를 만족하도록 네트워크가 설계되어 있음을 설명합니다. - 즉, 자율주행을 위한 딥러닝 모델을 설계하였는데,
latency가 적고,accuracy가 정확한 모델을 만들고자 하면서360°주변 전체를vision방식으로 인식하고자 한 것입니다. - 논문의 전체 내용은
NVIDIA의 자체 SoC에 실현 가능성 있게 구현을 잘 해본 것에 의의를 두고 있으나 코드 공개 및 실제 public 데이터셋과의 비교는 없어 다소 아쉬움이 있습니다.
목차
-
Abstract
-
1. Introduction
-
2. Related Work
-
3. NVAutoNet
-
4. Perception Tasks
-
5. Multi-task Learning and Loss Balancing
-
6. Experimental Evaluation
Abstract
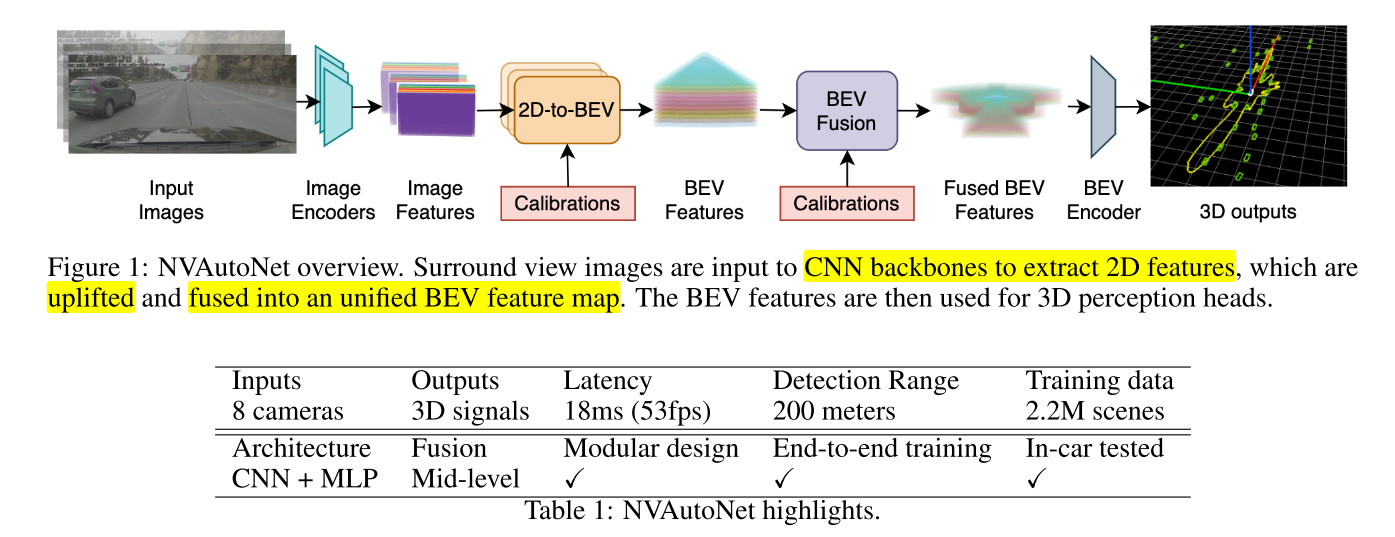
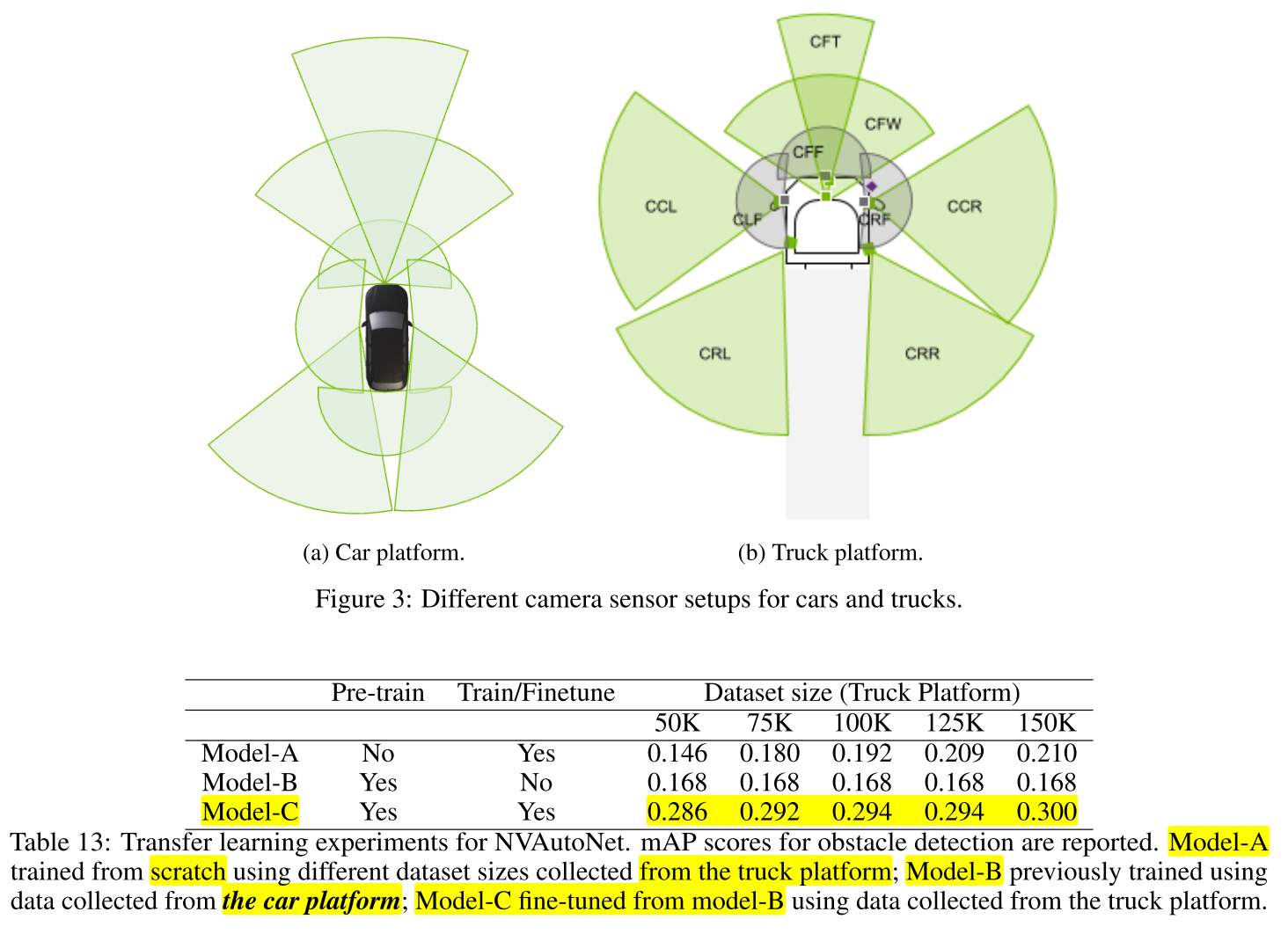
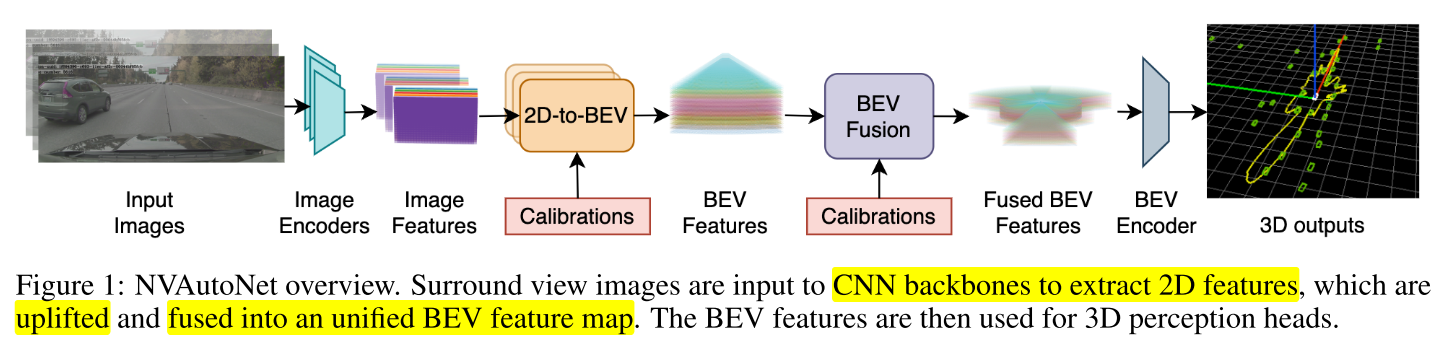
- 위 그림 및 테이블은
NVAutoNet에서 표현하고자 하는 전체 내용을 일목요연하게 보여줍니다. - ①
Input Images: 차량 주변의 360° 환경을 촬영한 이미지를 입력으로Image Encoder에 넣어줍니다. - ②
Image Encoders → Image Features: 각 이미지를 처리하는Image Encoder가 존재하여 각 이미지를 입력 받은 후 처리하여Image Feature로 만듭니다. - ③
2D-to-BEV + Calibrations → BEV Features:Image Feauture는 2D image에서 특징들을 추출한 것입니다. 따라서 아직 2D 이미지 공간에 있는 정보들입니다. 이 값들을BEV (Bird's Eye View)공간에 표현하기 위해uplift하는 과정을 거칩니다. 이 때, 카메라calibration (intrinsic 으로 추정함)값이 입력값으로 사용 됩니다. 이 과정을 통해 각 카메라 별BEV Feature를 생성합니다. - ④
BEV Fusion + Calibrations → Fused BEV Features: 각 카메라 별BEV Feature를 하나의BEV공간에 합치기 위해fusion을 합니다. 이 때, 통일된 하나의 공간으로fusion하기 위하여 카메라calibration (extrinsic 으로 추정함)값을 사용하여 하나의BEV공간에fusion된Fused BEV Features를 생성합니다. - ⑤
BEV Encoder → 3D outputs:Fused BEV Features에서 각 Task 별 원하는 출력을 생성하기 위하여BEV Encoder를 사용합니다. 본 논문에서는3D Object Detection과Freespace Detection2가지 문제를 풀기 위한 학습을Multi-Task방식으로 풀어 나갑니다.

- 본 논문은
time-synced camera image를 입력으로 받아서 3D 정보를 출력하는multi-task, multi-camera를 고려한 네트워크 설계를 소개합니다. (NVAutoNet) 여기서 3D 정보는 인식 대상의 크기, 방향, 위치 뿐 아니라 parking space 및 free space 등을 의미합니다. - 논문에서 제안하는 네트워크의 컨셉은
End-to-End이므로 별도의 post-processing을 필요로 하지 않으며 한번에 전체를 학습하는 방식을 이용합니다. NVAutoNet은NVIDIA Orin SoC에서53 fps의 수행 속도를 가지며NVIDIA ORGIN의 스펙은 다음 링크에서 참조 가능합니다. 아래 사이트에서는ORIN의 한국 총판을 맡고 있는 듯 합니다.- 링크 : https://www.mdstech.co.kr/AGXOrin
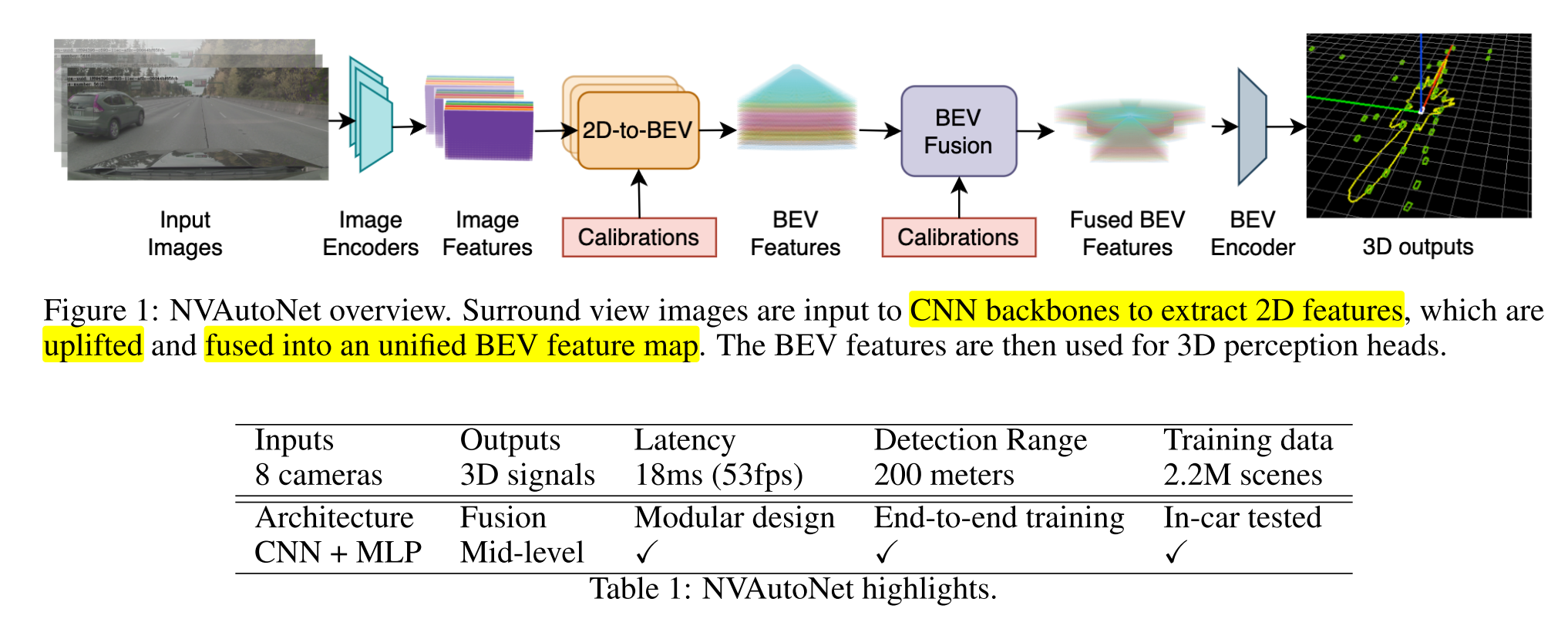
NVAutoNet은 실제 차량에서도 잘 동작함을 장점으로 꼽고 있습니다. 논문의 뒷편에 일반 차량과 트럭 모두에 적용할 수 있음을 보여주는데 카메라 장착 위치의 변화를 카메라 캘리브레이션 파라미터를 입력받아서 학습 및 테스트 시 사용하여 적절한fine-tuning했음을 보여줍니다.
1. Introduction

- 멀티 카메라가 있는 차량 환경에서도 단일 카메라에서 독립적으로 주변 환경을 인식하는 방식을 사용해 왔었습니다. 이와 같은 경우에는 각각의 카메라에서 인지한 결과에 에러가 발생하면 각 카메라 결과를 퓨전하는 데 어려움이 발생하나 이와 같이 카메라를 독립적으로 운용 (
camera independence)하는 방법이 제품의 안정성 등과 연관되어 단점이 있음에도 불구하고 사용되어 왔습니다. - 제품의 확장성 (
production scalability) 측면도 중요한 요소입니다. 차량의 종류 별로 카메라 장착 사양이 다르기 때문에 학습된 네트워크가 다양한 차량에 대응할 수 있도록 설계되어야 합니다. 본 논문에서는 카메라 사양으로camera mounting angles,positions,different radial distortion,focal length를 언급하였고 앞의 2개는camera extrinsic에 해당하고 뒤의 2개는camera intrinsic에 해당하는 것을 알 수 있습니다. - 마지막으로 저전력이면서
real-time성능이 나올 수 있도록 설계를 해야함을 언급합니다.

- 따라서
NVAutoNet은 5가지의 목표인 ①accurate 3D estimation, ②camera independence, ③end-to-end leaning, ④scalability, ⑤efficiency를 달성하기 위하여 전체 구조를 설계 합니다.

- 이와 같은 네트워크 설계를 위하여 크게 4가지를 고려합니다.
- ①
NAS를 이용한image → BEV feature extract네트워크를 설계합니다. - ②
feature level에서 멀티 카메라 퓨전을 하여 early fusion과 late fusion을 결합한mid-level fusion을 사용합니다. - ③
2d - to 3d uplift시depth prediction기반의 방법을 사용하지 않고MLP기반의uplift방법을 사용합니다. 이 때,camera intrinsic/extrinsic정보를 입력값으로 사용합니다. - ④ 모든 task는
detection task와 같이 구조화 되어 별도 post-processing을 필요하지 않도록 정의합니다.
2. Related Work

- 앞에서 설명하였듯이
NVAutoNet은Multi-camera의 정보를early fusion방식을 고려하여 단일 네트워크로 전달하며BEV representation상에서 최종 출력을 생성해 냅니다. - 따라서
Multi-camera를fusion하는 방식은 어떻게 각 이미지의 정보를BEV representation으로 나타내는 것인 지와 밀접한 연관이 있습니다.

2.2 Perspective to 3D View Transformation.에서는 본 논문의image fusion의 핵심인perspective image를BEV로 변환하는 방식에 대한 연관 내용을 소개합니다.vision기반의BEV표현 방식에 대한 내용은 아래 링크에서도 확인할 수 있습니다.
View Transformation을 하는 방식에는 크게 3가지 ①depth-based approach, ②ML based approach, ③transformer based approach가 있습니다.- 본 논문에서 제안하는 방식은
ML based approach를 경량화 한 방식을 사용합니다.
- 먼저 ①
depth-based approach은 가장 고전적인 방법으로flat-world model을 가정하거나 이미지의 픽셀 별depth정보를 알 수 있는 경우 사용 가능합니다. 하지만depth정보가 부정확하면3d uplifting (2D image → BEV representation)결과가 부정확해지는 문제가 발생하고 2D 이미지의 pixel 단위 별로3d uplifting을 하게 되면 전체 픽셀 변환량이 많아서 비효율적으로 변환을 해야 합니다. 뿐만 아니라 원거리 영역에서의depth가 부정확하기 때문에 원거리 영역의3d uplifting이 더 나빠지게 됩니다.
- 다음으로 ②
ML based approach은MLP (Multi-layer Perceptron)을 사용하여3d uplifting를 하며 BEV 관련 논문에서 많이 등장하는 VPN, FISHNET 등에서 이와 같은 방법을 사용하였습니다. 하지만 기존에 사용하였던 방식은 카메라의 intrinsic, extrinsic 정보가 사용되지 않아 한번 학습된 카메라 셋팅 환경과 달라지면 사용할 수 없다는 단점과MLP특유의 계산량이 많다는 단점이 존재합니다. - 본 논문에서는 이러한 계산량 문제를 개선하기 위하여
MLP연산을 각column방향으로 독립적으로 연산하는 방식을 사용합니다.
- 마지막으로 ③
transformer based approach가 있으며 이 방법은3d uplifting을 위하여 transformer 아키텍쳐를 적극적으로 사용하는 방법을 의미합니다. 앞의MLP based approach보다 좀 더 복잡도가 증가한 방법입니다. transformer based approach는 궁극적으로 실제 차량 환경에서real-time으로 동작하기 어려운 문제를 위 글에서는 문제로 삼고 있습니다.sparse set of BEV queries문제는 실제 모든 pixel에 대하여 transformer를 적용하였을 때, 계산량이 너무 복잡하여attention mechanism을 적용할 pixel을 전체 pixel의 subset으로 구성해야 하는 것을 의미하는데, 이 경우BEV representation과 같은dense prediction에는 적합하지 않음을 의미합니다.- 따라서
sparse set of BEV queries를 사용 시BEV representation에 충분하지 않다는 단점과transformer구조가 가지는 계산 비용에서 오는 한계점으로 인하여 실차 환경에 적합하지 않음을 설명합니다.
- 따라서 본 논문에서는
MLP연산을 각column방향으로 독립적으로 연산하는 방식을 집중적으로 설명할 예정입니다.

- 2.1과 2.2의 설명을 통해
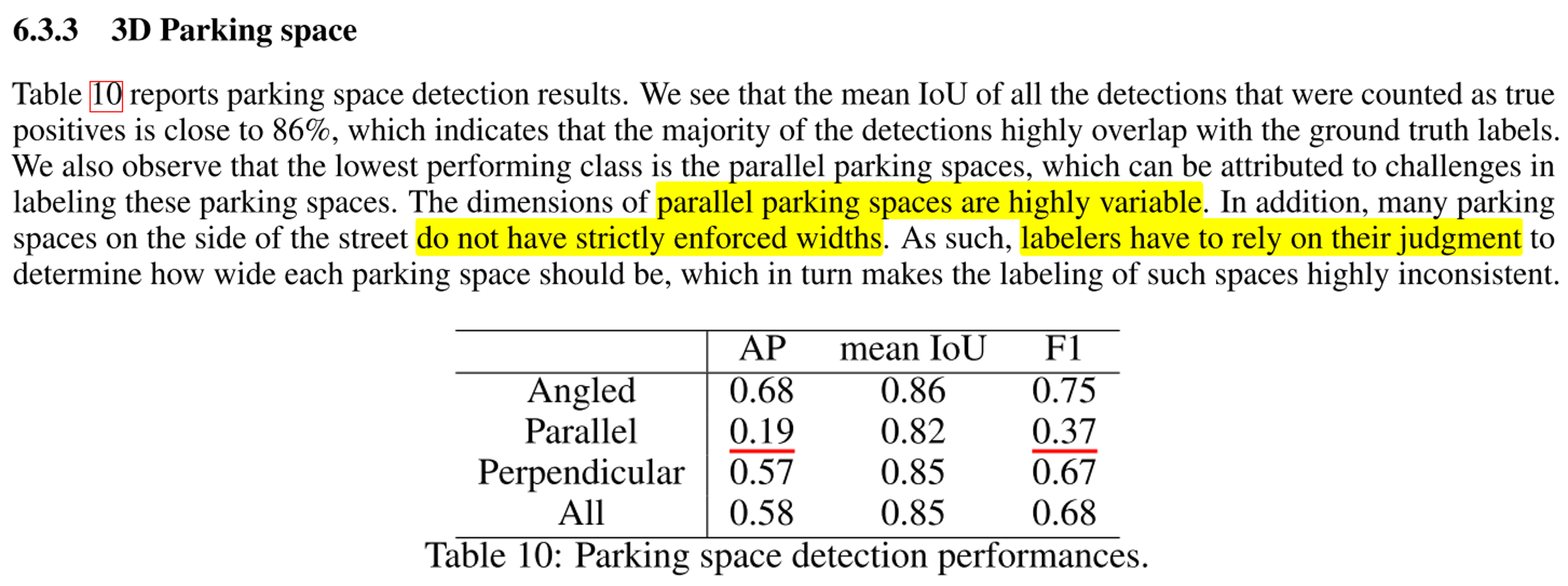
Multi-camera fusion을 통하여BEV상에 정보를 표현하고자 함을 확인하였습니다. 2.3에서는NVAutoNet이 출력하고자 하는 정보가obstacles,free/parking spaces임을 말해줍니다.
- 기존의
3D Object Detection은 2D 이미지에서 3D Bounding Box를 추출하는 Task이지만depth정보의 정확도 문제로 한계점이 있습니다. - 본 논문에서는 2D 이미지에서 3D 정보를 추출할 때,
image space가 아닌BEV space를 바로 이용하는 방식을 사용합니다. 실차 환경의 구현을 위해 transfomer를 사용하지 않고fully convolutional layer을 사용하고 3D object 정보를 추출하기 위하여 object의 3D 정보를 알기 위한 파라미터를 추론할 뿐 아니라 그 파라미터의 불확실성 (uncertainty) 까지 추론해 냅니다.BEV space에서 정보를 추론하지만roll,pitch,yaw모두의 방향에 대한 정보를 추론하는 것을 언급합니다.
Free space detection을 할 때에도 2D 이미지에서 정보를 찾는 기존의 방식을 사용하지 않고BEV에서 찾는 방식을 사용합니다. 따라서BEV공간에서polygon형태로free space를 나타내는 방식을 통해 별도의 post-processing을 거치지 않는 방식을 취합니다.
3. NVAutoNet
- 챕터 3에서는 2D image feuatre를 최종적으로 어떻게 fusion 하는 지 집중적으로 다룹니다.

NVAutoNet은 360◦ FOV를 가질 수 있도록 \(N\) 개의 카메라와 각 카메라의intrinsic,extrinsic을 입력값으로 사용합니다.2D Image Encoder는 2D image에서 feature를 추출하는 역할을 하며 각2D image feature는BEV feauture로 만들어진 후 최종적으로BEV Encoder로 보내집니다.BEV Encoder는 최종 출력인obstacle (obejct)의position, size, orientation과parking/free spaces를 출력합니다. 이와 관련된 전체 과정은 아래 내용을 다시 살펴보시면 됩니다.

2D image는 feature extractor를 통하여multi level feature\(F_{k}\) 를 추출하며 \(F_{k}\) 의 shape은 다음과 같이 여러 해상도의 크기를 가집니다.
- \[\text{shape of } F_{k} = \frac{H}{2^{k+1}} \times \frac{W}{2^{k+1}} \times C\]
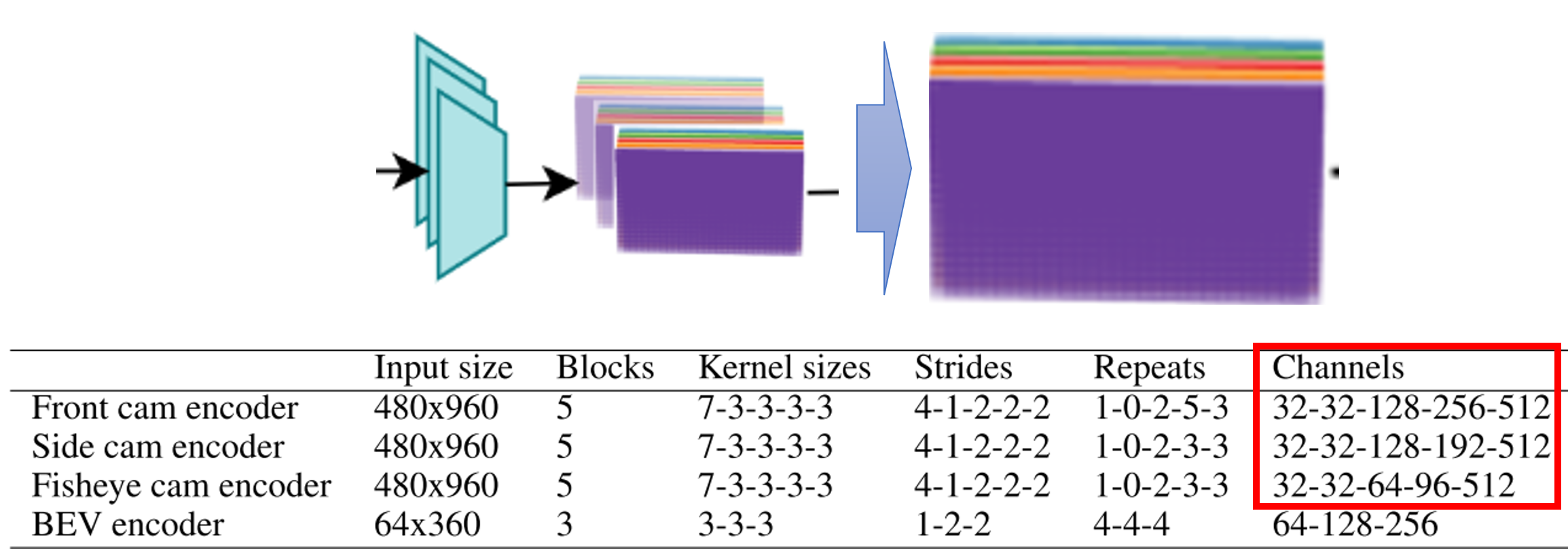
- 위 그림과 Table 2의
Channels정보를 보면 \(k = 0, 1, 2, 3, 4\) 로 5개가 적용된 것으로 추정 됩니다. - 위 테이블에서의 각
convolution의 파라미터는NAS (neural architectural search)를 통해 추정하였으며 논문에서는 latency와 accuracy를 고려하여 찾은 것으로 설명하였습니다. latency개선을 위하여residual connection을 제거되었으며 (성능 감소를 감수한 것으로 추정됩니다.) 각 level의multi-level feature를U-Net또는FPN구조와 같이 잘 조합하여 좋은 feature를 구성한 것으로 추정됩니다.- (위 테이블에서 각 카메라 별 인풋은 동일하지만) 서로 다른 카메라의 인풋 사이즈의 크기가 다르더라도
2D Image Feature Extractor가 각 카메라 별 이미지에 공용으로 사용할 수 있도록 설계하였음을 설명합니다.

BEV plane은 차량의 중심을 지나면서Z축에 직교하도록 구성됩니다. 본 논문에서BEV grid\(G^{\text{bev}}\) 는 \(W^{\text{bev}} \times H^{\text{bev}}\) 크기의dimension을 가지며grid의 셀 크기 및 표현 방식은 뒷 부분에서 설명합니다.BEV grid의 중심은 자차의 중심과 일치하도록 구성합니다.

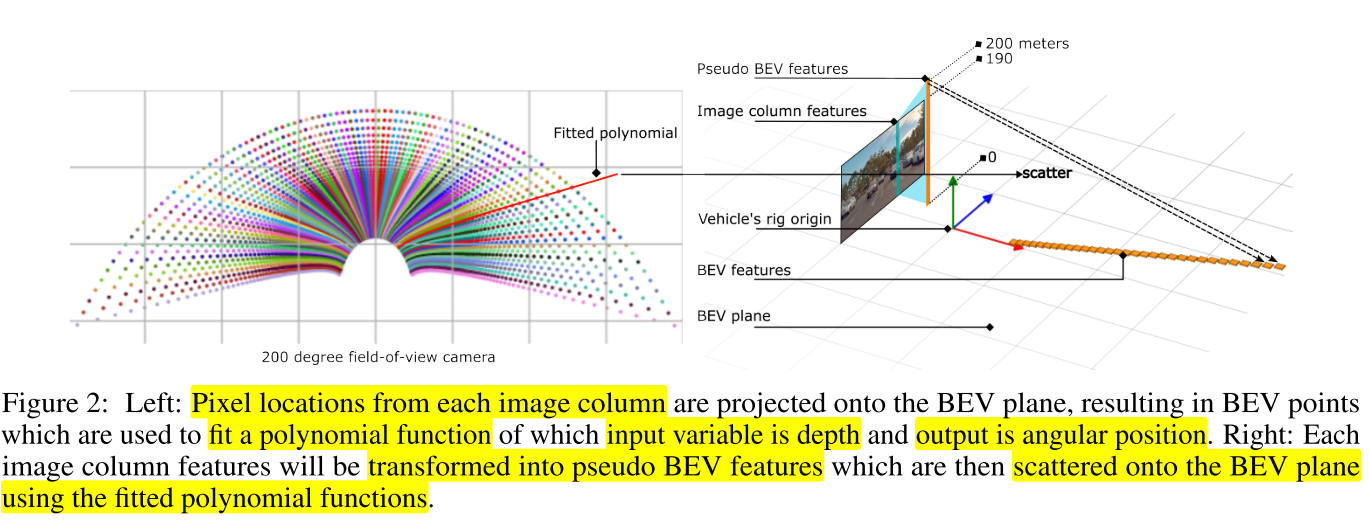



BEV transformation function인 \(B(\cdot)\) 은 단순한 1개의hidden layer를 가지는MLP block이며 각 이미지의 column 별 다른BEV tranformation방법을 가지기 때문에 이미지의 column 별 \(B(\cdot)\) 독립적인 function이 존재합니다.MLP를 사용하는 것은attention의 목적과 같으며global contextual information을 잘 사용하여image feature를BEV상의 올바른 위치에 위치 시키도록 하는 것에 목적이 있습니다. (직접적인depth를 추정하는 부분이 없으므로 object의 높이 부분이 있다면 그 부분을 반영해야 하기 때문입니다.)- 이와 같은 \(B(\cdot)\) 을 학습하기 위한 직접적인
supervision loss는 없으며 최종Loss를 통해 이 부분이 학습되도록 구성합니다.

NVAutoNet의 최대 200m 까지 인식하고자 하며 이와 같은 인식 거리를grid셀의 크기를 0.25 m로 설정하여Cartesian grid로 구성한다면 메모리도 많이 차지할 뿐 아니라 계산 비용도 너무 커지는 문제가 발생합니다.- 따라서 앞에서 설명한 바와 같이
Polar Coordinate를 사용합니다.Polar Coordinate는angle과 각angle의depth를 사용합니다. angle에 해당하는 \(W^{\text{bev}}\) 는 360의 크기를 가지도록 설정하며 이는 360◦를 의미합니다.depth에 해당하는 \(H^{\text{bev}}\) 는 64의 크기를 가지도록 설정하며 가까운depth는 조밀하게, 먼depth는 간격을 도어 설정하도록 하였습니다.Cartesian grid에서는 균일한 grid를 설정하는 것과 대조적입니다.- 따라서
NVAutoNet에서의BEV grid인 \(G^{\text{bev}}\) 는 \(360 \times 64\) 의 크기를 가집니다.


BEV Encoder의input size는 앞의polar coordinate를 반영하여 \(360 \times 64\) 가 되며 위 테이블과 같은 형태로convolution을 이용하여 구성됩니다.BEV Encoder를 이용하여 추출된 feature인 \(\hat{F}_{\text{bev}}\) 를 3가지 3D detection 태스크인3D Object Detection,3D Freespace Detection,3D Parking space Detection에서 사용합니다.
4. Perception Tasks
- 이번 챕터에서는 앞에서 정의한
BEV feature fusion정보를 이용하여3D Object Detection,3D Freespace,3D Parking Space기능을 구현하기 위한 출력과 학습 방법을 소개합니다.

3D Object Detection에서 구하고자 하는3D cuboid는 총 9개의 파라미터이며position,dimension,orientation의 각 3 자유도 씩 총 9개의 자유도를 구하는 것에 해당하며 NMS와 같은 별도 후처리를 필요로 하지 않습니다.BEV Encoder를 통해 추출한 \(\hat{F}_{\text{bev}}, \text{shape : } M \times N \times C\) 에서 추가적인convolution을 통하여3D cuboid정보를 추출합니다.- BEV feature의 \(M \times N\) 는
spatial dimenstion으로grid cell의 크기에 대응되며 각grid별 객체를 추정하므로 총 \(\hat{K} = M \times N\) 개의 객체를 추정할 수 있습니다. 3d cuboid를 추정하기 위하여 별도의head를 추가하여 아래와 같이classification,position,dimension,orientation을 각각 추정합니다.

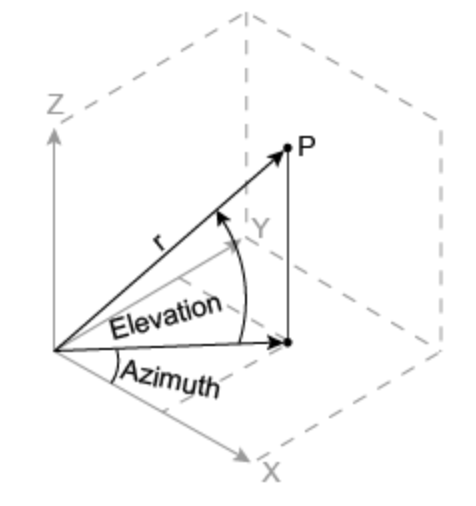
Position의azimuth angle과elevation은 아래 표시를 참조하시면 됩니다.

- 학습을 할 때에는 총 \(K\) 개의 GT와 \(\hat{K}\) 개의 prediction이 있을 때, 먼저 GT와 Pred를 매칭한 다음에 Loss를 계산합니다. 매칭을 잘못하면 Loss 계산이 잘못되므로 매칭 문제도 성능에 큰 영향을 미칩니다.
- 논문에서는
classification,position,dimension,orientation중position에 더 큰 가중치를 두어서 매칭하고 BEV grid 기준으로 GT와 Pred가 멀리 떨어져있으면 매칭하지 않는 간단한 greedy matching 방식을 사용하였음을 설명합니다. 이와 같은 방법을 통해 헝가리안 알고리즘과 같은 방식을 사용하지 않고 효과적으로 GT와 Pred를 매칭 하였습니다.

classification,position,dimension,orientation에 대한 각 Loss는 위 식을 참조하면 됩니다.Loss의 분모에 \(\sigma\) 는 각 구하고자 하는 값의uncertainty를 의미하며 이uncertainty는 별도 출력을 구할 수 있도록 모델을 설계하여 값을 도출해 냅니다.- 컨셉은 간단합니다.
uncertainty가 높으면 말 그대로 불확실하므로 이Loss가 정확하게 계산되었는 지 아닌 지 알 수 없음을 의미합니다. 따라서uncertainty가 높아지면Loss가 작아지도록 하여 잘못 학습이 되는 것을 방지합니다. 하지만 무한정uncertainty가 높아지게 되면 학습이 전혀 되지 않을 우려가 있으므로 \(\log{(2\sigma)}\) 를regularization term으로 추가하여uncertainty가 무한정으로 커지는 것을 방지합니다. - 반면
uncertainty가 낮아지면 그만큼 신뢰하고Loss를 사용할 수 있다는 뜻이므로Loss를 더 크게 만들어 학습에 반영합니다. - 이와 같은 컨셉으로 모든
Lossterm에 \(\sigma\) 가 적용되어 있습니다.

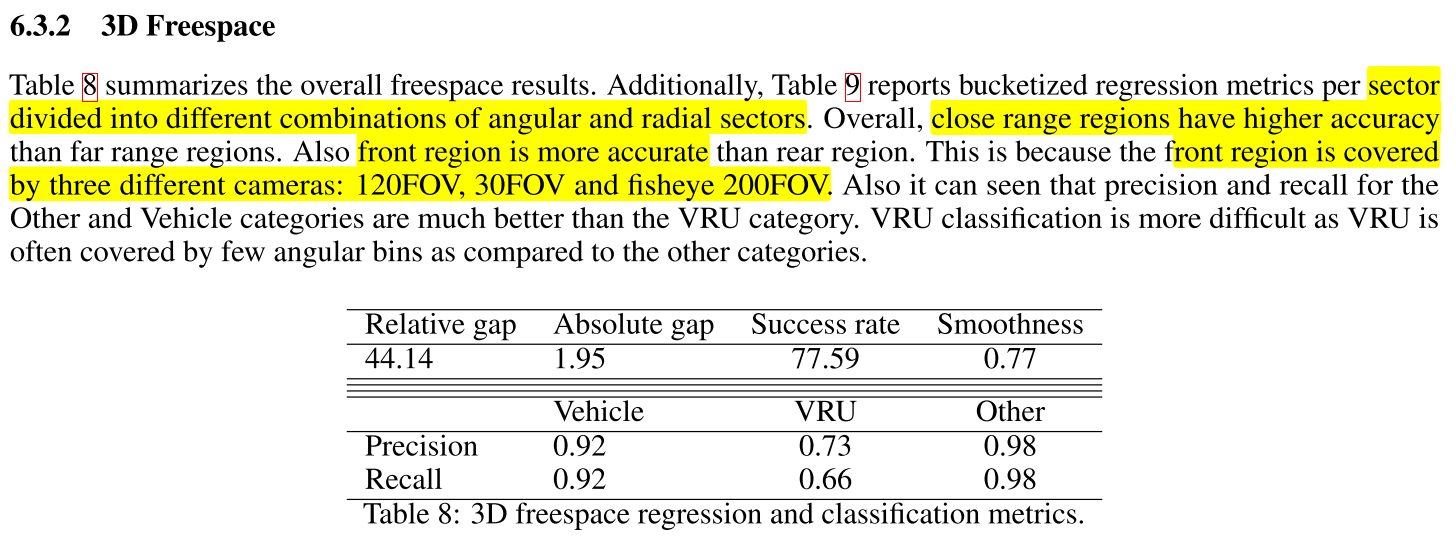
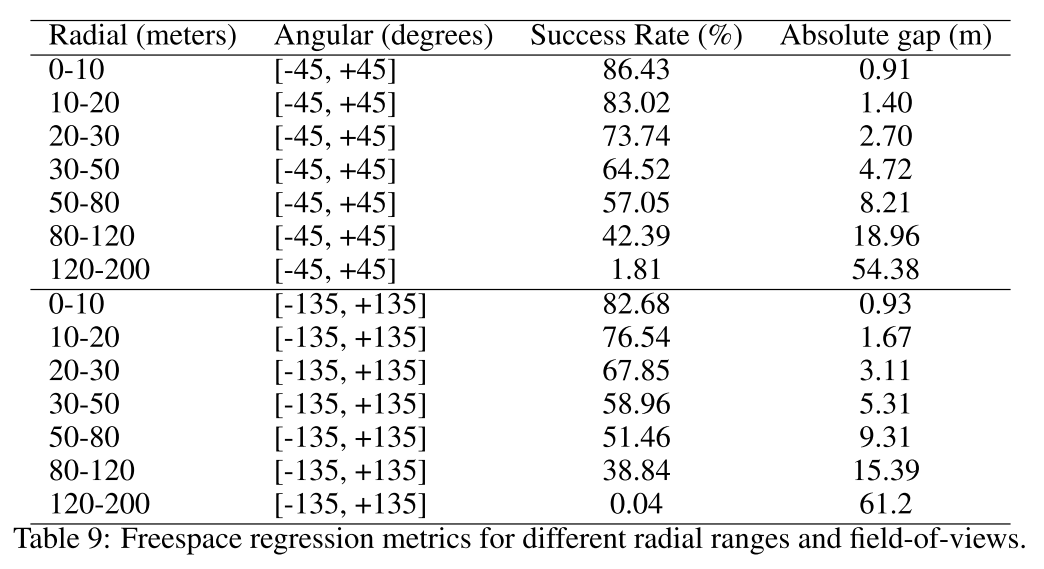
3D Freespace의 인식 대상은vehicle,VRU (vulnerable road users),Others(random hazard obstacels + static obstacles)이며 인식 대상은RDM (Radial Distance Map)에 나타냅니다.VRU의 용어 정의는 pedestrians, motorcycle riders, cyclists, children 7-years and under, the elderly and users of mobility devices이며 상세 내용은 다음과 링크를 참조하시면 됩니다.

RDM에서는equaiangle과radial distance를 이용하여 영역을 나누고 자차와 각angle별 자차와 가장 가까운radial distance의 경계를 찾는 방식으로3D Freespace를 인식합니다.- 따라서
BEV plane의 중심인 자차에서 부터 360도 전체 각도 별로 가장 가까운radial distance를 찾고 그 점들을 이어서polygon형태로 만드는 것이 최종 목적이 됩니다. 이와 같은 방식을 사용하면 추가적인 post-processing 없이 3D boundary를 만들 수 있습니다. polygon을 형성할 때 필요한 점들이label이 되며 라벨은 \((r, c)\) 형태로 표현할 수 있습니다. \(r\) 은radial distance vector이며 \(c\) 는boundary semantic vector입니다. 즉,RDM에서의 3D Boundary가 표시되는 점의 위치와 클래스가 됩니다.

3D Freespace Detection을 위한 추가적인 layer는shared neck과two seperated head이며 각head는radial distance와classification map을 추정합니다. 앞의3D Detection케이스와 동일하게shared neck은 \(\hat{F}_{\text{bev}}\) 를 입력으로 받아 처리합니다.

5. Multi-task Learning and Loss Balancing

6. Experimental Evaluation