
히스토그램 계산 - calcHist
2018, Dec 28
- Reference : Python으로 배우는 OpenCV 프로그래밍
-
Code : https://github.com/gaussian37/Vision/tree/master/OpenCV/histogram
- 히스토그램은 관찰 데이터의
빈도수를 막대그래프로 표시한 것- 히스토그램을 이용하면
데이터의 확률분포를 추정할 수 있습니다.
- 히스토그램을 이용하면
- 히스토그램은 이미지의 픽셀의 분포에 대하여 매우 중요한 정보를 제공합니다.
- 이미지의 픽셀 분포를 이용하여 즉, 히스토그램을 이용하여 아래 작업을 할 수 있습니다.
- 화질 개선 with 히스토그램 이퀄라이제이션
- 히스토그램 비교
- 히스토그램 역투영
- opencv에서 제공하는 히스토그램 함수는 opencv 내의 모든 함수 중에서도 좀 복잡한 편에 속합니다. 파라미터가 많기 때문입니다.
hist = cv2.calcHist(images, channels, mask, histSize, ranges(, hist(, accumulate)))
아래는 calcHist의 파라미터 입니다. 배열이라고 표시한 부분은 반드시 리스트로 입력해야 합니다.
- images : 히스토그램을 계산할 영상의
배열입니다. 영상은 같은 사이트, 깊이의 8bit unsigned 정수 또는 32bit 실수형 입니다. - channels : 히스토그램을 계산할 channel의
배열. (배열 형태로 입력 필요함), RGB면 channels이 3개입니다. - mask : images[i]와 같은 크기의 8bit 이미지로, mask(x, y)가 0이 아닌 경우에만 image[i](x,y)을 히스토그램 계산에 사용합니다.
- mask = None이면 마스크를 사용하지 않고, 모든 화소에서 히스토그램을 계산합니다.
- histSize : 히스토그램 hist (return 값)의 각 빈(bin) 크기에 대한 정수
배열입니다. - ranges : 히스토그램 각 빈의 경계값에 대한
배열입니다. opencv는 기본적으로 등간격 히스토그램을 제공합니다. - accumulate : True 이면 calcHist() 함수를 수행할 때, 히스토그램을 초기화 하지 않고, 이전 값을 계속 누적합니다.
- hist : 히스토그램 리턴값
import cv2
import numpy as np
src = np.array([ [0, 0, 0, 0],
[1, 2, 3, 4],
[3, 4, 4, 1],
[2, 5, 5, 3],
], dtype = np.uint8)
hist1 = cv2.calcHist(images = [src],
channels = [0],
mask = None,
histSize = [4],
ranges = [0, 8])
>> print("hist1", hist1)
hist1 [[6.]
[5.]
[5.]
[0.]]
hist2 = cv2.calcHist(images = [src],
channels = [0],
mask = None,
histSize = [4],
ranges = [0, 4])
>> print("hist2", hist2)
hist2 [[4.]
[2.]
[2.]
[3.]]
위에서 calcHist를 이용하여 간단하게 히스토그램을 구해보았습니다. 입력되는 파라미터를 보면 전부다 배열형태 즉,
리스트로 입력된 것을 볼 수 있습니다. 왜? 라고 물으신다면,,, opencv의 정책에 따른다고 밖에 말할 수 없겠네요.
개인적으로 calcHist가 python 버전, c++ 버전 모두 난해했던것 같습니다.
파이썬에서 사용하는 범위는 기본적으로 [, ) 범위를 가집니다. [ 는 이상을 뜻하고 )는 미만을 뜻합니다.
hist1에서는 histSize가 4이고 ranges가 0이상 8미만이므로, 각각의 범위는 아래와 같습니다.
- [0, 2) : 0, 1
- [2, 4) : 2, 3
- [4, 5) : 3, 4
- [6, 7) : 4, 5
이번에는 lenna 이미지를 그레이스케일로 받아서 히스토그램을 계산해 보겠습니다.
코드 라인 바이 라인으로 설명을 첨부해 놓았으니 한줄 한줄 따라가 보시면 되겠습니다.
import cv2
import os
import numpy as np
import argparse
import matplotlib.pyplot as plt
ap = argparse.ArgumentParser()
# 이미지 경로를 받습니다.
ap.add_argument("-i", "--image", required=True, help="Image path")
# 히스토그램의 간격 사이즈를 받습니다.
ap.add_argument("-b", "--bins", required=True, help="Each hist size")
args = vars(ap.parse_args())
path = args["image"]
histSize = int(args['bins'])
# 그래프 제목을 출력하기 위해 입력받은 사진의 이름을 저장합니다.
fname = os.path.splitext(path)[0]
# 이미지를 grayscale로 불러옵니다.
src = cv2.imread(path, cv2.IMREAD_GRAYSCALE)
# 이미지의 히스토그램을 입력받은 histSize 간격으로 계산합니다.
hist = cv2.calcHist(images = [src],
channels = [0],
mask = None,
histSize = [histSize],
ranges = [0, 256])
# 히스토그램을 flatten 하여 1차원 배열로 만듭니다.
histFlatten = hist.flatten()
# 히스토그램 bin의 간격에 맞게 [0, 255] 범위의 x축 범위를 만듭니다.
binX = np.arange(histSize) * (256//histSize)
# 히스토그램의 제목을 출력합니다.
plt.title("Histogram of grayscale " + fname + " image")
# 히스토그램의 중앙값을 선으로 연결합니다.
plt.plot(binX, histFlatten, color = 'r')
# 히스토그램을 그립니다.
plt.bar(binX, histFlatten, width = 8, color = 'b')
plt.show()
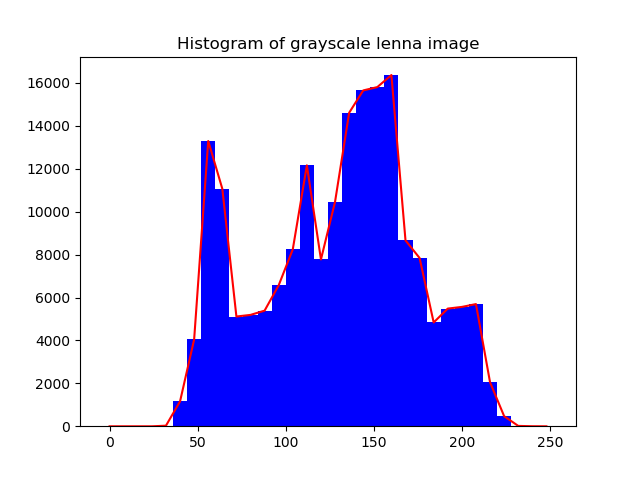
결과는 위와 같이 그레이 이미지에 관하여 히스토그램을 얻을 수 있습니다.
다음은 컬러 이미지의 히스토그램을 구해보겠습니다. 컬러 이미지의 히스토그램은 각각의 채널(R,G,B)를 구하여 비교해야 합니다.
import cv2
import os
import numpy as np
import argparse
import matplotlib.pyplot as plt
from matplotlib import ticker
from matplotlib.ticker import FuncFormatter
from mpl_toolkits.mplot3d import Axes3D
def compareColorHistogram(image, histSize, fname):
'''
R,G,B 히스토그램 각각을 그래프에 표시하여 비교하는 함수
'''
histColor = ['b', 'g', 'r']
# 총 256개의 픽셀 값에서 histSize 만큼 나눠 주게 되면 hist 구간의 갯수가 됩니다.
nbins = 256 // histSize
# x축을 nbins 만큼의 구간으로 만들되 각 tick를 [0, 255] 까지 범위로 만들어 줍니다.
binX = np.arange(histSize) * nbins
# B, G, R 을 차례로 접근하면서 히스토그램을 각 색깔에 맞게 그립니다.
for i in range(3):
hist = cv2.calcHist(images = [image],
channels = [i],
mask = None,
histSize = [histSize],
ranges = [0, 256])
plt.plot(binX, hist, color = histColor[i])
# plot의 제목을 출력합니다.
plt.suptitle("{} image histogram".format(fname), fontsize = 16)
plt.show()
def compareColorHistogram2d(image, histSize, fname):
'''
R,G,B 3가지를 2개씩 묶어서 나올 수 있는 경우의 수를 모두 2d로 표현하는 함수
'''
# (R, G), (G, B), (R, B) 3가지 경우의 수를 표현할 수 있도록 subplot을 구성합니다.
fig, axes = plt.subplots(1, 3, figsize=(15, 7))
channels_mapping = {0: 'B', 1: 'G', 2: 'R'}
for i, channels in enumerate([[0, 1], [0, 2], [1, 2]]):
# cv2.calcHist 함수를 통하여 이미지의 히스토그램을 구합니다.
# 2 채널의 이미지를 한번에 구해야 하므로 histSize와 ranges를 2개 입력해줍니다.
hist = cv2.calcHist(images = [image],
channels = channels,
mask = None,
histSize = [histSize] * 2,
ranges = [0, 256] * 2)
# x축, y축에 입력 될 채널을 할당해 줍니다.
channel_x = channels_mapping[channels[0]]
channel_y = channels_mapping[channels[1]]
# 각 subplot을 차례차례 접근합니다.
ax = axes[i]
# subplot의 x, y축의 범위를 정합니다. 범위는 [0, histSize) 까지로 먼저 정합니다.
ax.set_xlim([0, histSize - 1])
ax.set_ylim([0, histSize - 1])
# x와 y에 각각 어떤 color의 정보인지 기입합니다.
ax.set_xlabel("{} color".format(channel_x))
ax.set_ylabel("{} color".format(channel_y))
# 각 subplot의 title을 입력합니다.
ax.set_title(f'2D Color Histogram for {channel_x} and {channel_y}')
# 히스토그램 구간 총 갯수
nbins = 256 // histSize
# ax.set_x/ylib에서 정했던 scale에 bin 갯수만큼 곱해주어 [0, 255]의 범위를 갖게 합니다.
# 처음에 32개의 히스토그램 사이즈를 가지고 만들었다면, 각 채널당 8개의 구간이 존재합니다.
# 처음 셋팅을 [0, histSize) 의 범위로 셋팅을 해주었기 때문에 bin의 갯수를 곱해주면
# 전체 범위가 됩니다.
ax.xaxis.set_major_formatter(FuncFormatter(lambda x, pos:
'{:}'.format(int(x*nbins))))
ax.yaxis.set_major_formatter(FuncFormatter(lambda x, pos:
'{:}'.format(int(x*nbins))))
# img에 histogram들을 저장합니다.
img = ax.imshow(hist)
# image 상단부에는 subplot들이 있고 하단부에 colorbar를 그려줍니다.
fig.colorbar(img, ax=axes.ravel().tolist(), orientation='orizontal')
fig.suptitle('2D Color Histograms with {} histSize with {} image'.format(
histSize, fname), fontsize=32)
plt.show()
ap = argparse.ArgumentParser()
# 이미지 경로를 받습니다.
ap.add_argument("-i", "--image", required=True, help="Image path")
# 히스토그램의 간격 사이즈를 받습니다.
ap.add_argument("-b", "--bins", required=True, help="Each hist size")
args = vars(ap.parse_args())
path = 'lenna.png' # args["image"]
histSize = 32 # int(args['bins'])
# 그래프 제목을 출력하기 위해 입력받은 사진의 이름을 저장합니다.
fname = os.path.splitext(path)[0]
# 이미지를 color로 불러옵니다.
src = cv2.imread(path, cv2.IMREAD_COLOR)
compareColorHistogram(src, histSize, fname)
compareColorHistogram2d(src, histSize, fname)

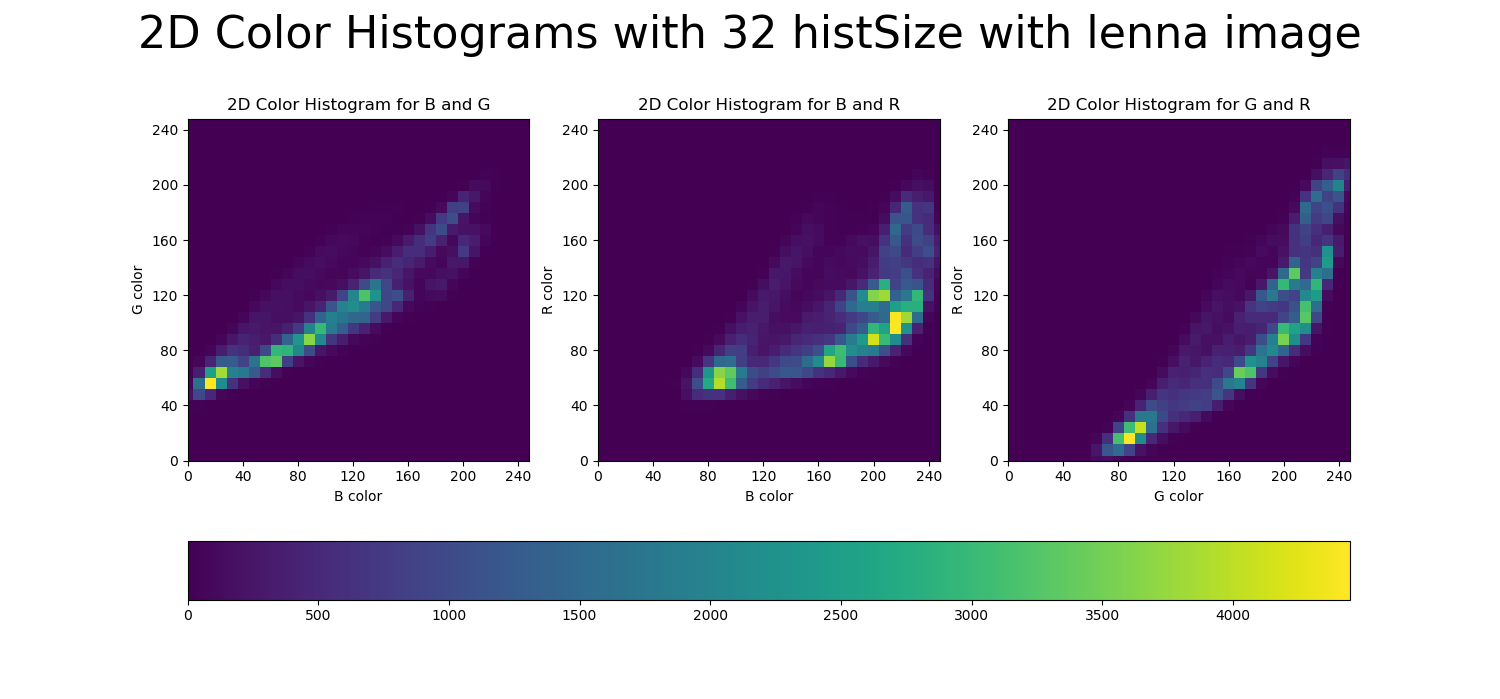
결과는 위와 같이 확인할 수 있습니다. 관련 내용은 본 포스트의 상단의 github을 참조하셔서 README를 읽고 실행해 보시면 되겠습니다.