Fully Convolutional Networks for Semantic Segmentation
2018, Aug 21
- 이번 글에서 다루어 볼 논문은
FCN으로 유명한 Fully Convolutional Networks for Semantic Segmentation 입니다.
목차
-
FCN의 배경
-
FCN 구조 설명 - downsampling
-
FCN 구조 설명 - upsampling
-
FCN 구조 설명 - skip connection
-
FCN 내용 정리
-
pytorch 코드
- 이 글에서는 FCN의 배경과 전체적인 네트워크 구조를 살펴보고 내용의 핵심이라 할 수 있는 Deconvolution 연산에 대하여 자세히 다루어 보도록 하겠습니다. 마지막으로 pytorch 코드 까지 살펴보겠습니다.
FCN의 배경
- 이미지 처리를 위한 딥러닝 네트워크의 시작은
CNN기반의 알렉스넷이 대회에서 성능을 거두면서 부터 시작되었습니다. - ‘12년도에
알렉스넷을 시작으로 다양한 딥러닝 기반의classification을 위한 네트워크가 고안되기 시작하였고 - ‘14년도에
VGG와GoogLeNet그리고 ‘15년도에 대망의ResNet이 나오면서classification성능에 비약적인 발전이 있어왔습니다. - 이렇게
classification에서 좋은 성능을 보인 CNN 기반의 딥러닝 네트워크를Localization이나Segmentation에도 적용시켜서 성능 향상을 해보려는 시도가 있었고 그 결과 확인하게 된것들이FCN에 반영됩니다.
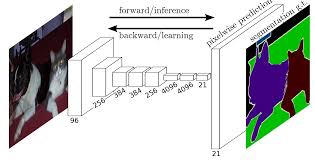
FCN 구조 설명 - downsampling

- 위 그림과 같이
classification을 할 때, 마지막 FC layer를 softmax로 출력을 하게 되면 확률 값이 나타나게 되고 가장 큰 확률값에 해당하는 클래스가 이미지에 해당하는 것으로 판단하게 됩니다. - 이와 같은 classification 작업에서는 물체의 위치 정보는 없고 단지 물체가 어떤 물체인지에 대한 확률 값만 가지게 됩니다. 즉, 물체의 위치 정보를 잃어버리게 되는 것이지요.
- 하지만 입력 값을 보면 이미지 내의 어떤 물체에 대한 공간 정보를 가지고 있었고 하위 레벨로 내려가면서도 그 공간 정보는 계속 가지고 있었습니다.
- 이런 공간 정보를 중간에 잃어버리게 되는 데 그 시점이 바로
fully connected layer가 되게 됩니다.- 왜냐하면
fully connected layer에서는 모든 노드들이 연결되어 버리기 때문입니다. (모든 노드들이 서로 곱해져서 더해지는 형태가 되지요)
- 왜냐하면
- 따라서 classifier 용도로 사용한
fully connected layer를 사용하면 안되겠다고 생각하게 됩니다.
- 그래서
fully connected layer를 대신하여 NIN(Network In Network, 1x1 Network)를 사용하게 됩니다.NIN은 현재 효율적인 네트워크 설계를 위해 많이 사용되었고(차원 축소 및 연산량 감소) 위에서 언급한Inception에서도 사용되었습니다.NIN은 이름 그대로 네트워크 에서 Multi layer perceptron의 역할을 수행하고 있습니다. (위 그림 참조)
Segmentation을 처리하기 위해서 공간 정보를 유지해야 하기 때문에fully connected layer자리 대신NIN을 넣게 되면 위 그림의 아래와 같이 volume 형태의 출력을 얻을 수 있습니다.- 이 결과를 heatmap으로 그려보면 공간 정보가 유지되고 있음을 확인할 수 있습니다.

- 앞에서 다룬 내용을 좀 더 입체적으로 표현한 것입니다.
- 위 그림의 아래 네트워크가
FCN에서 사용하는 방식의 앞부분 입니다. 즉,fully connected layer가 사라진 것이지요. 대신에NIN을 사용해서 차원을 축소하였습니다. - 이것을 이미지 크기로 복원하려면 다시
upsample하는 작업이 필요한데, 그것은 아래 글에서 계속 알아보겠습니다. - 먼저 여기까지 한 작업을 보면 마치 정보를 압축하는
encoder역할을 한것으로 볼 수 있습니다.featuer를 추출한 것으로 볼 수 있습니다.

- 참고로 segmentation에서 나타나는 전체적인 구조에서 네트워크의 사이즈가 줄어들었다가 다시 입력크기로 크게 만들때, 각 layer의 feature들의 해상도가 다른데, 이것들을 마지막 layer에서 concat을 하는 등의 합치는 작업을 하면 성능 개선에 도움이 되는 트릭을 사용하였습니다.
- 이 트릭을
fuse feature into depp jet이라고 하며 object detection의ssd에서도 사용되었습니다.
- 이 트릭을
- 해상도 관련 문제는 segmentaion 결과가 뭉게진 형태인 것으로 나타나는 문제인데 관련 그림은 아래
skip connection에서 확인해 보시면 됩니다.
FCN 구조 설명 - upsampling

- 지금까지 얘기한 것이
downsampling이었고 이제 downsample한 feature를 이미지 크기만큼 다시upsampling하는 방법에 대하여 다루어 보겠습니다. - feature의 크기를 다시 크게 하고 싶을 때 가장 쉽게 생각 할 수 있는 것은 bilinear interpolation 같은 방법일 수 있습니다.
- 물론 이런 간단한 방법으로는 성능이 나오지 않기 때문에 다른 방법이 고안되었는데요..
- encoder 단에서 convolution 연산을 하여 feature를 압축 시킬 때 필터의 parameter를 학습하듯이 decoder 단에서
deconvolution연산 이란 것을 해보고 그 결과 feature를 다시 팽창 시킬 때에도 parameter를 학습해보자는 것이 컨셉입니다.- inference 결과를 보면 이 방법이 훨씬 효과적인 것을 확인할 수 있고 직관적으로도 좀 더 딥러닝 네트워크에 가까운 것을 알 수 있습니다.
FCN 구조 설명 - skip connection

- 앞에서 설명한 해상도 문제가 위 그림의 아래 부분과 같습니다.
- 가장 왼쪽의 segmentation 결과를 보면 클래스별로 잘 구분해서 segmentation 하였지만 저해상도와 같이 뭉개져 있는 느낌이 들고 세세한 부분은 부정확하게 segmentation이 되어있습니다.
- 그래서 고해상도의 이미지 정보를 deconvolution 할 때 사용할 수 있도록 바로 전달해 주는
skip connection을 만들어 문제를 개선하였습니다. - 위 그림을 보면 각
대칭되는 네트워크 구조에 따라 각 단계별로skip connection이 만들어 지는 것을 볼 수 있고 skip connection을 여러개 넣을 때 더 성능이 좋아지는 것을 볼 수 있습니다. - 그러면
skip connection을 하는 자세한 방법에 대하여 바로 아래에서 다루어 보도록 하겠습니다.

- 위 그림을 보면
skip connection을 하는 간단한 방법을 확인하실 수 있습니다. - 그림에서
FCN-32s,FCN-16s,FCN-8s와 같이 표현이 되어 있는데 이것은FCN이 어떤 skip connection과 연결되고 그 결과 몇 배 upsampling한 지와 연관되어 있습니다. - 먼저
FCN-32s부터 살펴보면pool5에서 skip connection 없이 바로 32배upsampling하였습니다. - 그 다음
FCN-16s를 보면pool5를 2배 upsampling을 한 다음에pool4와sum을 합니다. 이것을 16배upsampling하여 원본 크기로 복원합니다. (그래서 이름이 FCN-16s 입니다.) - 한 단계 더 나아가서
FCN-16s에서 sum한 결과를 다시 2배 upsampling 합니다. 그리고pool3와sum을 합니다. 이것을 8배upsampling하여 원본 크기로 복원합니다.

- 기대(?)했던 것과 같이
FCN-8s가 성능이 가장 좋습니다. 이유는 Encoder 부분에서 압축된 부분을 원본에 가까운 상대적으로 고해상도 영역의 이미지와 sum을 하여 저해상도 문제를 개선할 수 있기 때문입니다.
FCN 내용 정리
- 마지막으로
FCN내용에 대하여 정리해 보겠습니다.

FCN은 Segmentation을 하기 위한 딥러닝 네트워크 구조로 원본 이미지를 의미 있는 부분끼리 묶어서 분할하는 기법입니다.- 픽셀 단위의
classification을 하므로 이미지 전체 픽셀을 올바른 레이블로 분류해야 하는 다소 복잡한 문제입니다.
- 픽셀 단위의

- 만약 위 그림처럼 Input이 RGB (hetight x width x 3) 또는 흑백(height x width x 1)이미지 일 때
segmentation결과는 위의 오른쪽 그림과 같이segmentation map형태 (각 클래스별로 출력 채널을 만든 형태)로 나타나고 최종적으로argmax를 취합니다. - 즉, 하나의 이미지에서 모든 클래스의 segmentation이 된 결과를 얻기 위하여 한 장의 segmentation 이미지를 생성할 때, upsampling된 각 클래스 별 heatmap에서 가장 높은 확률을 가지는 클래스만 모아주는 것입니다.
- 따라서 output으로는 각 픽셀별로 어느 클래스에 속하는지 레이블을 나타내는 segmentation map이 되고 input과 사이즈는 같습니다.

- 알렉스넷이나 VGG등 classification 분류 문제에 자주 쓰인는 네트워크들은 파라미터의 개수와 차원을 줄이는 layer를 가지고 있어서 자세한 위치 정보를 잃게 됩니다. 따라서
segmentation에는 적합하지 않습니다. - 보통
segmentation모델들은downsampling(encoder)와upsampling(decoder)의 형태를 가지게 되는데 위 그림과 같습니다.

- 먼저
downsampling(encoder)은 차원을 줄이는 역할을 하게 되는데 stride를 2 이상으로 convolution을 하거나 pooling을 사용하면feature정보를 잃게 됩니다.

upsampling(decoder)는 downsampling을 통해서 받은 결과의 차원을 늘려서 Input과 같은 차원으로 만들어 주는 과정입니다.FCN에서는strided transpose convolution을 사용하여 차원을 늘려줍니다.

strided transpose convolution을 이해하기 위하여 1차원에서의 예를 살펴보면 위와 같습니다. 동일한 원리로 2차원에서 적용하면 이미지에서 사용한 transpose convolution 입니다.

FCN에서는classification에서 classifier로 사용한 FC layer를 버리고 위치 정보를 유지하기 위해 1x1 convolution layer를 사용하였습니다.- FC layer를 버림으로 인하여 위치 정보 유지 뿐 아니라 convolution layer만 사용하게 됨으로 input size의 제한도 받지 않게 되었습니다.
- 위 그림에서 각 영역별로 의미를 살펴보면
- 1) feature extraction : 일반적인 CNN의 구조에서 많이 보이는 convolution layer들로 구성됩니다.
- 2) feature level classification : 추출된 feature map 각각의 pixel 마다 classification을 수행합니다.
- 3) upsampling: strided transpose convolution을 통하여 원래의 이미지 사이즈로 키워줍니다.
- 4) segmentation: 각 클래스의 upsampling된 결과를 사용하여 하나의 segmentation 결과 이미지를 만들어줍니다.

- 다시 한번 언급하자면 위와 같은 FC layer를 가지고 있는 네트워크의 특징은 FC layer의 특성으로 인하여 고정된 크기의 입력만 받습니다.
- 반면 convolution layer만 있으면 이미지 크기에 제한이 없어지고 공간 정보도 유지되어 맨 마지막의 feature map의 1픽셀 값은 원 영상의 32 x 32를 대변하게 됩니다.

- 여러 단계의 convolution layer와 pooling layer를 거치면, feature map의 크기가 감소되나 픽셀 단위의 예측을 하기 위해서는 feature map의 결과를 다시 키우는 과정이 필요합니다.

- 1x1 convolution의 결과로 얻어진 Score 값을 원 영상의 크기로 확대하고 strided transpose convolution을 이용하여 필터의 파라미터를 학습을 통해 결정합니다.
- 그러나 score를 단순히 upsampling 하게 되면 성능에 한계가 발생하여 skip layer를 도입합니다.

- 이전 layer는 마지막 convolution layer의 결과보다 세밀한 Feature를 포함하고 있으므로 이전 layer들의 feature를 같이 사용하는 방법으로 좀 더 세밀한(고해상도) 이미지 정보를 얻을 수 있습니다. (FCN-32s < FCN-16s < FCN-8s)
pytorch 코드
- 아래 코드는
VGG를 back-bone으로 하는FCN입니다. 위에서 다룬 것 처럼FCN-32s, FCN-16s, FCN-8s를 구현하였습니다.
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import models
from torchvision.models.vgg import VGG
from BagData import dataloader
import pdb
import numpy as np
import time
import visdom
import numpy as np
class FCN32s(nn.Module):
def __init__(self, pretrained_net, n_class):
super().__init__()
self.n_class = n_class
self.pretrained_net = pretrained_net
self.relu = nn.ReLU(inplace=True)
self.deconv1 = nn.ConvTranspose2d(512, 512, kernel_size=3, stride=2, padding=1, dilation=1, output_padding=1)
self.bn1 = nn.BatchNorm2d(512)
self.deconv2 = nn.ConvTranspose2d(512, 256, kernel_size=3, stride=2, padding=1, dilation=1, output_padding=1)
self.bn2 = nn.BatchNorm2d(256)
self.deconv3 = nn.ConvTranspose2d(256, 128, kernel_size=3, stride=2, padding=1, dilation=1, output_padding=1)
self.bn3 = nn.BatchNorm2d(128)
self.deconv4 = nn.ConvTranspose2d(128, 64, kernel_size=3, stride=2, padding=1, dilation=1, output_padding=1)
self.bn4 = nn.BatchNorm2d(64)
self.deconv5 = nn.ConvTranspose2d(64, 32, kernel_size=3, stride=2, padding=1, dilation=1, output_padding=1)
self.bn5 = nn.BatchNorm2d(32)
self.classifier = nn.Conv2d(32, n_class, kernel_size=1)
def forward(self, x):
output = self.pretrained_net(x)
x5 = output['x5'] # size=(N, 512, x.H/32, x.W/32)
score = self.bn1(self.relu(self.deconv1(x5))) # size=(N, 512, x.H/16, x.W/16)
score = self.bn2(self.relu(self.deconv2(score))) # size=(N, 256, x.H/8, x.W/8)
score = self.bn3(self.relu(self.deconv3(score))) # size=(N, 128, x.H/4, x.W/4)
score = self.bn4(self.relu(self.deconv4(score))) # size=(N, 64, x.H/2, x.W/2)
score = self.bn5(self.relu(self.deconv5(score))) # size=(N, 32, x.H, x.W)
score = self.classifier(score) # size=(N, n_class, x.H/1, x.W/1)
return score # size=(N, n_class, x.H/1, x.W/1)
class FCN16s(nn.Module):
def __init__(self, pretrained_net, n_class):
super().__init__()
self.n_class = n_class
self.pretrained_net = pretrained_net
self.relu = nn.ReLU(inplace=True)
self.deconv1 = nn.ConvTranspose2d(512, 512, kernel_size=3, stride=2, padding=1, dilation=1, output_padding=1)
self.bn1 = nn.BatchNorm2d(512)
self.deconv2 = nn.ConvTranspose2d(512, 256, kernel_size=3, stride=2, padding=1, dilation=1, output_padding=1)
self.bn2 = nn.BatchNorm2d(256)
self.deconv3 = nn.ConvTranspose2d(256, 128, kernel_size=3, stride=2, padding=1, dilation=1, output_padding=1)
self.bn3 = nn.BatchNorm2d(128)
self.deconv4 = nn.ConvTranspose2d(128, 64, kernel_size=3, stride=2, padding=1, dilation=1, output_padding=1)
self.bn4 = nn.BatchNorm2d(64)
self.deconv5 = nn.ConvTranspose2d(64, 32, kernel_size=3, stride=2, padding=1, dilation=1, output_padding=1)
self.bn5 = nn.BatchNorm2d(32)
self.classifier = nn.Conv2d(32, n_class, kernel_size=1)
def forward(self, x):
output = self.pretrained_net(x)
x5 = output['x5'] # size=(N, 512, x.H/32, x.W/32)
x4 = output['x4'] # size=(N, 512, x.H/16, x.W/16)
score = self.relu(self.deconv1(x5)) # size=(N, 512, x.H/16, x.W/16)
score = self.bn1(score + x4) # element-wise add, size=(N, 512, x.H/16, x.W/16)
score = self.bn2(self.relu(self.deconv2(score))) # size=(N, 256, x.H/8, x.W/8)
score = self.bn3(self.relu(self.deconv3(score))) # size=(N, 128, x.H/4, x.W/4)
score = self.bn4(self.relu(self.deconv4(score))) # size=(N, 64, x.H/2, x.W/2)
score = self.bn5(self.relu(self.deconv5(score))) # size=(N, 32, x.H, x.W)
score = self.classifier(score) # size=(N, n_class, x.H/1, x.W/1)
return score # size=(N, n_class, x.H/1, x.W/1)
class FCN8s(nn.Module):
def __init__(self, pretrained_net, n_class):
super().__init__()
self.n_class = n_class
self.pretrained_net = pretrained_net
self.relu = nn.ReLU(inplace=True)
self.deconv1 = nn.ConvTranspose2d(512, 512, kernel_size=3, stride=2, padding=1, dilation=1, output_padding=1)
self.bn1 = nn.BatchNorm2d(512)
self.deconv2 = nn.ConvTranspose2d(512, 256, kernel_size=3, stride=2, padding=1, dilation=1, output_padding=1)
self.bn2 = nn.BatchNorm2d(256)
self.deconv3 = nn.ConvTranspose2d(256, 128, kernel_size=3, stride=2, padding=1, dilation=1, output_padding=1)
self.bn3 = nn.BatchNorm2d(128)
self.deconv4 = nn.ConvTranspose2d(128, 64, kernel_size=3, stride=2, padding=1, dilation=1, output_padding=1)
self.bn4 = nn.BatchNorm2d(64)
self.deconv5 = nn.ConvTranspose2d(64, 32, kernel_size=3, stride=2, padding=1, dilation=1, output_padding=1)
self.bn5 = nn.BatchNorm2d(32)
self.classifier = nn.Conv2d(32, n_class, kernel_size=1)
def forward(self, x):
output = self.pretrained_net(x)
x5 = output['x5'] # size=(N, 512, x.H/32, x.W/32)
x4 = output['x4'] # size=(N, 512, x.H/16, x.W/16)
x3 = output['x3'] # size=(N, 256, x.H/8, x.W/8)
score = self.relu(self.deconv1(x5)) # size=(N, 512, x.H/16, x.W/16)
score = self.bn1(score + x4) # element-wise add, size=(N, 512, x.H/16, x.W/16)
score = self.relu(self.deconv2(score)) # size=(N, 256, x.H/8, x.W/8)
score = self.bn2(score + x3) # element-wise add, size=(N, 256, x.H/8, x.W/8)
score = self.bn3(self.relu(self.deconv3(score))) # size=(N, 128, x.H/4, x.W/4)
score = self.bn4(self.relu(self.deconv4(score))) # size=(N, 64, x.H/2, x.W/2)
score = self.bn5(self.relu(self.deconv5(score))) # size=(N, 32, x.H, x.W)
score = self.classifier(score) # size=(N, n_class, x.H/1, x.W/1)
return score # size=(N, n_class, x.H/1, x.W/1)
class FCNs(nn.Module):
def __init__(self, pretrained_net, n_class):
super().__init__()
self.n_class = n_class
self.pretrained_net = pretrained_net
self.relu = nn.ReLU(inplace=True)
self.deconv1 = nn.ConvTranspose2d(512, 512, kernel_size=3, stride=2, padding=1, dilation=1, output_padding=1)
self.bn1 = nn.BatchNorm2d(512)
self.deconv2 = nn.ConvTranspose2d(512, 256, kernel_size=3, stride=2, padding=1, dilation=1, output_padding=1)
self.bn2 = nn.BatchNorm2d(256)
self.deconv3 = nn.ConvTranspose2d(256, 128, kernel_size=3, stride=2, padding=1, dilation=1, output_padding=1)
self.bn3 = nn.BatchNorm2d(128)
self.deconv4 = nn.ConvTranspose2d(128, 64, kernel_size=3, stride=2, padding=1, dilation=1, output_padding=1)
self.bn4 = nn.BatchNorm2d(64)
self.deconv5 = nn.ConvTranspose2d(64, 32, kernel_size=3, stride=2, padding=1, dilation=1, output_padding=1)
self.bn5 = nn.BatchNorm2d(32)
self.classifier = nn.Conv2d(32, n_class, kernel_size=1)
def forward(self, x):
output = self.pretrained_net(x)
x5 = output['x5'] # size=(N, 512, x.H/32, x.W/32)
x4 = output['x4'] # size=(N, 512, x.H/16, x.W/16)
x3 = output['x3'] # size=(N, 256, x.H/8, x.W/8)
x2 = output['x2'] # size=(N, 128, x.H/4, x.W/4)
x1 = output['x1'] # size=(N, 64, x.H/2, x.W/2)
score = self.bn1(self.relu(self.deconv1(x5))) # size=(N, 512, x.H/16, x.W/16)
score = score + x4 # element-wise add, size=(N, 512, x.H/16, x.W/16)
score = self.bn2(self.relu(self.deconv2(score))) # size=(N, 256, x.H/8, x.W/8)
score = score + x3 # element-wise add, size=(N, 256, x.H/8, x.W/8)
score = self.bn3(self.relu(self.deconv3(score))) # size=(N, 128, x.H/4, x.W/4)
score = score + x2 # element-wise add, size=(N, 128, x.H/4, x.W/4)
score = self.bn4(self.relu(self.deconv4(score))) # size=(N, 64, x.H/2, x.W/2)
score = score + x1 # element-wise add, size=(N, 64, x.H/2, x.W/2)
score = self.bn5(self.relu(self.deconv5(score))) # size=(N, 32, x.H, x.W)
score = self.classifier(score) # size=(N, n_class, x.H/1, x.W/1)
return score # size=(N, n_class, x.H/1, x.W/1)
class VGGNet(VGG):
def __init__(self, pretrained=True, model='vgg16', requires_grad=True, remove_fc=True, show_params=False):
super().__init__(make_layers(cfg[model]))
self.ranges = ranges[model]
if pretrained:
exec("self.load_state_dict(models.%s(pretrained=True).state_dict())" % model)
if not requires_grad:
for param in super().parameters():
param.requires_grad = False
if remove_fc: # delete redundant fully-connected layer params, can save memory
del self.classifier
if show_params:
for name, param in self.named_parameters():
print(name, param.size())
def forward(self, x):
output = {}
# get the output of each maxpooling layer (5 maxpool in VGG net)
for idx in range(len(self.ranges)):
for layer in range(self.ranges[idx][0], self.ranges[idx][1]):
x = self.features[layer](x)
output["x%d"%(idx+1)] = x
return output
ranges = {
'vgg11': ((0, 3), (3, 6), (6, 11), (11, 16), (16, 21)),
'vgg13': ((0, 5), (5, 10), (10, 15), (15, 20), (20, 25)),
'vgg16': ((0, 5), (5, 10), (10, 17), (17, 24), (24, 31)),
'vgg19': ((0, 5), (5, 10), (10, 19), (19, 28), (28, 37))
}
# cropped version from https://github.com/pytorch/vision/blob/master/torchvision/models/vgg.py
cfg = {
'vgg11': [64, 'M', 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],
'vgg13': [64, 64, 'M', 128, 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],
'vgg16': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'M', 512, 512, 512, 'M', 512, 512, 512, 'M'],
'vgg19': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 256, 'M', 512, 512, 512, 512, 'M', 512, 512, 512, 512, 'M'],
}
def make_layers(cfg, batch_norm=False):
layers = []
in_channels = 3
for v in cfg:
if v == 'M':
layers += [nn.MaxPool2d(kernel_size=2, stride=2)]
else:
conv2d = nn.Conv2d(in_channels, v, kernel_size=3, padding=1)
if batch_norm:
layers += [conv2d, nn.BatchNorm2d(v), nn.ReLU(inplace=True)]
else:
layers += [conv2d, nn.ReLU(inplace=True)]
in_channels = v
return nn.Sequential(*layers)
if __name__ == "__main__":
vis = visdom.Visdom()
vgg_model = VGGNet(requires_grad=True)
fcn_model = FCNs(pretrained_net=vgg_model, n_class=2)
fcn_model = fcn_model.cuda()
criterion = nn.BCELoss().cuda()
optimizer = optim.SGD(fcn_model.parameters(), lr=1e-2, momentum=0.7)
#input = torch.autograd.Variable(torch.randn(batch_size, 3, h, w))
#y = torch.autograd.Variable(torch.randn(batch_size, n_class, h, w), requires_grad=False)
saving_index =0
for epo in range(100):
saving_index +=1
index = 0
epo_loss = 0
start = time.time()
for item in dataloader:
index += 1
start = time.time()
input = item['A']
y = item['B']
input = torch.autograd.Variable(input)
y = torch.autograd.Variable(y)
input = input.cuda()
y = y.cuda()
optimizer.zero_grad()
output = fcn_model(input)
output = nn.functional.sigmoid(output)
loss = criterion(output, y)
loss.backward()
iter_loss = loss.data[0]
epo_loss += iter_loss
optimizer.step()
output_np = output.cpu().data.numpy().copy()
output_np = np.argmin(output_np, axis=1)
y_np = y.cpu().data.numpy().copy()
y_np = np.argmin(y_np, axis=1)
if np.mod(index, 20) ==1:
print('epoch {}, {}/{}, loss is {}'.format(epo, index, len(dataloader), iter_loss))
vis.close()
vis.images(output_np[:, None, :, :], opts=dict(title='pred'))
vis.images(y_np[:, None, :, :], opts=dict(title='label'))
#plt.subplot(1, 2, 1)
#plt.imshow(np.squeeze(y_np[0, :, :]), 'gray')
#plt.subplot(1, 2, 2)
#plt.imshow(np.squeeze(output_np[0, :, :]), 'gray')
#plt.pause(0.5)
print('epoch loss = %f'%(epo_loss/len(dataloader)))
if np.mod(saving_index, 5)==1:
torch.save(fcn_model, 'checkpoints/fcn_model_{}.pt'.format(epo))
print('saveing checkpoints/fcn_model_{}.pt'.format(epo))