OSVOS, One-Shot Video Object Segmentation
2021, Mar 20
- 논문 : https://arxiv.org/abs/1611.05198
- 공식 페이지 : https://cvlsegmentation.github.io/osvos/
- 깃헙 : https://github.com/kmaninis/OSVOS-PyTorch
- 참조 : https://eungbean.github.io/2019/07/03/OSVOS/
- 이번 글에서는
Video Object Segmentation관련 논문에서 가장 인용수가 많고 성능 육성에 큰 영향을 준 OSVOS, One-Shot Video Object Segmentation (S. Caelles,K.-K. Maninis, CVPR 2017)에 대하여 알아보도록 하곘습니다. - 먼저 Video Object Segmentation 문제의 정의는 동영상에서 특정 물체를 연속적으로 세그멘테이션 하는 작업을 뜻합니다. 이와 유사하게 Sementic Segmentation은 동영상 또는 이미지에서 특정 물체가 아닌 배경을 포함한 모든 물체를 대상으로 세그멘테이션하는 것입니다. 따라서 Video Object Segmentation과 Sementic Segmentation에는 세그멘테이션 하는 대상에 차이가 있습니다.
목차
Introduction
- OSVOS 논문에서는 One-Shot 방법을 적용하여 Video Ojbect Segmentation 하는 방법에 대하여 다룹니다. 딥러닝에서 One shot이란 한 번 타겟을 보고 작업을 수행하는 것을 뜻합니다.

- 이 논문에서 다루는 One Shot의 의미는 첫 프레임(또는 그 이상의 프레임)에서 찾고자 하는 물체에 마스크를 제공하면 나머지 프레임에서 같은 물체를 찾아내는 방법을 뜻합니다. 이러한 방식의 VOS를
semi-supervised video object segmentation이라고 합니다. 위 예제를 참조하시기 바랍니다.
- 논문에서는 주요 Contribution으로 다음 3가지를 설명합니다.

- 첫 프레임의 Object를 Segment해주기만 하면 나머지 프레임에서도 물체를 찾아낼 수 있습니다.

- 딥러닝을 사용하면 각 프레임을 독립적으로 연산하더라도
Temporal Consistency를 얻을 수 있어서 Occlusion등에 강건한 장점을 가집니다. - 여기서
Temporal Consistency는 동영상에서 연속적인 시간에서 일관성을 가질 수 있도록 하는 것을 뜻합니다.

- 마지막으로 속도와 성능간의 Trade-off가 자유롭도록 모델을 설계할 수 있다는 점입니다.
One Shot Deep Learning
- One-shot이란, 학습 과정에서 모든 프레임에 대한 GT를 알려주는 대신, 첫 프레임의 GT를 알려주는 것으로 나머지 프레임에서 물체를 학습할 수 있도록 하는 기법을 말합니다.
- 보통 물체를 구분할 때, ① 물체와 배경을 먼저 구분하고 ② 물체 중에서 내가 찾는 물체외 그 이외의 물체를 구분합니다.
OSVOS에서는off-line방식을 이용하여 배경으로부터 물체를 분리하도록 학습하고on-line방식을 이용하여 분리된 물체 중 특정한 물체를 구별하도록 학습시킵니다.on-line방식은 주어진 첫 프레임으로 모델을 학습시키는 방법이고,off-line방식은 on-line과 같이 첫 프레임으로 별도 학습하지 않는 방법을 뜻합니다.on-line방식은 특정 object에 대하여 성능을 높이기 위하여 추가 학습을 하기 때문에 보통 성능이 높지만 특정 object에 대한 학습이 먼저 수행 되어야 하는 단점이 있습니다. 반면,off-line방식은 추가 학습이 별도 필요 없으나 on-line에 비해 성능이 약간 낮습니다.- 정리하면
OSVOS에서는 ① 물체와 배경을 먼저 구분할 때에는off-line학습 방식을 이용하여 비디오 전체를 모두 학습한 다음에 output으로 배경과 물체를 구분하는 비디오를 생성하고 그 결과를 통하여 ②on-line추가 학습 방식을 이용하여 각 프레임 별 관심이 되는 대상 물체를 별도로 학습한 다음에 프레임 별 결과를 출력합니다.

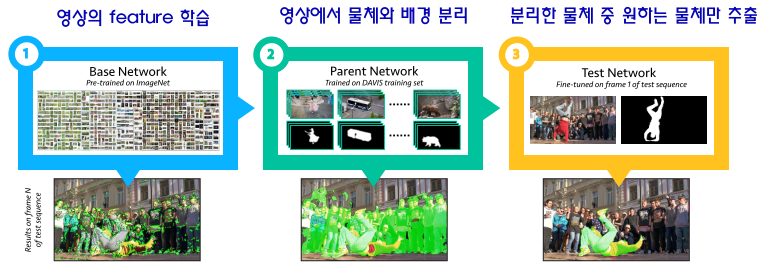
- OSVOS는 크게 3가지 단계를 이용하여 학습을 합니다. 위 그림과 같이
Base Network,Parent Network,Test Network가 이에 해당합니다. Base Network: 이미지넷에서 학습된 backbone 네트워크를 이용하여 영상의 feature를 얻습니다. 여기서는 ImageNet에 학습이 잘 된 VGG 백본 기반의 FCN 네트워크를 가져와서 사용하였습니다. 즉, static image로 먼저 학습을 하였습니다.
Parent Network: Base Network와DAVIS 데이터 셋을 이용하여 영상에서 모든 픽셀에 대하여 물체와 배경을 분리하는 binary classification 네트워크를 학습합니다. 이 때, 학습 데이터는 Dadvis Dataset의Binary Mask를 학습합니다.- 좀 더 자세하 살펴보면
VGG네트워크를 기반으로 각 state의 feature를 추출하고 원래 이미지 사이즈로 upscale 한 뒤 그 결과를 Linearly Fuse 합니다. 이 때, 사용되는 Loss는 다음과 같습니다.

- 위 Loss를 살펴보면 Binary classification을 위한 Pixel-wise cross entropy를 의미합니다. 하지만 이 경우 두 binary label의 imbalance 문제가 발생합니다. 왜냐하면 배경 클래스 많은 이미지가 많기 떄문입니다. 이를 개선하기 위하여 Loss를 다음과 같이 수정하였습니다.

Test Network: Parent Network를 통하여 배경으로 부터 분리된 Object들 중 특정 Object만을 세그멘테이션 할 수 있도록 하는 네트워크 입니다. 여기서One-Shot개념이 등장합니다. 첫 프레임에서 원하는 물체만 분리한Binary Mask를 제공해야 합니다. 그럼 네트워크는 첫 프레임의 Target Object Mask를 이용하여 나머지 프레임의 Target Object까지 정확하게 분리할 수 있게 됩니다. 이 과정은 흔히 알고 있는 fine-tuning과 같습니다. 이on-line과정에 학습 시간을 많이 할당 할수록 특정 물체에 대한 세그멘테이션 성능이 향상됩니다.
Contour snapping
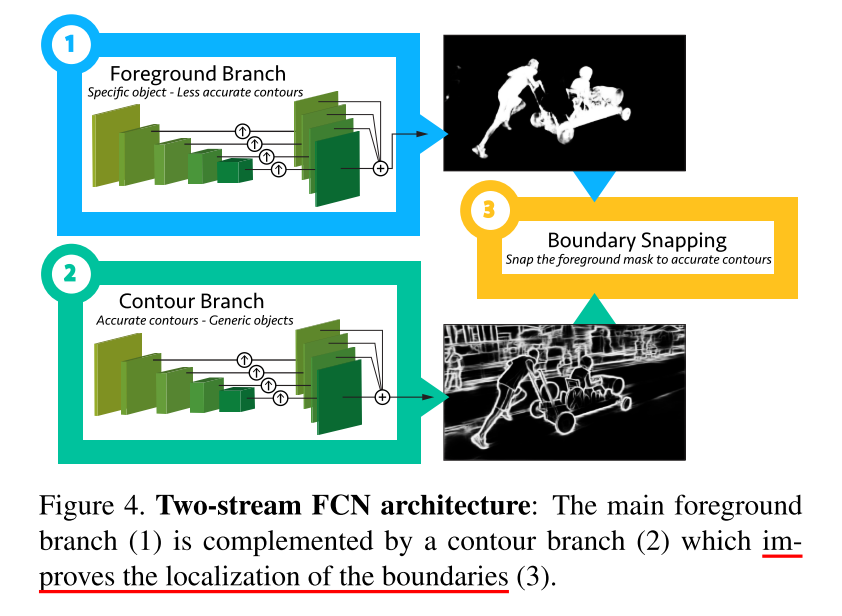
- 추가적으로 영상에서 물체를 더욱 정확하게 찾기 위해서,
Coutour Snapping방법을 적용하였습니다. 앞서 설명했던 Foreground Branch만을 사용하게 되면, 물체의 윤곽선이 비교적 부정확한 것을 알 수 있습니다. 이를 보정하기 위하여 두번째 네트워크인Contour Branch를 두어 다음과 같은 과정을 거칩니다. - 위 그림과 같이 ① 물체를 찾는 네트워크, ② Contour를 찾는 네트워크를 학습한 후 이 결과를 융합하여 더욱 정확한 결과를 얻어내었습니다. 저자는 이 융합하는 과정을 Contour Snapping 이라고 말하였습니다.
- Contour Branch Network는 기본적으로 Foreground를 학습할 때와 같은 구조를 가집니다. 차이점은 학습 데이터에 있습니다. Foreground Branch는 GT Binary로 Binary Mask를 학습한 반면 Contour Branch는 Contour를 학습하기 위하여 PASCAL-Context Dataset을 학습합니다.
- 두 네트워크에서 Foreground와 Contour를 얻으면 이를 합쳐주는 Snapping 작업을 합니다.
Experimental Validation
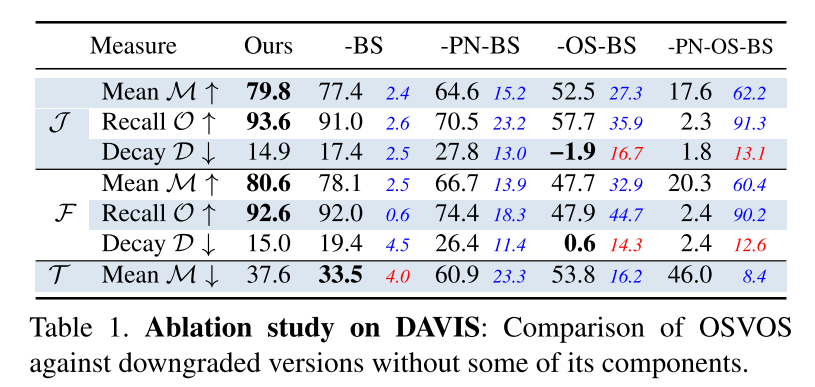
OSVOS의 결과를 살펴보면 Ours가 모든 결과를 적용한 내용이고,-BS는 without boundary snapping,-PN은 without pre-training the parent network on DAVIS,-OS는 without performing the one-shot learning on the specific sequence를 뜻합니다.- 위 결과를 살펴보면
OS를 뺏을 때, 가장 큰 성능 열화가 발생하는 것을 통해 특정 물체에 대하여on-line learning을 하는 것이 그 특정 물체를 찾는 문제에 대하여 성능 향상이 많이 되는 것을 알 수 있습니다. 논문에서는 Fine-tuning에 시간을 더 사용할 수록 성능 개선이 발생하였지만 어느 순간 부터 수렴되는 것을 확인 하였습니다. - 또한
PN과 관련하여 Parent Network를 학습할 때, 이미지가 많을 수록 성능이 좋지만 200장 정도에서 부터는 수렴이 되었다고 합니다.
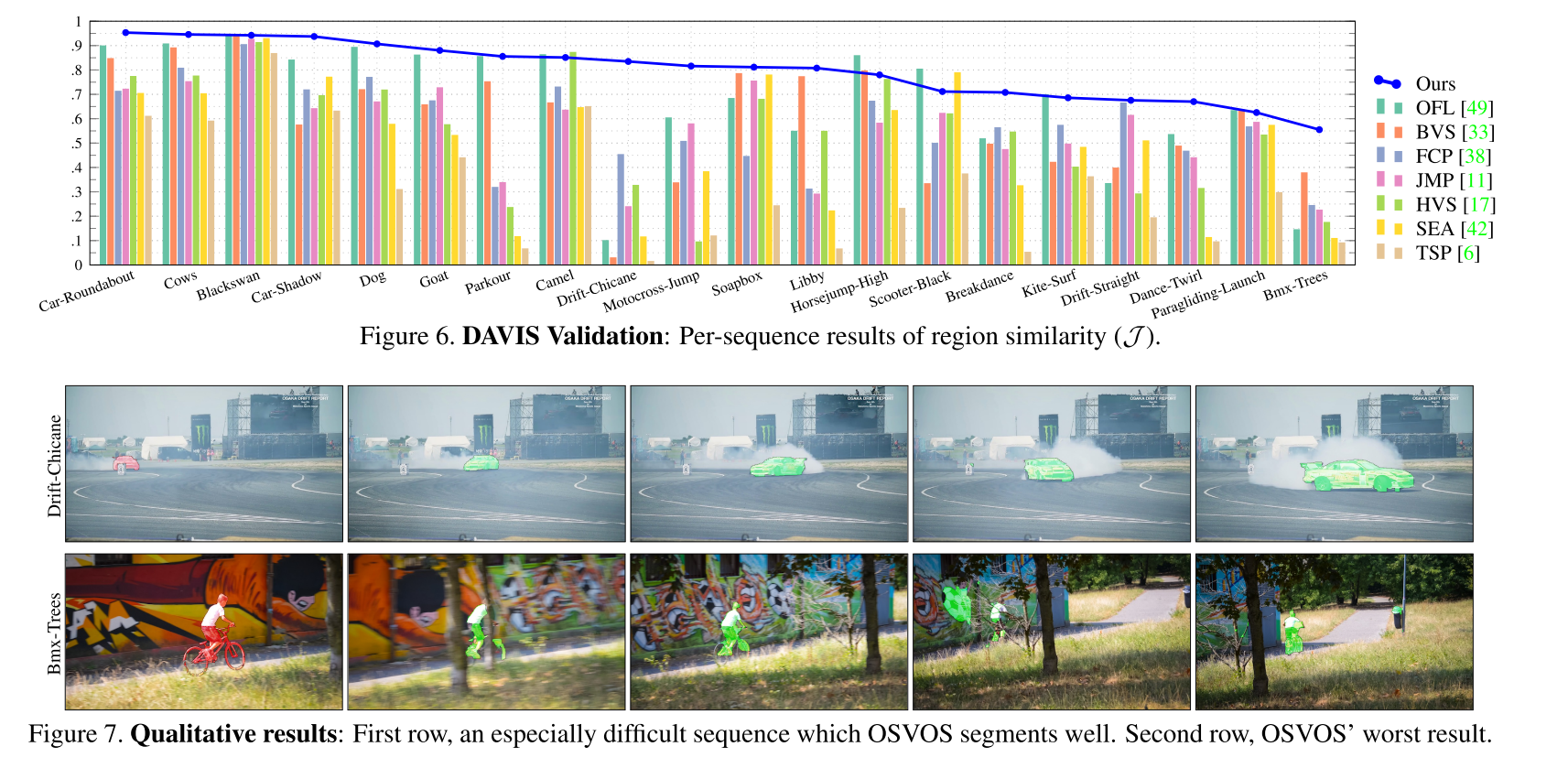
- 실험 결과를 살펴보면 그 당시의 다른 방법에 비해서는 성능이 좋은 것을 확인할 수 있습니다. 다만, 2020년 시점에서는 더 이상 OSVOS와 같은 방법을 사용하지는 않는 추세입니다.
- 먼저
OSVOS에 비하여 더 성능이 좋은 방법들이 많이 도입되었고,on-line learning은 특정 물체에 대해서 특화되는 학습 방법이라서 범용적으로 사용하기 어려운 한계가 있기 때문입니다. 따라서off-line learning방식 만으로 범용적으로 성능을 만들어 낼 수 있는 방법이 선호도가 높습니다.