PSPNet(Pyramid Scene Parsing Network)
2020, Oct 05
- 참조 : https://youtu.be/siwbdHhQPXE?list=WL
- 참조 : https://arxiv.org/pdf/1612.01105.pdf
- 참조 : https://intuitive-robotics.tistory.com/50?category=755664
목차
-
PSPNet의 소개
-
Local Context Information과 Global Context Information
-
Pyramid Pooling Module
-
실험 결과
-
Pytorch Code
PSPNet의 소개
- 이 글에서 알아볼
Pyramid Scene Parsing Network, 줄여서PSPNet은 CVPR 2017에서 발표된 Semantic Segmentation 모델입니다. - 먼저 용어에 대하여 알아보면
Semantic Segmentation은 각각의 픽셀에 대하여 알려진 객체에 한하여 카테고리화 하는 것을 말합니다. 반면Scene Parsing의 경우 이미지 내의 모든 픽셀에 대하여 카테고리화 하는 것을 뜻합니다. 즉, Scence Parsing 작업을 하였을 때, 이미지의 모든 픽셀을 대상으로 정보값이 있어야 합니다. - 그러면 Scence Parsing의 개념을 이해하고 PSPNet의 성능을 살펴보도록 하겠습니다. 앞으로 용어는 관용적으로 세그멘테이션으로 통일하겠습니다.
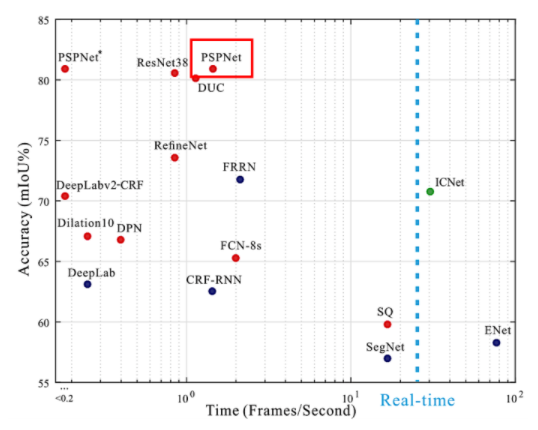
- 위 그래프와 같이 성능 지표를 살펴보면 PSPNet은 높은 정확도 성능을 가지지만 1.5 FPS로 실시간으로 사용할 수 없는 느린 수행 속도를 가집니다.
- 비록 수행 속도가 느린 모델이긴 하지만 대표적인 데이터셋인 CityScape에서 80.2% 의 정확도를 얻은 만큼 좋은 성능을 가지므로 PSPNet의 주요 아이디어를 통해 배울점이 있어 보입니다.
- PSPNet의 특징을 살펴보기 위하여 아래 그림과 같이 가장 기본적인 Segmentation 모델인 FCN과 비교하여 살펴보도록 하곘습니다.
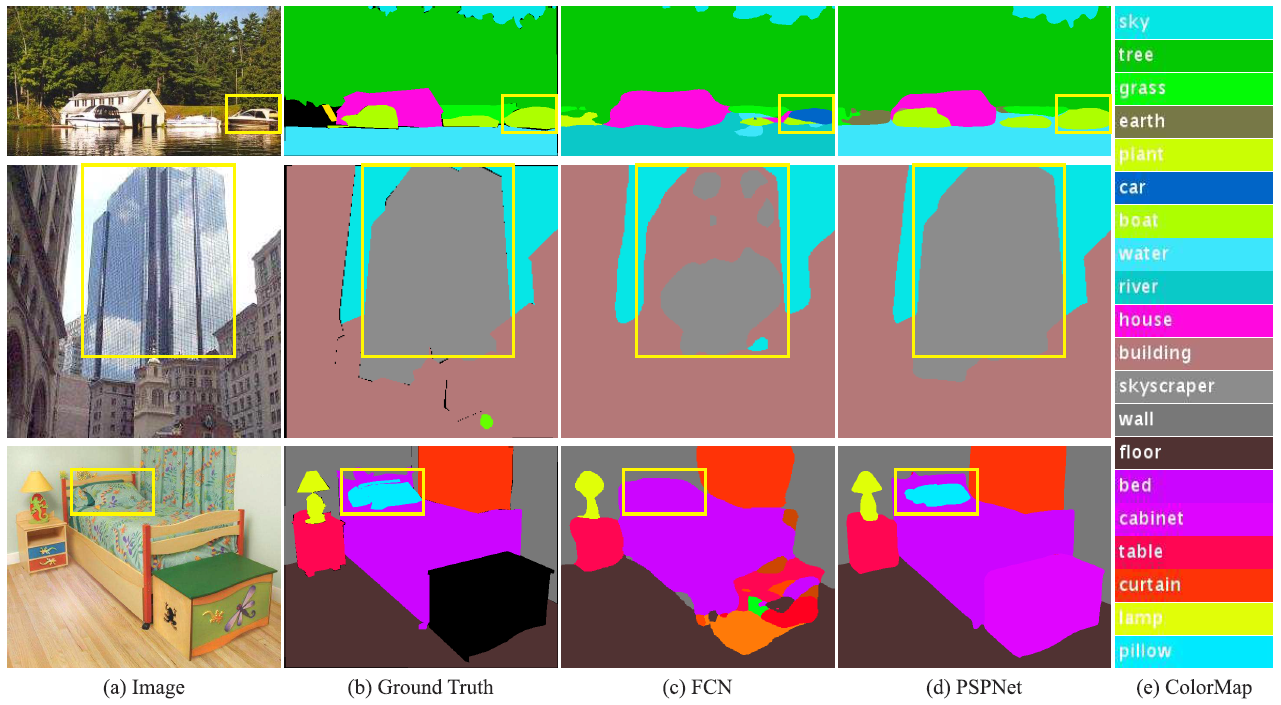
- 먼저 위 그림을 통해
FCN과PSPNet을 비교하여 기존의 FCN과 같은 세그멘테이션 모델의 문제점을 확인할 수 있습니다. Mismatched Relationship: 주변 상황가 맞지 않는 픽셀 클래스 분류를 뜻합니다.- 가장 위쪽의 호수 이미지에서, 노란색 박스의 영역은 보트로 분류가 되어야 합니다.
- 하지만 성능이 좋지 못한 FCN에서는 노란색 박스 영역을 자동차로 분류하였습니다.
- 노란색 영역에서 보트의 일부가 가려졌기 때문에 주변 상황을 고려하지 않고 노란색 박스 영역 내부만 살펴보면 자동차로 분류할 가능성도 있어보입니다.
- 하지만 상식적으로 물 위에 있는 물체는 자동차가 아니라 보트로 분류되는 것이 타당합니다.
Confusion Categories: 헷갈릴 수 있는 픽셀 클래스 분류를 뜻합니다.- 가운데 도시 그림에서의 핵심은 노란색 박스 영역입니다. 이 영역을 보면 유리 창으로 둘러 쌓인 높은 빌딩에서 하늘 모습이 비칩니다.
- FCN은 빌딩의 일부 영역을 skyscraper로 오분류하였습니다. 반면 PSPNet에서는 정확하게 빌딩으로 분류할 수 있었습니다.
Inconspicuous Classes: 눈에 잘 띄지 않는 물체의 픽셀 클래스 분류를 뜻합니다.- 가장 아랫쪽 그림의 노란색 박스를 자세히 보면 이불과 비슷한 모양의 베개가 있습니다. 주변 형상과 비슷하여 눈에 잘 띄지 않는 물체 케이스입니다.
- PSPNet에서는 전체적인 scence을 이해하여 베개를 정확하게 분류할 수 있었습니다.
- 위 3가지 문제인 Mismatched Relationship, Confusion Categories, Inconspicuous Classes를 개선하기 위해서 PSPNet과 같이
global information을 사용해야 합니다.
Local Context Information과 Global Context Information
- 앞에서 PSPNet은 global information을 잘 사용하여 3가지 문제를 개선할 수 있었다고 언급하였습니다. 여기서 말하는 global information에 대하여 정확히 이해하기 위하여
Local Context Information과Global Context Information에 대하여 알아보도록 하겠습니다.
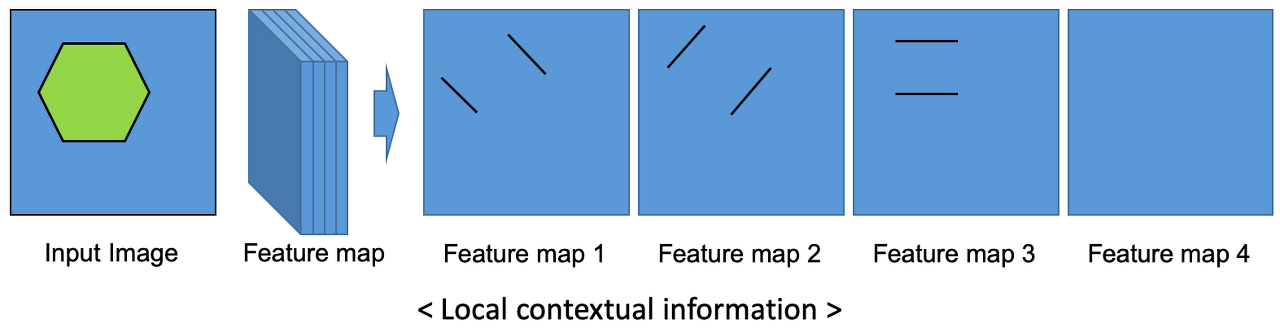
- 먼저 local context information을 이해하기 위해 위 그림을 살펴보도록 하겠습니다.
- 위 그림의 육각형과 같이 어떤 영역의 형상을 인식 하기 위해서는 그 형상에 대응하는 feature들을 추출해야 합니다.
- 위 그림에서는 feature map에 육각형을 인식할 수 있는 feature들이 있습니다. 예를 들어 feature map을 한개씩 살펴보면 feature map1에서는 왼쪽 대각선을, feature map2에서는 오른쪽 대각선을, 그리고 feature map3에서는 수평선을 인식하는 필터 역할을 합니다.
- 왜냐하면 입력된 이미지와 feature map에서의 feature 간 연산으로 변화량이 큰 지점을 찾게 되기때문입니다. 따라서 feature map과 입력 이미지의 연산에 따라 위 예제에서 대각선과 수평선의 변화량이 커서 육각형을 인식할 수 있게 됩니다.
- 위 과정을 살펴보면 각각의 feature map들은 feature map들이 가지는 값에 따라 다양한 필터 역할을 가질 수 있으며 feature map의 핵심이 되는 영역과 이에 대응되는 입력 이미지의 특정 영역에서 물체를 인지할 수 있습니다. 즉, 앞에서 언급한 global한 영역을 보지는 않습니다.
- 이와 같은 Local context information에 해당하는 대표적인 정보로는 모양, 형상, 재질의 특성등이 있습니다. 즉, 특정 영역의 고유 정보(모양, 형상, 재질등)에 해당합니다.
- FCN의 경우 가장 기본적인 Convolution / Transposed Convolution을 사용하므로
Local context information만 고려하게 됩니다. 따라서 PSPNet에 비해 성능이 낮습니다.

- 반면 PSPNet에서는 노란색 박스의 영역을 보트로 정확하게 분류할 수 있습니다.
- 왜냐하면 FCN의 경우와는 다르게 PSPNet에서는
Global context information을 사용하기 때문입니다. - 즉, 어떤 픽셀값의 클래스를 분류하기 위해 단순히 그 근처의 local 정보들만 이용하지 않고 좀 더 넓은 영역(Global)을 고려합니다.
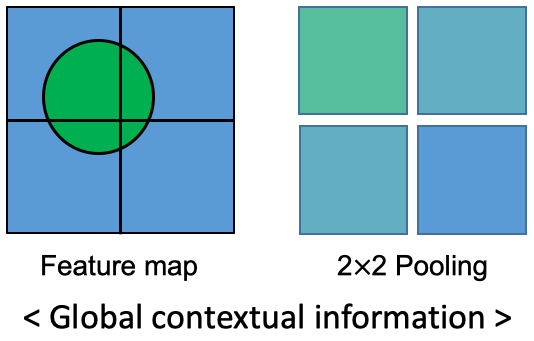
- CNN을 통해 만들어진 Feature map은 Pooling을 통하여 1×1×N, 2×2×N, 3×3×N, 그리고 6×6×N 의 크기를 가진 sub-region으로 만들어집니다. 이 때, 사용하는 Pooling 방법은
Max pooling과Average pooling을 사용합니다. PSPNet 논문에서는 Average pooling의 결과가 더 잘 나온 것을 제시하였습니다. - 위 그림은 Pooling을 통하여 어떻게 global contextual information을 얻는 지 설명합니다. 위 그림을 기준으로 설명해보겠습니다.
- 동그라미 Feature를 가진 Feature map을 4개의 sub-region으로 나눕니다. 나누어진 각 sub-region에 존재하는 pixel 값들을 평균(Ave Pooling)을 2×2 배열에 입력합니다. 그러면 위 그림과 같이 각 sub-region의 전체적인 특징이 나타낼 수 있습니다.
- 즉, 자동차 또는 보트의 feature로 추정되는 local contextual information의 근처에 물이 있다면 Max/Average Pooling을 통해 구한 global contextual information에 물의 feature가 포함되어 최종적으로 자동차가 아닌 보트로 추정하게 되는 원리입니다.
- 즉,
형상과주변 상황을 모두 고려할 수 있기 때문에 Segmentaion에 있어서 더 좋은 성능을 얻을 수 있습니다.
Pyramid Pooling Module
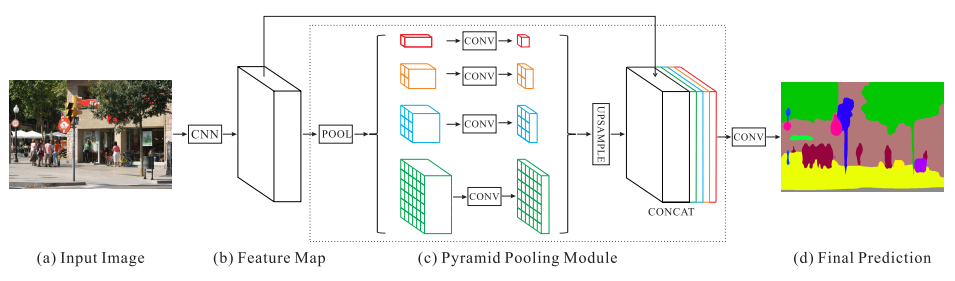
- 그러면 PSPNet의 핵심인 Pyramid Pooling Module에 대하여 알아보도록 하겠습니다.
- 말 그대로
Pooling모듈이기 때문에 Convolution 연산을 통하여 얻은 feature를 사용하는 연산입니다.
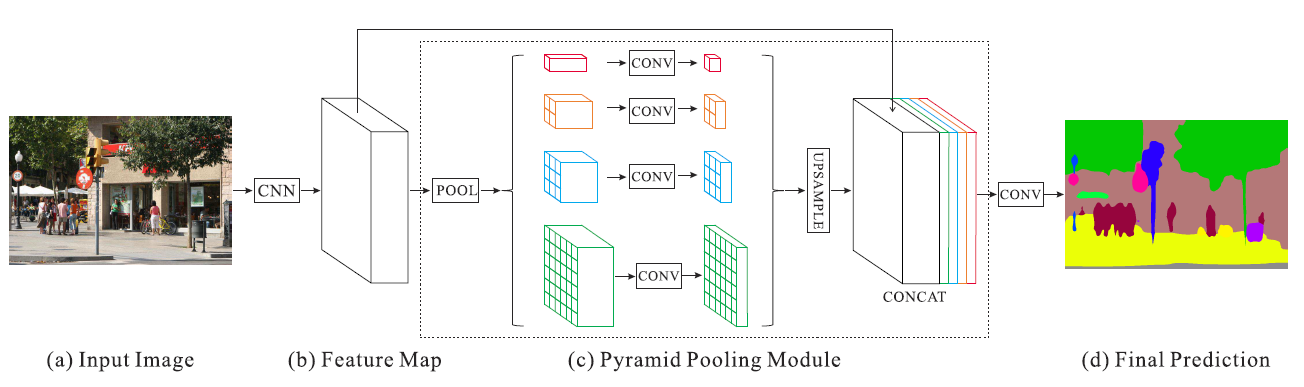
- 논문에서 표현한 Pyramid Pooling Module은 위와 같습니다. (a)와 같은 이미지가 입력 되었을 때, CNN을 통하여 feature map을 생성합니다. feature map을 추출하기 위하여 논문에서 사용한 방법은 ResNet에 Dilated convolution을 사용하였습니다. 이 연산을 거친 결과 (b)에서는 입력 이미지의 1/8 사이즈를 가지게 됩니다.
- 위 그림의 각 색깔별로 다른 크기의 Max/Average Pooling을 합니다.
- 빨간색의 경우 feature map 전체에 대하여 Pooling을 하기 때문에 1 x 1 x N 크기의 feature map이 생성됩니다.
- 주황색의 경우 sub-region이 2 x 2가 되도록 Pooling을 합니다. 따라서 2 x 2 x N 크기의 feature map이 생성됩니다.
- 이와 같은 원리로 하늘색은 sub-region이 3 x 3이 되도록 Pooling을 하고 초록색은 sub-region이 6 x 6이 되도록 Pooling을 합니다.
- 그 다음, 빨간색, 주황색, 하늘색, 초록색 feature map 모두 1 x 1 convolution을 적용하여 channel을 1로 만듭니다. 이를 통하여 각 feature map의 정보를 압축합니다.
- 마지막으로 각 feature map의 사이즈를 bilinear interpolation을 이용하여 입력되었을 때의 feature map 크기로 만들어 줍니다.
- 그러면 Pooling → 1 x 1 convolution → bilinear interpolation을 거친 각 feature의 크기는 입력 feature map과 같아지므로 concatenation이 가능해집니다.
- 마지막으로 기존의 feature map과 bilinear interpolation을 한 빨간색, 주황색, 하늘색, 초록색의 feature map을 모두 concatenation을 하여 합칩니다.
- sub-region을 사용하는 average pooling 방법은 SPPNet과 유사합니다.
실험 결과
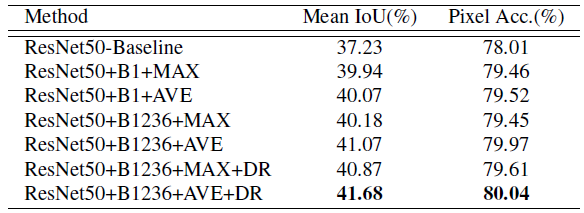
- PSPnet 논문에서 사용한 backbone은
ResNet50기반의 FCN입니다. ResNet50을 기준으로 위 그림과 같이 다양한 실험을 하였습니다. ResNet50-Baseline: ResNet50-based FCN with dilated network.B1과B1236: Pooling된 feature map의 height, width 사이즈를 뜻합니다. B1은 {1×1} 이고 B1236은 {1×1, 2×2, 3×3, 6×6}을 뜻합니다. 위에서 설명한 Pyramid Pooling Module은 B1236에 해당합니다.MAX와AVE: MAX는 Max pooling을 뜻하고 AVE는 Average Pooling을 뜻합니다. 앞에서 언급하였듯이 Average Pooling을 사용하였을 때, 더 좋은 성능을 가졌습니다.DR: Dimension Reduction을 뜻합니다.
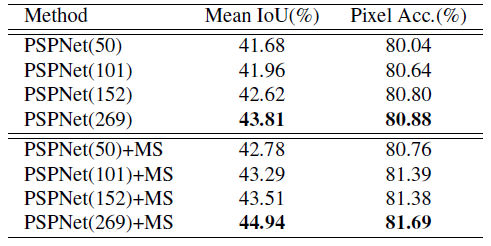
- 모델을 더 깊게 쌓을 수록 성능이 높아지고, Multi-Scale(MS) 형태로 이미지를 입력하였을 때, 성능이 더 좋아지는 것을 확인하였습니다.

- 대표적으로 Cityscapes 데이터셋에서의 성능을 다른 모델과 비교해 보면 논문을 냈을 당시의 SOTA 모델들 보다 더 좋은 성능을 내고 있음을 확인할 수 있습니다.
- 물론 시간이 지난 만큼 현재의 SOTA에 비해서는 성능이 낮지만, global context information을 이용하는 아이디어는 차용할 만한 가치가 있는 좋은 논문입니다.
Pytorch Code
- 아래는 PSPNet의 핵심이 되는
Pyramid Pooling Module입니다. 다른 세그멘테이션 모델에서 이 모듈만 붙여서 사용하면 되기 때문에 이 핵심 코드 부분만 분석해 보도록 하겠습니다.
class PSPModule(nn.Module):
"""Ref: Pyramid Scene Parsing Network,CVPR2017, http://arxiv.org/abs/1612.01105 """
def __init__(self, inChannel, midReduction=4, outChannel=512, sizes=(1, 2, 3, 6)):
super(PSPModule, self).__init__()
self.midChannel= int(inChannel/midReduction) #1x1Conv channel num, defalut=512
self.stages = []
# 각 sub-region을 ModuleList로 모음
self.stages = nn.ModuleList([self._make_stage(inChannel, self.midChannel, size) for size in sizes]) #pooling->conv1x1
# concatenation한 feature들에 convolution 적용
self.bottleneck = nn.Conv2d( (inChannel+ self.midChannel*4), outChannel, kernel_size=3) #channel: 4096->512 1x1
self.bn = nn.BatchNorm2d(outChannel)
self.prelu = nn.PReLU()
# 각 sub-regsion의 Average Pooling과 Convolution 연산을 하는 함수
def _make_stage(self, inChannel, midChannel, size):
# Average Pooling으로 (size, size) 크기의 sub-region을 생성합니다.
# 참조 : https://gaussian37.github.io/dl-pytorch-snippets/#nnavgpool2d-vs-nnadaptiveavgpool2d-1
pooling = nn.AdaptiveAvgPool2d(output_size=(size, size))
# sub-region을 1x1 convolution으로 채널 수를 midChannel 만큼 증감 시킵니다.
Conv = nn.Conv2d(inChannel, midChannel, kernel_size=1, bias=False)
return nn.Sequential(pooling, Conv)
def forward(self, feats):
# 입력으로 들어온 feature의 height, width 사이즈를 구합니다.
h, w = feats.size(2), feats.size(3)
# 각 sub-region을 input feature 크기로 interpolation을 합니다.
# stage(feats)는 input feature를 각 sub-region 형태로 구한 feature를 뜻합니다.
mulBranches = [F.upsample(input=stage(feats), size=(h, w), mode='bilinear') for stage in self.stages] + [feats]
# interpolation 한 각 sub-region을 concatenation 하여 하나의 feature로 만듭니다.
out = self.bottleneck( torch.cat( (mulBranches[0], mulBranches[1], mulBranches[2], mulBranches[3],feats) ,1))
# batch-normalation 적용
out = self.bn(out)
# prelu 적용
out = self.prelu(out)
return out
- 다른 코드에서 위 모듈을 사용하려면 위 모듈을 선언한 다음 feature를 입력으로 넣어주면 됩니다.
- 위 코드의 주석과 앞의 설명을 잘 읽으시면 이해하는 데 어려움은 없을 것으로 생각됩니다.