
Ashok Elluswamy (Tesla) CVPR 2022 Workshop on Autonomous Vehicles (Occupancy Network) 정리
2022, Sep 11
- 이번 글에서는 CVPR 2022의 Workshop에서 Tesla가 발표한
Occupancy Network내용에 대하여 정리해 보도록 하겠습니다. 발표 내용을 보고 제 의견도 중간에 같이 첨부하였으므로 틀린점이 있을 수 있으며 피드백 주시면 수정하겠습니다. 아래는 발표 내용입니다. (여담으로 Karpathy가 퇴사를 하고 Ashok Elluswamy이 Autopilot의 책임자로 임명되었습니다.)
- 아래는 현재
Full Self-Driving Beta 10.69.1의 성능입니다.
- 위 영상을 보면 현재
FSD의 뛰어난 성능이 이번 워크샵에서 제시하는Occupancy Network를 적용한 것으로 보입니다. - 이와 같은 변화는 테슬라가 컴퓨터 비전 (+ 기타 센서) 으로만 자율주행을 시도하기로 발표한 이후 기존의 한계 상황을 개선하기 위해
Occupancy Network라는 컨셉을 사용하면서 나타난 것으로 보입니다. - 기존 시스템에서는 Object Detection의 오인식 및 미인식 문제로 인하여
충돌 문제가 발생하였었습니다. 데이터 셋에 없는 물체가 나타날 경우 Object Detection으로 인식을 하지 못하고 라이다와 레이더가 없기 때문에 물체의 particle 또한 인지하지 못하기 때문에 Freespace로 인지하여 발생하는 문제입니다. - 따라서 이와 같은
충돌 문제를 개선하기 위하여 2가지 컨셉인Occupancy Network와Collision Avoidance를 제시합니다.
- 추가적으로 2022년 AI DAY에서 설명한 바로는
Occupancy Network로는 Voxel 단위로 물체가 점유해 있는 지 파악하는 용도이며 추가적으로 차선의 구분이나 물체의 구분은 다른 뉴럴 네트워크에서 구분하는 것을 확인하였습니다.
목차
-
Autopilot과 Full Self-Driving Beta Software
-
Classical Drivable Space 인식의 한계
-
Occupancy Network의 소개
-
Occupancy Network Architecture
-
Collision Avoidance
Autopilot과 Full Self-Driving Beta Software

- 위 슬라이드에서는 현재 개발된
Autopilot과FSD(Full Self-Driving) Beta software에 대한 설명이 되어 있습니다. - 현재 모든 차량에는 기본적인
Autopolut은 탑재되어 있고 이 기능은 자차가 차선을 벗어나지 않도록 유지하도록 하는 기능이고 주변 차량을 따라가는 역할을 합니다. 또한 안전 기능으로써 다양한 충돌을 피하기 위한 긴급 정지 및 회피 (emergency & steering) 기능이 적용되어 있습니다. - 그 다음 단계로 약 100만대의 차량에 Navigation On Autopilot이 적용되어 있습니다. 이 기능은 차선 변경과 고속도로에서 IC/JC를 자동으로 빠져나가는 기능을 지원합니다.
- 마지막으로 약 10만대의 차량에서
FSD를 사용중이며 이 기능은 주차장에서 부터 도심과 고속도로 전체에서 주행 보조를 지원합니다. 이 기능부터는 인식 범위가 확장되어 신호등과 정지 신호를 감지하여 멈출 수 있으며 교차로 및 보호/비호호 좌/우 회전에서 다른 차량에게 길을 양보하여 적당한 상황에서 자동 주행을 할 수 있으며 이 때 주차된 차들이나 장애물들을 피해갈 수 있습니다.
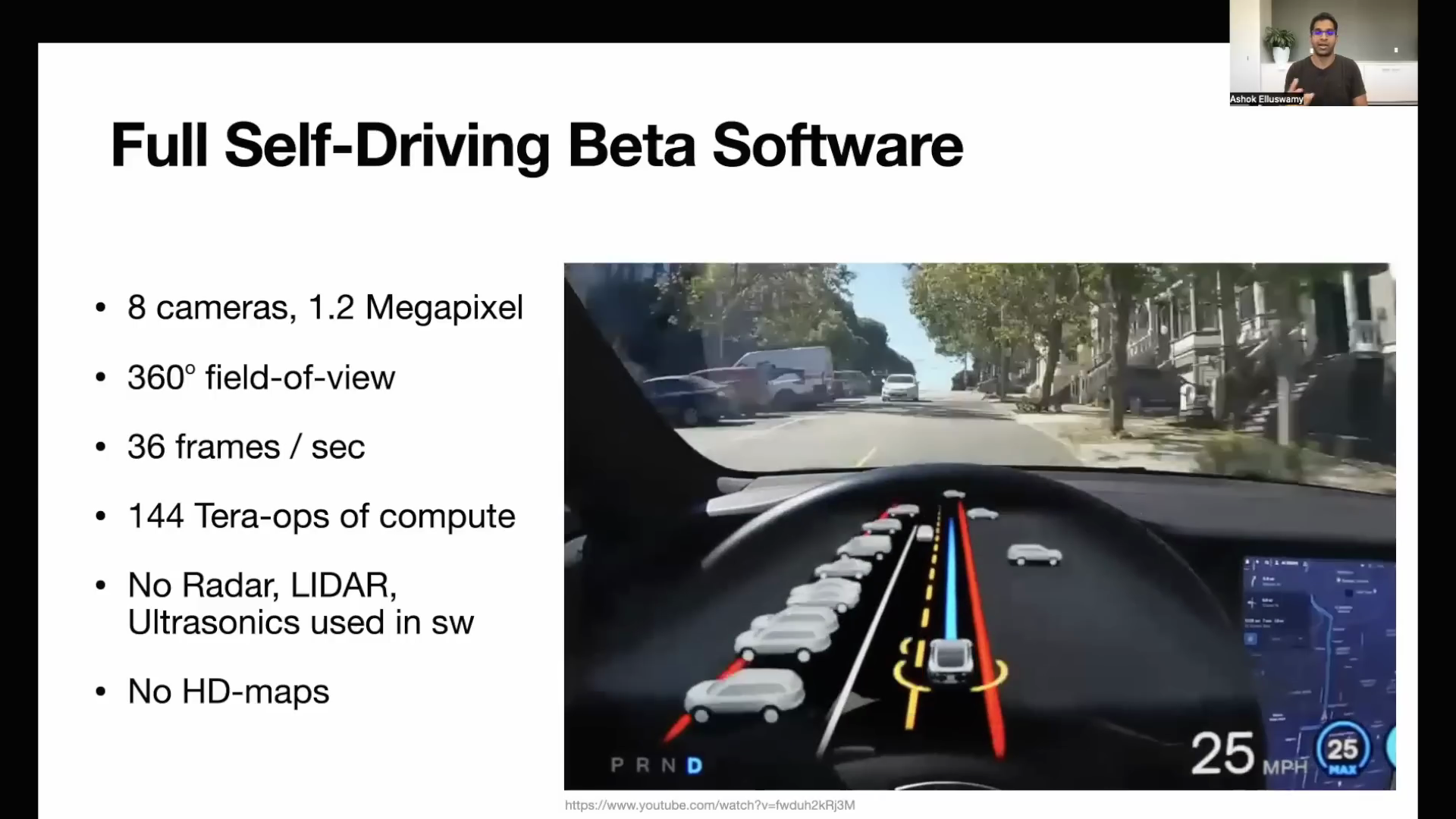
- 위 슬라이드에서는 테슬라의
FSD화면과FSD에 사용된 센서의 간략한 사양을 확인할 수 있습니다. - 8개의 카메라와 1.2 백만개의 픽셀 사이즈의 영상을 받는 카메라를 사용하고 8개의 카메라를 이용하여 360도 전체를 볼 수 있으며 (볼 수 있는 거리는 미확인) 초당 36 Frame을 입력으로 받을 수 있습니다. (실제 기능의 처리 시간은 아니며 카메라가 처리할 수 있는 FPS로 생각하면 됩니다.)
- 카메라 입력을 처리하는 하드웨어는 144 TOPS의 처리 속도를 가집니다.
- 이전에 테슬라에서 공개한 바와 같이 레이더, 라이다는 인식 기능을 위해 사용되지는 않았고 초음파 센서는 사용되었으며 HD map도 배제한 것으로 설명합니다.

- 자세한 인식 영상은 글 상단의 영상을 확인하시면 되며 몇가지 내용만 확인해 보겠습니다.
- 위 그림에서 보면 다양한 차들을 인식하며 인식 결과도 깜빡이지 않고 일관성 있게 출력하고 있습니다. 단, 위 그림과 같이 많은 차들이 일렬로 나열되어 인식 난이도가 올라가면 차량의 앞/뒤 또는 차량의 종류 구분에는 오인식이 발생하는 것으로 확인됩니다.
- 그럼에도 불구하고 차량 인식 성능이 과거에 비해 향상된 것으로 확인됩니다.
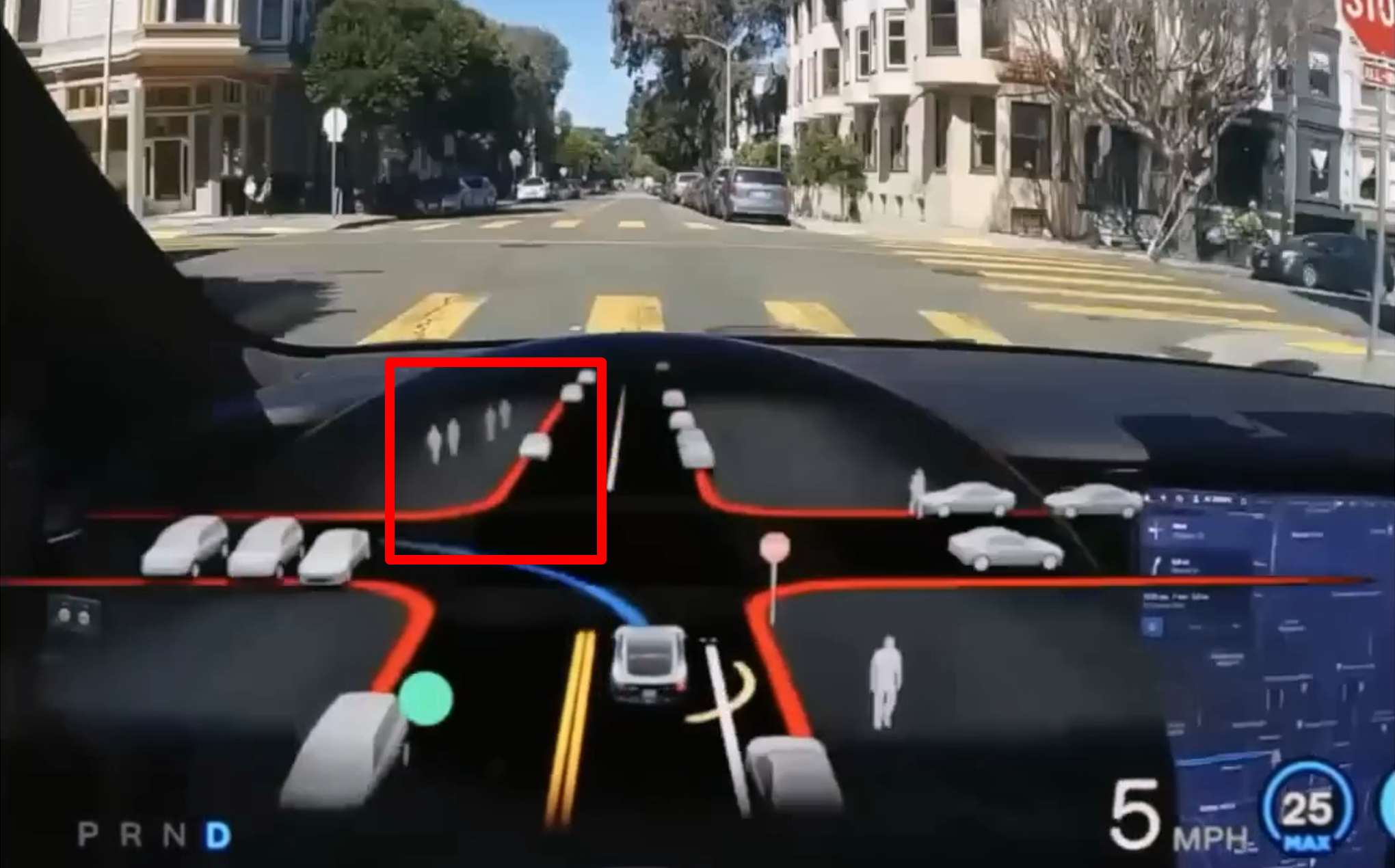
- 사거리에서의 영상 인식 성능도 향상된 것을 확인할 수 있으며 건너편의 사람도 인식이 되는 것을 확인할 수 있습니다.
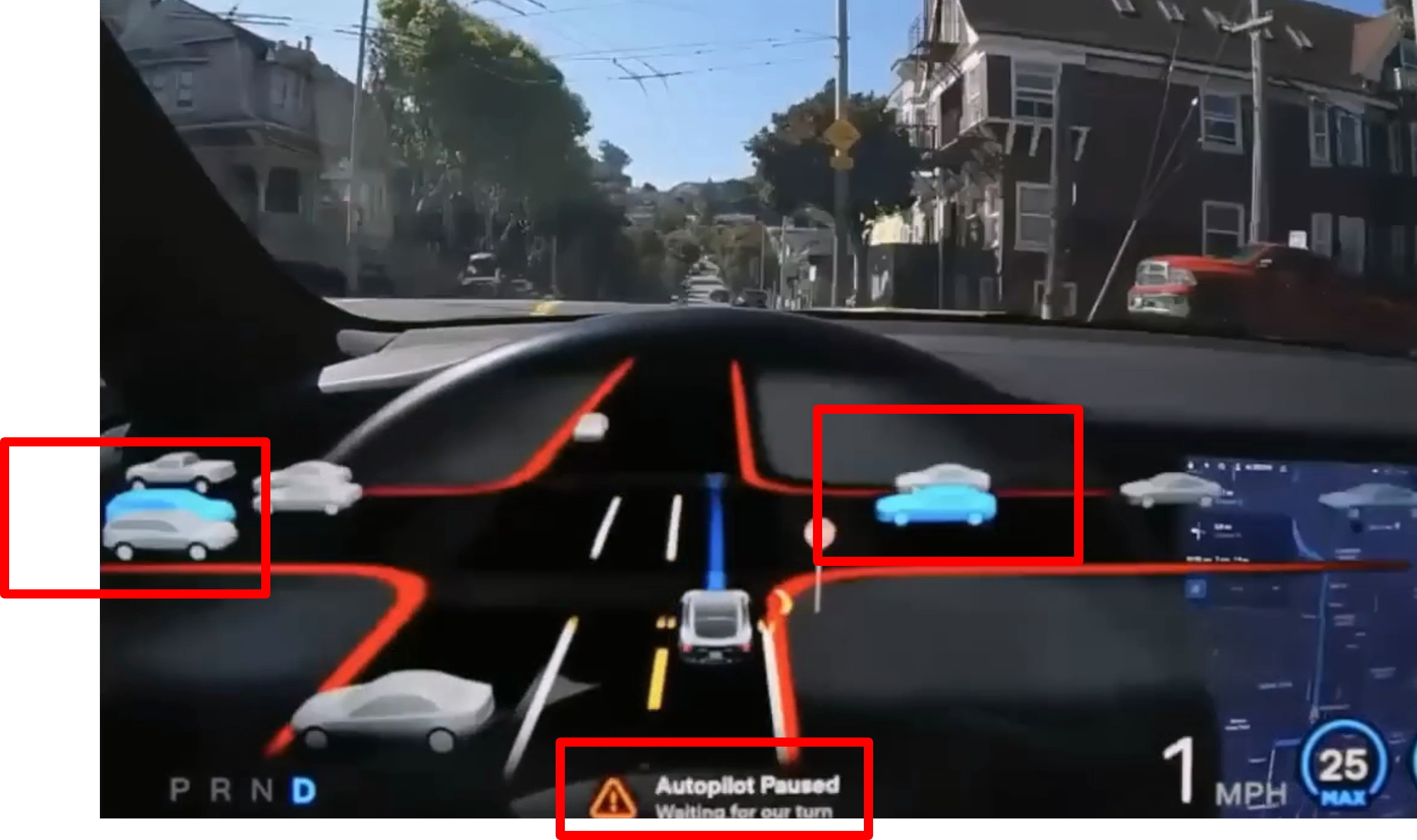
- 위 그림은 우회전 상황이며 이 때, 파란색으로 나타나는 차량이 화면에 표시되며 정확한 의미는 확인이 어렵지만, 충돌 가능한 차량으로 이 차가 지나가기를 기다리는 것으로 추정합니다.
Classical Drivable Space 인식의 한계

- 기존에 3D 공간의 주행 가능 영역 (drivable space)를 확인하는 방법은 2D 이미지 상에서 픽셀 별 (uv 좌표계 기준)로 주행 가능 영역인 지 Semantic Segmentation 모델을 이용하여 확인하고 Depth Estimation을 통해 3D 공간으로 확장하는 방법을 사용하였습니다.
- 테슬라에서 최근에 공개한 컴퓨터 비전 기반의 인식 모델의 컨셉은 다른 방향으로 바뀌었는데 어떤 문제가 있어서 컨셉의 변경이 있었는 지 슬라이드에서 제공하는
기존 문제점에 대하여 먼저 살펴보겠습니다. - Doesn’t get overhanging obstacles & provide 3D structure : 2D 이미지 → 3D 공간으로 변경 시 물체의 3D 형상을 예측하기 어렵습니다. 기본적으로 물체를 인식하기 위해 2D, 3D Bounding Box를 그리더라도 사각형 형태이기 때문에 위 슬라이드와 같이 포크레인 머리 부분의 돌출부나 건물 벽과 같은 영역의 돌출부의 3D 정보를 추정하는 데 한계가 있습니다.
- Extremely sensitive to depth at the horizon : 원거리에 있는 수평선 라인의 경우 주행 가능 영역인 지 또는 주행 불가능 영역인 지 확인 시 Segmentation의 결과를 이용하여 판단하고 주행 가능 영역의 거리는 Depth Estimation을 통해서 거리를 예측합니다. 하지만 원거리 영역에서의 Depth Estimation은 몇 픽셀에 따라서 큰 차이가 날 수 있고 Segmentation의 결과가 몇 픽셀 부정확하게 예측하면 오차가 크게 발생하는 문제가 생깁니다.

- 2D 이미지 → 3D 공간으로 변환 (
unproejct to 3d points)하는 것에 한계점은Depth Estimation의 출력에 한계가 있기 때문입니다. 2D 이미지 → 3D 공간으로 변환은 아래 링크를 참조하시기 바랍니다. - 위 슬라이드에서 지적하는 Depth Estimation의 단점은 크게 5가지가 있고 각 내용은 Depth Estimation의 해상도가 높지 않다는 것과 2D 이미지에서 Depth를 검출하는 것의 한계에 관련된 내용들입니다.
- Depth can be inconsistent locally : local 영역에 대하여 Depth 정보가 일관적이지 않는 경우의 문제 입니다. 이 경우 평평한 벽과 같은 물체에 대해서도 깊이가 일관적이지 않고 들쑥날쑥하게 됩니다. 특이 원거리 영역에서는 1, 2개의 픽셀이 넓은 영역의 depth를 의미하기 때문에 오차가 큽니다.
- Too Sparse closer to the horizon : local 영역에 대하여 Depth가 일관적이지 않아 너무 듬성 듬성 Depth 정보가 존재하게 되면 horizon으로 잘못 인식 하는 경우가 발생하게 됩니다.
- Cannot predict through occlusion : 2D 이미지를 통해 3D 공간을 복원하기 때문에 다른 물체에 의해 가려진다면 가려진 가려진 부분은 3D 공간에 복원할 수 없습니다. 이는 사람 또한 상상으로 복원하는 것이지 가려진 물체의 깊이 정보는 복원할 수 없으나 테슬라에서는 이 부분을 문제로 간주하고 개선하였습니다.
- Doesn’t distinguish between moving & static obstacles : 정적인 물체와 동적인 물체를 구분할 수 없습니다.
Occupancy Network의 소개
- Classical Drivable Space 인식 방법에는 앞에서 소개한 문제가 있고 이 문제를 개선하기 위하여
Occupancy Network를 사용합니다. Occupancy Network는Occupancy Grid Mapping이라는 로봇 공학 아이디어를 기반으로 하는 다른 종류의 알고리즘입니다. 이 방법은 실제 공간을 그리드 셀로 나눈 다음 어떤 셀이 점유되고 어떤 셀이 비어 있는지 정의하는 것으로 구성됩니다.- 특히 본 글에서는
Volumetric Occupancy Network로 표현되면 이것은 개념을 3D로 확장하겠다는 의미입니다. - Occupancy Network의 출력은 아래와 같습니다.

- 아래 링크의 영상 클립을 살펴보시면 데모 영상을 볼 수 있습니다.
- 링크 : https://youtube.com/clip/UgkxAWHFUi1Y-Jznqwh9zOLNJfnqjZ2Tc4oU

- 위 슬라이드에서는 테슬라에서 사용하는
Occupancy Network의 좋은 장점들을 소개합니다. - 8개의 카메라에서 입력되는 이미지를 동시에 처리하여 3D 공간 하나를 출력으로 만들고 그 공간에서 어떤 물체가 차지하고 있는 지, 그 물체가 무엇인 지 까지 확인합니다.
- 이와 같이 3D 공간 상에서 voxel 별 어떤 물체가 점유하고 있는 지 확인할 수 있으므로
volumetric occupancy라고 칭합니다.
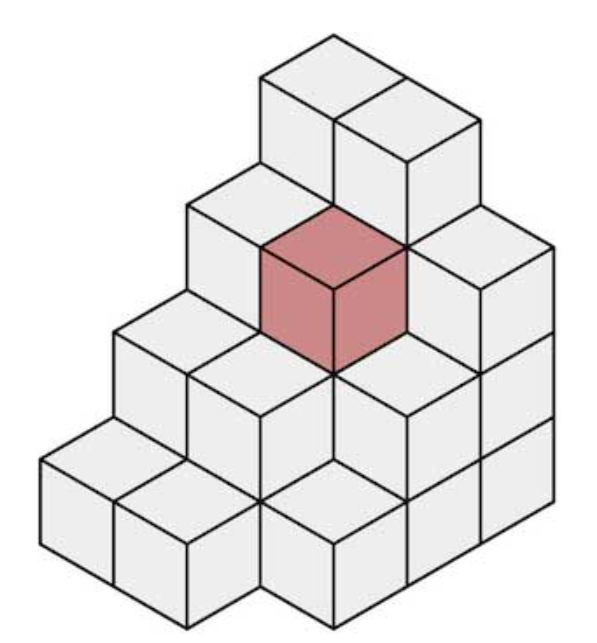
voxel은 위 그림과 같이 3D 공간을 정육면체 형태로 discrete하게 분할하였을 때, 정육면체 단위 하나를 의미합니다.
- Multi Camera를 Video로 처리하기 때문에 일부 보이지 않는 영역을 연속된 영상의 정보를 이용하여 처리할 수 있고 이 내용을
Multi-camera & video context, Dynamic occupancy으로 설명합니다. - 앞에서 다룬 2D 이미지 → 3D 공간으로 변환하는 경우 occlusion이 발생하여 2D 이미지 상에서 보이지 않는 물체는 형상을 그려내지 못하지만 위 슬라이드와 같이
Multi-camera & video환경에서 2D 이미지를 거치지 않고 바로 3D로 변환하는 경우 occlusion이 발생한 물체에 대해서도 일부 출력이 가능해 짐을 보여줍니다. (Persistent through occlusion) - 앞에서 살펴본 2D 이미지의 Depth Prediction은 근거리에서는 해상도가 높지만 원거리에서는 오차 범위가 커져서 해상도가 낮은 문제가 발생합니다. 이 문제로 인하여 Segmentation의 불안정한 출력이 거리 오차를 크게 만드는 문제가 있음을 이전 슬라이드에서 언급하였습니다.
Occupancy Network에서는 일정한 간격으로 Voxel을 형성하고 각 영역에 물체가 있는 지 여부를 확인하기 때문에 해상도가 급격히 안좋아지는 문제를 개선할 수 있음을 언급합니다. (Resolution were it matters) - 마지막으로 이와 같은 과정을 10 ms 이내에 처리할 수 있도록 메모리와 계산 측면에서 최적화 하여
Occupancy Network의 주기가 10 ms 가 될 수 있도록 구현하였다고 설명합니다. 이전 슬라이드에서 카메라 입력이 35 ms 주기이고 Occupancy Network의 연산이 10 ms 이므로Occupancy Network기준 전처리 및 후처리를 할 시간이 충분함을 시사합니다.
Occupancy Network Architecture
Occupancy Network의 Architecture를 살펴보면 크게Input,Network,Output형태로 볼 수 있습니다. 먼저Input에 대하여 살펴보도록 하겠습니다.
Occupancy Network Input

- 위 그림을 살펴보면 8개의 카메라 중 대표 샘플로
전방 FishEye카메라와Left Pillar카메라를 예시로Normalization작업을 설명하였습니다. Normalization으로 표현한 내용을 살펴보면 카메라 렌즈의 왜곡을 제거하고 유효한 영역을 적당한 크기로 crop 및 resize 한 것으로 추정됩니다.- 렌즈 왜곡에 대한 자세한 내용은 아래 링크를 참조해 주시기 바랍니다.
- 링크 : https://gaussian37.github.io/vision-concept-lense_distortion/

- 위 Fisheye 영상을 보면 빨간색 박스 영역이 Normalize 과정 이후에는 사라졌습니다. 렌즈 왜곡을 제거 후 직사각형 형태로 만들기 위해서는 이미지 가장자리 부분을 일부 제거해야 하며 그 과정을 통해서 제거된 것으로 추정됩니다.
- 렌즈 왜곡을 제거 하였기 때문에 위 그림의 파란색 박스의 곡선 부분이 Normalize 과정 이후 직선이 된 것을 확인할 수 있습니다.

- Left Pillar는 Fisheye 카메라와 비교하면 상대적으로 굴절이 덜 발생하였으나 위 이미지에서도 육안으로 곡선이 직선이 된 것을 확인할 수 있습니다. 파란색 박스의 표지판을 비교해 보면 됩니다.
- 이 영상 또한 렌즈 왜곡을 제거하였을 때, 이미지 가장자리 부분을 제거한 것으로 추정됩니다.

- 8개 카메라의 각 영상은 각 이미지의 feature를 추출하기 위한 딥러닝
backbone으로 입력됩니다. backbone이 하나이고 8번을 사용하는 것인 지, 8개의backbone을 각각 사용하는 것인 지 명확하게 나와있지는 않습니다.backbone을 통하여 각 카메라 영상의 feature를 추출할 수 있도록 영상의 입력이 준비 되어야 합니다.- 만약 하나의
backbone을 사용한다면 메모리 효율성에서 좋고 학습에 많은 이미지를 사용할 수 있으나 영상의 환경이 너무 다른 경우 학습 성능에 문제가 있을 수 있습니다. 또한backbone의 구조가 모든 이미지를 처리할 수 있어야 하므로 이미지의 사이즈가 많이 다르면 사용하는 데 제한이 있을 수 있으므로 이 점을 고려해야 합니다. - 반면 서로 다른
backbone을 사용한다면 각 이미지의 feature를 추출할 수 있도록 학습을 할 수 있고 입력 이미지의 크기 또한 통일할 필요는 없습니다. 단,backbone의 weight들을 backbone 갯수 만큼 더 저장해야하므로 메모리 문제가 있을 수 있습니다. - 이와 같은 점들을 고려하여 각 카메라의 입력 이미지의 사이즈를 정의한 것으로 추정합니다.
Occupancy Network Architecture
- 8개의 입력을 받은 후
backbone과Attention메커니즘을 이용하여 어떻게Occupancy Features를 생성하는 지 살펴보도록 하겠습니다.
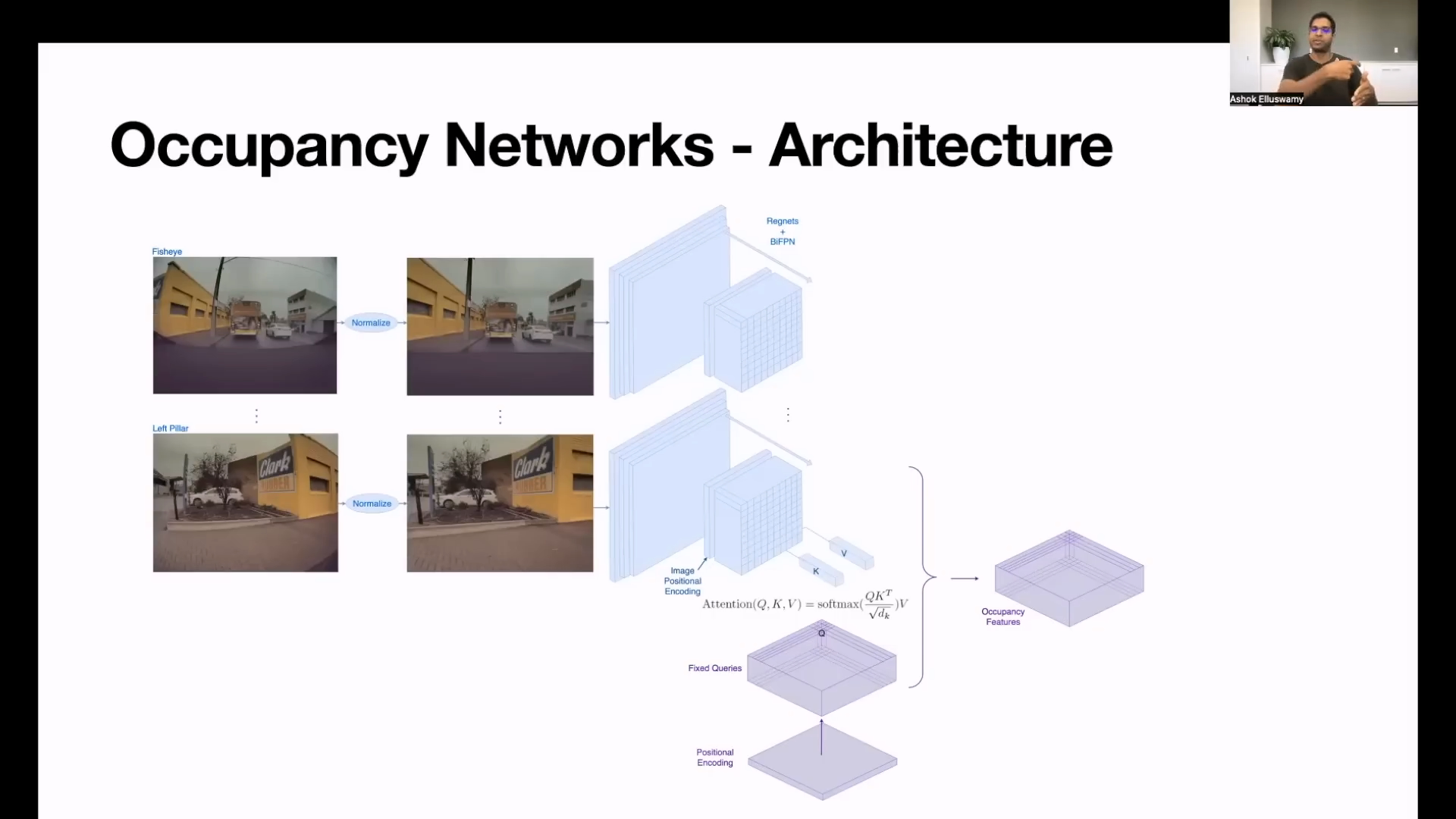
- 위 architecture와 같이 각 이미지를 입력으로 받아서
backbone을 통하여 해상도는 줄이고 채널 수는 늘이는 방향으로 feature를 생성합니다. 이 때, 사용한 구조는RegNet과BiFPN구조를 사용하였습니다. 2021 CVPR Workshop과 2021 AI Day에서 발표한 내용에서도RegNet과BiFPN을 사용하였었는데 변경이 되지 않은 점을 보았을 때,backbone으로써 충분히 효과가 있는 것으로 보입니다.RegNet내용 살펴보기 : https://gaussian37.github.io/dl-concept-regnet/BiFPN내용 살펴보기 : https://gaussian37.github.io/dl-concept-bifpn/
backbone을 통하여 feature extraction을 거친 후Image Positional Encoding(파란색 블록 중간)이 feature에 추가된 이후Attention과정이 진행 됩니다.Attention내용 살펴보기 : https://gaussian37.github.io/dl-concept-attention/
- 보라색 블럭의 시작을 보면
Positional Encoding이 있는 데Positional Encoding에서 부터 시작하여Attention에 사용할Query를 만들고 파란색 블럭의 최종 feature에서Key와Value가져와서Attention구조를 만듭니다.
- \[\text{Compare}(q, k_{j}) = \text{softmax}(\frac{q \cdot k_{j}}{\sqrt{d_{k}}}) = \text{softmax}(\frac{q^{T}k_{j}}{\sqrt{d_{k}}})\]
- \[\text{Aggregate}(c, V) = \sum_{j} c_{j}v_{j}\]
- 발표 내용에 의하면 이 Attention 메커니즘의 목적은
Query를 통해 Occupancy에서 3D point가 존재하는 지 존재하 지 않는 지 확인하기 위함이라고 말합니다. 따라서fixed queries의 목적은 3D 공간에서 각 분할된 공간이 차인 지 아닌 지, 표지판인 지 아닌 지 등에 대한 의미를 가지도록 학습이 되어야 한다고 추정합니다. - 각
Positional Encoding은 기존에Nerf에서 사용되는 방식으로 구성되는 것으로 추정하며 3D Occupancy Feature를 reconstruction 하는 데 도움이 되기 위하여 주파수 도메인의Fourier Feature를 추가한 것으로 추정합니다. Positional Encoding의 내용과 Nerf의 내용은 아래 링크를 참조하시기 바랍니다.Positional Encoding내용 살펴보기 : https://gaussian37.github.io/dl-concept-positional_encoding/Nerf내용 살펴보기 : https://gaussian37.github.io/vision-fusion-nerf/
- 이 과정을 통하여 최종적으로
Occupancy Feature를 생성합니다.
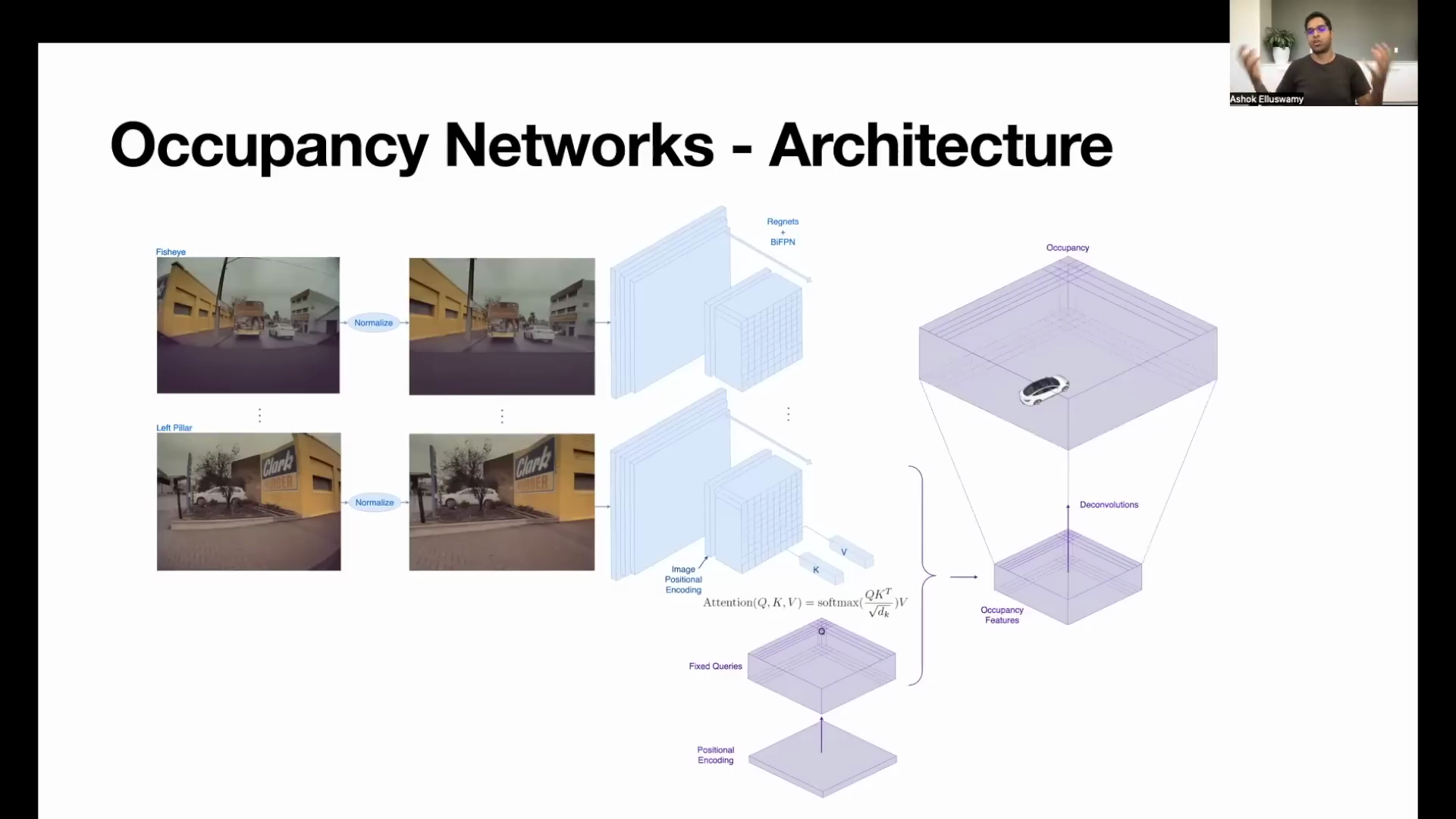
- 생성된
Occupancy Feature는 Low Resolution이기 때문에 (계산 효율 상 Los Resolution으로 생성한 것으로 추정함) 원하는 크기의 High Resolution으로 크기를 키웁니다. 위 슬라이드와 같이Deconvolutions작업을 통해 해상도를 키우는 데 일반적으로 Feature의 크기를 키우는Transposed Convolution또는Interpolation + Convolution과 같은 방법을 사용하였을 것으로 추정합니다.

- 그런데 앞에서 살펴본 출력을 보면 출력의 종류가 다양하지 않은 것을 알 수 있습니다. 위 그림에서도 보면 자차, 주변 차량, 도로 정도로 굉장히 단순화 되어 있습니다.
- 이러한 컨셉을 도입한 이유는
충돌 문제를 개선하기 위하여 단순히 해당 영역 (Voxel)에 물체가 Occupy가 되어 있는 지 여부를 확인하기 위한 것으로 소개합니다. (+ AI DAY의 추가 설명 확인 시, 클래스 구분은 다른 네트워크를 이용합니다.)
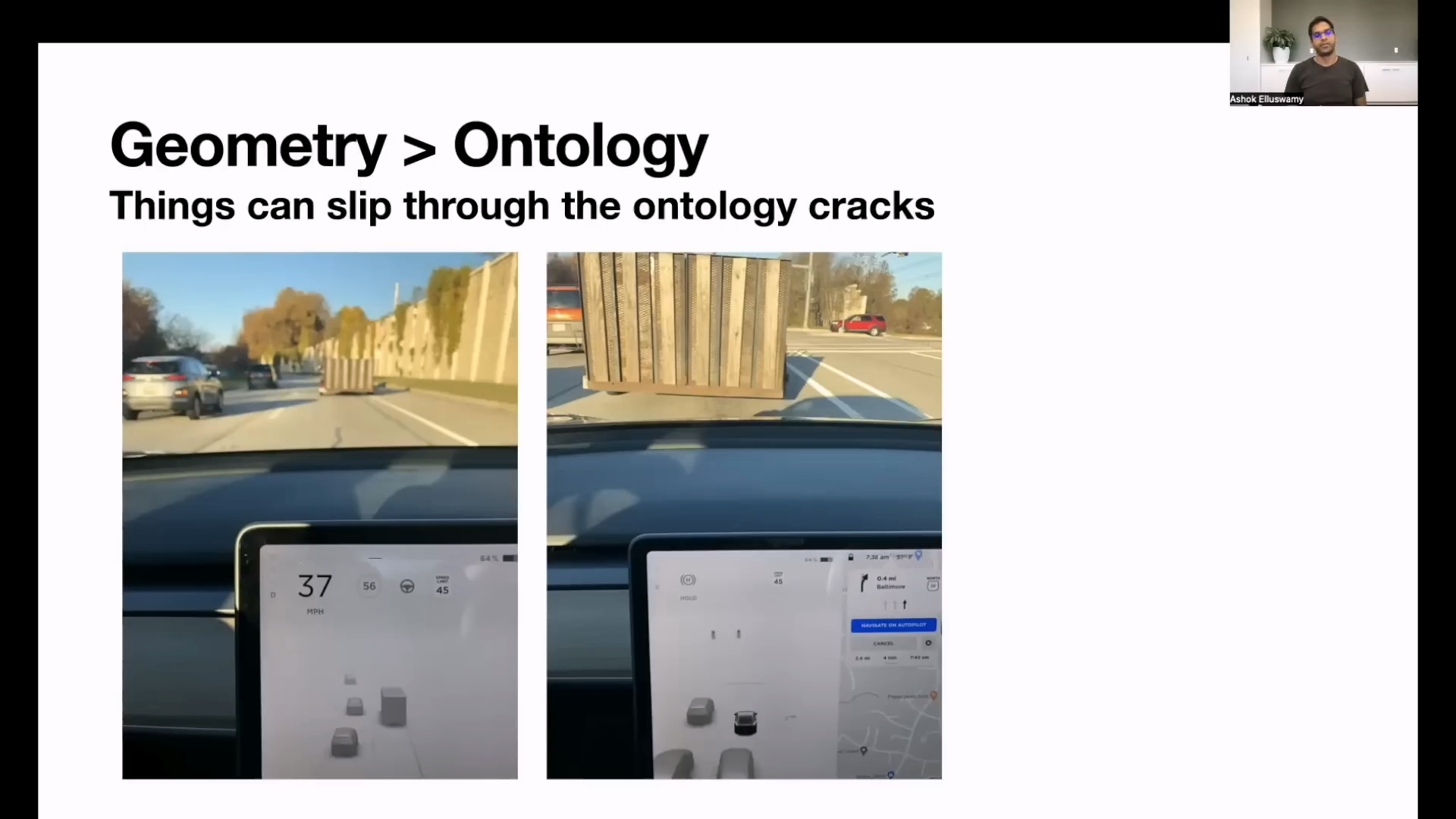
- 위 슬라이드의 제목은
Geometry > Ontology라는 내용으로 시작합니다. 즉,Ontology보다는Geometry를 사용하겠다는 내용이며 소제목으로Things can slip through the ontology cracks라고 표현합니다. 즉,Ontology라는 것을 통해서는 알아차리지 못하는 것들이 있다는 뜻입니다. - 여기서
Ontology의 뜻은 물체들의 유형을 어떻게 계층 별로 나눌 지 방법론에 관한 것입니다. - 예를 들면 자동차는 승용차, 상용차 등으로 나눌 수 있고 그 하위 항목으로 이륜차, 사륜차 등으로 나눌 수 있으며 또 그 하위에서 차, 트럭, 버스 등으로 나눌 수 있습니다.
- 따라서 딥러닝 모델이 인식한 물체를 분류를 할 때, 사전에 설계한 계층 분류도를
Ontology라고 말할 수 있습니다. Ontology의 한계점은 사전에 고려하지 못한 유형의 객체가 나타났을 때 어떤 분류에 속하지 못하는 경우에 발생하며 꽤 빈번하게 발생할 수 있습니다.
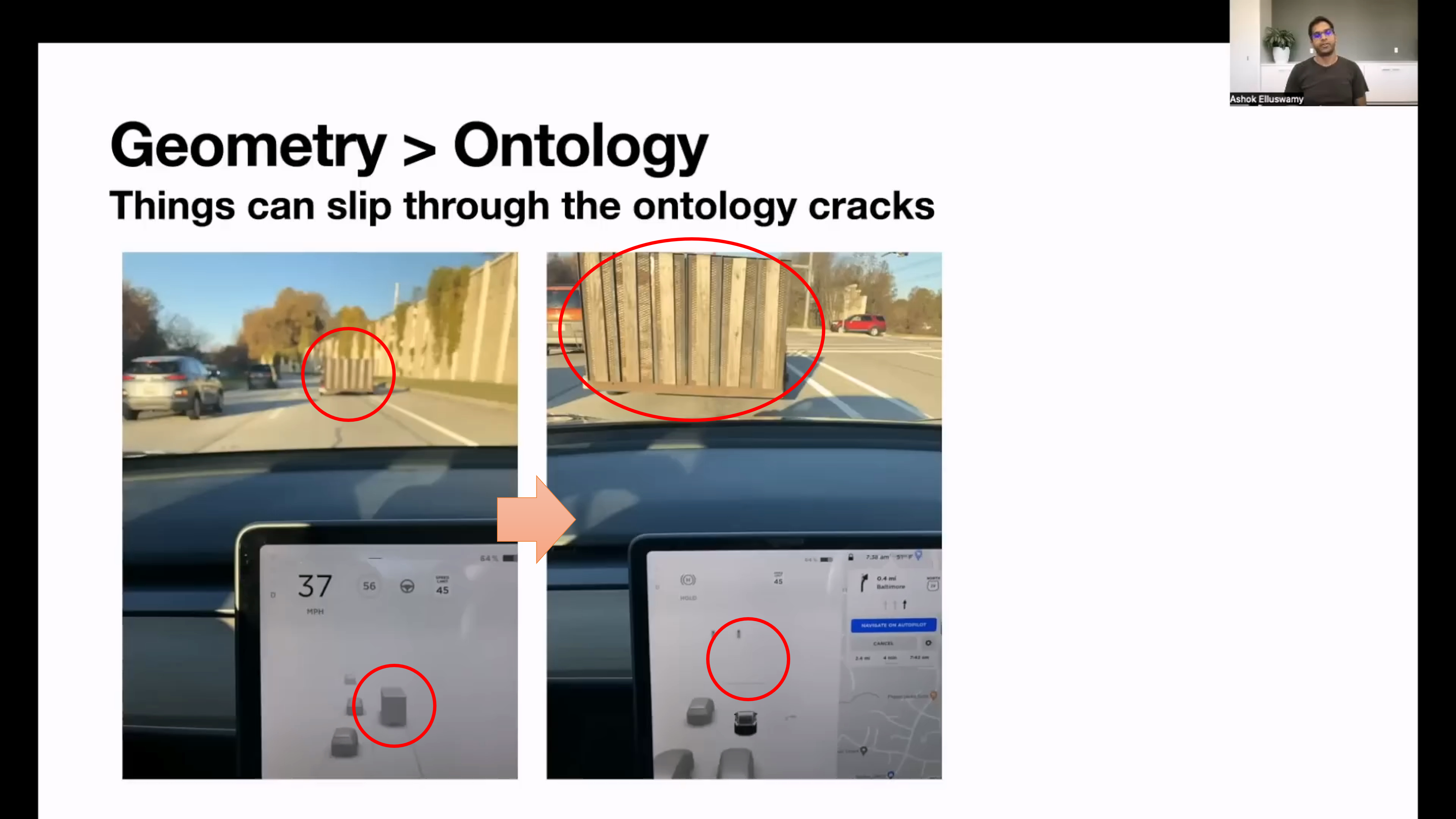
- 위 영상은 테슬라에서 겪은
Ontology의 한계점 중 하나를 나타냅니다. - 위 영상에 문제가 되는 부분은 컨테이너를 옮기는 차량의 컨테이너에서 발생합니다. 만약 딥러닝 모델이 움직이는 차량을 인식하고
Ontology에 대형 트럭이 있는 경우 사전에 인식이 가능할 수 있습니다. 하지만 신호에 대기하여 장시간 정차되고 컨테이너의 뒷모습만 보인다면Ontology에 속하지 않아서 인식 하지 못하는 경우가 발생합니다. - 따라서 사전에 분류되지 못하여 학습하지 못한 데이터는 인지하지 못한다는 한계점을 보여주는 예시입니다.

- 뿐만 아니라 위 슬라이드와 같은 문제 상황에서 인식을 하는 것에도 한계점이 있습니다.
- 위 슬라이드의 왼쪽 그림은 사람과 비슷하지만 움직이지 않는 사람 모형이고 오른쪽 그림은 사람처럼 보이지 않을 수 있지만 움직이는 사람입니다.
- 이러한 모든 객체에 대하여 Ontology로 분류하고 인식하는 것에는 한계가 있으며 궁극적인 목적이 움직이거나 정지된 장애물 모든것을 피해서 주행하는 것이라는 것과 일치하지 않습니다.
- 테슬라에서는 기존에 움직이는 물체 (Moving Object)와 움직이지 않는 물체 (Static Object)를 별도의 클래스로 구분하여 Ontology를 설계하였는데
- ① Ontology 설계의 한계점도 있고
- ② 궁극적인 목적에서도 정적인 물체와 동적인 물체를 구분하지 않아도 되며
- ③ 앞에서 소개한 바와 같이 정적인 물체 (ex. 컨테이터) 또한 동적인 물체가 될 수 있기 때문에
- Ontology 상에서 물체를 인식하지 않고 3차원 Geometry 상에서 Voxel 단위 별로 Voxel에 물체가 있는 지 없는 지 파악하는 방향으로 목적을 바꾸었습니다.
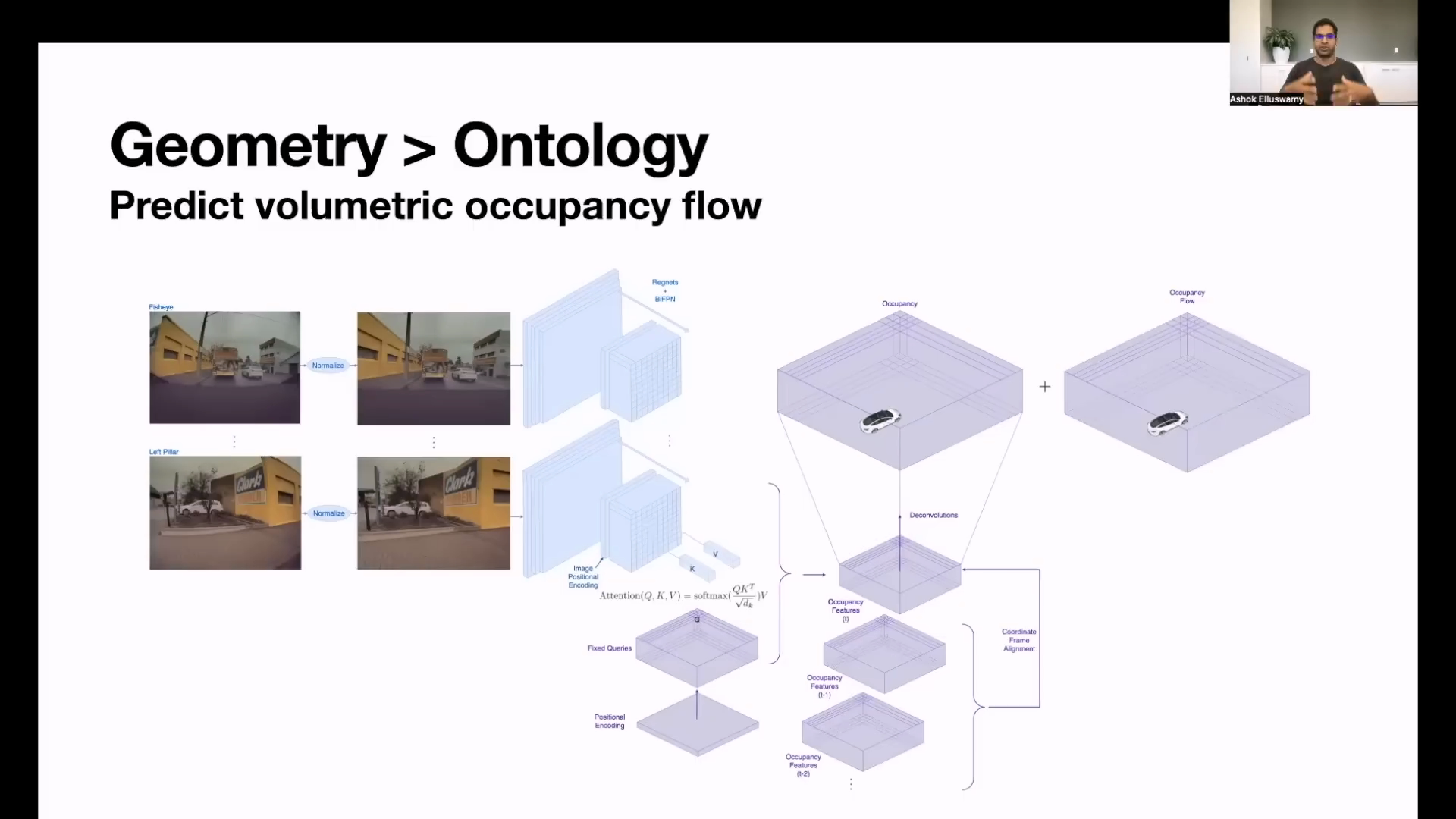
- 따라서 움직이는 물체를 인식하는 방식 대신 각 Voxel 별 물체의 존재 여부를 파악한 뒤 Voxel 단위 별로 움직임을 예측하는
occupancy flow방식을 사용하여 움직이는 물체를 물체의 종류와 상관 없이 인식합니다. - 마치
optical flow에서 어떤 픽셀이 다음 Frame에서는 어디로 이동할 지 motion vector가 출력이 되듯이occupancy flow를 통하여 voxel 단위의 motion vector를 추정하는 것으로 생각됩니다. occupancy flow를 사용하기 위하여 이전 Frame에서 생성한occupancy feature를 사용합니다. 위 슬라이드와 같이 t, t-1, t-2, … 등이 사용되는 것을 확인할 수 있습니다.occupancy flow를 사용하는 이유는 각 Voxel 별 움직임의 변화를 관찰하여Occlusion이 발생하더라도 이전 Frame의occupancy feature정보들로 인하여 3D 공간 상에서 Occlusion 된 곳 까지 Voxel의 물체 정보가 예측하도록 합니다.
Occupancy Network Output

occupancy network의 결과는 위 그림과 같습니다. 출력으로occupancy와occupancy flow를 생성하였고 그 결과를 위 그림과 같이 시각화 하여 표현하였습니다.- 빨간색 색상은 motion vector가 양의 방향 즉, 자차와 같은 방향으로 이동 중인 물체이고 초록색은 motion vector가 음의 방향 즉, 자차와 반대 방향으로 이동 중인 물체를 의미합니다. 그리고 회색 물체는 정지된 물체를 의미합니다.
- 정리하면 위 슬라이드에서는
occupancy network가motion flow vector를 추정할 수 있어서 voxel 단위의 모든 3D 위치를 추정할 수 있음을 시사합니다.

- 위 슬라이드에서는 앞에서 문제 제기한
ontology문제에 대한 개선점을 보여줍니다. 실제 어떤 물체인 지 모르더라도 voxel 상에 물체가 있다고 판단하면 Freespace가 아님을 인식합니다.

- 더 나아가 Voxel을 단위로 인식하기 때문에 직육면체(Cuboid) 형식의 객체 인식에서 더 나아가 3D 차원에서 자유로운 형상으로 인식할 수 있는 장점이 생깁니다.
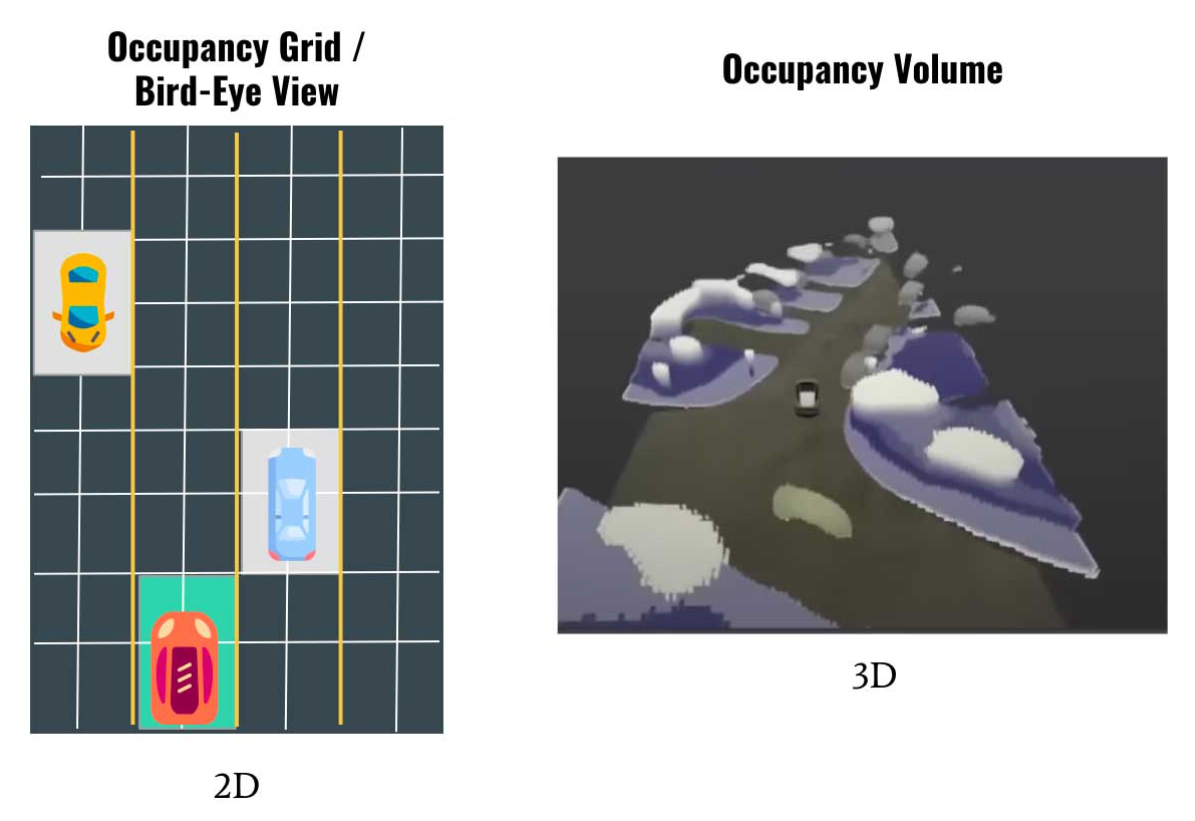

- 기존에는 3D Bounding Box 형태의 간단한 형식의 출력을 사용하기 때문에 특정 부분이 튀어나오면 인식하기가 어려웠고 최근 연구가 많이 되는 2D Bird Eye View 형태를 사용하면 3D 공간상의 정보를 잃어버리기 때문에 정확한 Freespace를 확인하기 어렵습니다.
- 위 그림과 같이 BEV에서 2D로 인식할 경우 원하는 사람과 같이 BEV 환경에서는 1개의 grid에서만 나타날 수 있는 객체 인식에서는 취약할 수 있습니다.
- 또한 트럭이나 포크레인과 같이 3차원 상에서 큰 구조물이 달려있는 경우에도 BEV에서는 구체적으로 형상을 알 수 없는 한계점이 있습니다.

- 그리고 앞에서 설명한 바와 같이 occlusion이 발생하더라도
occupancy와occupancy flow를 이용하여 Voxel에 대한 정보를 추론할 수 있습니다. - 위 그림은 비보호 좌회전을 하려는 사진이고 전방에는 교차로가 있고 왼쪽에 나무와 표지판에 의해 가려진 차량이 있습니다. 카메라 관점에서는 차의 정보가 보이지 않지만 3D 공간 상에서는 추론할 수 있음이
occupancy network의 장점입니다.
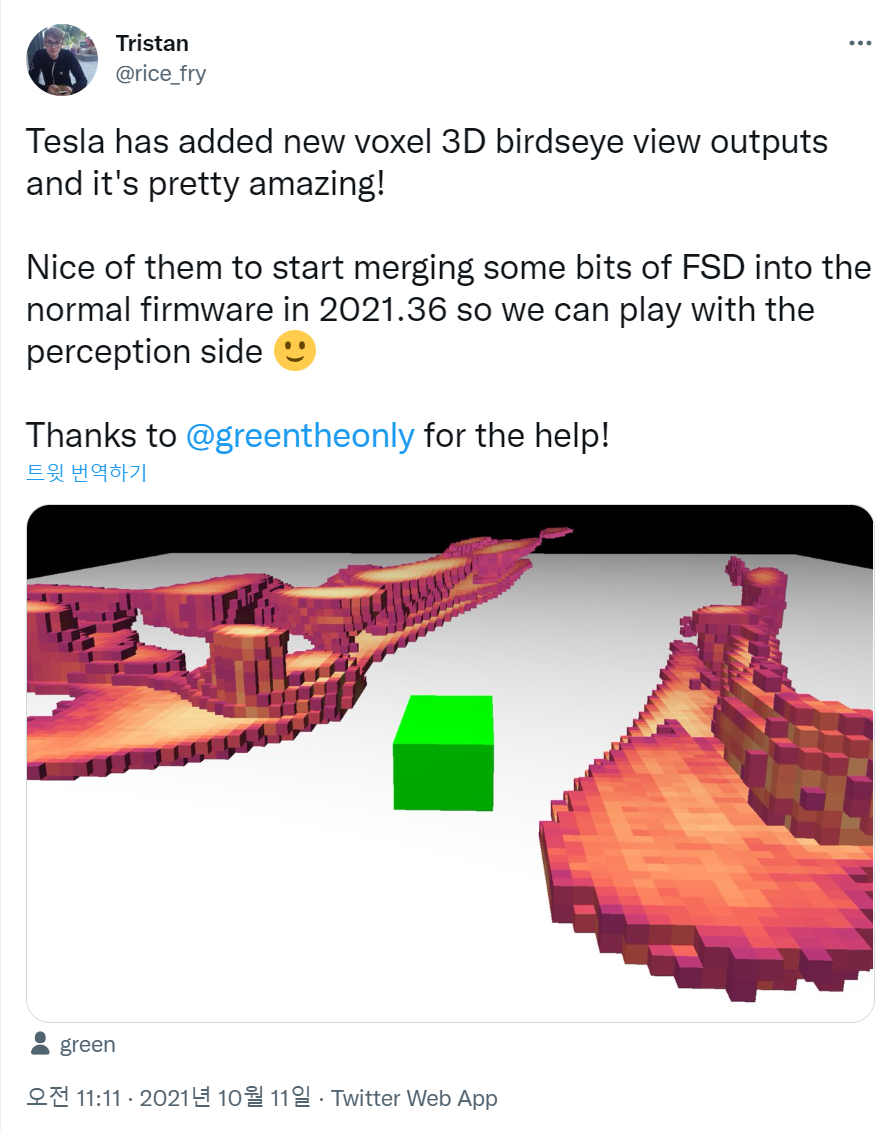
- 실제로 21년도 10월에 올라온 트위터 내용을 보면 3D 상에서 Voxel 기반의 출력을 추가했다는 글이 올라왔었습니다. 이미 Karpathy가 퇴사하기 전에도 진행이 많이 되었던 내용인 것으로 추정할 수 있습니다.
Occupancy Network Learning Data

Occupancy Network의 핵심은 어떻게 학습할 것인 지 문제에 달려 있습니다. 즉, 3D 공간을 Voxel 단위로 만들어 내야 이 Voxel 단위 별 Freespace를 예측할 수 있는데 이미지 별 정답값을 알고 있어야 하기 때문입니다.- 이 문제를 해결하기 위하여
NeRF를 사용하여3D reconstruction문제를 해결하였음을 보여줍니다. - NeRF 관련 상세 내용은 아래 링크를 참조하시기 바랍니다.
NeRF의 초기 모델은 정적인 이미지에 대한 3D reconstruction 방식을 제안하였으나 최근 몇년간 발전하여 움직이는 물체에 대해서도 Voxel 기반의 3D reconstruction을 수행할 수 있으며 NeRF에서는 이미지 취득 시 카메라의 위치를 알아야 하는데 차량의 이동 궤적을 추정하여 이 값을 알 수 있음을 설명합니다. (D-NeRF나 그 이후의 모델을 보는 것이 도움이 될 것으로 보입니다.)- 이 부분이 데이터를 만드는 가장 중요한 핵심이며 테슬라와 같이 실제 차에서 데이터를 얻어 학습할 수 있어야 (또는 시뮬레이션 환경에서 만들어 낼 수 있어야) 구현할 수 있으므로 학계의 연구와의 차이점이라 말할 수 있습니다.

- 구현 결과는 위 그림과 같습니다. 일부 artifact 형태의 결과가 보이긴 하지만 차량에서 취득한 이미지로 3D reconstruction한 결과라면 상당히 좋은 학습 데이터로 판단됩니다.

- 차량에서 학습 데이터를 얻을 때, 문제가 되는 것은 raw 데이터의 품질입니다. 카메라를 통해 얻는 이미지는 다양한 날씨에 의해 노이즈 (역광, 비 등) 가 있을 수 있으며 카메라에 먼지 등이 묻을 수도 있습니다.

- 테슬라에서는 RGB 정보 뿐 아니라 추가적인
descriptor를 이용하여 노이즈에 강건한 정보를 RGB에 추가적으로 NeRF에 사용한다고 설명합니다. 이와 같은 방식을 사용하면 RGB 값이 변경하더라도 이미지 내의 의미론적인 요소들이 보호될 수 있기 때문입니다.
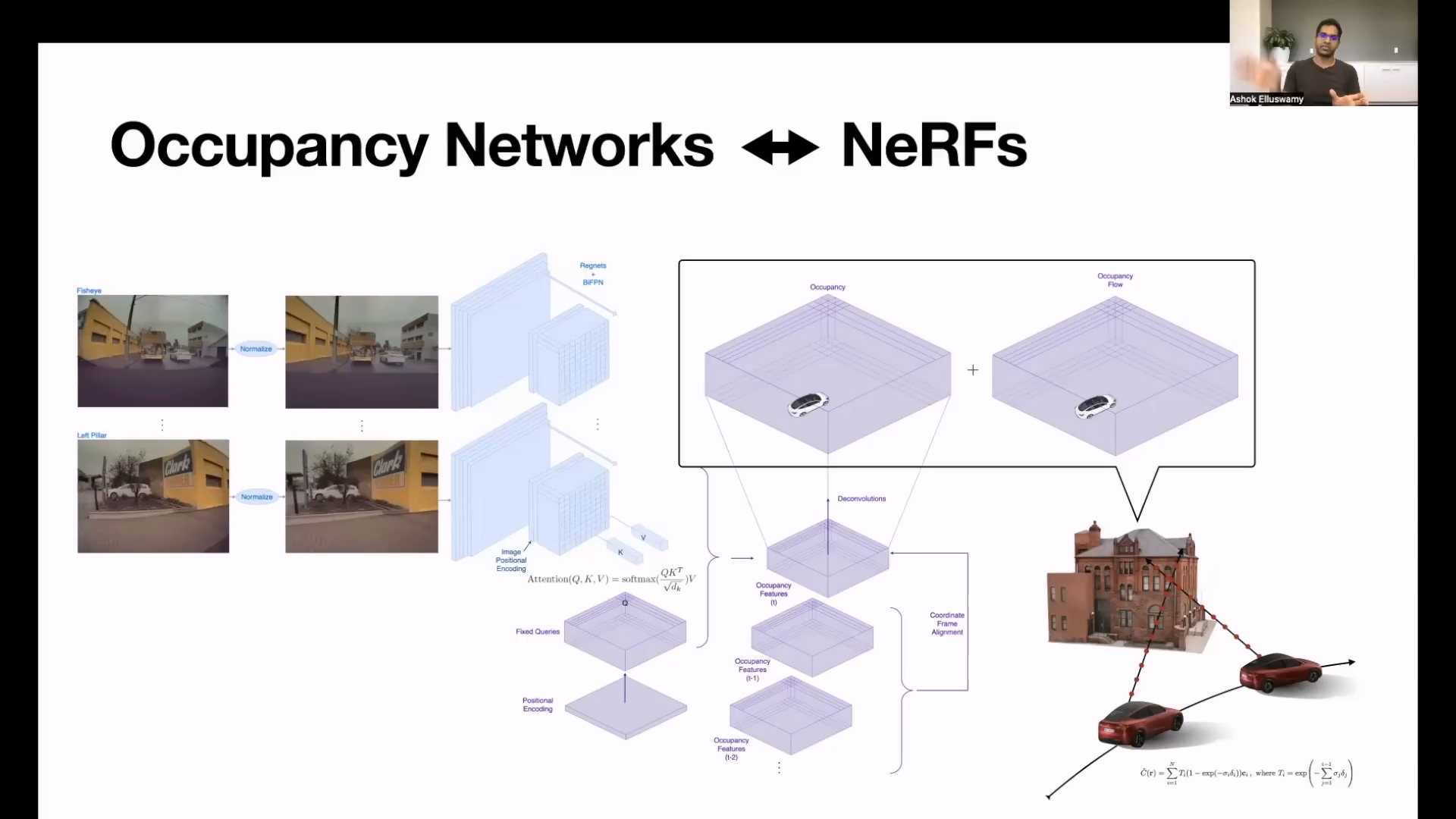
- 최종적으로
Occupancy Network의 Input, Architecture, Output과 Label 까지 모두 나타내면 위 슬라이드와 같습니다. - 테슬라에서는 부분적으로 차량에서 학습하는 기법을 사용하는 것이 지난번에도 공유가 되었습니다. 이번에 소개한 Occupancy Network 또한 NeRF를 이용하여 few-shot으로 3D reconstruction을 하고 부분적으로 최적화하기 위하여 차량에서 일부 학습을 진행함을 설명합니다.
- NeRF를 이용한 3D reconstruction과 네트워크 일부 학습을 차에서 진행한다는 것이 대단하다고 느껴지는 설명입니다.
Collision Avoidance

- 지금부터 살펴볼 내용은
Collision Avoidance에 관한 내용입니다. 본 글의 서두에 말씀드린 바와 같이 이번 발표의 핵심은 충돌을 어떻게 피하는 지에 관한 것입니다. - 지금까지 3D 공간 상에서
Voxel단위로 어떤 물체가 그Voxel을 점유한 지 유무를 살펴보았다면 그 정보를 활용하여Collision Avoidacne라는 기능을 어떻게 구현한 지 설명합니다.

- 위 슬라이드는 충돌 장면의 차 내부 장치의 움직임을 나타낸 것입니다. 왼쪽 상단 부터
AEB for pedal Misapplication,Driver Pressed Accel Pedal,Gear,Vehicle Acceleration에 해당하면 가로축은 시간축이고 세로 축은 각 장치의 센서값에 해당합니다. - 위 충돌 예시는 사람의 실수로 인한 충돌 예시이며 그 때 충돌에 영향을 주는 주요 인자의 변화를 그래프로 나타낸 것입니다. 그래프를 보면 가속 페달을 실수로 밟은 것으로 보입니다.
- 만약 차의 진행 방향등을 고려하였을 때, 충동 가능성이 있으면 사전에 충돌을 하지 않도록 입력된 센서값을 반영하지 않으면 충돌을 방지할 수 있습니다. 즉, 3D 공간 상에서 섬세하게 Freespace를 찾고 차의 이동과 관련된 센서값들을 이용하여 충돌 가능성을 계산해 내어야 합니다.

- 자율주행 기능을 유용하게 구현하려면
safe,comfortable,resonably fast3가지 조건을 만족하도록 구현하는 것을 목표로 합니다. - 이 때 단순히 충돌을 피하기 위해 급정거를 하거나 천천히 가는 전략이 아닌 실제 사용성이 있는 방향으로 구현하고자 하는 것이 테슬라의 목표입니다.
- 위 슬라이드에서 사용한
jerk라는 개념은 가가속도를 뜻합니다. 즉, 가속도의 변화량을 나타내며 식은 다음과 같습니다.
- \[r : \text{Position}\]
- \[\frac{dr}{dt} = r' : \text{Velocity}\]
- \[\frac{d^{2}r}{dt^{2}} = r'' : \text{Acceleration}\]
- \[\frac{d^{3}r}{dt^{3}} = r''' : \text{Jerk}\]
- 즉, 많은
jerk를 사용한다면 가속도의 변화량이 많아진다는 뜻이고 자차의 이동이 급변하는 지점이 많아진다는 뜻입니다. 즉, 현실적인 자차의 속도에 반할 수 있습니다.

- 테슬라에서는
Collision Avoidance를 사전에 알아차리기 위하여Obstacle Encoder를 추가하고Occupancy Networkfeature를 Encoder의 입력으로 사용합니다. Obstacle Encoder의 출력과vehicle state를 모두 이용하여 최종MLP (Multi Layer Perceptron)layer를 통해Collision Avoidance Implicit Field를 추론하며 각 영역의 충돌 가능성의 확률 값을 나타날 수 있도록 합니다.Implicit Field라고 하면 딥러닝 layer가 각 공간의 정보를 내부적으로 가지고 있어 특정 공간에 대한 정보를 확인하고자query를 입력하였을 때, 그 공간의 정보가 출력이 되도록 하는 구조를 말합니다. 이 때,vehicle state가query가 되어 학습된Implicit Field에vehicle state라는query를 입력하여 충돌 가능성을 확인합니다.vehicle state에는position( \((x, y)\) ),orientation(\(\theta\) ),velocity,lateral, longitudinal acceleration등이 포함됩니다.- 기존에는 딥러닝의 출력을 이용하여 충돌 가능한 공간과 충동 가능성을 확인하는 별도의 로직을 필요로 하였습니다. 별도 로직을 이용할 때, 충돌 가능 공간과 충돌 가능성을 확인하는 데 시간이 걸려 급정거를 하는 문제가 있었습니다. 하지만 위 슬라이드와 같이 딥러닝을 이용하여 빠르게 연산하였을 때, 수 micro seconds 단위에서 검출할 수 있음을 확인하였습니다. (따라서 위 슬라이드의 구조가 매우 간단하게 되어 있을 것으로 추정합니다.)

Collision Avoidance의 결과를 살펴보도록 하겠습니다. (실제 출력은 현재 위치에 대하여 충돌 가능성만 나타낼 뿐 위 그림과 같은 2D Bird’s Eye View 전체를 출력하지는 않을 것으로 추정합니다. 중요한 것은 현재 위치의 충돌 가능성 이기 때문이며 이 점만 알면 되기 때문입니다.)- 위 그림을 보면 크게
Obstacles,Unobservable region,Road surface,Road pain의 주변 형상이 있으며 자차ego vehicle을 원하는 위치에 둔 다음에 시뮬레이션을 할 수 있습니다. - 위 슬라이드의 예제는
Hheading angle과vvelocity를 변경하였을 때, 충돌 가능성을 왼쪽 BEV에서 나타냅니다.

- 먼저 위 그림에서는
Hheading angle을 변화하였을 때, 즉각적인 (instantaneous) 자차의 충돌 가능성을 나타냅니다. - 위 슬라이드에서 나타나는
H와V의 상태에서 각 픽셀의 위치에 자차를 위치시켰을 때, 안전하다고 판단되는 위치일수록 초록색으로 나타내었고 충돌 가능성이 있다고 판단하는 위치는 빨간색으로 나타냅니다. - 즉, 빨간색 영역에 해당하는 어떤 위치에 자차가 현재
H,V인 상태로 위치한다면 충돌할 위험이 높다는 뜻입니다. - 따라서 위 그림과 같이
H를 변경함에 따라 충돌 가능성이 높은 위치와 낮은 위치가 바뀌게 됨을 확인할 수 있습니다.

- 반면 위 슬라이드는 현재
H,V를 유지하였을 때 2초 이내에 충돌할 가능성이 있는 위치를 나타냅니다. - 2초의 이동 시간이 있기 때문에 충돌 가능성이 있는 위치가 크게 늘어난 것을 확인할 수 있습니다.

- 위 슬라이드에서는
Vvelocity를 변경하였을 때, 충돌 가능성이 큰 영역을 나타냅니다. V의 크기는 차 모양의 화살표로 나타내어 지며V의 크기가 커질수록 빨간생 영역 즉, 충돌 가능성이 큰 영역도 커지는 것을 확인할 수 있습니다.

- 마지막으로
H, V를 모두 수정하였을 때의 경향을 나타내며 앞선 예제를 확장한 것입니다.

- 위 그림의 그래프는 자차의 이동에 따른
velocity,acceleration,jerk를 차례로 보여줍니다. - 특히
jerk그래프를 보면longitudinal, lateral방향의 jerk 와 Collision Avoidance의 자차 주변 색이 같은 것을 확인할 수 있습니다.

- 위 슬라이드에서는 자차의 이동에 따른 각 차량의 움직인 이유를 1 ~ 4 번 항목으로 나누어서 설명합니다.
- 각 번호의 차량 움직임에서는 충돌을 피하기 위한 선회와 충돌 가능성이 낮을 때 속도를 낮추지 않고 이동하는 내용을 포함합니다.

Collision Avoidance모델을 학습하기 위하여 시뮬레이션 환경에서 부주의한 운전자의 운전 상황을 만들고 충돌을 회피하도록 만듭니다.

- 지금 까지 내용을 모두 정리하면 멀티 카메라의 영상을 입력으로 받고 Nerf를 이용한 3D Voxel 단위의 학습 데이터를 만들어 Voxel 단위로 물체의 존재 여부를 판단하는
Occupancy Network를 학습하고 그 결과Occupancy와Occupancy Flow를 예측 할 수 있습니다. - 추가적으로
Occupancy Network의 feature와Collision Avoidance Encoder를 이용하여Collision Avoidance Field를 생성하고vehicle state를query로 입력하였을 때, 자차의 충돌 가능성을 예측할 수 있도록 학습합니다.
- 여기 까지가 테슬라에서 CVPR 2022 Workshop에서 발표한 내용이며 이 내용을 기반으로 AI DAY 2022에 발표할 것으로 예상합니다.