15. Efficient Methods and Hardware for Deep Learning
2018, Jan 11
목차
-
Summary
Summary
Introduction
- 딥러닝이 발전함에 따라 모델 사이즈와 연산량이 해마다 커지는 추세이며 이에 따른 문제점이 제기되고 있습니다.
- ①
Model Size: 모바일이나 자율주행자동차 등에 무선망으로 배포하기에는 모델 사이즈가 큰 문제가 있습니다. - ②
Speed: Training time이 지나치게 길어질 수 있습니다. - ③
Energy Efficiency: 배터리 소모 문제 (모바일), 전기 비용 문제 (데이터 센터) 가 발생할 수 있습니다. 특히 이와 같은 경우 연산보다는 메모리 접근에 에너지 소모가 크므로 모델 크기를 줄이는 것이 중요합니다.
- ①
- 다음으로 숫자를 표현하는 데 사용하는 데이터 타입에 따른 배경 지식을 소개하겠습니다.
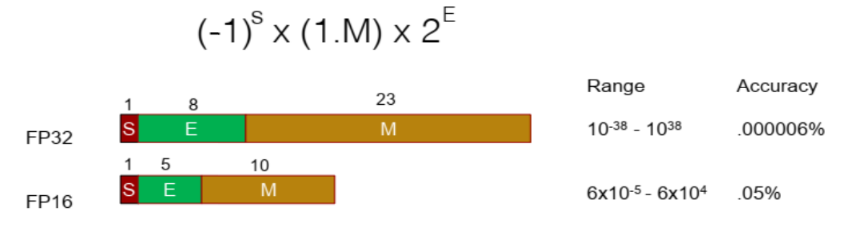
- 딥러닝 학습 시에 사용하는 대표적인 숫자 데이터 타입은
FP32와FP16입니다. 이 타입을 구성하는 비트 정보는 위 그림과 같으며 Range와 Accuracy도 확인하시기 바랍니다.
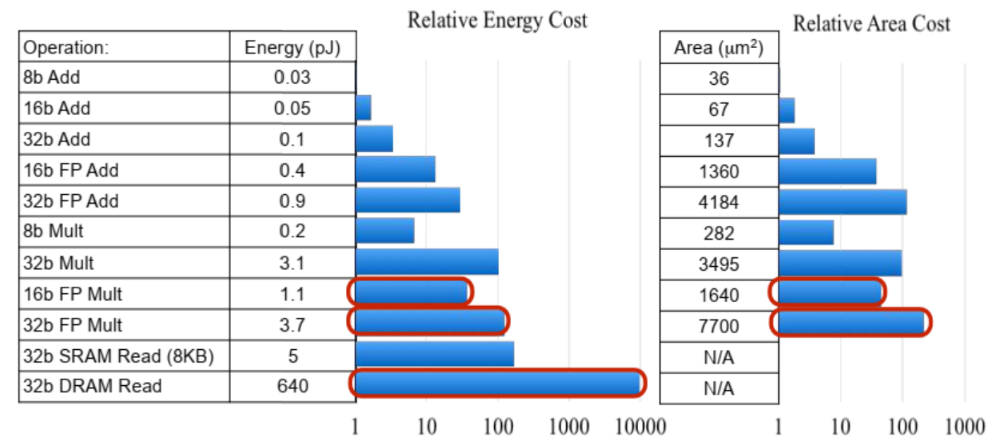
- 위 도표는 숫자 표현 및 메모리 접근에 대한 비용을 나타냅니다. 특히 메모리 접근에 대한 비용이 굉장히 큰 것을 알 수 있습니다.
- 이를 통하여 모델 사이즈 감소 및 가벼운 타입의 숫자 자료형을 사용하는 것의 중요성을 알 수 있습니다.
Algorithms for Efficient Inference
- 이번에는 효율적인 inference를 위한 몇가지 알고리즘에 대하여 알아보도록 하겠습니다.
- 먼저
pruning입니다. Pruning은 불필요하거나 성능에 큰 영향을 주지 않는 파라미터를 줄입니다. 다음과 같습니다.
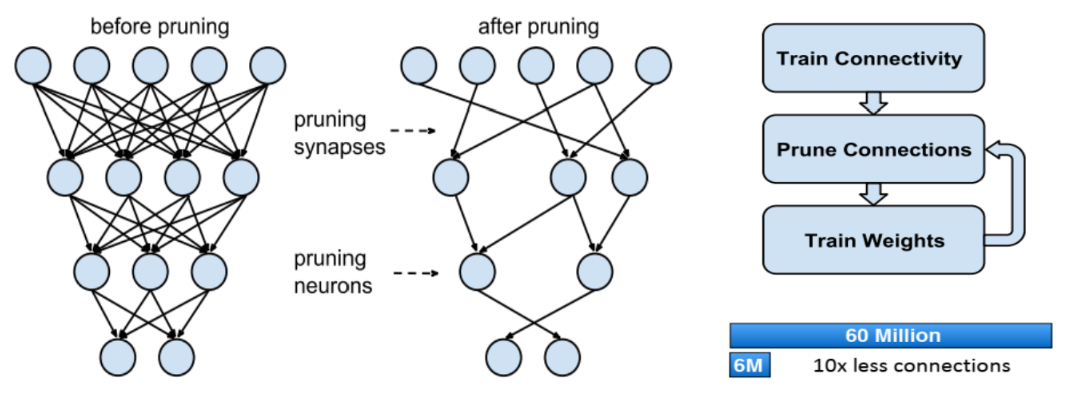
- 위 그림과 같이 pruning은 정확도 하락과 parameter pruning 사이에 trade-off를 가집니다.
- 반복적인 pruning과 retraining을 통하여 Han et al. (NIPS 15)에서는 AlexNet에서 90% 이상의 parameter pruning을 하면서 0.5% 미만의 정확도 하락을 보였습니다.
- 다음은
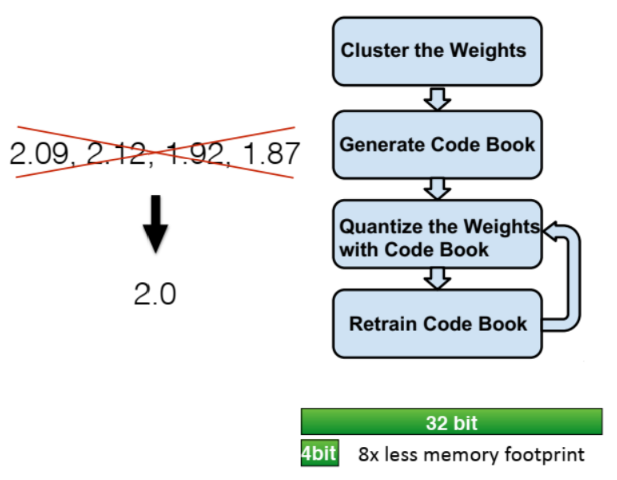
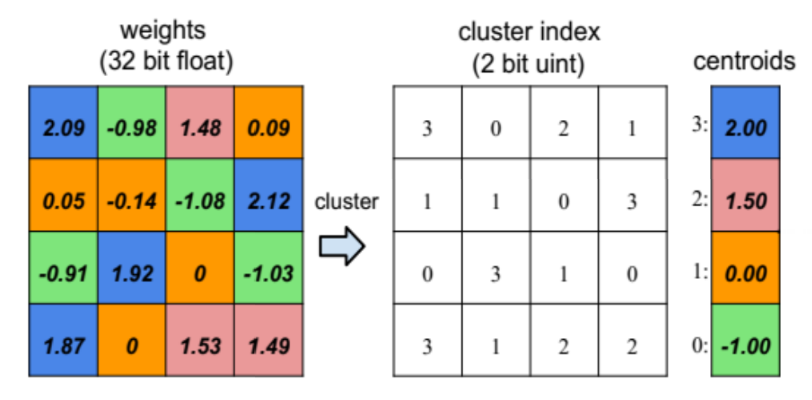
weight sharing입니다. 이는 비슷한 weight끼리 clustering 하여 같은 숫자로 표현하는 방법입니다. - 사용하는 parameter들을 적은 수의 숫자로만 표현하므로 정확도는 떨어지는 대신 숫자 표현에 사용되는 bit 수를 대폭 줄일 수 있어 간단하게 만들 수 있습니다. 일종의
quantization방법이라고 말할 수 있습니다. quantization이란 floating point 타입을 정확도를 크게 손상시키지 않는 선에서 더 적은 bit의 fixed-point로 변경하거나 integer 타입으로 변경하는 것을 말합니다.
- 또 다른 방법으로
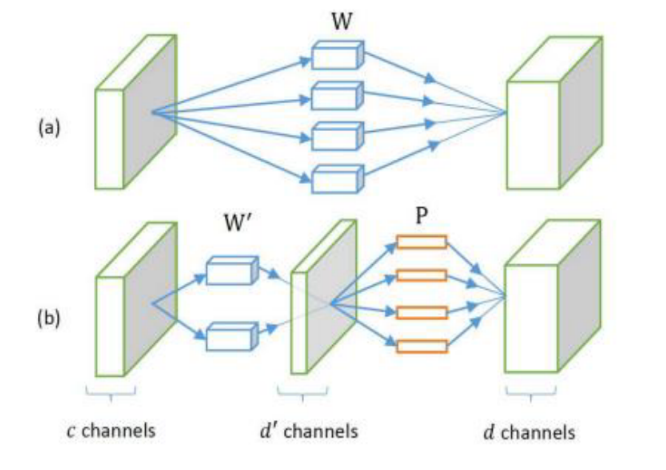
Low Rank Approximation이라는 방법이 있습니다. 이 방법은 아래 그림과 같이 복잡한 convolution layer 하나를 두개의 비교적 간단한 convolution layer로 분할하는 방법을 뜻합니다. Fully connected layer에도 이 개념은 적용 가능합니다.
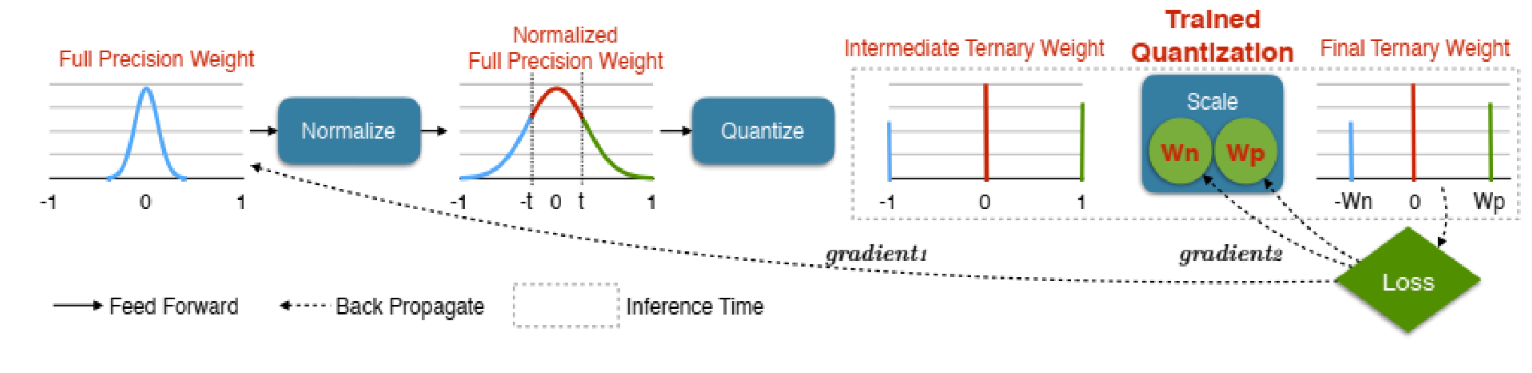
Tenary Net의 경우 아래 그림과 같이weight를 -1, 0, 1 즉, 3가지로만 표현하는 방법을 말합니다. 경우에 따라서 Binary로 0/1 로만 표현하는 경량화된 Network도 존재합니다.
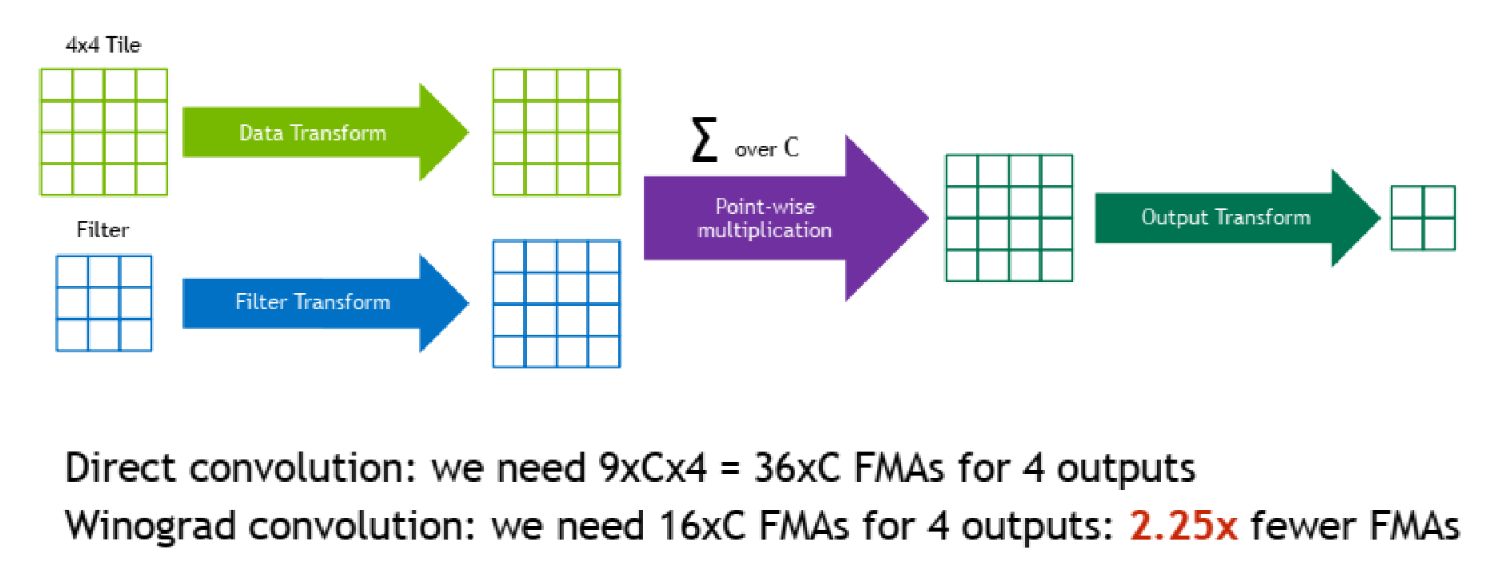
- 다음으로
Winograd Transformation이란 방법이 있습니다. - Convolution 연산 시 winograd transformation을 적용하면 matrix multiplication의 time complexity를 낮출 수 있습니다.
- 동일한 연산을 효율적으로 수행하는 것이므로 loss 없이 동일한 결과를 더 적은 시간 내에 얻을 수 있습니다.
Hardware for Efficient Inference
- 효율적인 inference를 위하여 하드웨어 측면에서의 연구도 이루어졌습니다. 예를 들어 CAS의 DaDianno, Google의 TPU, Stanford의 EIE 등이 있습니다. 이 하드웨어들의
공통적인 목표는 메모리 접근량의 최소화입니다.
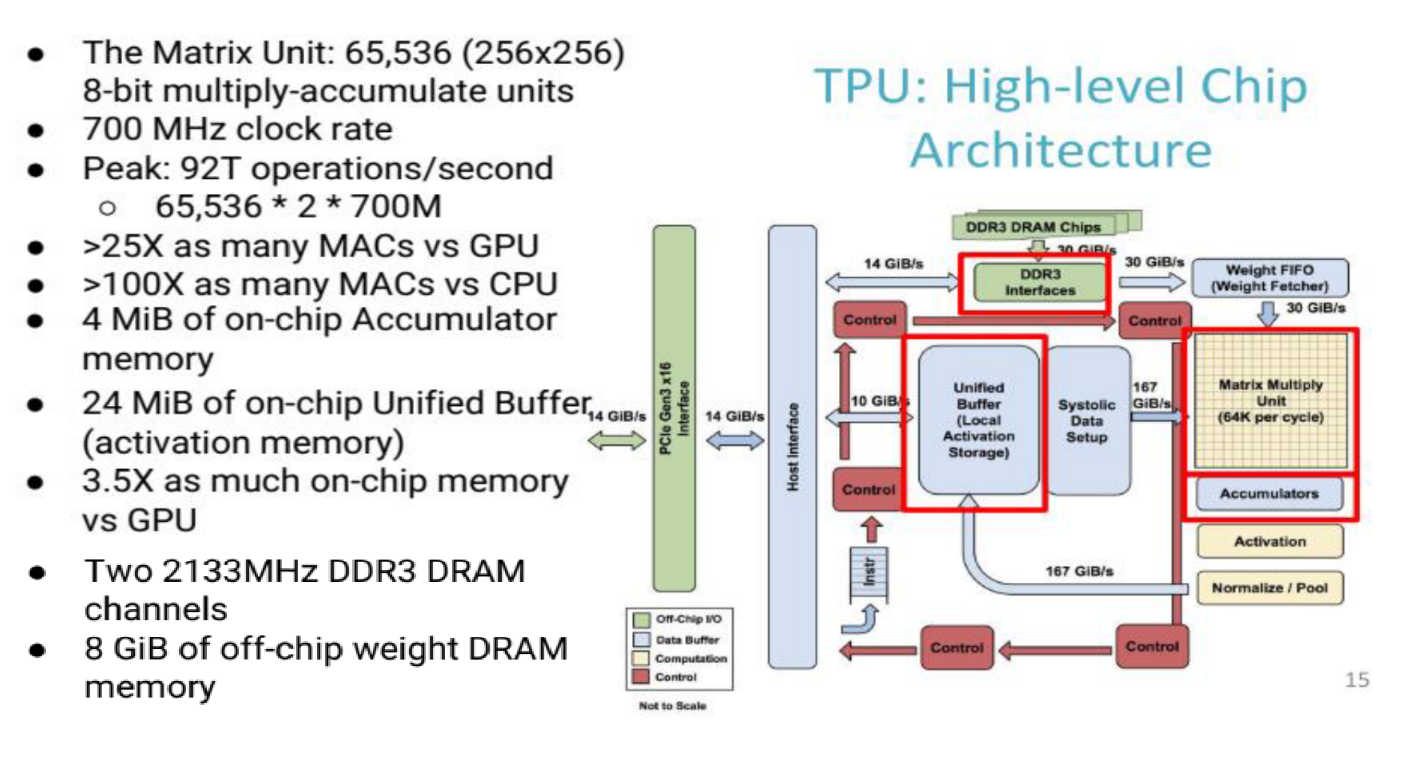
- 먼저 Google의
TPU에 대하여 알아보겠습니다. - 이 하드웨어는 당시 GPU와 비교하였을 때, Matrix Unit이 매우 커서 한 사이클에 가능한 matrix multiplication 수가 많은 것이 특징입니다. on-chip buffer와 on-chip memory의 크기가 당시 GPU에 비해서 비교적 큽니다.
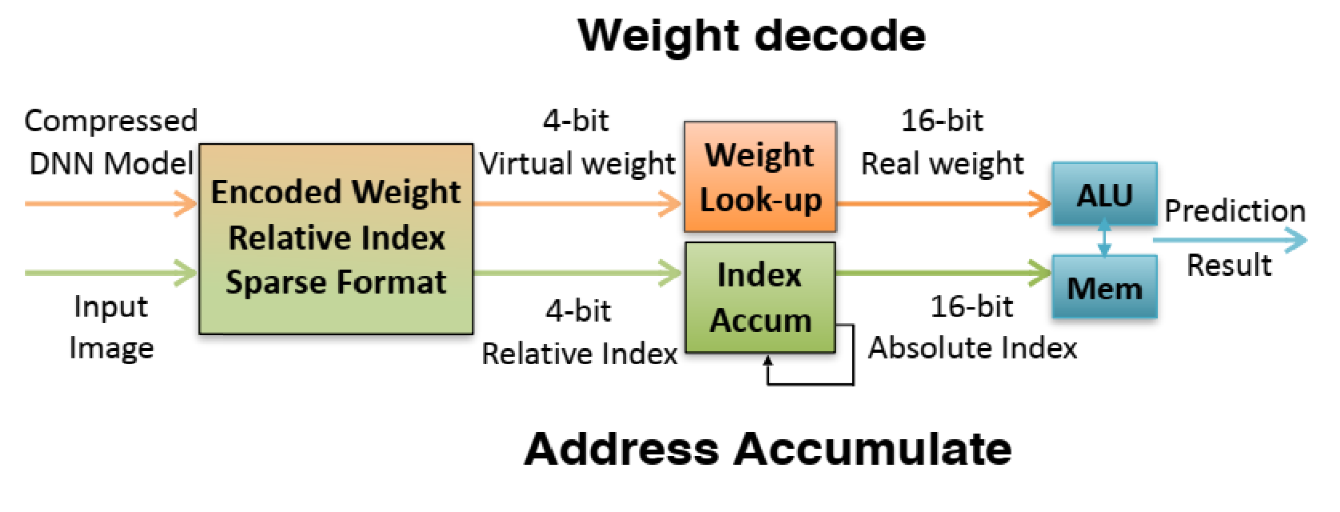
- Stanfor의
EIE의 특징은 data나 weight이 0인 연산을 skip 할 수 있어서 sparse matrix에 대한 연산에서 효율적인 전력 소모와 빠른 가속을 보입니다.
- 참고로 최근들어 GPU에서 코어 수와 memory size/bandwidth 가 증가하는 추세이며, Volta architecture 는 이전 세대인 Pascal architecture 에 없던 Tensor core가 추가되어 FP16 multiplication 의 가속을 지원하고 있습니다./
Algorithms for Efficient Training
- 먼저 학습 시 가장 효율적인 방법 중 하나는
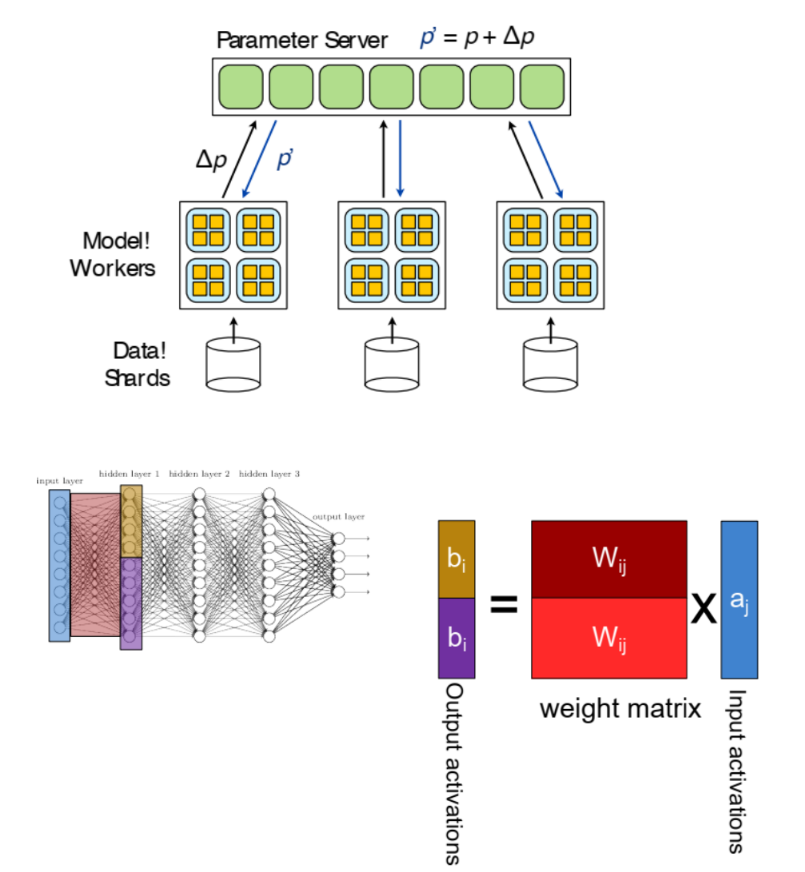
Parallelization입니다. 즉, 학습 시 병렬적으로 학습을 하는 방법을 뜻합니다. - 먼저
Data parallel방법은 여러 데이터를 동시에 학습하는 방법을 뜻하며, 각 worker들은 동일한 모델을 copy하여 보유하고 weight update는 parameter server에서 발생합니다. Model parallel방식은 아래 그림 예시와 같이 모델을 쪼개어 여러 worker에서 병렬 연산을 진행합니다.
- 다음으로
Mixed Precision with FP16 and FP32입니다. - 이 방법은 앞에서 언급하였듯이
FP16연산이FP32연산에 비해서 logic의 크기나 소모전력이 낮아서 효율적임을 이용하는 것입니다. - 그러나
FP16의 곱셈 결과는FP32로 저장해야 정확도가 보장이 됩니다. - 따라서 gradient를 accumulate하고 weight update할 때만
FP32를 쓰고, 나머지 부분에서FP16을 사용하면 전체 연산 효율을 증가시킬 수 있습니다.
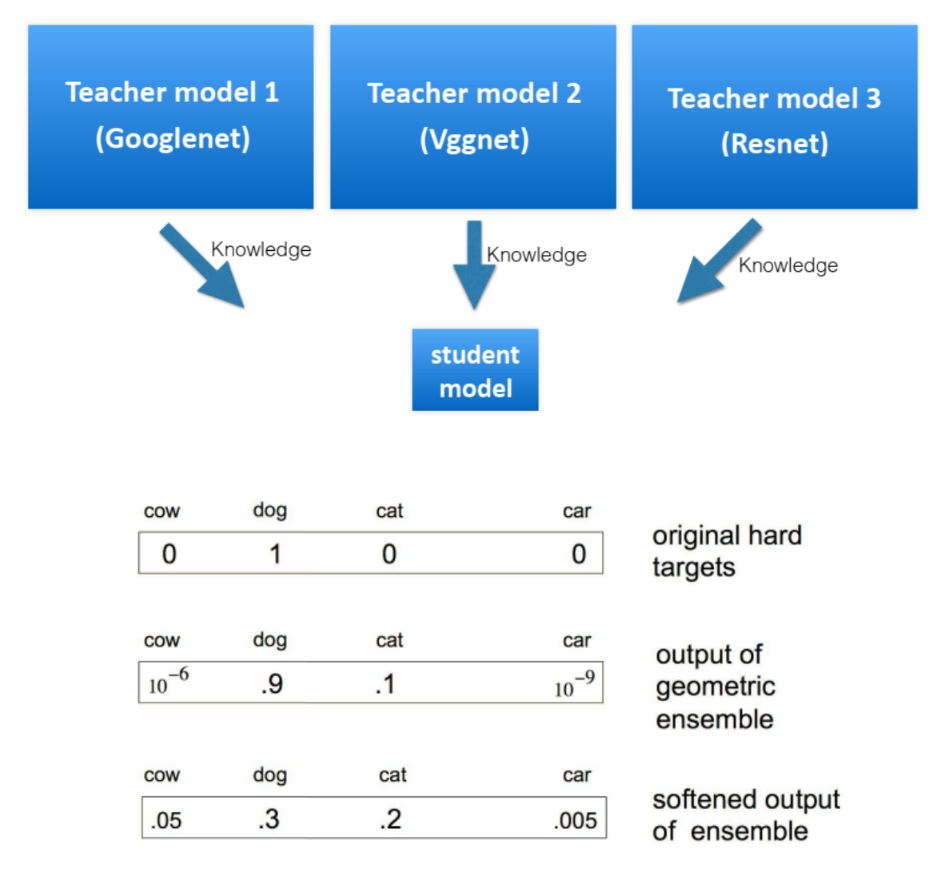
- 효율적인 학습 방법으로
Model Distillation방법이 있습니다. 이 방법은Teacher model을 이용하여 상대적으로 크기가 작은student model을 학습시킵니다. - 특히
Dark knowledge라는 개념은 재미있습니다. Student model을 학습 시 원본 one-hot encoded label 대신 teacher model의 softmax 결과를 사용하면 더 적은 수의 데이터로도 충분한 학습이 가능해집니다. (3% train data 사용, 정확도 58.9%에서 57.0%fh 1.9$만 감소; Hintol et al.)
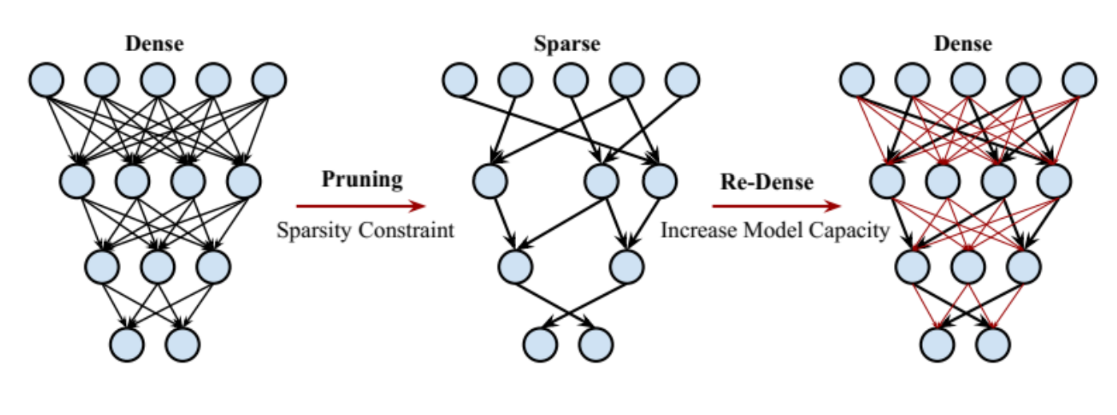
- 마지막으로
DSD : Dense-Sparse-Dense Training이라는 방법을 소개하겠습니다. - 원본 아키텍쳐를 학습시킨 이후, Pruning으로 핵심 parameter만 남긴 후, 나머지 (아래 그림에서 빨간색) parameter를 re-training 합니다.
- 나무에서 큰 뼈대를 먼저 학습한 후 잔가지를 학습하는 것이라 할 수 있습니다.
- 같은 아키텍쳐를 더 좋은 local minima로 이끄는 방법이라고 할 수 있습니다.