How Do Neural Networks See Depth in Single Images 리뷰
2022, Nov 26
- 논문 : https://openaccess.thecvf.com/content_ICCV_2019/papers/van_Dijk_How_Do_Neural_Networks_See_Depth_in_Single_Images_ICCV_2019_paper.pdf
- 이번 글에서는 Depth Estimation을 위한 뉴럴 네트워크가 단일 이미지에서 물체를 어떻게 인식하는 지 분석한 논문에 대하여 살펴보도록 하겠습니다. 논문 제목은
How Do Neural Networks See Depth in Single Images입니다.
목차
-
Abstract
-
Introduction
-
Related Work
-
Position Vs. Apparent Size
-
Camera Pose: Constant or Estimated
-
Obstacle Recognition
-
Concolusion and Future Work
Abstract

- 이번 글에서 다루는 논문은 뉴럴 네트워크를 이용한 Depth Estimation의 성능이 향상이 되었지만 어떻게 깊이를 추정하는 지에 대한 자세한 분석이 없어 그 분석에 대한 연구를 다룹니다.
- 논문에서 사용하는 모델은 monodepth2이며 이 모델을 기반으로 뉴럴 네트워크가 깊이를 추정할 때 민감하게 반응하는
visual cues를 살펴봅니다. - 그 결과 뉴럴 네트워크가 객체의 이미지 상의
vertical position에 민감한 것을 확인하였으며 객체와 지면과의 접촉면에서의edge가 중요함을 확인하였습니다.
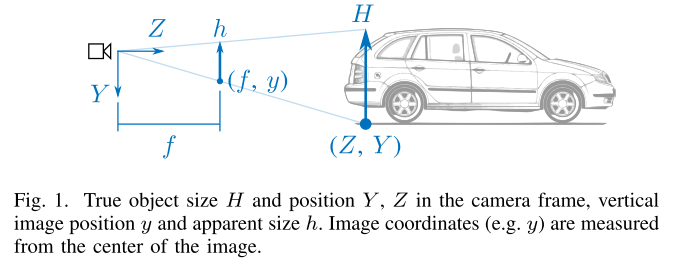
vertical position이란 위 그림의 \((f, y)\) 에서의 \(y\) 에 해당하며 이미지의 height 좌표축에서의 객체의 위치를 의미하며 \(y\) 값이 작을수록 상단을 의미하고 이미지 상의 하늘에 가깝고 \(y\) 값이 클수록 하단을 의미하여 이미지 상의 땅에 가까움을 의미합니다.
Introduction

- CNN 기반의 Depth Estimation 연구가 시작되면서 Depth Estimation의 성능이 많이 발전하였으며 처음에는 Supervised Learning 방식의 연구가 진행되었으나 본 논문의 저자인 Godard의 monodepth1, monodepth2의 발전으로 Self-supervised Learning 방식의 Depth Estimation이 연구로 방향이 전환되었습니다.

- 본 논문의 연구 바향은 뉴럴 네트워크가 이러한 좋은 성능을 내기 위해서 어떤 방향으로 학습하는 지 알기 위함으로 접근되었습니다.
- 이러한 접근 방식이 중요한 이유는 ① Depth Estimation 뉴럴 네트워크의 Visual Cue와 학습 메커니즘을 모르면 예상치 못한 시나리오에서의 동작 방식을 보장할 수 없고 ② 학습 메커니즘의 파악을 통하여 실제 학습 시 도움을 줄 수 있으며 ③ 카메라 장착 위치의 변화에 따른 부작용을 예상할 수 있기 때문입니다.

- 본 논문의 본문은 크게 3가지 파트로 구분되어 있습니다.
Section Ⅲ에서는 monodepth 모델이 객체를 인지할 때, 객체의 크기가 아니라 이미지에서의vertical position에 의존적임을 보여줍니다.Section Ⅳ에서는 monodepth 모델이 카메라 포즈를 고정된 값으로 여기는 지 살펴봅니다.Section Ⅴ에서는 monodepth 모델이 어떻게 객체와 배경을 구분하는 지와 학습 데이터셋에 없는 개체를 인지할 때 어떤 요소가 작용해서 객체를 인지하는 지 살펴봅니다.
Related Work

- 뉴럴 네트워크의 동작 방식을 확인하기 위하여 feature visualization을 이용하는 방법이 대중적인 방법인 반면 이번 논문에서는 입/출력 간의 상관 관계를 확인하기 위하여 특정
visual cue를 추가하였을 때, 결과가 어떻게 바뀌는 지 확인하고 이 결과의 상관관계를 살펴보는 방식으로 분석합니다. - 위 8개 항목에 대하여 분석하고자 하였으나 KITTI 데이터셋 환경에서의 제한으로
Position in the image,Apparent size of objects에 대하여 집중 분석하였습니다. Position in the image에서Position은Vertical Position을 뜻하며 이는 앞에서 설명하였습니다.Apparent size of objects는 이미지 상의 물체의 크기를 나타냅니다. 실제 이미지 크기를 Real-World size라고 한다면 이 크기는 불변이지만 이미지 상의 물체의 크기인 Apparent size는 원근법으로 인해 이미지의 크기에 따라 영향을 받습니다.- 이와 같은 연구의 배경으로실제 사람이 물체를 인식할 경우에 물체의 수직 위치와 크기, 배경 등이 중요한 것이 연구되었고 수평선(horizon line) 또한 중요한 요소임이 연구되었습니다.
Position Vs. Apparent Size
- 먼저 객체의 위치 (Position)와 크기 (Size)가 깊이를 추정하는 데 어떤 영향이 있는 지 살펴보도록 하겠습니다.
- 본 논문의 실험 조건은
focal length는 고정값을 사용하여 실험을 진행하였습니다.
- 위 식에 따라 \(Z\) 값은
핀홀 카메라에서 아래와 같이 구해집니다.
- \[Z = \frac{f}{h}H\]
- 즉, 실제 물체의 크기가 알려져 있다면 위 식을 통해 실험을 해볼 수 있습니다.
- 또 다른 방법으로 특정 객체의 크기 정보가 없더라도 지면이 평평하고 고정된 카메라 포즈 정보를 가지고 있다면 아래 식을 이용하여 구할 수 있습니다.
- \[Z = \frac{f}{y}Y\]
- 위 식에서 \(Y\) 는 실제 지면이고 \(y\) 는 이미지 상의 지면입니다.
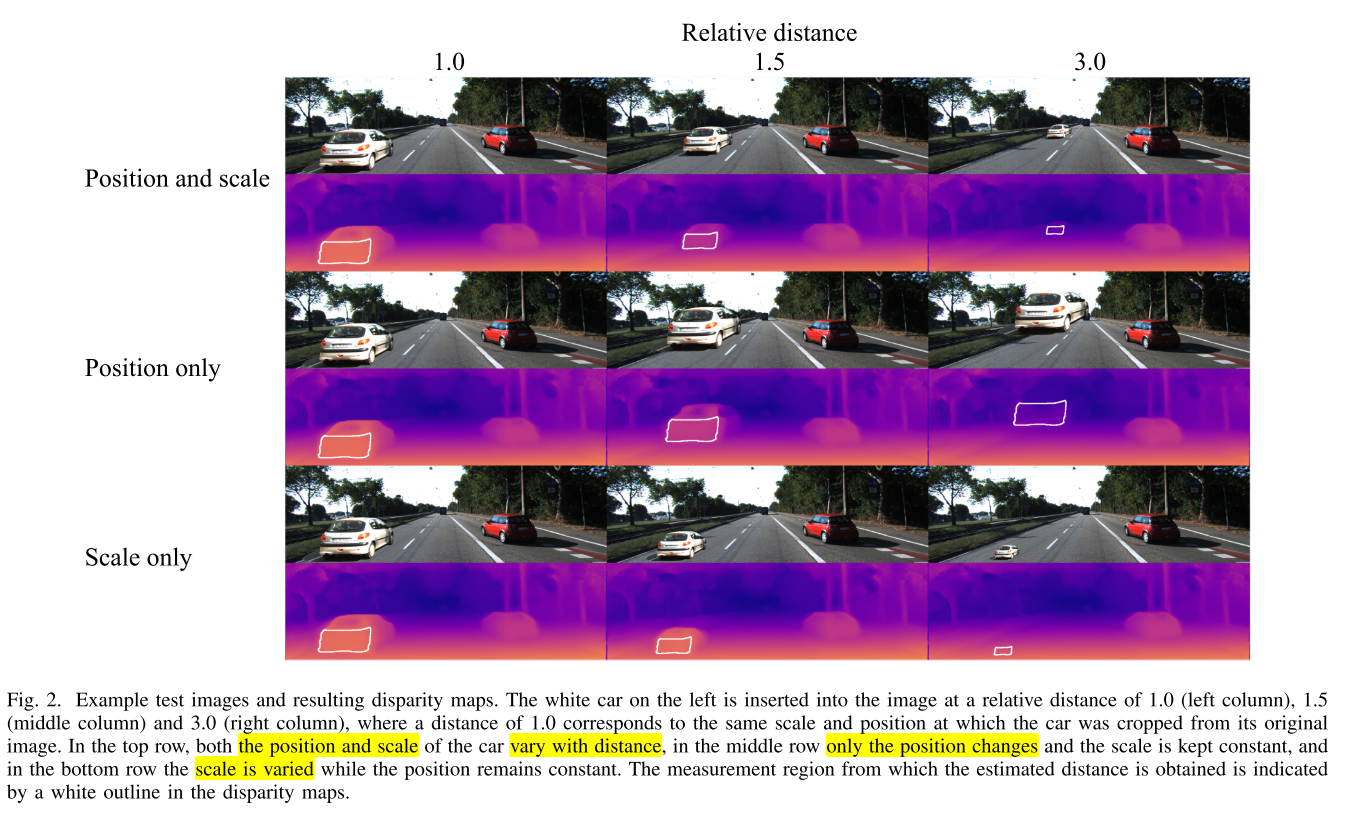
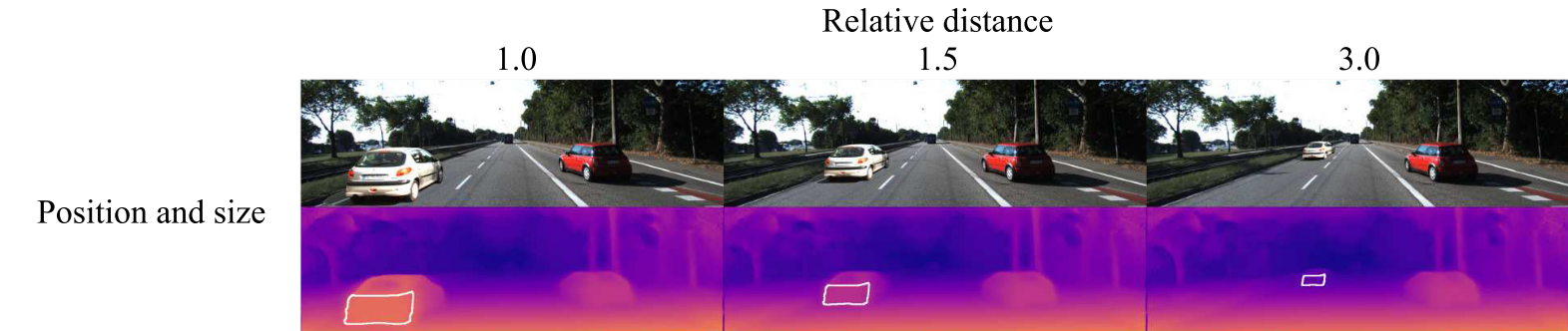
- 위 그림과 같이 위치와 크기를 모두 변경하거나 위치만 변경 또는 크기만 변경한 경우로 나누어서 분석하였으며 크기의 변경은 Relative distance가 1.0, 1.5, 3.0인 경우로 나누어서 적용하였습니다. 첫 행의 Position and scale이 위치에 따라 크기도 변경되는 일반적인 경우에 해당합니다.
Position and scale,Position only,Scale only의 케이스를 생성하기 위하여 사용된 도로 환경 및 객체는 KITTI 데이터 셋에서 추출하여 사용하였습니다.- 추출하여 삽입한 객체의 실제 거리는 라이다를 이용하여 만든 depthmap을 사용하더라도 정확히 알기는 어렵기 때문에
relative distance를 이용하여 성능 평가에 사용하였습니다. relative distance를 구하기 위하여 사용되는 스케일과 식은 다음과 같습니다.
- \[\text{scale : } s = \frac{Z}{Z'}\]
- \[x' = x \frac{Z}{Z'}\]
- \[y' = h_{y} + (y - h_{y})\frac{Z}{Z'}\]
- 위 식에서 \(x', y'\) 는 객체와 지면이 접하는 지점의 좌표이며 \(h_{y}\) 는 이미지 상의 수평선을 의미하며 고정값으로 사용합니다.
- 위 이미지의 분류인 scale 값인 1.0, 1.5, 3.0은 \(s\) 값이 변하도록 한 것입니다.
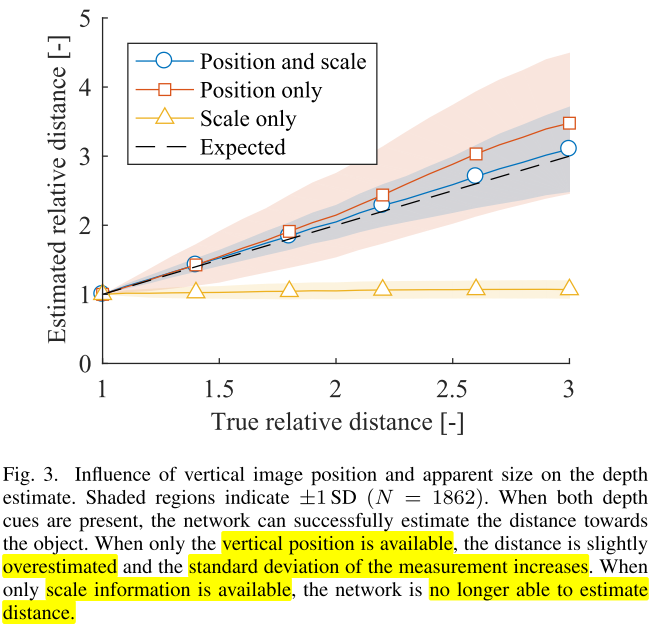
true relative distance와expected relative distance와의 관계를 확인하였을 때,position and scale의 expected relative distnace가 true relative distance와 가장 비슷하였습니다. 그 다음으로position only가 비슷하였으며 에러가 더 커졌지만 유사한 수준으로 보입니다.- 반면
scale only의 경우 distance 변화가 거의 없어보이며 에러가 점점 커지는 것을 볼 수 있습니다. 즉, relative distance가 1.0인 경우를 그대로 사용하는 것으로 보입니다. - 또한 사이즈만 변하는
scale only의 경우에 바닥과의 접점이 유지되는 것을 보면vertical position이 중요한 역할을 하는 것으로도 볼 수 있습니다. - 따라서
vertical position이 깊이를 추정하는 데 큰 역할을 하는 것으로 확인할 수 있습니다.
vertical position에 영향을 받는 것은 monodepth 모델이 지면이 평평하다고 가정하는 것과 카메라 포즈에 대한 사전 지식이 있다는 것을 뜻하기도 합니다.- 이번에는 카메라 포즈에 대한 영향을 알아보도록 하겠습니다.
Camera Pose: Constant or Estimated

vertical position을 이용하여 깊이를 추정하려면 카메라의 높이와 pitch 등의 정보를 알아야 합니다.- monodepth 네트워크는 카메라의 pitch를 이미지를 통해 추정하거나 카메라 포즈가 고정이라고 간주하고 동작합니다. KITTI 데이터 셋에서는 차 움직임에 의한 pitch 또는 떨리는 움직임, 현가 장치의 움직임이나 지면의 경사 등이 있으나 잘 동작합니다.
- 하지만 학습에 사용된 카메라 장착 환경과 다른 환경 (차종이 다른 차, 카메라의 높이가 다른 경우 등)에서 사용할 경우 문제가 발생할 수 있습니다.
- 따라서 monodepth가 단순히 고정된 카메라 장착 환경만을 가정하는 지 또는 장착 환경을 예측하여 어느 정도 보정 작업이 있는 지 확인이 필요합니다.
Camera pitch
- 아래는 **① 차량의
pitch변화로 인한estimated horizon level의 분석 내용입니다.

- 만약 monodepth가
camera pitch를 측정할 수 있으면camera pitch가 변경됨에 따라 depthmap에 변화가 발생해야 합니다. 또는camera pose가 지면에 대하여 고정되어 있다면 depthmap에서도 지면의 표면이 고정되어 있어야 합니다. - 논문에서는 KITTI 데이터셋에서 발생하는 차량의
pitch또는heave(차량의 들썩거림) motion에 의한 영향을 관찰하여 monodepth의 결과에 반영되는 지 확인하였습니다. 영향성을 확인하기 위하여true horizon level과 depth estimation을 통한estimated horizon level의 비교를 하였습니다. 실제 horizon level은 라이다를 통해 취득한 depthmap에서 정보를 취득하였습니다.
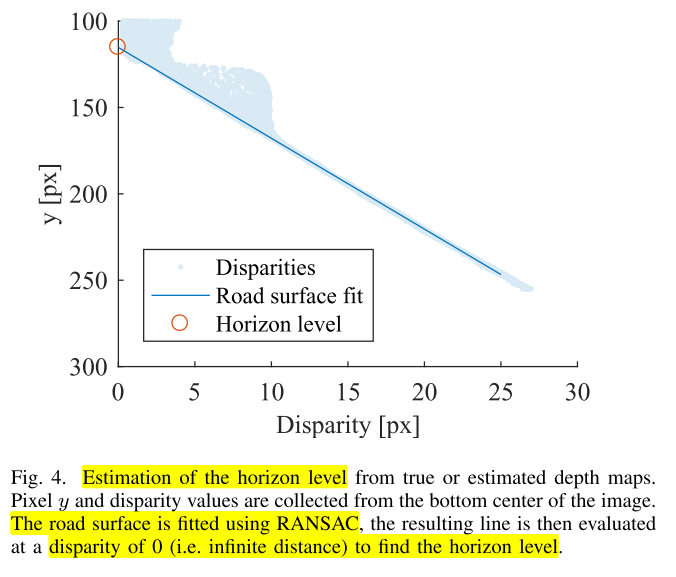
- depth estimation에서의 disparity들을 RANSAC을 이용하여 fitting 하여 나오는 선을 Road surface fit이라는 선으로 표현하였으며 이 선을 extrapolate하였을 때, disparity가 0인 지점을
estimated horizon level라고 추정합니다. 수평선의 경우 깊이가 무한하기 때문에 이와 같은 추정 방식을 사용합니다.
estimated horizon level과true horizon level을 비교하면 아래와 같습니다.
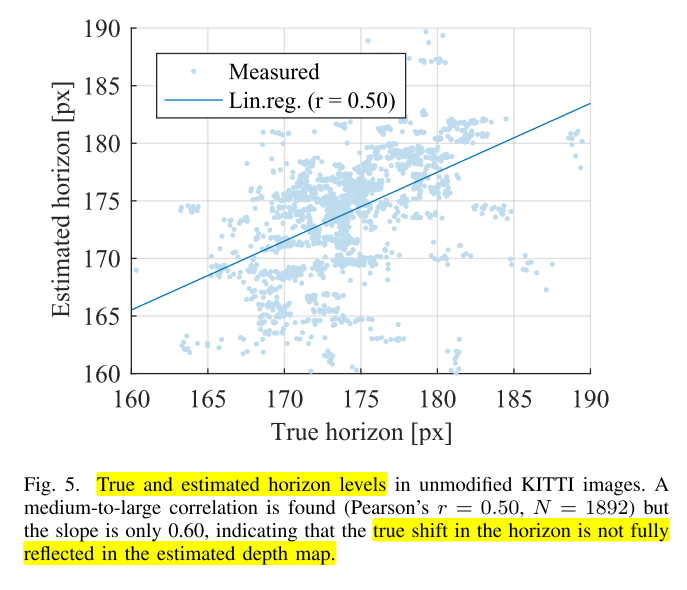
- 먼저 분석 결과를 살펴보면 상관계수가 0.5으로
애매한 상관관계를 가지는 것을 알 수 있고 그 결과 line의 경사도 0.6으로 True horizon과 Estimated horizon이 비례 (1.0) 하지 않음을 알 수 있습니다.
- 아래는 ② 이미지 crop을 이용한
horizon level이동에 따른 추정된 depthmap의horizen level변화를 확인한 내용입니다.


camera pitch를 구현하기 위하여 이미지의 중앙 부근을 crop 하여 pitch angle의 변화를 표현하였습니다. 픽셀의 변화는 -30 ~ +30 범위로 위 아래로 움직였습니다. 이 움직임은 카메라의 -3 ~ +3 도의 pitch 변화에 해당합니다.- horizon level의 변화를 확인하기 위하여 이미지 상에서 crop의 방식을 다르게 함으로써 변화게 생긴 horizon level을 depth estimation 결과가 얼만큼 똑같이 변화를 줄 수 있는 지 살펴봅니다.
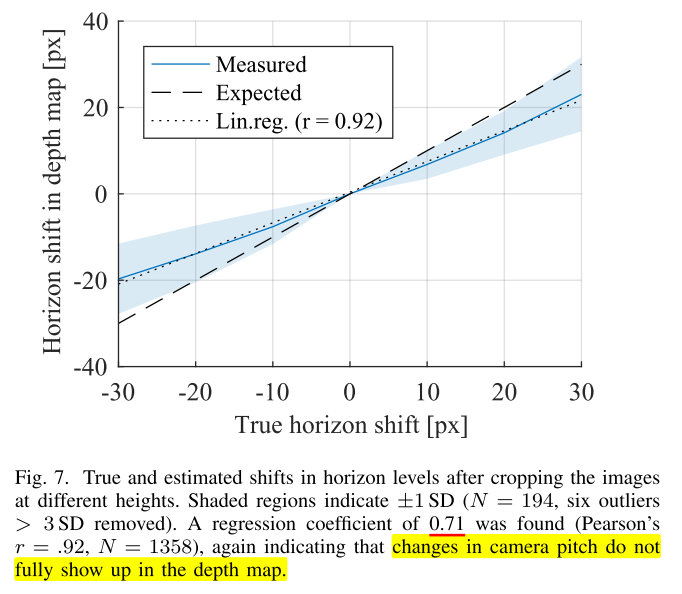
- 그 결과 위 그래프와 같이 관계를 살펴볼 수 있습니다. 검은색 점선과 같이 나오길 기대하나 파란색 선과 같은 관계를 확인할 수 있었으며 이 기울기는 약 0.71에 해당하므로 1.0과 차이가 있습니다. 다만 상관계서는 0.92로 높게 나와서 상관관계는 있다고 말할 수 있으나 depth estimation 결과가 실제 정답만큼 따라가지는 못하는 것을 알 수 있습니다.
- 하늘색 영역은 -1 ~ +1 표준편차 영역을 나타냅니다.
- 아래는 ③
horizon level이동에 따른 객체의 깊이 추정 변화량 확인 내용입니다.

- 앞에서 살펴본 바와 같이 Depth Estimation에서
Vertical Position의 역할이 큰 것을 알 수 있었습니다. - 만약 이미지에 어떤 객체가 있고 직전 실험과 동일한 방식으로
camera pitch의 변화를 주었을 때, 객체의 depth estimation의 변화가 있으면horizon level의 변화가 객체의 depth esimation 결과에도 영향을 준다고 생각할 수 있습니다.
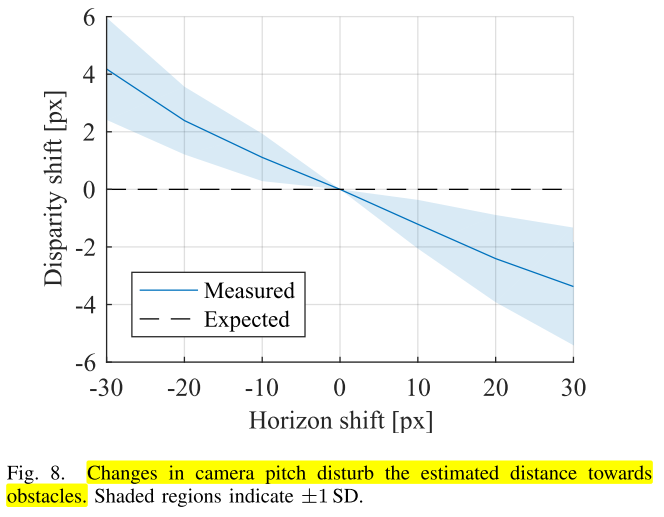
horizon level이 변화하더라도 객체의 거리가 변한것이 아니기 때문에disparity shift는 발생하지 않아야 합니다. 즉, depth esimation의 결과에 변화가 없어야 합니다.- 하지만 위 그래프를 통해 측정한 결과를 살펴보면 큰 차이가 발생하는 것을 알 수 있습니다. 즉,
horizon level이 depth estimation을 하는 데 큰 영향을 준다는 것을 알 수 있습니다.
camera pitch에 대한 실험 분석을 정리하면 다음과 같습니다.- ① 차량의 움직임에 의해 발생한
pitch의 변화를 라이다를 통해 얻은true horizon level과 depth estimation의 결과를 RANSAC으로 fitting 하여 얻은estimated horizon level의 상관관계 분석 시 어느 정도 상관은 있으나 충분한 상관관계를 나타낼 수 없으므로pitch의 변화를 모두 반영할 수 없습니다. - ② 이미지 crop을 이용한
horizon level이동에 따른 추정된 depthmap의horizen level변화를 확인한 결과 상관관계는 충분히 있으나 crop한 이미지에서 변화된 만큼 depthmap 출력에서 반영되지 않음을 확인하였습니다. - ③
horizon level이동에 따른 객체의 깊이 추정 변화량 확인 시 고정된 객체라도 이미지 상의horizon level이 변화하니 추정된 깊이값의 변화가 나타나는 것을 확인하였습니다.
- 따라서
camera pitch변화에 의한 depth estimation의 영향이 있음을 확인하였고 monodepth가 그 변화는 감지할 수 있으나 그 변화에 맞게 충분히 보상해주지는 못하는 것을 확인하였습니다.
Camera roll
- 이번에는
camera roll에 대하여 간단히 다루어 보도록 하겠습니다.

- 위 그림과 같이
camera roll이 발생한 상황을 가정하여 이미지 중앙 부분을 rotation 하여 crop을 한 후 rotation한 각도 만큼 depthmap에서도 반영되는 지 살펴보았습니다. camera pitch를 고려할 때에는vertical position만 고려하였지만camera roll에서는horizonal position도 고려해야 합니다.

camera pitch케이스와 유사한 방식으로 논문에서는 실험을 하였고 이미지에서 수평 성분을 뽑기 위하여 disparity가 0.03 ~ 0.0031 사이의 점들만 샘플링 한 다음 Hough Line Detector를 이용하여 수평선을 찾습니다.- 이렇게 찾은 수평선을 통해 추정한 각도와 실제 각도 간의 차이를 비교하면 다음과 같습니다.
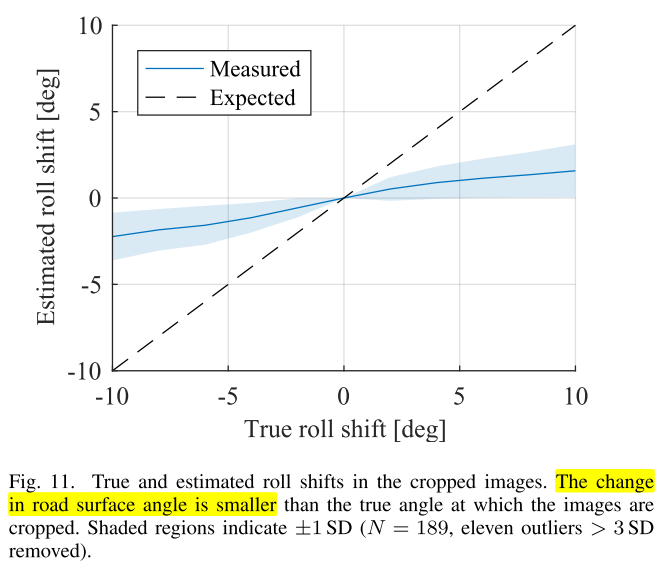
- 위 그래프를 통해 depthmap의 결과를 이용하더라도
camera roll이 발생한 것은 확인할 수 있으나 실제camera roll이 발생한 것보다 인식 수준에서 차이가 많이 나는 것을 확인할 수 있습니다.
Obstacle Recognition

- 지금까지 살펴본 내용으로
monodepth는 객체의vertical position을 참조한다는 것을 확인하였고 추가적으로 객체가 지면과 접하는 지점을 이용한다는 것도 확인하였습니다. - KITTI 데이터셋을 통해 학습한 monodepth는 지면과 접한 물체 특히 자동차와 관련된 물체를 인지할 수 있으며 반대로 자동차와 무관한 물체는 인식하는 데 어려움이 있었습니다. 또한 지면은 평평한 것으로 간주하는 것으로 확인하였습니다.

- 위 그림과 같이 자동차는 정확히 인식하지만 냉장고나 개 같은 경우 인지를 못한것을 알 수 있습니다.
- 그러면
monodepth가 객체를 인식할 때 어떤 점을 고려하는 지 ① 물체 표면의 색상이나 질감의 측면과 ② 모양 측면에서 분석해 보도록 하겠습니다.
color and texture
- 먼저 이미지의
color와texture가 monodepth에 어떤 영향을 미치는 지 살펴보도록 하겠습니다.


- 이 파트에서는 RGB 이미지를 4가지 방식으로 변형을 하여 성능을 확인한 결과를 설명합니다. 먼저
grayscale이미지와 segmentation 정보를 이용하여False colors,Class-average colors,Semantic rgb로 이미지를 각각 변형하여color가 성능에 어떤 영향을 주는 지 살펴보았습니다.
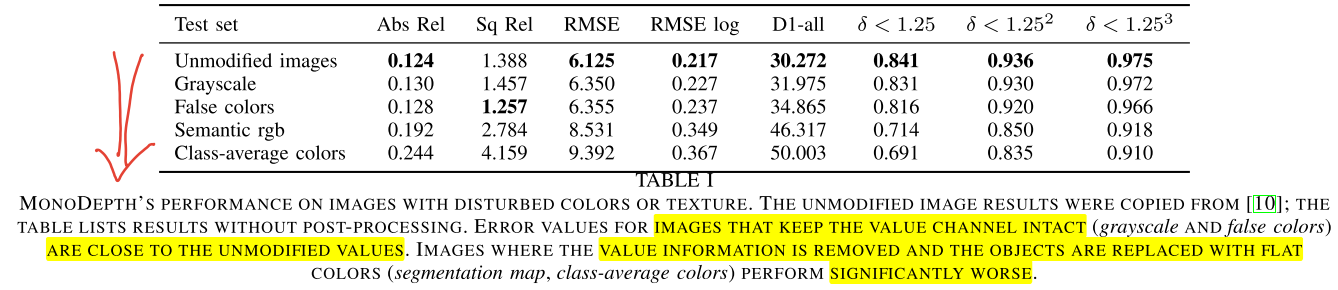
- 가장 성능이 좋은 인풋은 원본 이미지이며 Grayscale, False color, Semantic rgb, Class-average colors 순서로 성능이 나빠집니다.
- 마지막 Class-average colors 이외의 케이스에서는 성능 하락이 발생하지만 큰 성능 하락은 아닐 수 있습니다. 하지만 Class-average colors는 큰 성능 하락이 발생하였는데 이 점을 통하여 monodepth가 color 값에 민감하기 보다
contrast즉, 인접 영역 간의 밝기 차이 등에 성능이 민감한 것을 확인할 수 있었습니다.
shape and contrast
- 객체에 가장 큰 영향을 주는 것은
vertical position이고 도로와 객체 간의 경계가 중요함을 확인하였습니다. shapeandcontrast부분에서는 이 점을 기반으로 크게 3가지 실험을 진행합니다.

- ① 객체의 texture나 shape 보다는
vertical position과 도로와 객체가 만나는 객체의 하단 부분이 중요함을 보여줍니다.

- 위 상단, 하단 그림을 비교해 보면 하단의 그림에서는 texture를 완전히 제거하였음에도 불구하고 인식이 잘 되는 것을 볼 수 있습니다. 따라서
vertical position및 객체의 하단이 중요하며 texture가 중요하지 않음을 보여줍니다.
- ② 객체의 하단 부분과 측면 부분의
경계가 객체를 인식할 때 중요함을 보여줍니다.

- 위 그림과 같이 객체의 하단과 측면의 edge만 있으면 깊이를 추정하는 데 큰 문제가 없으며 심지어 객체 내부가 비어져 있어서 상관이 없음을 위 실험에서 보여줍니다.
- 특히 객체 하단 경계가 없으면 전혀 인지를 못하는 것에서 객체 하단 경계의 중요함을 보여줍니다.
- ③ 객체의 바닥면에 그림자를 추가하여 객체와 지면과의 의미를 더 부여하면 인식하지 못하던 객체도 인식할 수 있음을 실험적으로 보여주었습니다.
Concolusion and Future Work

- 본 논문은
monodepth의 KITTI 데이터셋으로 학습하여 실험을 진행하였으며 그 결과 monodepth2 모델은vertical position에 매우 민감하며camera pose에 영향을 받으며camera pose의pitch,roll의 변화가 발생하였을 때, 그 변화에 대한 인지는 가능하나 충분히 네트워크 자체로 보정하기는 어려움을 확인하였습니다. - 추가적으로 데이터 셋에 없는 객체라도 주변 환경 (객체와 지면 사이의 그림자 등)에 따라서 인식이 가능할 수 있음을 확인하였습니다.