
Monodepth2, Digging Into Self-Supervised Monocular Depth Estimation
2021, Jun 01
- 논문 : https://arxiv.org/abs/1806.01260
- 깃헙 : https://github.com/nianticlabs/monodepth2
- 참조 : https://towardsdatascience.com/depth-prediction-autonomous-driving-18d05ff25dd6
- 이번 글은
monodepth2에 대한 내용으로monodepth1에서 사용한 Left Right Consistency를 위한 스테레오 카메라의 학습 데이터 문제를 개선하여 동일한 시점의 left, right 영상이 아닌 연속된 단안 카메라 이미지 (\(I_{t-1}, I_{t}, I_{t+1}\)) 3장을 이용하여 딥러닝 모델을 학습하여 단안 카메라의 깊이를 추정 하는 내용의 논문 리뷰 입니다. - 현재 단안 카메라를 이용하여
Self-supervised방식으로 depth를 추정하는 많은 방식들이 다루어 지고 있고 그 모델들의 기본이 되는 모델 중 하나가 monodepth2이며 코드 공개와 방법이 자세히 설명되어 있는 몇 안되는 모델 중 하나로 이번 글을 통하여 내용을 깊게 확인해 보고자 합니다. disparity와 관련된 내용을 이해해야 monodepth2의 학습 방식을 이해할 수 있습니다. 아래 링크 내용을 참조하셔서 사전 필요한 지식을 먼저 읽으시길 권장 드립니다.- 3D 컴퓨터 비전의 기초 : https://gaussian37.github.io/vision-concept-basic_3d_vision/
목차
-
전체 내용 요약
-
Abstract
-
1. Introduction
-
2. Related Work
-
3. Method
-
4. Experiments
-
5. Conclusion
-
6. Supplementary Material
-
Monodepth2의 한계 상황
-
Pytorch Code
전체 내용 요약
- 이번 글에서 다루는 방법은 단안 영상에서 depth를 추정하기 위해 한 프레임과 다음 프레임 간의
disparity를 구하는 Unsupervised Learning (Self-Supervised) 방식의 딥 러닝 접근 방식입니다. monodepth2에서는 단일 프레임에서 depth를 예측하기 위해 depth 및 pose를 예측하는 네트워크의 조합을 사용합니다. 이 두 개의 네트워크를 훈련하기 위해 연속적인 프레임과 여러 손실 함수를 이용합니다.- 이 학습 방법은 학습을 위한 정답 (Ground Truth) 데이터셋이 필요하지 않습니다. 대신 이미지 시퀀스에서 연속적인 프레임 (t-1, t, t+1 프레임)을 사용하여 학습 하고 학습을 제한 (Constrain Learning)하기 위해 pose 추정 네트워크를 사용합니다.
- 모델은
입력 이미지와 pose 네트워크 및 depth 네트워크의 출력에서재구성된 이미지간의 disparity를 학습합니다. 재구성 과정은 이후에 다시 설명 드리겠습니다.
- 이와 같은 학습 구조에서
monodepth2에서 제안하는 주요 Contribution은 다음 3가지 입니다.
- ① 중요하지 않은 픽셀에서의 계산을 제거하는 auto-masking 방법
- ② Depth Map을 이용한 photometric reconstruction error를 구하는 변경된 방법
- ③ Multi-scale depth estimation
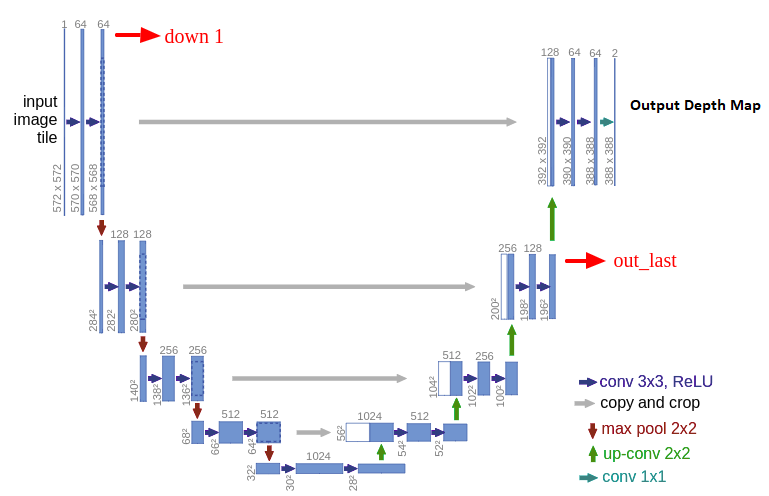
- 이 논문의 접근 방식은 depth 네트워크와 pose 네트워크를 사용합니다. depth 네트워크는 고전적인 U-Net
인코더-디코더아키텍처입니다. 인코더는 pre-trained된 ResNet 모델이고 depth 디코더는 시그모이드 출력을 depth로 변환하는 작업입니다.
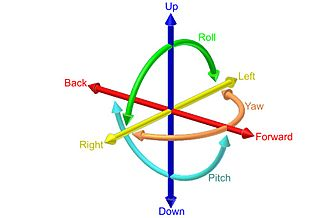
- 위 그림과 같은 6 DoF (Degree of Freedom)의 상대 pose 또는 rotation 및 translation을 예측하여 두 프레임 간의 카메라 pose 관계를 구하기 위하여 입력으로 두 개의 컬러 이미지를 받는 ResNet18의 pose 네트워크를 사용합니다. pose 네트워크는 일반적인 스테레오 이미지 쌍(pair)이 아닌 시간적으로 연속된 이미지 쌍(pair)을 사용합니다. 이것은 연속적인 다른 이미지(t-1, t 번째 프레임 이미지)의 관점에서 대상 이미지 (t번째 이미지)의 모양을 예측합니다.
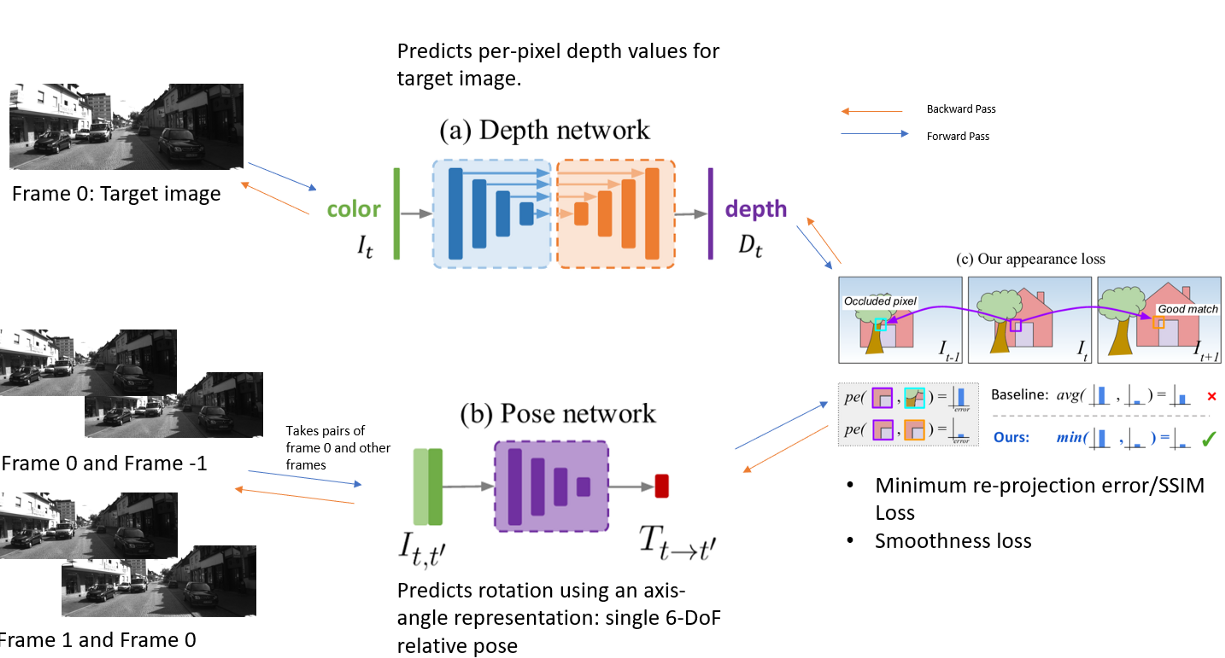
- 전체 학습 과정은 위 그림과 같습니다. Depth Network는 Depth를 추정하고 Pose Network는 6-DoF relative pose를 추정합니다. 최종적으로는 appearance loss에 사용되며 이와 관련된 내용을 차례대로 살펴보도록 하겠습니다.
Photometric Reconstruction Error
target 이미지( \(I_{t}\) ) 는 프레임 t에 있고 예측에 사용되는 이미지는 프레임 이전 또는 이후 프레임이 될 수 있으므로 \(I_{t+1}\) 또는 \(I_{t-1}\) 입니다. Loss는target 이미지와reconstruction된target 이미지(source → target reconstruction) 간의 유사도를 기반으로 계산됩니다.reconstruction프로세스는 pose 네트워크를 사용하여 source 프레임인 \(I_{t+1}\) 또는 \(I_{t-1}\) 에서 target 프레임인 \(I_{t}\) 로 변환하는 변환 행렬을 계산하는 것으로 시작됩니다. 이것은 rotation 및 translation에 대한 정보를 사용하여 source 프레임에서 target 프레임으로의 매핑을 계산한다는 것을 의미합니다.- 그런 다음
reconstructed target 이미지를 얻기 위하여target 이미지와 depth 네트워크에서 예측된 depth map과 pose 네트워크를 통해 얻은 변환 행렬을 사용합니다. - 이 프로세스에서는 depthmap을 먼저 3D 포인트 클라우드로 변환한 다음 카메라 intrinsic을 사용하여 3D 위치를 2D 포인트로 변환해야 합니다. 결과 포인트는 대상 이미지에서 bilinear interpolation을 하기 위한 grid sample 연산에 사용됩니다.
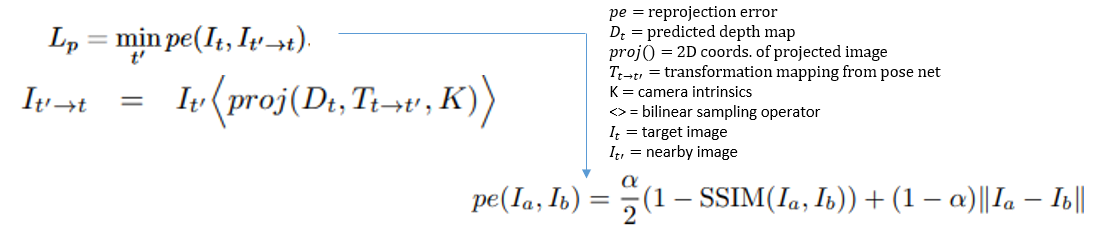
- 위 Loss의 목표는 target 이미지와 pose와 depth 정보를 이용하여 생성한 reconstructed target 이미지의 차이를 줄이는 것입니다.
- 여기 까지
monodepth2논문의 대략적인 방법론에 대하여 살펴보았습니다. self-supervised depth estimation과 관련된 내용을 처음 본다면 이해가 되지 않을 수 있습니다. 그러면 논문 내용을 차례대로 자세하게 살펴보도록 하겠습니다.
Abstract

- 픽셀 단위로 깊이 정보를 가진 정답 데이터를 얻는 것은 굉장히 어려우므로 이러한 한계를 극복하기 위하여
self-supervised방식 즉, 정답 데이터가 없는 unsupervised 방식의 학습 방식이 많이 연구가 되고 있습니다. - 이번 글에서 다루는 monodepth2는 self-supervised 방식의 깊이 추정 방식의 모델이며 정성 및 정량 모두에서 기존의 다른 모델에 비해 개선된 성능을 보였다는 점에서 의의가 있습니다.
- 기존의 self-supervised 기반의 깊이 추정을 위해서는 복잡한 모델 구조와 Loss 함수 그리고 disparity를 구하기 위한 이미지 생성 모델이 필요한데 monodepth2에서는 이러한 구조를 단순화 시킨 것에 의의가 있으며 성능 개선을 한 주요 내용은 크게 아래 3가지와 같습니다.
- ①
minimum reprojection loss: 기존의 average reprojection loss를 단순히 minimum으로 바꿈으로써 연속된 Frame 간 occlusion이 발생하더라도 강건해질 수 있도록 구조를 변경하였습니다. - ②
full-resolution multi-scale sampling method: depth estimation 결과에서 visual artifact와 같은 현상으로 depth 결과가 나타나는 데 이러한 문제를 개선하기 위하여 multi-scale에서 depth 정보를 추출할 수 있도록 하는 구조를 도입하였습니다. - ③
auto-masking loss: disparity를 구하기 위해 카메라 pose를 예측할 때, 전제 조건은 카메라는 프레임 간 이동이 발생하지만 그 이외의 물체는 정지되어 있어야 한다는 점입니다. 이러한 전제 조건의 위배되는 경우 중 하나가 카메라의 이동이 발생하지 않아서 물체가 완전히 정지되어 있는 경우입니다. 이와 같은 경우에는 diparity를 구할 수가 없기 때문에 Frame간 변화가 나타나지 않은 경우 필터링하여 학습하지 않도록 하는 방법을 도입하였습니다.
1. Introduction
- monodepth2에서는 Monocular video를 입력으로 사용한 경우와 stereo image pair를 입력으로 사용한 경우 2가지에 대한 실험이 있으나 Monocular video를 입력으로 사용한 경우에만 집중해서 이 글을 다룰 예정입니다.

- 일반적으로 깊이는 스테레오 카메라의 두 영상의
triangulation을 통하여 추정하게 되지만 본 글에서는 단일 컬러 이미지로 부터 깊이를 추정하는 것을 학습하고자 합니다. - 라이다 센서 없이 컬러 이미지로 부터 깊이를 추정할 수 있으면 사용처가 다양하며 특히 큰 볼륨의 라벨링이 없는 이미지 데이터셋으로 부터 깊이를 학습하는 것은 데이터 준비 측면에서 굉장히 효율적인 방법입니다.
- 따라서 현실적으로 대량의 데이터 셋을 구하기 어려운 깊이에 대한 정답 데이터를 구하는 대신에
self-supervised방식의 접근 방법이 연구되고 있고 그 방법은stereo pairs또는monocular video를 이용하는 방법이 있습니다.

stereo pair,monocular video2가지 방식 중에서monocular video방식은 단안 카메라 하나를 통해서 학습 데이터를 만들 수 있어서 데이터 준비 측면에서 더 쉬운 방식이며 센서를 구성하기도 쉽습니다. 하지만 Frame 간 자차 이동 발생 (ego motion) 정도를 알 수 있어야 학습 시 고려할 수 있습니다. 따라서pose estimation network를 통하여 ego motion을 예측해야 합니다.pose estimation은 연속적인 frame을 입력으로 받고 frame 간 이동된 카메라의 Rotation, Translation을 반영한 transformation matrix를 출력합니다.- monodepth2에서 사용하는 pose 네트워크는
Axis-angle rotation을 사용합니다. 따라서 네트워크의 입력은 연속적인 frame 2개를 받아서Axisangle과Translation을 출력합니다. 이 값을 통해 두 이미지의 카메라 간 Rotation과 Translation을 계산합니다. 일반적인 Euler rotation 방식을 사용하지 않고Axis-angle rotation을 사용하는 이유는 Eulear rotation에서 발생하는 짐벌락 문제로 성능에 영향을 끼치지 않기 위해서입니다. Learning Depth from Monocular Videos using Direct Methods에서도 이와 같은 이유로Axis-angle rotation을 사용하였습니다. 이와 관련 내용으로 저자의 의견을 아래 링크에서 볼 수 있습니다.- 링크 : https://github.com/nianticlabs/monodepth2/issues/85
Axis-angle rotation관련 내용은 아래 링크를 참조하시기 바랍니다.

- 앞에서 다룬 바와 같이 self-supervised 학습 방식을 잘 적용하기 위하여 크게 3가지 loss를 추가하여 사용 하였습니다.
novel appearance matching loss: monocular video에서 Frame 간 물체가 가려지는 문제를 다루기 위해 도입되었습니다.auto masking: frame간 움직임이 있어야 disparity를 구할 수 있는데 frame 간 움직임이 없는 경우 이를 필터링 하기 위한 masking 기법입니다.multi-scale appearance matching loss: 입력 이미지의 다양한 스케일 (1배, 1/2배, 1/4배, 1/8배)에서 각각 깊이를 추정하여 학습함으로써 다양한 해상도의 깊이를 학습함을 통해 visual artifact 문제를 개선할 수 있었습니다.- 이러한 기법을 모두 이용하여 self-supervised 방식의 모델 중에서 좋은 성과를 낼 수 있었습니다.

- 위에서 설명한 내용을 반영하여 학습 시, 위 깊이 추정 결과와 같이
monodepth2에서는 객체의 경계면에서 좀 더 선명하고 품질 좋은 depth map을 만들어 낼 수 있었습니다.
2. Related Work
- Depth Estimation을 학습하기 위하여 크게
Supervised Depth Estimation방법과Self Supervised Depth Estimation방법이 있으며 Self Supervised Depth Estimation에는 Self-supervsied Stereo Training 방식과 Self-Supervised Monocular Training 방식이 있습니다. - 이번 글에서 다루는 monodepth2의 주요 학습 방식은
Self-Supervised Monocular Training이며 이 학습을 위하여 Appearance Based Loss를 사용합니다.
- 먼저
Supervised Depth Estimation방법의 동향에 대하여 살펴보도록 하겠습니다.

- Depth Estimation을 하기 위하여 학습 기반의 방식이 다루어 지고 있습니다. 이러한 방법은 모델의 예측을 통하여 컬러 이미지와 그 컬러 이미지의 깊이 정보의 관계를 추정합니다.
- 깊이 정보를 추론하기 위하여 end-to-end 방식의 supervised learning 방식들이 연구가 진행되고 있습니다.

- supervised learning 방식은 효과는 좋으나 학습에 필요한 ground truth를 구하기 어렵다는 단점이 있습니다.
- 특히 실제 환경에서 이러한 gound truth를 구하는 것은 굉장히 도전적인 일이고 한계점도 많아서 학습 데이터가 weakly supervised로 구성됩니다. 예를 들어 이미지의 모든 픽셀에 대하여 대응되는 깊이 값을 ground truth로 구성하기는 어려운 문제가 있습니다. (따라서 깊이 정보가 듬성 등성 존재하는 sparse depth map을 사용합니다.)
- 현실에서 깊이 정보를 구하기 어려워 합성 데이터를 사용하는 대안이 있지만 실제 세상에서 나타나는 다양한 환경과 객체들의 움직임을 모두 구현하기는 어렵다는 한계점이 있습니다.
- 이러한 문제점들을 개선하기 위하여 structure-from-motion 방식과 sparse training data를 모두 이용하여 camera의 pose와 depth를 학습하는 방식을 이용하기도 합니다.
- 학습 데이터에 전적으로 의존하는 supervised learning 방식으로 깊이 추정 모델을 학습하는 경우 깊이 정보에 대한 GT를 정확하게 구성하기 어려운 한계가 있기 때문에 RGB 이미지에서 학습 정보를 추출하는
Self-supervised학습 방식에 대한 연구도 진행되고 있습니다.

- 만약 깊이 정보에 대한 GT가 없는 경우, 대안으로 학습할 수 있는 방식이
image reconstruction을 사용하여 학습의 정보로 사용하는 것입니다. - 이 때, image reconstruction을 하는 방법은 stero 이미지의 한 쌍이나 monocular sequence에서 한 이미지의 깊이 정보를 이용하여 다른 한 쌍의 이미지나 이전 또는 이후 Frame의 이미지를 예측하여 image reconstruction을 하는 것이고 이 reconstruction error가 작아질수록 disparity를 잘 구할 수 있도록 Loss를 설계하여 학습하도록 합니다.
- Self-supervised 방식의 학습은 데이터의 종류에 따라 학습 방법이 다릅니다. stero 데이터를 사용하거나 monoculdar sequence 데이터를 사용하는 것에 따라 달라집니다.
- 먼저
Self-supervised Stereo Training에 대하여 살펴보면 다음과 같습니다.

- stereo pair된 이미지를 이용하여 pixel의 disparity를 예측하도록 깊이 추정 네트워크를 학습하면 테스트 시 깊이 추정 네트워크가 단안 영상의 깊이 추정을 할 수 있도록 만들 수 있습니다.
- stereo 영상을 사용하는 학습 방법의 경향은 stereo 영상을 이용하여 disparity를 잘 구하도록 학습하고 실제 사용 시에는 단안 카메라로 disparity를 구해야 하므로 disparity를 구하기 위한 추가적인 영상을 복원하는 방법을 사용합니다. 예를 들어 단안 카메라가 스테레오 카메라의 왼쪽 카메라 라고 하면 딥러닝을 통하여 오른쪽 카메라 영상을 왼쪽 카메라 영상을 이용하여 복원하고 복원된 카메라 영상과 원본 카메라 영상을 이용하여 disparity를 구합니다.

- stereo가 아닌 단안 카메라 영상의 연속적인 frame을 사용하는 self-supervised 방식도 연구되고 있습니다.
- 이와 같은 데이터를 이용하기 위해서는 frame 간 카메라의 위치가 어떻게 변화하였는 지 알 수 있어야 합니다. 따라서 pose 네트워크라고 불리는 네트워크가 frame 간 카메라의 위치가 얼만큼 변화하였는 지 pose를 예측하고 깊이 추정을 하는 Depth 네트워크를 학습할 때, 이 정보를 사용합니다.
- 학습 이외의 과정에서는 깊이를 추정할 때에는 Pose 정보는 사용하지 않습니다. 이와 같은 컨셉이 본 논문에서도 사용됩니다.

- Self-supervised 방식 중 stereo 데이터 셋을 사용하는 것이 성능에는 효과적이었습니다. 하지만 Monocular Video 데이터셋을 구성하기가 효율적이기 때문에 Monocular Video를 이용한 학습 방법이 Stereo 데이터셋을 이용한 방법 수준으로 향상되도록 최적화 하는 방법이 연구되고 있습니다.

- Self-supervised 방식의 기본적인 학습 방법은 disparity를 구하는 것입니다. disparity를 구하기 위해서는 두 이미지 간의 동일한 객체를 나타내는 픽셀을 알아야 합니다.
- 즉, 두 이미지에서 같은 물체에 대한 픽셀 위치의 차이를 안다는 것은 그 차이 만큼 옮겼을 때, 두 이미지가 같아지는 부분이 생긴다는 것을 뜻합니다.
- 이렇게 같아지는 부분이 잘 생길 수 있도록 Loss를 설계하면 궁극적으로 두 이미지 간의
disparity를 잘 구할 수 있음을 의미하고 더 나아가 깊이를 잘 추정할 수 있게 됩니다. - 따라서 위 논문에서 언급한 바와 같이
appearance,material등에 대한 정보를 Frame 간 일치시킬 수 있도록 Loss를 설계하여 깊이 정보를 잘 추정하고자 하는 것이 학습 방법입니다.
3. Method

- 이번 절에서는 monodepth2에서는 깊이를 추정하는 네트워크가 컬러 이미지 \(I_{t}\) 를 입력 받아서 depth map \(D_{t}\) 를 출력하는 지 방법에 대하여 다루어 보도록 하겠습니다.
- 관련 내용으로는 뎁스 추정을 위한 네트워크와 Self-Supervised로 학습하기 위한 Loss가 이에 해당합니다.

- Self-Supervised 방식은 전통적으로 사용하는 Disparity를 구하는 방식을 딥러닝을 이용하는 방식입니다. Disparity를 구하기 위해서는 동일한 Scene에 대하여 2개의 View에 해당하는 이미지가 필요합니다.
- 따라서 monodepth2에서는 앞에서 설명한 바와 같이
monocular video를 이용하여 같은 Scene에 대하여 2개의 View를 구할 것입니다. 기준이 \(I_{t}\) 라고 하면 \(I_{t-1}\) 또는 \(I_{t+1}\) 를 이용하여 \(I_{t}\) Scene에 해당하는 영상을 네트워크 학습을 통하여 예측합니다. - 따라서 네트워크는 학습 파라미터를 이용하여 타겟 이미지인 \(I_{t}\) 시점의 Scene을 다른 시점의 이미지로 부터 생성하여 disparity 및 depth를 구하게 됩니다.

- 따라서 disparity를 구하여 Depth를 추정하기 위하여 \(I_{t-1}\), \(I_{t+1}\) 이미지를 \(I_{t}\) 의 Scene으로 가능한한 유사하게
reprojection을 합니다. - 즉, \(t-1 \to t\), \(t \to t+1\) 로 바뀜에 따라서 카메라의 위치도 바뀌게 되는데,
Pose Network라는 별도의 딥러닝 네트워크를 이용하여 서로 다른 시점의 (\(t\) 와 \(t-1\) 또는 \(t\) 와 \(t+1\)) 영상을 같은 시점( \(t\) ) 으로 카메라 위치를 맞추는 Rotation 및 Translation 행렬을 예측하는 방법을 사용합니다. - 따라서 Pose Network를 통해 구한 R,t 행렬을 이용하여 \(I_{t-1} \to I_{t}\) 로 변환하거나 \(I_{t+1} \to I_{t}\) 로 변환합니다. 이와 같은 작업을
reprojection이라고 합니다. - 위 식 (1)을 살펴보면 다음과 같습니다.
- \[L_{p} = \sum_{t'} \text{pe}(I_{t}, I_{t'\to t}) \tag{1}\]
- 여기서 \(L_{p}\) 는
photometric reprojection error라고 하며pe는photometric reconstruction error를 줄인말입니다.pe는 즉, 두 이미지가 얼만큼 다른 지 error를 구하는 것이고 \(t'\) 즉, \(t-1, t+1\) 2가지 경우에 대하여pe를 구하였을 때 error의 총합을 \(L_{p}\) 로 나타냅니다. monodepth2에서pe는 L1 Loss를 사용합니다.
- \[I_{t' \to t} = I_{t'}<\text{proj}(D_{t}, T_{t \to t'}, K)> \tag{2}\]
- 식 (2)는 이미지를 어떻게 \(t \to t'\) 로 시점을 변환하는 지 나타냅니다. 실제 코드를 살펴보면 다음과 같은 절차를 따릅니다.
- ① \(D_{t}\) 는 \(t\) 시점에서 \(I_{t}\) 를 입력으로 받은
Depth Network의 출력을 의미합니다. \(D_{t}\) 와intrinsic\(K\) 를 이용하여 깊이 추정 결과를 3D 포인트로 변환합니다. 즉, \(t\) 시점의 2D 이미지의 모든 픽셀을 3D 공간의 3D 포인트로 변환합니다. - ② \(I_{t}, I_{t'}\) 를 이용하여 Frame 간 카메라의
Rotation,Translation관계를 나타내는 \(T_{t \to t'}\) 를 예측합니다. 즉 \(t \to t'\) 로 카메라의 위치를 변환하는 변환 행렬을 구합니다. 이 변환 행렬의 카메라 좌표계의 변환 관계를 나타냅니다.- 논문의 코드를 살펴보면
Axis-Angle Rotation을 사용하여 카메라 좌표계의 회전 변환을 구한 것을 확인할 수 있습니다. 관련 내용은 아래 링크를 참조하시면 됩니다. Axis-Angle Rotation: https://gaussian37.github.io/vision-concept-axis_angle_rotation/
- 논문의 코드를 살펴보면
- ③ \(t\) 시점에서 구한 3D 포인트를 ②에서 구한 카메라 좌표계의 변환 행렬을 이용하여 \(t'\) 시점의 3D 포인트로 변환합니다. 실제 3D 포인트는 \(I_{t}\) 를 통해 \(t\) 시점에서 생성되었고 \(T_{t \to t'}\) 를 통해 \(I_{t'}\) 시점으로 옮겨간 것입니다. 바꿔 말하면 \(I_{t}\) 의 픽셀들에 해당하는 3D 포인트를 \(t'\) 시점의 공간으로 옮긴 것입니다.
- ④ 변환된 \(t'\) 시점의 3D 포인트 (X, Y, Z)를
intrinsic\(K\) 를 이용하여 2D 이미지 좌표인 \((u, v)\) 로 변환합니다. \((u, v)\) 2D 좌표가 의미하는 것은 \(t\) 시점의 \(I_{t}\) 의 각 픽셀 좌표를 \(t'\) 시점으로 옮겼을 때 해당하는 좌표에 해당합니다. 카메라의 원리에 맞게 3D를 거쳐서 왔으므로 논리적으로 잘 옮겨지게 됩니다. 이제 이 좌표에 RGB 컬러 값을 적용하여 실제 이미지 처럼 만들어야 합니다. 복원하고자 하는 시점이 \(t'\) 이므로 \(I_{t'}\) 의 RGB 값을 이용해야 합니다. 따라서 예측한 \((u, v)\) 이미지 좌표에 대응되거나 샘플링 할 수 있는 \(I_{t'}\) 의 이미지 좌표의 RGB 값을 가져오면 (이 때, grid_sample 연산을 사용합니다.) \((u, v)\) 를 RGB 이미지로 복원할 수 있습니다. 이 이미지를 \(I_{t' \to t}\) 라고 합니다. \(I_{t'}\) RGB 정보를 이용하여 \(I_{t}\) 를 복원하였기 때문에 이와 같이 명명하였습니다. - 정리하면 \(I_{t}\) 의 3D 정보를 \(I_{t'}\) 로 가져오고 \(I_{t}\) 의 3D 정보를 projection한 \((u, v)\) 좌표 위치로 \(I_{t'}\) 의 RGB 픽셀 정보를 가져와서 (grid_sample) 이미지를 형성하면 그 이미지가 \(I_{t' \to t}\) 가 됩니다. 이 때, 사용되는 연산은 grid_sample을 클릭하여 확인하시면 됩니다.
- 즉, \(I_{t' \to t}\) 의 픽셀의 좌표 정보는 \(I_{t}\) 를 이용하여 \(t'\) 시공간에 맞게 생성한 것이고 RGB 정보는 \(I_{t'}\) 를 이용한 것입니다. 따라서 \(I_{t' \to t}\) 로 표기됩니다.
- 이상적으로는 \(I_{t}\) 와 \(I_{t'\to t}\) 는 같은 대상 및 배경에 대한 이미지 ( \(I_{t' \to t}\) 는 \(I_{t'}\) 에 공간 정보를 반영하여 \(I_{t}\) 를 복원한 것) 이므로
reprojection loss를 통하여 \(I_{t}\) 와 \(I_{t'\to t}\) 가 유사해지도록 학습하거나 유사성을 구하는 데 활용할 수 있습니다. - 이 때, 영상의 복원이 잘된다는 의미는 ①의
Depth Network의 출력인Disparity (Depth)가 의미있게 출력되었다는 뜻이고 ②의 \(T_{t \to t'}\) 또한 의미있게 출력되어 시공간의 정확한 이동이 반영되었다는 것을 뜻합니다. - 이와 같은 방식으로 \(I_{t' \to t}\) 를 추정하는 것은 카메라의 위치만 변경되고 나머지 환경은 변하지 않았다는 가정을 두기 때문 성립할 수 있습니다.
- 하지만 이와 같은 이상적인 가정을 제외하고 현실적으로 이 가정은 성립하기가 어려운 점이 많습니다. 이 가정을 위배하는 몇 가지 문제는 그대로 성능적인 한계와 연결이 됩니다. 이러한 요소들을 글 뒷부분에서 다루어 보도록 하겠습니다.
- 다시 논문의 내용을 살펴보겠습니다.논문의 식 (2)를 통해 구한 \(I_{t' \to t}\) 와 \(I_{t}\) 를 논문의 식 (1)을 통해
Loss를 구하여 학습하면 두 값이 유사해지도록 학습됩니다.
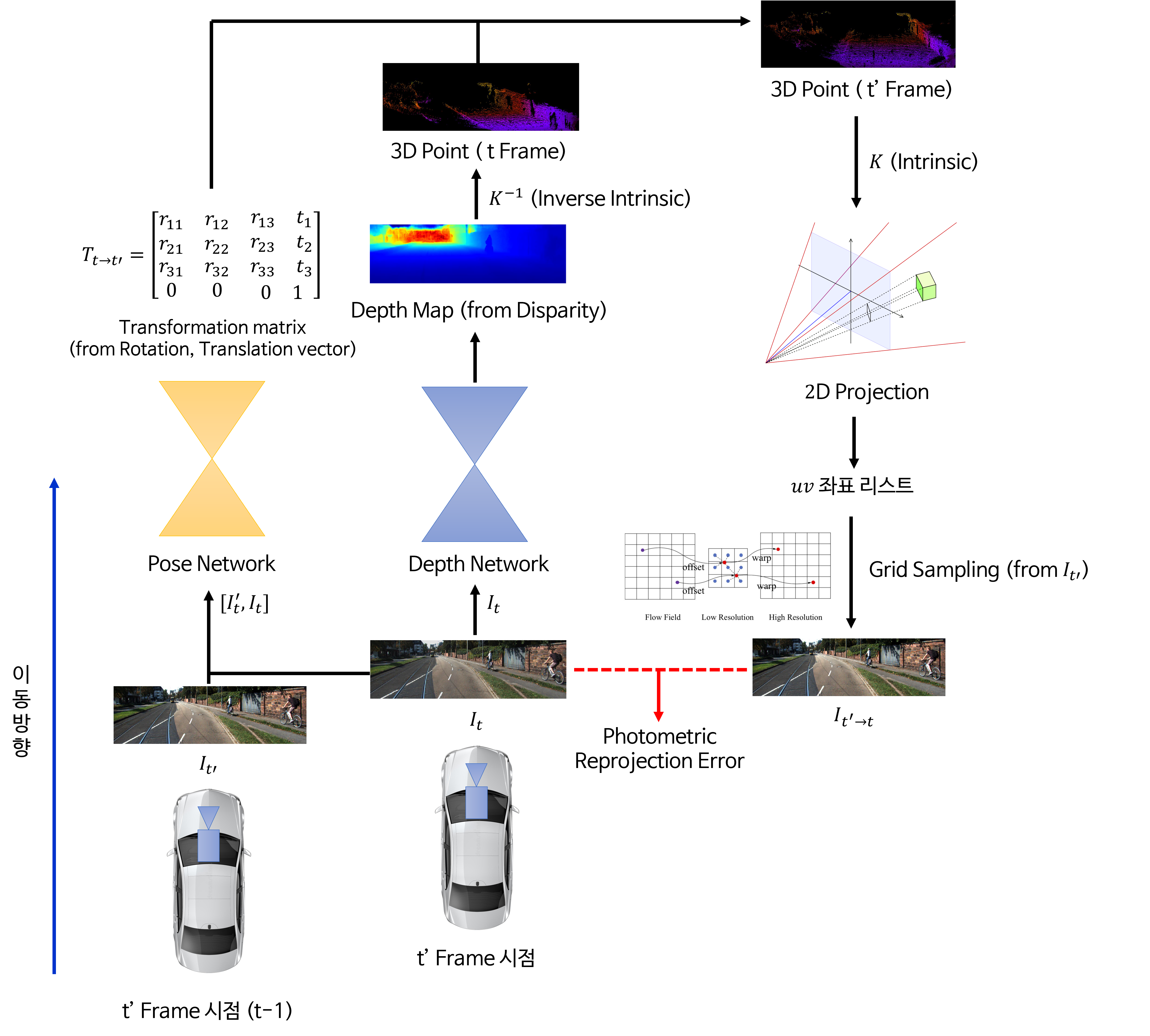
photometric reprojection error을 구하기 위한 전체 과정을 도식화 하면 위 그림과 같습니다. \(t'\) 가 \(t-1, t+1\) 2가지 경우가 있으므로 \(I_{t}\) 에 대하여 \(I_{t-1}, I_{t+1}\) 각각에 대하여 1번씩 총 2번의 경우에 대하여 에러를 계산하여 학습합니다.- 이 때, \(I_{t-1 \to t}\) 를 생성하기 위한
grid sampling연산 시 sampling 방법은bilinear방식으로 없는 픽셀에 대하여 interpolation 하여 생성하며 이와 같은 grid sampling 방식은 미분 가능하기 때문에 학습에 사용될 수 있습니다. - 식 (1)의 \(L_{p}\) 를 구하기 위하여 미분 가능한 이미지를 비교하는 대표적인 방식인
SSIM (Structural Similarity Index)과L1Loss를 같이 사용하였고 상대적으로SSIM에 좀 더 높은 가중치를 부여하였습니다.SSIM의 상세 내용은 아래 링크를 참조하시기 바랍니다.SSIM (Structural Similarity Index): https://gaussian37.github.io/vision-concept-ssim/
SSIM을 사용하면 좀 더 정교하게 이미지를 복원할 수 있다고 알려져 있으며 정성적인 내용은 아래 링크를 참조해 보시기 바랍니다. SSIM Loss 효과 참조

- 식 (3)에서는
edge-aware smoothenessLoss를 추가적으로 도입합니다.edge-aware smootheness는 monodepth1에서도 사용이 되었으며 사용 목적은 객체의 경계면에서 급격한 깊이 값의 변화를 방지하기 위함입니다. - 이와 같은 아이디어는 실제 세상에서는 객체의 경계가 급격하게 변하는 경우가 흔하지 않으며 어느 정도 연속적으로 점점 변화하기 때문입니다. 하지만 이미지에서는 경계가 급격하게 변하는 경우가 발생하기 때문에 현실 세계를 반영하여
edge-aware smoothness즉,edge부분을smooth하게 만드는Loss를 추가합니다. 이Loss는 일종의regularization term과 같이 기존 Loss에 추가됩니다. edge를 확인하기 위해서는depth(disparity)및rgb값을 이용하여 인접한 픽셀과의 변화량 (derivative)을 이용합니다.rgb 이미지 변화( \(\partial_{x}I_{t}, \partial_{y}I_{t}\) )가 크면 위 식의 \(e^{-\vert \partial_{x}I_{t}\vert}\) 와 \(e^{-\vert \partial_{y}I_{t}\vert}\) 가 작아지므로disparity 변화도 작아집니다. 물론disparity 변화가 작아지면depth의 변화도 작아집니다. 여기서 중요한 것은 disparity나 depth의 값이 아니라 인접 픽셀 간의 disparity나 depth의변화량을 의미합니다.- 반면 \(e^{-\vert \partial_{x}I_{t}\vert}\) 와 \(e^{-\vert \partial_{y}I_{t}\vert}\) 식을 통해 확인할 수 있듯이
rgb 이미지 변화량이 작아지더라도 \(\vert \vert\) 절대값으로 인하여 \(e^{-\vert \partial_{x}I_{t}\vert}\) 와 \(e^{-\vert \partial_{y}I_{t}\vert}\) 각각은 최대 1의 값을 가지게 되므로 오히려 disparity(depth)의 변화가 커지는 경우는 발생하지 않습니다. 따라서smoothness loss에서는rgb 이미지 변화가 큰 경우에 대해서disparity(depth) 변화가 작아진다는 점이 핵심입니다. - 이와 같은
Loss를 추가함으로써 깊이 추정에서의 문제점 중 하나인 물체의 경계면에서의 깊이 추정이 급격하게 변화하여 부정확해지는 문제를 개선합니다. 뿐만 아니라 같은 객체 내에서 색상의 차이가 크게 나타나는 영역에 대해서도disparity(depth) 변화를 작아지게 할 수 있습니다. 예를 들면 차량의 내부에 색상의 변화가 있지만 비슷한disparity(depth)를 가지는 경우가 있습니다. 단순히 색만 다른 경우가 있거나 빛 반사등으로 색 변화가 발생할 수 있기 때문입니다. 이와 같은 경우에smoothness loss는disparity(depth) 변화를 줄여주도록 하기 때문에 안정적인disparity(depth)을 얻을 수 있습니다. - 하지만
oversmooth가 되면 실제 물체의 상세한 정보가 사라지기 때문에 적정 수준에서smoothness loss의 가중치를 조정하여 사용할 수 있습니다. - 식 (3)에서는 \(d^{*}_{t} = d_{t} / \bar{d_{t}}\) 와 같은
normalization형태를 사용함으로써 학습이 잘 되도록 하였습니다. \(\bar{d_{t}}\) 는 \(d_{t}\) 의 전체 평균을 나타냅니다. \(d_{t}\) 의 shape은 (B, C=1, H, W)이므로 \(\bar{d_{t}}\) 는 (B, 1, 1, 1) 형태의 크기가 되도록 H, W의 차원 전체에서 평균을 구합니다. - 최종적으로 \(d^{*}_{t}\) 와 이미지 간 smoothness loss는 아래 코드와 같이 구하게 됩니다.
def get_smooth_loss(disp, img):
"""Computes the smoothness loss for a disparity image
The color image is used for edge-aware smoothness
"""
# disparity의 x 방향 변화량 확인
grad_disp_x = torch.abs(disp[:, :, :, :-1] - disp[:, :, :, 1:])
# disparity의 y 방향 변화량 확인
grad_disp_y = torch.abs(disp[:, :, :-1, :] - disp[:, :, 1:, :])
# image의 x 방향 변화량 확인
grad_img_x = torch.mean(torch.abs(img[:, :, :, :-1] - img[:, :, :, 1:]), 1, keepdim=True)
# image의 y 방향 변화량 확인
grad_img_y = torch.mean(torch.abs(img[:, :, :-1, :] - img[:, :, 1:, :]), 1, keepdim=True)
# 이미지의 변화가 클 때, exp 값이 작아지므로 disparity의 변화가 작아지도록 유도함
# 반면 이미지의 변화가 작아질 때, exp 값이 최대 1의 값만 가지므로 disparity의 변화가 커지지는 않음
grad_disp_x *= torch.exp(-grad_img_x)
grad_disp_y *= torch.exp(-grad_img_y)
return grad_disp_x.mean() + grad_disp_y.mean()

- 만약 monocular sequence를 이용하지 않고 stereo pair를 이용한다면 \(t'\) 가 서로 다른 시점이 아닌 같은 시점에서의 다른 카메라의 영상이 됩니다. 그 이외의 학습 방식은 Monocular Sequence를 이용하는 방식과 동일합니다.

- 지금까지 설명한 Loss를 통하여 Self-Supervised 방식의 학습을 할 수 있으나 supervised 학습 방식과의 차이를 줄이기 위하여 추가적인 3가지 기법을 더 적용하였습니다. 그 내용은 각각
Per-Pixel Minimum Reprojection Loss,Auto-Masking Stationary Pixels,Multi-scale Estimation입니다.
Per-Pixel Minimum Reprojection Loss
- 먼저
Per-Pixel Minimum Reprojection Loss의 내용은 간단하면서 효과적입니다.
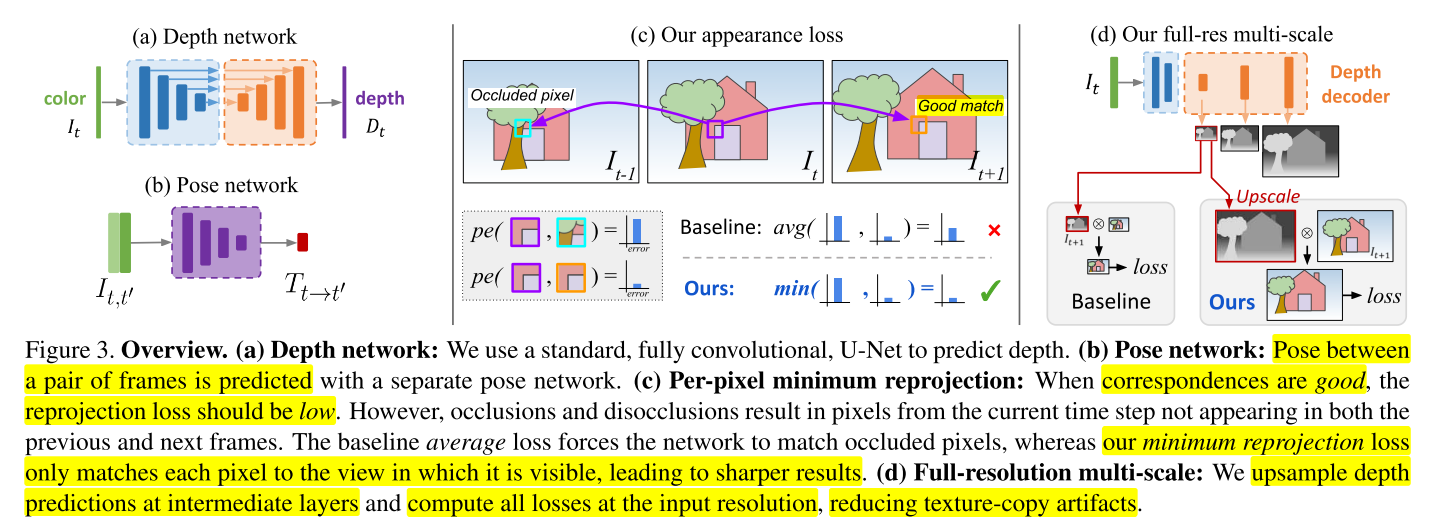
- 위 figure에서 (c)의 appearance loss를 살펴보면 \(I_{t}\) 와 \(I_{t-1}, I_{t+1}\) 의 관계에서 \(I_{t}\) 에는 보이는 영역이 \(I_{t-1}\) 에서는 보이지 않고 \(I_{t+1}\) 에서는 그대로 보이는 예시를 볼 수 있습니다. 일반적으로 이와 같은 경우 average를 사용하여 Loss를 구할수도 있지만 좀 더 좋은 성능을 위하여
minimum연산을 사용하였습니다. - 이와 같이
minimum연산을 적용하면 \(I_{t-1}, I_{t+1}\) 중 가능한한 \(I_{t}\) 와 이미지가 일치하는 이미지를 선택하여 연산을 할 수 있으므로 학습의 가정과 부합하지 않는 이미지를 배제할 수 있어서 더 좋은 결과를 얻을 수 있습니다. 평균을 적용하는 경우 깊이 추정 결과에서 blur가 생기는 정성적인 분석 결과도 있습니다. - 이와 같이 disparity를 구할 때, 가정에 어긋나는 2가지 주요 상황이 ① 이미지 경계 부근에서 view가 벗어나서 보이지 않게 되거나 ② 카메라가 이동하여 가려진 픽셀이 발생한 경우 입니다.
- ①과 같이 view가 벗어나는 문제에 대해서는 reprojection loss를 구할 시 sampling 연산을 통하여 view가 벗어나는 영역에 대해서 적절히 masking이 되어 문제를 개선할 수 있지만 occlusion이 발생한 문제에 대해서는 처리하기가 어렵습니다.
- 따라서 다음 식과 같이 \(t'\) 즉, \(t-1, t+1\) 중 reprojection error가 낮은 이미지만 Loss에 반영합니다.
- \[L_{p} = \min_{t'} \text{pe}(I_{t}, I_{t' \to t}) \tag{4}\]
- 이렇게 min error만 사용할 경우 다음과 같은 경우 도움이 됩니다.

- 위 그림과 같이 \(L\) 이 \(I_{t}\) 가 되어 기준이 되었을 때, 빨간색 동그라미의 차 옆의 벽돌 부분은 \(R\) 또는 \(+l\) 이미지에선 보이지 않지만 \(-l\) 이미지에서는 보입니다. 즉, disparity를 구할 수 있는 픽셀이 된다는 뜻입니다.
- 따라서 이와 같이 disparity를 구할 수 있는 영역이 많을수록 학습에 도움이 되므로
Per-Pixel Minimum Reprojection Loss를 사용하게 됩니다. - 이와 같은 방법을 통해 정성적으로 분석 시 이미지 경계 부분의 visual artifact 를 줄일 수 있고 occlusion boundary를 좀 더 정교하게 만들 수 있으며 정량적으로도 성능이 향상된 것을 확인할 수 있습니다.
Auto-Masking Stationary Pixels

- self-supervised으로 monocular sequence를 학습할 때, 2가지 전제조건이 있습니다. 카메라는 움직이되 주변 환경은 움직이지 않는 다는 것입니다. 만약 이 가정이 깨지게 되면 학습 시 문제가 발생합니다.
- 예를 들어 카메라의 위치가 움직이지 않는 경우 disparity를 구할 수 없어 학습에 적합하지 않는 데이터가 됩니다. 또한 객체의 움직임이 발생할 경우 같은 환경에 대한 disparity를 구할 수 없어 학습에 적합하지 않는 데이터가 됩니다. 즉, disparity를 구하지 못하는 환경의 데이터는 학습에 사용하기가 어렵습니다.
- 이러한 데이터로 학습하게 될 경우
hole이 발생하게 되고 이 hole에서는 무한한 깊이를 가지는 잘못된 출력을 만들어 내는 경향이 있습니다.

- 이러한 경향은 monocular sequence를 이용하여 학습하는 위 그림의 Monodepth2 이외의 모델에서 확인이 됩니다.
- 반면 monodepth2에서는 정성적인 결과에서 이러한 문제를 개선한 것을 확인할 수 있습니다. 개선 방법은
Auto-Masking Stationary Pixels입니다. 이 방법은 연속된 Frame에서 픽셀값에 변화가 없는 부분을 제거하는 방법입니다. 픽셀값에 변화가 없으면 Disparity를 구할 수 없기 때문에 제거합니다. - 이와 같은 방식으로 픽셀을 제거하면 네트워크는 카메라와 같은 속도로 움직이는 물체를 무시하게 되고 심지어 카메라가 움직이지 않을 때에는 Frame 전체를 무시하기도 합니다.

- 이와 같은 필터링을 하기 위하여 아래와 식 (5)을 사용하였습니다. 식 (5)를 통하여 \(\min_{t'} \text{pe}(I_{t}, I_{t' \to t})\) 와 \(\min_{t'} \text{pe}(I_{t}, I_{t'})\) 를 각각 구하고 후자가 큰 픽셀은 1 그렇지 않은 픽셀은 0으로 저장한 다음에 실제 Loss를 계산할 때, 픽셀이 1인 영역만 학습에 반영하는 마스크를 생성합니다.
- 식 (5)에서 \(\min_{t'} \text{pe}(I_{t}, I_{t' \to t})\) 는 앞에서 다루었던 minimum reprojection error입니다. 반면 \(\min_{t'} \text{pe}(I_{t}, I_{t'})\) 는 \(I_{t}\) 와 \(I_{t'}\) 를 대상으로 minimum reprojection error를 계산합니다. 즉, 어떤 픽셀에 대하여 \(I_{t-1}, I_{t+1}\) 중에서 \(I_{t}\) 와 유사한 픽셀과의 reprojection error를 구하고 이 error가 \(I_{t}, I_{t' \to t}\) 를 통해 얻은 reprojection error 보다 큰 경우에만 학습을 진행합니다.
- 이 연산의 의미는 \(I_{t}, I_{t'}\) RGB 이미지에서 영상 간의 차이가 충분히 있어야 학습하는 데 의미가 있다고 판단하는 것입니다. 이 연산을 통하여 카메라의 이동 속도와 같아서 움직임이 없어 보이는 물체 또는 카메라가 움직이지 않아서 변화가 없는 픽셀을 제외할 수 있습니다.

- Figure 5를 살펴보면 1행의 예시가 카메라의 이동 속도와 비슷한 속도로 이동한 물체를 필터링한 경우이고 그 결과 자동차의 대부분의 픽셀이 학습에서 제외된 것을 확인할 수 있습니다.
- 2행을 보면 대부분의 픽셀이 학습에서 제외된 것을 확인할 수 있는데 이 경우는 자차가 정차되어 있는 상황으로 판단됩니다.
Multi-scale Estimation

- 성능 개선을 위하여 Multi scale Estimation을 적용하였습니다. Multi scale Estimation은 간단하게 low resolution의 출력을 upsample 하여 high resolution으로 만들고 이렇게 만든 high resolution 결과를 이용하여 reprojection loss를 구하는 방식을 말합니다.
- 이와 같이 다양한 scale (low/mid/high resolution)의 출력으로 부터 high resolution으로 복원을 하여 학습을 하면 같은 각 해상도에서의 깊이 정보에 대한 학습을 다양하게 할 수 있으며 변화량이 작은 영역인 low-texture region에서 주로 발생하는
hole또는artifact문제에 대하여 다양한 scale의 깊이 정보를 통해 개선할 수 있습니다.

- 지금까지 다룬
Loss에 대한 내용은 크게 \(L_{p}\) 즉,minimum reprojection loss와 \(L_{s}\) 즉,edge awareness smooth loss입니다. - 위 식의 \(\mu\) 는
auto masking을 의미하므로 \(\mu L_{p}\) 는masked photometric loss가 됩니다. - 위 식의 \(\lambda\) 는 smoothness의 가중치를 의미합니다.
- 따라서 최종 Loss인 \(L\) 을 multi-scale에 대하여 모두 적용하면 monodepth2의 최종 Loss 형태가 됩니다.

- Depth Network의 Encoder와 Decoder 그리고 Pose Network에 대한 상세 내용을 Additional Consideration에서 확인할 수 있습니다.
- Depth Network의 Encoder는 ResNet을 사용하였으며 ResNet18과 같은 다소 가벼운 네트워크도 사용하여 구현하였습니다.

- Depth Network의 Decoder의 마지막 출력에 sigmoid를 적용하였고 이 출력 결과를 Depth로 변환합니다. 이 때, \(D = 1 / (a \sigma + b)\) 의 식을 사용하며 \(a, b\)는 Depth의 결과를 0.1 ~ 100 사이의 값으로 제한하기 위해 사용됩니다.
- Depth Decoder에서는 reflection padding을 사용하여 경계 부근에서의 artifact와 관련된 성능을 개선할 수 있었습니다.

- 카메라의 위치를 추정하는 Pose Network는
axis-angle로 표현법을 사용하여 6 DoF의 파라미터를 추정하여 Transformation Matrix를 구성합니다. Pose Network의 입력은 연속된 2개의 Frame을 채널 방향으로 붙여서 입력받습니다.
4. Experiments

- Experiments에서는 앞에서 설명한 내용에 대하여 어떤 성능 평가를 가질 수 있었는 지 확인합니다.
reprojection loss관점에서는 occluded pixel이 존재 시 단순히 average를 사용하는 것 보다 minimum 값을 사용하였을 때 성능이 좋다는 것을 보여줍니다.auto-masking관점에서는 statoc camera 즉, 카메라의 위치가 움직이지 않는 경우에 대하여 auto-masking이 효과적임을 보여줍니다.multi-scale관점에서는 multi-scale을 이용하여 학습 시, 정확도가 향상됨을 보여줍니다.
… 작성중 …
5. Conclusion

- 지금 까지 내용으로 논문의 전체적인 내용은 마무리가 되었습니다. 저자는 monodepth2에서의 contribution을 3가지로 요약하였으며 앞에서 언급한 최적화 기법인
minimum reprojection loss,auto-masking loss,full-resolution multi-scale sampling방식을 언급하였습니다. minimum reprojection loss와auto-masking loss를 통하여 Monocular Video를 학습 데이터로 사용하였을 때,disparity를 구하기에 적합하지 않는 전제 조건을 개선하였습니다.minimum reprojection loss는 서로 다른 위치로 인하여 disparity를 구하기 어려운 이미지 쌍을 가능한 배제하고자 하는 기법이고auto-masking loss는 disparity를 구하기 위해서는 동일 물체에 대해서 픽셀 간의 위치 차이가 발생해야하는데 카메라가 움직이지 않아 픽셀 간의 위치 차이가 발생하지 않아 disparity를 구하기 어려운 픽셀을 배제하고자 하는 기법입니다.full-resolution multi-scale sampling방법을 통하여 다양한 해상도의 정보를 이용하여 학습하는 것이 성능 향상에 효과적임을 확인할 수 있습니다.- 무엇보다
monodepth2의 학습 프레임워크를 이용하면 Monocular Video 데이터 뿐만 아니라 Stereo 데이터에도 적용할 수 있으며 더 나아가 Monocular Video와 Stereo 데이터를 동시에 적용하는 것도 가능하다는 것에 장점이 있습니다.
6. Supplementary Material
… 작성중 …
Monodepth2의 한계 상황
Pytorch Code
- 원본 깃헙 링크 : https://github.com/nianticlabs/monodepth2
- 위 링크는 monodepth2 저자가 제공하는 학습 코드이며 상당히 자세하게 잘 작성되어 있습니다.
- Ablation study와 다양한 기능을 On/Off 할 수 있도록 작성되어 있어 구체적으로 어떤 기능을 사용할 지 선택할 수 있으나 처음 볼때에는 다소 복잡해 보일 수 있습니다.
- 따라서 아래 링크에서 중점적으로 사용해야 하는 기능인
Monoculdar Video Data를 사용하고,Minimum reprojection loss,Auto-masking을 사용하며 스테레오 관련 데이터는 모두 제외하도록 간소화 하였습니다. - 코드를 확인하시고 문의 사항이 있으시면 댓글 달아주시면 감사하겠습니다.
- 간소화된 깃헙 링크 : https://github.com/gaussian37/monodepth2_simple
monodepth2의 코드는trainer.py에 해당하는 코드 내용을 이해하면 전반적으로 이해할 수 있습니다. 위 깃헙 링크 코드 중간소화된 깃헙 링크는 몇가지 조건을 정하여 코드를 설명하며 불필요한 부분과 ablation study 부분은 제거하고 주석을 추가하였습니다.- 몇가지 조건은 스테레오가 아닌 단안 (mono) 카메라를 통해 얻은 비디오 영상을 이용하고 연속하는 3개의 프레임 ( \(I_{t-1}, I_{t}, I_{t+1}\) ) 을 이용하는 옵션만 적용하였으며 Pose Network는 별도 모델을 사용하는 것으로 적용하였습니다. 즉, 논문의 최고 성능을 발휘할 수 있는 코드만 남기고 나머지 코드는 제거하였습니다.