센터넷, CenterNet (Objects as Points)
2020, Nov 25
- 참조 : Objects as Points (https://arxiv.org/abs/1904.07850)
- 참조 : https://youtu.be/mDdpwe2xsT4
- 참조 : https://medium.com/visionwizard/centernet-objects-as-points-a-comprehensive-guide-2ed9993c48bc
- 참조 : https://nuggy875.tistory.com/34
- 참조 : https://seongkyun.github.io/papers/2019/10/28/centernet/
- 참조 : https://github.com/gakkiri/simple-centernet-pytorch/tree/master/model
- 참조 : https://www.kaggle.com/kyoshioka47/centernet-starterkit-pytorch
- 참조 : https://github.com/JavisPeng/CenterNet-pytorch-detection-simple-tutorial
목차
-
CenterNet, Objects as Points 소개
-
CenterNet Architecture
-
Abstract
-
Introduction
-
Related work
-
Preliminary
-
Objects as Points
-
Implementation details
-
Experiments
-
Conclusion
-
Pytorch Code
CenterNet, Objects as Points 소개
- 이번 글에서는 Objects as Points라는 논문의 내용을 다루어 보겠습니다. 이 논문에서 제시하는 object detection 모델의 이름은
CenterNet으로 실시간으로 Object Detection을 할 수 있는 모델 중 좋은 성능을 가집니다. - 또한 Anchor Box를 사용자가 정의하지 않아도 되는 (Anchor free) 장점이 있어서 많은 어플리케이션에 사용되는 추세입니다.
- Anchor free 방식의 Object Detection 방식에는 여러가지가 있습니다. 그 중 CenterNet은 KeyPoint 기반의 접근 방법을 사용합니다.
- KeyPoint 기반의 접근 방법은 사전에 정의된 key point들을 예측하고 이를 이용하여 Object 주위에 Bounding Box를 생성합니다. 대표적인 예제로 CornetNet, CenterNet(Objects as Points, KeyPoint Triplets), Grid-RCNN 등이 있습니다.

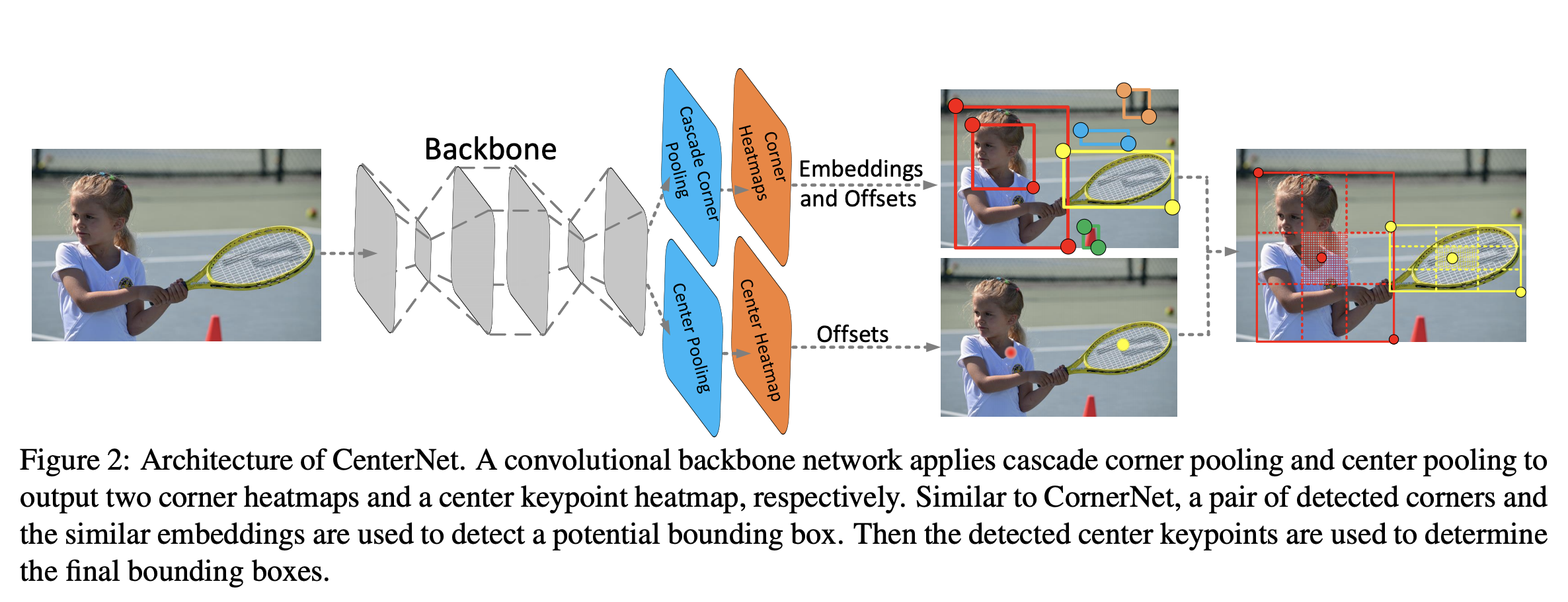
- CenterNet은 object detection을 위하여 위 그림과 같이 Keypoint를 사용합니다. 위 그림에서 보행자를 찾은 Keypoint는 박스의 Center point입니다.
- 이 논문에서는 박스의 중앙점을 object로 판단하고 이 중앙점을 이용하여 bounding box의 좌표를 예측합니다.
- 따라서 object의 중앙점을 예측하는 것이 이 네트워크의 가장 기본적이면서 중요한 예측 문제라고 할 수 있습니다.
- CenterNet에서는 네트워크를 통하여 입력으로 받은 이미지를 연산 하면 최종 출력되는 feature에서는 서로 다른 key point들에 대하여
heatmap을 가지게 됩니다. 이 heatmap의 최고점(peak)이 object의 중앙점으로 예측되는 구조입니다. - 각각의 중앙점은 bounding box를 위해 고유한 width와 height를 가집니다. 따라서
중앙점 + width + height로 그려지는 bounding box로 인하여 다른 네트워크 구조에서 사용된NMS(Non-Maximal Suppresion)이 사용되지 않는 장점이 있습니다. (단 하나의 Anchor를 사용한다고 보면 됩니다.) - 각 중앙점이 어떤 클래스에 해당하는 지 파악할 때에도 앞에서 언급한 heatmap의 peak를 사용하게 됩니다.
- 따라서 이 중앙점과 그 정보들을 사용함으로써 박스의 위치 및 크기와 그 박스가 나타내는 클래스의 정보를 알 수 있습니다.
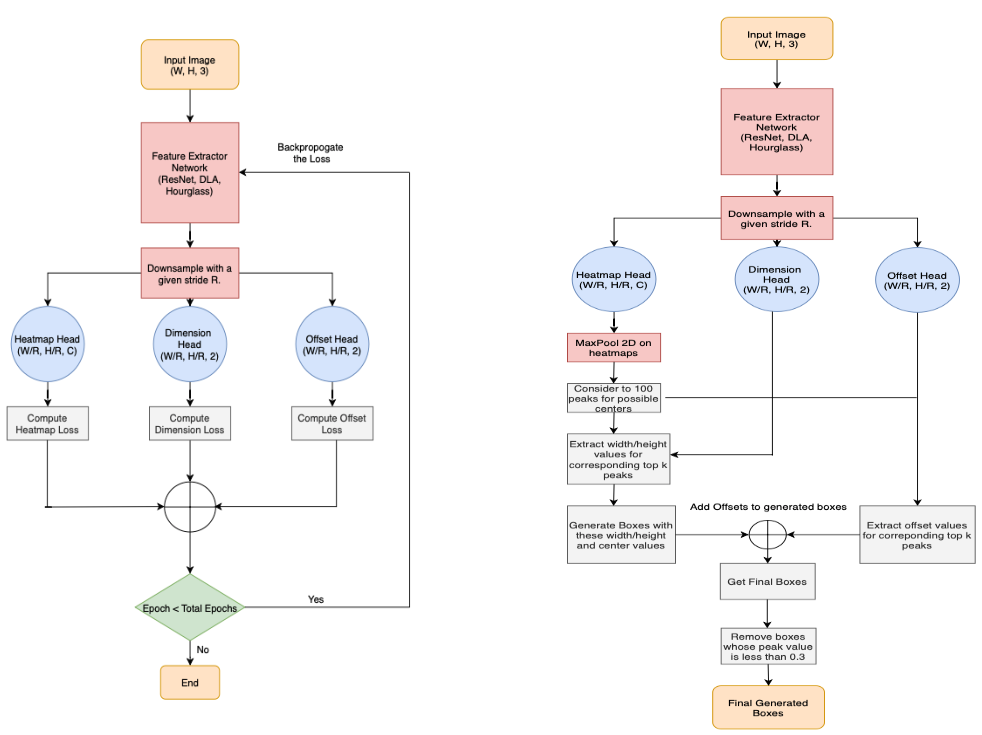
CenterNet Architecture
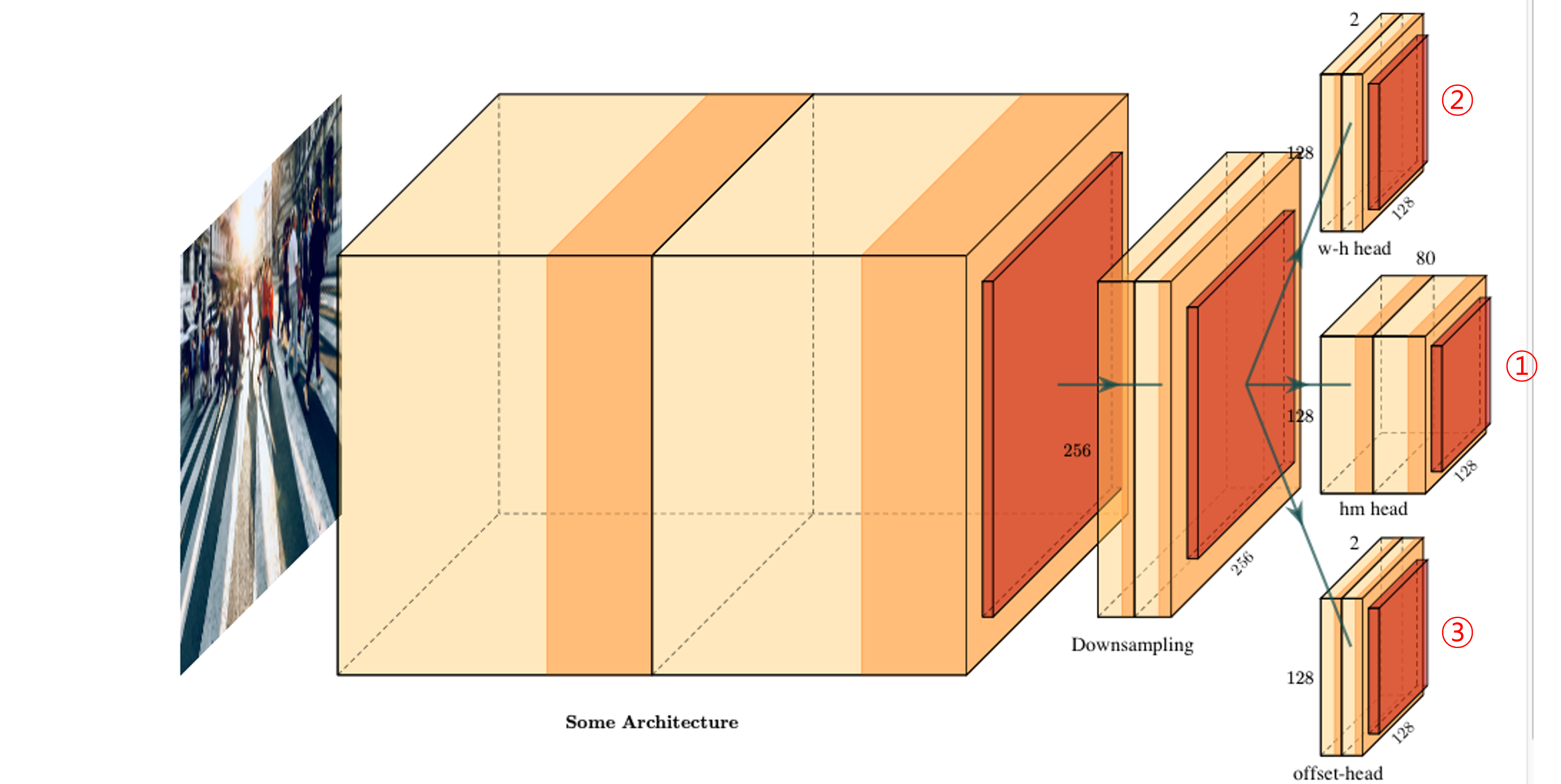
- CenterNet의 아키텍쳐를 단순화 시켜서 보면 위 그림과 같습니다. 출력 부분을 보면 3개의 모듈로 나뉘어 지는 것을 확인할 수 있습니다.
- 각 모듈은
dimension(w-h) head,heatmap head,Offset head가 있습니다. - 입력 이미지
I의 height가H, width가W, 채널은C = 3이라고 하겠습니다.R은 output stride로 3가지 head의 dimension에 영향을 줍니다. 모든 head는 같은 크기의 height, width 사이즈 (H/R,W/R)를 가집니다. 위 아키텍쳐 예제에서R = 4로 각 head는 (512/4=128, 512/4=128)의 크기를 가집니다. - 반면 채널
C는 서로 다른 값을 가집니다. 위 그림의 아키텍쳐에서w-h 또는 dimension head는2개의 채널을 가지고heatmap head는80개의 채널 을 가지고 마지막으로Offset head는2개의 채널을 가짐을 알 수 있습니다. heatmap head가 가지는 80개의 채널은클래스의 수에 해당합니다. 여기서 80이라는 클래스의 수는 COCO 데이터 셋 클래스 기준입니다. - 그러면 각 head가 가지는 의미에 대하여 알아보도록 하겠습니다.
① heatmap head
heatmap head는 주어진 입력 이미지의 key point들을 추정하는 데 사용됩니다. 여기서 key point는 object detection의 박스의 중심점을 나타냅니다.heatmap head의 목적은 heatmap인 \(\hat{Y}\) 을 예측하는 것이며 이 값은 (W/R,H/R,C)의 dimension을 가집니다. 이 때, output stride는R, 클래스의 수는C를 가집니다. (COCO 데이터셋을 기준으로 클래스는 80입니다.)- 여기서 \(\hat{Y}\) 은 \(x, y, c\) 의 function 형태로 나타낼 수 있습니다. 만약 \(\hat{Y}(x, y, c) = 1\) 이라면 어떤 클래스 \(c\) 의 center point를 감지한 것으로 나타낼 수 있습니다. 반면 \(\hat{Y}(x, y, c) = 0\) 이라면 배경(background)라고 나타낼 수 있습니다.
- \[Y_{xyc} = \text{exp}\biggl( -\frac{ (x - \tilde{p}_{x})^{2} + (y - \tilde{p}_{y})^{2} }{2\sigma^{2}_{p}} \biggr)\]
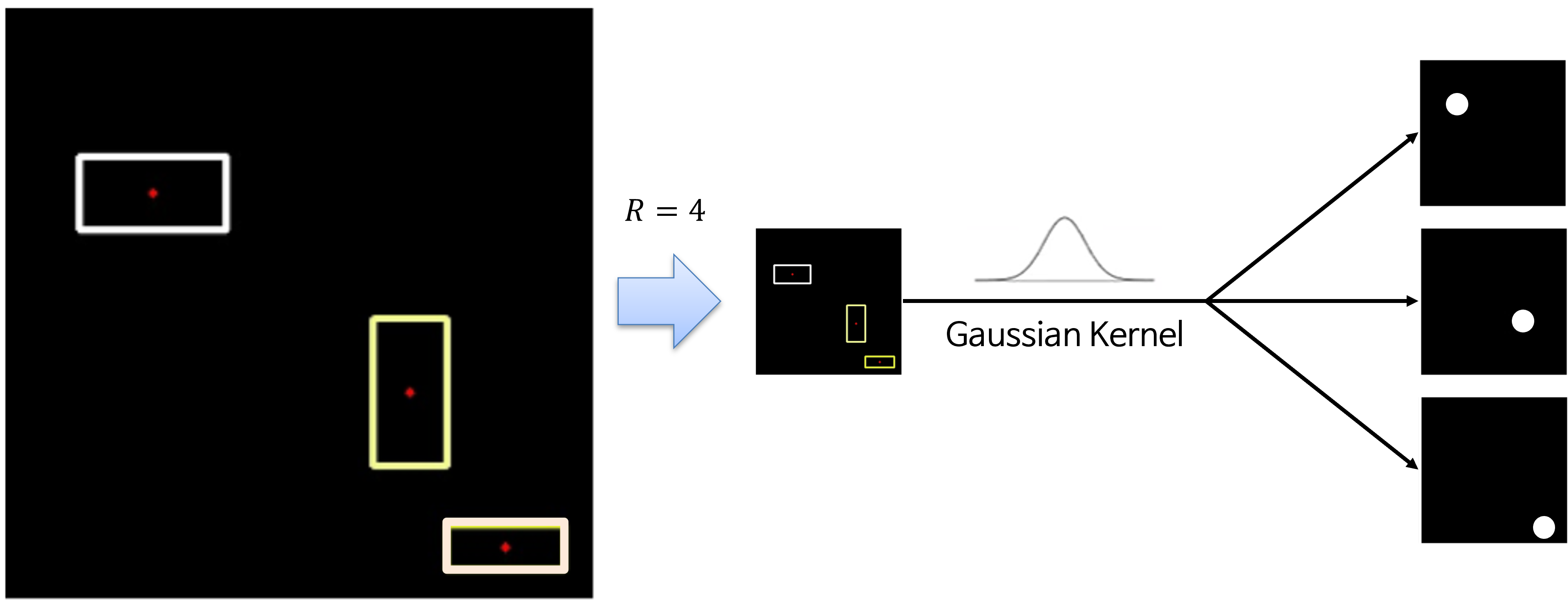
- heamap head에서 loss를 구하기 위해
ground truth에 대한 전처리가 필요하여 그 과정은 위 flow와 같습니다. - 먼저 stride를 거친 저해상도 영상을 바로 사용하지 않고
2D Gaussian Kernel을 이용하여blur를 적용합니다. - 가장 왼쪽의 기존의 해상도 영상에서 빨간색 점을 저해상도로 변환 후 바로 사용하면 GT에 해당하는 점, 단 하나만 1의 값을 가지고 주변은 0의 값을 가지게 됩니다. 이 경우 prediction한 결과와 ground truth에 해당하는 좌표가 상당히 가까이 (극단적으로 바로 옆에) 있어도 prediction을 잘 했다고 Loss를 반영하기가 어려워집니다.
- 따라서 Gaussian Kernel을 이용하여 blur를 적용한 ground truth를 사용하면 prediction에 대한 허용 오차가 생기게 되어 Loss 반영이 좀 더 쉬워집니다.
- 위
커널식의 사용된 \(\sigma\) 는 객체의 크기에 adaptive하게 표준 편차가 적용됩니다.
- 구체적인 예를 들어 설명해 보겠습니다. \(C = 3\) 이고 입력 이미지의 dimension이 (400 X 400), stride \(R = 4\) 라고 가정해 보겠습니다. 이 경우 \(C = 3\) 이기 때문에 3개의 heatmap이 생성되어야 하며 각각의 heatmap은 주어진 클래스에 대응되어야 합니다. \(R = 4\) 이기 때문에 heatmap의 결과물은 100 X 100이 됩니다.
- \[Y_{xyc} \longleftrightarrow \hat{Y}_{xyc} \in [0, 1]^{\frac{H}{R} \times \frac{W}{R} \times C }\]
- 따라서 최종적으로 Loss를 계산하기 위하여 \(Y_{xyc}\)와 \(\hat{Y}\) 간의 비교를 통하여 Loss를 계산할 수 있습니다.
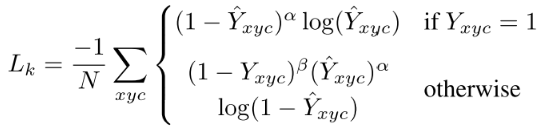
- ※ Focal Loss에 대한 상세 내용 : https://gaussian37.github.io/dl-concept-focal_loss/
heatmap head에서 사용하는 loss는Focal Loss를 사용합니다. Focal Loss의 내용을 간단하게 살펴보면 \(Y_{xyc} = 1\) 이면 즉, 예측한 좌표가 center point가 맞다면, 예측한 좌표가 얼만큼 오차가 있는 지 구합니다. 반면에 \(Y_{xyc} \ne 1\) 이면 즉, 예측한 좌표가 center point가 아니면, 0인 영역에서 얼만큼 떨어져 있는 지를 통하여 Loss를 구합니다.- 이와 같이 Focal Loss를 사용하는 이유는 Detection이 쉬운 Object의 경우 Loss 값을 낮추고 Detection이 어려운 Object의 경우 Loss 값을 높여서 잘 검출이 안되는 Object에 집중을 하여 학습을 하겠다는 방법입니다. (Focal Loss의 상세 내용은 위 링크를 참조하시기 바랍니다.)
② dimension head
dimension head는 bounding box의width와height를 나타내기 위해 사용됩니다.- 예를 들어 \(c\) 클래스에 해당하는 \(k\) object의 bounding box의 좌표가 \((x^{1}, y^{1}, x^{2}, y^{2})\) 라고 가정하면 object의 크기 \(s_K = (x^{2} - x^{1}, y^{2} - y^{1})\) 로 추정할 수 있습니다.
- 이 값을 구하기 위하여
dimension head는L1 distance norm을 Loss로 사용합니다. - 이 head의 dimension은 (
H/R,W/R,2)의 크기를 가지고 channel 방향으로 가지는 2개의 값은 center point를 기준으로width,height크기에 해당하는 값을 가집니다.
③ offset head
offset head는 input의 downsampling으로 부터 발생한 오차를 정정하기 위하여 사용됩니다.- center point를 예측한 후에, 이 예측한 center point를 입력 이미지의 해상도에 맞추어 매핑을 해야합니다. downsampling 된 해상도에서의 center point를 입력 이미지 해상도에 맞게 복원할 때,
정수값의 좌표로 복원해야 하므로 floating point → integer 값으로 좌표를 복원할 때 값을 정정해 주기 위하여offset head\(\hat{O}\) 를 사용합니다. - offset head의 dimension은 (
H/R,W/R,2)를 가지며 channel 방향으로 가지는 2개의 값은x,y방향으로의 좌표 offset 값을 나타냅니다.
Pytorch Code
- 참조 : https://github.com/gakkiri/simple-centernet-pytorch