FlowNet (Learning Optical Flow with Convolutional Networks) 알아보기
2019, Dec 26
- 논문 : https://arxiv.org/abs/1504.06852
- 참조 : https://github.com/ClementPinard/FlowNetPytorch
- 참조 : https://medium.com/swlh/what-is-optical-flow-and-why-does-it-matter-in-deep-learning-b3278bb205b5
- 참조 : https://towardsdatascience.com/a-brief-review-of-flownet-dca6bd574de0
- 참조 : https://lmb.informatik.uni-freiburg.de/resources/datasets/FlyingChairs.en.html#flyingchairs
목차
-
Contribution
-
Abstract
-
1. Introduction
-
2. Related Work
-
3. Network Architectures
-
4. Training Data
-
5. Experiments
-
6. Concolusion
-
Code Review
Contribution

- 이번 글에서는 딥러닝을 이용한 옵티컬 플로우를 추정하는 논문인
FlowNet을 알아보도록 하겠습니다. 옵티컬 플로우는 위 그림과 같이 픽셀 단위의 움직임(Motion)을 나타내는 Vector Map (Pixel Displacement)를 의미 합니다.
- 위 영상을 통해
FlowNet의 데모 영상을 확인할 수 있습니다. FlowNet의 목적에 맞게 옵티컬 플로우를 잘 추정하는 것을 볼 수 있습니다. - 위 영상의 색이 의미하는 바를 먼저 살펴보면 첫번째 그림과 같이 모든 픽셀에 대하여 모션 벡터를 화살표 형태로 표현하기에는 시인성이 좋지 않으므로 모션 벡터의 정보를
HSV컬러 정보를 이용하여 표현한 것입니다.
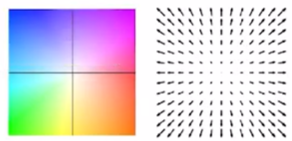
H (Hue): 색상 정보를 나타내며 모션 벡터의 방향을 의미합니다. 예를 들어 파란색에 가까울수록 픽셀의 움직임이 왼쪽 위 방향 (↖)으로 해석할 수 있고 빨간색에 가까울수록 픽셀의 움직임이 오른쪽 아래 방향 (↘)인 것으로 해석할 수 있습니다.S (Saturation): 채도 정보를 나타내며 모션 벡터의 크기 즉, 얼마나 많이 움직였는 지 나타냅니다. 흰색에 가까울수록 움직임이 거의 없다고 해석할 수 있고 색이 진할수록 움직임이 크다고 해석할 수 있습니다.V (Value): 명도 정도를 나타내며 여기서는 사용되지 않습니다.
- 다음으로 FlowNet의 논문을 읽으면서 느낀
contribution에 대하여 먼저 정리해 보겠습니다. - ① Optical Flow를 위한 최초의 딥러닝 모델의 의미가 있다고 생각합니다. 초기 모델인 만큼 아이디어와 네트워크 아키텍쳐도 간단합니다.
- ② 현실적으로 만들기 어려운 학습 데이터를 저자가 직접 합성 데이터를 만들어서 학습을 진행한 점입니다. 이 학습 데이터는 이후에 다른 옵티컬 플로우 논문에서도 학습을 위해 사용됩니다.
- ③ 합성 영상을 이용하여 학습을 하여도 현실 영상에 적용이 가능한 수준임을 확인한 것입니다.
- 정리하면
FlowNet은 옵티컬 플로우 문제를 딥러닝을 이용하여 해결해 보려는 시도였고 학습을 하기 위해 합성 영상 데이터셋을 만들어서 학습을 하였는데 이 결과가 현실 영상에서도 적용 가능했다는 점입니다. - 옵티컬 플로우는 보통 옵티컬 플로우 자체가 목적이라기 보다는 픽셀 별
모션 벡터를 이용하여 어플리케이션에 적용하기 위해 사용됩니다. 즉,FlowNet을 통하여 딥러닝 방식으로 옵티컬 플로우를 추정하게 되면End-To-End방식의 어플리케이션을 적용할 수 있다는 의의도 있습니다. - 현재 시점으로는
FlowNet을 발전시킨FlowNet 2.0이 많이 사용되고 있습니다. 개선된 버전의 핵심 내용은 FlowNet을 따르므로 이 글을 잘 이해하고 그 다음 FlowNet 2.0 글을 읽으시길 추천드립니다.
Abstract

- FlowNet은 옵티컬 플로우 추정을 supervised learning 방식으로 학습을 하는 알고리즘을 뜻합니다.
- 네트워크의 아키텍쳐에 따라서
generic architecture에 해당하는FlowNetS모델이 있고 반면에 서로다른 이미지의 featue vector의 correlation을 이용하는 방법인FlowNetC이 있습니다. - 앞에서 언급하였듯이 학습을 하기에 충분한 데이터가 없으므로
Flying Chairs라는 인공적으로 만든 합성 데이터를 이용하여 학습을 진행하였습니다.
1. Introduction

- 이 논문에서는 CNN의 End-To-End 방식의 학습 방법을 이용하여 이미지 쌍에서의 옵티컬 플로우를 추정합니다.
- 옵티컬 플로우 추정인
픽셀 단위의 localization문제라고 말할 수 있습니다. 이것을 하기 위하여 두 이미지 사이의 픽셀 단위의 관계를 찾는 것이 필요합니다.

- CNN 아키텍쳐를 End-To-End 형식으로 학습하기 위하여
correlation layer라는 것을 도입하여 쌍으로 주어진 이미지의 픽셀 정보를 매칭하는 데 이용하였습니다.
- 위 그림과 같이 인풋으로 2개의 이미지와 라벨링 값으로 픽셀 단위의 모션 벡터가 주어지면 End-To-End로 CNN이 학습을 하는 구조입니다.

- 옵티컬 플로우를 학습할 수 있는 픽셀 단위의 모션 벡터 정보를 가진 데이터의 수가 매우 적으므로 학습을 위해서 Flying Chairs 데이터 셋이라는 것을 만들었습니다.
- 이 데이터는 현실 세계의 데이터 형태와 다르지만 쉽게 데이터를 만들어 낼 수 있다는 장점이 있습니다.
2. Related Work

- 옵티컬 플로우를 추정하는 기존의 방식은 Luckas-Kanade, Horn-Schunck 와 같은 알고리즘이 있습니다. 이러한 알고리즘은 학습을 이용하지 않고 파라미터를 매뉴얼 하게 정합니다.
- 하지만 FlowNet과 같은 딥러닝 방식을 이용하여 손수 파라미터를 정할 필요는 없어집니다.

- 이전에도 머신러닝 방법과 unsupervised 학습 방식을 통하여 옵티컬 플로우를 추정하려는 연구는 진행되어 왔습니다.

- CNN 방식이 계속 발전해 오고 있지만 FlowNet 이전까지 옵티컬 플로우 추정을 CNN을 이용한 방법은 없었으나 FlowNet에서는 직접적으로 옵티컬 플로우 필드를 계산하여 예측합니다.

- CNN을 이용한 어플리케이션 중
픽셀 단위의 작업들이 있습니다. 예를 들어 semantic segmentation이나 depth estimation이 있습니다. 옵티컬 플로우 추정 또한 이와 같은 픽셀 단위의 작업입니다. - 이와 같은 픽셀 단위의 작업을 위한 CNN 아키텍쳐들이 많이 연구되어 왔습니다. 대표적으로 추출된 feature들을 upsampling 하여 원하는 해상도로 만든 다음에 합치는 방식입니다. 이 때 upsampling 하는 해상도는 예측해야 하는 픽셀과 대응하며 일반적으로 입력 영상과 같은 해상도로 복원한 후 입력 영상의 픽셀과 대응되도록 원하는 값을 추정합니다.

- 픽셀 단위로 출력된 정보를 다시 정제 (refine) 하는 연구도 진행되어 왔습니다. 예를 들어 coarse 한 depth map 출력을 좀 더 정제하기 위하여 추가적인 학습을 하는 방식도 연구되어 왔고
upconvolutional layer(transposed convolutional layer)를 이용하여 contractive 한 네트워크 부분(즉, Encoder를 통해 feature를 추출한 부분)을 원하는 해상도로 복원한 다음 정제하는 방법의 연구도 진행되었습니다.
3. Network Architectures

- FlowNet 아키텍처의 목적은 옵티컬 플로우의 End-To-End 학습을 위함입니다.
- 계산 복잡도를 고려한 현실적인 학습을 위하여 Pooling layer는 필수적이며 Pooling layer를 통하여 넓은 영역의 정보를 합칠 수 있습니다. 하지만 Pooling layer를 거치면 해상도가 줄어들게 되므로 픽셀 단위의 출력을 하기 위해서는 앞에서 설명하였듯이 다시 고해상도로 원복하는 작업이 필요합니다.
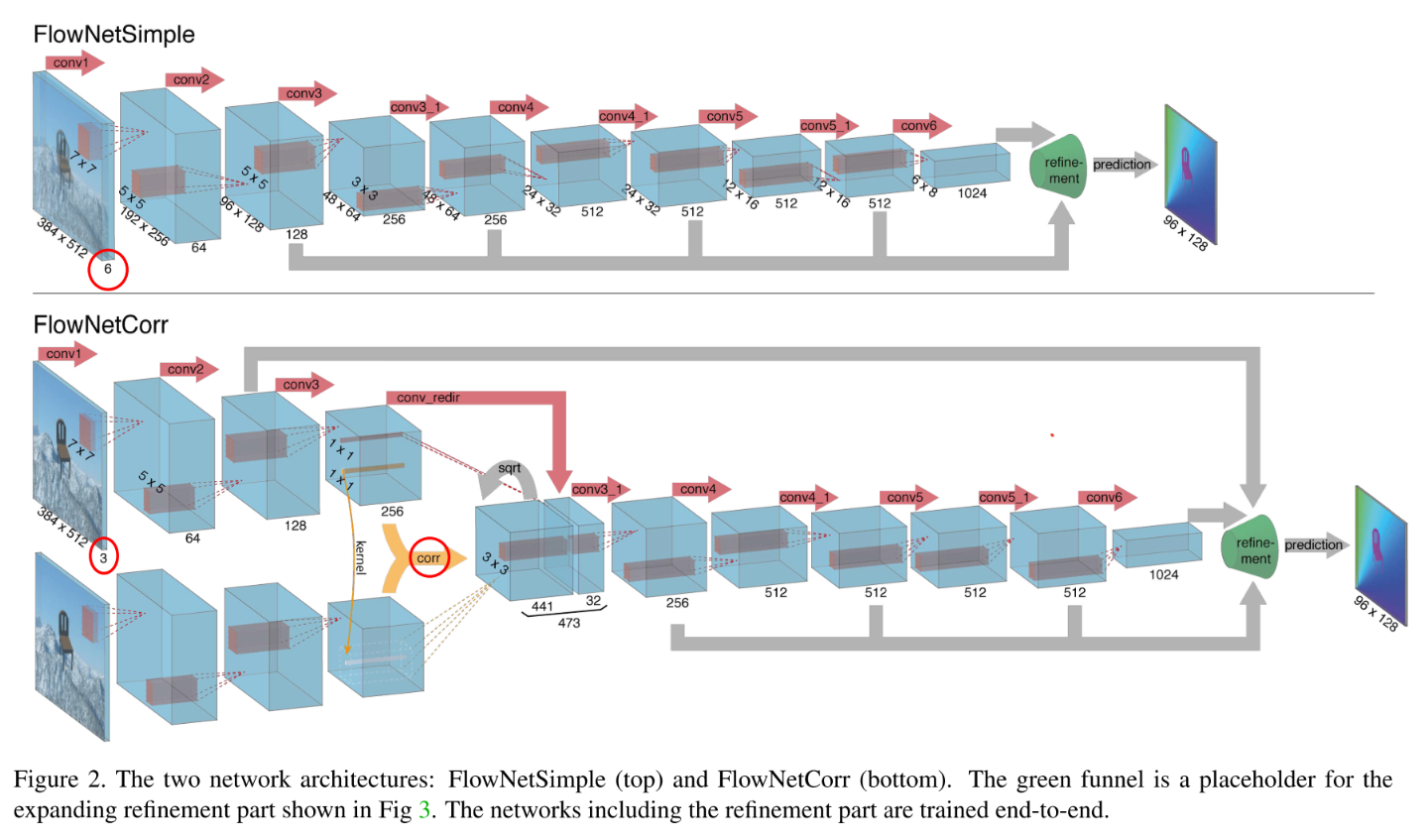
- 따라서 위 그림과 같은 아키텍처를 통해 이 작업을 수행하며 논문에서는
FlowNetSimple과FlowNetCorr2가지 아키텍쳐를 제안합니다.

- 위 2가지 아키텍쳐를 살펴보면 Figure 1은 좀 더 간단한 형태로
FlowNetSimple이라는 구조입니다.채널 수를 보면6인 것을 통해 알 수 있듯이, 2장의 이미지를 concat한 다음에 네트워크의 입력으로 넣어줍니다. 이를 통하여 네트워크가 어떻게 이미지 쌍의 모션 정보를 추출할 지 스스로 결정할 수 있도록 학습시킵니다. - 반면에 Figure 2는 조금 더 복잡한 형태로
FlowNetCorr이라는 구조입니다. 이 구조는 입력단이 2개로 분리되어 있고 각 입력은 이미지를 받습니다. 채널이 3임을 통하여 컬러 이미지 각각을 입력 받는 것임을 알 수 있습니다. 2개 입력단의 구조는 완전히 동일하며 이후 layer에서correlation연산을 통하여 하나로 합쳐집니다. 각 입력단의 네트워크를 통하여 의미있는 representation feature를 추출한 다음에 하나로 합쳐지도록 학습 시키는 구조입니다.

- Figure 2에 해당하는
correlation 연산에 좀 더 자세하게 알아보도록 하겠습니다. 이 작업은 두 이미지에서 추출한 feature \(f_{1}, f_{2}\) 의 매칭을 잘 하기 위한 연산입니다.

correlation 연산을 위한 수식은 식 (1) \(c(x_{1}, x_{2})\) 와 같습니다.