DeepLabv3+, Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation
2019, Nov 05
- 이번 글에서는 딥러닝 segmentation 모델 중에서 좋은 성능을 보이는 모델 중 하나인 deeplab 시리즈 중에서 2019년도 기준으로 가장 최신인
deeplab v3+를 다루어 보도록 하겠습니다. - 그 전에 deeplab 시리즈가 어떻게 발전해왔는지 제목을 통하여 한번 알아보도록 하겠습니다.
- DeepLab v1 : Semantic Image Segmentation with Deep Convolutional Nets and Fully Connected CRFs
- Fully Connected CRFs를 적용하였습니다.
- DeepLab v2 : Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs
- Atrous Convolution 개념을 적용하였습니다.
- DeepLab v3 : Rethinking Atrous Convolution for Semantic Image Segmentation
- DeepLab v3+ : Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation
- 이번 글에서 다룰 내용의 키워드 2가지는 Encoder-Decoder 구조와 Atrous Separable Convolution입니다.
DeepLab v3+를 이해하기 위해서는DeepLab v3를 이해하고 오시기를 추천드립니다.
목차
-
Atrous Convolution
-
Spatial Pyramid Pooling
-
DeepLab V3+
-
Xception backbone
-
Decoder effect
-
Pytorch 코드 리뷰
Atrous Convolution
- 먼저 DeepLab v3+에서 사용되는 convolution 연산 중에
Atrous convolution에 대하여 알아보도록 하겠습니다.
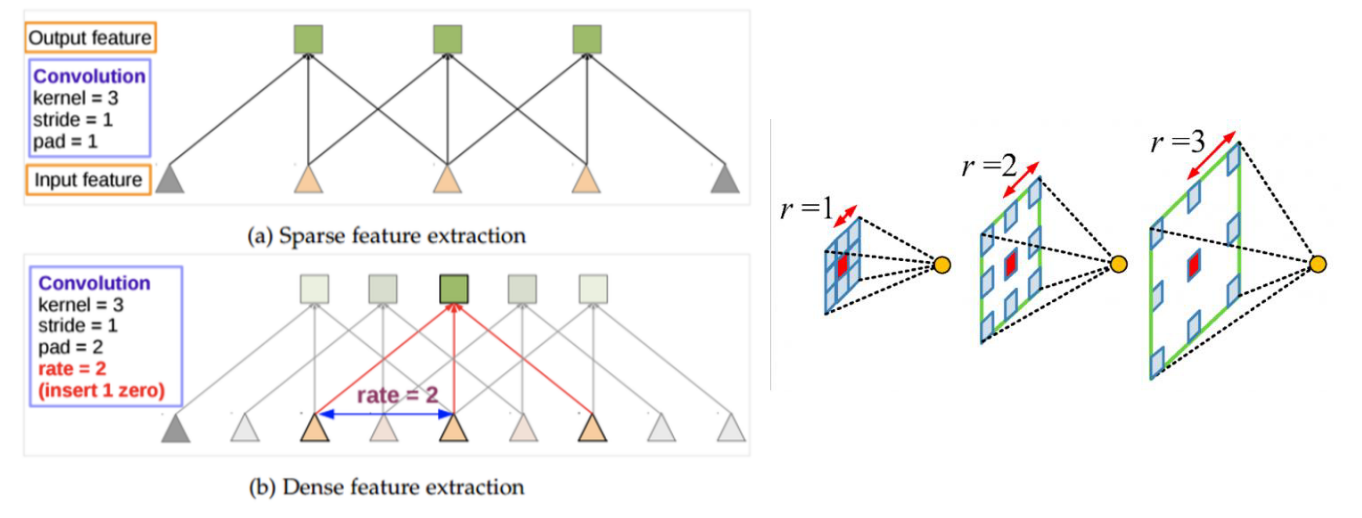
- atrous convolution은 위 그림과 같이 convolution 연산 시 receptive field 사이에
hole을 추가하여 receptive field를 확장하는 구조를 가집니다. - 이 때
hole의 크기 또는 필터의 픽셀 간의 거리를rater로 나타냅니다. r = 1인 경우가 일반적인 convolution으로 필터의 픽셀 거리가 1인 경우이고(즉, 모두 붙어있음) r = 2인 경우가 픽셀 거리가 2로 한칸 씩 떨어진 경우 잉ㅂ니다. - 정리하면 단순히
r=1일 때가 기본적인 convolution 연산인 반면에r=2이상일 때에는 convolution 연산 시 feature 사이에 간격이 벌어진 채로 convolution 연산을 하게 됩니다. - 이렇게 filter 사이에 간격을 주는 이유는
넓은 영역을 보기 위함입니다.
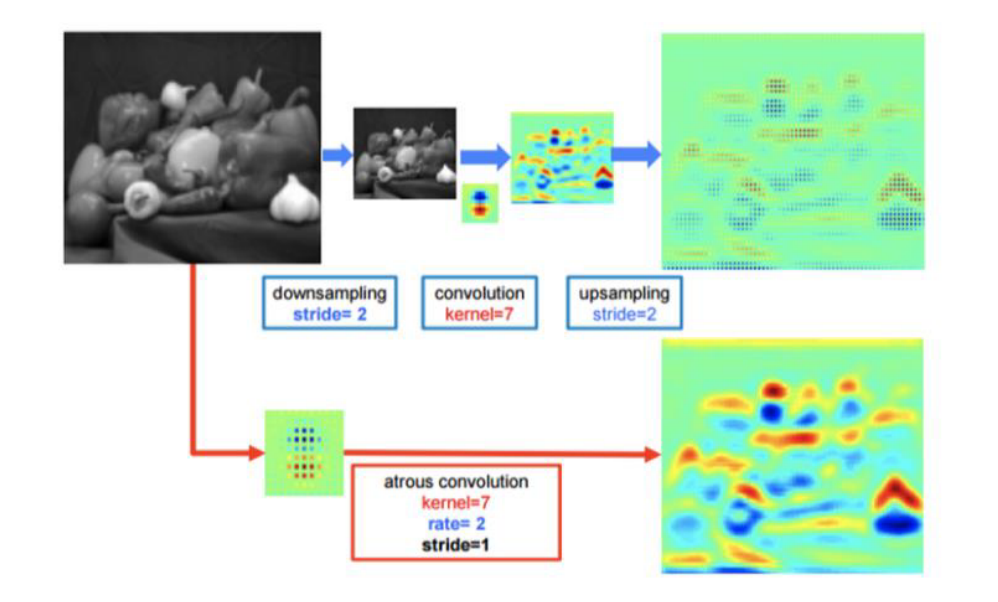
- 이렇게 atrous convolution을 사용하게 되면 위 그림과 같이 downsampling - convolution - upsampling 과정을 거치는 것보다 더 좋은 성능을 가지는 것을 논문에서 보여줍니다.
Spatial Pyramid Pooling
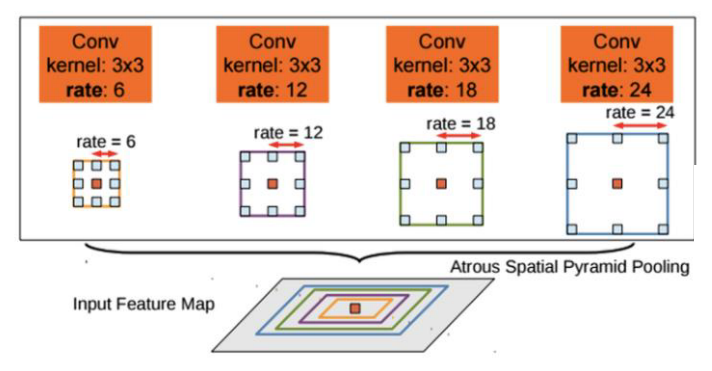
- 그런데 atrous convolution을 사용할 때, 고정된
rate를 사용하게 되면 필터의 크기가 고정이 되어버리고 다양한 feature 중에서 한정된 feature 밖에 찾지 못하는 문제를 가지게 됩니다. - 따라서 이 문제를 개선하기 위하여 위 그림과 같이
다양한 크기의 rate를 사용하게 됩니다. - 이 방법을
Atrous Spatial Pyramid Pooling이라고 하고 줄여서ASPP라고도 부릅니다. - 이 내용은 DeepLab V2에서 부터 적용되어 그 이후 v3, v3+ 까지 사용되고 있습니다.
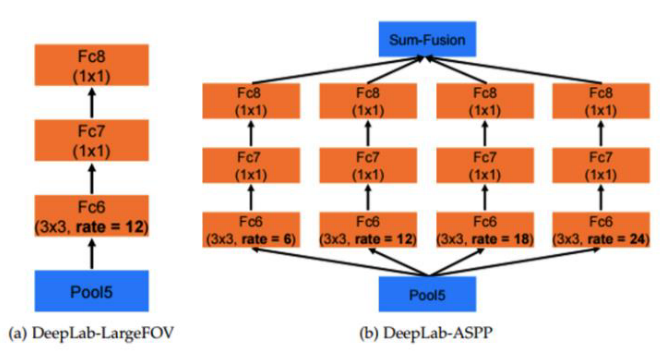
- 위의 왼쪽 그림은 고정된 rate를 사용한 경우이고 오른쪽 그림은 병렬적으로 다양항 크기의 rate를 사용한 경우입니다.
- 오른쪽 그림과 같이
ASPP구조를 적용한 경우에는 다양한 receptive field에 대응할 수 있는 장점이 있습니다.
- 그러면
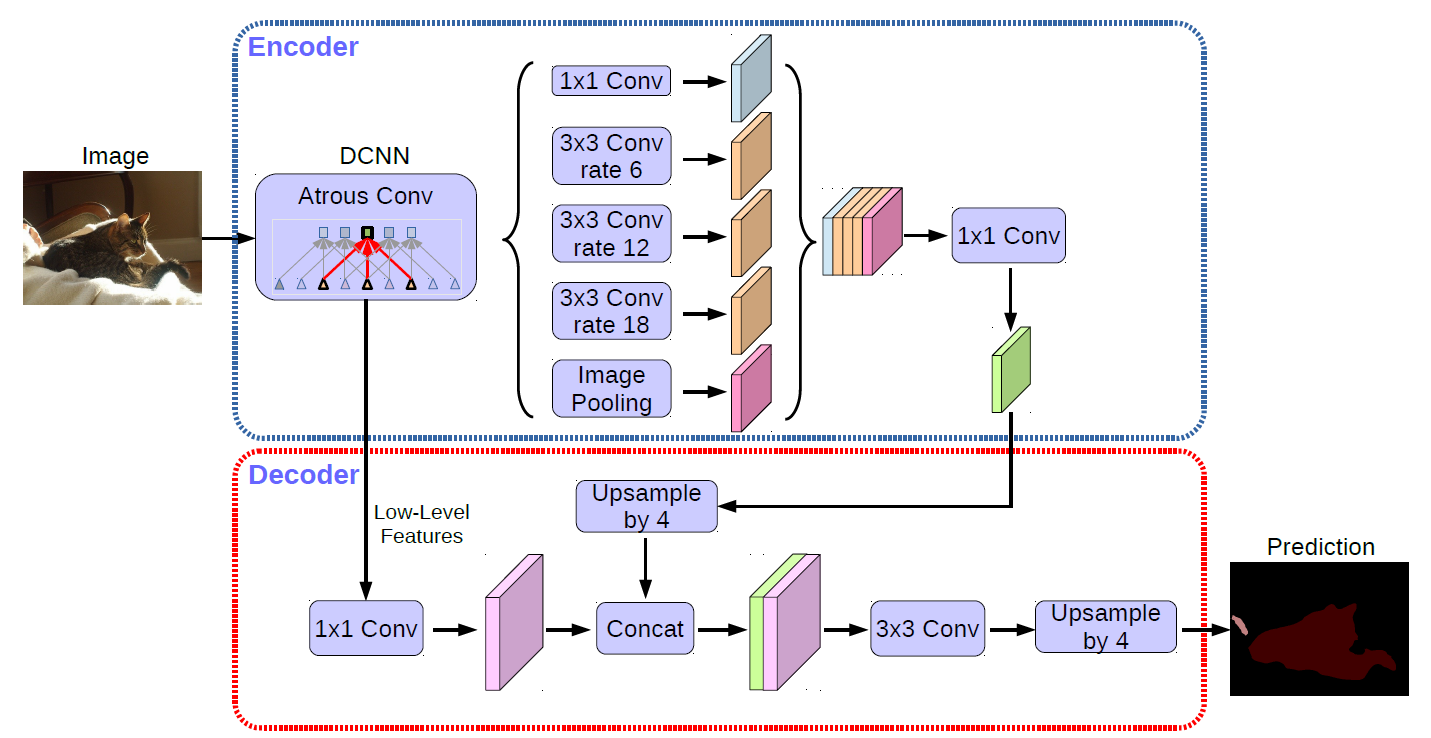
v3+에서 개선한 내용에 대해서 살펴보겠습니다. - 먼저 논문 제목의 키워드인 Encoder-Decoder with Atrous Separable Convolution에 따라 여기서 살펴 볼 것은 Atrous Convolution에 Encoder Decoder 구조를 접목했다는 것입니다.
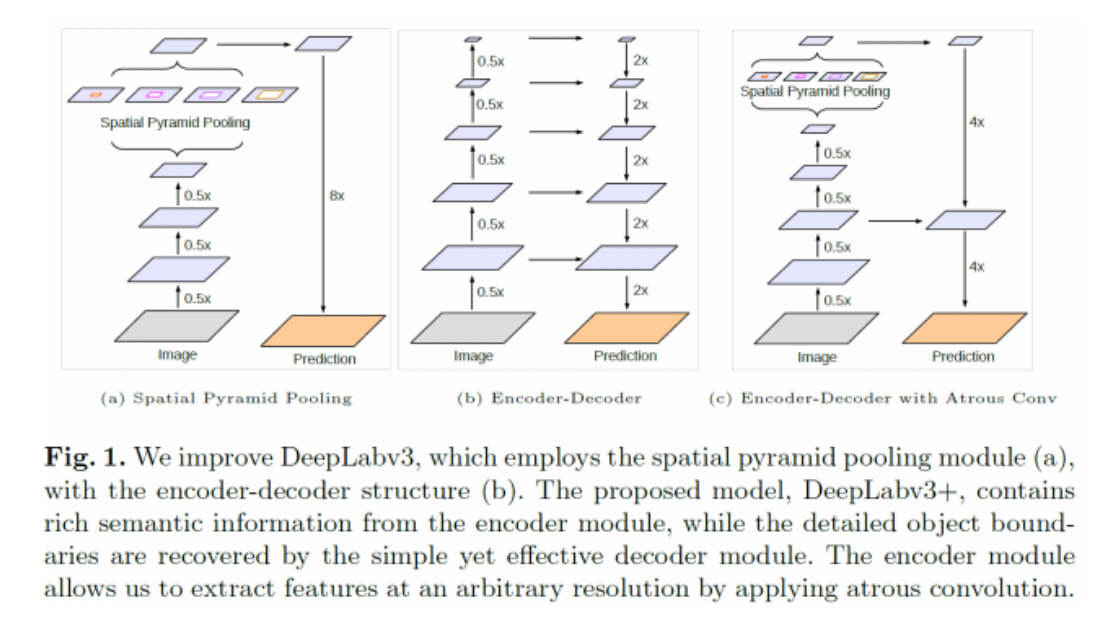
- 기존의
spatial pyramid pooling에서는 연산을 하고 난 결과를 단순히 upsampling 하였습니다. 여기서 단순히 upsampling 하는 과정이 문제가 있다고 판단하였습니다. - 위 그림의 (b)과 같은 Encoder - Decoder 형태의 구조를 이용하면 Encoder에서 좀 더 풍부한 semantic 정보를 추출할 수 있으므로 최종적으로
Spatial Pyramid Pooling과Encoder-Decoder를 결합해보려고 합니다.
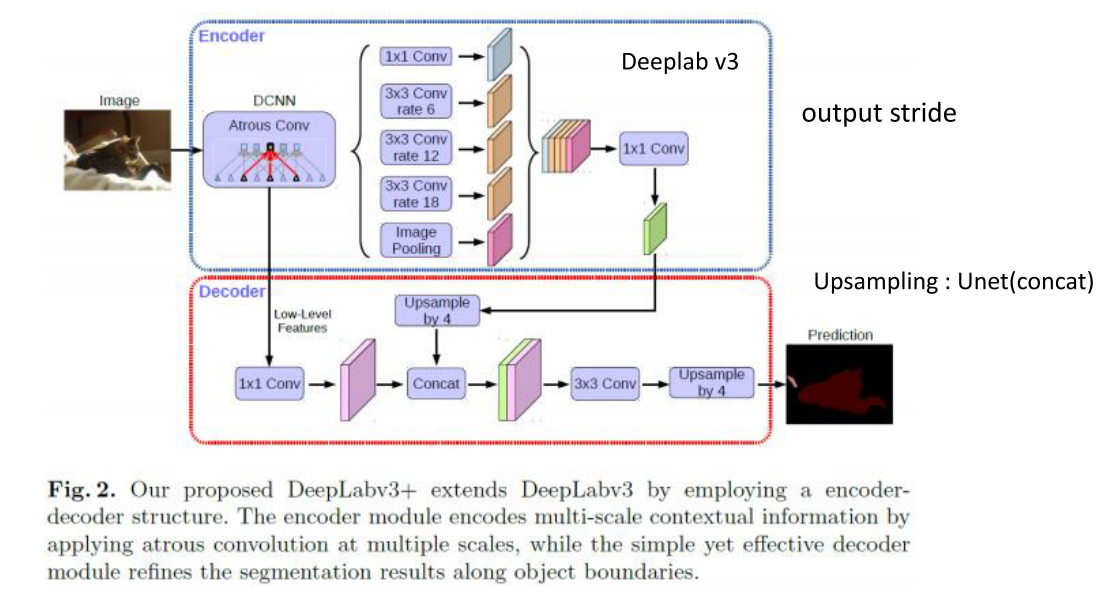
Encoder부분은DeepLab v3에서 다룬 내용과 같습니다.- Encoder 마지막 부분에서는 upsampling을 하기 위해서 마지막에 1x1 convolution을 하고 차원 축소를 한 다음에 upsampling 시 concat하는 방법을 가집니다. 이것은 마치 U-Net의 구조와 유사합니다.
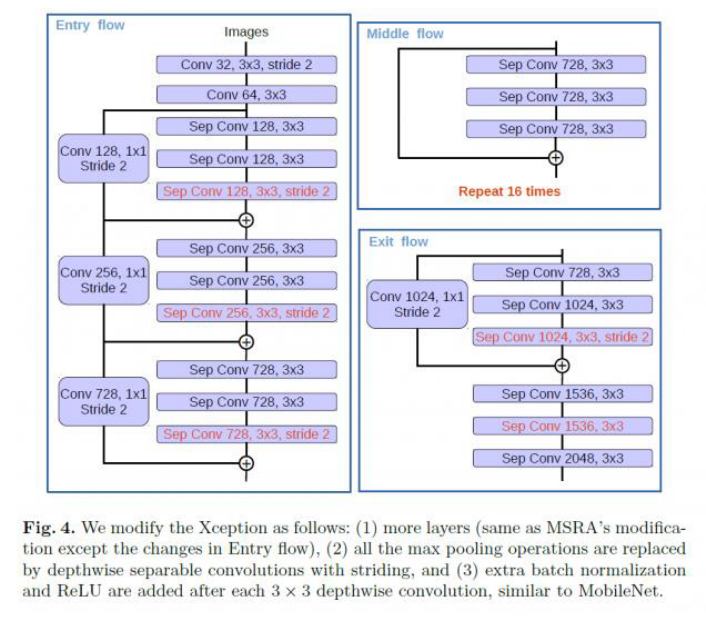
- DeepLab v3+에서 사용된 backbone 네트워크는 Xception과 ResNet-101입니다. 사용 결과 성능은 유사하나 Xception에서 조금 더 좋은 성능이 나왔다고 하였고 이 때 적용한 Xception 구조는 약간 변경되어 적용되었습니다.
- Atrous separable convolution을 적용하기 위하여 모든 pooling을 depthwise separable convolution으로 대체하였습니다.
- 그리고 각각의 3x3 depthwise convolution 이후에 추가적으로 batch normalization과 ReLU 함수를 추가하였습니다
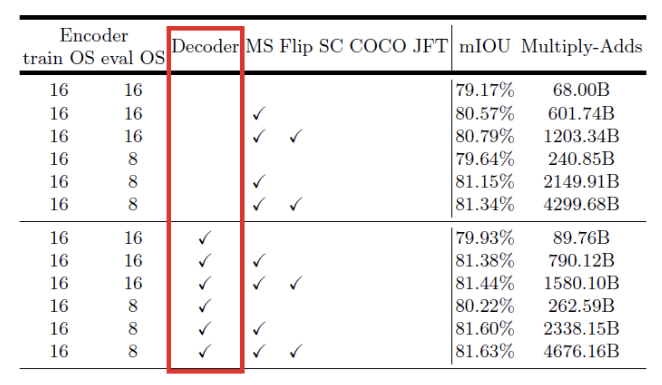
DeepLab v3+에 추가된Decoder부분의 개선 성능을 평가 지표로 살펴보겠습니다.Encoder부분은 기존의 DeepLab v3에도 있었기 때문에 위의 6개는 Encoder만 있고 아래 6개는 Encoder + Decoder 구조가 됩니다.mIOU를 비교해 보면 아래 6개의 성능이 더 좋습니다.- 참고로
mIOU는 IOU의 평균이고 segmentation에서는 픽셀 단위 기준으로 IOU를 실시하게 됩니다.
- 참고로

- segmentation 결과를 보면 가장 오른쪽의
w/ Decoder부분의 성능이 좋아진 것을 볼 수 있습니다. - 참고로 w/ BU에서 BU는 Bilinear Interpolation을 통한 Upsampling으로 Decoder 없이 Upsampling 된 방법입니다.
- 정리하면
DeepLab v3+에서는Atrous Spatial Pyramid Pooling을 통하여 receptive field를 다양하게 하였고 그 효과로 크고 작은 객체의 segmentation 작업을 잘 할 수 있도록 고안하였습니다. - 또한
U-net에서 사용한 Encoder-Decoder 구조와 Encoder Decoder 간 concatenation 구조를 적용하는 Upsampling 방식을 사용하여 bilinear interpolation upsampling 보다 좋은 효과를 얻을 수 있었습니다.
Pytorch 코드 리뷰
- 작성중 ….