LiteSeg, A Novel Lightweight ConvNet for Semantic Segmentation
2020, Jun 20
- 출처 : https://arxiv.org/abs/1912.06683
- 이번 글에서는 Cityscapes benchmark에 등록되어 있는 모델 중 하나인
LiteSeg에 대하여 다루어 보도록 하겠습니다. - 이 모델은 Realtime 성능 위주의 Sementic Segmentation 모델 중 하나입니다.
- 논문 전체의 내용이 DeepLabv3와 관련이 있으므로 아래 링크를 먼저 보시는 것을 추천 드립니다.
- deeplabv3 : https://gaussian37.github.io/vision-segmentation-deeplabv3/
- deeplabv3+ : https://gaussian37.github.io/vision-segmentation-deeplabv3plus/
- aspp(atrous spatial pyramid pooling) : https://gaussian37.github.io/vision-segmentation-aspp/
목차
-
Abstract
-
Introduction
-
Methods
-
Experimental Results and validation
-
Conclusion
-
Pytorch Code
Abstract
- LiteSeg 모델은 semantic segmentation 종류의 하나로 핵심 내용은 ASPP(Atrous Spatial Pyramid Pooling)를 조금 더 깊게 만드는 것에 있습니다. 이 때, 짧고 긴 residual connection과 depthwise separable convolution을 사용하여 좀 더 빠르고 효율적인 모델을 만듭니다.
- 논문에서는 3개의 backbone인 darknet19, mobilenet_v2, shufflenet을 차례 대로 사용합니다. 3개의 backbone 중에서 darknet19가 무겁지만 성능이 좋고 shufflenet이 가볍지만 상대적으로 성능이 나쁩니다. 이 3개의 backbone을 이용하여 accuracy와 computational cost의 상관관계를 다루고 backbone에 따른 segmentation의 성능도 비교해 봅니다. LiteSeg에서 제안한 backbone은 그 절충안인 mobilenet_v2입니다.
- Mobilenet_v2를 사용하였을 때 LiteSeg의 성능은 Cityscapes 데이터 셋에서 67.81% mIoU 입니다.
Introduction
- Semantic segmentation은 모든 pixel들에 label을 할당하는 문제로 자율주행, 영상 의학등에 많이 사용되고 있습니다. segmentation 문제는 특히 Convolution Neural Network의 사용으로 점점 더 발전되고 있습니다.
- 또한 segmentation 모델의 발전에 힘입어 edge device에서의 segmentation 활용이 필요해짐에 따라 가볍고 효율적인 segmentation 모델의 필요성이 점점 커지고 있습니다. 이에 따라서 segmentation 모델 중 accuracy를 낮추는 손해를 보더라고 parameter와 연산량을 줄여서 실시간으로 사용할 수 있도록 발전되는 모델들도 있습니다. 대표적으로 ENet, ESPNet, ERFNet 등이 있습니다.
- CNN을 이용한 Sementic segmentation의 발전을 논한 때에는
FCN(Fully Convolutional Network)는 빼놓을 수 없습니다. FCN에서는 Encoder-Decoder 구조를 사용하여 Segmentation을 하였습니다. 특히 Encoder에서는 Classification 모델을 이용하여feature extraction을 하고 Decoder에서는 이를upsample하는 방법을 하여 입력된 이미지 사이즈를 맞추게 되는데 이 방법은 대부분의 Segmentation 모델에서 사용되고 있습니다. - 또한
Skip architecture를 사용하여 accuracy를 높였습니다. skip architecture는 input에 가까운 layer(earlier layer)와 output에 가까운 layer(deeper layer)를 합치는 방법을 말합니다. 이렇게 두 종류의 layer를 합치는 이유는earlier layer은 spatial information에 유리하고deep layer은 semantic information에 유리하기 때문입니다. 서로 다른 유형의 layer를 합쳐서 더 좋은 결과를 만들어 냅니다. - 그럼에도 불구하고 FCN은 low resolution 문제가 있습니다. 즉, detail 하지 못한 결과가 출력됩니다. 이를 해결하기 위해 여러가지 방법들이 제시되어 왔습니다. 예를 들어
multi-scale network를 사용하는 방법이 있습니다. 이는 여러 scale을 적용하여 만든 resolution의 feature들을 조합하여 사용하는 방법으로 단순한 패턴의 single scale network에 비하여 low resolution 문제를 개선하였습니다. - 또한
deeplab시리즈 논문에서 적용된dilated convolution또는atrous convolition을 이용하여 파라미터 수의 증가 및 계산량의 증가 없이 receptive field를 확장시켜서 성능을 개선하였습니다. 그리고CRF(Conditional Random Field)를 후처리로 적용하여 출력 결과를 좀 더 detail 있게 개선하였습니다. - 이 이후에는
multi-scale을 사용하여 pooling 하는 방법들이 적용되었습니다. 대표적으로PPM과ASPP가 있습니다.PPM(Pyramid Pooling Modlue)은 서로 다른 크기의 kernel 사이즈를 이용하여 Pooling을 하는 연산 방법입니다.ASPP는 서로 다른 크기의 dilation을 사용하는 dilated convolution을 이용한 Pooling하는 방법입니다.
- segmentation 모델의 발전 양상을 살펴보면 위에서 다룬
skip architecture,multi-scale,multi-scale pooling방법들을 이용하여 accruacy 성능을 높였습니다. 하지만 accuracy 성능이 높아짐에 따라 computational cost가 증가하기도 하였습니다. - 이 문제를 개선 하기 위하여 segmentation 모델의 또다른 발전 측면으로 realtime 성능을 확보하기 위한 모델들도 있습니다. 이 모덷들에 대하여 살펴보도록 하겠습니다.
ERFNet은 computational cost와 accuracy을 절충하기 위하여residual connection구조와depthwise separable convolution을 사용하였습니다.ESPNet은 Efficient Spatial Pyramid라는 Module을 제안하였습니다. 이 module은point wise convolution과dilated convolition의 spatial pyramid구조를 사용합니다.RTSeg에서는 decoupled encoder-decoder 구조를 제안하였습니다. 이 구조는 다양한 encoder 구조들 (VGG16, MobileNet, ShuffleNet, …)와 decoder 구조들 (UNet, Dilation, SkipNet)을 서로 독립적으로 붙였다 떼었다 할 수 있는 블록과 같은 구조입니다. 특히RTSeg논문에서는 SkipNet (decoder)와 MobileNet 또는 ShuffleNet (encoder) 구조에서 좋은 성능을 보였습니다.
LiteSeg논문에서는 encoder-decoder 구조에ASPP,dilated convolution,depthwise seperable convolution을 이용하여 새로운 architecture를 제시합니다. LiteSeg architecture의 가장 큰 장점은 어떤 backbone과도 결합이 가능하여 다양한 trade-off (accuracy vs. computation)를 시험해 볼 수 있습니다.LiteSeg를 정리하면 모든 backbone과 가능한 결합 + ASPP module 적용 + long/short residual connection 적용으로 요약할 수 있습니다.
Methods

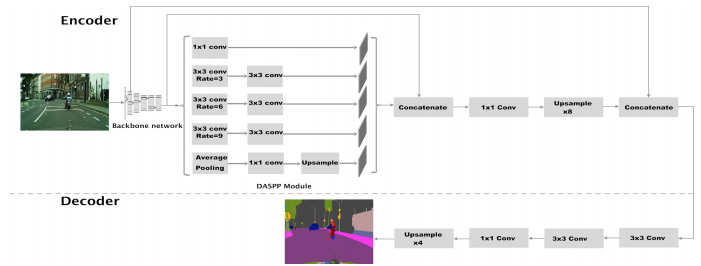
- 먼저 위 그림은 LiteSeg의 전체 Architectur를 설명합니다. 구조는 크게
Encoder와Decoder부분으로 나뉘게 됩니다. Encoder에서는 이미지를 입력 받고 high dimensional feature vector를 생성합니다. - Decoder에서는 Encoder에서 전달 받은 feature vector를 이용하여 공간 정보를 복원합니다. 그 결과 입력 이미지와 같은 크기로 feature vector의 사이즈를 변경합니다.
- 특히, Encoder 부분의 DASPP 모듈을 자세히 살펴보시기 바랍니다. (기존의 ASPP 참조) 그러면 LiteSeg에서 사용된 기법들에 대하여 차례대로 알아보도록 하겠습니다.
Atrous Convolution
- CNN에서는 (특히 classification에서는) stride와 pooling을 이용하여 공간 정보를 줄여나갑니다. 반대로 segmentation에서는 이 점이 receptive field를 줄여서 공간 정보에 대한 손실이 생겨서 detail한 segmentation 결과를 만들 때, 단점이 됩니다.
- 이 문제를 개선하기 위하여
Atrous(dilated) convolution을 사용하였습니다. 이 방법을 통하여 파라미터 수의 증가 또는 feature map의 감소 없이 receptive field를 넓힐 수 있습니다. - receptive field를 넓힌 결과, 네트워크는 global context feature를 학습할 수 있게됩니다. 즉 이미지 전체를 바라보고 segmentation 할 수 있게 됩니다.
Depthwise Separable Convolution
- Depthwise separable convolution은 계산량 감소 목적으로 사용됩니다. 이미 많은 네트워크에서 유사한 성능, 심지어 더 좋은 성능을 depthwise separable convolution을 통하여 만들기도 하였습니다. 따라서 이 네트워크에서도 이 연산을 사용하였습니다.
Long and short residual connection
- 위 그림의 구조를 보면 backbone의 low level과 high level에서 각 feature를 뽑아서 DASPP 이후에 concatenation 하는 구조를 보여줍니다.
- 이 connection의 목적은 ResNet, DenseNet에서 사용된 것과 같은 의도로 학습이 잘되기 위함에 있습니다.
- 특히 두 종류의 connection인 (SRC)short residual connection과 (LRC)long residual connection 각각은 memory unit과 같은 역할을 하여 bottom layer에서 top layer 까지 정보를 유지하도록 도와줍니다. (backbone의 끝 부분에 있는 residual이 SRC이며 backbone의 시작 부분에 있는 residual이 LRC 입니다. concatenation되는 지점과의 거리를 기준으로 short/long을 붙였습니다.)
- residual을 합치는 방법은 대표적으로 addition(ResNet)과 concatenation(DenseNet)이 있습니다. LiteSeg에서는
concatenation하는 방법을 사용하였습니다. DensNet의 논문에 따르면 concatenation 방법이 메모리를 더 사용하는 단점이 있지만 성능이 더 좋다고 실험을 통하여 증명하였기 때문입니다. - concatenation을 하기 위해서는 concat을 할 feature들의 height, width, depth의 dimension이 맞아야 합니다. dimension을 맞추기 위하여 upsampling과 1x1 convolution을 이용하여 feature들의 크기를 맞추어줍니다. 여기서 1x1 convolution은 계산량을 줄이기 위하여 depth를 줄이는 용도로 사용됩니다.

- SRC, LRC 그리고 DASPP를 사용하였을 때의 효과는 위 그림과 같습니다.
- LRC의 사용은 좀 더 선명한 sementic boundary를 생성하는 데 도움이 되고 SRC + DASPP는 sementic segmentation의 fine tuning에 도움이 됩니다. 이 모든것을 조합한 결과 많은 공간 정보가 포함된 형태 결과가 나타나게 됩니다.
Proposed Encoder
- 논문에서 제안한 Encoder 구조는 크게 다음과 같이 3가지 특성을 가집니다.
- 1) backbone 구조를 가지며 backbone의 accuracy 성능과 computation cost의 trade-off 관계가 LiteSeg의 성능에도 영향을 끼칩니다.
- 2) output stride 지표(input image의 크기와 backbone이 출력하는 feature 간의 비율)는 accuracy 성능과 computation cost의 trade-off 관계를 가진다.
- 3) ASPP를 조금 개량하여
- 먼저 Encoder의 backbone 구조입니다.
- Encoder의 구조는 feature extraction을 위한 classification 모델을 포함하고 있습니다. 논문에서 사용한 모델은
DenseNet19,MobileNetV2,ShuffleNet입니다. DenseNet19의 accuracy 성능이 가장 높지만 속도가 느리고 ShuffleNet의 속도가 가장 빠르지만 성능은 나쁩니다. - 앞에서 설명하였듯이 LiteSeg에서 backbone의 accuracy, computation cose의 trade-off가 어떻게 작용하는 지 확인하기 위하여 3가지 backbone을 이용하여 실험하였습니다.
- 그 다음은 Ecnoder의 output stride 입니다.
- backbone 뿐 아니라
deeplabv3에서 소개된 output stride가 성능에 어떻게 영향을 주는 지 확인하였습니다. output stride는 input image size 대비 feature map의 size입니다. 예를 들어 input image의 사이즈가 height = H, width = W 이고 (output stride에서는 depth는 고려하지 않습니다.) feature map의 사이즈가 h, w이면output stride = (H * W) / (h * w)가 됩니다. - (H * W)의 크기는 고정이므로 (h * w)의 크기에 따라 output stride가 달라질 수 있습니다. output stride가 크다는 것은 (h * w)가 작다는 뜻이고 feature map의 크기 또한 작다는 뜻입니다. 반면 output stride가 작다는 것은 (h * w)가 크다는 것이고 feature map의 크기 또한 크다는 뜻입니다.
- output stride가 작을수록 feature map이 크다는 것이고 feature map이 클 수록 공간 정보를 유지하는 데 유리하기 때문에 성능이 좋습니다. 반면 feature map이 큰 상태를 유지하면 feature map이 작을 때에 비하여 계산 비용이 늘어납니다.
- 따라서 output stride의 크기를 이용하여 성능과 속도의 trade-off를 고려해야 합니다. 정리하면 output stride가 작을수록 성능이 좋으나 계산 비용이 커집니다.
- DeepLabv3+에서는 backbone의 output feature의 output stride를 조정하기 위하여 maxpooling layer를 제거하고 마지막 convolution layer를 수정하였습니다. 참고로 DeepLabV3+에서는 output stride를 16으로 잡는 것이 가장 적합한 trade-off 였다고 설명합니다. 물론 네트워크 구조와 데이터의 특성에 따라 이 값이 무의미할 수 있습니다.
- 이 논문에서는 3가지 backbone인 DenseNet19, MobileNetv2, ShuffleNet을 사용하였고 각 backbone의 output stride는 16, 32, 32입니다. DenseNet19를 이용하였을 때, 성능이 가장 좋은 반면 수행 속도가 느린것을 보면 output stride가 LiteSeg의 성능 경향을 파악하는 데 도움이 된다고 말할 수 있습니다.
- 마지막으로 Encoder의
DASPP구조 입니다. - DeepLabV3에서는 ASPP(Atrous Spatial Pyramid Pooling)을 사용하였습니다. 이 모듈은 서로 다른 dilation 비율을 이용하여 multi-scale 정보를 얻는 pooling 방법입니다. (자세한 내용은 이 글의 처음 ASPP 링크를 참조하시기 바랍니다.)
- 이 논문에서는 기존의 ASPP 구조를 사용하되 조금 변경하여 사용하였습니다. 아래 그림을 참조하시면 됩니다.
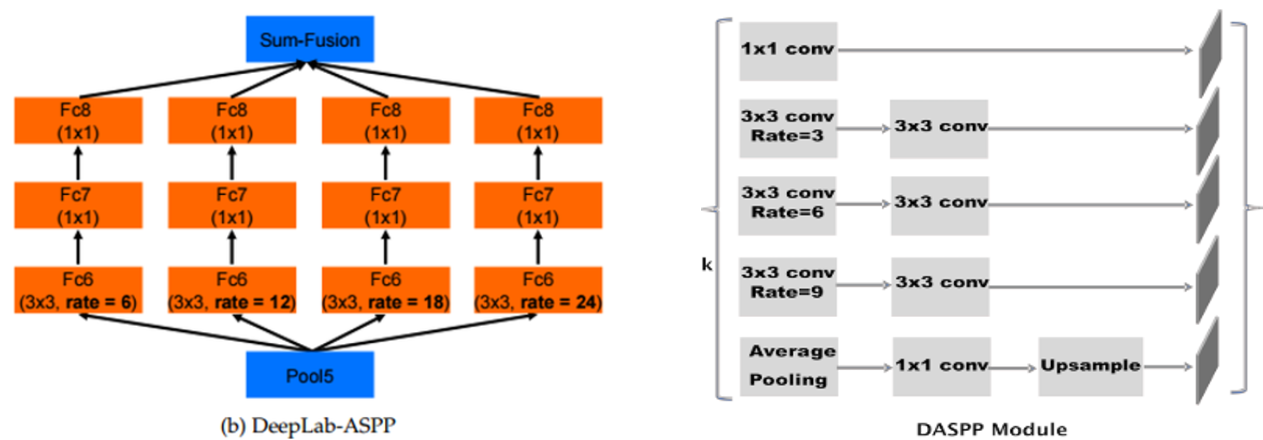
- 위 그림을 보면 1x1 convolution 대신 3x3을 적용하였다는 것과 rate의 비율을 deeplabv3에 비하여 줄였다는 것입니다.
- ASPP의 경우 convolution filter의 수가 255개인 반면 DASPP에서는 96개로 줄여서 computational cost를 줄일 수 있었습니다.
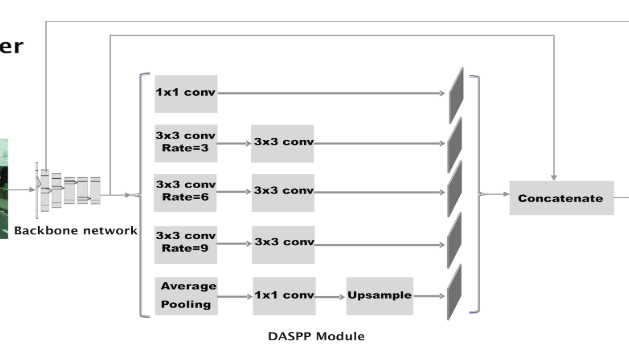
- DASPP의 모듈 뒤에는 앞에서 정의한 SRC와 concatenation이 됩니다. 위 그림을 참조하시기 바랍니다.
Deeplabv3+ as a Decoder
- LiteSeg에서 사용된 Decoder 모듈은 DeepLabV3 → DeepLabV3+에서 추가된 Decoder 구조를 사용하였습니다.
- 추가적으로 ASPP → DASPP의 구조 변경으로 인한 점과 SRC, LRC를 Concatenation한 결과를 반영하여 DeepLabv3+의 Decoder 구조를 변경하여 사용하였습니다.
- 특히 Encoder의 최종 출력은 LRC와 concatenation을 한 결과입니다. 이 때 사용한 LRC의 channel의 수가 작지 않기 때문에, 1x1 convolution을 이용하여 channel의 수를 줄이는 방법을 사용하였습니다. 이를 통하여 computational cost를 줄입니다. 이는 어떤 backbone을 사용하는 지에 따라 적용할 필요가 있을 수 있고 없을 수 있습니다. 상대적으로 가벼운 backbone인 MobileNetv2의 경우 LRC의 경우 24 channel이므로 추가적인 1x1 convolution은 필요없을 수 있습니다.