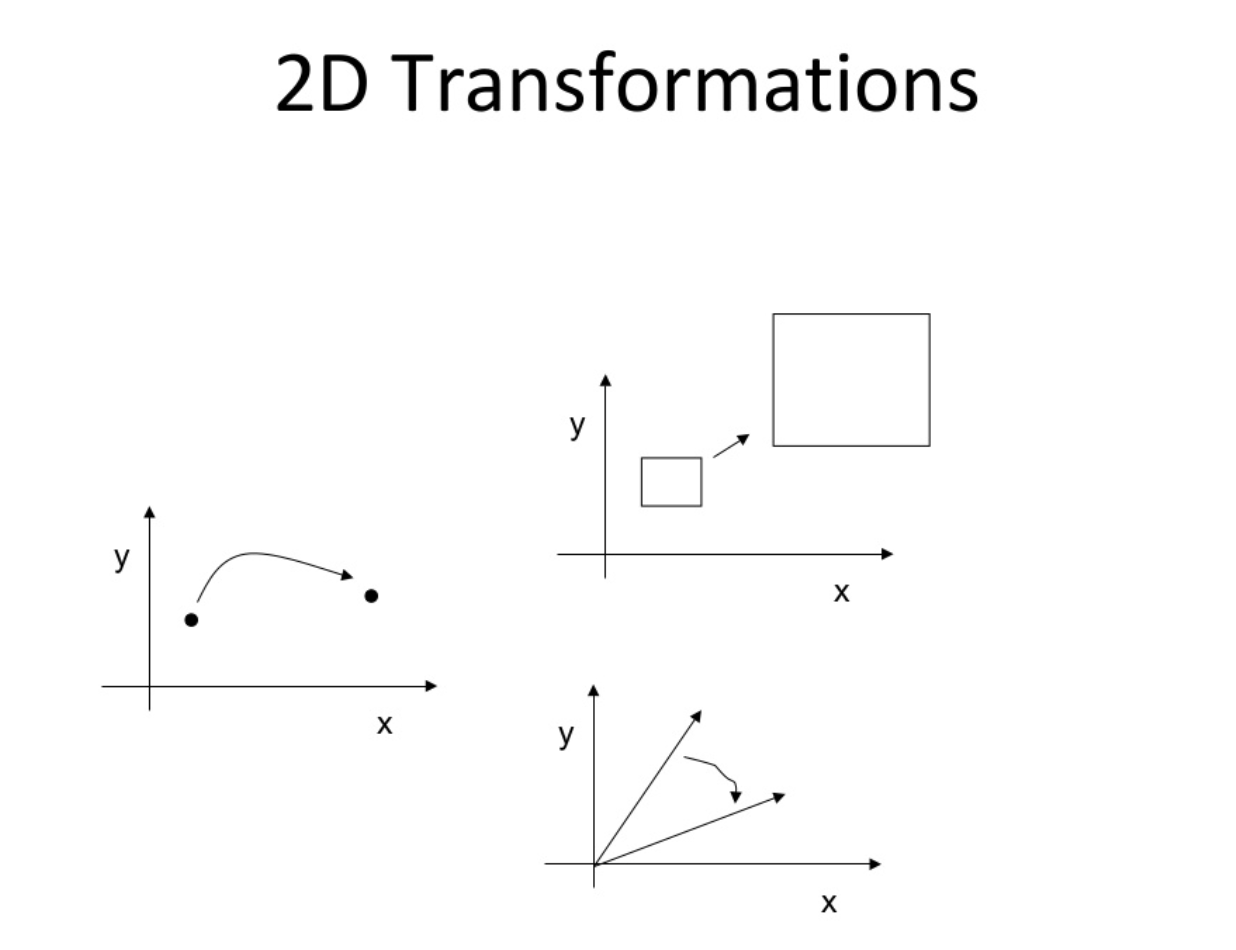
Image Transformation 알아보기
2019, Dec 26
- 참조 : Computer Vision Algorithms and Applications (Richard Szeliski)
- 참조 : Introduction to Computer Vision
- 참조 : OpenCV를 활용한 컴퓨터 비전
- 이번 글에서는 2D 이미지를 다양한 방법으로 Transformation하는 방법들에 대하여 총 정리해 보도록 하겠습니다.
목차
-
Geometric Transformation (기하학적 변환)의 정의
-
Translation Transformation (이동 변환)
-
Shear Transformation (전단 변환)
-
Scale Transformation (크기 변환)
-
Reflection Transformation (대칭 변환)
-
Rotation Transformation (회전 변환)
-
Affine Transformation과 Perspective Transformation
-
remap 함수를 이용한 remapping
-
Perspective Transform을 이용한 문서 스캐너
Geometric Transformation (기하학적 변환)의 정의
- 흔히 알려진 기본적인 이미지 처리 방법인 필터 적용, 밝기 변화, 블러 적용등은 픽셀 단위 별로 변환을 주는 작업입니다. 이는 픽셀 값의 변화가 있을 뿐 픽셀의 위치 이동은 없습니다.
- 영상의
기하학적 변환 (Geometric Transformation)이란 영상을 구성하는 픽셀이 배치된 구조를 변경함으로써 전체 영상의 모양을 바꾸는 작업을 뜻합니다. 즉, 어떤 픽셀의 좌표가 다른 좌표로 이동되는 경우를 말합니다.
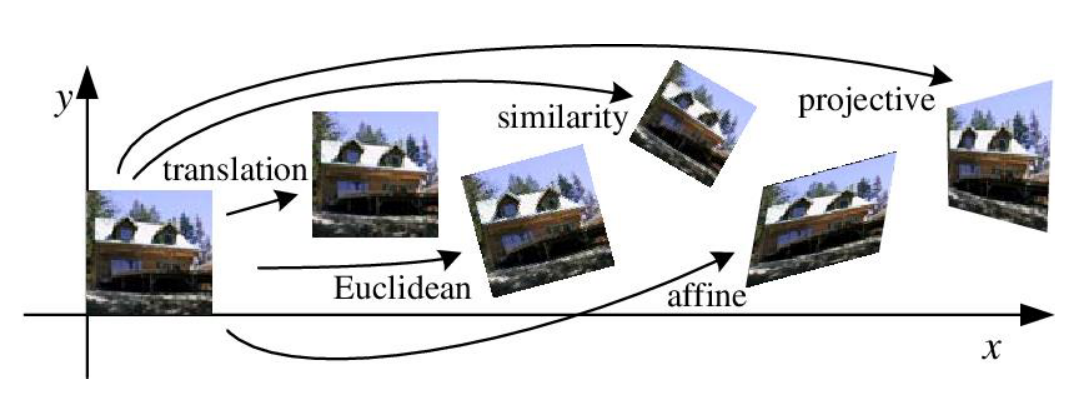
- 위 그림은 대표적인 Geometric Transformation의 예시를 나타냅니다. 이 중에서
affine변환과projective변환에 대해서는 이 글의 내용을 읽어 보시길 권장드립니다. 그 만큼 중요합니다.
Translation transformation (이동 변환)
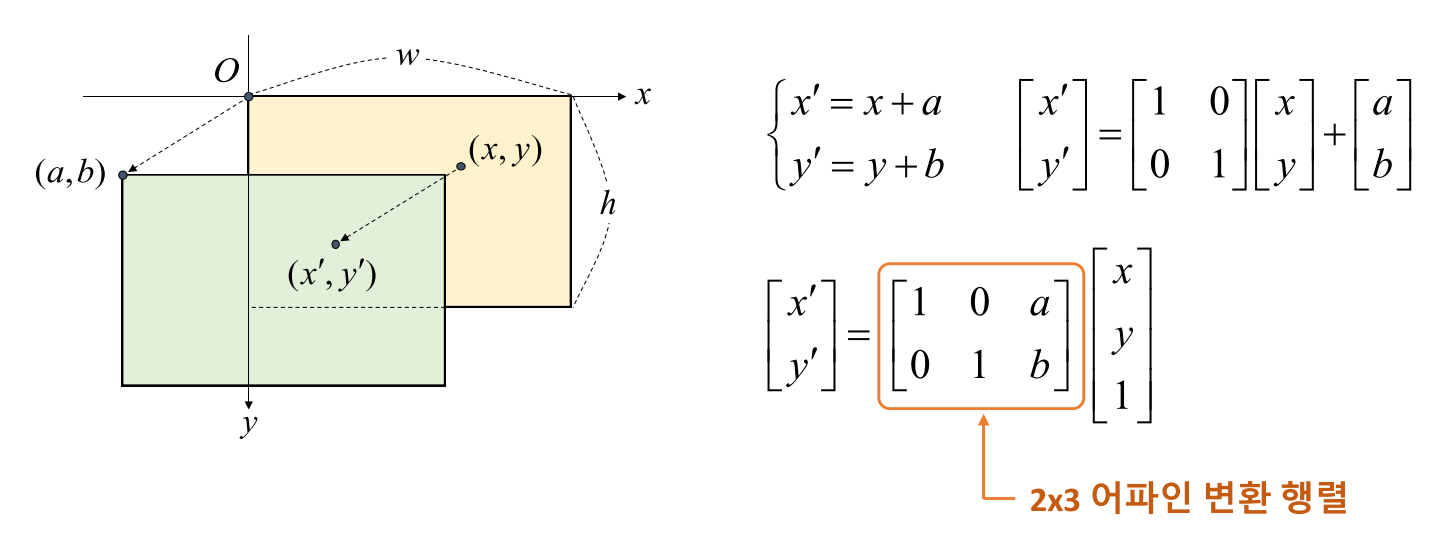
- 먼저 영상의 이동 변환에 대하여 알아보도록 하겠습니다. 영상의 픽셀 값이 한 쪽 방향으로 이동한 경우를 나타내며 shift 라고도 합니다.
- 이동 변환에서는 영상이 \(x\)방향 또는 \(y\)방향으로 이동이 발생합니다. 따라서
이동 변위를 지정해 주어야 합니다. - 위 그림에서 \(x\) 방향으로 \(a\) 만큼, \(y\) 방향으로 \(b\) 만큼 이동한 것을 확인할 수 있습니다.
- \[\begin{cases} x' = x + a \\[2ex] y' = y + b \end{cases}\]
- 영상 처리에서 이러한 수식을 편리하게 사용하기 위해서는 수식을 행렬로 나타내어야 합니다. 따라서 다음과 같이 나타낼 수 있습니다.
- \[\begin{bmatrix} x' \\ y' \end{bmatrix} = \begin{bmatrix} 1 & 0 \\ 0 & 1 \end{bmatrix} \begin{bmatrix} x \\ y \end{bmatrix} + \begin{bmatrix} a \\ b \end{bmatrix}\]
- 간단하게 수식을 위 행렬처럼 변환할 수 있습니다. 영상 처리에서는 위 수식을 다음과 같이 곱셈 하나의 형태 (
homogeneous)로 표시합니다.
- \[\begin{bmatrix} x' \\ y' \end{bmatrix} =\begin{bmatrix} 1 & 0 & a \\ 0 & 1 & b\end{bmatrix} \begin{bmatrix} x \\ y \\ 1 \end{bmatrix}\]
- 여기서 \(\begin{bmatrix} 1 & 0 & a \\ 0 & 1 & b\end{bmatrix}\)을 이동 변환을 나타내기 위한
affine변환 행렬 이라고 합니다.
- OpenCV에서 Affine 변환 행렬을 이용하여 영상의 이동 변환을 하는 방법은 아래 링크를 참조하시기 바랍니다.
Shear Transformation (전단 변환)
- 영상의 전단 변환은 \(x, y\) 축 방향으로 영상이 밀리는 것 처럼 보이는 변환을 뜻합니다. (아래 그림 참조) 따라서 축에 따라서 픽셀의 이동 비율이 달라집니다.
- 따라서 전단 변환의 결과로 한쪽으로 기울어진 영상을 만들어 낼 수 있습니다. 따라서 각 방향으로 기울어진 변환을 적용하기 위하여 \(x\)축과 \(y\)축 각각에 대하여 변환을 적용하면 됩니다. 아래와 같습니다.
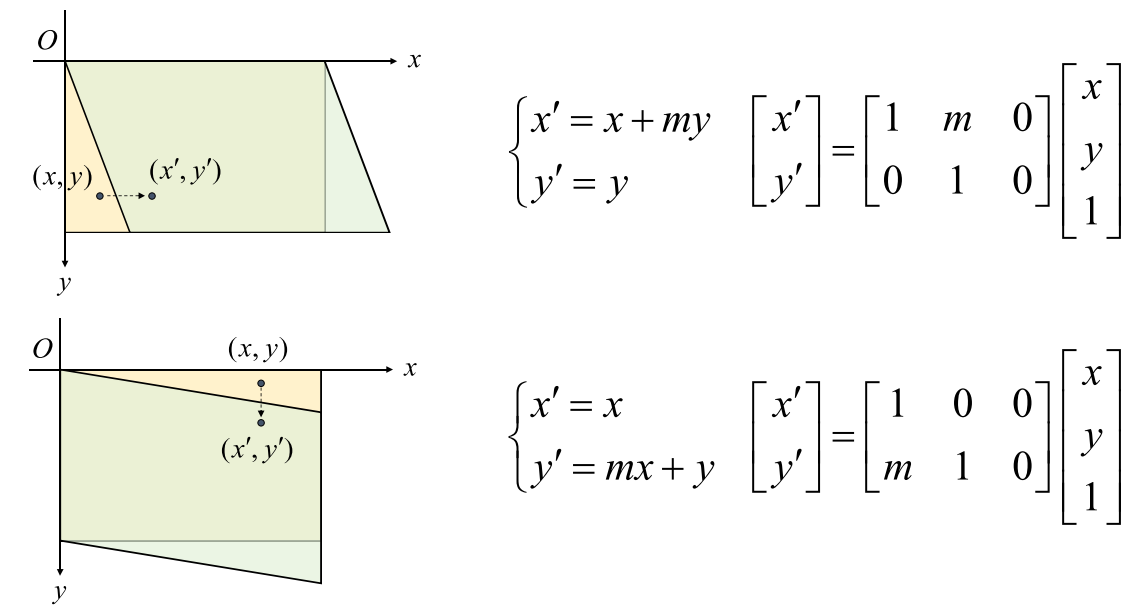
- 전단 변환 또한 affine 변환 행렬을 통하여 변환 상태를 나타낼 수 있습니다. affine 변환 행렬로 나타내는 방식은 이동 변환과 똑같은 방식입니다.
- \[\begin{cases} x' = x + my \\ y' = y\end{cases}\]
- 위 수식을 보면 \(x\) 좌표에 \(y\) 좌표 값에 스케일링 값 \(m\)을 곱한 값을 더하여 \(x\)값을 변환하였습니다.
- 이 방식을 통하여 \(x\) 값은 변환하고 \(y\) 값은 고정 시킬 수 있습니다.
- \[\begin{cases} x' = x \\ y' = mx + y \end{cases}\]
- 위 식은 앞의 식과 기준 축을 바꾼 경우이고 원리는 같습니다.
Scale Transformation (크기 변환)
- 영상을 확대하거나 축소할 수 있는 크기 변환에 대하여 알아보도록 하겠습니다.
- 크기 변환을 하기 위해서는 \(x\) 방향 또는 \(y\) 방향으로 얼마나 크게 또는 작게 만들기 위한
scale factor가 필요로 합니다.
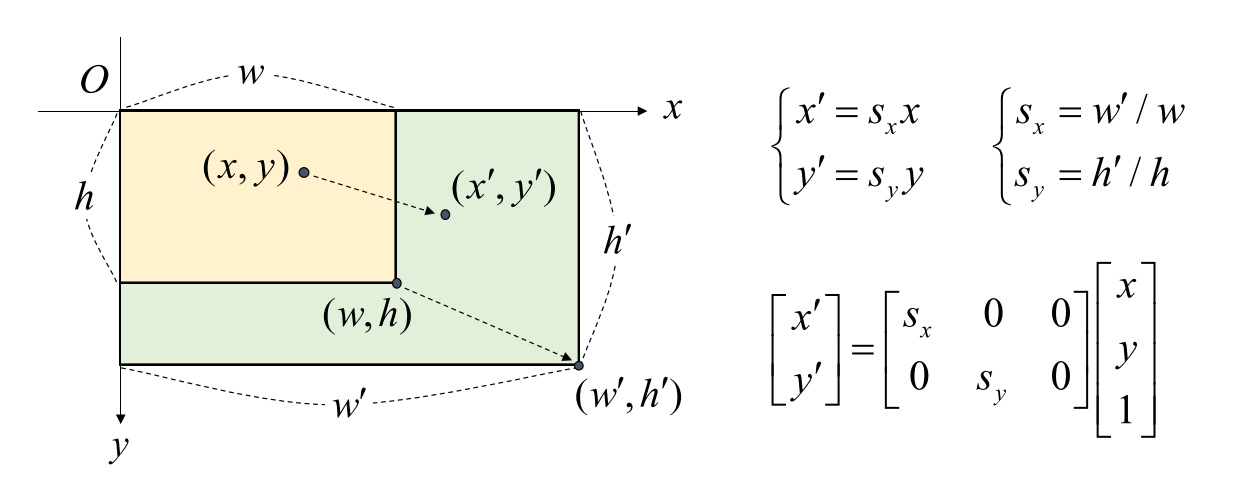
- 확대 및 축소를 위한 비율은 입력 영상과 출력 영상의 비율을 이용하여
scale factor를 구할 수 있습니다. - 이 factor를 위 수식과 같이 \(S_{x}, S_{y}\)로 구할 수 있고 이 값을 이용하여 affine 변환 행렬을 만들 수 있습니다.
- \[\begin{bmatrix} x' \\ y' \end{bmatrix} = \begin{bmatrix} S_{x} & 0 & 0 \\ 0 & S_{y} & 0 \end{bmatrix} \begin{bmatrix} x \\ y \\ 1\end{bmatrix}\]
- 따라서 위 식과 같은 affine 변환 행렬을 이용하면 이미지의 크기 변환을 적용할 수 있습니다.
- 영상의 크기 변환은 기하학적 변환 중에서도 굉장히 많이 사용되는 변환입니다. 따라서 affine 변환이 아닌 변도의
resize함수를 이용하여 사용하곤 합니다.
- 영상의 크기 변환은 Affine 변환을 이용하여 할 수도 있지만 좀 더 편하게 사용하기 위하여
resize함수라는 별도 함수를 이용하여 크기 변환을 할 수 있습니다. 다음 링크에서 기능을 확인하시기 바랍니다. - 링크 : https://gaussian37.github.io/vision-opencv_python_snippets/#resize를-이용한-크기-변환-1
Reflection Transformation (대칭 변환)
- 이미지의 대칭 변환은 크기 변환 + 이동 변환을 조합한 결과를 통해 만들어 낼 수 있습니다.

- 예를 들어 좌우 대칭된 변환은 크기를 -1배하여 변환할 수 있고 (위 그림의 왼쪽) 그 결과를 이동 변환을 통하여 (위 그림의 오른쪽) 기존 이미지를 대칭한 것 처럼 변환할 수 있습니다.
- 이 방법은 좌우 대칭, 상하 대칭, 좌우 상하 대칭에 모두 적용할 수 있습니다.
- 실제 구현할 때에는 간단하게 opencv의 flip 함수를 사용하면 됩니다. 아래 링크를 참조하시기 바랍니다.
Rotation Transformation (회전 변환)
- 이번에는 영상을 회전하는 회전 변환에 대하여 알아보도록 하겠습니다.
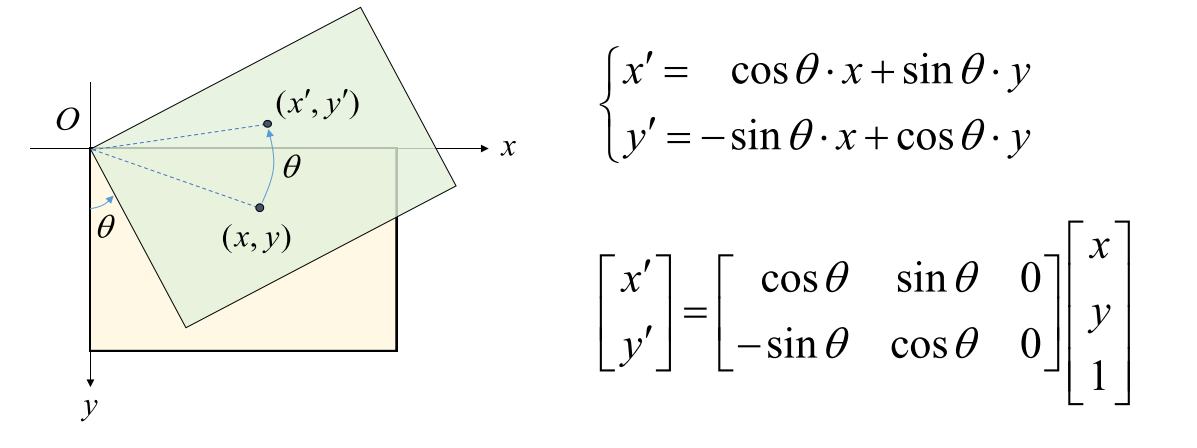
- 영상을 회전 하기 위한 변환은 위 식과 같이 \(\sin{\theta}, \cos{\theta}\)의 식을 이용하여 표현할 수 있습니다.
- 위 식의 유도 과정은 다음 링크를 참조하시기 바랍니다.
원점 기준의 회전과특정 좌표 기준의 회전모두 설명되어 있습니다. - 위 식을 통하여 변환되는 \(x, y\) 좌표를 통하여 원하는 각도 만큼 이미지를 회전할 수 있습니다.
- 앞의 다른 변환과 마찬가지로 affine 변환 행렬을 이용하여 변환하려면 2 X 3 크기의 행렬을 사용할 수 있습니다.
- \[\begin{bmatrix} \cos{\theta} & \sin{\theta} & 0 \\ -\sin{\theta} & \cos{\theta} & 0 \end{bmatrix}\]
- 위 affine 변환 행렬을 이용하면 원점 (0, 0)을 기준으로 이미지가 회전을 하게 됩니다. 이 때, 문제점이 발생하는데 한정된 공간에서 왼쪽 상단의 (0, 0)을 기준으로 회전을 하게 되면 영상의 많은 영역이 잘리게 됩니다.
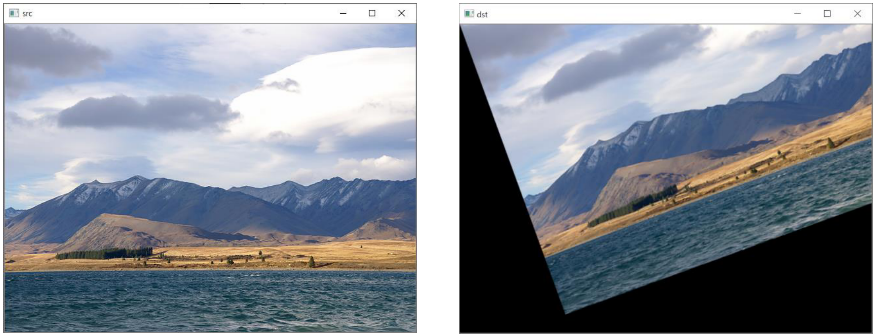
- 따라서 영상의 원점이 아닌 중앙점을 이용하여 회전하는 것이 일반적입니다. 이 때, 사용하는 affine 변환 행렬은 다음과 같습니다.
- \[\begin{bmatrix} \alpha & \beta & (1-\alpha) \cdot x - \beta \cdot y \\ -\beta & \alpha & \beta \cdot x + (1-\alpha) \cdot y \end{bmatrix} \ \ \text{ where, } \begin{cases} \alpha = \cos{\theta} \\ \beta = \sin{\theta} \end{cases} , \ \ (x, y) = \text{Rotation point}\]
- 위 affine 변환 행렬을 보면 3열에서 (0, 0)이 아니라 연산되는 항이 추가로 정의 되어 있습니다. 이 원리는 위 링크를 보면 확인 할 수 있고 간단하게 설명하면 다음과 같습니다.
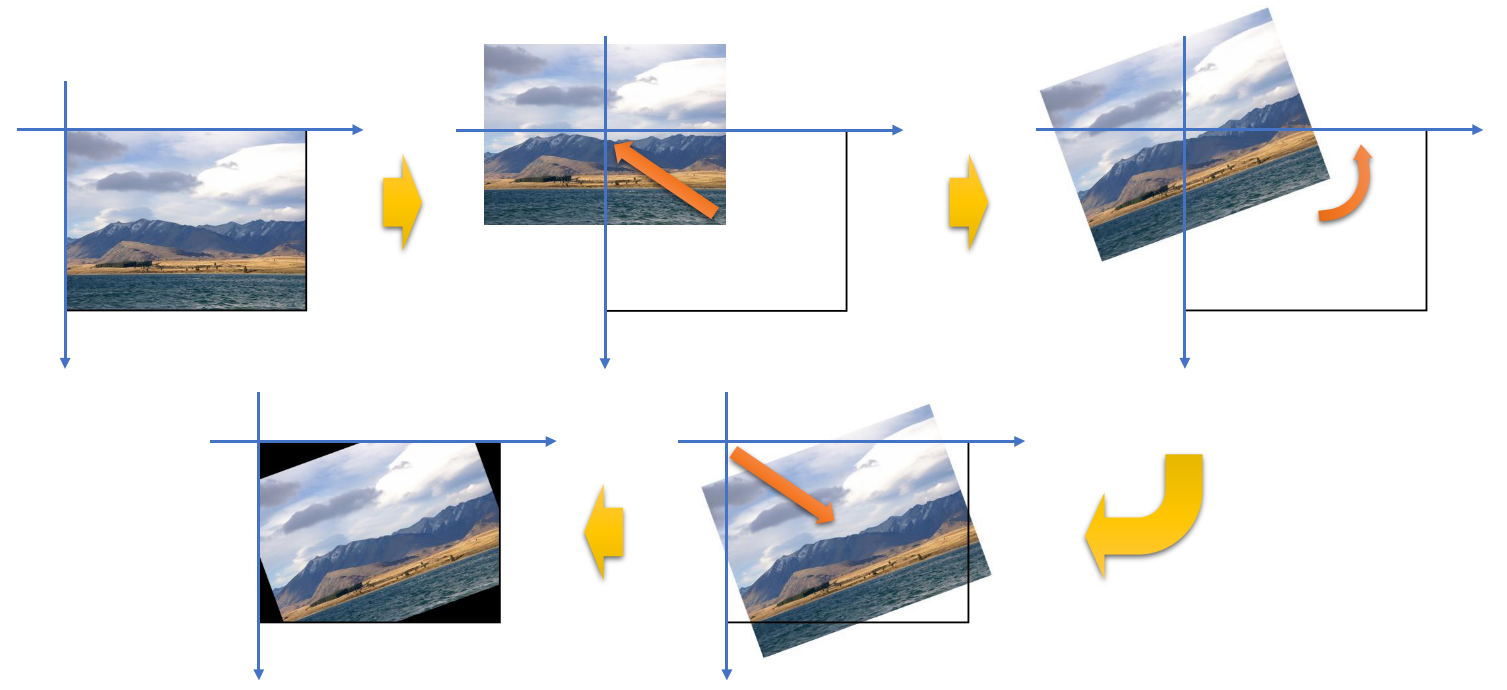
- 위 변환 순서를 보면 한번에 어떤 점 (ex. 중앙점)을 기준으로 회전하는 것이 아니라, ① 회전 기준점을 원점으로 이동 변환 ② 회전 변환 ③ 이동 변환을 거쳐서 임의의 점을 기준으로 회전을 하는 작업입니다.
- 추가적으로 위 affine 변환 행렬에서 크기 변환 까지 한번에 적용할 수 있습니다.
- \[\begin{bmatrix} \alpha & \beta & (1-\alpha) \cdot x - \beta \cdot y \\ -\beta & \alpha & \beta \cdot x + (1-\alpha) \cdot y \end{bmatrix} \ \ \text{ where, } \begin{cases} \alpha = \color{red}{scale} \cdot \cos{\theta} \\ \beta = \color{blue}{scale} \cdot \sin{\theta} \end{cases} , \ \ (x, y) = \text{Rotation point}\]
- 위 식과 같이 \(\alpha, \beta\)에
scale값을 주게 되면 회전 변환과 동시에 크기 변환도 적용 할 수 있습니다. - 이와 같은 회전 변환을 쉽게 구현하기 위해서 OpenCV에서는
warpAffine과getRotationMatrix2d함수의 조합을 사용할 수 있습니다. - 링크 : https://gaussian37.github.io/vision-opencv_python_snippets/
Affine Transformation과 Perspective Transformation
- 앞에서 살펴본 변환들은 모두
Affine Transformation입니다. 따라서 기본적으로affine 변환 행렬을 통하여 변환할 수 있었습니다. Affine Transformation의 공통점은 변환 결과가 모두평행사변형(Parallelograms)이라는 점 입니다. 즉, 앞에서 다룬 이동 변환, 전단 변환, 크기 변환, 대칭 변환, 회전 변환의 결과는 모두 평행 사변형 꼴의 변환입니다.- 이 때, 2 X 3 크기의 Affine 변환 행렬을 통하여 Affine Transformation을 적용하였습니다.
Affine Transformation을Perspective Transformation(또는 Homography, Projective Transformation 라고도 함)과 비교하기 위하여 2 X 3 크기의 행렬을 3 X 3 크기의 행렬로 확장하여 아래와 같이 비교해 보겠습니다.
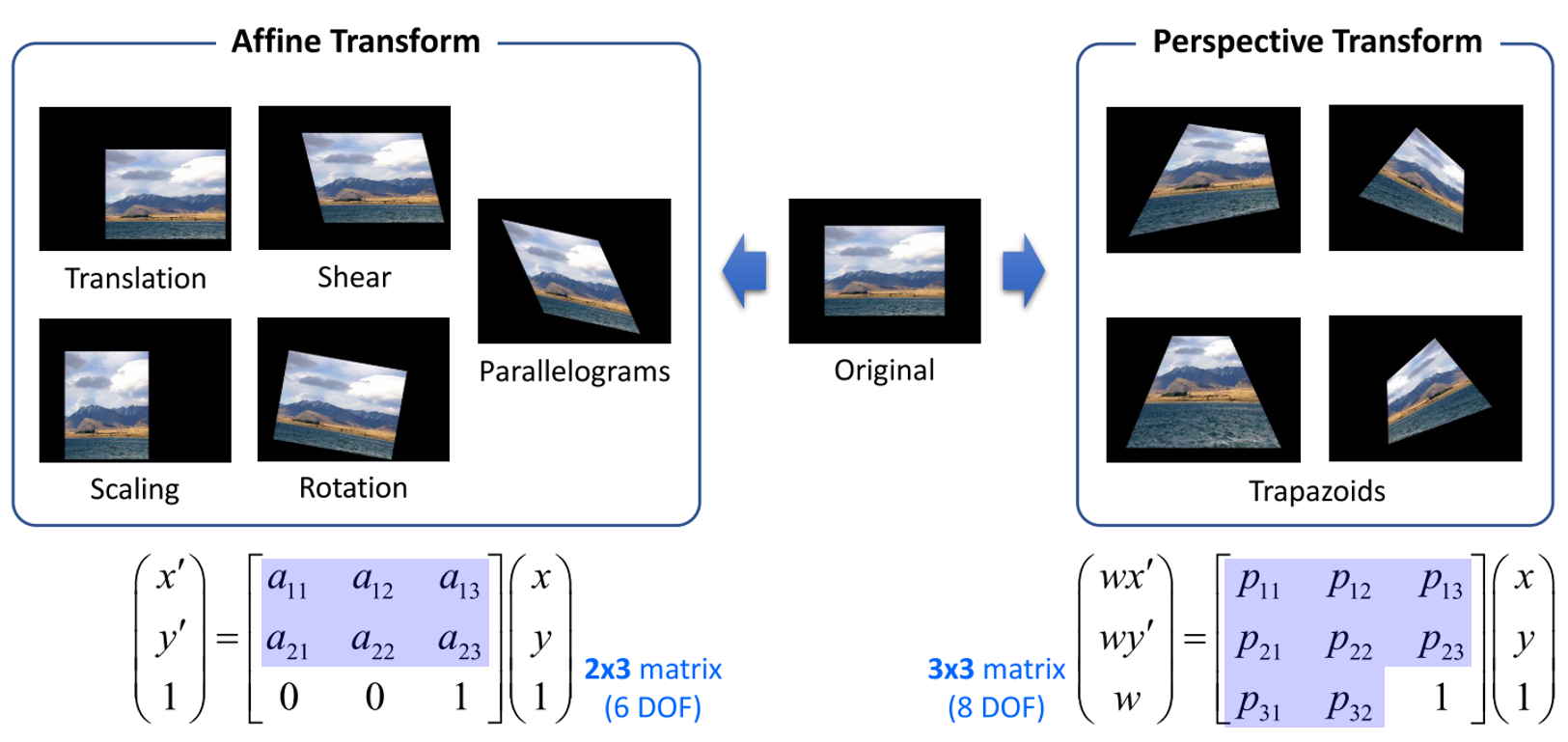
- 먼저 Affine Transformation은 앞에서 다룬 것과 같이 6개의 파라미터를 가집니다. 여기서 파라미터를
DOF(Degree Of Freedom)이라고 하며 DOF를 통하여 자유롭게 변형이 이미지의 기하학적 변환이 가능하기 때문에 이와 같은 이름으로 불립니다. - Affine Transformation에서는 위 변환 행렬에서
2 X 3 행렬크기의 파란색 음영의6개DOF가 정해지면 그 값에 맞춰서 이동, 전단, 크기, 대칭, 회전 등의 변환을 하게 됩니다. - 반면 Perspective Transformation에서는
3 X 3 행렬에서 파란색 음영의8개DOF가 정해지면 그 값에 맞춰서 변환을 하게 됩니다. - 변환된 이미지의 모양을 보면 평행사변형(Parallelograms) 형태의 Affine Transformation 보다 Perspective Transform이 더 자유로운 모양을 띄게 됩니다. 그 이유는 DOF가 2개 더 많기 때문에 자유로움이 더 높이 때문입니다.
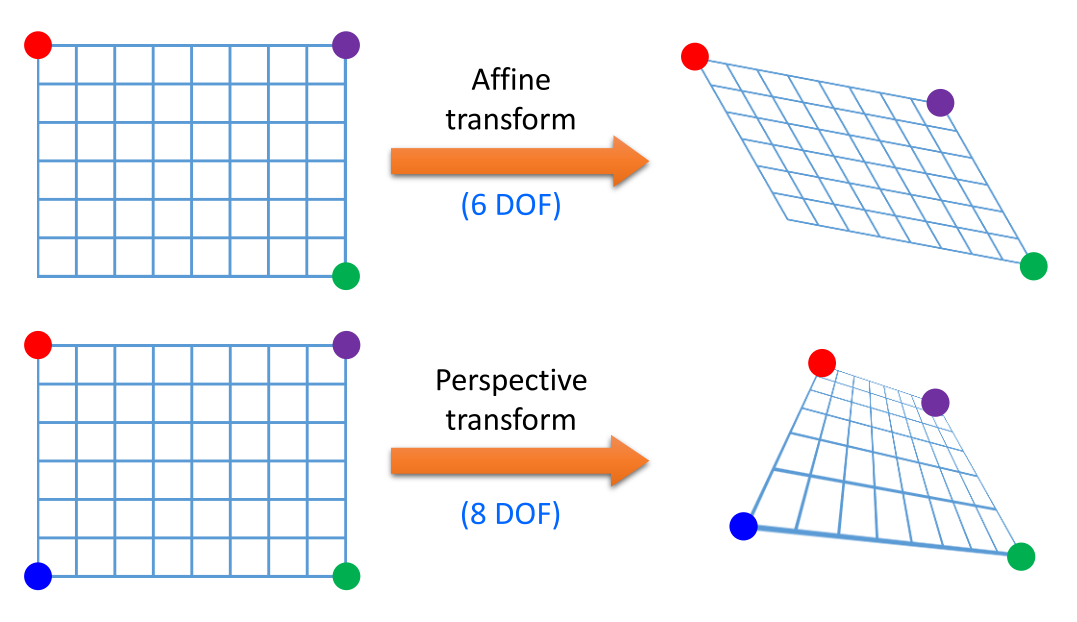
- Affine Transformation에서 6개의 파라미터를 알기 위해서는 6개의 연립 방정식이 필요합니다. 1개의 (x, y)에 대한 homogeneous 행렬에서 DOF에 관한 2개의 식을 구할 수 있기 때문에 3개 점의 6개 식을 이용하면 6개의 DOF를 구할 수 있습니다. 이는 위 그림과 같이 Affine Transformation이 평행사변형 형태를 유지하는 변환이기 때문에 3개의 점을 지정하면 자동적으로 하나의 점이 고정이 되어 3개의 점을 통해 변환 행렬을 구할 수 있는 것과 의미가 같습니다. 따라서 3개의 점의 변환 전 좌표와 변환 후 좌표를 알아야 Affine 변환 행렬을 구할 수 있습니다.
- 이와 동일한 관점에서 Perspective Transformation은 8개의 DOF를 구하기 위하여 4개의 점을 사용하여 구할 수 있습니다. 이는 위 그림과 같이 Perspective Transformation에서는 4개의 꼭지점이 자유롭게 변환된 상태로 이미지를 변환할 수 있어야 하기 때문에 4개의 점의 변환 전 좌표와 변환 후 좌표를 알아야 Perspective 변환 행렬을 구할 수 있습니다.
remap 함수를 이용한 remapping
- 리매핑은 (remapping)은 영상의 특정 위치 픽셀을 다른 위치에 재배치하는 일반적인 프로세스이며 projective transformation과 같은 기하학적 변환이 발생하였을 때 일반화하여 mapping 할 때 주로 사용합니다.
- 리매핑을 사용하면 변환 행렬 없이도 이미지 변환을 사용할 수 있고 비선형 변환 (src에서 직선이었던 물체가 dst에서는 곡선이 될 수 있음)도 할 수 있기 때문에 매우 유용합니다.
- \[\text{dst}(x, y) = \text{src}(\text{map}_{x}(x, y), \text{map}_{y}(x, y))\]
- 위 식의 의미를 살펴보면 출력 영상
dst의 각 픽셀 좌표 \(x, y\) 를 입력 영상src에서 참조를 하는데 어느 위치에서 참조할 것인 지를 \(\text{map}_{x}, \text{map}_{y}\) 라는 함수를 정의하여 사용한다는 것입니다. - 리매핑 시 \(\text{map}_{x}, \text{map}_{y}\) 을 잘 정의하면 앞에서 배운 Projective Transformation 뿐만 아니라 다양한 형태의 Transformation을 유연하게 변환할 수 있습니다.
- \[\text{map}_{x}(x, y) = x - 200\]
- \[\text{map}_{y}(x, y) = y - 100\]
- 위 식은 이동 변환을 나타내며 이동 변환을 위한 행렬을 사용하지 않더라도 위 식을 통하여 변환을 할 수 있습니다.
- \[\text{map}_{x}(x, y) = x - 20\]
- \[\text{map}_{y}(x, y) = y - 10\]
- map 식에서 주의할 점은 \(x, y\) 가
dst기준의 좌표값이라는 것입니다. 즉, 출력값의 \(x, y\) 좌표가 있을 때, 이 값이src에서는 어디를 가리키는 지 위치를 알아야 합니다. 예를 들어dst에서의 \((x, y) = (30, 40)\) 인 픽셀은src에서 \((30 - 20 = 10, 40 - 10 = 30) = (10, 30)\) 에 해당합니다. - 즉,
src에서의 \((10, 30)\) 의 좌표가dst에서는 \((30, 40)\) 이 되는 것입니다. 따라서 이동 변환이 x축 기준으로 +20, y축 기준으로 +10이 되었습니다. - 따라서
dst의 좌표값 \((x, y)\) 를src로 부터 참조한다고 생각하면 변환의 방향을 잘 생각하실 수 있습니다.

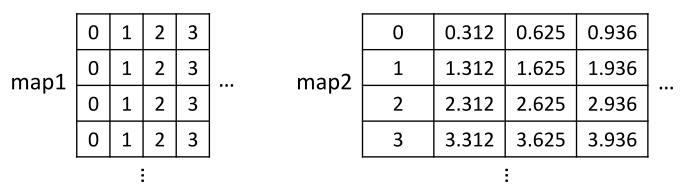
- 위 함수 설명의
map1과map2가 각각 \(\text{map}_{x}, \text{map}_{y}\) 에 해당합니다.map은 입력 영상과 크기가 같으며 사용 방법은 다음 예제를 통해 살펴보겠습니다. - 만약 \(x, y\) 위치에 해당하는 값이 없으면 0의 값 즉, 검정색 값으로 채우게 되는 것에 유의하시기 바랍니다.
src = cv2.imread('scene.png')
h, w = src.shape[:2]
map2, map1 = np.indices((h, w), dtype=np.float32)
map2 = map2 + 10 * np.sin(map1 / 32)
# dst = cv2.remap(src, map1, map2, cv2.INTER_CUBIC)
dst = cv2.remap(src, map1, map2, cv2.INTER_CUBIC, borderMode=cv2.BORDER_DEFAULT)
cv2.imwrite('dst.png', dst)
- 위 코드에서
map1,map2가 각각 x, y에 대한 위치를 나타냅니다. numpy에서 행렬을 다룰 때에는 y축 값을 먼저 기준으로 사용하기 때문에map2,map1순서로np.indices()함수를 이용하여 받습니다.map1,map2의 값 각각은 다음과 같습니다.
- 입력
src의 (h, w) 크기와 같은map1,map2가 생성되며 각 좌표값을 기준으로 가까운 좌표를 가지고 오게 됩니다. 그 결과는 다음과 같습니다.

- 위 결과를 보면 가장 왼쪽이 원본 src이고 중간이 borderMode가 없는 상태이고, 가장 오른쪽이 borderMode가 default (cv2.BORDER_CONSTANT)로 적용된 결과 입니다.
- 리매핑 과정에 따라
dst에서 참조할 수 없는 좌표를src에서 참조하게 되면 중간 그림과 같이hole이 발생하게 됩니다. 이러한 문제를 개선하기 위하여 가장 자리 부분을 채우는 방법이 사용되는데, 기본값은 가장자리 근처의 픽셀값을 고정으로 사용하는 것입니다. 그 결과가 가장 오른쪽 그림과 같습니다.
Perspective Transform을 이용한 문서 스캐너
- 앞에서 배운
Perspective Transform을OpenCV를 이용하여 구현하려면 다음 링크의 함수를 참조해야 합니다.
- 아래 코드는 입력 받은 이미지의
Perspective Transformation행렬을 구하여 A4 용지 크기로 변환하는 코드 입니다. - 아래 코드를
main.py라고 저장한다면python main.py 이미지_경로형태로 입력하시면 됩니다. (ex.python main.py ../test.png)

- 위 그림과 같이 UI를 이용하여 Perspective Transformation을 하여 이미지를 펼 수 있습니다.
import sys
import numpy as np
import cv2
def drawROI(img, corners):
cpy = img.copy()
c1 = (192, 192, 255)
c2 = (128, 128, 255)
for pt in corners:
cv2.circle(cpy, tuple(pt.astype(int)), 25, c1, -1, cv2.LINE_AA)
cv2.line(cpy, tuple(corners[0].astype(int)), tuple(corners[1].astype(int)), c2, 2, cv2.LINE_AA)
cv2.line(cpy, tuple(corners[1].astype(int)), tuple(corners[2].astype(int)), c2, 2, cv2.LINE_AA)
cv2.line(cpy, tuple(corners[2].astype(int)), tuple(corners[3].astype(int)), c2, 2, cv2.LINE_AA)
cv2.line(cpy, tuple(corners[3].astype(int)), tuple(corners[0].astype(int)), c2, 2, cv2.LINE_AA)
disp = cv2.addWeighted(img, 0.3, cpy, 0.7, 0)
return disp
def onMouse(event, x, y, flags, param):
global srcQuad, dragSrc, ptOld, src
if event == cv2.EVENT_LBUTTONDOWN:
for i in range(4):
if cv2.norm(srcQuad[i] - (x, y)) < 25:
dragSrc[i] = True
ptOld = (x, y)
break
if event == cv2.EVENT_LBUTTONUP:
for i in range(4):
dragSrc[i] = False
if event == cv2.EVENT_MOUSEMOVE:
for i in range(4):
if dragSrc[i]:
dx = x - ptOld[0]
dy = y - ptOld[1]
srcQuad[i] += (dx, dy)
cpy = drawROI(src, srcQuad)
cv2.imshow('img', cpy)
ptOld = (x, y)
break
# 입력 이미지 불러오기
# reverse.py
src = cv2.imread(sys.argv[1])
if src is None:
print('Image open failed!')
sys.exit()
# 입력 영상 크기 및 출력 영상 크기
h, w = src.shape[:2]
dw = 500
dh = round(dw * 297 / 210) # A4 용지 크기: 210x297cm
# 모서리 점들의 좌표, 드래그 상태 여부
srcQuad = np.array([[30, 30], [30, h-30], [w-30, h-30], [w-30, 30]], np.float32)
dstQuad = np.array([[0, 0], [0, dh-1], [dw-1, dh-1], [dw-1, 0]], np.float32)
dragSrc = [False, False, False, False]
# 모서리점, 사각형 그리기
disp = drawROI(src, srcQuad)
cv2.imshow('img', disp)
cv2.setMouseCallback('img', onMouse)
while True:
key = cv2.waitKey()
if key == 13: # ENTER 키
break
elif key == 27: # ESC 키
cv2.destroyWindow('img')
sys.exit()
# 투시 변환
pers = cv2.getPerspectiveTransform(srcQuad, dstQuad)
dst = cv2.warpPerspective(src, pers, (dw, dh), flags=cv2.INTER_CUBIC)
# 결과 영상 출력
cv2.imshow('dst', dst)
cv2.waitKey()
cv2.destroyAllWindows()