DeepLab v3 (Rethinking Atrous Convolution for Semantic Image Segmentation)
2019, Nov 04
- 참조 : https://arxiv.org/abs/1706.05587
- 참조 : https://medium.com/free-code-camp/diving-into-deep-convolutional-semantic-segmentation-networks-and-deeplab-v3-4f094fa387df
- 참조 : https://towardsdatascience.com/transfer-learning-for-segmentation-using-deeplabv3-in-pytorch-f770863d6a42
- 이번 글에서는 Semantic Segmentation 내용과 DeepLab v3 내용에 대하여 간략하게 알아보도록 하겠습니다.
- DeepLab v3의 핵심은
ASPP (Atrous Spatial Pyramid Pooling)이며 이 개념의 도입으로 DeepLab v2 대비 성능 향상이 되었고 이전에 사용한 추가적인 Post Processing을 제거함으로써 End-to-End 학습을 구축하였습니다.
목차
-
Semantic Segmentation
-
Model Architecture
-
ResNets
-
Atrous Convolutions
-
Atrous Spatial Pyramid Pooling
-
Torchvision DeepLabv3 살펴보기
Semantic Segmentation
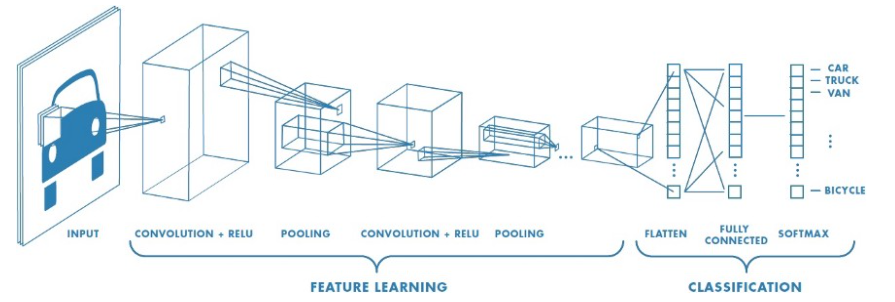
- 위 그림은 기본적인 classification 문제를 다루는 CNN 구조를 나타냅니다. 기본적인 convolution, activation function, pooling, fc layer 등을 가지는 것을 알 수 있으며 입력 이미지를 받았을 때, 이러한 operation들을 이용하여 feature vector를 만들어내고 이 값을 이용하여 classification을 하게 됩니다. (이미지가 어떤 클래스에 해당하는 지 출력합니다.)

- image classification 문제와는 다르게 semantic segmentation에서는 모든 픽셀에 대하여 픽셀 단위 별로 classification을 하고자 합니다. 즉, semantic segmentation에서는 이미지 내의 모든 픽셀에 대한 의미를 이해해야 합니다.
- 일반적으로 사용하는 image classification 모델을 이용하여 단순히 semantic segmentation을 하면 잘 동작하지는 않습니다. 크게 2가지 이유가 있습니다.
- ① image classification 모델은
input feature의spatial dimension을 줄이는 데 집중되어 있습니다. 결과적으로 이러한 목적으로 만들어진 layer는 semantic segmentation을 할 만큼 디테일한 정보를 가지고 있기 어려워 집니다. 첫번째 그림의 예시를 살펴보면feature learning이란 부분에서 feature의 크기가 계속 작아지는 것을 살펴볼 수 있습니다. - ② fully connected layer는 고정된 크기의 layer만 가질 수 있으며 계산 과정 중에 공간적인 정보를 잃어버리는 성질이 있습니다.
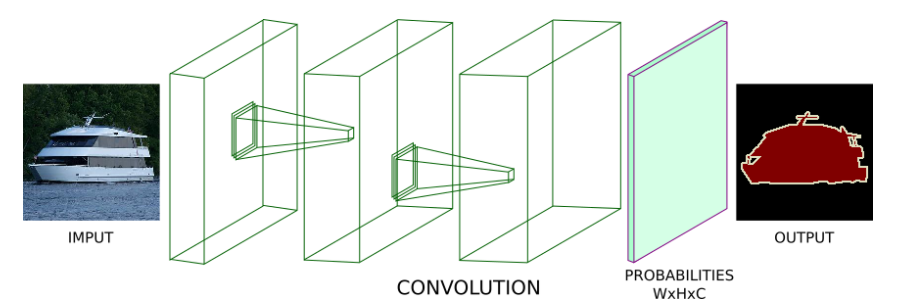
- 반면 위 그림과 같은 예시에서는 pooling 또는 FC layer 대신에 연속적인 convolution을 거치도록 만들었습니다. 특히 convoltuion의
stride=1과padding=same이라는 조건을 사용하였는데 이와 같은 조건의 효과는 convolution이 input의 sptial dimension을 보존하도록 합니다. - 따라서 위 구조에서는 단순히 convolution layer을 쌓기만 하였고 그 결과 segmentation 모델을 만들 수 있습니다.
- 이 모델은
(W, H, C)와 같은 형태의 출력을 가지게 되며W,H는 입력 이미지의 사이즈와 같으며C는 각 픽셀 별 구분하고자 하는 클래스의 수와 같아집니다. 마지막C의 갯수 만큼 확률 분포를 가지게 되며argmax연산을 통하여 가장 큰 확률 값을 가지는 클래스를 선택하였을 때,(W, H, 1)의 크기를 가지는 segmentation 결과를 가지게 됩니다. - 이 결과를 이용하여
Cross Entropy와 같은 Loss function을 통해 실제 ground-truth 이미지와의 차이를 학습을 하게 됩니다.
- 위 과정은 전체적인 semantic segmentation 과정을 잘 설명합니다. 하지만 효율성에 문제가 있습니다.
- 위 구조와 같이 단순히
stride=1,padding=same을 가지는 convolution layer를 계속 쌓게 되면 공간 정보를 계속 유지할 수 있다는 장점은 있지만, 연산량이 많이 증가한다는 단점이 있어 메모리 낭비가 심하며 한 개의 입력을 처리하는 데 처리 시간도 많이 필요합니다.
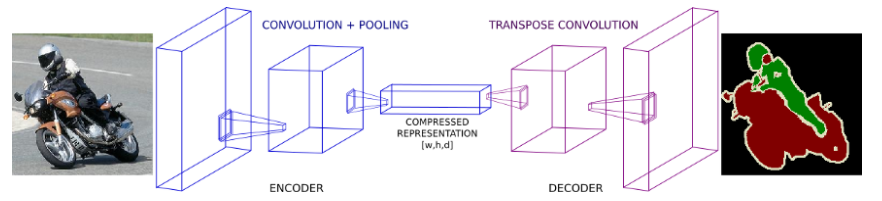
- 이러한 문제를 해결하기 위하여 가장 많이 사용되는 방법이 위 그림과 같이
downsampling와upsamplinglayer를 사용하여 연산량을 줄이는 방법입니다. - 먼저
downsampling방법을 살펴보면convolution layer를stride또는pooling연산과 함께 사용하는 방법이 있습니다.downsampling의 목적은 feature map의 spatial dimension을 줄여서 효율성을 높이는 것입니다. 위 그림의Encoder영역을 보면 이와 같은 역할을 볼 수 있습니다. 연산의 효율성을 높이는 대신에 feature 일부를 소실한 것을 확인할 수 있습니다. - 이와 같은
Encoder구조는classification에서 fully connected layer를 적용하기 이전의 구조와 같습니다. 즉feature extraction을 하는 역할을 한다고 볼 수 있습니다. - 가운데
compressed representation을 살펴보면feature의 shape이(w, h d)로 나타내어져 있고 모양을 보았을 때,w,h는 입력 이미지에 비해 작을 것이고d는 입력 이미지에 비해 클 것으로 판단됩니다. 이와 같은 방식으로 spatial dimension이 압축이 되었습니다. - 이제 압축된 feature를 다시 원래 해상도로 원복하는 역할을 해야 합니다.
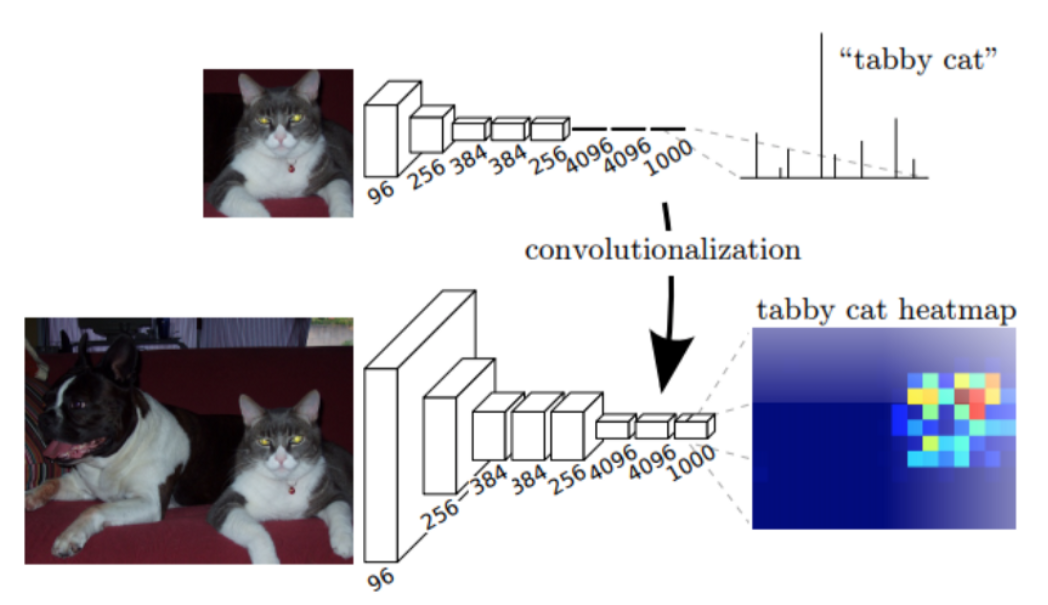
- 윗쪽 이미지는 전형적인 classification을 나타낸 것이고 아랫쪽 이미지는 classification의 마지막 fully connected layer를 1x1 convolution으로 대체한 뒤 나온 출력을 heatmap 형태로 표시한 것입니다. 이 때, 어느 부분이 classification에 직접적으로 사용된 영역인 지 heatmap으로 볼 수 있습니다.
- 이와 유사한 방법으로 feature의 마지막 부분에
upsample layer를 붙여서 압축된 feature를 원래 해상도로 다시 복원하는 작업을 하여 segmentation을 완수합니다.
upsample방법으로strided transpose convolution을 많이 사용하곤 합니다. 이 layer는 기본적으로 deep 하고 narrow한 feature를 wider 하고 shallow한 형태로 바꾸는 작업을 합니다.- 대부분의 논문에서는 입력 이미지를 압축된 feature로 바꾸는 역할의 layer를
Encoder라고 하며 압축된 feature를 다시 원복하는 역할을Decoder라고 합니다. - 많은 segmentation 모델들은
Encoder - Decoder형태를 따르고 있으며 이번 글에서 다루는DeepLab v3또한 이와 같은 구조를 따릅니다. - 이번 글에서 다룰 점은
DeepLab v3의Encoder와Decoder가 어떤 형태를 따르는 지 살펴보겠습니다.
Model Architecture
- DeepLab v3에서는
multi-scale contextual feature를 학습할 수 있도록 구조를 설계하였습니다.
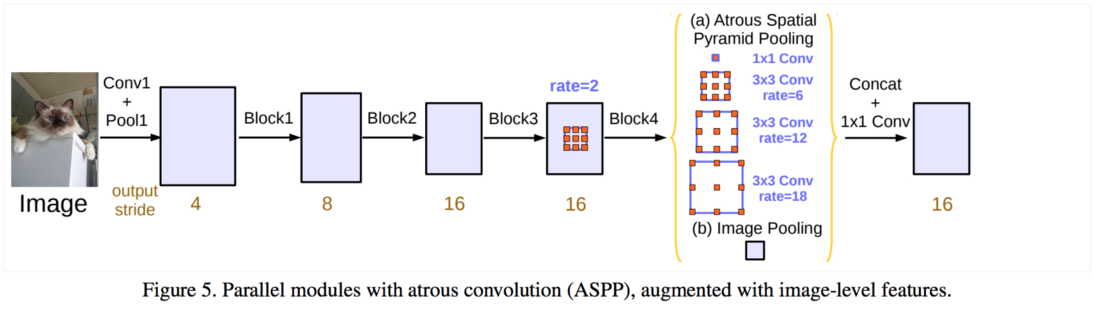
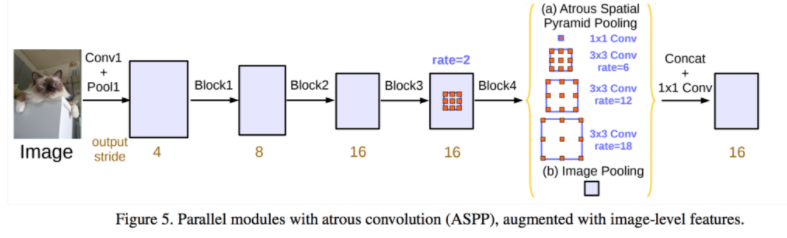
- 위 그림에서 (a) Atrous Spatial Pyramid Pooling 이 핵심 내용이 됩니다.
- DeepLab v3에서는 feature extractor로써 ImageNet pre-trained 된
ResNet을 사용합니다. 차이점은 ResNet 마지막 부분에 단순히 convolution으로 끝나는 것이 아니라 atrous convolution을 사용한다는 점입니다. 이 각각의 atroud convolution의 dilation을 다르게 적용하여multi-scale context를 학습하는 데 그 목적이 있습니다. - 이러한 구조가 위 그림에서 나타낸 (a) 이며 이 내용은 글 아래에서 더 자세하게 살펴보겠습니다.
- 그러면
Encoder를 정확히 알아보기 위하여 ①ResNet, ②Atrous Convolution, ③ASPP(Atrous Spatial Pyramid Pooling)순으로 나누어 알아보겠습니다.
ResNets
- ResNet은 더 깊은 네트워크를 쌓을 수 있도록 skip connection을 적용한 유명한 모델이며 이 글에서는 DeepLab v3에서 어떤 ResNet을 적용하였는 지 위주로 살펴볼 예정입니다.
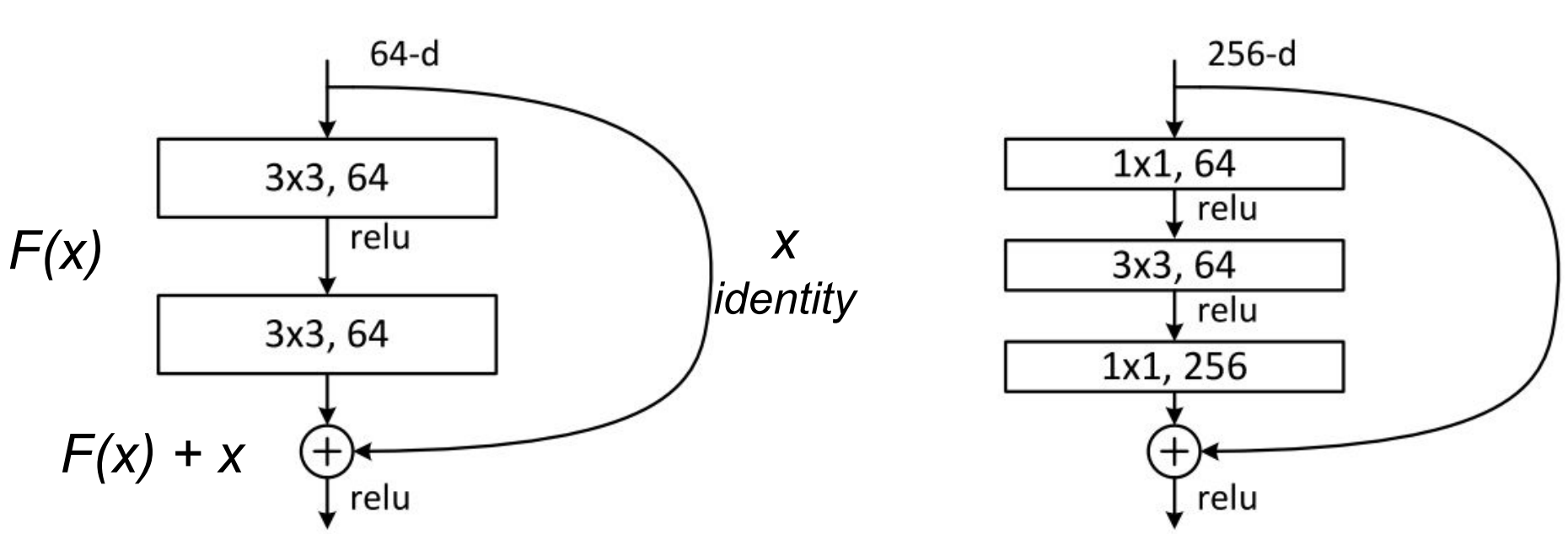
- 위 그림에서 왼쪽 형태가 ResNet의 기본 block 중
baseline이라고 불리고 오른쪽 형태가bottleneck unit이라고 불립니다. - 각 사각형 박스는 convolution layer를 의미하며 각 convolution layer는
conv - batchnorm - ReLu의 형태로 이루어져 있습니다. - 위 식에서는 convolution layer를 거친 feature를
F(x)로 표현하고 skip connection을 통해 그대로 전파된 feature를x로 표현하였습니다. F(x) + x에서 x를 통해 전파되는 gradient의 값이 유지되므로 gradient vanishing문제를 개선할 수 있었고 그 결과 더 깊은 layer를 쌓을 수 있었습니다.baseline은 단순히 2번의 convolution layer와 skip connection으로 연결된 feature를 합치는 방식을 취합니다.bottleneck unit은 baseline에 비해 추가된1x1 convolution을 이용하여 feature의 dimension 크기가 줄었다가 다시 커지는 형태를 띄게 됩니다- 2가지 방식의 성능을 비교하면
baseline에서도 충분히 좋은 accuracy 성능을 가지지만 연산 속도 측면에서bottleneck unit이 더 이점을 가지게 됩니다.
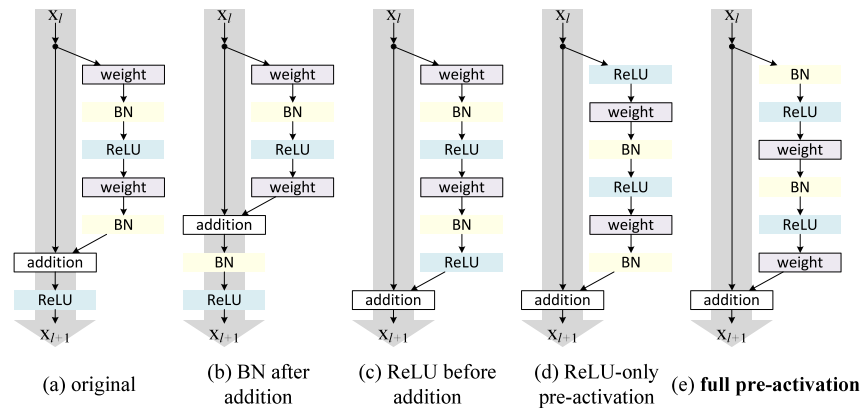
- DeepLab v3에서 사용되는 ResNet의 형태는 위 그림의 가장 오른쪽과 같으며
full pre-activation버전이라고 칭합니다. DeepLab v3 당시 full pre-activation 버전의 성능이 좋았으므로 이와 같이 적용 되었습니다.
Atrous Convolutions
- Atrous (diliated) convolution은 기본적인 convolution layer에서 filter의 FOV (Field Of View)를 늘리기 위하여 필터 window 내부적으로 간격을 띄운 형태를 의미합니다.
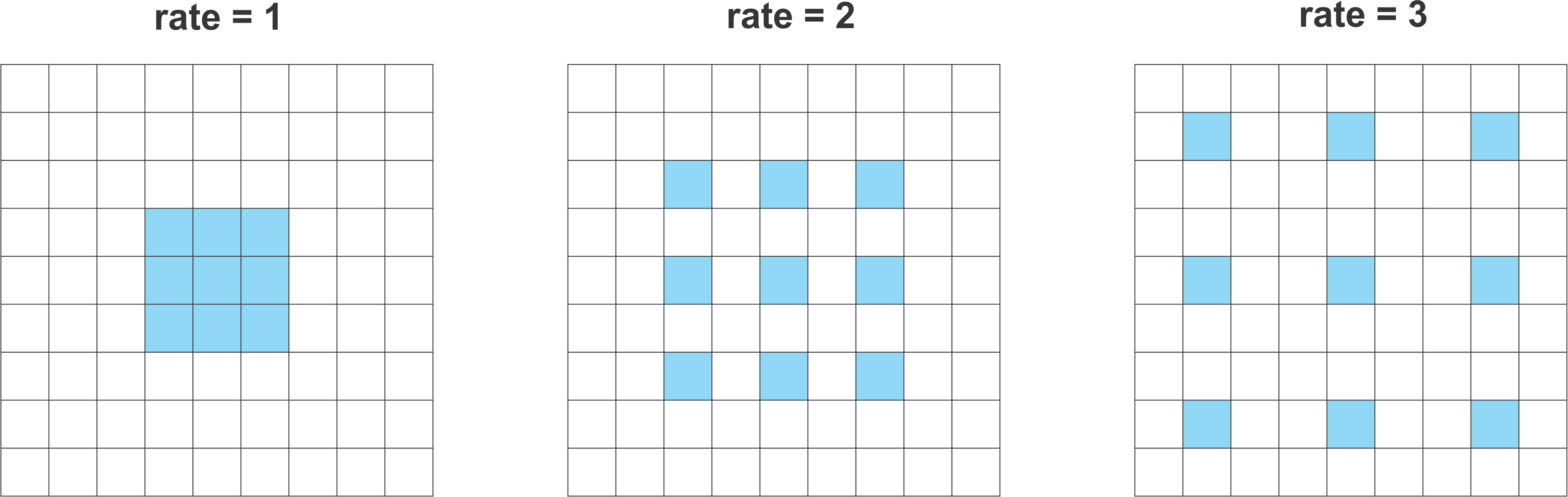
- 위 그림은
dilation rate를 변화하였을 때, convolution layer의 FOV를 나타냅니다. rate를 높였을 때, filter가 가지는 weight의 갯수는 같지만 FOV는 좀 더 넓어진 것을 볼 수 있습니다. - dilation rate가 커지면 filter 내부적으로 빈 공간이 늘어나게 되고 이 빈 공간은 0으로 채워지게 되어 sparse한 형태를 가지게 됩니다.
- 만약 dilation rate = 2로 적용한 경우 5 x 5 convolution과 같은 영역을 보게되지만, sparse한 형태를 가지므로 연산은 3 x 3 convolution과 같아집니다. 이러한 연산을 효율적으로 하기 위하여 각 framework에서는 실제 sparse한 형태의 큰 필터를 설계하지 않고 3 x 3 의 크기만 연산할 수 있도록 operation을 지원합니다.
- 이와 같은 원리로 dilation rate = 3으로 적용한 경우 7 x 7 convolution과 같은 영역을 보도록 convolution layer를 만들 수 있습니다.
- 이와 같은 방식으로 FOV는 넓히고 파라미터 수와 연산량은 유지하는 방법을 사용하고자 하는 것이 Atrous Convolution입니다.
- DeepLab v3에서 보여준 점 중에서 feature map의 크기에 따라서 dilation rate를 튜닝해 주어야 한는 점이 있습니다. 이와 같은 이유는 작은 feature map에 너무 큰 dilation을 적용하였을 때 발생하는 문제점때문입니다.

- 위 그림과 같이 작은 feature map에 너무 큰 dilation rate를 적용하면 의도치 않게 3 x 3 convolution이 1 x 1 convolution 처럼 적용되는 문제가 발생하게 됩니다.
- 따라서 핵심이 되는
dilation rate를 어떻게 조정하는 지가 성능에 큰 영향을 끼치게 되며 이 값을 튜닝하는 데 노력을 기울여야 한다고 설명합니다.
- 추가적으로
output stride라는 용어를 통해 입력 이미지의 해상도 대비 출력 feature의 해상도의 비율을 관리하고 이 비율이 너무 줄어들지 않도록 합니다. deeplab v3에서는output stride=8또는 ``output stride=16을 사용하여 공간 정보가 너무 줄어드는 것을 관리하였습니다. 예를 들어 입력 이미지가 (512, 512)의 사이즈를 가지고 출력하고자 하는 feature의 해상도가 (32, 32)를 가지면output stride=8`이 됩니다. output stride가 작을수록 segmentation의 결과가 더 정교합니다. 물론 연산해야 할 feature의 크기는 크므로 연산량은 더 많아지는 단점이 있습니다.
Atrous Spatial Pyramid Pooling
- DeepLab v3에서는 이와 같은
Atrous Convolution의 개념과Output Stride라는 개념을 이용하여ASPP라는 모듈을 만들어 사용합니다. ASPP는 DeepLab v2에서 먼저 사용되었고 DeepLab v3에서는 이 ASPP 구조를 좀 더 개선하여 사용하고 있습니다. 자세한 내용은 아래 제 블로그 링크에서 확인할 수 있습니다.- 이 글에서 간략하게 다루어 보면
ASPP는 Atrous Convolution을 Multi-Scale로 적용하는 것이 핵심으로 다양한dilation rate의 convolution을 parallel 하게 사용하여 Multi-Scale의 FOV를 가질 수 있도록 합니다. 구체적으로 1개의 1x1 convolution과 3개의 3x3 convolution을 parallel하게 사용하며 3x3 convolution 각각은dilation = (6, 12, 18)또는dilation = (12, 24, 36)을 적용하였습니다. - 추가적으로
GAP (Global Average Pooling)또한 사용하여 Global Context를 이해할 수 있도록 하여 최종적으로 다음과 같은 연산을 거치게 됩니다.
- ① = 1x1 convolution → BatchNorm → ReLu
- ② = 3x3 convolution w/ rate=6 (or 12) → BatchNorm → ReLu
- ③ = 3x3 convolution w/ rate=12 (or 24) → BatchNorm → ReLu
- ④ = 3x3 convolution w/ rate=18 (or 36) → BatchNorm → ReLu
- ⑤ = AdaptiveAvgPool2d → 1x1 convolution → BatchNorm → ReLu
- ⑥ = concatenate(① + ② + ③ + ④ + ⑤)
- ⑦ = 1x1 convolution → BatchNorm → ReLu
- 글의 처음에 사용한 DeepLab v3의 이미지를 다시 한번 살펴보겠습니다.
- 각 파란색 박스는
Residual Block을 나타내며 앞의 글ResNet에서 다룬 내용에 해당합니다. - 각 feature 아래에 노란색 글씨는 feature의
output stride를 나타내며rate는dilation rate를 나타냅니다. Block4는Atrous Residual Block이 적용이 되었고 방법은Multi Grid = (1, 2, 4) or (2, 4, 8)방법을 사용하였습니다.Atrous Residual Block이후에는ASPP구조가 적용되었습니다.
Torchvision DeepLabv3 살펴보기
- 다음은 위에서 배운 개념과 비교하여
torchvision에서 제공하는 DeepLab v3과 비교해서 살펴보도록 하겠습니다. 사용한 모델은resnet50 기반의 deeplabv3입니다. - 먼저 다음과 같은 코드를 이용하여
onnx를 만든 다음과netron에서 실행 후 비교하겠습니다. 상세 과정은 다음 절차를 참조 하시면 됩니다.
import torch.onnx
from torchvision import models
model = models.segmentation.deeplabv3_resnet50()
dummy_data = torch.empty(1, 3, 512, 1024, dtype = torch.float32)
torch.onnx.export(model, dummy_data, "deeplabv3_resnet50.onnx", opset_version=11)
torch.onnx.export(model, dummy_data, "deeplabv3_resnet50.onnx", opset_version=11)
onnx.save(onnx.shape_inference.infer_shapes(onnx.load("deeplabv3_resnet50.onnx")), "deeplabv3_resnet50.onnx")
- 위 코드를 살펴보면
(C, H, W) = (3, 512, 1024)의 사이즈의 입력을 사용하였습니다. - 생성된 전체 모델의 아키텍쳐를 살펴보려면 다음 링크 또는 글 가장 아래 이미지를 참조해 주시면 됩니다.
- 앞에서 다룬 내용과 torchvision의 모델에는 차이점이 있는 것을 확인하였습니다. 이점 참조하여 아래 내용 살펴보겠습니다.
- 살펴볼 내용은 크게 3가지 부분으로 ①
downsampling, ②residual block, ③ASPP입니다. - 입력 데이터를 받은 후 ①, ②를 반복하여 구성한 다음에 마지막에 ③ 을 통해
Encoder를 완성하고 마지막에는interpolation을 통해 원래 해상도로 복원하는Decoder를 적용하였습니다.
{kind=link}
- ①
downsampling내용을 살펴보겠습니다.
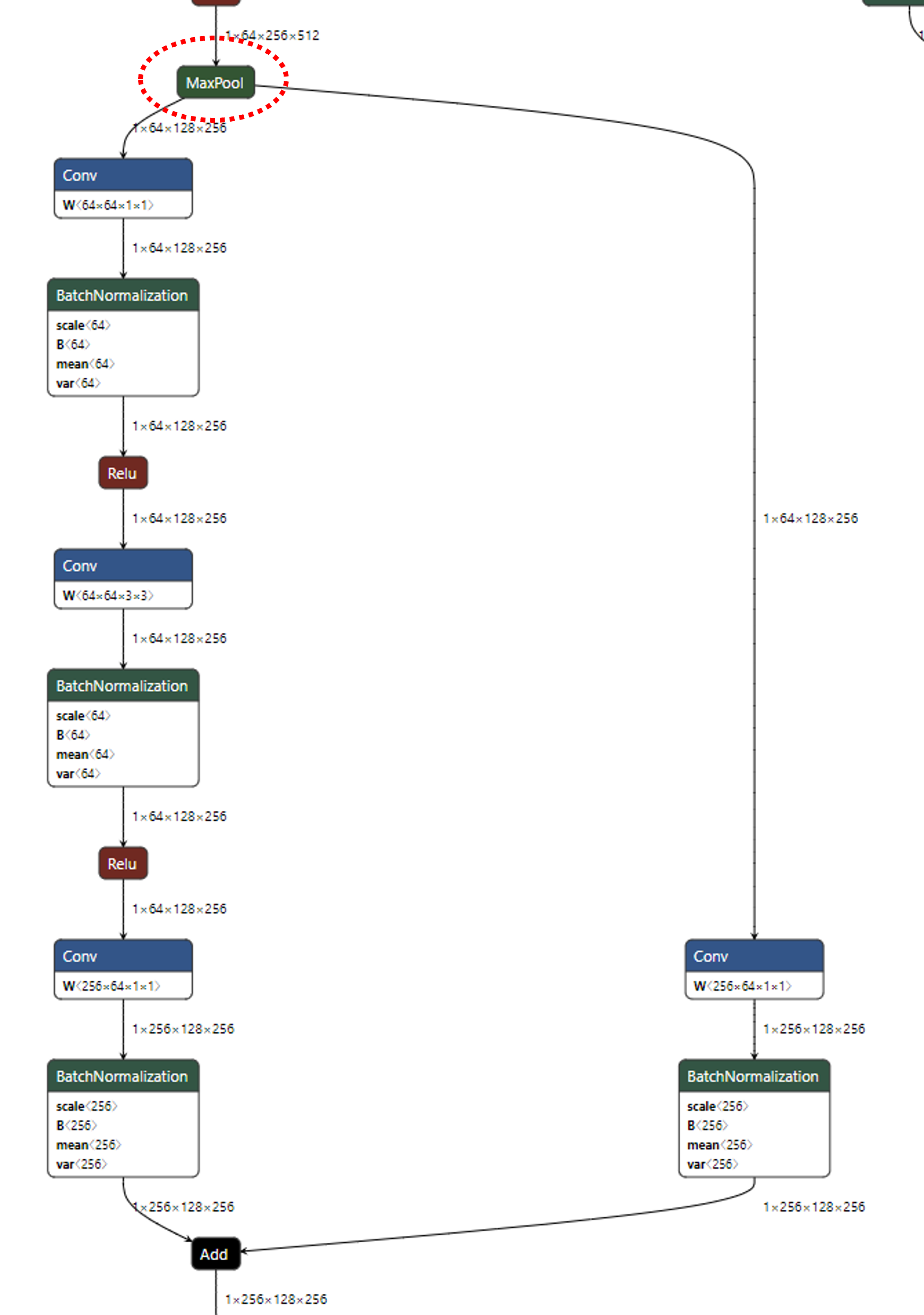
intput 및 feature를 입력 받으면maxpooling을 통하여 downsampling을 한 뒤, 위 아키텍쳐와 같은 형태로 block을 구성합니다.
- ②
residual block내용을 살펴보겠습니다.
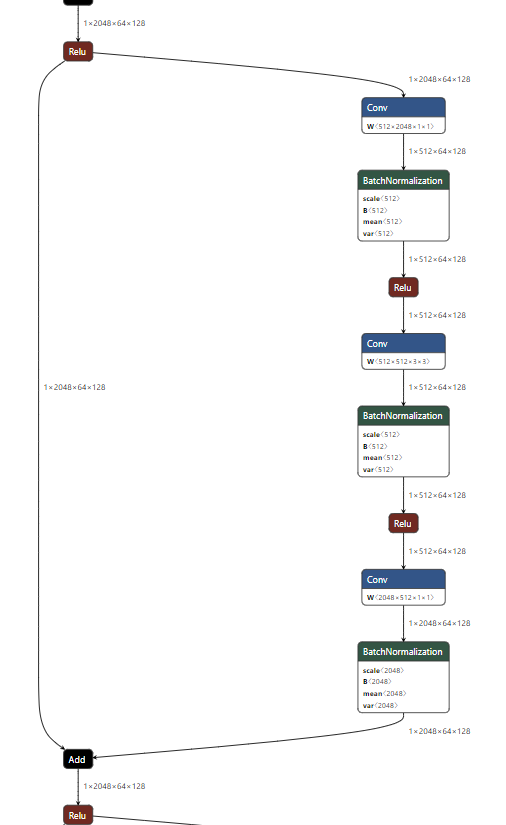
- 앞에서 다룬
fuul pre-activation구조가 아닌 기본적인baseline구조를 사용하였습니다. 어떤 연산도 적용되지 않은skip connection과conv-batchnorm-relu2번이 적용된 feature가Add된 후 다시relu가 적용된 형태가residual block이 됩니다.
- ③
ASPP내용을 마지막으로 살펴보겠습니다.
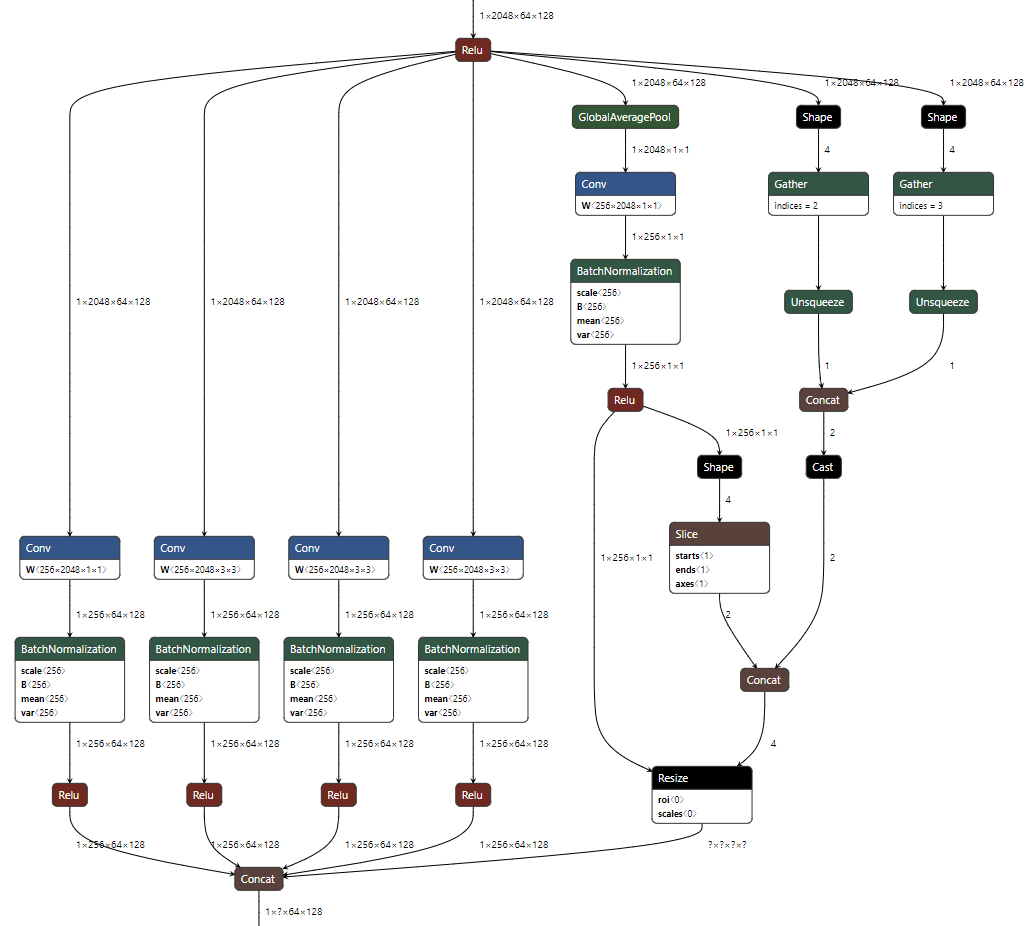
- 왼쪽서 부터 4개의 convolution이 parallel하게 있습니다. 가장 왼쪽은 1x1 convolution이고 2, 3, 4번째 convolution은 3x3 convolution이며 dilation=(6, 12, 18)로 적용되어 있습니다.
- 추가적으로 Global Average Pooling도 parallel하게 적용되어 있는 것을 볼 수 있습니다.
- 다음은 전체 아키텍쳐를 나타낸 것입니다.
